基于高光谱信息的烟叶分级方法比较
2021-11-02李士静陈熙卓朱均燕吴碧致谢小芳温永仙
李士静,潘 羲,陈熙卓,朱均燕,吴碧致,谢小芳,温永仙*
1.福建农林大学计算机与信息学院,福州市仓山区上下店路15号 350002 2.福建农林大学统计及应用研究所,福州市仓山区上下店路15号 350002 3.福建省三明市烟草公司宁化分公司,福建省宁化县镇南大街烟草大厦 365400 4.福建省烟草公司三明市公司,福建省三明市崇桂新村100幢 365000 5.厦门大学近海海洋环境科学国家重点实验室,福建省厦门市翔安区S201 361000 6.福建农林大学生命科学学院,福州市仓山区上下店路15号 350002
烟叶是我国重要的经济作物之一,严格规范其品质检验与等级划分过程具有重要意义。传统的烟叶分级主要依靠人工感官和经验进行判定,但不同人的感官和经验存在差异,因此人工分级具有较强的主观性和随意性,容易导致烟叶分级不准确,对卷烟生产造成不良影响[1]。针对此问题,近年来采用人工智能技术代替人工分级已有较多研究,主要分为3个方面:①基于机器视觉技术结合神经网络的烟叶自动分级研究[2-4],利用机器视觉技术提取烟叶表面特征,将烟叶的颜色、形状、纹理等特征作为神经网络的输入变量,建立基于烟叶图像特征的分类模型。该方法对同一片烟叶需要进行3次以上图像采集,采集样本量大,耗费时间长,且采集过程容易受到外部因素影响,导致图像质量不高,从而影响烟叶等级识别的正确率[5]。此外,机器视觉技术只提取烟叶表面特征,当烟叶存在未完整放置、未完整铺开、正反面放置不一致、叶片之间有重叠等问题时,会导致烟叶分级效果降低[6]。②基于模糊模式识别的烟叶自动分级研究[7-8],结合模糊数学和模糊模式识别并基于化学指标建立烟叶等级识别模型,但该方法的数学规则推导复杂且化学指标测量过程耗时长,导致分类正确率不高。③基于光谱技术的烟叶自动分级研究[9-10],通过无损方式获得烟叶光谱数据,进而建立基于光谱特征的烟叶分类模型。光谱技术具有快速、简单、无损等特点,利用光谱技术可以获得反映烟叶外部结构特征的光谱,以及与烟叶密切相关的化学指标和内部结构信息。与机器视觉技术相比,利用光谱技术建立的烟叶分类模型可靠性更高。
高光谱成像是一种将成像技术与光谱技术相结合的影像数据技术,具有光谱分辨率高、多波段、检测速度快且无损等特点[11]。高光谱图像包含图像信息和光谱信息,图像信息可以真实地展现农作物的表面损失及外部特征,光谱信息则能反映出农作物的内部结构及成分组成。高光谱成像技术目前已广泛应用于农产品内外部品质检测、损伤识别、作物信息获取等方面[12]。