基于残差网络的蛋白质超二级结构图像分类
2021-11-01马金林马自萍
马金林,石 立+,马自萍
(1.北方民族大学 计算机科学与工程学院,宁夏 银川 750021; 2.北方民族大学 数学与信息科学学院,宁夏 银川 750021)
0 引 言
蛋白质是构成生命的基础物质,通常分为一级结构、二级结构、三级结构和四级结构[1]。蛋白质二级结构通常由两个及以上的二级结构单元与连接多肽链接,通过一些简单的螺旋和折叠组成基础结构,这些局域空间结构称为蛋白质超二级结构或简称基元[2]。超二级结构由α螺旋和β折叠通过简单排列形成局域空间结构,简单超二级结构有α-loop-α、α-loop-β、β-loop-α和β-loop-β这4类,拥有较强的序列信号,对蛋白质三级结构的预测和分类有重要帮助[3]。
Uddin等[4]提出了Saint,它将自我注意机制与Deep3I网络结合起来,以便有效地捕捉氨基酸残基之间的短程和长程相互作用,提高了预测精度,优于现有的最佳替代方法。Kumar等[5]将卷积神经网络(CNN)和双向递归神经网络(BRNN)相结合,提出了一种有效的由42维混合特征组成的预测模型。Guo等[6]提出了DeepACLSTM,从蛋白质序列特征和轮廓特征预测8类PSS。Cheng等[7]提出了一种基于CNN和LSTM的蛋白质二级结构预测方法。
针对传统方法在蛋白质结构预测问题上精度低的问题,本文从图像领域入手,建立蛋白质超二级结构图像数据库,利用ResNet对图像进行分类,得到90.2%的精度。实验结果表明,与传统方法相对比,模型应用于蛋白质超二级结构图像分类有较好的结果,具有可行性、有效性和鲁棒性。
1 模 型
