基于多域对抗学习的无人机目标跟踪算法
2021-11-01张高峰武晓嘉上官宏王安红李晏隆
张高峰,张 雄,武晓嘉,上官宏,王安红,李晏隆
(太原科技大学 电子信息工程学院,山西 太原 030024)
0 引 言
目前,目标跟踪方法[1]根据目标外观模型主要分为生成式模型和判别式模型两大类。生成式模型通过在当前帧对感兴趣目标区域建模,在下一帧搜索与模型最相似的区域来实现跟踪。典型的生成式模型跟踪算法包括光流法、粒子滤波及均值漂移算法等。判别式模型将目标跟踪视为一个背景信息和目标信息的分类问题,通过划分目标和背景信息来实现目标跟踪。典型算法有CT(real-time compressive tracking)、TLD(tracking-learning-detection)等。Nam H等[2]提出的基于多域检测跟踪网络MDNet,通过用不同的视频序列训练网络学习通用的特征表示来进行跟踪,达到了很好的跟踪精度。Jung等[3]提出的RT-MDNet,利用RoIAlign提取目标特征映射,构建高分辨率的特征图来进行跟踪。然而,由于多域检测跟踪网络在特征空间中正样本严重不足,强判别特征导致分类器过拟合,应用于无人机视频跟踪很难保证理想的跟踪效果。针对这些问题,本文在多域检测视频跟踪网络的基础上,融合生成对抗网络和空洞卷积特征抽取设计了一种无人机实时目标跟踪算法,并添加调制因子来平衡正负样本。本文算法能快速鲁棒地跟踪无人机拍摄的跟踪目标。
1 研究背景
近些年来,深度学习发展迅速,研究者开始利用卷积神经网络来进行目标跟踪。采用深度学习的跟踪算法根据网络结构不同大致可以分为3类:相关滤波方法、孪生网络和多域检测跟踪网络。传统的相关滤波方法使用手工特征HOG、灰度、Harris等,而深度学习方法不依赖于人工设计的特征,所提取的深度特征表达更加精确。因此,研究者开始将相关滤波方法中的手工特征替换成深度特征来提高跟踪器的精确度。Ma等[4]提出的HCF是将深度学习引入相关滤波中的典型方法,HCF使用多层的卷积特征来对感兴趣目标进行外观表示,并将多层特征分别通过相关滤波器进行模板学习,最后的目标位置由滤波器置信图加权融合得到。