程术希等[11]采用多元散射校正(Multivariate Scattering Correction,MSC)预处理方法对大白菜种子的高光谱信息进行消噪,利用极限学习机(Extreme Learning Machine,ELM)和 随 机 森 林(Random Forest,RF)等方法识别大白菜种子,识别正确率均超过90%。杨思成等[13]基于PCA(Principal Component Analysis)提取特征光谱的图像信息,结合Fisher识别模型、偏最小二乘回归模型、人工神经网络模型对稻谷品种进行分类识别,分类正确率均达到95%。李丹等[14]采用多元散射校正(MSC)、标准正态变量变换(Standard Normal Variate transformation,SNV)等方法对树种叶片的高光谱数据进行预处理,运用随机森林(RF)和支持向量机(Support Vector Machine,SVM)分类模型进行建模,分类正确率在54.41%~77.06%之间。张龙等[15]利用高光谱成像技术对烟叶和杂物进行分类,分类正确率达到99.92%,提高了除杂效果。邢雪霞等[16]基于烤烟叶片的高光谱曲线特征,建立了色素含量的预测模型,选择出与色素含量相关性最高的高光谱特征参数。但利用高光谱成像技术进行烟叶分级的研究则鲜见报道。为此,基于高光谱信息探讨了不同数据预处理方法以及分类模型对烟叶分类正确率的影响,建立了基于特征波段的4种烟叶分类模型并对其进行验证,以期提高烟叶等级识别正确率,提升烟叶分级智能化水平。
1 材料与方法
1.1材料
数据集A的烟叶样本为31个2019年国家标准样本,包含B1F、B2F和B3F共3个等级;数据集B的烟叶样本为147个2020年国家标准样本,包含C2F、C3F和C4F共3个等级。所有烟叶样本均由福建省烟草专卖局烟草科学研究所提供,并按照烤烟分级国家标准(42级)GB2635—1992[17]进行定级。具体样本信息见表1。

表1 烟叶样本信息Tab.1 Information of tobacco leaf samples
1.2 设备与仪器
数据集A的高光谱成像系统由Gaiasky-mini2-VN光谱仪(四川双利合谱科技有限公司)、HSIALS-T-200W专用光源(四川双利合谱科技有限公司)以及安装有Spectral-image(台湾五铃光学股份有限公司)的专用计算机组成,见图1。系统参数:图像分辨率为960 pixel×176 pixel;波长范围为400~1 000 nm,共包含176个波段;光谱分辨率为3.5 nm;曝光时间为6.4 ms;光源强度为200 W。由于波长400~1 000 nm范围内的波段头尾处存在较大噪声,故选取500~900 nm范围内的116个波段进行分析。
