动态信任衰减和信息匹配的混合推荐算法
2021-10-28任静霞武志峰
任静霞,武志峰
(天津职业技术师范大学 信息技术工程学院,天津 300222)
0 引 言
推荐系统[1]是大数据背景下商品飞速增长、信息爆炸所萌生的个性化定制服务,它在用户和物品数量剧增的情况下,根据历史数据为用户和物品间建立连接关系,进而预测未来的连接,主要解决评分预测和行为预测问题[2],即预测连接强度和是否会产生连接问题。推荐系统作为一种信息过滤系统能够帮助使用者快速、准确地找到有用的信息,发现自己的潜在兴趣和需求,为企业带来利益的同时,也为用户提供便捷的服务,得到了各大电子商务网站的广泛应用。
从20世纪90年代开始,推荐系统持续受到社会关注,各种推荐算法层出不穷,却各有利弊。如协同过滤推荐算法[3]具有较好的推荐效果,但不适用于稀疏矩阵也无法处理新用户或新物品出现时的冷启动问题,而矩阵分解算法[4]能够解决冷启动问题,但可解释性却较差等,研究者们始终致力于追求更高质量、更具扩展性的推荐算法。贾彭慧等人[5]通过用户之间的交叉性、信任性以及趋同性因子加权来挑选近邻;原福永等人[6]通过划分时间序列,考察不同时间段用户的点击率来为用户找到近邻;刘珊珊[7]通过用户访问同一项目的次数确定用户偏好并推荐相似项目;孙光福等人[8]通过基于时序行为的消费网络图来找到近邻;肖春景等人[9]采用时序信息通过随机游走进行近邻选择;邓存彬等人[10]通过改进SVD++算法[11]划分时间段来考察用户、物品偏置实现动态协同过滤;郝雅娴等人[12]将用户近邻与项目近邻评分信息融合为一个评分矩阵,挖掘目标用户对目标项目的评分信息。文中提出了一种基于动态信任衰减和信息匹配的混合推荐算法,考察共同评分数和时间因子调整邻居选择机制,引入信任衰减重新定义近邻影响从而改进传统协同过滤算法,根据算法的初步推荐和历史信息的不匹配度,将改进后的动态信任协同过滤算法与传统矩阵分解算法按照特定规则进行混合,采用二次矩阵分解解决冷启动问题,算法推荐准确度得以提高,可扩展性、可解释性也得以加强。
1 传统算法
1.1 基于相似度的协同过滤算法
基于相似度的协同过滤算法(collaborative filtering,CF),其原理是兴趣相似的用户倾向于喜欢相同的物品,同一用户对同类型物品的喜好程度类似,用户的行为和打分都是可以体现用户偏好的有效数据。根据邻居类型,基于相似度的协同过滤算法可分为基于用户的协同过滤(User-based CF)和基于物品的协同过滤(Item-based CF)。User-based CF利用已收集到的用户偏好找到用户的K近邻,根据近邻用户的打分权重计算目标用户的可能打分。Item-based CF利用已收集到的用户偏好找到物品的K近邻物品,根据用户给近邻物品的打分权重计算用户对目标物品的可能打分。
1.2 基于模型的协同过滤算法
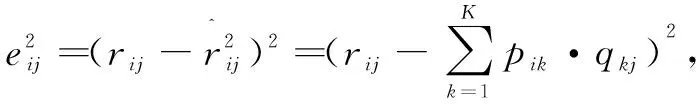