与深度特征相结合的相关滤波方法,利用卷积神经网络提取出了更好的特征,使得跟踪精度得到提升,但速度下降,大多数算法在GPU加速下也难以达到实时。Bertinetto等[5]提出的Siam-FC首先引入孪生网络进行目标跟踪,Siam-FC在精度上面表现良好,跟踪速度达到实时。Bo Li等[6]在Siam-FC的基础上加入了区域候选网络(RPN),通过RPN进一步回归目标框的位置,提升了Siam-FC的精度。基于孪生网络的跟踪算法仅将目标模板与搜索区域进行相关操作,网络不涉及模板的更新,所以跟踪器在遇到相似背景干扰和遮挡场景中跟踪效果较差。多域检测跟踪网络提取各种视频域目标存在的共同属性来提高跟踪器的泛化能力,例如光照改变、尺度变化等属性。MDNet将多域学习的方法应用到目标跟踪中,通过在任意视频域中训练CNN网络来区分目标和背景,提高了网络泛化能力,有效地提升了视频跟踪网络应对复杂场景跟踪的能力,且达到了很高的跟踪精度,取得了VOT2015竞赛的第一名。Jung等提出的RT-MDNet是一种基于MDNet的实时目标跟踪算法,利用RoIAlign提取目标特征映射,构建了高分辨率的特征图,降低了计算复杂度,提高了实时性。
2 本文方法
2.1 网络结构
本文在多域检测跟踪网络基础上,引入了生成对抗学习的思想,来增加正样本的多样性,使之适应无人机视频跟踪中目标姿态变化和环境参数变化,提高网络的泛化能力。
本文的网络结构由特征提取、对抗特征生成器和二元判别器3部分组成,如图1所示。特征提取由三层卷积网络构成,并使用空洞卷积来提升网络的多尺度特征抽取能力。对抗特征生成器包含两个全连接层,输出为权重掩膜,每种掩膜代表目标的一种外观变化,丰富了目标特征在样本空间的多样性。二元判别器输出K个支路,每个支路对应一个独立的视频域,用来区分在特定域上的目标和背景,满足多域学习在结构上的需要。以上3部分的详细介绍如下。
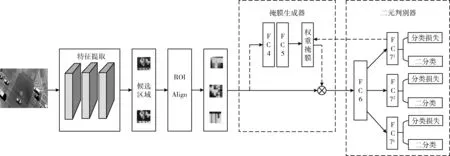
图1 本文网络结构
2.1.1 特征提取
