基于E-OEM模型的Web数据精准挖掘研究
2021-11-01刘张榕
刘张榕
(福建林业职业技术学院 信息工程系, 福建 南平 353000)
0 引言
E-OEM模型是一种描述半结构化数据的自描述数据模型,模型中同时存在数据值和模式,在不同数据值和模式的配合下,可以灵活表示数据结构[1]。Web数据挖掘技术是以Web环境作为支撑,将网络技术与网页技术结合起来的一项技术[2]。
随着计算机信息技术的快速发展,相关研究受到国内外很多学者的广泛关注。在国外,首次提出Web挖掘技术是在上个世纪末,在各项技术的支持发展下,现今已经形成了一种Web会话聚类的一种新框架,Web数据挖掘的精度也有了一定的提升[3]。国外有学者引入分布式算法,设计JAM系统,通过JAM有效挖掘并提取数据信息到相互独立的数据库中。而在国内关于Web数据挖掘的相关研究起步较晚,有学者在考虑服务器的应用逻辑基础上,将Web产生的页面拓扑结构整合为一种挖掘算法[4]。也有学者基于Hadoop大数据开发系统平台开发了PDMiner系统,改进传统算法的开发组件,以提高数据挖掘精度。目前,相关研究已进入到快速发展的阶段。
但是现有的Web数据挖掘方法受到图片数据的后缀影响,所构建的数据结构较为冗杂,此外,在大数据的背景下,数据结构呈现出了多元化的发展,使得Web数据挖掘的精度较低,不能有效实现数据挖掘,为此在E-OEM模型的支持下,设计一种Web数据精准挖掘方法。通过E-OEM模型分类数据结构,降低数据结构的冗杂影响,从而实现精准挖掘。
1 基于E-OEM模型的Web数据精准挖掘研究
1.1 采集及预处理Web数据
Web数据主要由Web日志中的各项数据组成,所以在采集数据时,需将Web日志文件转换为数据库文件,并使用HITS算法处理转化后的页面[5],计算Web页面间的权威权重数值为式(1)。
(1)
其中,q,p分别表示Web页面;hq表示两个页面之间的HITS算法。选用权重数值大于0对应的数据作为Web数据,形成的Web数据预处理过程如图1所示。
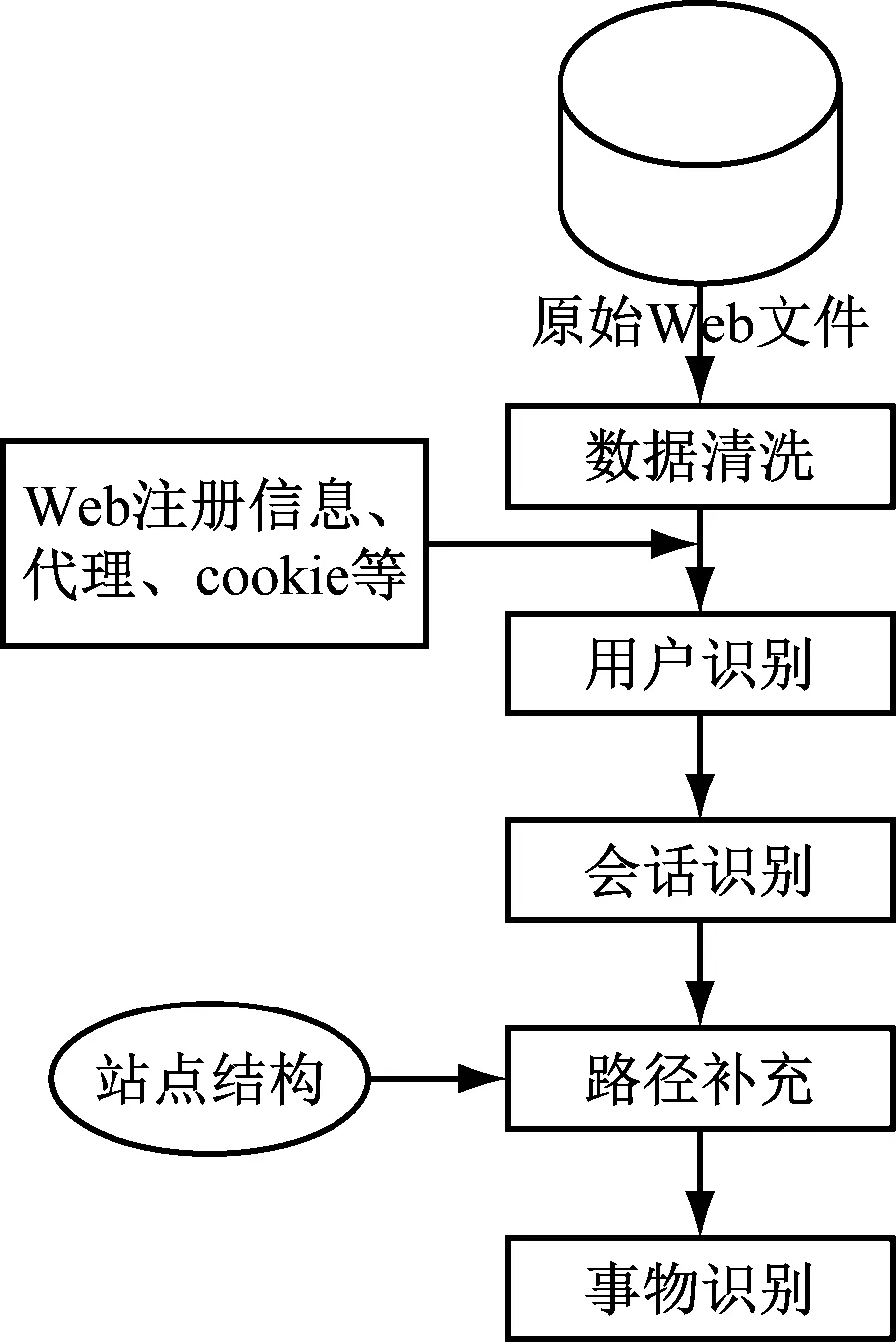
图1 Web数据预处理过程
在图1所示的数据预处理过程下,首先清洗文档中的无用数据,以文件无用的后缀数据作为数据特征值[6-7],计算得到文档中无用后缀数据出现的次数,计算式可表示为式(2)。
wi(d)=φ(tfi(d))
(2)
其中,t表示数据库文件;φ表示文档中的无用后缀数据;tfi(d)表示无用后缀数据出现的次数。根据文件库中文件的数量,计算得到总的无用后缀数据总和,为了消除该部分数据的影响,归一化处理上述次数权重数值,计算式可表示为式(3)。
