基于知识图谱的问答系统研究与应用
2021-10-28施运梅
袁 博,施运梅,张 乐
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101; 2.北京信息科技大学 计算机学院,北京 100101)
0 引 言
伴随着现代信息技术的飞速发展,互联网从无到有,从相对匮乏的知识储量到现如今的包罗万象。互联网的强大之处归根结底在其知识库的庞大,数以万亿计的知识呈指数爆炸式增长,同时利用网络获取知识的人数也呈飞速上升的态势。据CNNIC《2020年第45次中国互联网络发展状况统计报告》数据显示,截至2020年3月,国内网民规模为9.04亿,互联网普及率达64.5%。但信息爆炸和网民人数的增多带来的问题也愈发凸显,人们该如何从海量的知识中获取自己想要的部分成为急需解决的问题。
人们在互联网获取答案的方式大多依赖搜索引擎,但传统的搜索引擎存在针对性低、搜索结果过多等不足,它返回给用户的结果只是若干个网页以及列表,而不是用户想了解的具体的答案。如何有针对性地获取自己想要的答案变得越来越重要。在这样的背景下,问答系统依托现代科技以飞快的速度发展。
随着问答系统的出现,获取用户想要的知识变得便捷,且相较于传统的搜索引擎而言,其具有速度快、针对性较高的特点。而在传统的问答系统发展的过程中,也出现了一些新的问题。传统的问答系统因为知识库结构化程度低,缺乏足够的高质量知识,具有单一性与局限性的缺陷。KBQA的出现填补了这一缺陷,实现了问答结果的多样化,提升了问答结果满意度。
通过一系列的调研显示,KBQA在现阶段得到了学者的广泛关注,并在业界取得了良好的应用效果。其在多个领域都发挥了巨大的作用。文中将梳理基于知识图谱的智能问答系统的发展脉络,对其中涉及的概念、方法与技术应用展开深入的探讨和分析。
1 知识图谱与问答系统
本节主要介绍知识图谱与问答系统的历史发展与其相关的知识库以及其技术应用领域等。
1.1 知识图谱
知识图谱的前身是知识库,知识库是一种结构化的数据形式。Wordnet[1]是提出最早的知识库,其在众多结构化知识中添加了六种语义信息,为之后知识图谱提出“实体-关系-实体”提供了理论基础。之后相继出现的freebase[2]、hownet(中文知网词库)等跨语言知识库更加完善了数据量与数据结构。其中freebase知识库是基于Wikipedia(现在公认最大的在线百科全书)创立的拥有超过5 800多万实体的超大型知识库,也是公开可以得到的最大的知识库之一。
知识图谱,是一种通过将数学、图形学、信息技术和关系映射等结合在一起的现代化、高度结构化的知识理论。对于知识图谱来说,其本质为语义网络的知识库。语义网[3]早在1968年被提出,起初是用来为自然语言处理数据建立一种新的组织方式。语义网标明了各数据之间的联系,它是融合语义信息表达来创建的网络。而知识图谱则是经过漫长时间的发展与技术的不断优化,衍生出来的语义网2.0。过去人们往往聚焦于对个体事物的分析与理解,而知识图谱则破除了这一界限,将其引申向每件事物的联系。在知识图谱中,通常将事物定义为“实体”。知识图谱将它们之间联系起来,形成一个纵横交错的“网”。用一句话来讲,知识图谱是以若干“实体-关系-实体”构成的三元组组成的集合。
