基于数据挖掘的专门用途英语(ESP)测试自动评分
2021-11-01薛慧娟刘敏
薛慧娟, 刘敏
(1.陕西铁路工程职业技术学院 基础课部, 陕西 渭南 714000; 2.陕西理工大学 数学与计算机科学学院, 陕西 汉中 723001)
0 引言
随着改革开放的不断深入,我国对外贸易规模不断提高。国内外的各种社会交流也逐年增长,这些都离不开我国对英语教育事业的大力支持。但是,随着竞争的不断加剧,社会对复合型人才的需求越来越多。企业要求这些人才不仅要具有扎实的专业知识,还需要具备熟练的英语表达能力,例如专业领域的术语沟通等。专门用途英语(ESP)因此应运而生[1-3]。不同于普通英语,ESP教学侧重在真实语境中灵活运用语言达到交际目的,因此口语能力相当重要。
虽然教学形式得到了多样化的发展,但是现阶段ESP的口语教学还处在人工判定阶段。需要教师花费大量的时间和精力进行各种主观性测试,导致工作效率无法有效提高,特别是大规模的ESP测试场景[4]。目前,随着人工智能技术的兴起和发展,基于各种人工智能算法的英语测试自动评分技术开始逐渐被提出[5-8]。例如,魏扬威等[8]提出结合语言学特征和自编码器的英语作文自动评分,取得了很好的预测效果和鲁棒性。李婷等[9]提出了一种集中趋势自适应增强的英语作文评分算法,解决了过拟合问题,相比人工评分该算法的误差均小于20%。但是可以看出,目前已提出的英语自动评分技术均仅从软件或者算法方面进行研究,因此实时性较差且无法应用于ESP口语测试。