2 DTDIM-CF算法
传统协同过滤算法忽略了不同邻居影响程度和用户兴趣漂移,文中提出的DTDIM-CF算法通过在邻居选择前添加最低公共评分限制,并在剩下的备选邻居中引入时间因子调整近邻选择,再根据信任衰减重新计算不同邻居造成的近邻影响,得到改进后基于用户的动态信任衰减的协同过滤算法(User-DTDCF)和基于物品的动态信任衰减的协同过滤算法(Item-DTDCF)。其中考虑到用户间不同评分习惯造成的评分差异,使用了一种可适用于不同评分区间的评分规范化方法计算皮尔逊相关系数以完成相似度计算,采用矩阵分解算法处理协同过滤算法中新用户、新物品出现时存在的冷启动问题。就传统单一算法适应性不强但各具优势,DTDIM-CF算法根据所得预测评分与历史数据的不匹配度将改进后的User-DTDCF、Item-DTDCF和SVD算法进行不同情况下的动态加权混合。
算法分为四个Part,Part1对User-based CF算法改进,得到User-DTDCF算法,Part2对Item-based CF算法改进,得到Item-DTDCF算法,Part3介绍利用SVD算法特性解决冷启动问题,Part4介绍算法中User-DTDCF、Item-DTDCF和SVD的动态加权混合策略。
2.1 User-DTDCF算法
2.1.1 用户的近邻选择
在传统User-based CF的邻居选择中,首先考察目标用户与用户备选邻居的共同评分数,通过已评分物品挖掘用户潜在兴趣,用户间公共评分物品越多,二者越可能有共同兴趣,则用户关系越密切。反之,若用户间公共评分物品数较少,在根据已有评分分析用户时,认为用户间关联较少,关系较疏远。故在邻居选择前添加最低公共评分限制,不满足公共评分数num的备选邻居被淘汰。在剩余的候选邻居中考察时间因子,选取与该用户共同评分时间较接近的前Nn位用户作为其最终近邻,定义tuv为目标用户u对物品i的评分时间,tvi为近邻用户v对物品i的评分时间,tuivi为目标用户u和近邻用户v对物品i的评分时间间隔,tuv为目标用户u和近邻用户v的近邻选择评分时间差,令tuivi=|tui-tvi|,近邻选择公式如下:
(1)
选择tuv值最小的前Nn位用户作为最终近邻用户,得到基于num值近邻用户选择的num-User-based CF算法。
2.1.2 用户的近邻影响机制
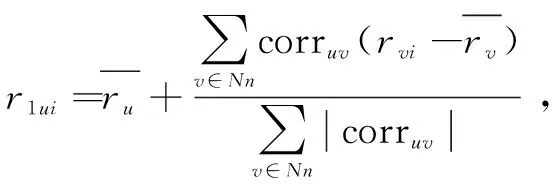
(2)
(3)
2.1.3 基于用户的主观评分规范化
定义改进后的User-DTDCF算法中,近邻用户v对目标用户u的影响因子为fv,则所得预测评分如下:
(4)
式中,根据不同用户打分习惯不同,在计算预测评分时,对fv做如下调整。
对于原始评分矩阵中每一个rui值,其评分区间为[rmin,rmax],则目标用户u与近邻用户v间的相关系数corruv计算如下:
(5)
(6)
2.2 Item-DTDCF算法
