数据驱动跟驰模型综述
2021-10-30贺正冰徐瑞康谢东繁宗芳钟任新
贺正冰,徐瑞康,谢东繁,宗芳,钟任新
(1.北京工业大学,交通工程北京重点实验室,北京100124;2.北京交通大学,交通系统科学与工程研究院,北京100044;3.吉林大学,交通学院,长春130022;4.中山大学,智能工程学院,广州510006)
0 引言
车辆跟驰模型刻画了同一车道前后相邻车辆间的相互作用关系以及行驶状态变化趋势,是最基本的微观驾驶行为模型之一。跟驰模型是交通流理论的核心问题之一,吸引了来自交通工程学、心理学、车辆工程等诸多领域学者的广泛关注,取得了丰硕的理论与实践成果。
传统跟驰模型通常运用动力学方法研究前车(引导车辆)运动状态变化对后车(跟驰车辆)运动状态的影响,通过定量分析车道上各个“引导车-跟驰车”的车辆对的动态特性认识交通流运行特征,揭示交通拥堵、交通振荡等交通现象的形成与演化机理。在以往的研究中,研究者大多借助车辆动力学、驾驶人心理学以及数理统计和微积分等传统数学、物理方法构建具有实际物理意义的跟驰模型,这类跟驰模型被称作模型驱动跟驰模型。对于这类跟驰模型,已有学者进行了回顾。BRACKSTONE等[1]于1999年较早的发表了一篇关于跟驰模型的综述文章,总结了经典的Gazis-Herman-Rothery 模型[2]、安全距离(Safety Distance)模型[3]、线性(Linear)模型[4]、生理-心理(Psycho-Physical)模型[5]、基于模糊逻辑(Fuzzy Logic-based)模型[6]等的特征与适用性。HOOGENDOORN等[7],OLSTAM 等[8],PANWAI 等[9]以及TOLEDO[10]分别从微观交通流建模,跟驰模型在仿真软件中的应用,驾驶人的角度总结模型驱动跟驰模型的研究进展。我国学者王殿海等[11]于2012年回顾了跟驰模型的发展历程,将跟驰模型分为交通工程和统计物理两类,从建模思想与理论体系、模型结构、参数标定等方面详细阐述各类模型驱动跟驰模型,指出各类模型的不足之处,并讨论了难点问题。
模型驱动跟驰模型定义严谨且具有严格的推导过程,大多参数具有明确的物理意义。然而,尽管近年相关研究充分考虑了驾驶人驾驶风格、心理和非理性等因素,并取得了一定的成果,但是,由于驾驶行为涉及复杂的人的因素,且不同的车辆性能、道路条件、环境条件等均会显著影响驾驶人行为。因此,将多样化的因素融入数学模型中,势必会增加模型的复杂度,给模型参数标定带来极大的困难。同时,由于标定模型所使用的数据源不尽相同,标定方法与评价指标也有差异,参数标定的结果经常存在较大误差。