(3)
其中各项系数含义不变,清洗无用数据后,识别Web日志上显示的站点用户,根据数据信息显示出的信息增益[7],识别出用户与Web站点间产生的会话,站点产生的信息增益可表示为式(4)。
(4)
其中,F表示产生的会话信息;P(W)表示信息站点;P(Ci)表示信息的特征值。在上述所得信息特征值的控制下,采用长度法构建一个有效的用户会话过程,有效的用户会话过程就可表示为式(5)。
(5)
其中,ipt表示用户会话的用户IP;uidt表示该项会话的用户标识;Lt表示会话类型数量;Si表示用户会话的集合。设定上述有效会话间的时间差后,以时间差规划得到的路径作为补充[8],不断补充有效对话间的有效数据,整合有效数据后,采用E-OEM模型分类处理Web数据结构。
1.2 利用E-OEM模型分类Web数据结构
为了使数据挖掘更精准,需要对Web服务器的应用逻辑、页面拓扑等方面多重考虑,在用户浏览时产生的Web数据都是统一登记在日志表中,利用E-OEM模型分类数据结构,综合考虑了Web页面拓扑结构和用户浏览路径等多个数据源,通过结合数据属性三元组方法解决对用户访问数据的标定问题,降低数据结构的冗杂影响。使用上述处理得到的Web数据,标记处理各个数据的类内标识后,根据数据对应的ID,使用E-OEM模型构建一个单独系列的子树,其表达为式(6)。
