基于申威421的视频解码的向量化并行
2021-10-28张书钦
裴 航,王 磊,王 威,张书钦
(1.中原工学院 计算机学院,河南 郑州 451191; 2.中原工学院 前沿信息技术研究院,河南 郑州 451191)
0 引 言
随着互联网的高速发展以及第五代移动通信技术的到来,人们对多媒体品质的需求日益提升,高清视频的高效编解码成为研究热点。很多处理器平台都研发出相应的扩展部件来增强计算机多媒体数据处理能力。单指令流多数据流(SIMD)[1]结构可以高效地对大规模数据进行并行处理,有效实现应用程序中规整的数据级并行(data level parallelism,DLP),从而提升了处理器的吞吐率,在一定程度上满足了多媒体计算能力需求[2]。Intel公司在Pentium处理器中最早采用了支持MMX[3]的SIMD技术,一直不断升级至现在的AVX2技术。ARM公司推出的Cortex-A系列处理器采用了NEON技术[4]。如今越来越多的厂商都在处理器内集成、升级SIMD扩展部件,很多应用程序都在寻求SIMD并行,以增强移动终端的多媒体处理能力。
申威[5]是国内自主研发的通用处理器,提供256位向量寄存器且包括支持256位向量访存及运算的SIMD扩展指令。对于某些处理器体系结构,SIMD扩展指令允许将原来需要多次装载的内存中地址连续的数据一次性装载到向量寄存器中。使用一条SIMD扩展指令实现对SIMD向量寄存器中所有数据元素的并行处理,这种执行方式非常适合于处理计算密集、数据相关性少的多媒体程序,如音视频编解码[6]。
H.264[7]视频编码格式是目前发展比较成熟的编码格式。常用的开源解码器有JM[8]、T264[9]和FFmpeg[10],目前很多国产平台都对FFmpeg视频解码器针对各个平台特点做了相应的优化。文献[11]针对视频解码时CPU占用率高,专用硬件解码耗时长等问题,研究了飞腾平台上GPU硬件加速视频解码技术,设计了基于VDPAU硬件解码接口的GPU硬件视频解码方案。文献[12]在实现FFmpeg解码器到国产龙芯3B平台的移植的基础上,并通过龙芯3B所支持的向量扩展指令,对FFmpeg解码器的各个关键模块代码进行了向量优化。文献[13]结合飞腾多核DSP同构多核架构以及共享存储的特点,采用面向共享存储系统结构的工业标准Open MP,通过设立并行域以及设置私有变量对解码程序有针对性地进行了并行优化。
文中基于国产自主可控平台申威421,在对H.264解码器的开源程序FFmpeg移植后,H.264视频解码效率低,高分辨率的视频播放不流畅甚至卡顿,严重影响国产平台桌面用户体验,阻碍了申威处理器的市场化进度。针对此现象,文中充分利用了申威SIMD扩展部件对多媒体程序进行向量化并行。H.264解码器性能显著提升,解决了视频播放不流畅问题,推动了国产申威处理器市场化的发展。
1 基于FFmpeg的H.264解码器
