基于图和K近邻的文本分类算法
2021-11-01吴宗卓
吴宗卓
(陕西国防工业职业技术学院 计算机与软件学院, 陕西 西安 710300)
0 引言
文本分类是指在预先定义的主题或类别中,将每一个文本分类为其相关主题或类别的过程[1-2]。作为初步任务,预先定义了有限数量的类别,并准备用一个或一些预先定义的类别标记的示例文本[3]。在学习过程中,利用样本标记文本构造分类能力。后续文本是从样本标记文本中分离出来的文本,被归类为泛化过程。在本研究中,即使有其他的方法,如人工规则学习和其他启发式方法,也假设使用有监督的学习算法[4-5]。
然而,将文本编码成数值向量会导致诸如大维数和稀疏分布等问题[6]。图成为知识或信息的普遍代表,称为本体论或词网[7-8]。因为本体是用来将知识表示为图的,所以在以前的工作中,有很多处理图的算法。因此,基于这些动机,将文本编码成图,并将机器学习算法修改成接收图作为输入数据的版本。本研究采用邻接矩阵来表示每一个图。通过避免将文本编码成数值向量的问题,希望所提出的算法比传统的K近邻(K-Nearest Neighbor,KNN)算法有更好的性能。由于图是比数值向量更多的符号文本表示,所以期望在编码中有更多的透明度。为了更有效地处理文本,并使得文本的表示更加紧凑。因此,本研究的目标是实现满足效益的文本分类。
1 背景知识
1.1 文本编码
将文本编码成图的过程,如图1所示。

图1 文本编码成图的过程
将图分解为两组:顶点集和边集。顶点和边分别对应于单词及其语义关系。在本研究中,将表示文字的图作为加权无向图。因此,在本节中,将详细描述把文本表示为图的过程。
在将文本编码到图中之前,需要构造一个索引列表,其中每个文本都链接到一个单词列表。直接从语料库中生成文本列表。每个文本都被索引到一个单词列表中,并与它自己包含的单词列表相关联。每个单词都有其权重,并将信息作为其与文本的关系发布。文本的索引基本上有三个步骤:标记化、词干化和停止字删除。
在将文本编码成图的过程中,需要定义顶点后接边。顶点对应于文本中包含的单词列表。其中一些是通过其作为顶点的权重选择的,如式(1)。
D(v)={vi1,vi2,…,vim}
(1)
考虑通过对文本进行排序来选择固定数量的文本的排序选择,以及选择权重大于或等于阈值的文本的基于分数的排序选择作为选择方案。通过索引提取一组表示单词的顶点。
需要定义边集和顶点集,以便将一个词表示成一个图。计算所有可能的顶点对的相似度来表示单词。因此构造了一个相似度矩阵,其条目是来自语料库的词之间的相似度。选择相似度大于给定阈值的词对,并定义由以下边组成的集,如式(2)。
D(e)={ei1,ei2,…,ein}
(2)