为了有效解决ESP口语测试的自动评分,就必须从硬件上对评分系统进行整体设计。由于ARM9系列平台在实时数据采集和传输方面具有功耗低、便携性、成本低和性能强等优势,武晓燕等[10]设计了基于ARM的语音识别及控制系统,为ESP口语测试的自动评分研究提供了思路。
因此,在上述研究的基础上,本文提出一种基于数据挖掘和嵌入式ARM设备的英语口语自动评分系统。在硬件方面采用基于三星S3C6410芯片微处理器、UDA1341TS音频编解码器和以太网接口的ARM开发板,能够实现音频信号的实时采集并上传。调用科大讯飞API接口实现音频文件转换生成文本答案。对识别出的文本答案进行聚类特征提取,并采用关联规则数据挖掘技术进行预测评分。实际测试结果验证该系统的效率较高,其评分性能达到了人工评分的水平。
1 ESP测试自动评分平台设计
1.1 系统硬件设计
为了降低整体系统的成本,提出系统在硬件方面采用基于三星S3C6410芯片微处理器、UDA1341TS音频编解码器和以太网接口的ARM开发板,能够实现音频信号的实时采集并上传。工作系统采用ARM+LINUX架构,支持 LCD 接口和JTAG 调试接口,且体积小、专用性强,系统硬件框图如图1所示。
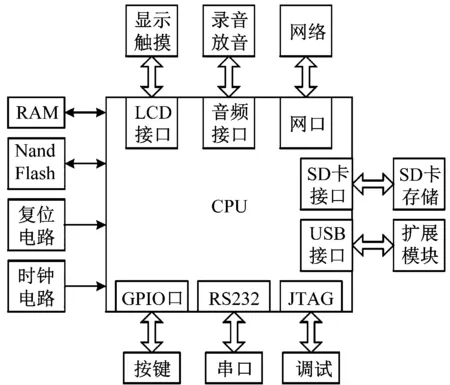
图1 ESP测试自动评分系统的硬件框图
1.2 UDA1341TS音频接口电路设计
本系统采用了飞利浦基于IIS音频总线的UDA134TS,可以外接8/16 bit的立体声。UDA134TS音频芯片的工作电压为1.8 V-3.6 V。S3C6410微处理器通过AC-Link 数字接口对UDA134TS音频芯片进行功能控制,如图2所示。