H.264是国际标准化组织(ISO)和国际电信联盟(ITU)共同提出的继MPEG4之后的新一代数字视频编解码标准。最大的优势是具有比较高的数据压缩比率,在相同图像质量的条件下,H.264的压缩比是MPEG-2的2倍以上,是MPEG-4的1.5~2倍。H.264视频编解码标准没有明确规定如何实现编解码器,但规定了编码视频比特流的语法和比特流的解码步骤方法[14]。
本研究主要基于FFmpeg的H.264解码器进行优化。FFmpeg是一套基于Linux操作系统的开源编解码解决方案,它集成了音视频录制、格式转换和编解码器,也可在大多数操作系统中编译和使用[15]。它不仅包含各种音频和视频编解码库,还支持基于流媒体的实时流传输。
FFmpeg中H.264解码器的解码流程如图1所示。首先通过函数h264_decode_frame解码一帧图像数据,其中decode_nal_units是用于解码NALU的函数。decode_nal_units首先调用ff_h264_decode_nal判断NALU的类型,然后根据NALU类型的不同调用不同的解析函数和解码函数,解析函数包括解析SPS/PPS/SEI以及slice_head。ff_h264_execute_decode_slices用于解码获取图像信息,ff_h264_execute_decode_slices调用了decode_slice函数,在decode_slice函数中完成了熵解码、变换与量化、宏块解码、环路滤波等解码的细节工作。

图1 H.264解码器解码流程
熵解码部分的功能是读取数据(宏块类型、参考帧、运动矢量、残差等),并按照H.264的语法和语义规则将其分配到H.264解码器中相应的变量中。其中熵解码方面的函数有ff_h264_decode_mb_cabac和ff_h264_decode_mb_cavlc。分别用于解码CABAC编码方式的H.264数据和CAVLC编码方式的H.264数据。
根据熵解码后各宏块的信息,函数hl_decode_mb会根据宏块类型的不同做处理,主要针对帧间或者帧内宏块。如果是帧间预测宏块,调用函数hl_motion_422或者函数hl_motion_420进行四分之一像素运动补偿;如果是帧内预测宏块,就会调用hl_decode_mb_predict_luma进行帧内预测。经过帧内预测或者帧间预测步骤之后,就得到了预测数据。最后hl_decode_mb会调用hl_decode_mb_idct_luma等几个函数对残差数据进行DCT反变换,并将变换后的数据叠加到预测数据上,形成解码后的图像数据。
Decode_slice在完成宏块解码后,调用loop_filter函数进行环路滤波工作。环路滤波主要是为了去除图像变换量化后产生的块状视觉效应。loop_filter函数遍历该行宏块中的每个宏块,并且针对每一个宏块调用ff_h264_filter_mb_fast。函数ff_h264_filter_mb_fast中h264_filter_mb_fast_internal完成一个宏块的环路滤波工作。该函数分别调用filter_mb_edgev或filter_mb_edgeh对亮度垂直或边界进行滤波,和调用filter_mb_edgecv或filter_mb_edgech对色度的垂直或水平边界进行滤波。