Google公司在2012年5月提出知识图谱概念的同时发布了知识图谱Google Knowledge Graph[4]。当用户对问题进行搜索时,除得到搜索结果外,还可显示与其相关的人、物或者事件。它一改往日对关键字匹配处理的方式进行问答反馈,而是将问题中的“实体”识别出来,联合知识网络寻找与其“实体”相关联的“实体”,从而进行推荐与显示。
除Google Knowledge Graph外,常用的大型知识图谱还有DBpedia,YAGO3等。在中文领域,有开放式知识图谱平台OpenKG[5],其中包含了15大类的开放型知识图谱。
对于知识图谱,从其出现至今已经在各领域取得了较为成熟的应用。例如将知识图谱集成在推荐系统中,可以更有效地匹配用户习惯进行推荐;将知识图谱集成在犯罪检测领域,可以分析嫌疑人之间关系来获取更多的线索;将知识图谱运用在问答系统中,可以将数据结构化以便更快地匹配各个实体及关系之间的映射关系。知识图谱应用于生产生活的各个方面,具有很大的研究价值。
1.2 问答系统
公认最早的问答系统理论是二十世纪六十年代由艾伦·麦席森·图灵提出的著名的图灵测试[6]。在之后数十年的发展中,问答系统也随着人工智能的兴衰而更迭,涌现出一批具有代表性的问答系统。
二十世纪六、七十年代代表其技术应用的系统有Baseball[7]系统与Lunar[8]系统等。Baseball系统是最早应用在实际生活中的问答系统之一,旨在回答限定棒球领域的事实性问题;Lunar系统则是为了分析月球中矿石成分而开发出的问答系统。两者都可以回答出一些简单的问题,缺点是必须使用固定形式去提问,灵活性极低,且当时受限于匮乏的网络知识资源,其处理数据量很小,并不能大规模应用。
二十世纪八十年代,因计算语言学的发展,计算机进入语言学时期,研究者将研究点转向如何利用语言学的优势去改进问答系统,在提升准确率的同时降低成本。其阶段的代表系统为Unix Consultant系统[9]。
二十世纪九十年代末,因为互联网络的发展及数据量的爆炸式增长,出现了基于检索匹配的问答系统。其思路是从用户的自然语言问句中提取核心字,并在文本库或网页中搜索相关的文档。这种方法在一段时间内取得了很好的效果,但仍未解决用户问题多样性以及自然语言复杂性的问题,在数据的质量方面,采用的都是从网页或文档中抽取的非结构化数据,质量参差不齐,导致数据处理效果不尽人意。
直到近年来知识库与知识图谱的出现,将数据和其中的关系整合为一个结构化的系统,优化了数据的质量;同时深度学习飞速发展,使得自然语言处理变得相当便捷,解决了先前两种方法的不足。智能问答系统也由基于文档形式的智能问答转变为基于知识图谱的智能问答,迎来了质的飞跃。
在实际生活应用中还有很多领域也融入集成了问答系统。在电商领域,出现的“自动问答机器人”。如阿里巴巴旗下的淘宝客服机器人,网易游戏旗下的游戏问题自动回复客服等。可以对用户的问题化繁为简,大大提升了效率。在教育领域,出现的可以提供给孩子各种各样的百科知识等的“早教机器人”,可以替代老师的部分职能,节省家长的财力与精力。在医疗领域,出现的可以快速根据临床表现回答病症的问答系统等。问答系统涉及诸多应用领域,随着社会发展,如何提升问答系统的效率与准确性也是今后研究的一大热点问题。
2 基于知识图谱的问答系统构建方法
KBQA的含义为基于知识库的问答,知识库有很多种,文中只讨论基于知识图谱知识库的问答方法。现阶段已经有大量针对不同领域的知识图谱的问答系统的研究,在KBQA的各个领域也出现了对其应用方法的相关研究[10-13],这些研究都针对生活中的实际应用,优化解决了生产生活中的诸多问题。
