实时大数据网络流量在云计算技术中识别算法研究
2021-11-02易灿,彭婷
易 灿,彭 婷
(湖南大众传媒职业技术学院,湖南 长沙 410100)
0 引言
目前,用户对网络运维提出更高要求,主要体现在网络流量识别、预测、流量异常的监控等方面。流量识别算法和网络流量模型在网络设计、服务质量、网络管理及监视中起着重要作用。任何情况下的应用程序与管理员都需要实时监视网络运行状况,以保证网络服务质量与网络安全,从而通过使用网络流量应用程序层分类技术来防止网络攻击影响管网。
1 大数据网络流量识别算法研究概述
1.1 网络流量分类简介
网络流量分类技术的关键性作用在于对网络流量的细粒度进行深入分析,能够承载各个通路网络应用所产生的流量,并以此展开网络流量中的网络协议模型,能够准确分析网络用户行为,评估网络安全水平,并以此为依据展开流量控制,是实现三网融合的有效手段。
1.2 网络流量分类技术应用
首先,通过检测端口数据来对网络流量展开分类,这一方法的实效性已经开始逐步减少。结合端口检测技术下的网络流量识别技术与相关管理部门提出的规则,整合出更加完整的通信机制,才能对当前网络流量进行有效识别与分类,即通过端口与应用协议之间的映射机制来实现高校的流量分类。
其次,当基于端口映射技术的网络流量分类起着重要作用时,大规模网络流量分类技术的骨干也起着关键作用。
再次,考虑到应用层协议已经全面覆盖了网络流量信息中的数据。基于此,从理论层面出发,DPI技术在网络协议的识别中具有更高应用价值。DPI技术能够更加深入挖掘特定协议,网络数据包中经常会出现稳定的字符串的独特特征,这些字符又存在大多数带有网络通信协议签名中。
最后,基于网络流量统计特征的识别方法具有创新意义,且已成为当前流量识别与分类的主要手段之一。此类方法的作用机制是将与网络协议不一致的统计特征进行收集,并通过分类算法,对网络流量分类情况仿真模拟训练,以此达成网络流量精准分类的目的[1]。
2 大数据网络流量特征
2.1 自相似性
自相似性能受定向性行为特征的影响,用户定期访问具有稳定的随机访问过程和时间顺序,并且不同用户访问内容具有很强的自相关性,网络流量的运算特征与相似性数学特性相符合。
首先,满足网络流量是平稳的随机过程X=(x(t),t≥0),类似参数H满足X(ct)=cH=X(t),t≥0,c>0,0<H<1。
其次,网络流量运行情况受其自身影响较多,不稳定的网络流量状态是正常的。若处于抽象不确定性构造情况下,随机过程X的平均值为常数A,A=E{X(t)},而网络访问自相关函数符合R(θ)=E{X*(t)X(T+θ)}。
最后,堆叠X以生成一个时间序列,该时间序列表示为X(m)={Xk(m),k≥θ},并且该时间序列能够表示出每单位时间所到达的数量。
2.2 长相关性
对网络力量进行检测时,尽管各个对象之间存在较大的时间间隔,但其依旧具备较强的长相关特性。用户可以结合自身需求对平台进行访问,时间间隔通常为数月、一年或更长时间。以数学形式表达,将选取时间函数用X代表,t和t+k时的值分别为X(t)和X(t+k),则长相关函数表示为:
μ代表平均值,σ代表方差。得出全部相关总和这表明k网络流量中存在长相关性[2]。
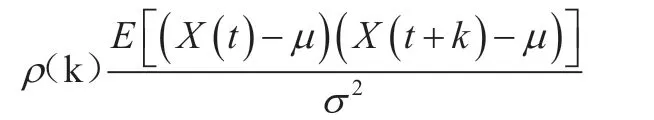
3 属性选择算法
3.1 属性选择过程