T={P1,P2,P3,…,Pn}
(6)
其中,Pn(n=1,2,3,…,n)为子树序列。在上述子树结构中,以L作为标签数据所含的属性,构建预处理后Web数据间的属性关系,采用三元组表示数据间的属性关系后[9],根据数据间的相似度划分为不同的数据组,就可通过计算得到相似度S,如式(7)。
(7)
其中,wi表示数据属性关系的三元组;p表示子树序列一点;wli表示带有标签的数据属性关系的三元组;k表示网络数据的类型;n表示数据的分布参数。将相似度数值结果相近的数据划分为一个类别,采用K-means聚类算法处理对应为一个类别的数据集[10],首先选取对应类别的数据中心,聚类数据中心计算过程就可表示为式(8)。
(8)
其中,uic表示分区矩阵;Xi表示数据集合。在上述处理过程下,聚类中心的形成过程如图2所示。
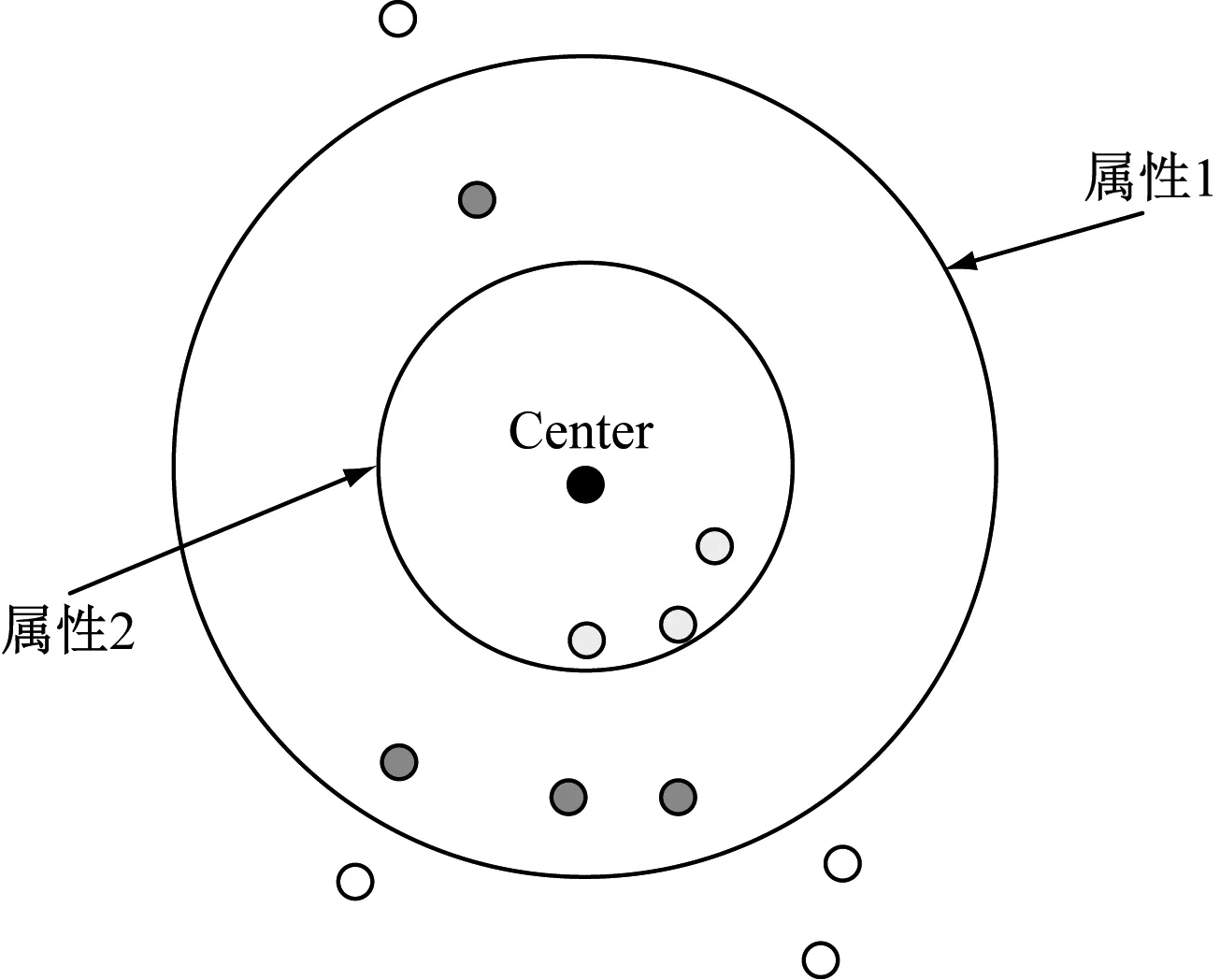
图2 聚类中心的形成过程
在图2所示的聚类中心形成过程下,定义不同的聚类中心代表不同的Web数据结构,以数据聚类中心作为精准挖掘的点[11],在实现Web数据的精准挖掘时,设置聚类中心的序列模式。
1.3 实现Web数据的精准挖掘