本文使用卷积神经网络中的残差网络[8]模型进行4类蛋白质超二级结构模型的图像分类。影响网络模型性能的因素主要有3个:所选用网络模型、网络模型的层数和目标特征数,随着网络层数的加深,模型性能降低,而利用残差学习单元进行网络训练可以解决神经网络的退化问题。本文采用残差网络模型,以ResNet-34模型为例,图像经过输入层进入卷积层,卷积核大小为7×7,滤波器个数64,步长为2;随后进入尺寸3×3,步长2的最大池化层;接下来构造残差网络单元,在残差网络单元中,卷积层由大小为3×3的卷积核构成,滤波器个数分别是64、128、256和512,每两个卷积层作为一个残差网络单元;最后经过平均池化层和具有softmax的1000维全连接层。模型流程如图1所示。
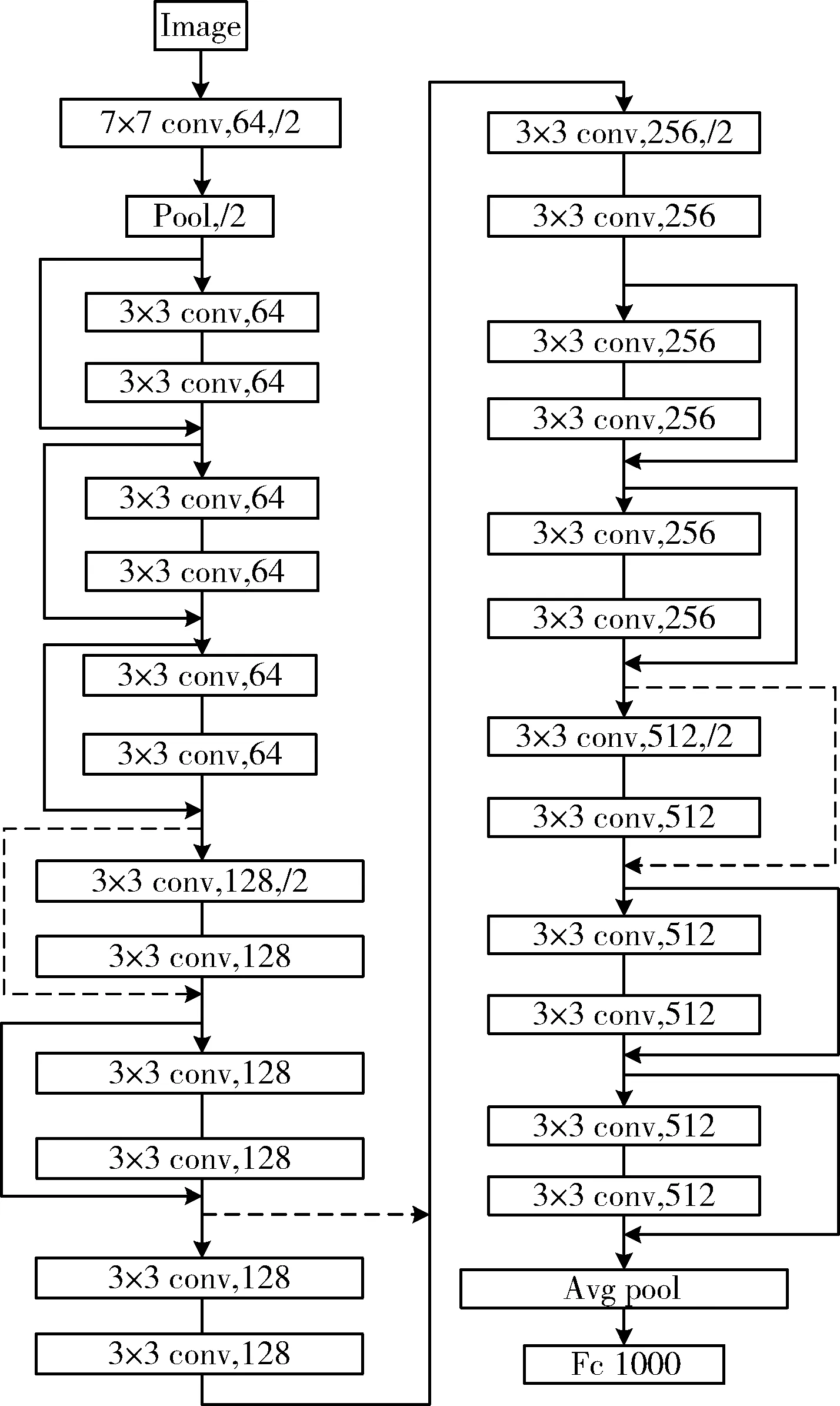
图1 ResNet-34模型结构
模型参数见表1。

表1 5种网络层数模型的参数
1.1 残差网络单元
随着深度卷积神经网络的出现,各种图像分类问题随之有所突破,残差网络是深度卷积神经网络的一种。深度网络通过端到端的方式,将低级到高级的特征和分类器进行集成。为了尽可能获取特征,通常可以通过增加模型网络层数,即增加模型深度来实现。在ImageNet数据集中排名靠前的网络模型都采用了深层结构,许多视觉识别任务从深层模型中收益颇大。
由于网络层数的深度直接影响最后的分类和识别效果,一般会将网络设计的较深,因为网络层级的增加会提高模型精度,但是模型层数过高会使训练精度和测试精度下降。这是梯度爆炸现象所导致的,当模型层数很深时难以训练。
残差网络结构对比传统的平原网络结构,增加了一个恒等的捷径连接,通过人为制作恒等映射,可以令整个模块向恒等映射的方向收敛,同时也能解决错误率由于层数变深而变差的问题。残差网络单元工作方式如图2所示。
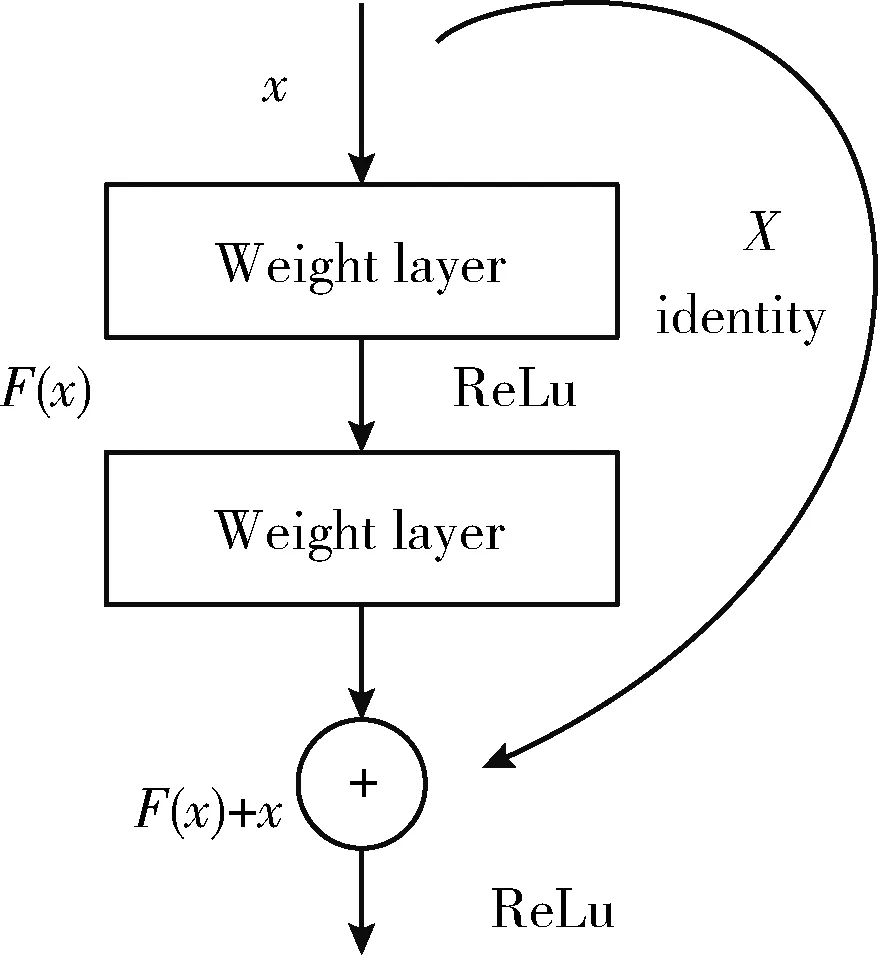
图2 添加了捷径连接的残差网络单元
1.2 输入层