随着大数据时代的到来,数据采集技术快速提升,研究者可以获取高精度、大样本、瞬时车辆运动数据,数据驱动跟驰模型应运而生。数据驱动跟驰模型,是以真实的车辆行驶数据为基础,利用数据科学与机器学习等理论和方法,通过样本数据的训练、学习、迭代、进化,挖掘跟驰行为的内在规律。针对数据驱动跟驰模型,王殿海等[11]在跟驰模型研究进展中总结为模糊逻辑和人工神经网络两类跟驰模型。近年来,信息技术和数据技术迅猛发展,机器学习等相关领域取得了突破性成果,亟需对最新数据驱动跟驰模型成果进行系统性梳理。另外,杨海龙等[12]在跟驰模型综述中介绍了数据驱动跟驰模型进展并展望未来发展趋势,但由于只是跟驰模型综述的一部分,对于数据驱动跟驰模型本身的系统性与深入性分析不足。本文聚焦数据驱动跟驰模型,并从数据来源、模型输入与输出、模型验证3个对数据驱动跟驰模型最重要的方面深入梳理相关研究,评述研究现状,展望发展趋势。
1 数据驱动跟驰模型简介
近20年的两项科技进步极大推动了数据驱动跟驰模型的诞生与进步。首先,颠覆世界科技的深度学习的诞生,解决了数据驱动模型的“工具”问题;其次,高精度、大样本车辆轨迹数据的出现,解决了数据驱动模型的“原料”问题。本文以深度学习的出现为界,分类综述基于神经网络、支持向量回归、K 近邻这3 大传统机器学习方法的数据驱动跟驰模型和基于深度学习的数据驱动跟驰模型;介绍部分数据与模型混合驱动跟驰模型;并渗透式总结车辆轨迹数据的应用。
1.1 基于传统机器学习方法的数据驱动跟驰模型
1.1.1 基于神经网络的跟驰模型
神经网络是一种仿照人类大脑结构建立的网络模型,将人脑神经元抽象成不同的节点,并按照不同的连接方式组成不同的网络。神经网络起源于20 世纪40年代,兴起于20 世纪80年代,是持续20 余年的人工智能领域研究热点。随着神经网络的兴起,KEHTARNAVAZ 等[13]于1998年提出基于时延前反馈神经网络的跟驰模型,通过输入人工驾驶车辆行驶数据训练神经网络,并通过实车实验测试跟驰效果,很好地证实了神经网络应用于车辆跟驰,尤其是自动驾驶车辆跟驰的可行性。随后,我国学者贾洪飞等[14]、徐学明等[16]以及国外学者MA[15]、PANWEI 等[17]分别从不同角度,例如,神经网络结构、输入输出、数据源等开展研究,提出不同的基于神经网络的跟驰模型。文献[13]给出实车实验测试跟驰情景,如图1所示。

图1 搭载神经网络模型的自动驾驶车辆及其实车跟驰测试情景[13]Fig.1 Autonomous vehicle equipped with proposed neural network-based car-following model and its real-world car-following tests[13]
1.1.2 基于支持向量回归的跟驰模型
支持向量回归是在支持向量机基础上考虑了回归问题,理论上较人工神经网络有更强的数据学习能力和泛化能力。为研究车辆跟驰过程的非对称性及其对交通流演化的影响,WEI等[18]提出一种基于支持向量回归的跟驰模型,从微观层面讨论走停波的时滞现象,并在宏观层面再现了不同的拥堵传播模式。ZHANG等[19]将道路条件引入自动驾驶车辆的驾驶决策,以支持向量机回归为基础,采用加权混合核函数和粒子群优化算法,设计了适用于自动驾驶汽车的驾驶决策模型。文献[18]给出基于支持向量机回归的跟驰模型结构,如图2 所示,图中,K(⋅∙)为核函数,X 和X′为样本,ω 和b 为回归模型参数。
