情感极性和影响函数的OBTM弹幕主题演化
2021-11-01黄竹韵张梦甜贾耀清
吴 迪,黄竹韵,生 龙,张梦甜,贾耀清
(1.河北工程大学 信息与电气工程学院,河北 邯郸 056038; 2.河北工程大学 河北省安防信息感知与处理重点实验室,河北 邯郸 056038)
0 引 言
目前,弹幕文本分析主要集中在情感分类[2]和情感演化[3]两个方面,一般采用主题模型[4]或者改进词向量模型[5]方法,但是准确率有待提高。因此,孟仕林等[6]提出了融合情感词典和词向量方法。然而,弹幕词语大多未收录在情感词典中,需要进一步提高词向量方法对未收录词的情感分析能力。
短文本流特征稀疏问题影响了演化效果,解决方法有:基于文本标签[7]或融合词向量[8]的主题模型方法,以及双词共现建模[9]方法。Shi L等[10]提出了SADTM动态模型,进一步优化了文本流的主题演化效果。但是,SADTM只考虑了相邻时间片的主题分布的关系,实际上,前n个时间片的主题对第n+1个时间片都有不同程度的影响。
因此,针对情感极性信息提取和衰减因子设定单一的问题,提出情感极性和影响函数的OBTM弹幕主题演化方法(emotion polarity and influence function based OBTM,EI-oBTM)。通过结合情感词典和改进负采样的word2vec算法,有效地标注情感极性;构建影响函数,以优化历史文本在下个时间片上的演化效果;利用情感极性信息和影响函数改进OBTM建模过程,以优化弹幕主题演化效果,同时获得主题情感极性的演化结果。
1 问题定义