传统的蛋白质二级结构预测方法主要集中在蛋白质序列的特征表示和蛋白质二级结构预测方法两方面。蛋白质特征表示使用合适的数学模型完整表示蛋白质的序列和结构的信息。通过蛋白质序列表示进行二级结构预测方法有:基于氨基酸组成及位置的方法和基于氨基酸物理化学特征提取方法[9]。本实验使用残差网络从图像领域对蛋白质的可视化模型进行分类。
输入层直接输入图像数据,并对数据进行去均值、归一化以及PCA降维处理。
1.3 卷积层
卷积层实际上担任提取特征的作用,可以自动提取样本的深度信息。使用深层网络可以使卷积层从低级特征中提取出复杂特征,通过反向传播算法得出最佳输出。每个卷积层都由若干特征面组成,每个特征面又由若干神经元组成。在神经元中通过卷积核的局部区域将每个特征面连接在一起,将特征面连接在一起的局部区域又称为卷积核的局部感受域,即权值共享。
每个输出通过卷积计算若干特征图的值
(1)
(2)
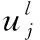
每隔几个堆叠层采用残差学习,在残差网络单元中,除了必须的卷积层还有一个捷径连接,这个捷径连接负责把这个单元的输入和输出直接连接起来,捷径连接的这部分输出和通过卷积层正常得到的输出相加,即为整个单元的输出,公式如下
y=F(x,Wi)+x
(3)
式中:x是输入向量,y是输出向量,函数F(x,Wi)表示捷径连接的输出,即要学习的残差映射。如果F(x,Wi)中所有参数的全部为0,y就是一个恒等映射。
1.4 池化层
输入的图像数据经过卷积层和激活函数处理后,包含的无用信息会降低模型精度,破坏算法的平移不变性,需要通过池化层进行筛选。池化层的主要功能是对图像降维,将图像分块,在平均池化中,在每块区域中计算均值,再将所有数值依次排序,在减少数据量的同时保留有用信息,提高图像特征的变换不变特性。计算公式如下
(4)
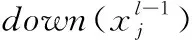
1.5 全连接层