文中对KBQA的构建方法进行了梳理,总体上可以划分为三种方法:(1)基于模板匹配的方法;(2)基于语义解析的方法;(3)基于向量建模的方法。
2.1 基于知识图谱的模板匹配方法
基于模板匹配的方法是智能问答系统中最基本的方法,也是最早提出的方法。基于模板匹配的方法是在二十世纪六十年代提出的,在当时因所有可从网络中获取的数据量极少,且缺少结构化的数据,所以基于模板和规则的匹配问答所面对的数据大多是无规则的文档以及文本。在数据的处理上无法做到统一标准与格式,只能依靠关键字匹配的方式来返回答案,准确率并不可观。直到知识库以及知识图谱的出现,基于模板匹配方法的处理对象由散乱的文档、文本转变为结构化、逻辑严密的知识图谱,解决了模板匹配数据量少,匹配难度大等缺点。
基于模板匹配的方法拥有相较于其他方法显著的优点,其问答成功率高,响应速度快。缺点则是需要人工构筑大量的模板来保证和用户问题的匹配,一旦用户的问题中没有相对应的模板,则会导致返回答案的不准确。这也是制约其发展的最大问题。
2.1.1 模板匹配方法的处理流程
模板匹配的方法是将用户的自然语言转化为三元组形式,根据三元组寻找与之相匹配的SPARQL查询模板,再根据SPARQL查询模板与知识库中的RDF数据相匹配获得最终的答案。具体流程如图1所示。

图1 基于模板匹配方法的具体流程
在问答系统发展的前期,使用这样的流程可以轻松地处理用户使用指定格式提出的简单问题。然而在问答系统的发展中,人们已经不满足于系统只能回答简单的问题,用户的问题趋向于复杂化,使用更为复杂的自然语言查询成为一种急需解决的问题。
2012年Christina Unger等人[14]提出一种经典的基于模板匹配的改进方法,解决了以往用户只能用规定格式的查询语言查询的弊端,使用户可以用自然语言去查询问题。2016年Cui W等人[15]利用机器学习方法对数以百万计的问答对进行训练,使系统自动生成模板,再通过后续的用户意图识别进行分类、匹配,最终形成答案。
2018年Google公司发布了Bert算法[16],该算法也是截至目前在NLP领域里表现最好的算法之一,在NLP领域里刷新了诸多记录。在问答领域也有学者融入了Bert模型来解决现有的问题。2019年Aiting Liu等人[17]融入Bert预训练模型训练系统生成模板,解决了人工创造模板以及算法需要大规模训练数据量的缺点,且相较之前最好的方法正确率提高了一个百分点。
2.1.2 模板匹配中的意图识别
对于问答系统来说,意图识别阶段是必不可少的环节。如果用户意图分辨不明确,会直接导致后续成功率下降。可以分三种方法来对用户的意图进行判定,分别为:(1)基于辞典及模板的规则方法;(2)基于特征统计的分类方法;(3)基于神经网络的方法。每一种方法都有各自的优缺点。
基于辞典及模板的规则方法需要人为构筑领域词典,对于限定领域的意图识别任务来说,具有相当好的效果,正确率非常高,但相应地,因为其需要的人工成本太高,且需要相当准确的专业词典,导致它的可移植性较差。一旦需要更换领域,就需要重新构筑模板及词典。
基于特征统计的分类方法,其主要思路是将既定语料进行关键特征的提取,再将语料进行分类,因此该方法实质就是分类问题,利用训练分类器的方法实现了意图分类。常用的模型有朴素贝叶斯模型[18]、支持向量机模型[19]、逻辑回归模型等。