2 H.264关键模块的向量化
文中在对H.264解码器关键模块进行向量化并行时首先对热点函数中的循环进行向量化分析,分析循环内是否具有数据相关性、对齐、连续等条件。如果满足向量化分析,使用SIMD指令进行替换。如果不满足,分析是否可以通过循环变换数组重组等方法来满足向量化分析,然后通过内嵌汇编进行向量指令替换。最后对向量化后的程序性能进行测试,如果没有性能提升,继续对下一个循环进行分析。
2.1 热点函数分析
perf是内置于Linux内核源码中的性能剖析工具。基于事件采样和性能事件的原则,它支持处理器和操作系统相关性能指标的性能配置文件,并可用于查找瓶颈和定位热点代码。本研究针对视频序列foreman,使用perf工具列出了H.264解码器在在整个视频解码过程中所占比重较大的热点函数,如表1所示。

表1 H.264解码器热点函数
热点函数为应用程序中耗时较多,执行次数较多的函数,对热点函数进行优化相对来讲性能提升比较明显。通过性能分析工具可以发现热点函数主要集中在宏块解码的帧内预测、运动补偿、环路滤波等模块。上述函数几乎占据整个解码过程的55%,因此对上述函数中的循环做向量化,解码器性能理论上可以得到显著提升。
2.2 热点函数向量化并行
热点函数中h264_qpel系列函数用于对1/4像素内插做运动补偿,其中h264_qpel_lowpass类函数完成了半像素内插函数的初始化工作,主要对2×2、4×4、8×8大小的图像方块通过水平或垂直方向滤波计算半像素。H.264标准采用了一个6抽头的有限脉冲响应滤波器(finite impu1se response,FIR)进行计算,滤波器系数为(1/32,-5/32,5/8,5/8,-5/32,1/32),虽然6抽头滤波器比较复杂,但可以明显改善运动补偿性能[16]。半像素插值计算如图2所示,半像素点(如b,h,m)通过对相应整像素点(图中灰色方块)进行6抽头滤波得出。半像素b的计算可由同一行中的整像素E、F、G、H、I、J得出。计算公式见式(1),其中CLIP用于将取值限幅在0~255。
b=CLIP[(E-5F+20G-20H+5I+J+16)>>5]
(1)

图2 1/2像素插值
对于1/2像素插值计算,由于计算需要像素每行的存储规则,且像素间不存在数据相关性,这种计算密集,复杂度较高的运算十分适合利用SIMD扩展部件对其进行向量计算,使用申威SIMD扩展指令集可以一次性装入一行整像素点。通过向量计算得到每行的1/2像素点,循环8次就可以计算出8×8块的64个1/2像素点。8×8图像块的每行的1/2像素点的SIMD计算如图3所示。
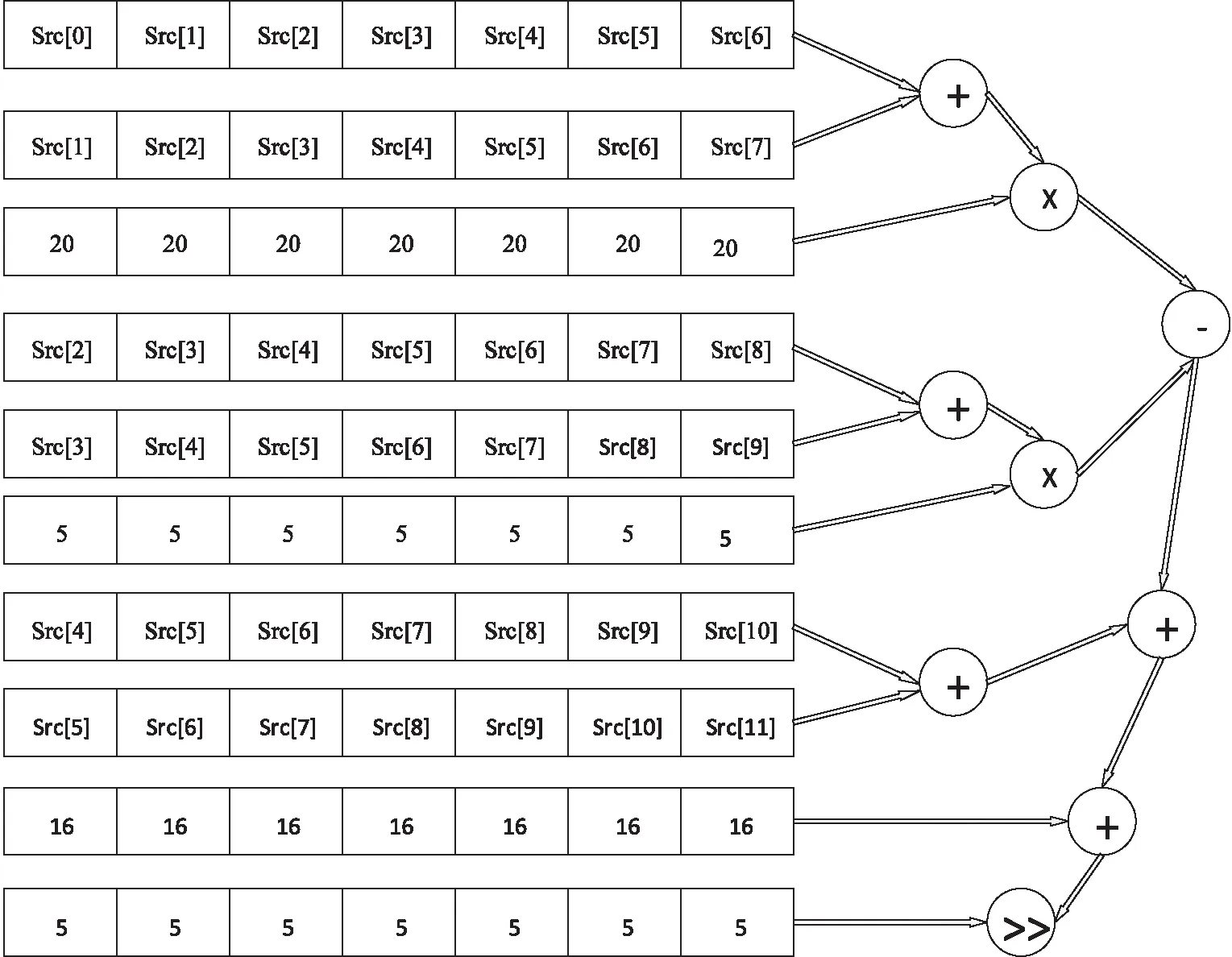
图3 1/2像素插值SIMD计算