全连接层作为模型的分类器使用,采用ReLU函数作为激活函数,整合卷积层或池化层中具有类别区分性的局部信息。最后一层的全连接层连接输出层,使用线性分类器softmax,进行逻辑回归分类。全连接层l利用输入进行加权求和,再利用激励函数的响应进行计算
xl=f(ul)
(5)
ul=wlxl-1+bl
(6)
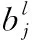
1.6 输出层
输出层输出分类标签。模型层数越深,对图像的特征提取效果就越好,在处理特征不明显的数据对象时深层网络更显得至关重要,我们将划分好的数据集在残差网络中进行训练和测试,利用恒等捷径链接,可以令整个模块向恒等映射的方向收敛,同时也能解决错误率由于层数变深而变差的问题。
2 实验与分析
2.1 实验设计
针对传统算法在蛋白质结构分类任务中精度低的问题,本文从图像领域入手,由蛋白质超二级结构3D模型获得图像数据,进行数据增强后并制作成数据集,利用残差模块对样本特征进行提取,再通过加深残差网络的层数来提取深度特征,最终实现对蛋白质超二级结构的图像分类应用。
本实验流程如下:首先获取4类蛋白质的3D模型,再通过14角度拍摄获得2D图像,进行数据增强后进行贴标签处理并做成4类超二级结构的数据集,再将数据集输入到设计好的残差网络模型中进行训练和测试,最终输出分类精度,流程如图3所示。
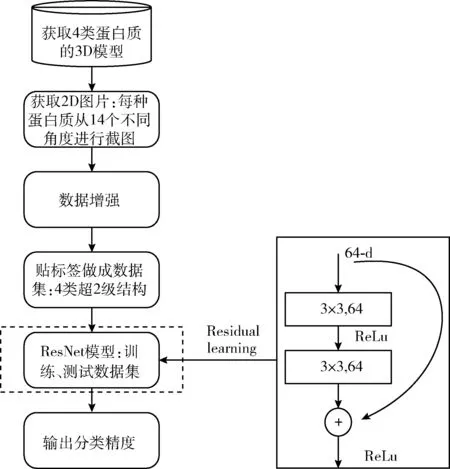
图3 实验流程
2.2 数据集
在蛋白质数据库PDB[10]和SCOP[11]中,我们获得了4类超二级结构蛋白质的3D模型。其中alpha类有7623种,beta类有10 672种,alpha or beta(a/b)类有11 961种,alpha and beta(a+b)类有10 942种。每个超二级结构蛋白质都有相对应的唯一ID,本实验的数据集就来源于这些3D的可视化模型。