基于神经网络的方法是在深度学习方法成熟的情况下发展而来的,现有的深度学习框架,如百度框架paddlepaddle等也可以很好地解决意图分类的问题,对意图识别也相继出现了其他融入深度学习的算法来提升性能[20-23]。这表明在意图识别领域融入深度学习方法已经是大势所趋。
2.2 基于知识图谱的语义解析方法
基于知识图谱的语义解析方法是一种不依赖于模板的方法,该方法的思路是对用户提出的问句进行归一化语义解析,目的是将其转化为一种可以使知识图谱理解的表示。再对知识图谱的知识进行推理,转化为一种逻辑形式,根据逻辑形式查询知识库得到结果。
2.2.1 语义解析方法的处理流程
基于知识图谱的语义解析方法的步骤可以分为三步,即语句解析→形式匹配→答案生成。其中语句解析这一步是为了使计算机可以理解用户输入的自然语言。对于用户输入的自然语言,句子的结构是由语法及词汇构成的,语句解析的目的是将语法成分以及各词汇的属性关系分离。在对语句解析的步骤中,根据层次的深度,将其分为较浅层次的解析和较深层次的解析。
2.2.2 浅层解析
浅层解析的第一步简单理解就是对语句的分词、清洗等操作。使用传统的LSTM+CRF方法,或是调用现成的jieba分词库都可以实现分词的目的。根据句子的语法将句子结构解析出来,最终形成的实际上是一棵语法解析树,如图2所示。
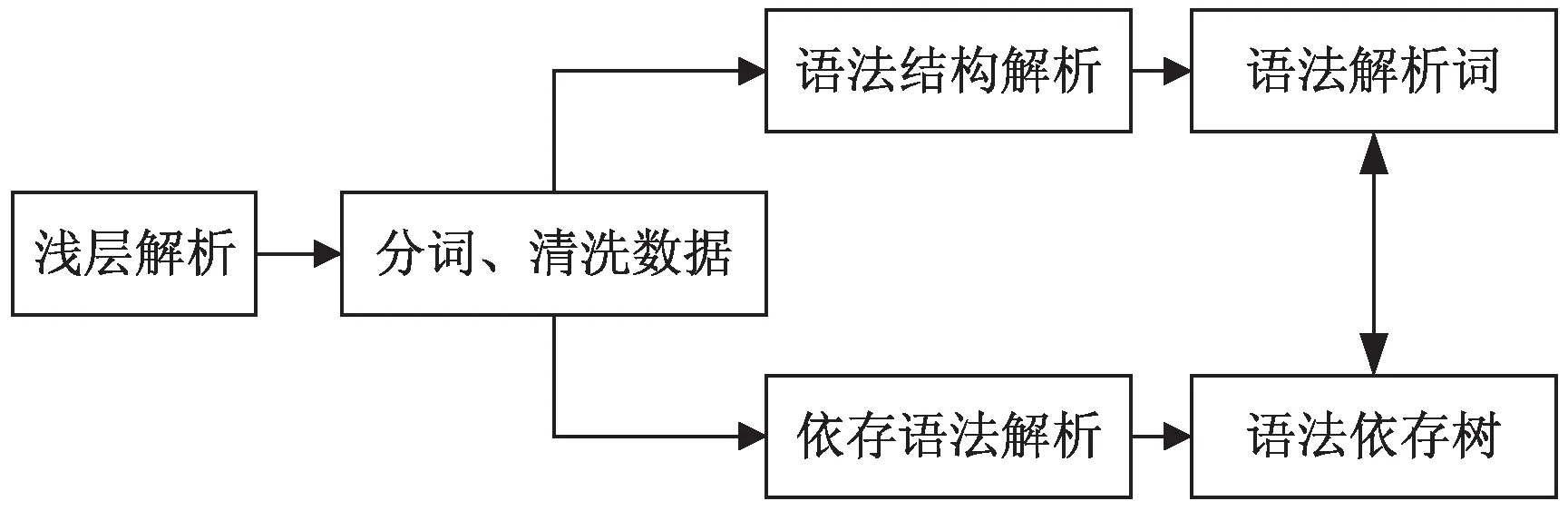
图2 浅层解析示意图
语法解析的方法主要是上下文无关法、考虑词汇的上下文无关语法以及基于概率分布的上下文无关语法等。这些算法大多针对英文语料,对中文语料的适应性并不足。王鹏等人[24]根据中文的结构特点,发现想要在中文领域取得较好的效果,必须考虑中文特性辅助其他算法以提升准确率。国内很多学者都在其基础上针对中文语料进行优化,林颖等人[25]提出句法结构共现,引入上下文信息的方法改进基于概率分布的上下文无关语法,突破了中文库规模小的局限性。
2.2.3 深层解析
浅层次的解析是将句子分离、解析,而深层次的解析着重点转移到了单词的含义或是句子的含义上面。其中需要用到的技术有语义角色标注技术与语义依存解析技术,如图3所示。

图3 深层解析示意图
语义角色标注的实质,是将问题中的实体等与知识图谱中的实体,关系及属性相匹配,将单纯的语句转化为一句带有相应角色的标注。针对语义角色标注技术,国内学者做了大量研究。刘怀军等人[26]针对中文的特点,提出了更有效的新的特征及特征组合。丁金涛等人[27]随后发现特征及特征组合并不是越多效果越好,效果取决于特征的组合,从而进行了优化特征优化组合的方法研究,且取得了较好的效果。
当句子语法被解析出来之后,还需要分析句子各单词之间的相互依存关系,传统的方法为依存句法分析(dependency parsing),其分析的是句子之间的句法结构,然而传统的方法对复杂问句的分析能力不足。刘雄等人[28]为了解决复杂问句的语义解析,在依存句法分析的基础上提出一种复合型问句的分解方法,提升了问句分类的准确性。
依存句法分析主要识别的语法成分的侧重点在句子的“主谓宾”等部分。因为这个特点,这种方法对于介词在句子中的权重作用体现尤为明显。但是很多时候如果谓语、介词等较少,句法依存的方法就会大打折扣。针对这一问题,杜泽宇等人[29]结合了哈工大LTP语义依存分析(semantic dependency analysis)替代了传统的依存句法分析,辅助以word2vec算法进行相似度计算。在电商领域问答系统取得了较好的效果。