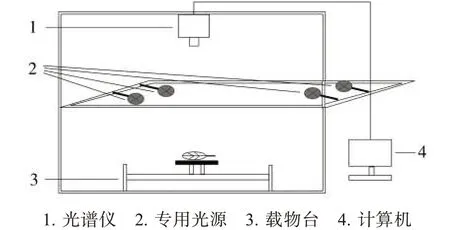
图1 数据集A的高光谱成像系统结构示意图Fig.1 Structure of hyperspectral imaging system for dataset A
数据集B的采集系统由高感度EM285CL EMCCD相机(北爱尔兰Raptor Photonics公司)、Imspector V10E成像光谱仪(芬兰Spectral Imaging公司)、IT 3900 150 W卤素灯(美国Ocean Optics公司)以及安装有Spectral-image(台湾五铃光学股份有限公司)的专用计算机组成,见图2。系统参数:图像分辨率为1 024 pixel×237 pixel;波长范围为400~1 000 nm,共包含237个波段;光谱分辨率为2.4 nm;曝光时间为8 ms;光源强度为70 W;平台移动速度为13.3 mm/s。

图2 数据集B的高光谱成像系统结构示意图Fig.2 Structure of hyperspectral imaging system for dataset B
1.3 高光谱图像采集
如图3所示,将每个烟叶样本展开平铺在载物台的黑布上,通过高光谱成像系统进行数据采集。利用遮盖镜头及标准白板图像获得黑板和白板校正图像,用于对原始高光谱图像进行校正[12]。计算公式为:

图3 烟叶样本的高光谱图像Fig.3 Hyperspectral image of tobacco sample
式中:R表示校正后样本图像;I表示样本原始图像;B表示黑板校正图像;W表示白板校正图像。

在黑白板校正后的高光谱图像中,利用ENVI(Enviroment for Visualizing Images,美国ITT Visual Information Solutions公司)软件在叶茎两侧的叶片部位随机选取15 pixel×15 pixel的感兴趣区域(Region of Interest,ROI),每个像素点包含一条光谱信息,将ROI内所有像素点的平均光谱反射率作为样本的高光谱数据。每个等级烟叶选取300个ROI,数据集A和B分别得到900个样本。随机选择800个样本作为训练集,100个样本作为测试集。
1.4 数据预处理
高光谱数据中除了包含烟叶样本化学指标信息外,还含有其他无关信息和噪声。因此,在建立模型前,利用多元散射校正(MSC)、标准正态变量变换(SNV)、Savitzky-Golay卷积平滑(SG)3种方法对数据进行预处理[18],以消除高光谱数据中的无关信息和噪声。