为了尽可能提取3D模型的关键信息并且增强目标特征,我们用Jmol软件调整了所获得的3D模型的空间填充、框架、骨干和亚基等可视化参数,并且从14个不同的角度进行截图,令每个蛋白质模型都对应14张不同角度的图像。我们又提取了每个图像的中心感兴趣区域,使图像大小变为50*50,进一步缩短了神经网络的训练时间。总共获得了576 772张50*50像素的2D图像。考虑到所选取的网络模型层数深和数据集过大导致的训练时间过长问题,我们决定从每类蛋白质超二级结构的3D模型中随机选取300个,并将这些3D模型对应的2D图像做成数据集。整个数据集中总共包含16 800张2D图片。数据集类别及各类比样本数目见表2。

表2 数据集
随机选取到a/b类中ID为3FIB的数据作为示例,图4为未经过处理的3D蛋白质模型。图5是经14角度拍摄的2D图像。

图4 ID为3FIB的3D蛋白质模型

图5 3FIB经14角度拍摄的2D图像
2.3 实验环境及参数设置
本实验所用计算机操作系统为windows10,实验所用主要硬件设施为NVIDIA的GeForce RTX 2080款GPU,内存为8 G,并在亚马逊(AWS)云服务器中启用了用于深度学习的Ubuntu系统服务器,其中包含内存为12 G的p2.xlarge和内存为16 G的p3.2xlarge两种GPU实例。
实验使用深度学习的TensorFlow架构,并使用Keras这一开源人工神经网络库作为高阶应用接口,进行模型的设计、调试、评估、应用和可视化。在模型中加入L2范数正则化,抑制了模型中产生过拟合的参数,增强了网络模型的泛化能力并且防止了过拟合现象的发生。
经过大量实验得出结论:当Epoch≥10,模型的性能趋于平滑稳定,即使增加也不会获得更好的表现,因此我们将所有层数的模型Epoch设置为10;正则化系数λ设置为0.000 01;学习率(learning race)对于网络的最终结果起到了至关重要的作用,分别使用了0.0001、0.000 05、0.000 03和0.000 01等值作为不同层数网络的参数;Batch Size的大小影响模型的优化程度和速度,分别设置了30、50、100、200等值;使用Kfold数据集划分方法,将k值设置为10,使用10折交叉验证。