在传统Item-based CF算法的基础上,对物品近邻重新选择、物品近邻机制重新定义并进行基于物品的主观评分规范化得到Item-DTDCF算法,改进方法同2.1节中User-DTDCF算法生成。
2.3 冷启动解决
文中改进后的算法User-DTDCF和Item-DTDCF仍存在冷启动问题[14],故在算法开始前先进行判断,若不存在新用户、新物品,则直接用DTDIM-CF算法进行预测,反之,若存在,则利用SVD算法特性,当新用户或新物品出现时,提取该新数据,将剩余数据作为新的数据集,运用DTDIM-CF算法进行评分预测,得到评分矩阵后,添加已提取数据到该矩阵中,再使用SVD算法进行二次矩阵分解得到最终预测结果,进而解决算法冷启动问题。冷启动解决流程如图1所示。

图1 DTDIM-CF算法冷启动解决流程
2.4 加权混合策略
针对User-based CF、Item-based CF算法基于已有信息为用户进行推荐,冷启动问题无法解决,SVD算法解释性不强等,DTDIM-CF算法充分利用各算法优势将三种算法进行动态加权混合。混合策略为:首先将初始用户-物品评分矩阵R[m×n]使用User-DTDCF、Item-DTDCF和SVD算法分别进行评分预测,得到预测矩阵R1[m×n]、R2[m×n]、R3[m×n],再根据所得的预测评分与已有历史数据的不匹配度将三种算法进行不同情况下的动态加权混合,其中,若存在冷启动问题,则使用SVD算法进行二次矩阵分解,最终得到预测评分矩阵R4[m×n]。DTDIM-CF算法流程如图2所示。
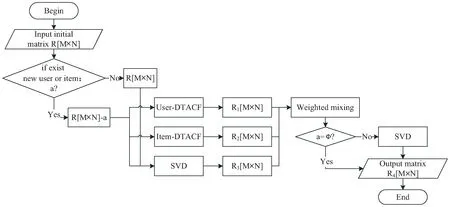
图2 DTDIM-CF算法流程
一般情况下基于用户、物品的协同过滤算法推荐准确度较高、可解释性较强,但在数据稀疏情况下效果不佳,不同环境下表现也不同。DTDIM-CF算法根据算法预测评分与历史数据的不匹配度动态调整各算法权重,若某一算法原始评分存在而预测评分为空,则认为该算法在该情况下的效果较差,适当降低该算法权重,若存在多个合理推荐值,则优先选择匹配度较高算法进行预测。定义DTDIM-CF推荐算法中,初始用户-物品评分矩阵R[m×n]中,用户u对物品i评分值为rui,通过User-DTDCF、Item-DTDCF、SVD算法进行预测得到的评分矩阵R1[m×n]、R2[m×n]、R3[m×n]中预测评分值分别为r1ui、r2ui、r3ui,len=∑items,a为矩阵R1中空值个数,b为矩阵R2中空值个数。首先判断历史数据与User-DTDCF、Item-DTDCF算法所得预测评分空值情况,若历史数据为空,而以上两种算法均无预测评分,则使用SVD算法进行评分预测;若历史数据为空,而以上两种算法仅有一种算法有评分,则使用SVD算法与该算法进行特定加权混合得到预测评分。