特征提取模块由卷积层conv1-3组成,用于构建共享特征映射,通过将VGG网络预先在大型数据库Imagenet上训练,然后将预训练模型迁移到多域检测跟踪网路上,构造特征提取模块。这种方法减少了对大规模训练数据的依赖,降低了训练数据集不足对跟踪性能的影响。卷积层连接RoIAlign层。使用RoIAlign从共享特征映射中提取与每个RoI对应的CNN特征。通过这种特征计算策略,在提高特征质量的同时,显著降低了计算复杂度。
在特征提取中使用全卷积神经网络VGG结构,在卷积层中加入具有不同扩展系数的空洞卷积进行多尺度特征抽取,构建具有更高预测精度的特征提取模块。空洞卷积具有在不损失池化信息的情况下扩展感受野的优点,可以更好地抽取图像中的全局信息或长序列信息。无人机目标尺度变化较大,使用空洞卷积抽取的特征能更好地捕捉目标信息,能够提高目标特征表达的有效性。
2.1.2 对抗特征生成器
为了得到更鲁棒的跟踪器模型,本文将对抗性学习应用到多域检测跟踪框架中,在特征提取和分类器之间增加了一个生成对抗网络。网络输入为目标特征,输出为特征的权重掩膜。每一种权重掩膜对应于目标的一种外观变化,权重掩膜与目标特征相乘后得到一种新的目标特征表达,丰富了特征空间的正样本。通过对抗学习,训练得到的掩膜可以对单帧中判别力强的特征进行削弱,有利于生成鲁棒性更强的全局目标特征,防止分类器过拟合于某个样本。
生成对抗网络的目标函数定义如下
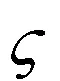
(1)
其中,D代表二元判别器,G代表生成器,C代表输入特征,G(C)为生成器生成的掩膜。网络训练时每次迭代,生成器G生成预测掩膜G(C),预测掩膜与特征C进行点乘操作后得到新特征,新特征输入到二元判别器D中,D输出分类损失,选出损失值最大的特征所对应的掩膜,该掩膜能够有效降低强判别力特征的影响,增加二元判别器的鲁棒性,将这个掩膜作为式(1)中的M。
2.1.3 二元判别器
定义y∈{0,1}作为分类标签,p∈[0,1]作为y=1标签的估计概率,则y=0的估计概率为1-p。二元分类的交叉熵CE损失函数可以表示为
L(p,y)=-(y·log(p)+(1-y)·log(1-p))
(2)