为了获得弹幕文本情感极性演化结果,设计了基于word2vec的情感极性标注方法。Word2vec中采用负采样方法,减少梯度更新工作量。负采样的基本思路:对每个词都进行一次词频统计,将词频映射到长度为1的区间上,生成随机数,对随机数所在区间的词语进行采样。经典负采样方法获得高频词的概率大,而需要进行情感极性标注的词语不属于高频词,因此,提出了融合TF-IDF和一元分布[11]的负采样。
定义1 假设vi是需要情感极性标注的词语,wj是已知情感极性的词语,wf用于记录词频累加和,tfidf(vi) 表示vi的词频—逆文档频率,U(wj) 表示wj的一元分布概率,则融合TF-IDF和一元分布的负采样如式(1)所示
wf=0.5*tfidf(vi)+0.5*U(wj)(i≠j)
(1)
式中:wj可通过查找弹幕词集和情感极性词典中共有的词语得到,为了保证wf累加和为1,tfidf(vi) 和U(wj) 同乘0.5。
在OBTM模型中,弹幕文本的历史影响性由衰减因子来传递,而且衰减因子为定值。然而,历史影响的程度实际上是不断变化的,应当充分考虑前n个时间片的主题对当前时间片的历史影响,因此,提出了影响函数,以更准确传递弹幕文本的历史影响。
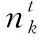
(2)
(3)
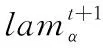
(4)
(5)
2 情感极性和影响函数的OBTM弹幕主题演化方法
针对OBTM缺少情感极性信息和忽略历史影响性的问题,提出了EI-oBTM方法。首先,融合TF-IDF和一元分布改进word2vec负采样过程,对弹幕词语进行情感极性标注,得到情感极性特征向量;然后,人工删除弹幕重复片段,划分OBTM时间片,构造影响函数;最后,利用情感极性特征向量和影响函数改进OBTM得到EI-oBTM。过程如图1所示。