(1)多元散射校正(MSC)是一种多变量散射校正技术,可以消除样本间散射所导致的基线平移和偏移现象,增强与成分含量相关的光谱吸收信息,提高原始光谱的信噪比[19]。

式中:xi表示所需校正光谱集的第i条光谱(i=1,2,…,n);xi(MSC)表示多元散射校正处理后的第i条光谱;n表示需要校正的光谱数量;mi和bi分别表示利用最小二乘法求取的第i条光谱的系数和截距。
(2)标准正态变量变换(SNV)的作用是消除固体颗粒大小、表面散射的影响,以及光程变换对NIR漫反射光谱的影响[18]。

式中:xi,k表示第i条光谱在第k处波长(k=1,2,…,m)的反射率值;m表示波长点数;x(iSNV)表示标准正态变量变换处理后的第i条光谱。
(3)Savitzky-Golay卷积平滑法(SG)是一种信号平滑方法,主要用于消除高光谱数据的随机噪声。
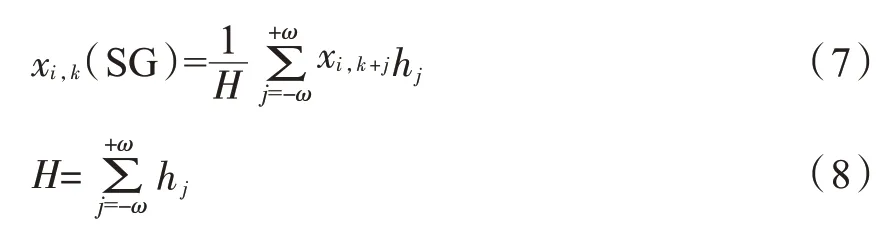
式中:xi,(kSG)表示SG卷积平滑处理后的第i条光谱在第k处波长的反射率值;xi,k+j表示第i条光谱在第(k+j)处波长的反射率值;2ω+1表示平滑窗口的宽度;hj表示平滑系数,测量值乘以平滑系数hj的目的是尽可能地减少平滑处理对有用信息的影响;H表示归一化因子。
1.5 化学计量学方法
采用随机森林(RF)、支持向量机(SVM)、极限学习机(ELM)和梯度提升决策树(GBDT)4种算法分别建立分类模型;采用F-Score算法选取烟叶高光谱数据的特征波段。随机森林(RF)是Breiman等[20]提出的一种基于决策树的集成算法,对数据噪声容忍度好,具有人工干预少、运算速度快等优点[21]。支持向量机(SVM)是一种基于结构风险最小化的统计学习方法[22],其决策函数由少数的支持向量确定,在某种意义上避免了“维数灾难”问题[23],因此具有较强的泛化能力。本研究中选择了用于处理SVM模式识别与回归的软件包LIBSVM[24],核函数选用了径向基函数(Radial Basis Function,RBF)。极限学习机(ELM)是由Huang等[25]提出的一种简单高效的单隐层前馈神经网络算法,具有学习速度快、耗时短、效率高、算法复杂度低等优点[26]。梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是 由Friedman[27]提出的一种由多个弱分类器经过迭代形成的强分类器,可灵活处理各种数据,预测准确率高,对异常值具有较强的鲁棒性[28]。F-Score算法主要用于衡量特征在不同类别间的分辨能力,通过计算数据集中每个特征的F-Score值以及所有特征的F-Score平均值而得到阈值。如果某一特征的F-Score值大于阈值,则将该特征加入特征空间;否则,则将该特征从特征空间中移除[29]。F-Score算法能够选择较小的变量子集进行计算,从而减少计算消耗,提高算法性能。