2.4 实验结果及分析
本文模型与以下模型及方法进行比较,文中所有实验均使用蛋白质超二级结构图像数据库作为训练集与测试集:
SVM[12]:按照监督学习的方式,对蛋白质图像数据多分类任务转化为二分类,决策边界是对学习样本求解的最大边距超平面并输出预测值。
Bayes分类器[13]:按照统计分类方法,利用贝叶斯公式,通过某对象的先验概率计算后验概率,令后验概率值的最高项作为对象的类。
LSTM[14]:通过学习长期依赖信息,记忆结构显著改善训练时权重影响过大以及梯度消失等问题,在图像序列的演进方向进行递归且所有节点按链式连接,利用双层单向LSTM对蛋白质图像数据进行分类。
GRU[15]:由于LSTM中3个门控对提升其学习能力的贡献不同,略去贡献小的门控和其对应的权重,简化神经网络结构并提升其学习效率,利用双层单向GRU对蛋白质图像数据进行分类。
AlexNet[16]:使用ReLU作为模型的激活函数,通过卷积层提取特征,全局使用最大池化,避免平均池化的模糊化效果,使用Dropout层,避免模型过拟合,最终输出预测结果。
VGG16[17]:卷积核全部替换为3×3,扩大通道数;相比于AlexNet的3×3池化核,VGG全部使用2×2的卷积核;层数更深特征图更宽;测试阶段全连接转卷积。
在神经网络的图像分类应用中,网络模型的性能主要判断指标有训练精度(train accuracy)、验证误差(validation error)和测试准确率(test accuracy)等参考值。使用ResNet进行实验,训练精度折线图如图6所示,在低于50层时训练精度收敛的较慢,高于50层的模型收敛速度很快且稳定。由实验可以得出,网络层数越深收敛速度越快、训练精度越高。ResNet-152训练精度达到93.8%。