在无人机目标跟踪中,在背景中存在大量的简单负样本,只有较少的正样本。在反向传播中,简单负样本占据了梯度的主要部分,主导了梯度的传播,这种正负样本数量不平衡的问题,不利于网络的训练。
本文在CE损失中添加了一个调制因子,并将该调制因子设定为网络输出概率p,建立了如下新的损失函数
L(p,y)=-(y·(1-p)·log(p)+(1-y)·p·log(1-p))
(3)
并根据修改的CE损失,构建了新的目标函数
(4)
其中,K1=1-D(M·C),K2=1-D(G(C)·C)是平衡训练样本损失的调节因子。
2.2 跟踪和网络更新
跟踪过程分为两个阶段,首帧初始化训练和模型在线更新。在初始化训练中,使用随机梯度下降法迭代100次来更新生成器G和判别器D的网络参数。模型在线更新采用了长短期更新机制,长期更新每隔10帧对G和D网络参数进行10次迭代更新,当检测到跟踪目标得分低于设定阈值时短期更新会被随时触发,这两种更新的执行取决于目标外观变化的速度。
网络的输出代表输入帧中目标和背景的得分值,跟踪目标由得分最高的目标框确定,公式表达如下
(5)
其中,xi表示采样的目标候选框,f+(xi)表示候选框的正分数,x*表示最优目标框。
3 实验结果
本文算法采用Pytorch框架,并在Intel i7处理器的计算机配置平台上测试算法性能,同时利用GTX1070型号的GPU对算法进行加速。在网络训练阶段,网络迭代次数设置为1000,学习率为0.0001。测试阶段,在每个测试视频的第一帧对网络进行微调,绘制500个正样本和5000个负样本。在线更新时,网络的迭代次数为10,学习率定为0.0003,权重衰减因子和动量因子分别固定在0.0005和0.9,在线更新的训练数据在每个帧中完成跟踪后收集,当iou>0.5,收集50个正样本,iou<0.3时收集200个负样本。采用公开数据集对本文算法进行测试,下面分别从定性和定量角度对算法性能进行分析。
3.1 OTB100定量分析