1.6 数据分析软件
采用ENVI 5.3软件提取烟叶样本ROI的光谱反射率信息;采用MATLAB 2016a建立随机森林(RF)、支持向量机(SVM)和极限学习机(ELM)的分类模型,并利用F-Score算法选取特征波段;采用Python 3.8建立梯度提升决策树(GBDT)的分类模型。
2 结果与分析
2.1 烟叶原始光谱曲线和平均光谱曲线
两个数据集中所有烟叶样本的原始光谱反射率随波长变化曲线见图4。可见,不同波长下反射率整体呈上升趋势,在670~680 nm范围内存在一个反射率波谷,原因是该波段范围为叶绿素的强吸收带,而叶绿素a和b对植物的反射率光谱曲线影响较大[30]。数据集A和B在680~700 nm范围内反射率急剧上升,曲线几乎垂直于x轴。
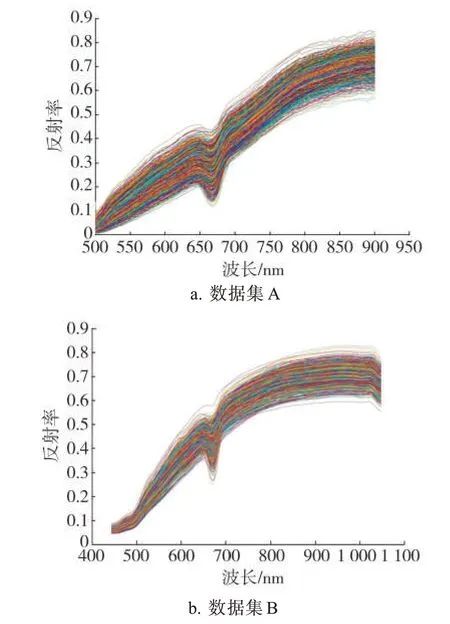
图4 两个数据集中所有烟叶样本的原始光谱曲线Fig.4 Original spectral curves of tobacco leaf samples in two datasets
两个数据集中同一等级烟叶样本的平均光谱在不同波长下的反射率变化曲线见图5。可见,同一数据集中不同等级烟叶的平均光谱曲线变化趋势相似,曲线之间的间隔较小,这种现象在数据集B中更为明显,说明依靠原始数据区分不同等级烟叶难度较大,需要进一步进行数据预处理和建模分析。
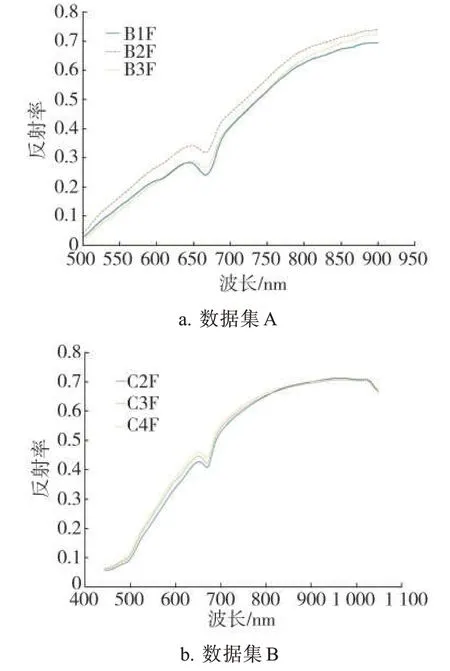
图5 两个数据集中同一等级烟叶样本的平均光谱曲线Fig.5 Average spectral curves of tobacco leaf samples of different grades in two datasets
2.2 不同数据预处理法对分类正确率的影响
分别采用MSC、SNV、SG这3种方法对两个数据集中不同等级烟叶的高光谱数据进行预处理,并绘制预处理后所有烟叶样本的光谱曲线,见图6和图7。可见,经MSC预处理后两个数据集的光谱曲线更加集中,其中数据集A预处理后在波长500~600 nm和800~900 nm处的曲线没有原始数据曲线光滑,原因可能是数据集A烟叶样本间的基线平移和偏移现象不明显,经过预处理反而加入了噪声。经SNV预处理后数据集B的相对反射率(原始反射率经预处理变换后得到的反射率)相比数据集A波动较大,可能是由于数据集B的波长点数多于数据集A,导致标准偏差增大。数据集A与B经SG预处理后的光谱曲线与原始光谱曲线差异不明显。