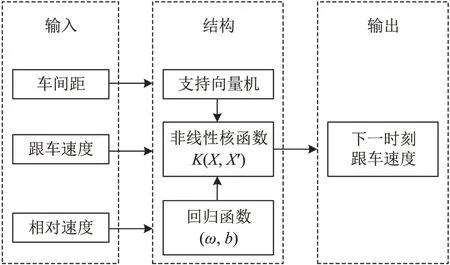
图2 基于支持向量回归的跟驰模型[18]Fig.2 Framework of Support Vector Regression-based carfollowing model[18]
1.1.3 基于K近邻的跟驰模型
作为最经典的机器学习算法之一,K 近邻有着简单而强大的特点。基于“面对同样的驾驶情景(或局势),驾驶人往往表现出相似的驾驶行为”的假设,HE 等[20]通过搜索历史车辆轨迹数据库,匹配相似的K 个历史驾驶场景,得到最可能的驾驶行为,作为模型输出,得到基于K 近邻的数据驱动跟驰模型。相较于结构完全不透明的其他机器学习方法,基于K 近邻的跟驰模型有着更贴近驾驶行为的建模假设和更加清晰易懂的建模思想。文献[20]给出基于K 近邻的跟驰模型建模思路,如图3所示。
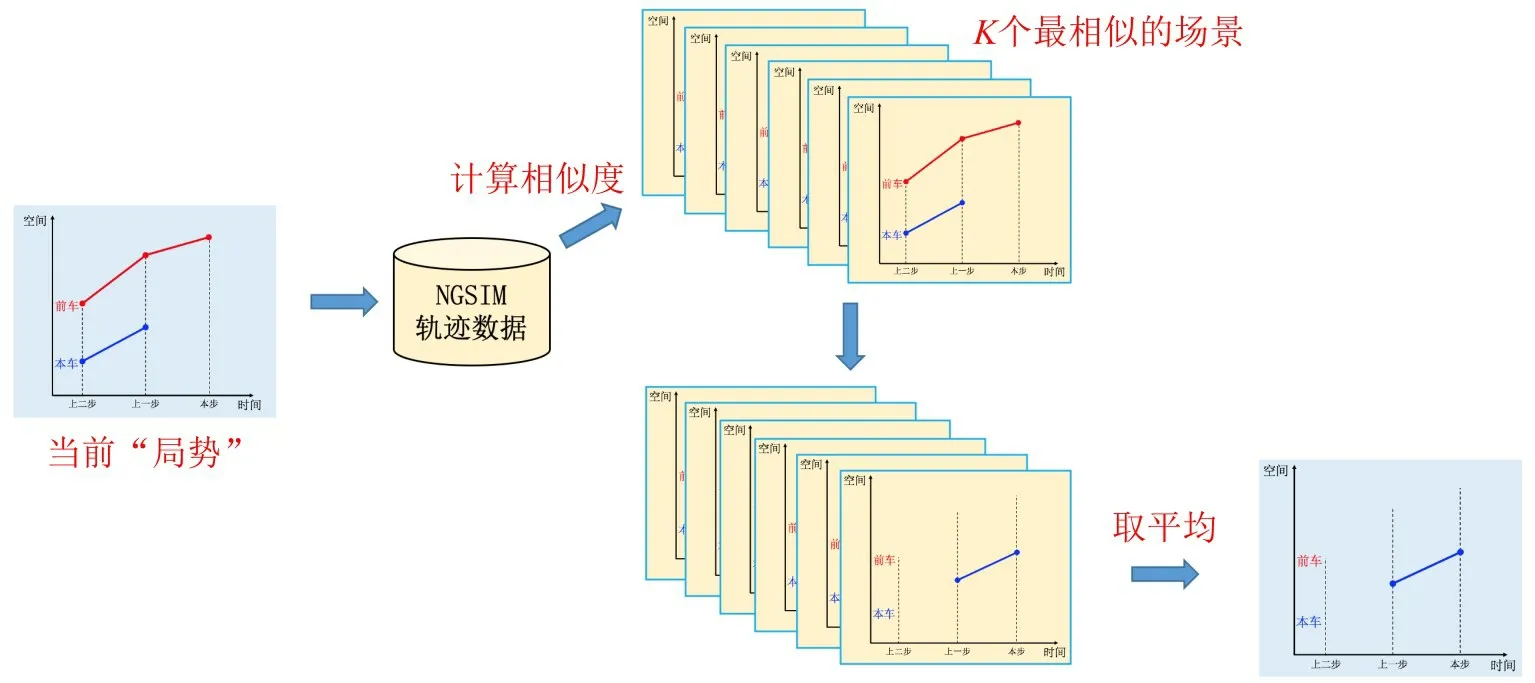
图3 基于K近邻的跟驰模型建模思路Fig.3 Modelling logic of K-Nearest Neighbor-based car-following model
1.2 基于深度学习的数据驱动跟驰模型
典型的深度学习模型就是很深层的神经网络[32]。相较于传统神经网络模型,深度学习模型通常具有多个隐层(通常有5~6 层,甚至10 多层的隐层节点)以及相应的数量巨大的神经元连接权、阈值等参数。常见的深度学习方法有:卷积神经网络(Convolutional Neural Network)、深度信念神经网络(Deep Brief Neural Network)、递归神经网络(Recurrent Neural Network)和长短期记忆神经网络(Long Short-Term Memory Neural Network)等。在近10年里,深度学习模型取得了巨大成功,甚至影响了整个世界科学,因此,逐渐成为机器学习领域一个独立分支。
同样,深度学习的快速发展亦引起了交通流研究者的广泛关注,各种基于深度学习的跟驰模型在过去5年集中出现。ZHOU 等[21]于2017年提出基于递归神经网络的车辆跟驰模型,递归神经网络内置机制将连续历史时间序列数据作为输入,包含前车和后车的动态数据。递归神经网络通过预测数据序列,实现输入序列长度调整。通过数据验证,该模型在预测跟驰车辆的轨迹方面表现良好,能够准确捕捉和预测走停交通波现象。但是该模型最多仅考虑了近2 s 的历史数据,相较于之后的长短期记忆网络模型是偏短的。