在上述聚类中心的控制下,以聚类中心周围的有效数据作为处理对象[12],处理上述有效数据为度量指标,处理过程可表示为式(9)。
(9)
其中,C表示聚类数量;S(Uk)表示聚类数据的类内相似度;S(Ul)表示聚类数据的类间相似度;d(Uk,Ul)表示相似度数值间的有效距离数值。处理有效Web数据为度量指标后,将度量指标整合为一条节点序列,确定序列中的频繁项,计算式可表示为式(10)。
(10)
其中,tk表示不同序列长度;CD表示D频繁项对应的序列长度;CS表示S频繁项对应的序列长度。通过两两序列对比的方式,不断确定频繁项序列的长度大小,在不同的序列长度模式上附加一个数值ei,将ei作为数据序列的尾部标识,计算含尾部标识的序列支持度,计算式可表示为式(11)。
(11)
其中,mi表示尾部标识在序列中的权重数值。以式(11)得到的支持度,整合为不同的挖掘条件序列[13],以支持度数值3作为支持度处理对象,形成挖掘条件序列结果如图3所示。
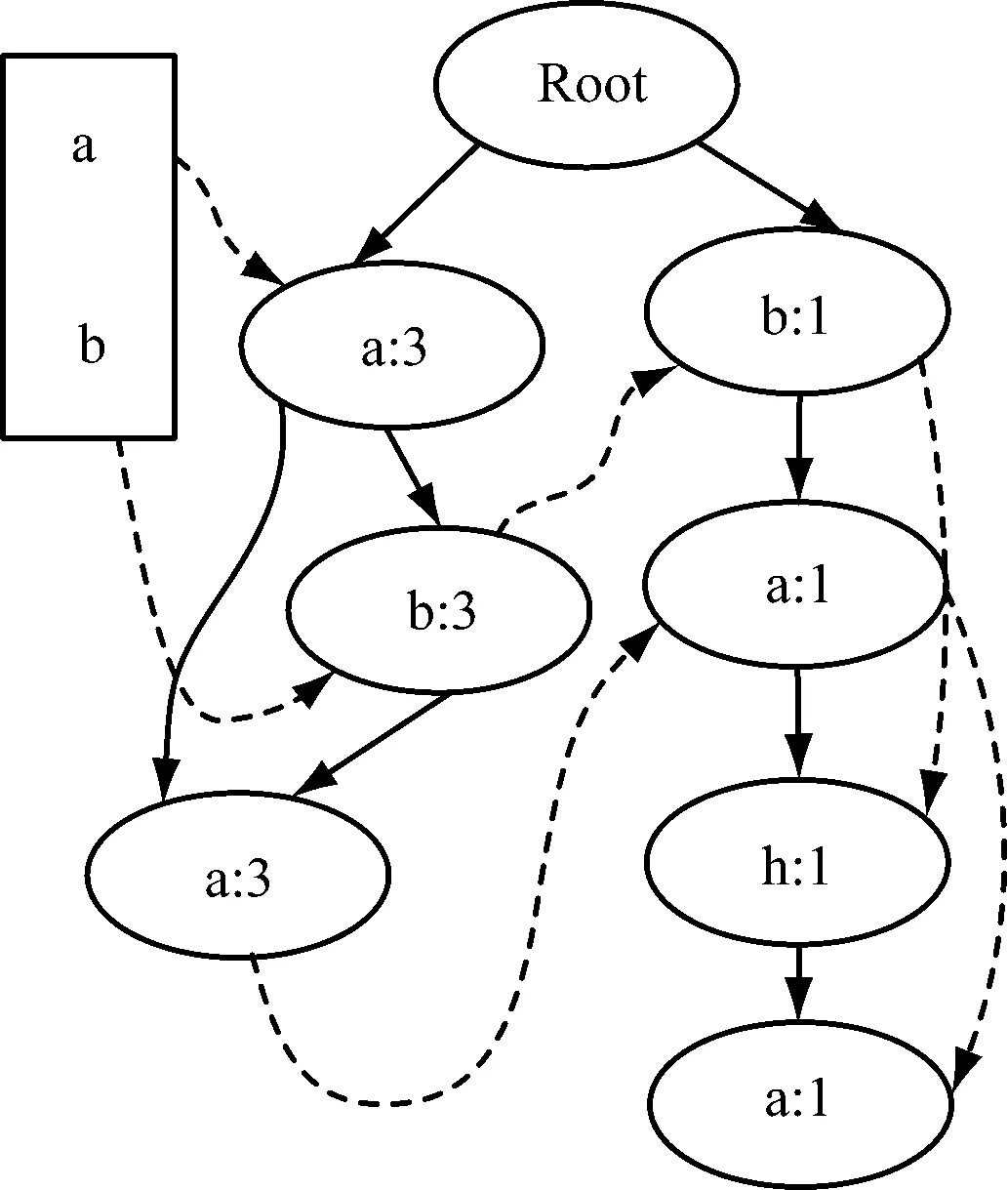
图3 形成的序列挖掘条件
在图3所示的序列挖掘条件下,当存在两个聚类中心时,以Root作为精准挖掘的起点,结合不同序列的支持度数值[14-15],在a、b、h序列基的参与下,形成不同的精准挖掘路径。综合上述处理,最终完成对基于E-OEM模型的Web数据精准挖掘方法的研究。