User-DTDCF算法推荐为空时,三种算法权重因子分别为w1=0、w2=1/2(1-b/len)、w3=1/2(1+b/len),Item-DTDCF算法推荐为空时,三种算法权重因子分别为w1=1/2(1-a/len)、w2=0、w3=1/2(1+b/len);若User-DTDCF、Item-DTDCF算法均有评分,则使用三种算法进行特定加权混合作为预测评分,权重因子分别为w1=1/4(1-a/len)、w2=1/4(1-b/len)、w3=1/4(2+(a+b)/len);反之,若历史数据不为空,而以上两种算法均无预测评分,则使用SVD算法进行评分预测;若历史数据不为空,而以上两种算法仅有一种算法有评分,则选择SVD算法与该算法中与历史评分相比较接近的评分值作为预测评分;若两种算法均有评分,则使用三种算法中与历史评分值较接近的评分值作为预测评分。三种算法涉及权重因子时,总评分为r4ui=w1r1ui+w2r2ui+w3r3ui,由DTDIM-CF算法加权混合后得到的最终评分预测矩阵R4[m×n]中评分值为r4ui。算法加权混合流程如图3所示。
3 实验分析
3.1 数据集
文中使用的数据集为GroupLens提供的MovieLens,实验采用ml-100k的数据集,数据格式如表1所示,其中包含用户-电影(943*1 682),共100 000条评分,分值为0-5分,每位用户至少有20条打分记录,数据集稀疏度达0.936 9,评分时间段为1997/9/20 11:5:10-1998/4/23 7:10:38,换算为时间戳为874724710-893286638。

表1 ml-100k数据集(部分数据截取)
3.2 评价标准
文中涉及的所有实验均使用均方根误差(root mean square error,RMSE)和平均绝对误差(mean absolute error,MAE)作为评价指标。
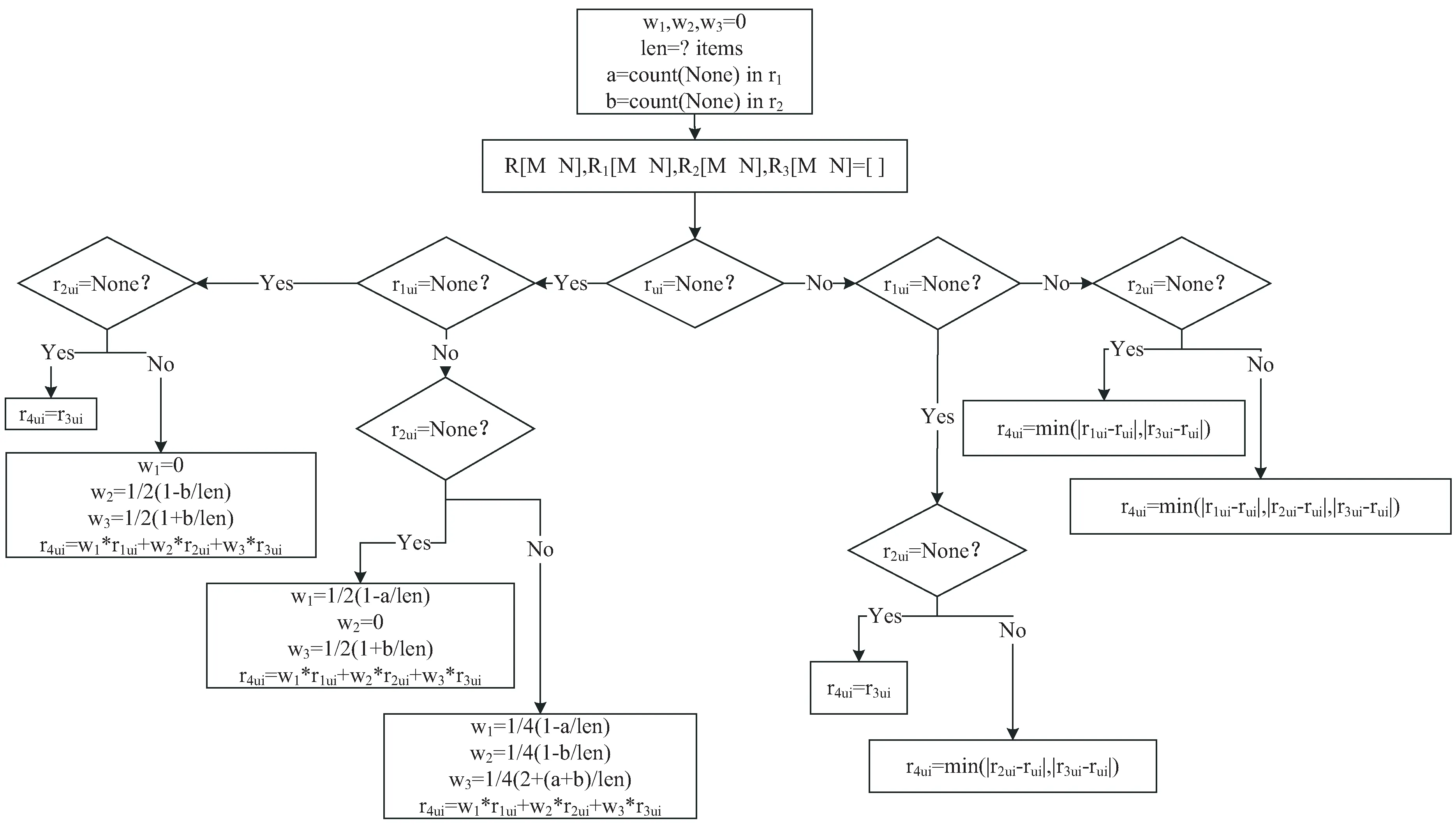
图3 DTDIM-CF算法加权混合流程
RMSE计算公式如下:
(7)
MAE计算公式如下:
(8)
3.3 实验结果
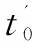
3.3.1 num-User-based CF中num值选取
通过在传统User-based CF算法的基础上添加公共评分数限制,并考察时间因子进行用户邻居选择,对算法进行改进。实验比较当邻居数Nn改变时,num-User-based CF算法在公共评分数num值不同的情况下,通过时间因子进行邻居选择得到的推荐结果。
实验得到,随着邻居数Nn的增加,改进后的num-User-based CF算法误差逐渐减小,当Nn值取40时总体误差最小,算法中num值的选取对算法最终推荐效果起到了积极作用,使得根据时间因子进行邻居选择后算法误差明显小于传统User-based CF算法,随着num值增大,总体呈现先减小后增大的趋势,故调整公共评分数后通过时间因子选择邻居可使算法的误差减小,且邻居选择更加合理有效。当num=40时,RMSE和MAE的误差值均取到较小值,故将此num值作为最佳公共评分数。