针对“浅层”神经网络较难处理连续时刻上的车辆速度、速度差和位置差等多元数据的问题,WANG等[22]利用长短期记忆网络中参数少、更易训练和使用的门控循环单元模型,学习车辆跟驰行为,在输入历史时间序列数据后,直接输出下一时刻速度预测值,并通过模型对比,说明模型的有效性。随后,WANG 等[23]以走停波的时滞现象为目标,验证车辆驾驶过程中驾驶人长记忆效应的重要性,说明长短期记忆网络在车辆跟驰行为建模上的适用性。同时期,HUANG 等[24]基于长短期记忆网络建立跟驰模型,重点捕获驾驶人在控制车辆加速与减速过程中所表现出来的非对称性特征,研究与非对称驾驶行为密切相关的时滞现象和驾驶人的不完美驾驶行为等,说明了长记忆效应的重要性。此后,LIN 等[25]从队列生成角度分析传统训练方法中导致时间误差和空间误差传播的原因,提出改进采样机制和互联的长短期记忆网络结构,克服跟驰模型中时间误差和空间误差传播问题,提高跟驰行为预测精度。最近,MA 等[26]考虑反应延迟在驾驶过程中的重要作用,在长短期记忆网络之上加入多序列层,构成基于多序列对多序列(Sequence to Sequence)的跟驰模型。将连接向量传递到长短期记忆网络单元,多步加速度。通过对比,该模型展现出比仅仅基于长短期记忆网络的跟驰模型更好的跟驰行为预测效果。文献[24]给出基于长短期记忆网络的跟驰模型结构,如图4 所示,图中,t 为时间,v 为速度,Δx 为车间距,Δv 为速度差,Δx′和为输出,h 代表LSTM结构的输出门。
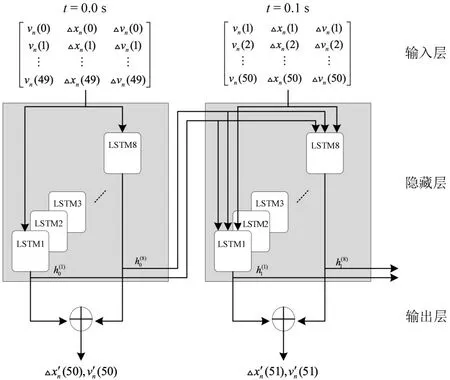
图4 基于长短期记忆网络的跟驰模型结构[24]Fig.4 Schematic structure of Long Short-Term Memory Neural Network-based car-following model[24]
除了长短期记忆网络,深度强化学习(Deep Reinforcement Learning)和生成对抗模仿网络(Generative Adversarial Imitation Learning)等更新、更先进的深度学习模型已应用到跟驰模型中。例如,ZHU 等[27]将历史驾驶数据输入模拟环境,通过基于奖励函数的试错交互学习,获得最佳策略,即以和人类相似的方式从绝对速度、相对速度、车间距以及加速度中学习跟驰行为。测试表明,该模型的车间距误差低于一些典型模型,包括智能驾驶人模型(Intelligent Driver Model)、基于局部加权回归模型、基于神经网络模型。
ZHOU 等[28]提出一种基于生成对抗模仿学习的跟车模型,该模型无需指定奖励便可从实际驾驶人驾车行为中学习驾驶策略,通过将门控循环神经网络(Gated Recurrent Neural Network)整合到奖励函数,赋予模型挖掘历史信息的能力。交叉验证结果表明,与智能驾驶人模型和基于递归神经网络的跟驰模型相比,能够更准确地再现跟车轨迹和驾驶人风格。
1.3 模型与数据混合驱动的跟驰模型