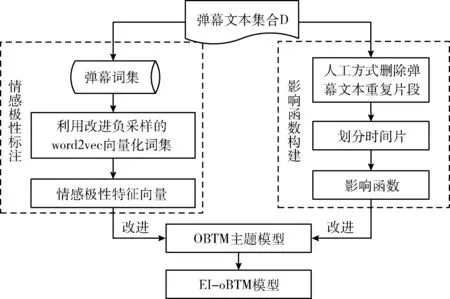
图1 EI-oBTM方法流程
2.1 情感极性标注
弹幕词语中的网络新词一般隐含用户的情感或观点但不包含在NTUSD中,为了保留这些弹幕词语,提出基于改进负采样的word2vec的情感极性标注算法,如图2所示。

图2 基于改进负采样的word2vec情感极性标注流程
该算法首先将通过NTUSD标注的已知情感极性的词语Exw作为“参照词”,然后利用改进负采样的word2vec算法对wordset进行向量化,记作Vecw,计算Vecw与Exw的相似度SW, 若SW∈(δ,μ), 则Vecw和Exw情感极性一致并标注。另一方面,考虑到反义词在相似语境中的相似度很高,若SW>μ, 则人工判断情感极性;若SW<δ, 则Vecw和Exw情感极性不一致并且不标注。其中,融合TF-IDF和一元分布的负采样算法如下。
算法1: 融合TF-IDF和一元分布的负采样算法
输入:情感词Exw; 词表wordset; 词频tf-idf
输出:负采样词频数组wf[wordset]
(1)初始化词频数组wf, i=0;
(2)wf←计算wordset [0]的一元分布频率;
(3)if wordset [i] in Exw
(4) 计算wordset [i]的一元分布频率, 累加到wf; i++;
(5)else
(6) 读取wordset [i]的tfidf值, 累加到wf; i++;
(7)end if
(8)输出负采样词频数组wf[wordset]
2.2 影响函数构建