接着,需要考虑如何在实现层将图表示为其结构化形式。这里有三种方法,第一种方法主要采用的是邻接矩阵,其中顶点对应于其行和列,条目指示边权重。把顶点作为节点、边作为指针的链表看作是图的另一种表示形式。第三种方式为一个图被表示成一个边的列表,这些边被作为一对顶点标识符给出,并且每个权重都与它自己的权重相关联。在本研究中,采用第三种方案,即图被表示成一组边。
1.2 图
本节讨论图运算及其实现的基础。它由两部分组成,相似度矩阵及其运算。
(1) 相似度矩阵:本小节关注相似度矩阵作为对字符串向量执行语义操作的基础。相似度矩阵的每一行和每一列对应于语料库中的一个单词。所有可能的词对的相似度都是以0和1之间的标准化值给出的。从语料库中构造的相似矩阵,该矩阵是对称元素和对角元素为1的N×N方阵。在本小节中,将正式描述相似矩阵的定义和特征。
相似度矩阵的每个条目都表示两个对应单词之间的相似度。这两个词ti和tj被视为两组文本。这两个词之间的相似性,由式(3)计算。
(3)
其中,|Ti|为集合的基数Ti。相似度总是以0和1之间的标准化值给出;如果两个文档彼此完全相同,则相似度变为1,如式(4)。
(4)
如果两个单词没有共享的文本,那么Ti∩Tj=Ø的相似度为0,如式(5)。
(5)
在下一步的研究中将考虑更先进的相似度计算方案。
从文本集合中,构建了N×N方阵,如式(6)。
(6)
集合N中包含的单个单词对应于矩阵的行和列。条目sij由式(3)计算,如式(7)。
sij=sim(ti,tj)
(7)
式(3)中的分母防止了文本长度的高估或低估。对于文本数N,构建上述矩阵需要二次复杂度O(N2)。
用数学方法来描述上面的相似矩阵。由于每一列和每一行在矩阵的对角线位置对应其相同的文本,所以对角线元素总是由式(3)给出1。在矩阵的非对角位置,由于式(3)中的0≤2|Ti∩Ti|≤|Ti|+|Tj|,这些值总是作为介于0和1之间的标准化值给出。证明了相似矩阵是对称的,如式(8)。
(8)
因此,该矩阵被描述为由0到1之间的归一化值组成的对称矩阵。
相似矩阵可以从语料库中自动构造。语料库中包含的N个文本作为输入,每一个文本都被索引成一个单词表。生成所有可能的词对,并通过式(1)计算它们之间的相似性。通过计算它们,构造了由相似性组成的方阵。一旦建立了相似度矩阵,它将继续作为对字符串向量执行操作的基础。
(2) 图之间的相似度:本节涉及计算两个图之间相似度的方案。单词被编码成图,其中顶点是文本标识符,边是文本之间的相似性。假设每一个图都是一组边,并考虑计算图之间相似性的三种情况:都重合,只有一个重合,以及无重合。图之间的相似度是通过平均边之间的相似度来计算的,并且总是以0到1之间的标准值给出。因此,本节旨在正式描述计算图之间相似度的过程。
需要考虑由sim(ei,ej)表示的两个独立边ei和ej之间的相似性,每个加权边由两个节点组成,其权重如式(9)。
ei={vi1,vi2,wi}