针对属性的选择,首先需要结合网络流量数据,整合生成相对应的数据子集,之后对全部子集展开评估与筛选。通过对比分析,查找出最符合要求的子集,并以此判断子集的实际优越性。如果选择的子集为最佳,则停止准则,开始验证;如果选择的子集没有达到最佳值,则将原有子集进行替换,并重新进行子集评估。
3.2 属性选择算法设计
网络平台中关于流量属性的选择,可以通过包装模型的流动特征进行针对性选择,而包装模型需要分类器进行评估函数属性进行区分。这一模型识别准确性较高,但是每次搜索都需要选择一个属性子集进行交叉,存在识别速度慢、灵活性差的缺点。基于此,将ReliefF算法添加至包装模型的计算过程中,并对各个属性展开权重分类,之后结合权重,将属性按照顺序进行排列[3]。当相邻k个样本时,特征权重值是T,循环过程为m次,更新后的权重公式表示为:

4 大数据网络流量监控识别模型
4.1 基于机器学习的网络流量识别
机器学习用于描述网络流量样本集,表示为Y={Y1,Y2,…,Yn},输出类型集表示为X={X1,X2,…,Xn},以F:X→Y表示网络流量分析流程。数据源涵盖整体数据记录,在属性选择算法的基础上,分类整理数据包资源,通过机器学习识别方法,完成特征的统计,之后创建特征列表,完成数据评估与检测。
4.2 K-Means聚类算法应用
K-means聚类算法能够将数据样本之间的相关性展开聚类,并通过聚类明确未知样本。但是,由于K-means聚类算法不具备直接用于判断网络流量的功能,所以,需要将监督学习方法与非监督学习方法引入K-means聚类算法中。
数据集表示为:Sm={(S1,l1),L,(Sm,l2)}∪(Sm+1,Sm+2,L,Sm+n)。
其中,(Sm,lz)是已知类型的数据样本;L={l1,l2,…,lz}代表流量应用程序具体类型;m和n代表样本数;z代表应用程序类型的数量。在K-means算法的基础上,初始中心点选择已知类型标签数据的样本。使用捕获工具进行专业认证以捕获平台网络流量数据,并结合源地址、源端口、目的地址、目的端口以及传输协议属性将流量数据进一步归纳整理,以便于将过滤后的数据进行抽样检查[4]。
5 实验分析
5.1 实验仿真
平台访问实时数据包括浏览页面、上载、下载、交互、网络安全、数据库访问等所产生的流量。划分流量类型并收集相关流量编号,如表1所示。
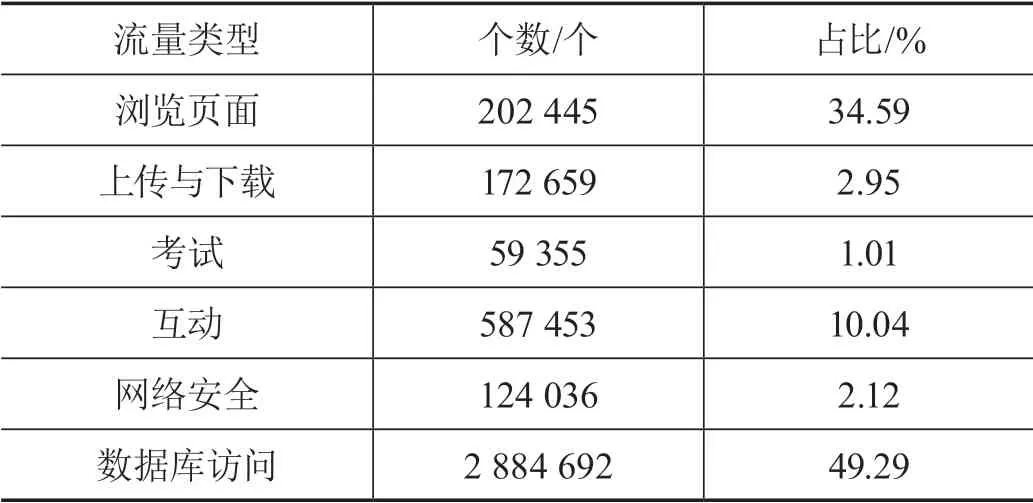
表1 流量类型及其个数与占比
选择IP数据包的容量与TCP窗口大小的负载容量,并将两个数据包的到达时间进行标记,以此作为流量分类特征。之后利用IO构建Map/Reduce并进行相关实验环境界面映射中输入数据,通过在Reduce端选择属性,进行度量,设置流量识别模型,运行时将进行并行计算,合并完成后将数据分为几个数据块计算。
5.2 结果
通过仿真实验得出,创建出的新型模型能够实现对数据流量的精准分类,并能快速完成标记流量的识别与分类,通过聚类算法准确计算出未知标签流,从识别速度出发,通过将样本数量从100 M增加到600 M的实验。实验结果表明:在样本数量逐步递增的情况下,设计模型的识别效率基本保持稳定状态。
6 结语
综上,本文从3个方面研究了职业认证平台的网络流量监控和识别算法。首先,选择平台的网络流量属性以降低二元性,并采用ReliefF算法和打包模型进行度量;其次,结合K-means聚类算法,采用机器学习中的监督学习方法和非监督学习方法,建立交通监控模型;最后,选择专业的认证平台来捕获实时数据包。实验证明该模型识别流量准确有效。
