基于关联规则的人事档案信息资源分类方法
2021-11-01周毛青海民族大学青海省西宁市810007
周毛 青海民族大学 青海省西宁市 810007
0 引言
企业的发展离不开人才的引进,针对此,主要有两个途径,一方面是以定向的方式进行有针对性的人才招聘,另一方面就是在缺乏明确目标的情况下,在海量的人才市场中筛选出符合招聘需求的人才[1]。与前者相比,筛选式的人才招聘将面对海量的信息资源,因此,对这些信息合理地分类是十分必要的[2]。由于在复杂的社会环境下,每个人的工作经历都呈现出明显的个性化特征,但又由于行业之间的内在联系,导致不同岗位之间也存在一定的互通性,这就对档案的分类工作提出了更高的要求[3]。
为了提高分类的可靠性,许多学者均针对信息资源分类问题进行了研究。其中,文献利用DenseNet迁移学习对分类信息之间的相似性进行计算,并通过设置阈值,实现对信息资源的分类,该方法的分类结果对阈值设定的依赖性较强,因此稳定性较低;文献[5]提出以深度卷积网络为基础的分类方法,通过对信息的特征进行聚类处理,实现分类,有效提高了分类的效率,但分类后数据之间的距离较大;文献为了避免卷积神经网络粒度问题对分类结果产生的负面影响,将分类信息中的表型信息作为特征提取的基础,实现了高精度的信息分类,但适用范围较小,对于部分不包含表型信息的资源,难以实现其分类效果;文献在对分类信息进行数据增强处理的基础上,利用贝叶斯卷积神经网络实现资源分类,取得了良好的分类效果,但数据增强阶段的工作较为复杂,对操作人员的技术水平要求较高,因此,难以实现普及性应用。由此可以看出,加强信息资源分类方法的研究具有十分重要的意义和价值。
基于此,本文提出了一种基于关联规则的人事档案信息资源分类方法研究。在准确提取信息特征的基础上,利用关联规则挖掘信息之间的内在关系,以此提高最终分类结果的可靠性。并通过实验验证了所提方法的有效性。通过本文研究,以期为信息资源的分类工作提供有价值的参考。
1 基于关联规则的信息分类方法
1.1 信息特征提取
信息资源分类的基础是对数据特征的准确提取,考虑到人事档案信息的类型存在明显的多样化特征,因此,本文将信息增益作为特征提取的依据。
首先,作为一种较为常用的机器学习方法,信息增益的应用相对成熟。在提取人事档案信息资源特征时,以信息中的特征作为增益计算的依据,统计目标特征词在信息中出现的次数。假设在某人事档案中,对于类别A的特征词a出现的次数为xa,那么其对应的信息增益可以表示为:

式中,IG(a)表示关于关键词a的信息增益。通过这样的方式,以此计算出待分类数据中,关于不同分类类别以及对应关键词的信息中信息增益。将信息增益的差值作为信息特征的判定结果,其表示为:

式中,ΔIG(i)表示信息增益的差值,i表示信息资源中的属性特征,xi表示i类别特征词的数量,表示频率。为了确保分类结果满足不同的分类要求,通过对ΔIG(i)的标准进行设定,调整特征提取的精度,使分类结果具有不同的支持度。
1.2 基于关联规则的数据挖掘
根据上文的特征提取结果,建立了关联规则,挖掘不同属性特征下信息资源之间的深层关系,提高分类结果的可靠性。
首先,本文以信息资源特征提取结果为基础,建立评估函数,以此实现对不同信息之间特征相似性的计算。为此,以ΔIG(i)值为标准,令ΔIG(i)=0作为中心,计算信息到中心的距离,该过程可以表示为:

根据这样的方式,对信息资源之间的内在关系进行分析,为后续的分类提供基础。
1.3 信息资源分类
在上述得到信息之间关联的基础上,实现对人事档案信息资源的分类。为此,本文通过3个步骤实现该过程。
(1)确定项集
首先对待分类信息以二元的形式表示,用0表示二元变量表中的空,用1表示二元变量表中的非空,这样做的目的是将信息与特征分离。由于特征词的多样性,一条信息资源中可能存在多个特征,因此,将信息与资源分离后,以具有相同类型特征的信息作为一个训练项集,确保特征分类的全面性。
(2)分类训练
考虑到关联规则下特征之间的目标距离是决定最终分类结果的关键因素,因此,本文通过训练的方式对不同距离下的分类结果进行分析,计算不同距离下的分类准确性,并将最高准确率对应的距离作为最终分类的目标距离。
(3)最终分类
最终,将训练结果中的最佳距离作为信息分类的目标距离,对信息特征之间的关联程度作出准确计算。同时,比较同一信息中对应的特征计算结果,根据计算结果,实现对信息的准确分类。
2 实验分析
为了对所提方法的实际应用效果作出客观评价,进行了实验分析研究,将文献方法和文献方法作为对比方法,通过对比所提方法、文献方法和文献方法的分类结果,分析所提方法的分类效果。
2.1 实验环境
本文进行测试的硬件设备内存为64GB,实验数据的属性设置为n个,共10组数据,其中,每组数据都包含所有属性,且包含50条信息。同时,设置数据的最小支持度为20%,最小置信度为100%。以此为基础,分别采用三种方法对数据进行分类。为了准确评价分类结果的可靠性,本文定义平均准确率为评价指标表示为:

2.2 实验结果
在确定最终的分类结果前,所提方法对数据组进行训练,训练集的大小从100逐渐增加至500,考虑到待分组数据的总量500条信息,因此训练集的大小设置为1500。以此为基础,统计了当最小支持度分别为3%、5%、7%时的训练结果,统计结果如表1所示。
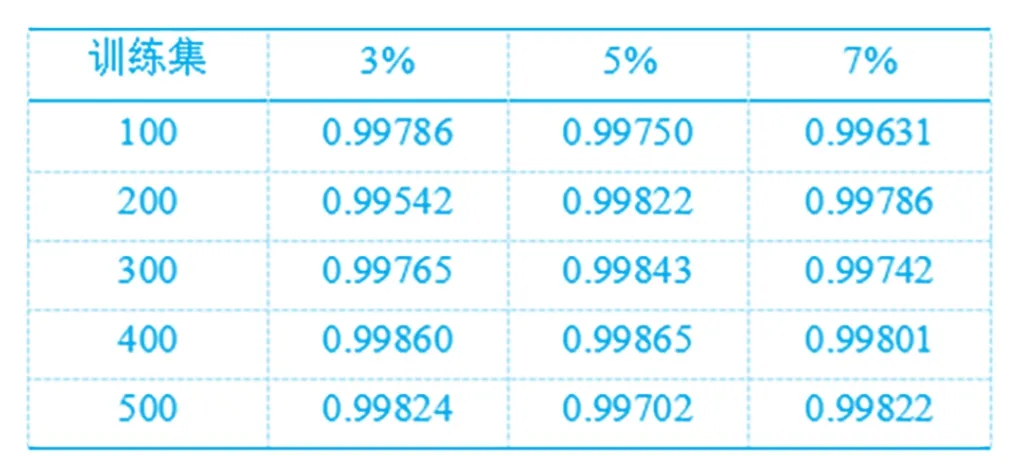
表1 不同最小支持度下所提方法训练结果
从表1中可以看出,在不同的最小支持度下,所提方法的训练结果始终具有较高的准确性,且当最小支持度为3%时,其训练结果的可靠性依然保持在99.5%以上。以此为基础,分别以3%、5%、7%的最小支持度对待分类数据进行分类处理,并与文献和文献的分类结果进行对比,结果如图1所示。

图1 不同方法的分类结果
从图1中可以看出,随着最小支持度的增大,文献[5]方法和文献[6]方法分类结果的平均准确率均呈现出明显的上升趋势,差异程度较为明显,且当最小支持度达到7%时,两种方法的平均准确率也未达到0.99以上。相比之下,所提方法的分类结果较为稳定,平均准确率始终保持在0.995以上,且并未由于最小支持度的变化而出现较大波动。由此可知,所提方法的分类结果具有较高的可靠性。这主要是因为所提方法实现了对数据间内在关联的深层挖掘,因此具有更加可靠的分类依据。
3 结束语
人事档案信息资源的分类结果直接关系到后续信息查找的效率以及相应工作进程的推进速度,虽然与其他部门相比,档案管理工作更加枯燥,但其意义是十分重大的。为此,如何实现海量信息资源的快速准确分类也成为了档案管理部门的一项重要工作内容。本文提出基于关联规则的人事档案信息资源分类方法研究,有效提高分类结果的可靠性。通过本文的研究,以期为信息分类工作的开展提供帮助。