(9)
边权用w(ei)=wi表示。如果没有节点被两条边(A,B,0.2)和(C,D,0.4)共享,则相似度为零。如果(A,B,0.2)和(B,C,0.4)这样的两条边只共享一个节点,则相似度变成两个权重的乘积,具体如式(10)。
sim(ei,ej)=w(ei)w(ej)
(10)
如果两个节点都共享,则相似度将成为两个权重的平均值,如式(11)。
(11)
假设边之间的每一个权重总是作为0到1之间的标准化值给出。
两个图G1和G2表示为两组,如式(12)。
(12)
并且假设两个图的边数相同。所有可能的边对都是由这两个图生成的。对于一个图中的每一条边,计算其与另一条图中的边的相似度,得到其中的最大值作为边与图之间的相似度为式(13)。
(13)
两个图之间的相似性是通过对边与另一个图之间的最大相似性进行平均来设置的,如式(14)。
(14)
由于边的权值总是作为规范化值给出的,所以图之间的相似度总是如此。
接下来,从数学上描述计算图之间相似性的操作。如果两个图G1和G2彼此相同,并且所有边都用1值加权,即∀i,w(e1i)=1,w(e2i)=1,则两个图之间的相似性变为1,如式(15)。
(15)
如果两个图G1和G2具有不同的权重,则两个图之间的相似性是两个图的平均权重,如式(16)。
(16)
如果两个图之间没有共享边,则相似度为零,如式(17)。
(17)
从数学刻画可以证明,两个图之间的相似性总是一个介于0和1之间的标准化值。

2 改进的KNN算法
传统的KNN算法如图2所示。
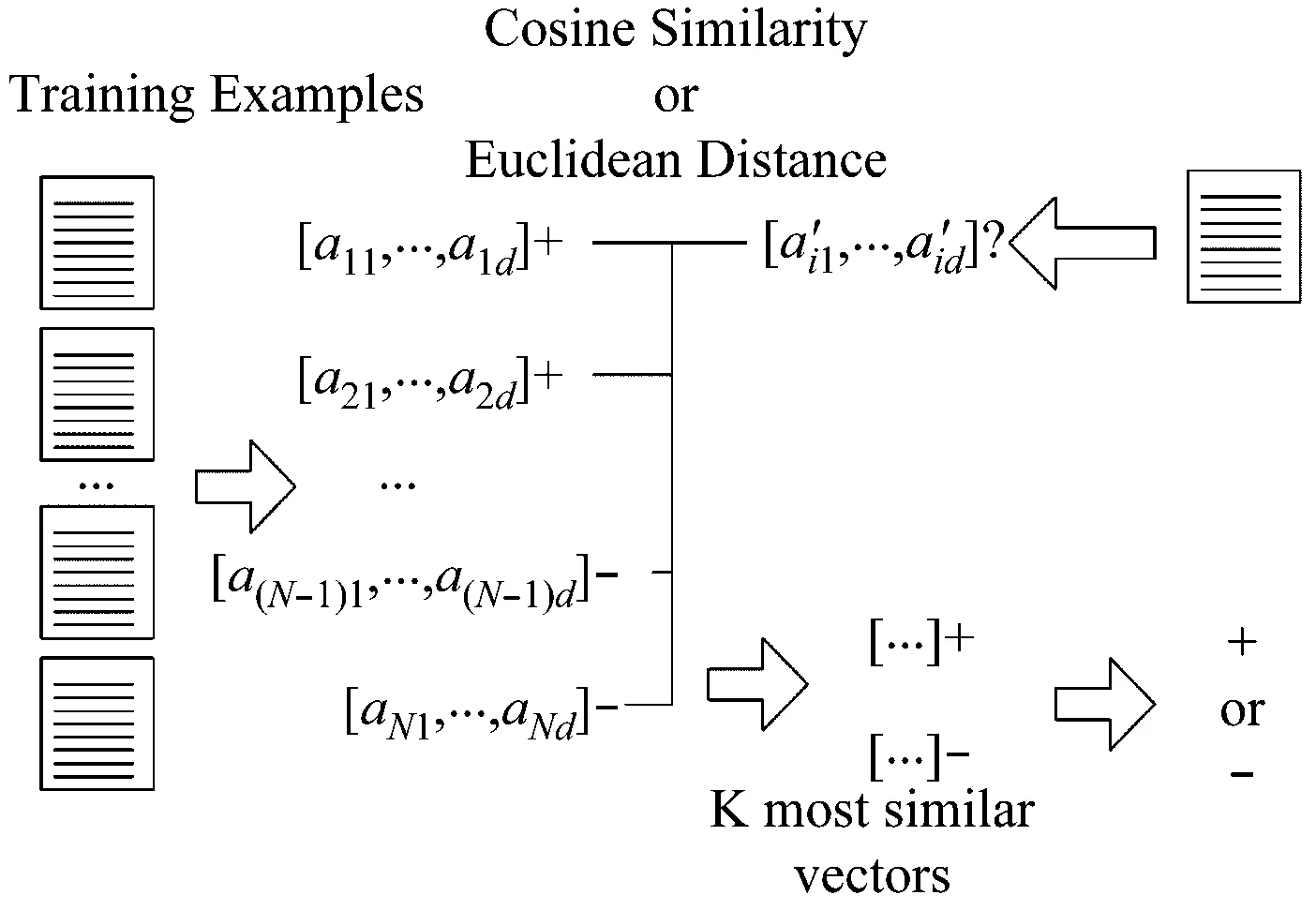
图2 传统KNN示意图
用正类或负类标记的样本词被编码成数值向量。用欧几里德距离或余弦相似性计算表示新样本的数值向量与已有样本的数值向量之间的相似性。选取K个最相似的样本词作为K个最近邻,通过投票决定新样本的标签。但是,请注意,传统的KNN版本在计算非常稀疏的数值向量之间的相似性方面非常脆弱。
与传统的分类方法不同,改进后的KNN算法的分类过程,如图3所示。
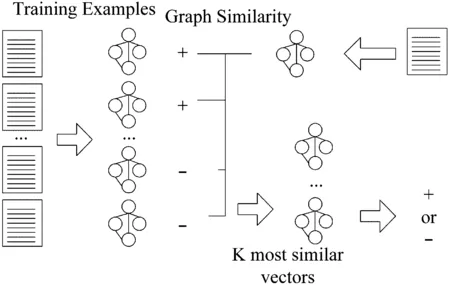
图3 改进的KNN示意图
用正类或负类标记的样本文本通过第1.1节中描述的过程编码成图。两个图之间的相似性通过第1.2节中描述的方案计算。与传统版本相同,在提出的版本中,选择K个最相似的样本,并通过对样本实体的投票决定新样本的标签。由于图中的稀疏分布在本质上是不可得的,因此本研究一定能克服稀疏分布的差分性,并且还可以继续优化,如可以将不同的权重分配给选定的邻居,而不是相同的邻居:最大的权重分配给第一个最近的邻居,最小的权重分配给最后一个邻居。与固定数量的近邻不同,选择了一个已给定的新样本为中心的超球体内任意数量的训练样本作为近邻。分类分数是根据训练样本的相似性按比例计算的,而不是选择最近的邻居。还可以考虑两个以上的变体组合在一起的变体。