2 仿真实验
2.1 实验准备
准备计算机软硬件参数如表1所示。

表1 软硬件参数
使用上表所示参数的服务器6台,搭建实验环境如图4所示。

图4 搭建的实验环境
在图4所示的实验环境下,使用版本为1.7的JDK环境,上传JDK安装包后,规划安装目录,解压安装过程,如图5所示。
图5 JDK解压安装
采用Iris数据集作为精准挖掘的对象,分别使用传统挖掘方法、文献[1]中的挖掘方法以及文中设计的挖掘方法进行实验,对比3种挖掘方法的性能。
2.2 结果及分析
基于上述实验准备,调用上图实验环境内的6台服务器同时运行Iris数据集,控制JDK中的变量后,实现Web数据的待采集状态,将6个服务器作为6个挖掘对象,控制3种挖掘方法同时进行挖掘,对比3种挖掘方法的作用时间,得到时间结果,如图6所示。
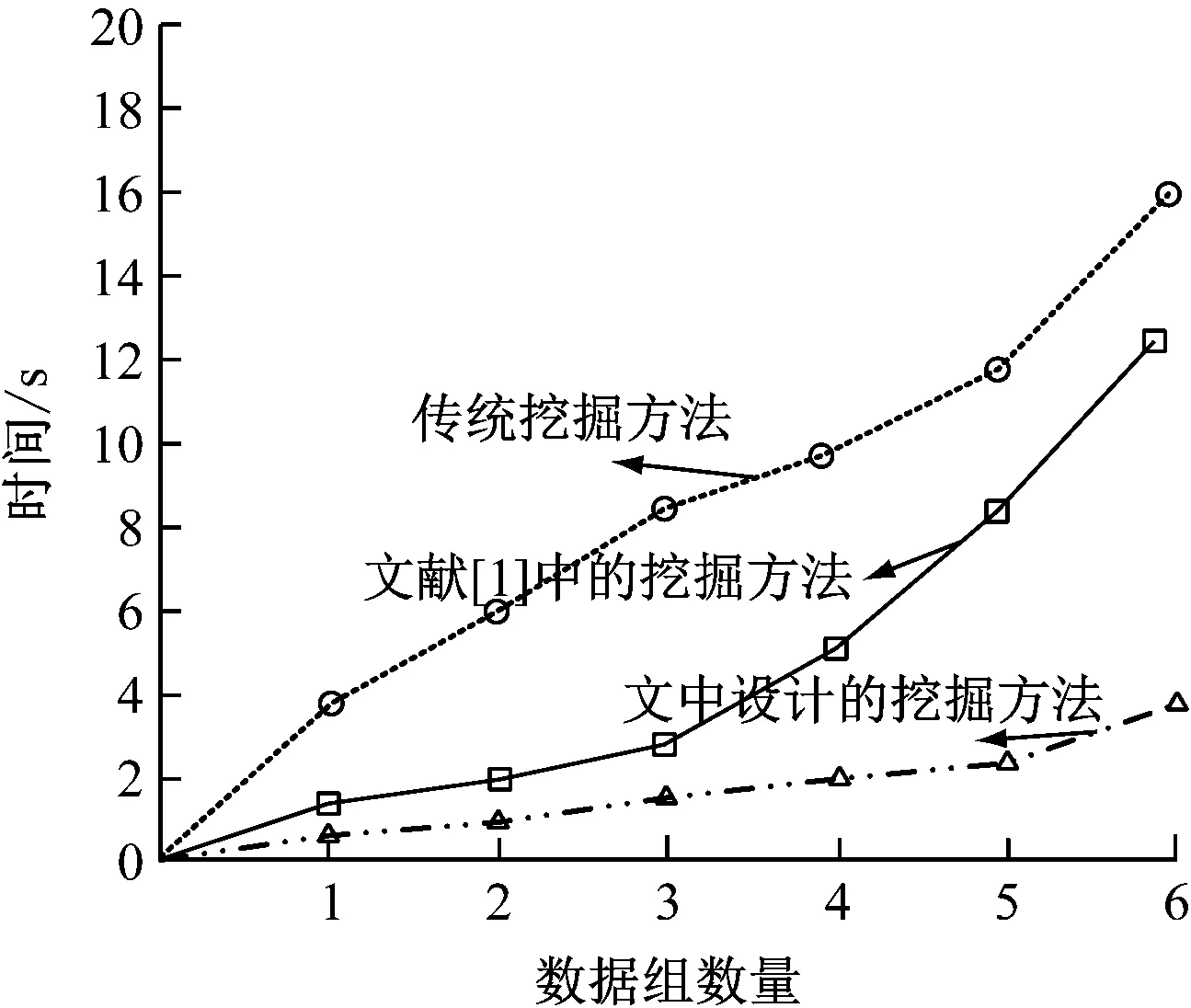
图6 3种挖掘方法作用时间结果
由图6所示的作用时间结果可知,在3种挖掘方法的控制下,针对同等实验环境内的相同实验数据集,传统挖掘方法实际作用时产生的挖掘时间最长,当待挖掘数据集为6时,实际的挖掘时间在16 s左右,所消耗的挖掘时间较长。文献[1]中挖掘方法在相同数量的数据集下,实际挖掘时间在12 s左右,所消耗的挖掘时间较短。而文中设计的挖掘方法在挖掘相同数量的数据集时,所需的时间仅在4 s左右,与上述两种挖掘方法相比,文中设计的挖掘方法消耗的挖掘时间最短。