申威扩展指令集提供VLDW_U/VSTW_U非对齐装入/存储指令,可以从存储器中取出8个32 bit或32个8 bit元素到256位向量寄存器,并支持不同长度的加/减移位等运算。8 bit的像素可以一次装入32个元素到256位向量寄存器/存储器中,但对于8×8的图像块的1/2像素点的计算,只需使用向量寄存器的64位,每次进行8个元素的运算。函数put_h264_qpel8_h_lowpass优化前和优化后的代码如下所示:
优化前:
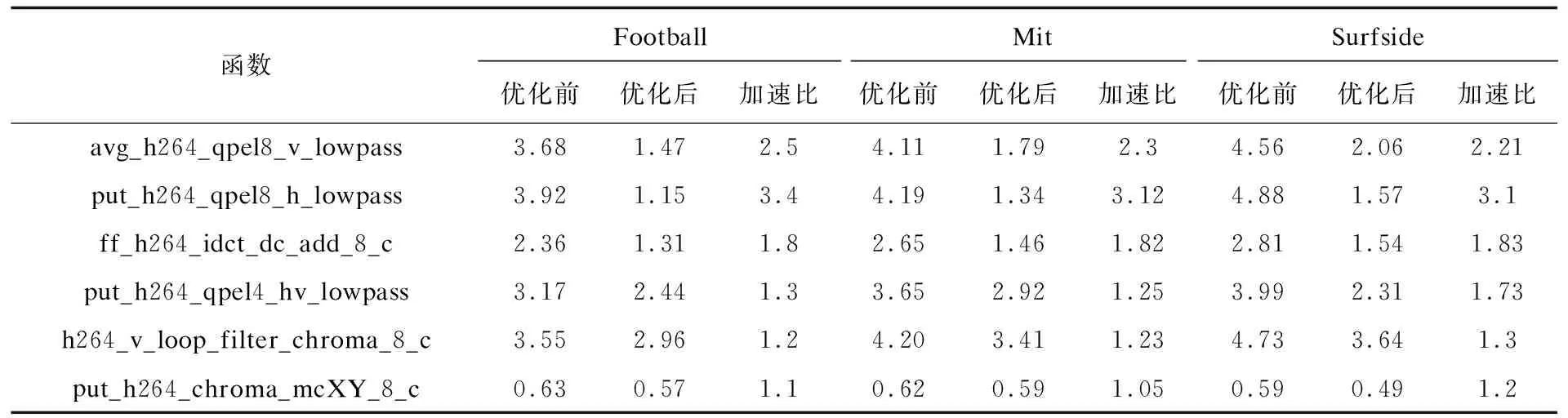
for(i=0; i { dst[0]=CLIP((((src[0]+src[1])*20-(src[-1]+src[2])*5+(src[-2]+src[3]))+16)>>5); dst[1]=CLIP((((src[1]+src[2])*20-(src[0]+src[3])*5+(src[-1]+src[4]))+16)>>5); ...... } 优化后: for(i=0; i { vldw_u $f1,0(a0) vldw_u $f2,0(a1) vldw_u $f3,1(a1) vldw_u $f4,-1(a1) vldw_u $f5,2(a1) vldw_u $f6,-2(a1) vldw_u $f7,3(a1) ldwe $f10,0,(a2) vaddw $f2,$f3,$f2 vsllw $f2,4,$f8; vsllw $f2,2,$f9 vaddw $f8,$f9,$f8 vaddw $f4,$f5,$f4 vsllw $f4,2,$f9 vaddw $f9,$f4,$f9 vsubw $f8,$f9,$f8 vaddw $f6,$f7,$f6 vaddw $f8,$f6,$f8 vaddw $f8,$10,$f8 vsrlw $f8,5,$f8 vstw_u $f8,0(a0) } 首先从存储器中取出以原像素点src[0]为起始的8个整像素点放置向量寄存器中,然后分别与依次扩展1位的连续8个整像素点进行向量运算。其中乘法直接用加法和移位来代替,最后将计算的8个结果分别放置8个目标分像素点,完成一行的分像素点计算。接着增加步长进行下一行的分像素点计算,循环8次完成8×8块的分像素计算。使用申威SIMD指令进行替换,一条SIMD指令可以同时进行8次相同运算,计算出每行的分像素点,有效提升了分像素插值的效率。 对于4×4、2×2块的水平或垂直方向的1/2像素插值计算向量化并行同8×8块计算方法相似,只是4×4块对于每行1/2像素点的计算只能一次进行4个像素点计算。而对于双向预测的1/2像素点的计算更加复杂一些,同样适合使用SIMD指令来进行向量化并行计算1/2插值点。 在H.264关键模块算法中都存在满足向量化分析的循环,对此可以直接进行向量指令替换。经过1/4像素运动补偿的帧间或者帧内预测后,就需要将残差数据进行DCT反变换,DCT系列函数中ff_h264_idct8_dc_add_8c对只有DC系数的8×8矩阵进行整数DCT反变换。