3.3.2 用户的近邻选择User-DTDCF中t0值选取
在上一节中对传统User-based CF添加了公共评分数限制并通过时间因子选择邻居得到num-User-based CF算法的基础上进一步改进,考察由于时间信息造成的用户信任衰减,从而调整邻居影响得到User-DTDCF算法。实验比较信任衰减未发生的时间段t0在不同值下的算法推荐效果,为User-DTDCF算法找到合适的t0值,取num=40,t0取值范围为[0,t],当邻居数Nn改变时,调整t0/t的值以获得较小的误差值。
实验得到,随着邻居数Nn的增加,改进后的算法误差逐渐减小,当Nn值取30时总体误差最小,在上一节对算法改进的基础上通过信任衰减定义邻居影响,进而进行预测得到的User-DTDCF算法推荐误差明显小于num-User-based CF算法,随着t0/t值的增大,误差逐渐增大,当t0/t=0%时,RMSE和MAE误差值均最小,此时,算法效果最佳。根据前文假设,在某固定时间范围[0,t0]内,认为评分影响不发生改变,而最佳t0值为0,由此可得出结论,User-based CF邻居影响中信任衰减总是存在,且时刻都在衰减。
3.3.3 num-Item-based CF中num'值选取
通过在传统Item-based CF算法的基础上添加公共评分数限制,并考察时间因子进行物品的邻居选择,对算法进行改进,实验比较当邻居数Nn改变时,num-Item-based CF算法在公共评分数num'值不同的情况下,通过时间因子进行邻居选择得到的推荐结果。
实验得到,改进后的num-Item-based CF算法的RMSE和MAE误差值较传统Item-based CF算法明显减小,算法中num'值的选取对算法最终推荐效果起到了积极作用,使得根据时间因子进行邻居选择后算法误差明显小于传统Item-based CF算法,随着num'值增大,误差出现波动,总体呈现先减小后缓慢增大的趋势,故调整公共评分数后通过时间因子选择邻居可使算法的误差减小,且邻居选择更加合理有效。当num'=40时,RMSE和MAE的误差值均取到较小值,故将此num'值作为最佳公共评分数。
3.3.5 传统User-based CF和User-DTDCF、DTDIM-CF算法比较
通过在传统User-based CF算法的基础上添加公共评分数限制并引入时间信息为目标用户选择最佳邻居,考察由于时间信息造成的信任衰减,以及不同邻居对目标用户影响不同,动态调整邻居选择,进而进行评分预测,得到User-DTDCF算法。在此基础上,将改进后的User-DTDCF、Item-DTDCF和SVD算法根据信息匹配度进行混合推荐,得到DTDIM-CF算法。设置对比实验,比较当邻居数Nn改变时,三种算法的推荐效果。本实验中User-DTDCF、DTDIM-CF算法涉及到的变量采用值如表2所示(实验3.3.1-3.3.4)。实验得到的RMSE、MAE误差值如图4所示[15]。