在上述实验环境下,随机抽取3个Iris数据集作为实验对象,将数据集定义为3种类型,定义3种数据集中的聚类中心为精准挖掘中心,精准挖掘中心结果如图7所示。

图7 定义的挖掘中心
图中用不同的图案形状表达对数据集中数据的分类,并通过聚类分析得到图7所示的聚类中心X,即为数据精准挖掘的对象。使用3种挖掘方法对图7中的Iris数据集进行分类,以聚类分析得出的3种数据集中的聚类中心位置作为标准参考,对比聚类中心X的位置变化,统计3种挖掘方法挖掘的结果。结果如图8所示。
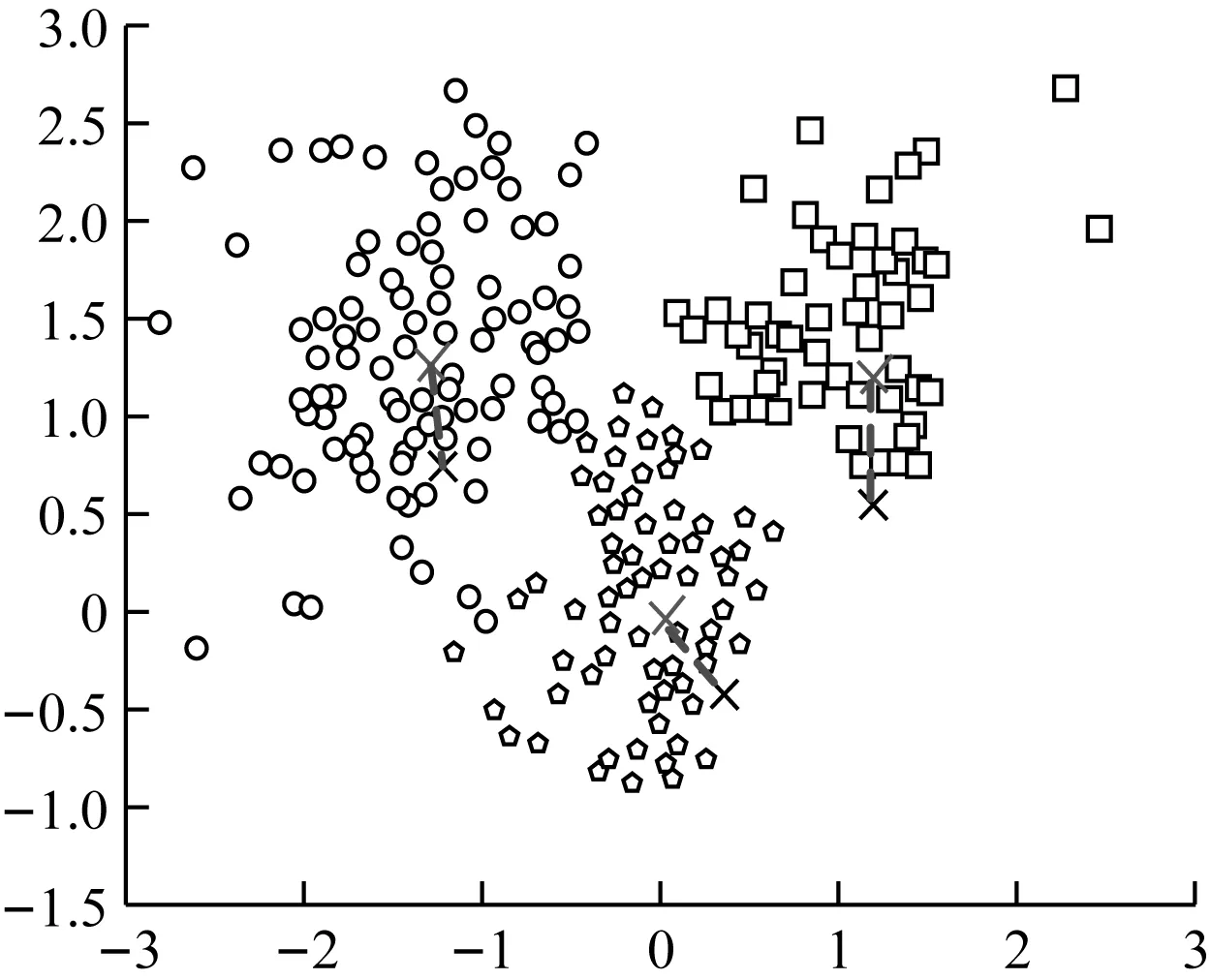
(a) 传统挖掘方法挖掘中心结果
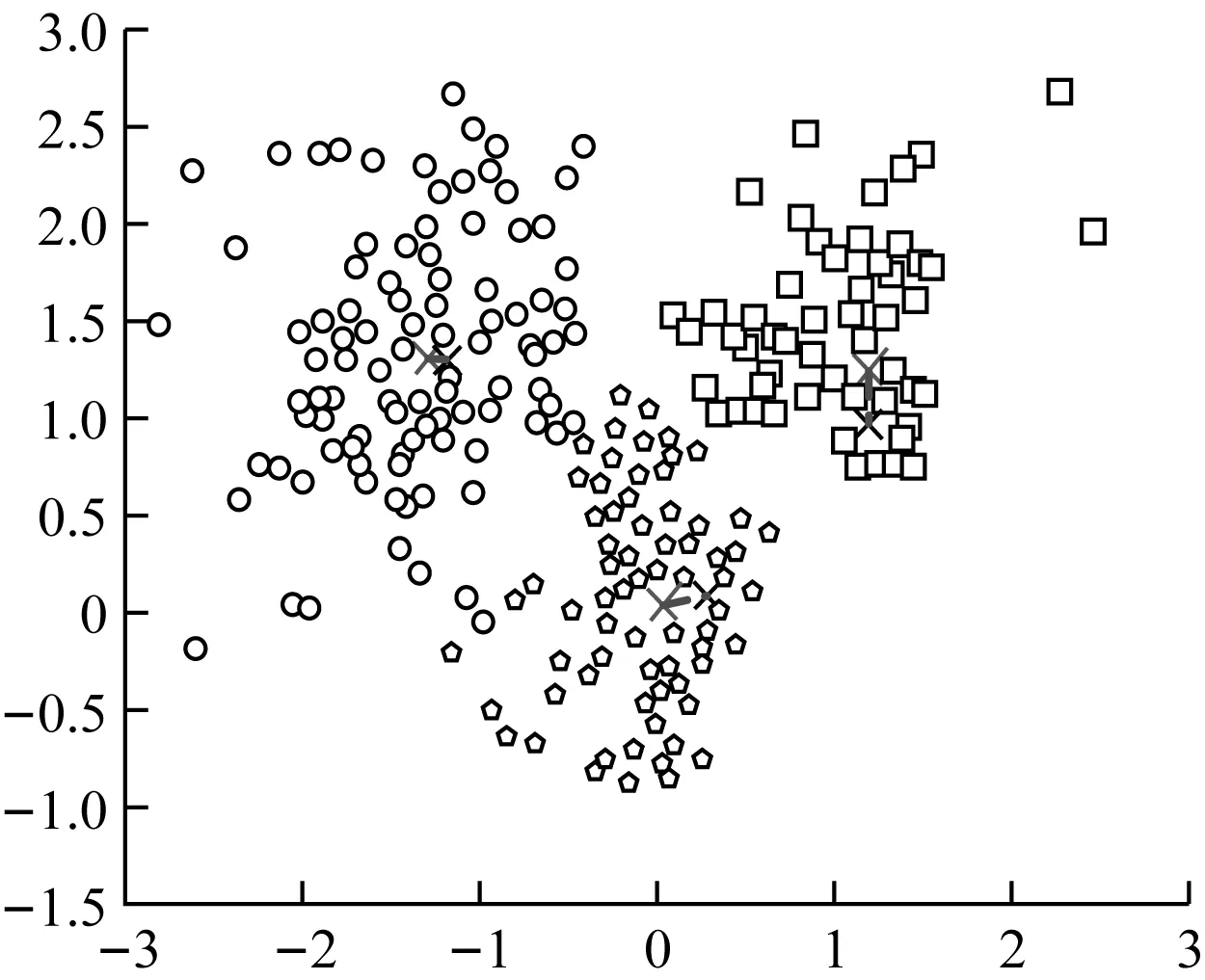
(b) 文献[1]中的挖掘方法挖掘中心结果

(c) 文中设计的挖掘方法挖掘中心结果
图中用蓝色X表示设定的聚类中心位置,黑色X表示采用该数据挖掘方法后的聚类中心位置,用红色虚线表示聚类中心偏移差。