最内层循环通过一条向量指令vaddw就可以实现对8×8像素每行与dc系数的累加来代替最内层的8次循环,降低了循环开销。相对比较复杂的4×4整数DCT反变换函数ff_h264_idct_add_8_c,先对每列进行一维整数变换,然后对经过列变换块的每行进行一维整数变换,最后将变换后的残差数据叠加来实现传统整数变换的矩阵乘法。由于数据是以行来存储的,所以使用SIMD扩展指令可以先实现一行元素的整数变换,经过四次向量计算完成整个块的纵向一维整数变换。再对经过纵向一维整数变换的块进行另一维的向量整数变换,最后通过向量指令进行残差数据叠加。而对于环路滤波中h264_loop_filter类函数由于循环内数组访问不连续以及存在控制流,不能直接向量化,需要对数组进行重组,然后进行向量化。 本次实验平台基于国产自主可控平台申威421,操作系统为deepin15.5,编译器为申威自主研发编译器swgcc-5.3.0。实验环境如表2所示,为使测试结果具有代表性,实验分别选取了3组不同分辨率720×486、1 600×960、2 048×1 024的视频序列,视频播放采用FFmpeg组件ffplay。 表2 实验环境 基于移植到申威平台的H.264解码器有很大性能提升。表3表示对各个热点函数向量化与向量化后的性能对比,表4表示3个视频序列在对解码器中关键模块向量化后的性能对比。 表3 各函数向量化前后性能对比 表4 测试视频向量化前后性能对比 通过实验对比,对热点函数中满足向量化分析的循环进行向量指令替换,增加了指令吞吐率,在保证原视频清晰度的基础上,视频解码性能有大幅度提升。其中函数put_h264_qpel8_h_lowpass向量化后加速比达到3.4,而函数put_h264_chroma_mcXY_8_c中由于对未知变量的乘法,需要对系数进行判断再执行移位运算来代替乘法继续向量运算,向量化指令更加复杂,加速比只有1.1。测试的3个视频序列中football的解码性能最高有35.3%的提升。并且CPU占用率明显降低,释放了CPU资源,2 048×1 024分辨率高的视频播放流畅度更高,提高了国产申威平台用户的多媒体视觉体验。 本次研究针对H.264解码器中的热点函数使用SIMD扩展部件来进行向量化计算,提升解码器性能。但是由于并没有充分利用到256位向量寄存器,向量重组等技术存在一定开销,向量化效果并没有达到理想的提升。接下来将会针对热点函数中由于数组非对齐及存在数据依赖等程序进行重点分析,充分利用256位向量寄存器,更深层次地挖掘数据的并行性。随着高性能计算的发展,SIMD扩展部件仍然是程序加速的重要手段,SIMD扩展部件结构简单、功耗低、加速效果明显,不需要增加通信以及cache和内存的开销,在多媒体领域,数字信号处理中都起着关键作用。而如何充分利用SIMD扩展部件更深层次地挖掘数据并行性,提升程序性能,是长久的工作重心。3 实 验
3.1 实验环境

3.2 实验结果分析

4 结束语