OTB100(online object tracking benchmark)公开测试数据集,其中包含100个在不同跟踪场景下获取的视频,在每个视频的每一帧图像中,标注了目标的位置注明了目标属性,各属性分别为:尺度变化(scale variation,SV)、光照变化(illumination variation,IV)、目标遮挡(OCClusion,OCC)、背景杂波(background clutters,BC)、目标形变(DEFormation,DEF)、运动模糊(motion blur,MB)、快速运动(Fast Motion,FM)、平面内旋转(in-plane rotation,IPR)、平面外旋转(out-of-plane rotation,OPR)、目标超出视野(out-of-view,OV)及低分辨率(low resolution,LR)[7]。将本文算法与对比算法在OTB100数据集上测试,对比算法包括:RT-MDNet、FCT、CT、DSST[8]、STRUCK、KMS。图2显示了在OTB100数据集测试后不同算法的跟踪精度曲线和跟踪成功率曲线。从图中可以看出,本文算法在跟踪精度和跟踪成功率这两方面都取得了良好的表现。在跟踪速度方面,本文算法是一种实时目标跟踪算法,跟踪速度达到20 FPS。这一特点也使得本文算法更适用于实际应用,在无人机跟踪过程中,在保证实时跟踪速度的同时,有较高的精度和成功率。与目前较流行的另外一种基于深度学习的实时跟踪算法RT-MDNet相比,本文算法在精度上提升了2.2%,在成功率上提升了1.4%。
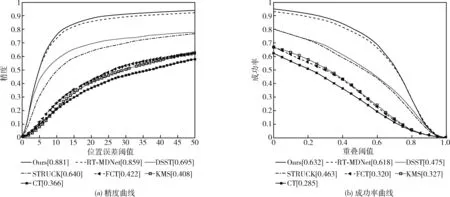
图2 OTB100测试结果的精度曲线和成功率曲线
算法在OTB100数据集各属性分析结果见表1和表2。可以看出,本文算法在11种属性上均取得了较好的跟踪结果。本文算法在保证实时性的同时取得了更高的成功率。与实时跟踪算法RT-MDNet相比,本文算法在各属性上都有着不同程度的性能提升,验证了本文算法采用生成对抗学习策略的有效性。
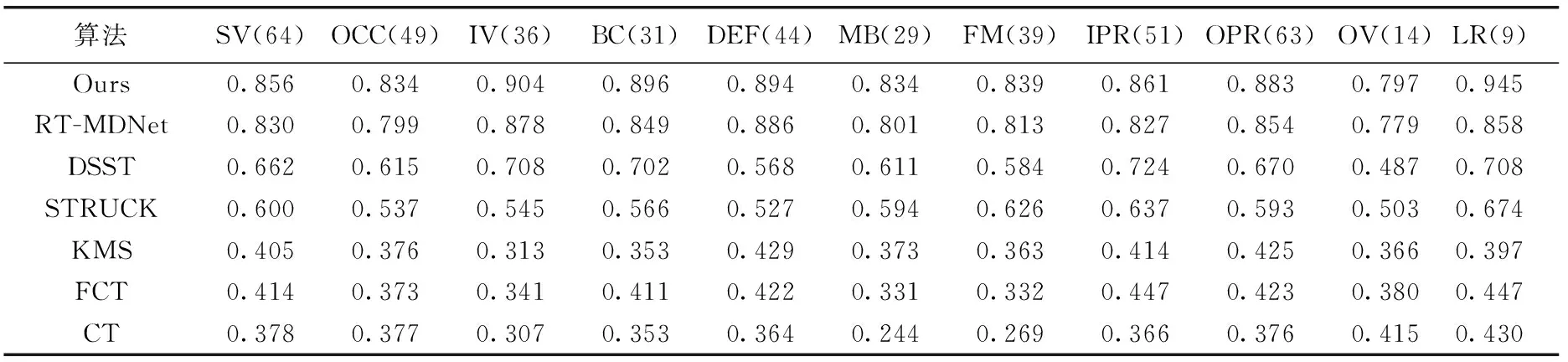
表1 各属性下算法的跟踪精度对比结果
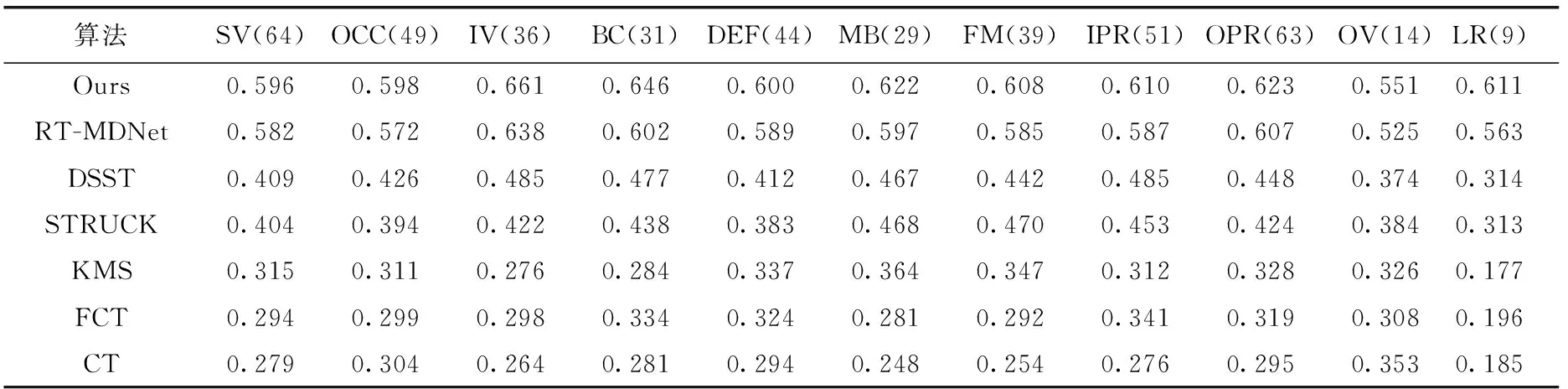
表2 各属性下算法的跟踪成功率对比结果