由图8所示的实验结果可知,以Iris数据集的聚类中心作为精准挖掘中心,在3种挖掘方法的控制下,传统挖掘方法得到的挖掘中心在横纵坐标上偏离标准坐标1个单位距离,文献[1]中的挖掘方法偏离标准挖掘中心0.4个单位距离,而文中设计的挖掘方法得到的挖掘中心与标准的挖掘中心相差不大,与前述两种挖掘方法相比,该种挖掘方法得到的挖掘中心更加准确。
保持上述实验环境不变,将准备的Iris数据集以10个数据作为一个实验组,共划分为15个实验数据组,以该实验组作为对象,统计并计算3种挖掘方法对数据分类的的准确性,准确率结果如表2所示。

表2 挖掘准确率结果
由表2可知,以相同数量不同内容的数据作为挖掘对象,在3种挖掘方法的控制下,传统挖掘方法对数据分类的准确率数值在72%-80%之间,准确率数值较小。文献[1]中的挖掘方法对数据分类的准确率结果在85%-89%之间,准确率数值也不高。而文中设计的挖掘方法对数据分类最终得到的准确率数值在92%-98%之间,实际得到的准确率数值最大。综合上述实验结果可知,文中设计的精准挖掘方法挖掘时间最短,确定得到的挖掘中心最标准且数据分类的准确率最高。
3 总结
对数据的精准挖掘是当下Web数据技术的研究重点,在E-OEM模型技术的支持下,设计一种数据精准挖掘方法,能够改善现有精准挖掘方法挖掘时间较长的不足,同时能够有效地消除Web数据中的冗余数据,增强挖掘方法的准确性,为今后研究精准挖掘方法提供参考。