影响函数需要利用OBTM时间片之间的文本相似性来构建。但是,弹幕中存在跟风发文的现象,用户跟风发送弹幕内容几乎无变化并且不具有代表性,这会加剧相似度计算的偏差。因此,需要删除弹幕文本重复的片段,使相邻时间片中的文本内容更连贯。
影响函数构建如图3所示,首先,通过人工删除D中的重复片段得到D*;然后,将D*按照时间顺序平均分为m个片段;最后,依次计算每两个时间片的相似度S,并且根据定义2,将S用于构建影响函数。
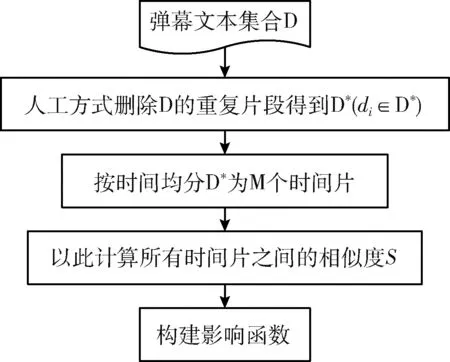
图3 影响函数构建流程
2.3 情感极性和影响函数的OBTM模型构建
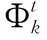
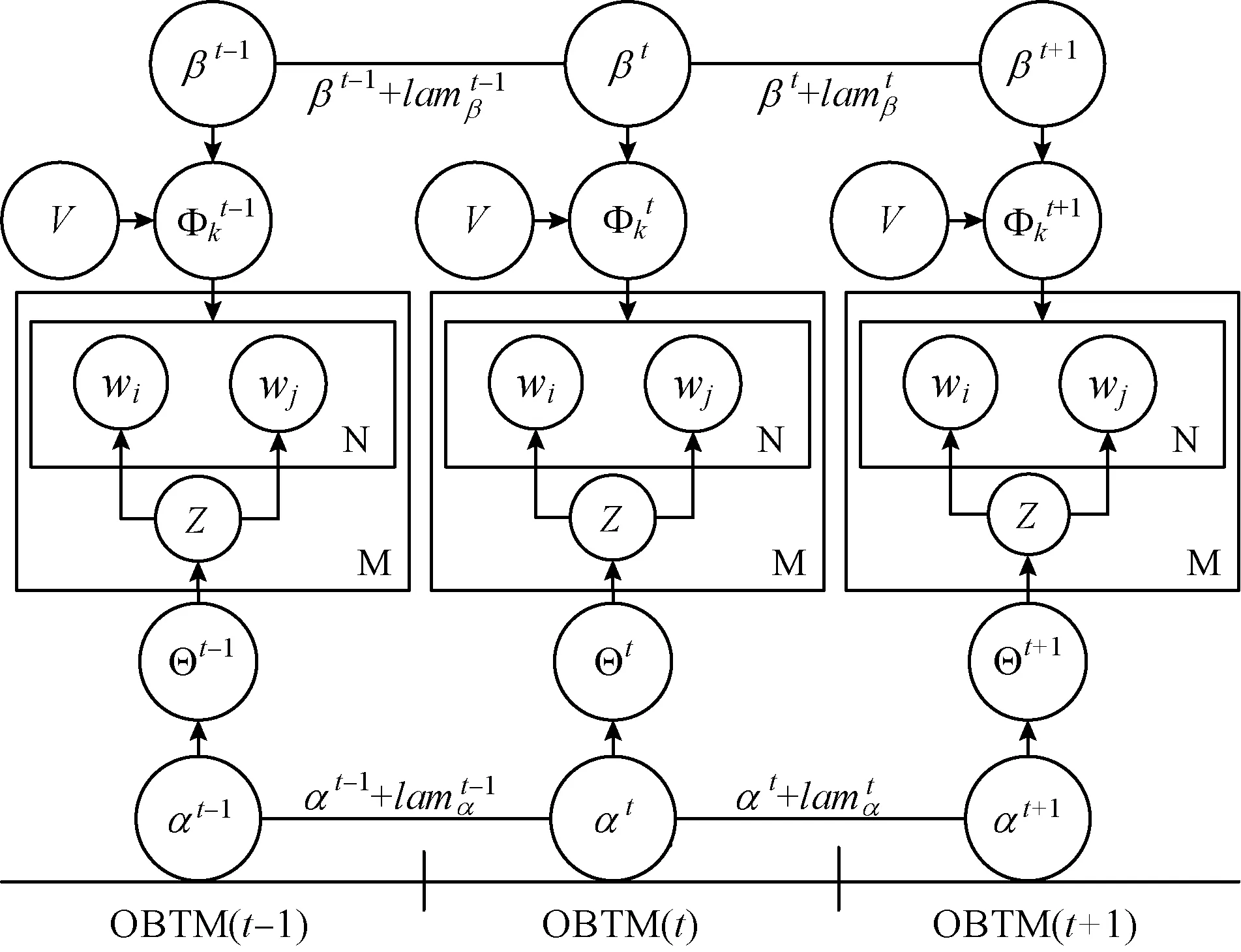
图4 基于情感极性和影响函数的OBTM模型
算法2: 基于影响函数的OBTM算法 (核心部分)
输入:时间片day=2; 文本相似度St; 超参数αt=50/k,βt=0.005
(2)for (d=0;d<3;d++)
(4) 根据式(4)和式(5)更新αt+1和βt+1;
(5)end for
3 实验结果与分析
3.1 实验数据集
本文采用了BiliBili视频弹幕数据集进行实验。通过python爬取视频号为BV1Kt411U7Hz的视频下所有弹幕文本(网站:https://www.bilibili.com/),经过预处理后,获得时间和分词后的文本,保存为danmu.txt,结果见表1,弹幕数据集参数描述见表2。

表1 弹幕文本示例

表2 数据集参数描述
3.2 实验环境与评价指标
实验利用Visual Studio Code 1.39.2(配置:Python3.7、c/c++)软件进行编译;计算机RAM为8.0 G,