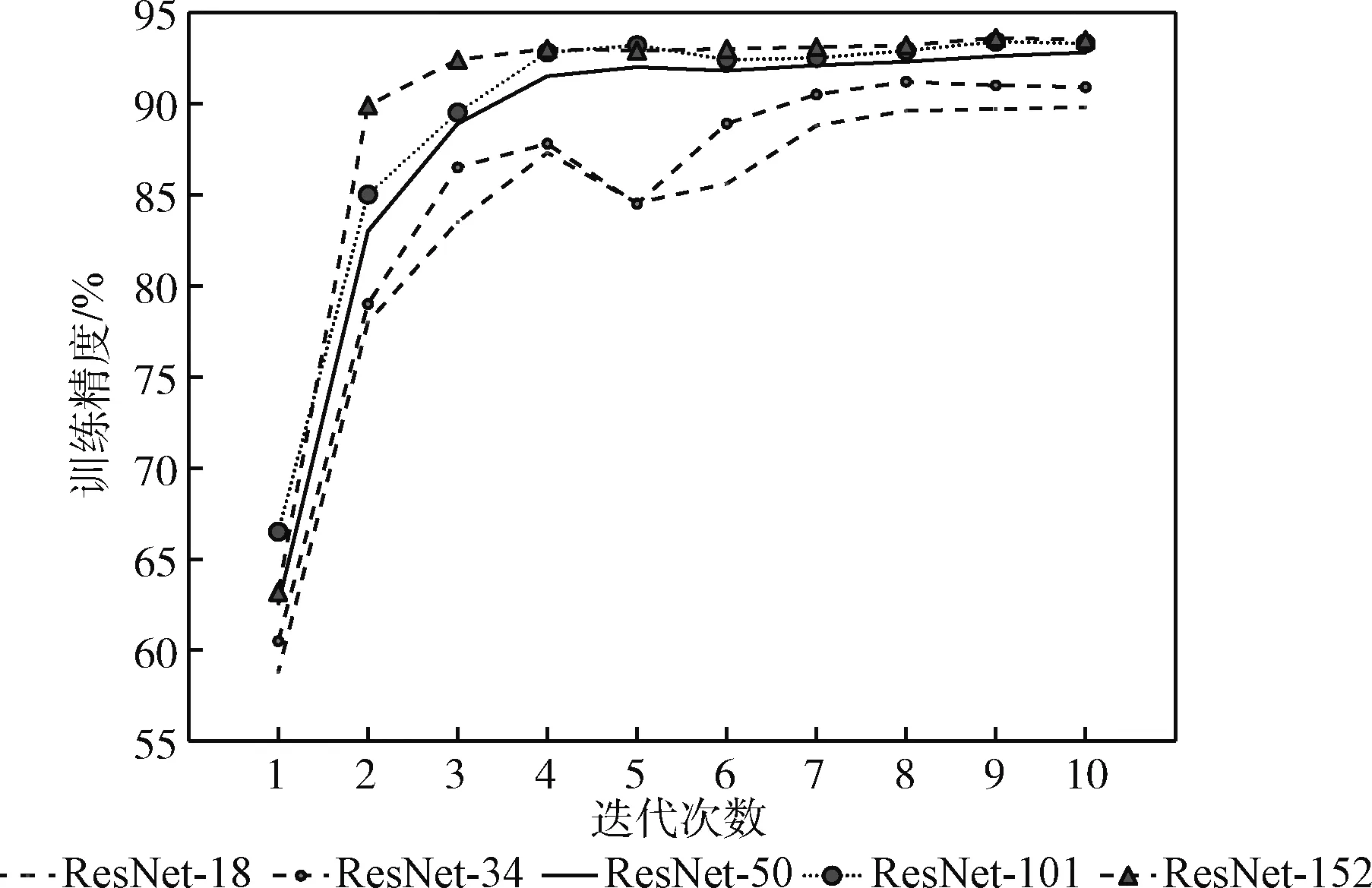
图6 5种层数的ResNet训练精度
我们将训练好的网络进行测试集验证,ResNet的验证误差随层数增加逐渐降低,如图7所示。由实验得出,层数越深的网络验证误差越小,测试精度越高。
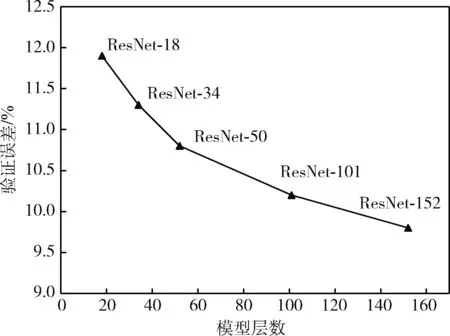
图7 5种层数的ResNet验证误差
训练模型期间,保存最佳验证精度的模型,对4类样本进行分类,获得ResNet-152精度为90.2%,高于其它较低层数的ResNet。
对比实验中,SVM和Bayes分类器的多分类性能评价指标:准确率(Accuracy)、精度(Precision)、F1分数(F1-score)和召回率(Recall),计算公式如下
(7)
(8)
(9)
(10)
其中,每个样本仅有一个标签,标签为两种情况:有(1)和无(0),预测结果有4种:真阳性(true positive,TP),诊断为有,实际上也有;假阳性(false negative,FN),诊断为有,实际上无;真阴性(true negative,TN),诊断为无,实际上也无;伪阴性(false positive,FP),诊断为无,实际上有。
SVM和Bayes分类器实验结果见表3、表4,其中所有类的F1-Score取算术平均,得到宏平均Macro avg,Weighted avg为加权平均,Support为验证性能指标的样本数。由表中数据可知,SVM与Bayes分类器的平均精度分别为67%和53%。

表3 SVM实验结果

表4 Bayes分类器实验结果
LSTM、GRU、AlexNet与VGG16模型的训练精度如图8所示,Epoch设置为50。
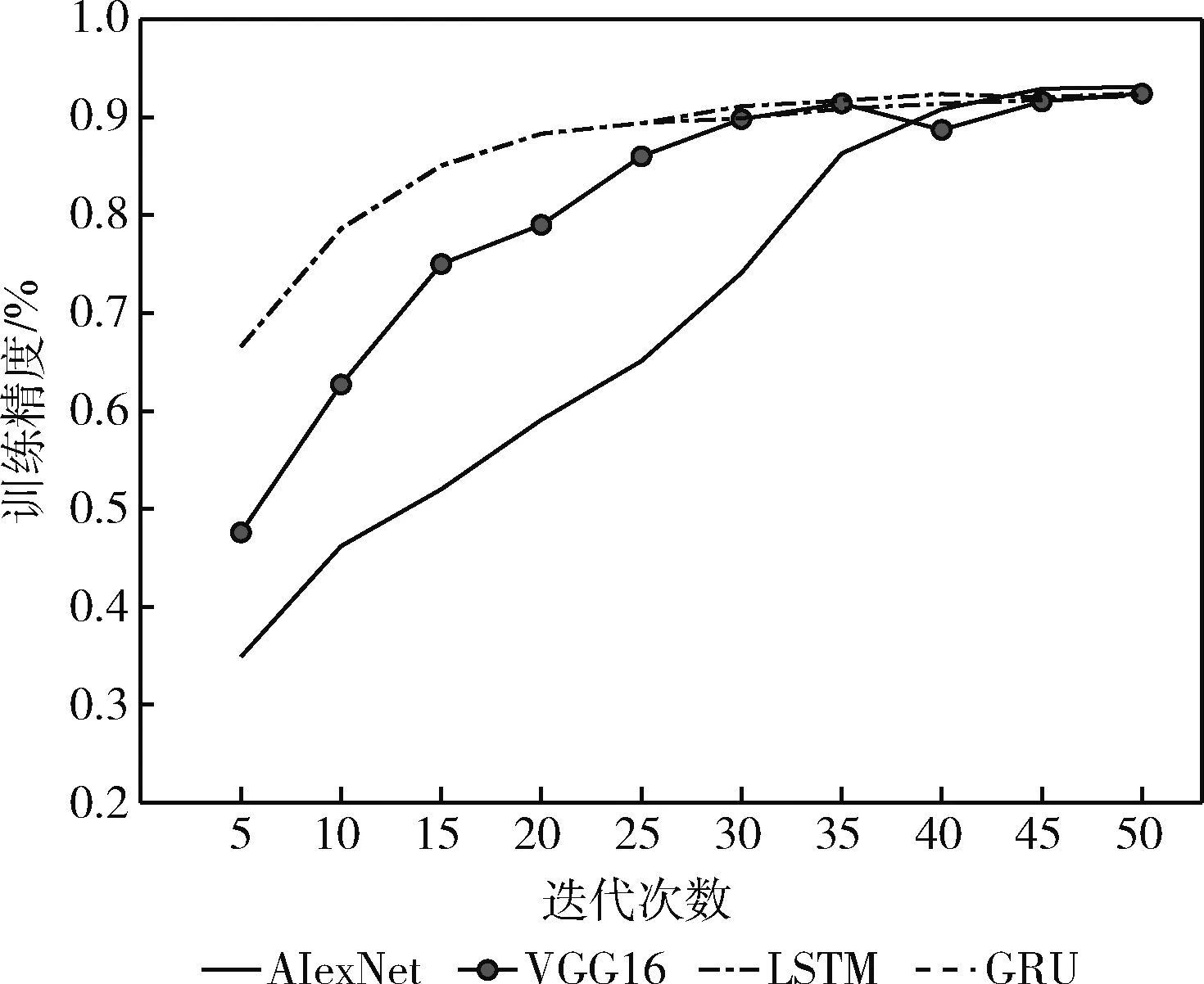