受限于数据驱动方法本身的局限性,数据驱动跟驰模型往往存在泛化能力差(即对于数据库中不存在状态,往往无法准确估计)等问题。而受限于数学公式本身有限的表达能力,模型驱动跟驰模型通常无法准确刻画驾驶人行为等复杂因素。为了取长补短,有学者将两者融合,提出兼具两者优点的模型与数据混合驱动的跟驰模型。
基于线性组合预测理论,丁点点等[29]将Gipps模型和神经网络跟驰模型结合,建立兼具两者优点(Gipps模型的优点为安全;神经网络模型的优点是准确)的模型与数据混合驱动的跟驰模型。通过控制神经网络和Gipps 模型的权重,实现控制预测速度的准确性和安全性的目的。
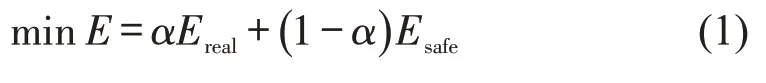
式中:E 为综合真实值(Ereal)和安全目标值(Esafe)的组合目标函数(速度);α 为权重参数。类似地,罗颖等[30]利用线性组合预测理论,建立基于智能驾驶人模型与径向基函数神经网络(Radial Basis Function Neural Network)的混合跟驰模型。
LI 等[31]通过自适应卡尔曼滤波(Adaptive Kalman Fusion)融合标定后的智能驾驶人模型和具有良好驾驶行为预测能力的长短期记忆网络,提出混合长短期记忆网络与智能驾驶人模型的混合跟驰模型。
综合上述,数据驱动跟驰模型相关文献、数据源、模型输入输出、模型评价与验证如表1所示。
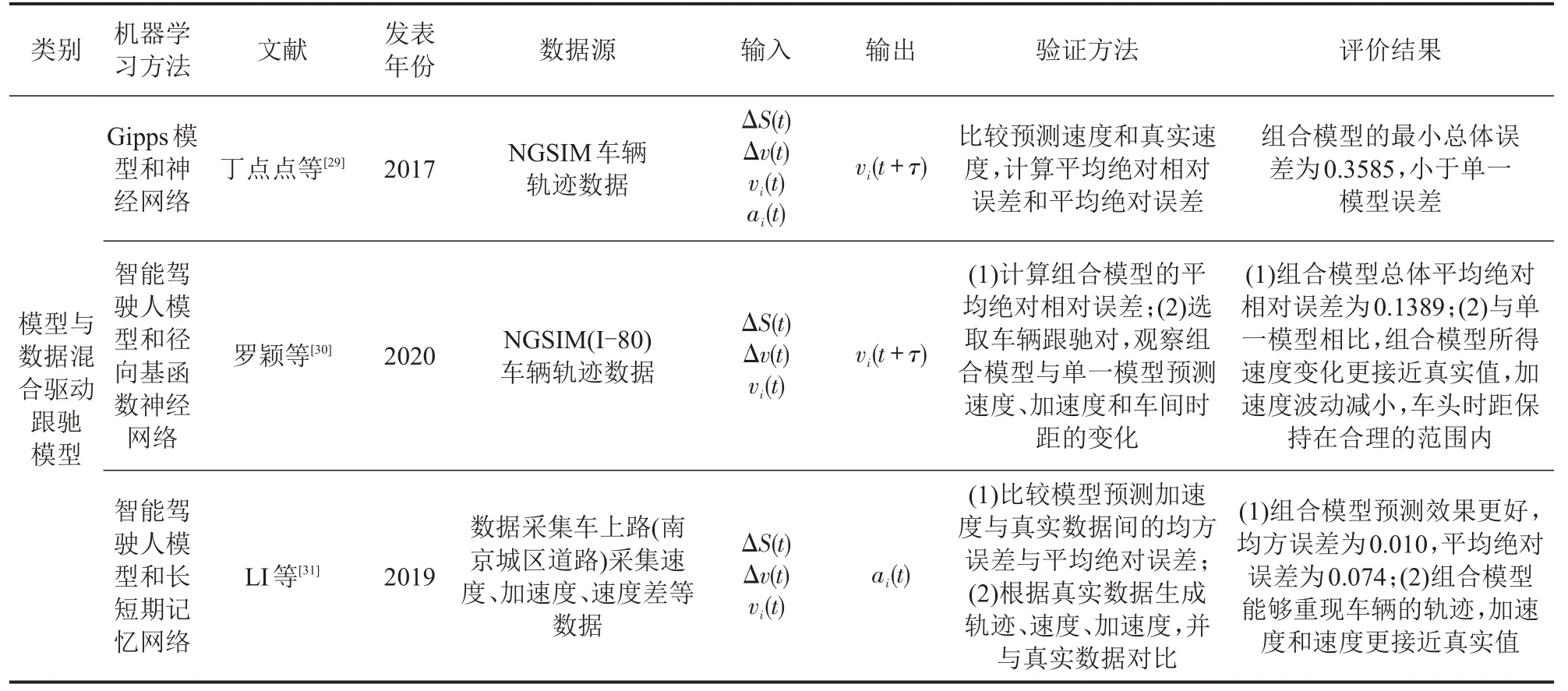
表1 续表
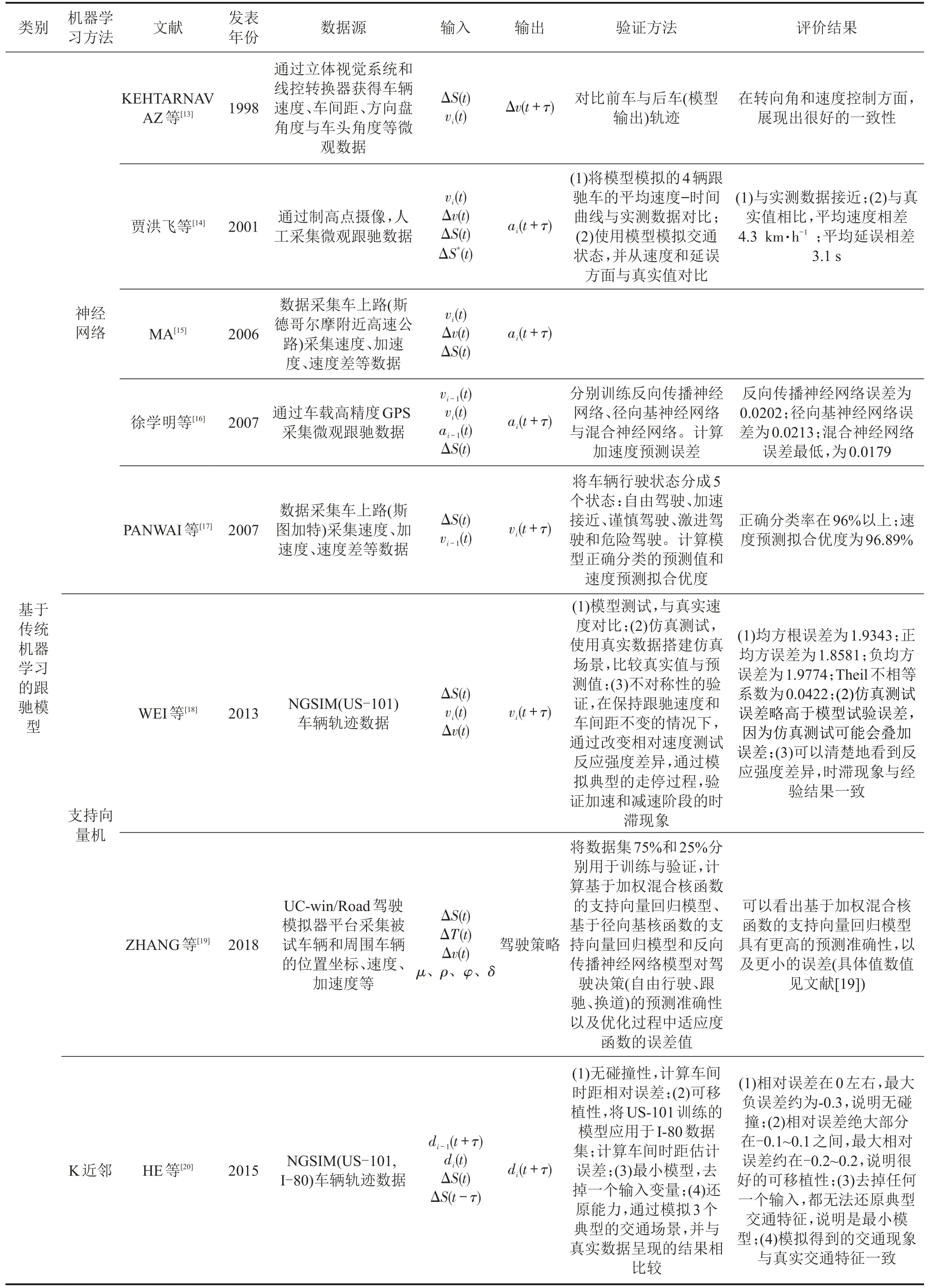
表1 数据驱动跟驰模型相关文献、数据源、模型输入输出、模型评价与验证Table 1 Summary of data-driven car-following models:literature,data source,input and output,evaluation and validation
2 数据驱动跟驰模型的数据源
从表1 可以看出,Next Generation Simulation(NGSIM)高精度车辆轨迹数据[33-34]的出现极大的改变了数据驱动跟驰模型的研究。在2006年NGSIM轨迹数据出现之前,受限于缺少大规模时空轨迹数据,研究者通常使用在高处架设摄像机和人工视频标定的办法[14],或使用车载设备实车上路[13,15-17]等手段获取车辆运动数据。显然,这些采集方式很难为数据驱动方法提供模型训练所需的大量微观车辆行驶数据。
NGSIM 轨迹数据出现后,便成为各数据驱动跟驰模型的首选,使用率约占表1 中文献的80%。从简单的K 近邻[20]、支持向量回归[18]到各种深度学习跟驰模型[21-26,28],均通过NGSIM 轨迹数据实现了自身理想的模型训练与测试。