表2 实验3.3.5变量采用值(实验3.3.1-3.3.4)
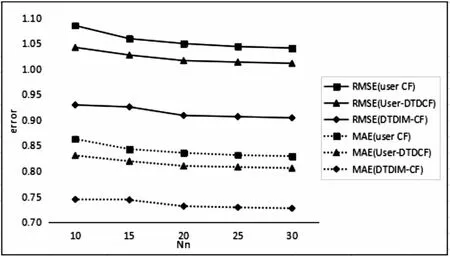
图4 传统的User-based CF、改进的User-DADCF 和DTDIM-CF算法的RMSE、MAE比较
由图4得,随着邻居数Nn的增加,User-based CF、User-DTDCF、DTDIM-CF算法误差RMSE和MAE均逐渐降低,三种算法进行比较发现,相较User-based CF,User-DTDCF算法误差有所降低,添加公共评分数限制并通过时间因子选择后获取的邻居关系更紧密,考虑信任衰减动态调整用户的邻居影响,对于用户评分预测更具有参考价值,算法可解释性更强,算法推荐效果有所提升。
与前两个算法相比,DTDIM-CF算法误差RMSE和MAE均大幅度下降,将改进的User-DTDCF、Item-DTDCF算法与SVD算法进行混合,充分利用各算法优势,弥补传统User-based CF算法冷启动、可扩展性差等问题,得到的混合算法DTDIM-CF能有效解决和改善算法不足,并取得较好的推荐效果。
3.3.6 传统Item-based CF、Item-DTDCF、DTDIM-CF算法比较
通过在传统Item-based CF算法的基础上添加公共评分数限制并引入时间信息为目标物品选择最佳邻居,考察由于时间信息造成的信任衰减,以及不同邻居对目标物品影响不同,动态调整邻居选择,进而进行评分预测,得到Item-DTDCF算法。在此基础上,将改进后的User-DTDCF、Item-DTDCF和SVD算法根据信息匹配度进行混合推荐,得到DTDIM-CF算法。设置对比实验,比较当邻居数Nn改变时,三种算法推荐效果。本实验中Item-DTDCF、DTDIM-CF算法涉及到的变量采用值如表2所示。实验得到的RMSE、MAE误差值如图5所示。
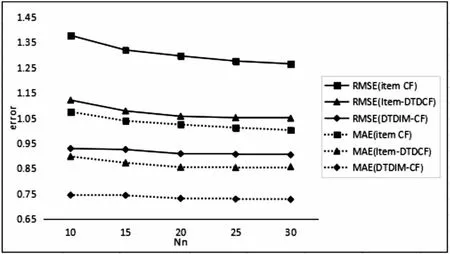
图5 传统的Item-based CF、改进的Item-DADCF 和DTDIM-CF算法的RMSE、MAE比较
由图5得,随着邻居数Nn的增加,Item-based CF、Item-DTDCF、DTDIM-CF算法误差RMSE和MAE均逐渐降低,三种算法进行比较发现,相较Item-based CF,Item-DTDCF算法误差大幅度降低,添加公共评分数限制并通过时间因子选择后获取的邻居关系更紧密,考虑信任衰减动态调整物品的邻居影响,对于用户评分预测更具有参考价值,算法可解释性更强,算法推荐效果有所提升。
与前两个算法相比,DTDIM-CF算法误差RMSE和MAE均大幅度下降,将改进的User-DTDCF、Item-DTDCF算法与SVD算法进行混合,充分利用各算法优势,弥补传统Item-based CF算法冷启动、可扩展性差、有时推荐效果不佳等问题,得到的混合算法DTDIM-CF能有效解决和改善算法不足,并取得较好的推荐效果。