CPU为Intel(R) Core(TM) i5-8265U@1.60 GHz;程序在Ubuntu 16.04系统下测试。
本文采用F-score、主题一致性(coherence)[12]以及(JS)散度[13]3个评价指标对所提出的方法进行评价。首先,定量分析改进负采样后的word2vec情感极性标注算法的效果,利用F-score指标对改进前后的word2vec算法的标注结果进行对比;然后,采用coherence指标对主题模型进行评价,并根据评价结果获得最优主题数k;最后,利用JS散度指标分析EI-oBTM在主题演化方面的效果。
F-score是精确率(Precision)和召回率(Recall)的调和均值,如式(6)所示。P=正确标注的词语数/弹幕词语总数;R=正确标注的词语数/经过标注的词语总数
(6)
指标coherence包括内在度量(umass)和外在度量(UCI)两个衡量标准,如式(7)所示,umass表示主题词和文本中前后相邻单词的紧密度,如式(8)所示;UCI表示主题词和同主题下其它词语的相关性,如式(9)所示
coherence=umass+UCI
(7)
(8)
(9)
其中,D(vi,vj) 表示包含vi,vj单词对的文本数量,D(vj) 表示包含vj的文本数量,ε是平滑因子。p(wi,wj) 表示某滑动窗口中同时出现的词对 (wi,wj) 的联合概率分布;p(wi) 是词语wi在边缘概率分布范围内出现在滑动窗口的边缘概率。
相比Kullback-Leibler(KL)散度,JS散度满足对称性,可以用于衡量两种概率分布之间的差异。因此,选择JS散度进行主题演化效果的评价,如式(10)所示