尽管NGSIM轨迹数据极大的满足了各种模型的需要,但NGSIM 轨迹数据的代表性问题不容忽视。NGSIM轨迹数据仅来自于美国US-101和I-80两条高速公路数百米路段的交通拥堵数据,总持续时间约为2 h,这些数据在多大程度上可以代表其他路段上甚至是其他国家的驾驶行为,是值得探讨的,也直接影响了数据驱动模型的泛化能力。关于泛化能力,由于数据的限制,目前的讨论不多。NGSIM框架内一个折中的办法是使用一段路数据训练模型(例如,US-101 数据),使用另一段路的数据验证模型(例如,I-80数据)[20,35]。
随着无人机的民用化和高精度视频采集技术的出现,近年出现了开源高精度车辆轨迹数据,例如:德国的HighD数据库(https://www.highd-dataset.com)包括了采集于德国高速公路长度为420 m的4个观测路段的60 段轨迹数据。相比于NGSIM 数据,其优点是更大的样本量、更高的数据准确性等。但是,需要注意的是整个数据集包含较大比例的卡车并且处于拥堵状态的轨迹较少。日本的ZenTraffic 数据库(https://zen-traffic-data.net),包含了2 段空间长度为1.6 km 和2 km,时间长度约为10 h的大时空车辆轨迹数据,并且包含较大量的拥堵状态轨迹,是目前可用于交通流研究的理想数据集。此外,包含有多国多场景(高速公路、城市道路、环岛等) 高精度轨迹数据和地图的INTERACTION 数据库(http://interaction-dataset.com)和我国东南大学的无人机视频轨迹数据库(http://seutraffic.com)等也是值得关注的新数据集。这些高精度轨迹数据的出现,有助于解决NGSIM轨迹数据代表性的问题,同时,也对重新测试现有模型的泛化能力提出了新的机遇与挑战。
3 数据驱动跟驰模型的输入与输出
传统模型驱动的跟驰模型多以目标车(i)及其前车(i-1)的瞬时车辆状态(例如,瞬时位置和速度等)作为模型输入(自变量),以目标车辆的加速度或速度为模型输出(因变量),即
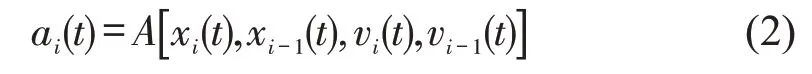
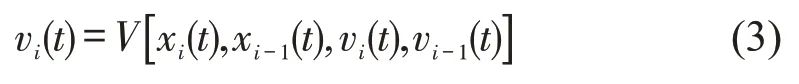
说明了影响目标车驾驶行为的最直接因素是目标车与前车的瞬时状态;其中,A(⋅)和V(⋅)分别为加速度函数和速度函数。
从表1中可以发现,绝大多数数据驱动跟驰模型并未突破这一框架,主要输入是瞬时参数,即车间距ΔS(t)、车间时距ΔT(t)、速度差Δv(t)、加速度a(t)、速度v(t)、位置x(t)等;主要输出量为目标车辆的瞬时加速度a(t)与速度v(t+τ)。欣喜的是,借助于深度学习更强大的变量处理能力(例如,长短期记忆神经网络对时间序列的考虑),部分数据驱动跟驰模型考虑了车辆历史驾驶行为[22,25-26,28]或道路条件参数[19],并且取得了理想的效果,充分展示了深度学习方法的优越性。
尽管如此,仍存在3个问题值得思考:
第一,如何考虑更多驾驶行为相关变量。这里涉及到深度学习架构设计和数据采集两个因素。尤其是数据采集方面,如何进一步挖掘高精度车辆轨迹数据,将车辆横向位置、车长等琐碎信息引入模型训练,值得思考。此外,尽管高精度车辆轨迹数据不断涌现,但并非是真实驾驶过程中驾驶人观察到的全部信息。因此,有必要探索新的数据源。自然驾驶数据[27]和自动驾驶车辆数据具有较大的潜力弥补这个不足。
第二,是否有必要考虑更多驾驶行为变量。尽管深度学习方法强大,无限引入所有变量并不是科学研究方式。因此,哪些是影响驾驶行为最关键的变量[36],如何构造最小化模型[20],应该是数据驱动跟驰模型需要认真思考的问题。
第三,现有输入输出是否可替换。众所周知,交通流宏观、微观变量间存在很强的关联性[37]。那么,目前的数据驱动跟驰模型是否对与其关联的其他输入输出有效?这一问题与模型的敏感性直接相关,对输入、输出变量不敏感的机器学习方法意味着更好的模型性能。
4 数据驱动跟驰模型的测试与验证
从表1中发现,目前数据驱动跟驰模型测试与验证方法主要分为比较预测精度和测试交通特征还原能力两类。前者通常使用均方误差、平均绝对误差、均方根百分比误差等误差计算指标,比较模型在速度、加速度、车间距等关键参数上的预测能力。后者以重要交通特征(例如,走停波速度、时滞现象、非对称驾驶行为等)为目标,重点考察模型还原交通流特征方面的表现。
目前,数据驱动跟驰模型测试与验证较为普遍的存在3个问题:
第一,测试不充分。有的研究仅仅通过一辆跟驰车的全局预测误差评价模型好坏,例如,图5(a),却忽略了整个微观跟驰轨迹中,不同位置对宏观交通特征的影响是不同的。以图6 中车辆经历的走停波为例,车辆减速、加速的时间与强度才是决定走停波性质的关键点,相比之下,其他位置的精度对整个交通特征的影响较为有限。如果仅仅使用一个全局预测值,很可能将局部关键点的预测误差掩盖。此外,进行车队跟驰测试时,车队长度不够也会影响测试的充分性。例如,图5(b)中只展示了前车后面十几辆车的跟驰情况,之后走停波是收敛还是扩散,很难判断。较好的方式是应用所提跟驰模型持续几十分钟、包括上千辆车的大规模交通演化测试,如图5(c)所示,可以有效的检验模型在各种场景下的预测能力。
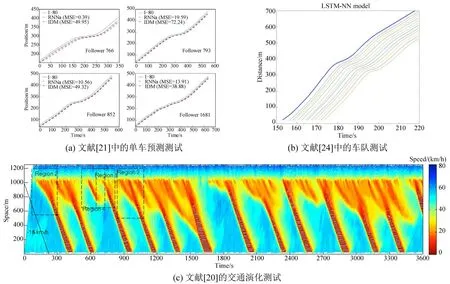
图5 现有文献中的数据驱动跟驰模型验证Fig.5 Validations of data-driven car-following models in existing literature
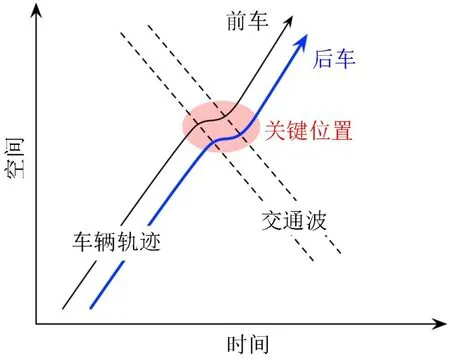
图6 交通流演化关键区域Fig.6 Critical place for traffic evolution