2.2.4 检 索
对于语句解析处理完毕之后的自然语言,问答系统需要与知识图谱里的实体关系以及属性进行检索匹配,输出格式化的数据。这一阶段就是检索阶段,其需要利用上一阶段生成的语义解析树根节点中逻辑形式,与知识库中的信息进行检索匹配。
当逻辑形式与知识图谱中的数据匹配完成之后,在答案生成阶段,利用查询语句在知识库中查询答案并返回答案。常用的查询语言为Cypher和SPARQL以及SQL等。
2.3 基于知识图谱的向量建模方法
基于知识图谱的向量建模方法是KBQA系统三大基本方法中的最后一种,该方法的核心思想是将问题与答案都转化为向量形式。利用转化的向量形式来使计算机自动学习、自动从知识库中寻找与“问题向量”相似的“答案向量”。
2.3.1 向量建模方法的处理流程
这一阶段首要任务是需要根据用户输入的问题,找到其中心词汇,根据这个核心词汇找到答案库中一组候选的答案组。在得到用户输入问题与其候选答案组之后,需要将用户输入的问题由高维度降至低维度,将问题与答案都映射到低维空间中(即向量形式),得到其分布式表达。分布式表达是深度学习概念中十分重要的一环,它的含义为利用向量代表实体数据。即词向量或者词嵌入(word embedding),用向量形式来表示一个词在计算机中的具体含义。
在得到问题与答案的分布式表达之后,需要将问题与答案进行匹配,这一阶段需要利用数据集来对分布式表达进行训练,使得其问题与答案之间的相似度尽可能高。最后根据候选答案组中向量表示与用户输入问题表达得到分数最高的返回最终答案。具体流程如图4所示。
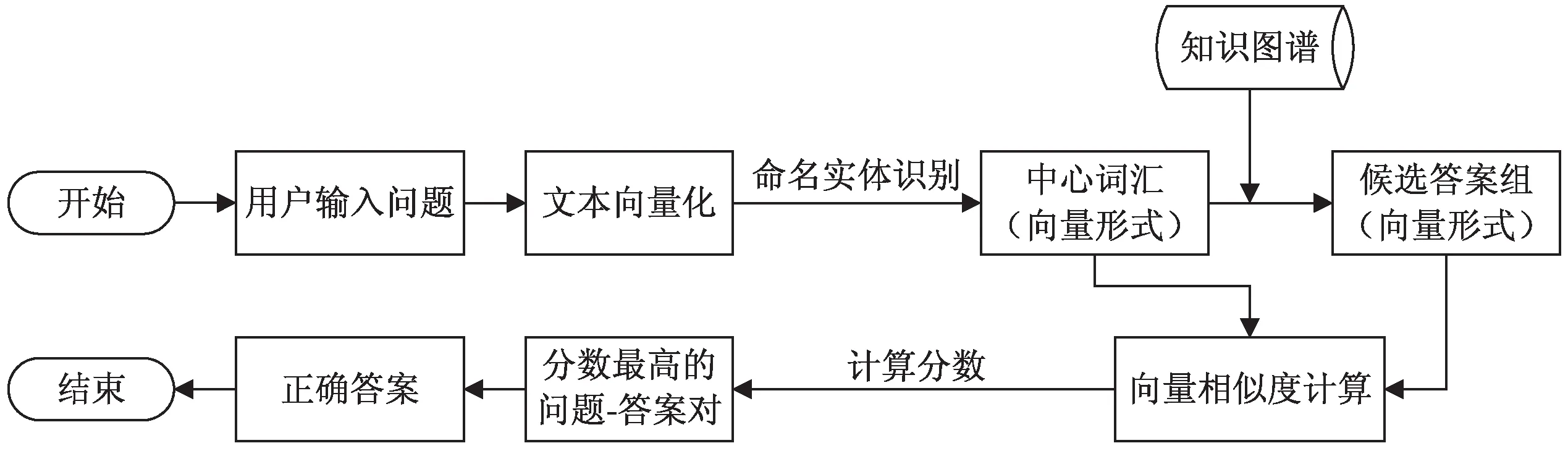
图4 基于向量建模的流程
2.3.2 问题-答案对向量化
在基于向量建模的方法中,最关键的一步是如何将问题与答案转化为向量的形式,在向量化研究的过程中有以下难点:(1)如何让机器明白人类的语言;(2)如何联系上下文进行语义表征;(3)如何解决一词多义问题。
对于将文本向量化,有多种方法可以实现,早期的向量化实现过程中词袋模型(bag-of-words)的应用为主要手段,其中one-hot、TF-IDF、textrank等算法是最简单的文本向量化方法,然而这些方法在语义表达上存在语义鸿沟、语义无法关联上下文等问题。之后相继出现了Word2vec、FastText、GloVe等算法,结合了语境问题实现了文本向量化。然而这些算法仍然无法解决一词多义的问题,为此又出现了基于语言模型的动态表示方法,如ELMo[30]、GPT[31]、BERT,解决了一词多义的问题,即同样的单词在不同的语境下会有不同的向量表示。
在基于向量建模的方法中,Bordes Antoine等人[32]在2014年提出embedding模型,在不借助任何人工干预和提取特征的情况下,利用向量建模以及深度学习训练问题答案对的方式完成问答任务。实验效果超越了之前的方法。2015年,Dong L等人[33]考虑到了语言顺序对词向量向量化的影响,在传统的向量建模方法中融入了卷积神经网络,进行问答性能的提升。同年Bordes A等人[34]融入记忆网络,解决了大样本多数据问答系统效果差的缺陷。Zhang Y等人[35]在2016年联合了知识表示学习和注意力机制来表达出合适的候选答案,解决了表示答案效果差的问题。并在WEBQUESTION数据集[36]上表现出很好的效果。2018年Qu Y等人[37]又在传统的基于向量模型的基础上,提出一种AR-SMCNN模型,利用了CNN与RNN神经网络优化提取信息的精度,解决了之前忽视自然语言原始信息的问题,取得了SimpleQuestion测评上的最优效果。