(10)
式中:P和Q代表相邻两个时间片中得到的主题-词分布Φ, JS(P‖Q) 代表P和Q两个概率分布的相似度,DKL代表KL散度的结果,DKL如式(11)所示,其中,pj和qj代表分布P和Q中的第j个概率值
(11)
3.3 结果分析
3.3.1 情感极性标注结果分析
本文方法改进了word2vec算法中的负采样过程,以实现弹幕词语的情感极性标注,改进效果见表3。
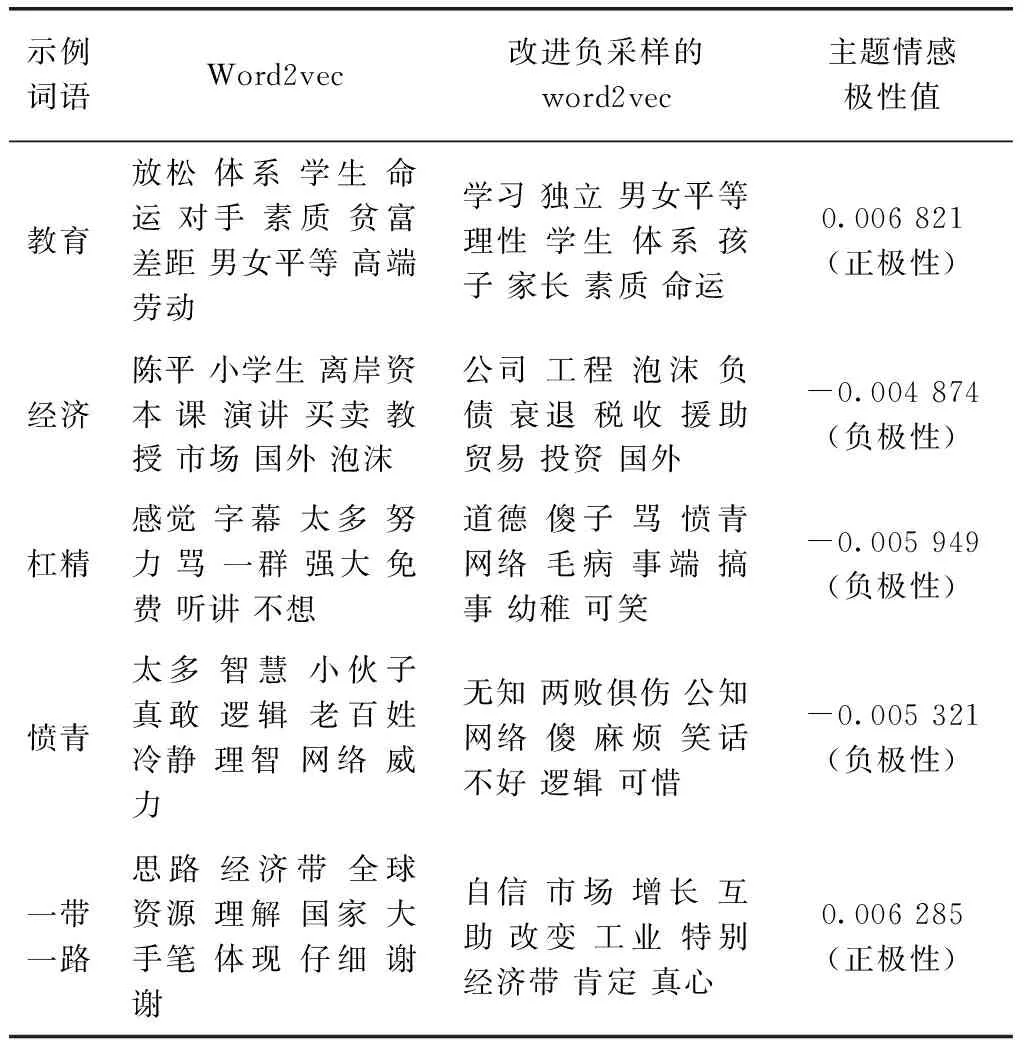
表3 word2vec负采样改进效果示例
表3以“教育”、“经济”、“杠精”、“愤青”和“一带一路”为例子,列举了相关度排名前10的关联词,通过关联词分析获得原词的情感极性。其中,“教育”和“经济”属于常用名词,其作为话题带有一定情感极性,例如,“经济”在本文涉及的弹幕文本中表现为负极性;“杠精”和“愤青”属于网络新词,本身具有情感色彩;“一带一路”属于时政热词,其带有的情感极性隐含民众态度。利用经典word2vec算法得到的关联词,多是与示例词语上下文联系紧密的词语,在NTUSD词典中仍然匹配不到,因此,无法通过关联词分析得到示例词语的情感极性。在改进word2vec负采样过程后,关联词语中出现了“独立”、“衰退”、“无知”、“增长”等已知情感极性的词语,通过这些词的情感极性,可以判断示例词语的情感极性,进而得到主题情感极性值。
利用F-score评价情感极性标注的准确率,如图5所示,改进负采样的word2vec算法与经典word2vec算法相比,F-score较高,说明改进后的word2vec情感极性标注算法的准确率较高。
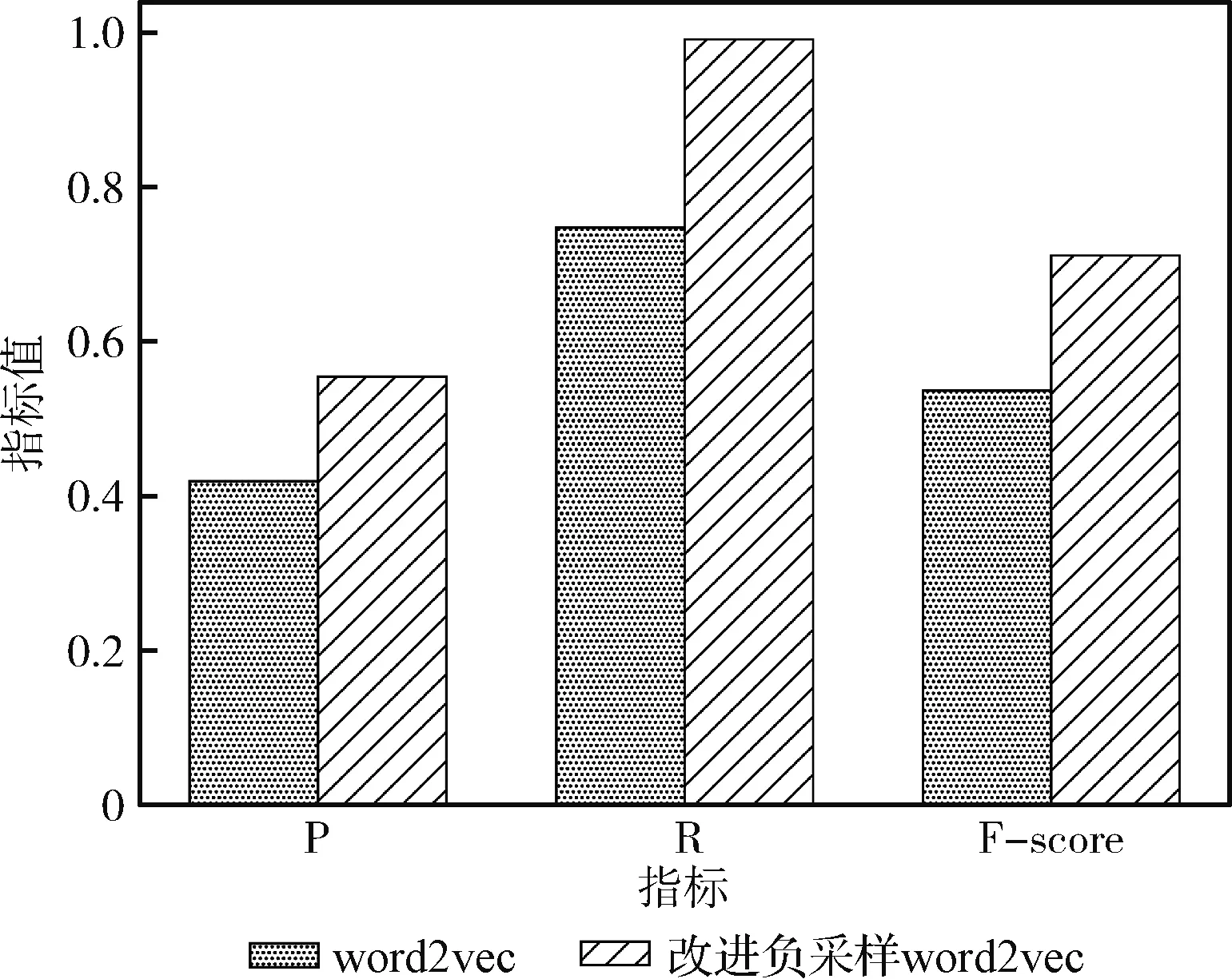