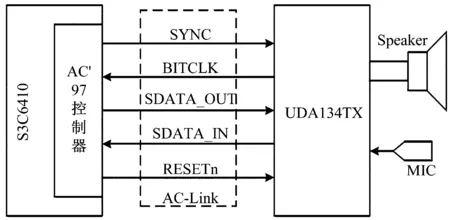
图2 AC-Link 数字接口硬件框图
音频芯片UDA134TS与S3C6410微处理器的连接电路以及外围电路,如图3所示。
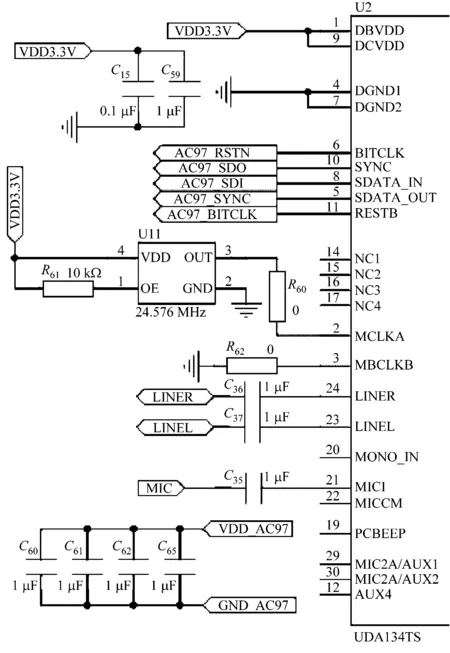
图3 音频接口部分电路
ARM开发板的音频相关电路有两个3.3 V输入电源,为音频芯片UDA134TS供电,如图4所示。
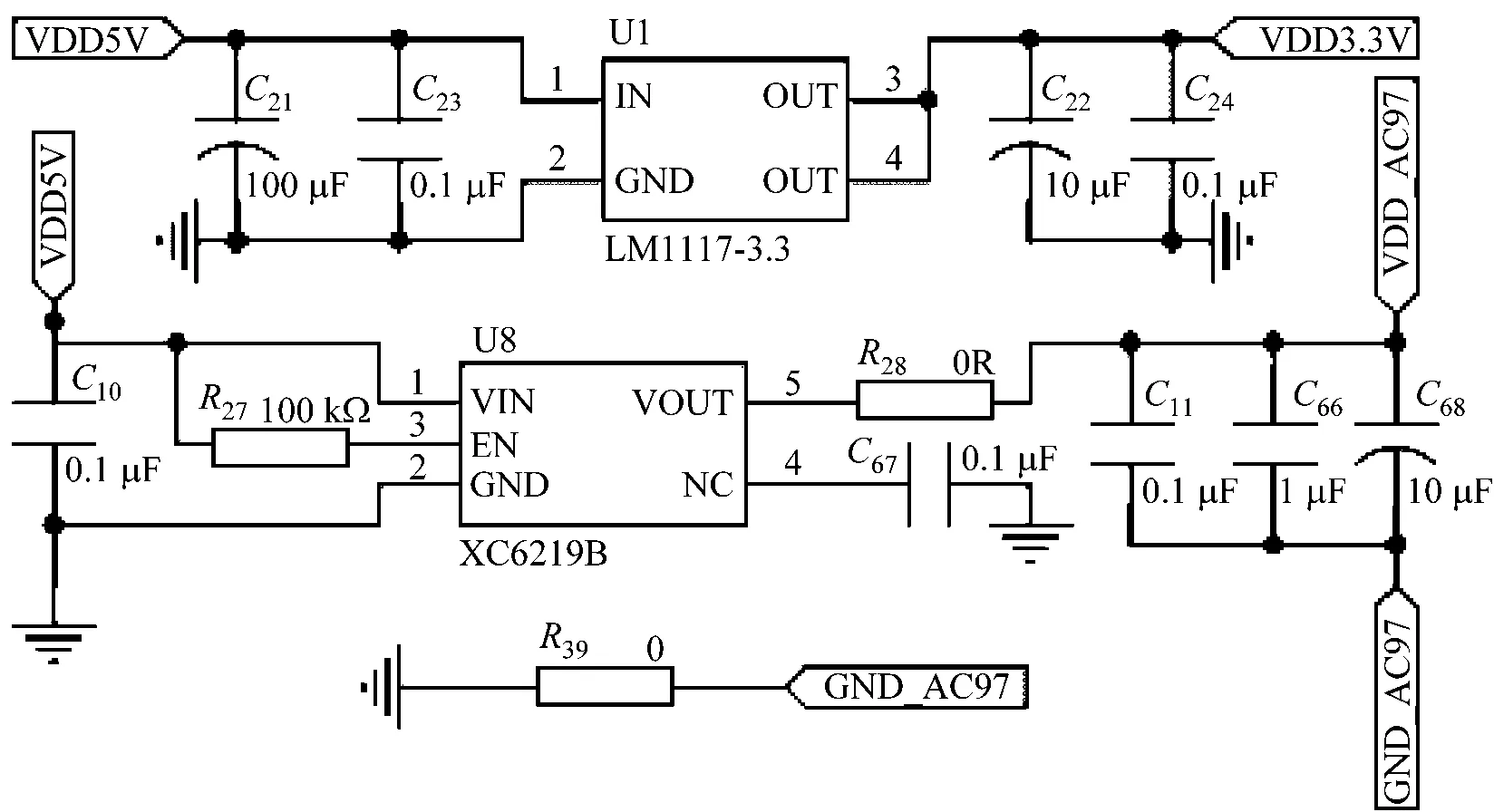
图4 音频接口电源电路
1.3 系统的软件实现
在ARM开发板上需要通过交叉编辑构建开发环境,安装Linux内核、根文件系统配置和加载相关驱动程序。Linux 系统选用的是 Ubuntu 12.04,需要下载到开发板上运行、验证程序,交叉开发模式如图5所示。
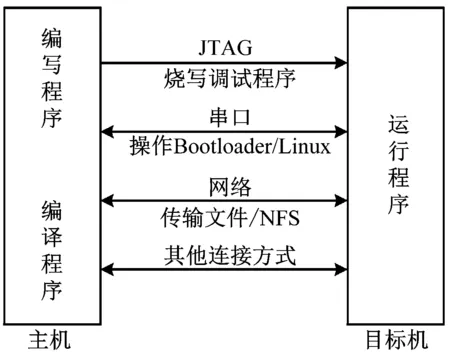
图5 交叉开发模式
在临时环境变量配置成功后,通过执行$ct-ng menuconfig命令打开Linux的图形配置界面。然后编译并安装arm-linux-gcc 4.8.4交叉编译工具链。
音频芯片UDA134TS电路不断采集语音信息,并由IIS总线接口输入各个缓冲区中。用户程序可以从当前缓冲区存储空间直接读取数据音频模块的语音信号。
2 自动评分功能的实现
通过ARM开发板采集ESP测试中用户语音信息后,通过以太网口上传到PC端生成音频文件。然后调用科大讯飞API接口(语音听写接口)实现音频文件的转写,生成英语文本答案。