3.2 UAVDT定量分析
此外,由于无人机的角度和高度不一致,目标角度和比例是可变的,视频所面临的跟踪挑战也非常困难。为了验证算法应用于无人机车辆视频的有效性,本文也选取公开的无人机UAVDT数据集[9]对算法性能进行了测试,UAVDT包含50个在不同跟踪场景下无人机拍摄的车辆视频,在每个视频的每一帧图像中,目标的位置都标注了坐标,并且每个视频都注明了属性。属性表示每个视频所面临的跟踪挑战,该数据集共有9种属性,分别为:BC、SV、IV、相机运动(camera motion,CM)、大面积遮挡(large occlusion,LO)、长时跟踪(long-term tracking,LTT)、目标模糊(object blur,OB)、目标移动(object motion,OM)、小目标(small object,SO)。将本文算法与对比算法在UAVDT数据集上测试,对比算法包含RT-MDNet、CT、FCT、Staple_CA[10]、MCPF[11]、KCF。
图3显示了在UAVDT数据集测试后不同算法的跟踪精度和跟踪成功率曲线。从图中可以看出,在跟踪难度更大的UAVDT无人机数据集上,本文算法表现良好。
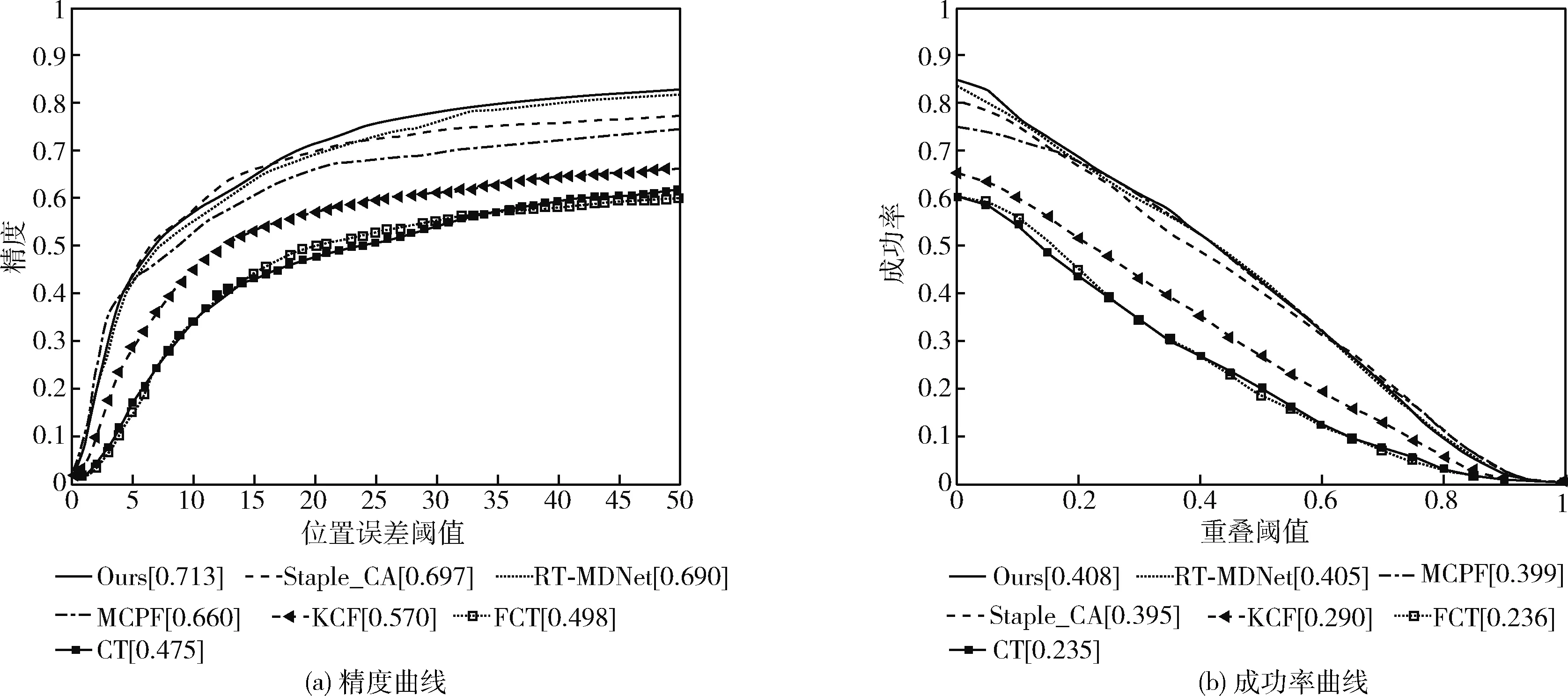
图3 UAVDT测试结果的精度曲线和成功率曲线
算法在UAVDT数据集各属性分析结果见表3和表4。从表中可以看出,本文算法在所有属性中均取得了优良的效果。与RT-MDNet相比,本文算法在6个属性方面都表现出更高的跟踪性能。
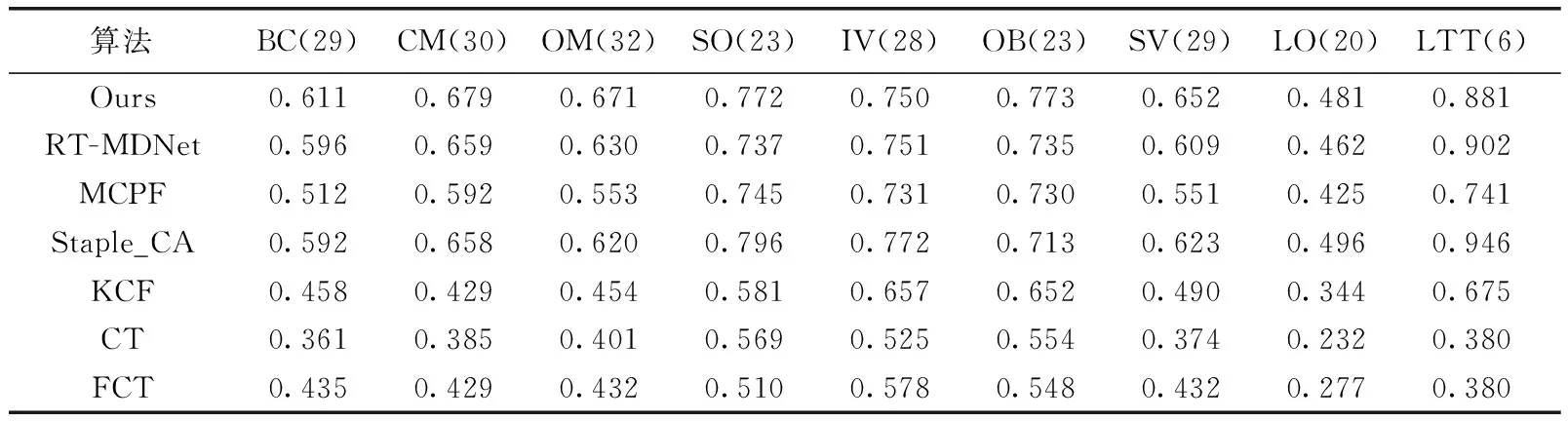
表3 各属性算法的跟踪精度对比结果
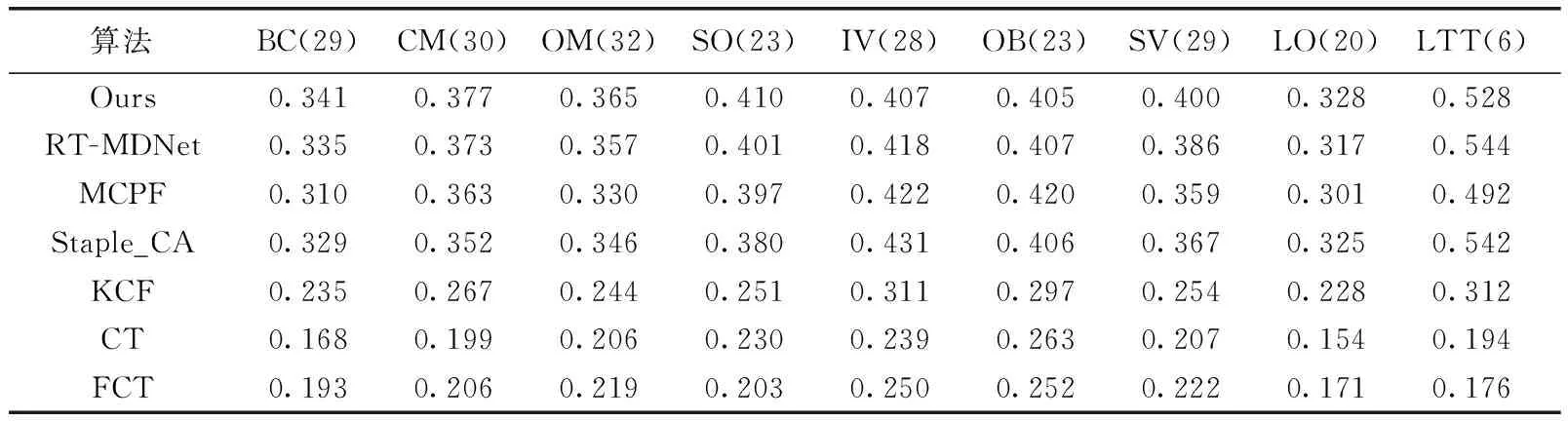
表4 各属性算法的跟踪成功率对比结果
3.3 定性分析
3.3.1 跟踪速度
评价跟踪算法的整体性能,不仅要考虑跟踪精确度和跟踪成功率,还需要考虑跟踪速度,跟踪速度直接关系跟踪算法在实际生活中的应用。本文选取了6种具有代表性的测试序列进行跟踪速度评测,将测试序列在相同参数下运行5次,取每秒内的平均跟踪帧数(fps)作为算法在测试序列下的跟踪速度。表5为本文算法与RT-MDNet、CT与FCT算法在不同测试序列下的跟踪速度。从表中可以看出,本文跟踪算法的跟踪速度在20 fps左右,与其它3种算法的跟踪速度相近。