图5 情感极性标注P、R和F-socre值对比
3.3.2 最优主题数选取及主题演化结果分析
通过实验可知,当超参数α=50/k、β=0.005, 模型迭代次数iter为1000,时间片day为6时,模型效果最好,因此,本文实验均在α=50/k、β=0.005、iter=1000和day=6的情况下进行,主题数k为实验变量,k取值为5,6,7,8,9,10,11,12,13,14。
图6和图7分别展示了弹幕文本umass、UCI指标的结果和不同模型下弹幕文本的coherence值。如图7所示,EI-oBTM在k=13时coherence值最高;另外4种模型在k=12时coherence值最高。EI-oBTM、SADTM和OBTM趋势相接近,DTM和OLDA趋势相接近,EI-oBTM、SADTM和OBTM的主题一致性总体上高于DTM和OLDA,SADTM模型的效果优于OBTM和其原模型DTM。
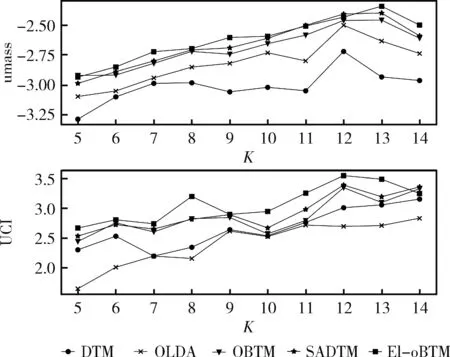
图6 不同k值对应的umass、UCI值对比
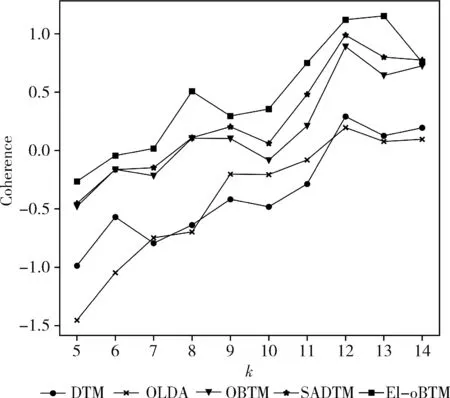
图7 不同k值对应的coherence值对比
分析得到以上结果的可能原因如下:DTM和OLDA均为LDA的动态模型,较适用于长文本,而本文数据集是视频弹幕短文本;SADTM、OBTM和EI-oBTM均采用双词共现的方法,以解决短文本的稀疏性,较适用于短文本;SADTM在时间片内自耦合,等同于扩展了文本长度,并利用了双词共现进行词频统计,从两方面解决了短文本稀疏性。
根据coherence指标对EI-oBTM的评价可知,主题数k的最佳取值为13。因此,在k=13时,根据式(10)计算JS散度,以展示弹幕文本主题演化效果。