图8 LSTM、GRU、AlexNet与VGG16模型的训练过程
基于蛋白质超二级结构图像数据库的实验模型对比见表5。
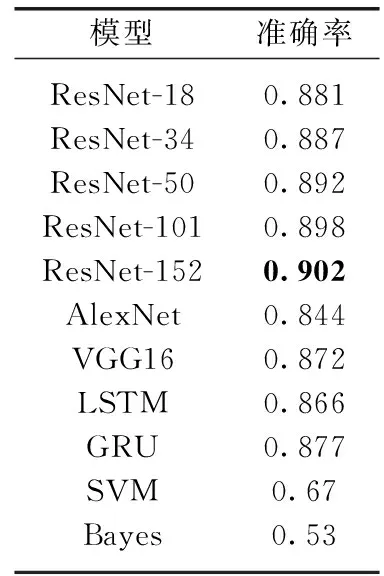
表5 蛋白质图像数据库下实验模型对比
实验总结:在训练过程中,ResNet-152的训练精度上升最快且最稳定,最高93.8%;在测试集验证阶段,验证误差最低,只有9.8%;在最终分类结果上, ResNet-152达到了90.2%的准确率,SVM、Bayes分类器、LSTM、GRU、AlexNet和VGG16模型分别得到了67%、53%、86.6%、87.1%、84.4%和87.2%的准确率,均低于ResNet-152。
实验结果表明,相比于其它算法,利用残差网络进行蛋白质超二级结构图像分类任务的精度较高。在传统算法如SVM、Bayes分类器中,图像分类结果不理想,均低于循环神经网络与卷积神经网络,说明神经网络更适合蛋白质分类工作。而在神经网络中,循环神经网络在序列的演进方向进行递归且所有节点按链式连接,无法对图像进行高效处理;卷积神经网络利用卷积层提取特征,通过加深层数可以提取深度特征,最终获得高于循环神经网络的测试精度。卷积神经网络模型中利用残差学习模块代替卷积层进行特征提取,可以无限增加网络深度且不会引起梯度爆炸。因此基于残差网络的蛋白质超二级结构图像分类具有可行性、有效性和鲁棒性,且表现良好。
3 结束语
相对于以往的蛋白质分类方法,本文从图像领域将蛋白质3D模型转换为2D图片并划分为多分类任务。通过利用卷积神经网络模型训练学习4种蛋白质超二级结构的不同特征,进行蛋白质超二级结构分类,在各层数模型下进行实验,ResNet-152得到了90.2%的准确率。实验结果表明,根据深度学习在图像领域上的表现,我们将其运用在蛋白质结构类和折叠类的分类识别上可行且有较好效果,该方法对硬件要求高,深层网络所需训练时间长,后续将继续进行优化。