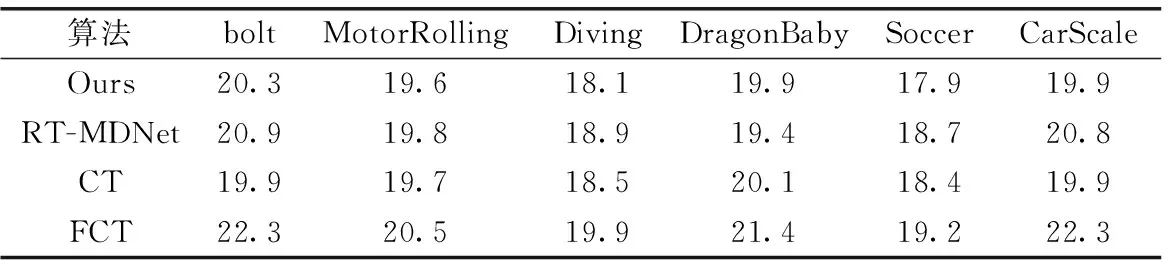
表5 不同测试序列下的跟踪速度
3.3.2 OTB视觉效果分析
不同算法在OTB视频序列上的跟踪结果如图4所示。

图4 OTB视频定性分析
(1)快速运动:以“MotorRolling”视频为例,跟踪目标为竞赛比赛中的摩托车,跟踪目标在运动过程快速运动和快速翻转,给跟踪算法带来挑战。在“MotorRolling”视频中,摩托车在88帧时,在对比算法中,FCT、CT这两种跟踪算法已经出现了跟丢目标的情况,RT-MDNet算法出现漂移现象,而本文算法仍能精确鲁棒的跟踪到目标,在视频106帧后,除本文算法外,其余对比算法均出现不同程度的跟踪漂移问题。
(2)尺度变化、目标旋转:以视频“DragonBaby”为例,跟踪目标为打闹的孩童。在孩童转身的过程中,跟踪目标出现较大程度的旋转和尺度变化问题,加大算法跟踪困难。在“DragonBaby”视频的第26帧,CT算法已跟丢目标,在视频81帧,CT、FCT和RT-MDNet算法开始出现漂移问题,在104帧后,其余算法都已跟踪失败,只有本文算法能准确跟踪目标,跟踪效果达到最优。
(3)目标遮挡、背景杂乱:以视频“Soccer”为例,跟踪目视频背景信息杂乱,跟踪目标在跟踪过程中出现不同程度的遮挡现象。在“Soccer”视频的第66帧,本文算法与对比算法都能跟踪到目标,在视频的141帧,CT、FCT和RT-MDNet算法受到背景干扰,开始出现跟踪目标的问题,只有本文算法表现良好,在视频的283帧以后,除本文算法外,其余算法均全部跟丢目标,本文算法能够准确跟踪到目标。
3.3.3 UAVDT视觉效果分析
不同算法在UAVDT视频序列上的跟踪结果如图5所示。

图5 UAVDT视频定性分析