图6 数据集A预处理后的光谱曲线Fig.6 Preprocessed spectral curve of dataset A
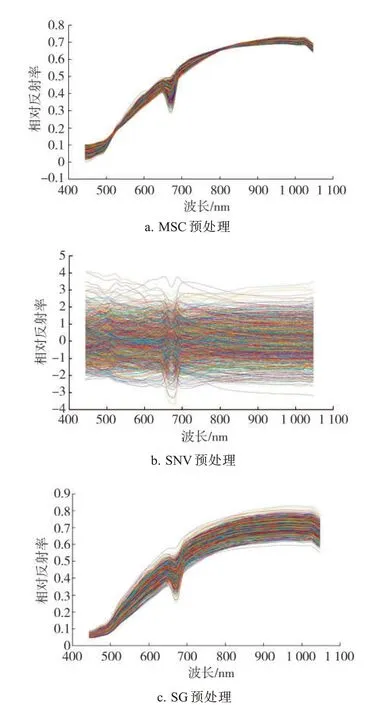
图7 数据集B预处理后的光谱曲线Fig.7 Preprocessed spectral curve of dataset B
将预处理后的数据集作为输入变量,烟叶等级对应的标签作为输出变量,建立随机森林(RF)、支持向量机(SVM)、极限学习机(ELM)以及梯度提升决策树(GBDT)4种烟叶分类模型。选择分类正确率作为分类模型的评价指标,分类正确率是指正确分类的样本占所有样本的比例。对原始数据和不同预处理后数据进行分类,结果见表2和表3。可见,经SG或SNV预处理后两个数据集的分类正确率整体上与原始数据的分类正确率接近,可能是烟叶样本间散射现象不明显,随机噪声小,导致经过预处理的数据丢失了有效信息。数据集A经MSC预处理后,SVM模型的分类正确率明显下降,可能是经MSC预处理后增加了噪声,而SVM模型对噪声比较敏感。MSC预处理在数据集A中提高了ELM和GBDT模型的分类正确率,在数据集B中提高了全部4种模型的分类正确率。对比发现,经MSC预处理后分类正确率相对较高,在数据集A中平均分类正确率仅比SNV、SG低1.00百分点、1.75百分点,但在数据集B中比SNV、SG高18.25百分点、11.75百分点。综上,MSC预处理略优于其他两种预处理方法,能够提高分类模型的识别效果。
2.3 不同模型的分类正确率比较
在RF模型中,利用逐步搜索法选择决策树的个数,得到数据集A和B的决策树个数分别为200和50。在SVM模型中,利用LIBSVM软件包中K折交叉验证法(本文中为五折交叉验证法)进行参数选择,得到数据集A的惩罚系数C为256,核函数参数γ为0.25;数据集B的惩罚系数C为1 024,核函数参数γ为0.062 5。在ELM模型中,选择常用的Sigmoidal函数作为激励函数,采用十折交叉验证法对隐层节点数进行选择,数据集A和B的分类正确率随隐层节点数变化的曲线见图8。当验证集的分类正确率逐渐趋于稳定时,得到分类正确率最大时数据集A对应的隐层节点数为139个,数据集B为169个。在GBDT模型中,利用网格搜索法对参数进行选择,得到数据集A的学习率为0.1,迭代次数为180次,决策树深度为7;数据集B的学习率为0.1,迭代次数为170次,决策树深度为7。

图8 不同隐层节点数下两个数据集分类正确率变化曲线Fig.8 Variation curves of classification accuracy at different hidden node numbers for two datasets