3 基于知识图谱的问答系统应用
通过对市场上已有的基于知识图谱的问答系统调研可以发现,其在现实生活中的应用非常广泛。有很多典型的产品,各个领域都出现了对其技术的应用。
在语音识别领域应用的问答系统有“Google now”、微软小冰、苹果公司的“Siri”语音问答系统、“Cortana”问答系统、百度公司的对话式人工智能秘书“度秘”等。这些产品方便用户通过语音来获得自己想要得到的答案,具有很强的交互性。
在医疗领域应用的问答系统有“左手医生”、“白狐智能医疗问答”等产品,为患者自查病症、医生查询药方药材等提供了便利。
在电商领域应用的问答系统有“淘宝客服”、“京东客服”、“Amazon”电商网站客服系统等。方便了购买者询问产品详细情况,同时节省了客服的人力,提升了服务质量与速度。
总体上,基于知识图谱的问答系统是现在各行各业应用的焦点,其中需要的技术也是学者们研究的热点问题之一。在基于知识图谱的问答系统应用场景越来越广泛的社会环境下,如何提升技术更好地服务于应用,是其发展的关键。
4 未来与展望
随着人工智能、自然语言理解等技术的进步,未来技术应用的发展趋势已趋向于智能化,问答系统智能化的程度越高,人们从问答系统中获取到的答案就越准确。从问答系统技术应用的角度来看,问答系统及其衍生的设施,诸如聊天机器人、陪伴机器人等都是未来社会不可或缺的部分。问答系统在未来会取代互联网搜索引擎的可能性也非常之大,问答系统或许会成为从互联网获取知识的新途径。
对于一个优秀的问答系统来说,最关键的是它如何尽可能理解问题和如何获取高质量的知识来源。对于高质量的知识来源这一问题来说,知识图谱很好地解决了这一个问题,它提供了高度结构化的知识库。而在问题理解方面,人类更倾向于使用多类型、无规则的自然语言去提出问题,而机器只能识别结构化的问题,如何更好地使机器理解用户的问题,是今后人工智能大背景下基于知识图谱的问答系统需要解决的问题。
虽然深度学习技术现在已经较为成熟,但是深度学习技术的应用也会带来一些问题,比如如何提升深度学习方法的可解释性,如何尽可能减少人工成本等,这些都是需要面临的挑战。基于知识图谱的问答还有很大的优化提升空间。
5 结束语
总体上,从技术应用层面来看,基于知识图谱的问答系统已经渗透于各行各业中,在很多与人们生活息息相关的领域,如金融、医疗、交通、刑侦、电商等,都已经运用得较为成熟。并且在今后的发展中其应用深度会越来越深,涉及领域也会越来越广,具有极大的研究价值。从研究方法层面上来看,在工业实际应用中,使用最多的方法实际上是基于规则与模板匹配方法或基于这种方法的变种。因为其虽然受制于模板质量与人工成本等因素,但其对于问答极高的正确率仍然使它暂时成为各大公司开发项目的首选。融入深度学习的方法还处在研究改进阶段,其方法需要较强的约束条件,不具有普适性,无法大规模投入工业开发使用。但在未来深度学习发展更为成熟以后,因为其对复杂问题,多实体问答等问题的处理具有的先天优势,在三大基本方法中融入深度学习技术提升问答效果也只是时间问题。在现阶段的应用中各个方法之间有其共同点,也有长短优劣,多种技术与算法之间取长补短才是发展KBQA的关键。