(1)相机运动:以视频“S0101”为例。由于无人机飞行姿态的变化,相机发生运动,使得所拍摄的视频目标外观产生改变,给跟踪带来挑战。在“S0101”视频的第156帧,跟踪目标为小型货车,CT与FCT算法虽然能跟踪到目标,但跟踪框内包含了大量背景信息,本文算法与RT-MDNet算法的跟踪效果较好,但本文算法的跟踪框更为精确。在视频的第156帧,CT、FCT算法的跟踪框过大,在视频的第262帧,受到相机运动的影响,目标跟踪难点加大,CT与FCT算法已经跟丢目标,RT-MDNet出现漂移现象,而本文算法仍能准确跟踪到目标。
(2)目标遮挡:以视频“S0310”为例。跟踪目标被树木大面积遮挡,给跟踪带来困难。在“S0310”视频的第37帧,本文算法与对比算法都能够跟踪到目标,在视频第65帧中,跟踪目标被路边遮挡物栏杆遮挡,CT、FCT和RT-MDNet算法都出现不同程度地漂移,而本文算法表现良好,在视频的105帧,除本文算法外,其余3种算法均跟丢目标,本文算法表现良好。
(3)目标模糊:以“S1101”视频为例。跟踪目标为马路上的车辆,由于相机拍摄角度问题,跟踪目标会出现模糊现象。在视频“S1101”的第164帧,CT算法开始跟丢目标,FCT算法跟踪框过大,RT-MDNet算法出现漂移,本文算法表现良好,在视频的第203帧,目标出现更大程度模糊,本文算法仍能准确跟踪到目标,在视频的236帧,本文算法与对比算法相比,跟踪效果表现最优。
4 结束语
本文提出了一种基于多域对抗学习的实时无人机目标跟踪算法,采用了生成对抗思想来生成鲁棒性更高的全局特征,克服了强判别特征引起的过拟合问题,利用空洞卷积扩大了特征感受野,并在损失函数中添加了调节因子来缓解正负样本数量不平衡的问题。在测试过程中,采用了OTB100数据集中的100个视频序列(针对面临的11种跟踪挑战)和UAVDT数据集中的50个视频序列(针对9种具有挑战性的跟踪场景),对本文算法进行定量分析和定性分析,实验结果表明,本文算法的跟踪精度和跟踪成功率均有提高,而且对于光照改变、背景遮挡、目标旋转等跟踪场景下具有更高的鲁棒性。本文所提出的算法还有进一步优化和提升的空间,如在特征提取时加入不同的注意力机制,改进模板更新策略等,从而可以在不影响实时性的情况下进一步提升跟踪成功率和精度。