3.3.7 混合算法有效性验证
针对User-DTDCF、Item-DTDCF算法冷启动问题无法解决且稀疏矩阵中推荐效果差,而SVD算法解释性不强等问题,将User-DTDCF、Item-DTDCF和SVD算法根据推荐信息匹配度进行混合,得到DTDIM-CF混合算法。设置对比实验验证混合算法的有效性,使用DTDIM-CF算法混合策略对传统的User-based CF、Item-based CF和SVD算法进行加权混合,将得到的预测结果(tradition CF)与DTDIM-CF算法作比较,同时与传统的User-based CF、Item-based CF作比较,随着近邻数Nn的改变,各算法RMSE和MAE值的比较结果分别如图6和图7所示,本实验中DTDIM-CF算法涉及到的变量如表2所示。
由图6、图7得,随着Nn值的增大,传统的User-based CF、Item-based CF以及DTDIM-CF算法误差明显减小,混合后的tradition CF误差缓慢减小,故各算法随着近邻数增大推荐效果变好。相较传统的User-based CF、Item-based CF,混合后的tradition CF算法误差RMSE和MAE值均减小,几组算法比较中,DTDIM-CF算法误差始终最小,推荐效果最好,且本实验通过控制变量,使用传统User-based CF、Item-based CF算法与SVD算法进行混合后得到的混合算法较传统算法推荐误差均有所降低,故文中混合算法的加权混合策略即使作用于传统算法对于改进推荐效果也有明显作用。

图6 传统的User-based CF、Item-based CF、混合后 的tradition CF、DTDIM-CF算法的RMSE比较
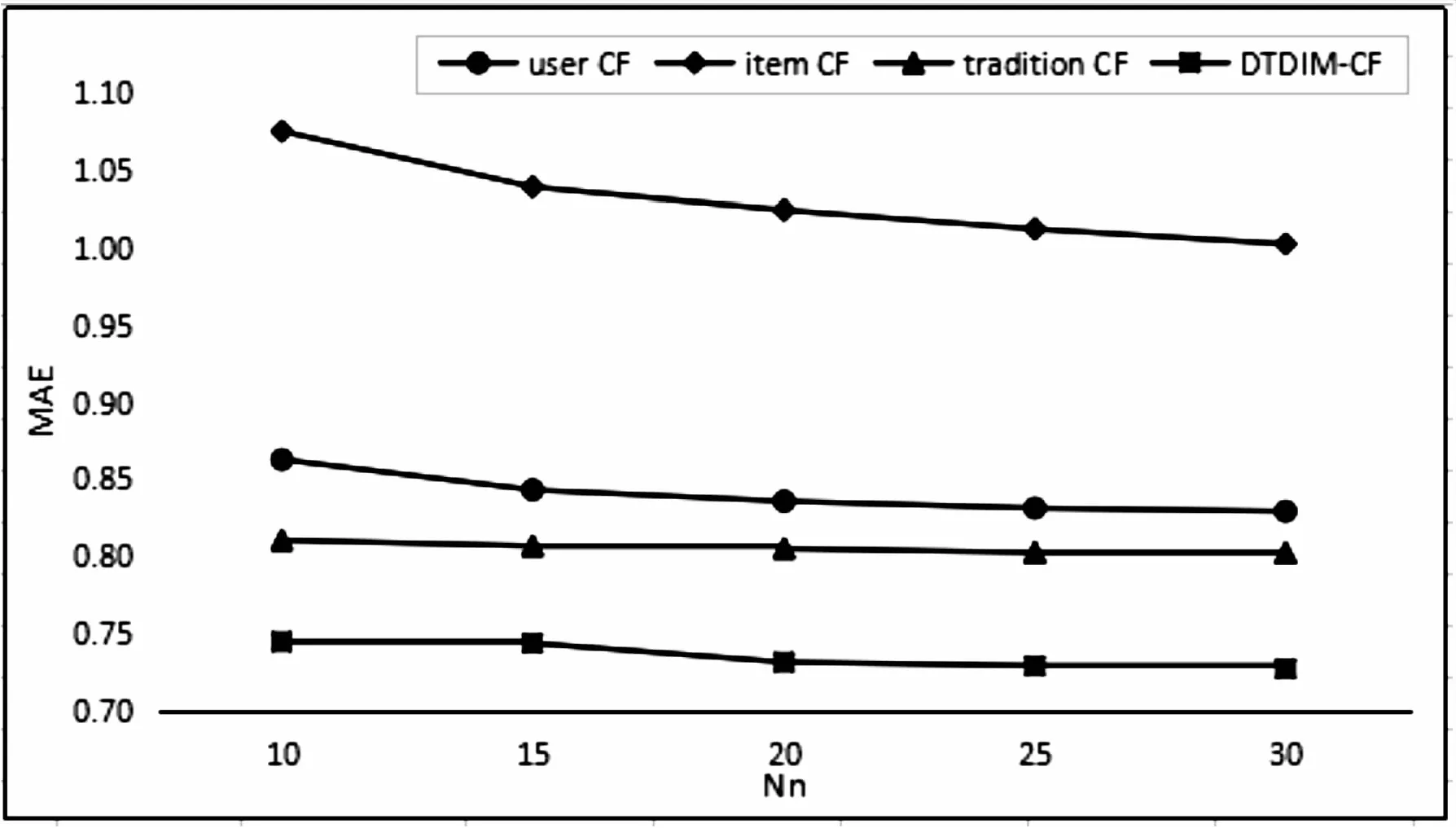
图7 传统的User-based CF、Item-based CF、混合后 的tradition CF、DTDIM-CF算法的MAE比较
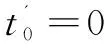
4 结束语
文中提出了一种基于动态信任衰减和信息匹配的混合推荐算法,对传统协同过滤算法进行了改进,通过添加近邻公共评分数限制并引入时间因子调整近邻选择,考察随着时间动态发生的信任衰减重新定义了近邻影响机制,使得推荐更加合理有效。提出一种评分规范化方法规范预测评分,充分发挥各算法优势,根据算法预测与历史数据匹配度进行动态加权混合推荐,算法可扩展性得以提高,可解释性加强,通过二次矩阵分解,解决了冷启动问题,稀疏矩阵中也有较好的推荐效果。在GroupLens提供的MovieLens数据集上进行实验,结果表明算法误差明显降低,可解释性、可扩展性都有所提高,推荐效果得以提升。基于动态信任衰减的方法可有效改善协同过滤算法性能,并应用于基于协同方法的多数混合算法中,未来研究对该方法进行调整以合理提升基于协同过滤的混合算法性能和利用率。