4种分类模型下两个数据集的分类正确率见表2和表3。可见,RF和GBDT模型对数据集A原始数据(波段数116个,维数116)的分类正确率为77%和76%,对数据集B原始数据(波段数237个,维数237)的分类正确率为54%和55%。在数据集B中分类正确率下降的原因,除了基线平移和偏移外,还可能是随着数据维数的增加,存在过拟合现象。对比发现,ELM和SVM模型的识别效果最佳,基于MSC预处理的分类正确率在数据集A中分别达到84%和80%,在数据集B中分别达到96%和95%。其中,ELM模型可能对SNV预处理后的数据比较敏感,分类正确率受到较大影响,在数据集A中从83%下降到77%,在数据集B中从91%下降到62%。综上,基于全波段建立的分类模型识别效果较优,其建模方案是预处理方法为多元散射校正(MSC),分类模型为极限学习机(ELM)或支持向量机(SVM)。
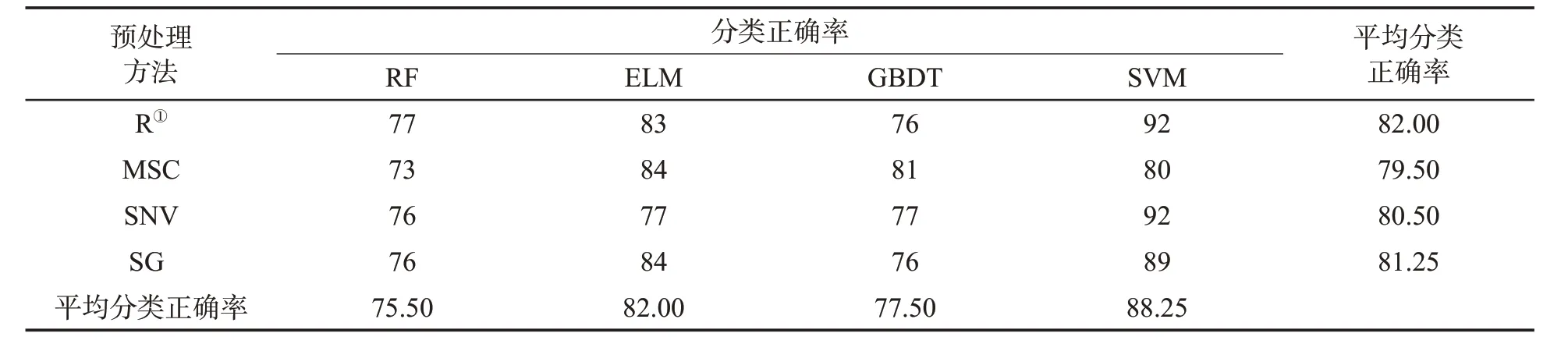
表2 不同预处理方法和分类模型下数据集A的分类正确率Tab.2 Classification accuracy for dataset A with different preprocessing methods and classification models(%)

表3 不同预处理方法和分类模型下数据集B的分类正确率Tab.3 Classification accuracy for dataset B with different preprocessing methods and classification models(%)
2.4 不同特征波段的分类正确率比较
采用光谱全波段建模,信息量大、变量多,且样本的部分光谱信息与样本性质无明显相关性,对样本等级的识别贡献小。因此,利用F-Score算法选取对烟叶分类有较大贡献的特征波段作为分类模型的输入变量。F-Score算法能够在降低高光谱数据维度的同时,保留原有高光谱波段的物理意义,提高模型运行速度[31]。由上述分析结果可知,经MSC预处理后分类正确率相对较高,因此对数据集A和B先进行MSC预处理,再利用F-Score算法选取特征波段。按照全波段F-Score值的大小进行降序排列,选择前10%~90%作为特征波段,然后按照波长大小对特征波段进行排序,结果见表4。