2.1 聚类后的特征提取
为了对英语文本答案的内容进行准确表征,本文将英语文本的词向量进行K-means聚类分析。词向量的生成借助了词向量计算的工具Word2vec[11-13]。将生成的英语文本答案内容表征成3×k维向量,则聚类分析的步骤如下。
(1) 设Word2vec生成的词向量集合为X={x1,…,xM},其中xi表示英语文本的词向量。
(2) 随机初始化k个聚类中心,u1,u2,…,uk∈Rn。
(3) 对xi的类型结果进行计算,为式(1)。
(1)
(4) 然后对聚类中心进行调整,为式(2)。
(2)
式中,j∈[1,k]。
(5) 判断聚类中心是否不发生变化,是的话就结束聚类,否则跳转到步骤(2)继续执行。
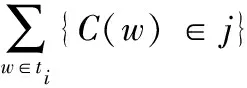
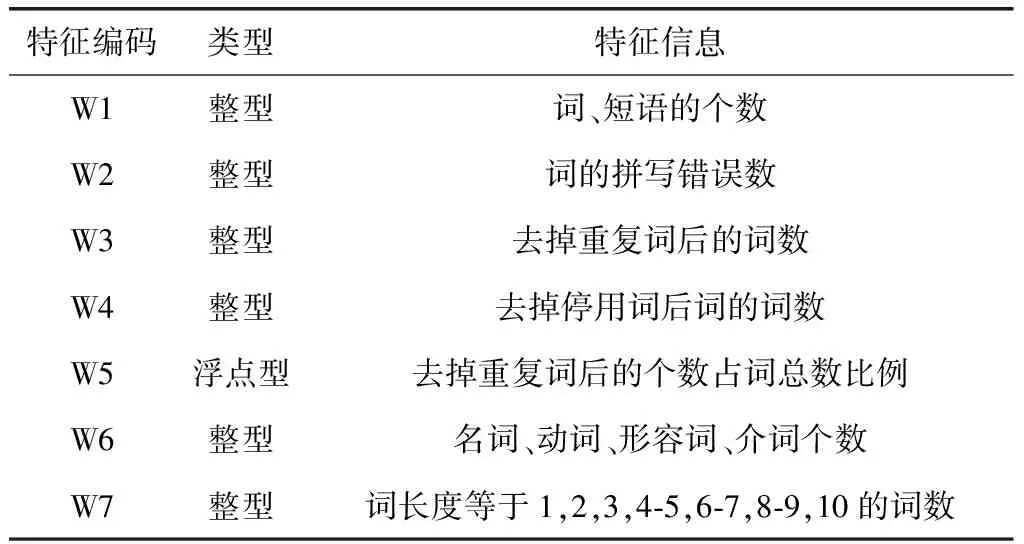
表1 词法特征
2.2 关联规则数据挖掘
在特征构建好后,将采用FP_Growth关联规则挖掘算法[14]应用于英语文本评分的预测任务。令I={i1,i2,…,id}是特征数据中所有项的集合,而T={t1,t2,…,tN}是所有事务的集合。每个事务ti包含的项集都是I的子集。
在关联分析中,支持度(support)和置信度(confidence)的具体表示方式为式(3)、式(4)。
(3)
(4)
式中,N表示事务的数量。
英语文本评分的支持度计算方式如式(5)。