第二,对比不完整。例如,研究提出AB组合方法,然而在模型测试阶段,仅仅与独立A 或B 的预测结果比较;或者,将所提的基于深度学习的跟驰模型与模型驱动跟驰模型(例如,智能驾驶人模型),或者与基于传统机器学习的跟驰模型(例如,基于神经网络的跟驰模型)对比。不难想象,AB的组合方法,一般都会好于A或B的独立方法(例如,多序列对多序列加长短期记忆神经网络会好于单独的长短期记忆神经网络);更新更先进的机器学习方法通常会带来更准确的结果(例如,长短期记忆神经网络会比递归神经网络模型好)。因此,更有说服力的做法是将AB组合方法与另一种最新的同等级跟驰模型对比(例如,将多序列对多序列加长短期记忆神经网络与生成对抗模型或者深度强化学习模型对比),最好是最近两年文献中被充分检验过的模型进行对比。
第三,缺少统一的测试集和测试标准。尽管NGSIM 数据的出现很好地解决了数据存在性问题,但仍然没有一套统一的数据驱动跟驰模型测试方法和测试集。事实上,目前80%以上的数据驱动跟驰模型是通过NGSIM 数据来训练和验证的,距离提出一套基于NGSIM数据的模型测试集和测试标准并不遥远。究其原因,可能并不在于理论或技术,而是缺少影响整个学术圈的权威,即目前的研究还是百家争鸣,缺少一锤定音的权威工作;并且提出测试集和测试标准工作本身琐碎且缺少原创性,愿意深耕的学者不多。因此,呼吁有影响力的团队或机构牵头,组织学者开展更为细致的文献梳理、方法再现与比较工作,确定一套全面、准确的测试集和测试标准。
5 结论
数据驱动跟驰模型的发展迄今经历了两次高潮,伴随着神经网络复苏的基于神经网络的数据驱动跟驰模型(约在1998—2007年)以及深度学习热潮推动下的基于深度学习的数据驱动跟驰模型(约为2017年至今)。同时,高精度车辆轨迹数据集的出现,也极大的推动了数据驱动跟驰模型的进步。
不难发现,两次高潮均是机器学习领域快速发展的产物。但是,目前数据驱动跟驰模型研究多是“方法应用”,对交通机理和现象解释的“本质挖掘”相对较少。关于应用机器学习方法解决某领域内问题的相关研究,一直存在着新颖性争议,即直接采用现有的机器学习模型或组装多个现有模型研究某领域(例如,交通领域)问题,是否具有新颖性。相较于计算机领域对方法的追逐,交通领域更应该关注交通的本质问题与机理,才是交通专业价值与知识的体现。
从神经网络、K 近邻到深度学习、深度强化学习,数据驱动跟驰模型的内核越来越复杂。但是,对于跟驰行为本身,模型是否越复杂越好,不妨从跟驰模型的目的去思考这个问题[38]。如果跟驰模型是为交通流仿真服务,实现交通推演与基本交通特征再现,显然,非常细微的驾驶人行为不会有重要影响,因此,不必使用“功能强大”的深度学习模型。相比之下,如果以服务自动驾驶、实现车辆上路运行为目的,应用深度学习模型,必须充分考虑数量巨大且变化多样的复杂因素。因此,提出数据驱动跟驰模型的目的对于方法的选择尤为重要。
最后,根据要解释的驾驶行为特征,选择在这方面具有优势的机器学习模型或者通过建立混合模型实现优势互补,是数据驱动跟驰模型成功的关键。例如,长短期记忆神经网络可以有效捕获驾驶行为中后续行为对前序行为的依赖性,从而成功地还原跟驰过程中驾驶人不对称的加速、减速过程以及走停波相应的时滞现象。希望在未来,可以见到更多充满交通智慧的数据驱动跟驰模型。