根据表4结果建立RF、ELM、SVM和GBDT分类模型,不同特征波段数量和分类模型下两个数据集的分类正确率见表5和表6。可见,当特征波段数量较少时,4种模型的识别效果均不理想。随着特征波段数量的增加,4种模型的分类正确率均有所提高,其中ELM和SVM模型的分类正确率增加20百分点左右。在数据集B中可能是受到特征波段数量的影响,SVM模型随着维数的增加呈先上升后下降趋势,由于SVM模型能够克服“维数灾难”,最终分类正确率趋于稳定。当特征波段数量达到70%时,4种模型的分类正确率大部分接近全波段。在数据集B中,当特征波段数量达到30%时,SVM模型的分类正确率(97%)已经优于全波段(95%,见表3),说明特征波段的选择有益于SVM模型进行数据分类。综上,当特征波段数量占比为70%时,烟叶分类正确率已接近基于全波段的分类正确率,且可减小数据规模,提升运算速度。
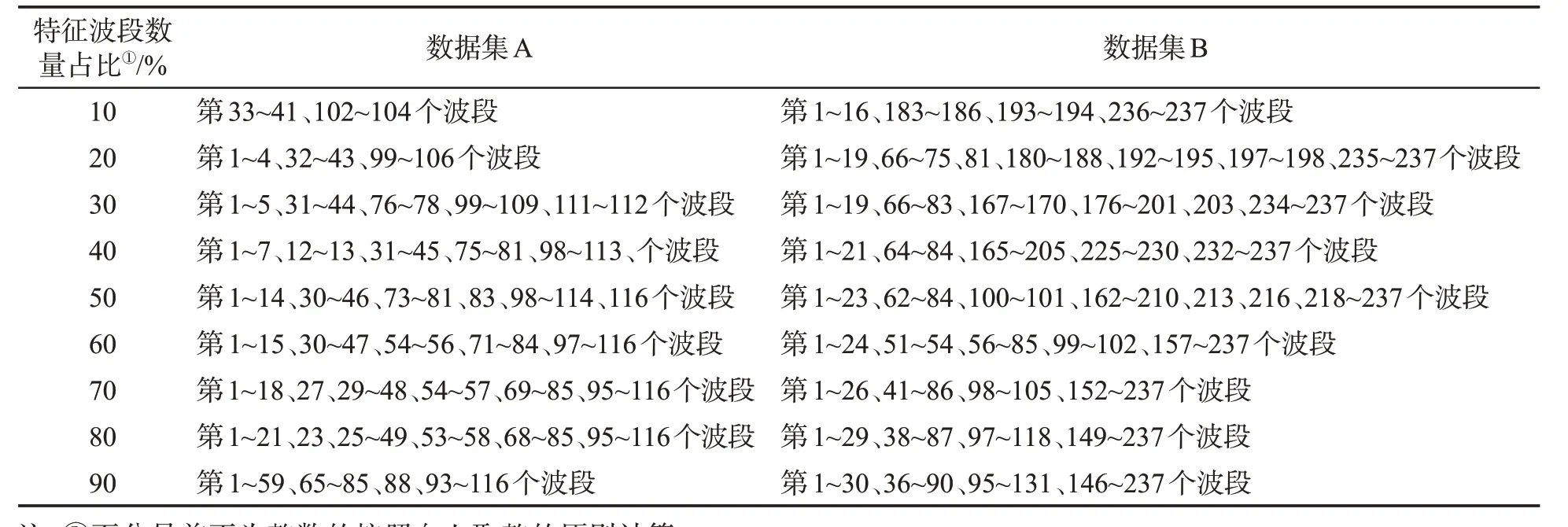
表4 两个数据集中特征波段数量选择结果Tab.4 Numbers of characteristic bands selected by F-Score algorithm based on two datasets
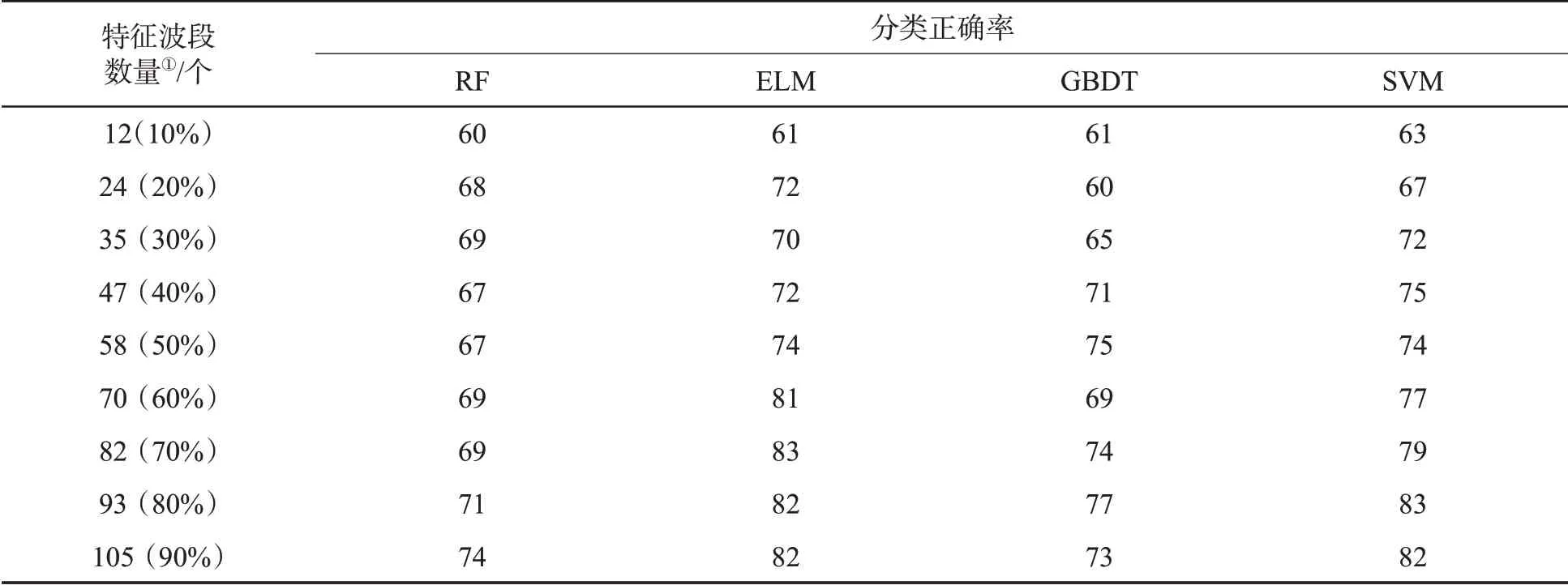
表5 不同特征波段数量和分类模型下数据集A分类正确率Tab.5 Classification accuracy for dataset A in case of different numbers of characteristic bands and different classification models (%)
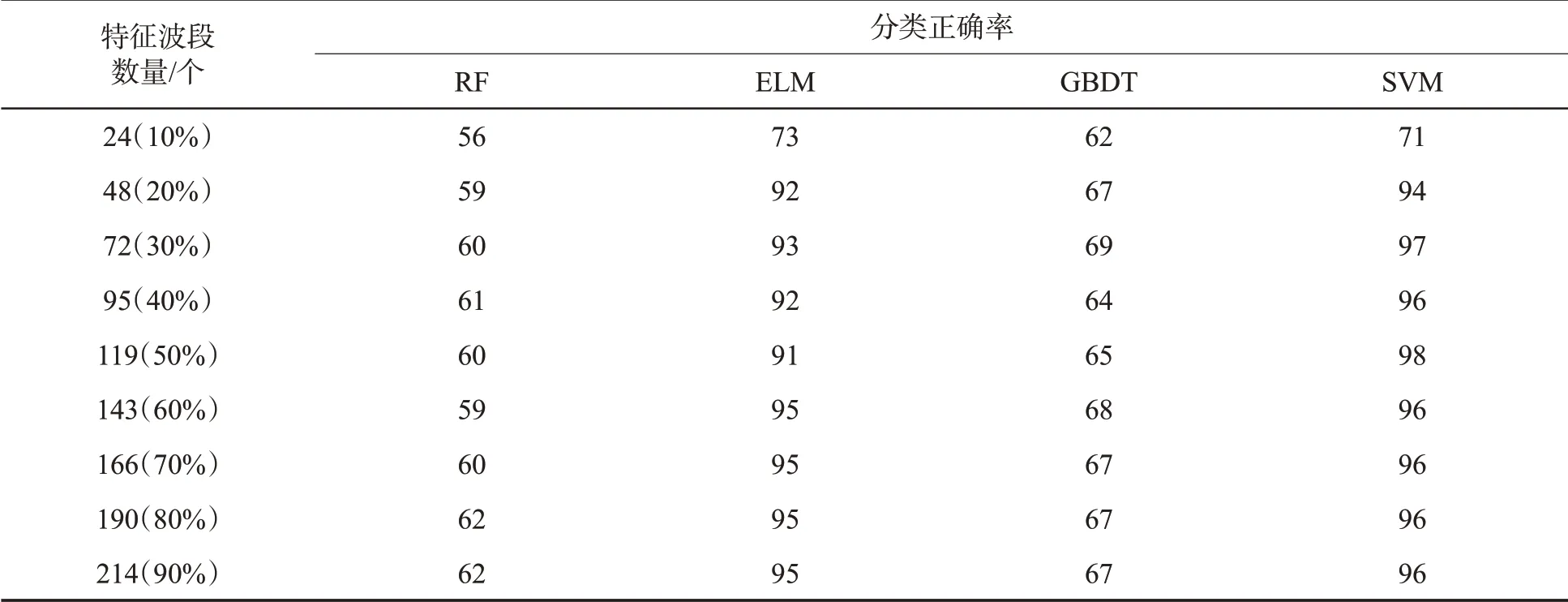
表6 不同特征波段数量和分类模型下数据集B分类正确率Tab.6 Classification accuracy for dataset B in case of different numbers of characteristic bands and different classification models (%)
3 结论
基于烟叶高光谱信息,采用多元散射校正(MSC)等3种预处理方法以及支持向量机(SVM)等4种分类模型,分析了烟叶等级的分类正确率。结果表明:①MSC预处理的分类正确率较高,在数据集A中平均分类正确率仅比SNV、SG低1.00百分点、1.75百分点,但在数据集B中比SNV、SG高18.25百分点、11.75百分点。②在4种模型中,ELM和SVM模型识别效果较优,基于全波段和特征波段的分类正确率均高于其他模型,其中经MSC预处理后基于全波段的分类正确率在数据集A中达到84%和80%,在数据集B中达到96%和95%。③当选择的特征波段数量达到全波段的70%时,4种模型的分类正确率已接近基于全波段的分类正确率,其中SVM模型对数据集B的分类正确率达到96%。研究结果显示利用烟叶的高光谱信息对烟叶进行分级是可行的。