s=|{x|x∈D,rulei∈x}|
(5)
其中,D表示训练数据集;rulei表示D的规则。在关联分析中集合是被视为项集(itemset)。
基于FP_Growth关联规则挖掘的英语文本评分预测的核心步骤是构建FP-tree树节点,以便减少所需频繁项集的数量。事务型数据的示例如表2所示。

表2 事务型数据
FP_tree树的节点机构如图6所示。
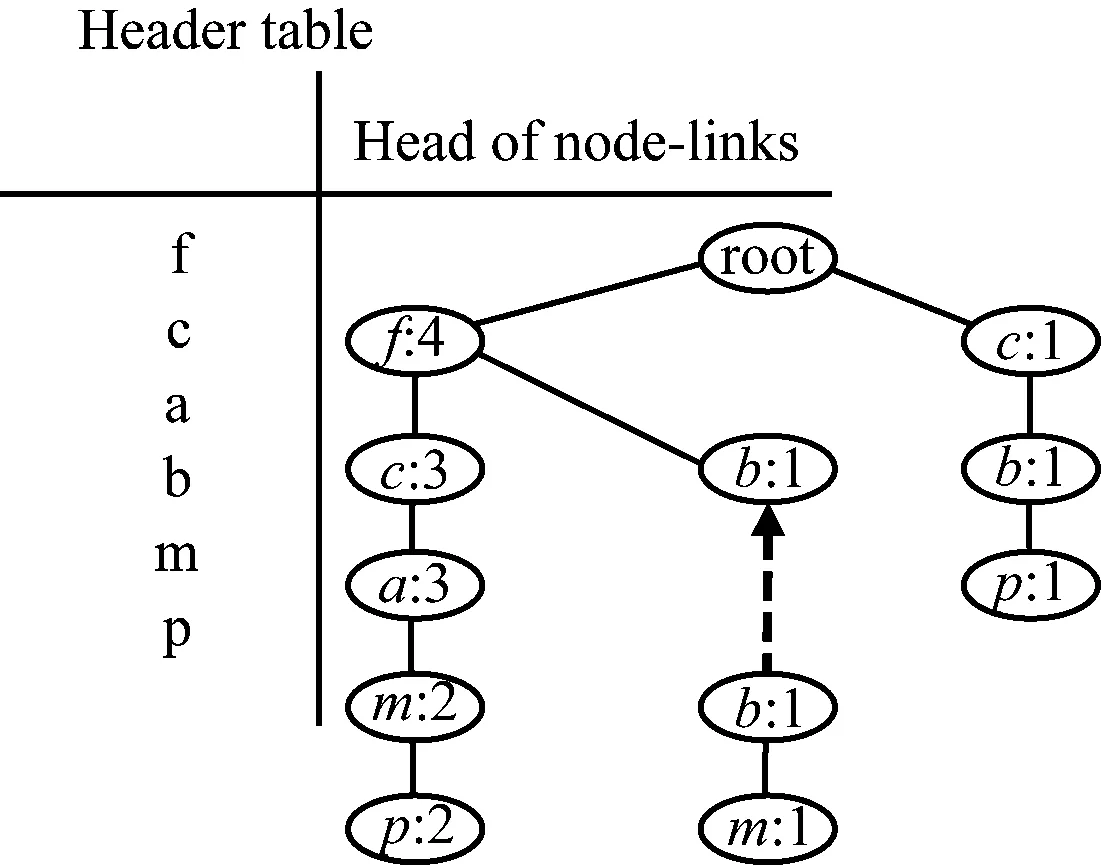
图6 FP-tree节点
3 实验结果与分析
3.1 实验数据和评估指标
为了验证所提ESP测试自动评分系统的有效性,进行了具体测试。实验数据库为国内高校ESP口语比赛数据集中随机选取的800道简答题。选择一个测试者进行现场ESP口语简答测试,然后分别进行人工评分和音频采集自动评分。PC端系统运行环境配置信息如表3所示。

表3 系统运行环境参数
本文自动评分系统和人工评分均采用二次加权的Kappa值[15]进行量化评估,其计算方式如式(6)。
(6)
其中,Oi,j表示分数同时为i和j的答案的数量(由两个不同的评分人给出);w表示权重,其计算方式如式(7)。
(7)
其中,N表示评分的等级数。Kappa值越大则准确度越高。针对同一个测试者分别进行了5次人工评分和自动评分,其中每次人工评分由3个专家打分并取平均值,每次自动评分也是取3次结果的平均值。
3.2 时间和准确度
利用3.1节中数据集对基于FP_Growth关联规则挖掘算法的ESP测试自动评分系统进行实验,在不同最小支持度情况下系统运行时间结果如图7所示。