如图8所示,坐标点代表了时间片day(n)和day(n+1)之间的JS散度,JS散度越高表示时间片之间的相似度越高。相比DTM、OLDA、OBTM和SADTM、EI-oBTM的JS散度值最高,并且折线走势较平稳,说明上个时间片文本的历史影响有效传递到下一个时间片中,因此,EI-oBTM的主题演化效果最好。
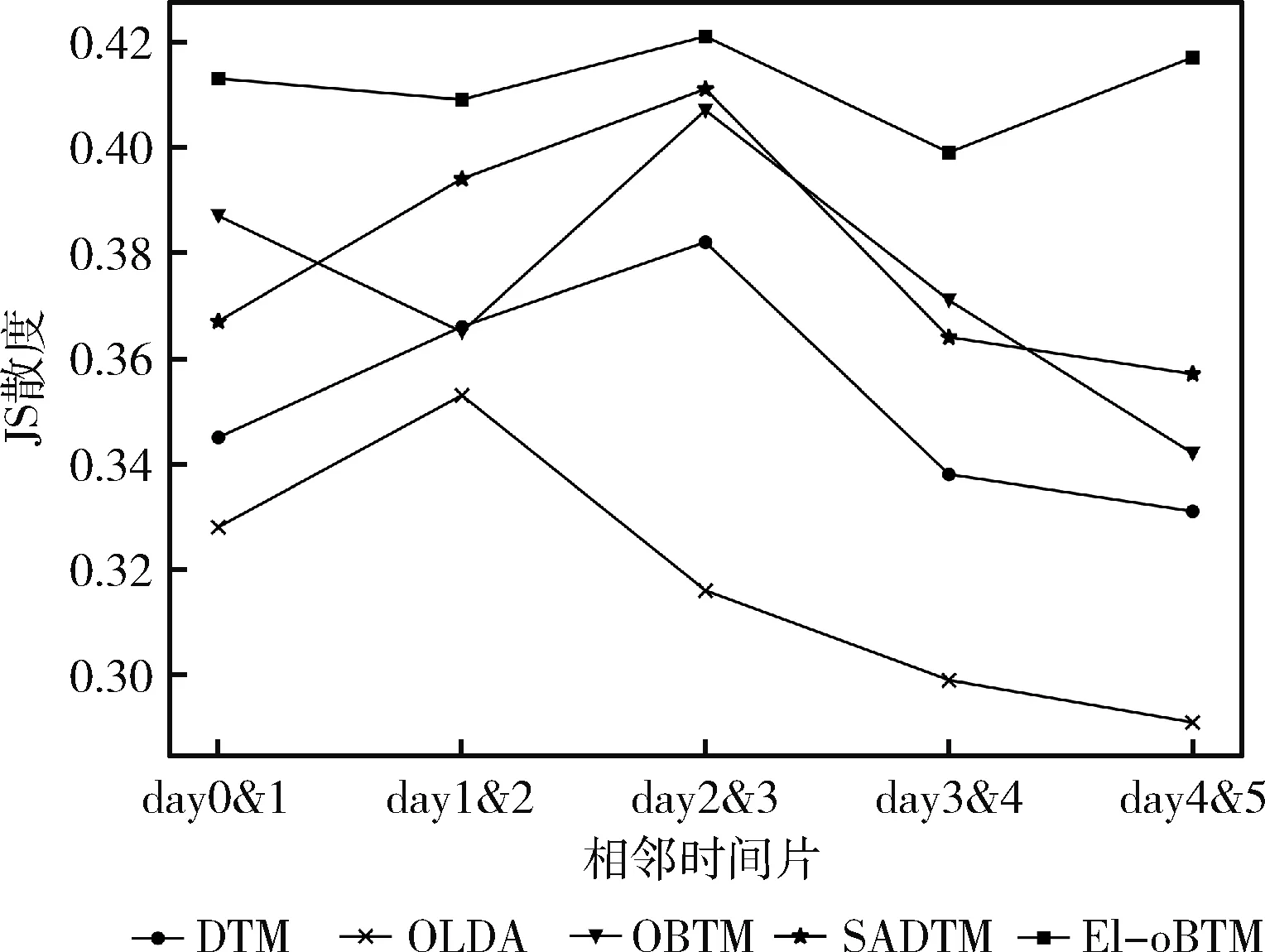
图8 JS散度对比
3.3.3 弹幕文本主题情感极性演化结果分析
将上述情感极性标注结果和影响函数改进到OBTM建模过程中,在最优主题数k=13的情况下进行实验,得到该弹幕文本的主题演化结果如图9所示,在day5内,弹幕情感正极性最高,在day1和day3内有所下降,说明民众情绪在这两个时间片内起伏较大,但总体大于0,由此判断该弹幕文本内容趋于正向。
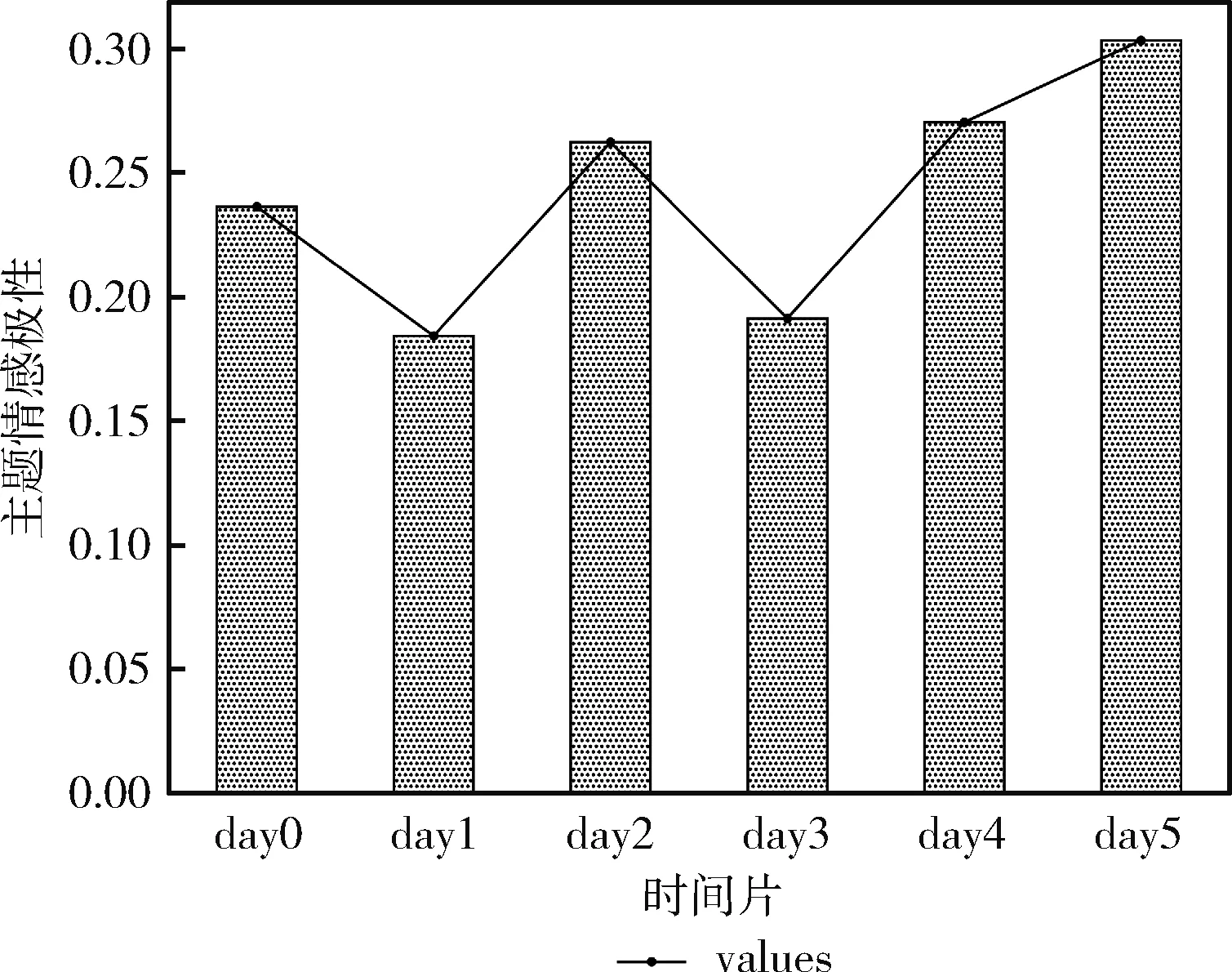
图9 弹幕文本主题情感极性演化
4 结束语
本文针对OBTM模型中如何融入情感极性和优化主题演化效果的问题,提出了情感极性和影响函数的OBTM弹幕主题演化方法EI-oBTM。在融合情感词典与word2vec过程中,改进word2vec词向量模型的负采样过程,提高了情感极性词语标注的准确率。进一步地,通过计算时间片之间的相似度,构建了影响函数,有效地传递了文本的历史影响。实验结果表明,相比DTM、OLDA、OBTM、SADTM方法,EI-oBTM具有较好的主题演化效果,同时,利用主题情感极性演化结果直观展示了弹幕隐含的用户情感倾向,为弹幕舆情分析提供了一种研究方法。