3 实验与评估
3.1 实验环境
本研究的实验环境主要是基于Ubuntu 14.04的Linux操作系统,采用Intelcore I7 2.5 GHz的CPU,16 GB的内存,使用的编程语言为Python 2.7, 在Pycharm下运行。在所有实验中使用的数据来源为路透社公开的分类语料库[9]。在实验中从语料库中选择了相当数量的数据作为训练集,并同时选取了对应的作为测试集。分类类别包括了计算机、政治、教育、艺术、环境、历史。整个训练集共有3 283个样本,其中每一小类的样本数量不小于400篇。测试集共有2 942个样本,其中每一小类的样本数量不小于500篇。
3.2 评价指标
评价文本分类算法性能主要是通过准确率P,召回率R,以及与这两个值相关的F1值。具体计算式如式(18)。
(18)
式中,a代表实例正确分配到正类中的数目;b代表分配到正类中的误分实例;c代表属于被分到负类中原本属于正类的实例的数量。
因为召回率和准确率是相互互补的。所以为了综合考虑这两个因素,通过计算F1值得到相关结果,如式(19)。
(19)
3.3 结果评估
为了体现提出算法的性能,将本研究与传统KNN算法,LLKNN(Locally LinearK-Nearest Neighbor)算法[10]以及TextCNN(Textconvolutional neural networks)算法[11]进行对比。结果如表1所示。

表1 数据集对比结果(%)
从表1结果可以知道,本研究相比KNN、TextCNN以及LLKNN算法,本研究提出的算法的性能较好,平均能达到92%左右,尤其是相对于原始的KNN算法,结果提高了将近6%。从细节上看,提出算法的P值在环境这一小类中达到最大为98.98%,在计算机分类中,达到最大,为99.35%。同样的在计算机分类中,F1也是最大的,为96.53%。综上所述,提出的改进算法具有较好的性能。
4 总结
所提出的研究成果可以应用于医学或工程学等特定领域的技术文献分类,而不是单单限于不同领域的新闻文章。通过在表示文本的图上用数学方法定义和刻画更高级的运算,使用更复杂的操作,将更先进的机器学习算法修改为基于图的算法。采用该方法,将文本分类系统作为一个系统模块或一个独立的软件来实现。
未来还需要在图上定义更多的操作,以便将其他机器学习算法修改为基于图的版本。在本研究中,只有定义图之间的相似度,才能修正KNN算法。为了修改K均值算法,需要再定义一个操作,在这些操作之间建立一个具有代表性的原型图。对于输入和权重都以图的形式给出的感知器或多层感知器,还需要图的更新规则。为了在图上定义更高级的运算,未来还需要在图论的基础上对运算做更多的理论研究。