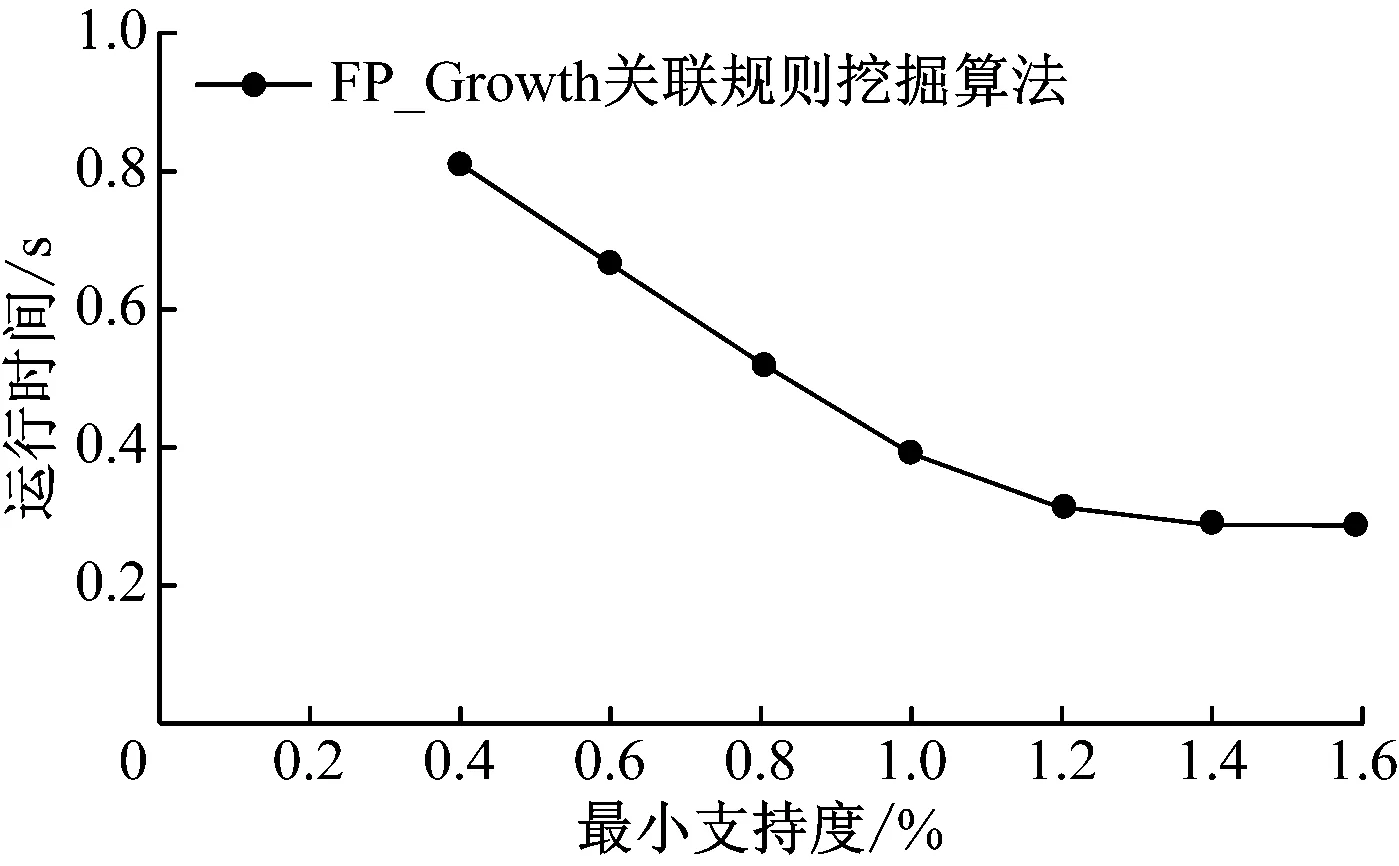
图7 运行时间分析
从图7可以看出,随着最小支持度逐渐增大,自动评分系统的运行时间逐渐减少。但是在支持度较大时,本文提出自动评分方法的评分精度也会有所降低,因此需要做出适当的平衡,本文选取的最小支持度为1.2%。
利用ESP口语比赛数据集和人工评分结果,对本文自动评分方法、传统自动评分方法(VikP)和Adaboost/CT自动评分方法[9]这3种方法进行准确度分析,如表4所示。
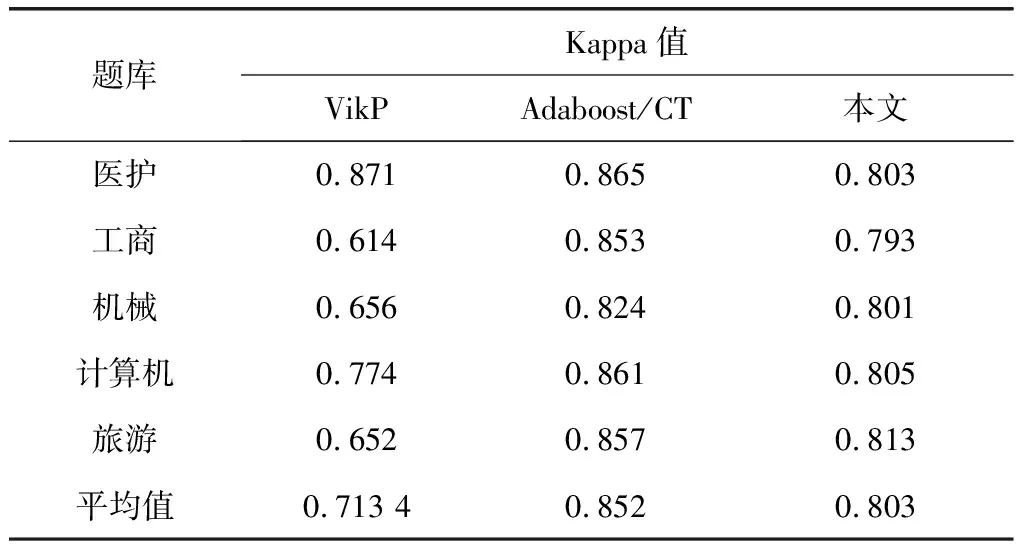
表4 3种自动评分方法的准确度对比
从表4可以看出,对于不同的ESP题库,虽然比Adaboost/CT方法要低,但是本文自动评分方法的准确度明显高于传统的VikP自动评分方法,更接近人工评分的结果。Adaboost/CT方法在准确度方面优于本文方法,这是由于其采用深度学习框架,但也导致其运行时间较长,而本文则是侧重实时性,以便配合嵌入式ARM开发需求。另外,噪声达到45左右时,会对语音测试者的识别造成明显的干扰,识别的精度降低,导致最终的评分性能较差。
4 总结
本文提出一种基于数据挖掘和嵌入式ARM设备的英语口语自动评分系统。采用ARM开发板实现音频信号的实时采集。调用科大讯飞API接口实现音频文件转换生成文本答案,并进行聚类特征提取。采用关联规则数据挖掘技术进行预测评分。实际测试结果验证该系统的可行性。但是语音识别时的噪声干扰对整体性能有一定的影响,降噪问题将是后续工作重点。
