基于随机森林与多源信息融合的疲劳驾驶检测方法
2021-10-28葛文杰
葛文杰,陈 龙
(杭州电子科技大学电子信息学院,浙江杭州 310018)
0 引言
世卫组织统计报告称全球范围每年大约有135 万人死于道路安全事故[1],在这些重大事故的诱发因素中,疲劳驾驶占了极高比例。根据目前道路安全事故的增长速度,未来5 年交通事故将成为全球人员死亡的主要原因。
驾驶员处于疲劳状态时,身体的各方面机能都有所下降,心理上处于一种松懈状态,遇到行人闯出、路口车辆突然汇入等紧急情况,无法及时准确地作出反应、规避危险。在日常行车中,大部分驾驶员无法及时意识到自身处于疲劳状态而继续驾驶车辆[2],极易引发车祸,因此需要设计一款能够便捷安装在车辆中的系统,对驾驶员的疲劳状态进行实时检测,当驾驶员出现疲劳状态时,发出警报,及时提醒驾驶员停车,避免因疲劳驾驶造成生命财产损失。
1 相关研究
一直以来,全球对如何避免疲劳驾驶都极其重视,越来越多的公司、科研机构设计了各式各样的装置以避免疲劳驾驶。疲劳驾驶检测方法一般分为基于生理信号、基于车辆信息、基于驾驶员面部3 种方法[3]。
生理信息检测法通过与人体直接接触的传感器采集驾驶员的生理信号来判断驾驶员行车中的疲劳状态,这种方法得到的数据可靠,且生理信号直接来自人体,进行疲劳状态分析时准确可靠,但是通常要在驾驶员身上安装检测生理信号的装置,对驾驶员的干扰较大。
车辆信息检测法根据检测驾驶者对方向盘的操控力度[4]、转动快慢变换以及对油门踏板的压力是否平稳、车辆的行驶轨迹等信号特征检测驾驶员的疲劳状态。这种检测实现方法简单,但是容易受到环境因素的影响,如行驶的路面环境良好程度、气候是否恶劣等,检测系统抗干扰能力差[5]。此外,一些正常的驾驶操作如超车、并道等行为,也可能会引发误判。
驾驶员面部信息检测法在车辆内安装高清摄像头,当驾驶员启动车辆,摄像头就开始工作。通过计算机视觉的方式检测驾驶员面部表情特征变化,如眨眼频率、眼睑闭合度PERCLOS、眼球跟踪、瞳孔反应[6]、头部转动幅度及抬起高度、是否打哈欠等行为,评定驾驶员有无进入疲劳状态,成本较低、实现简单。但由于拍摄图像清晰度由环境光照条件决定,这种方法对光线要求较高,且摄像头一直对着驾驶员拍摄,会对驾驶员的隐私造成一定影响,驾驶员心理上容易出现抗拒、烦躁情绪,影响驾驶安全。
现有的疲劳驾驶检测方法大多只采用了单一信号以判断驾驶员疲劳状态,实际行车过程中的信号采集容易受到各种因素干扰,有时采集到的数据不够准确,由于判别依据单一,训练出的模型鲁棒性较差,容易发生误报等情况,反而影响驾驶员的行车安全。因此,本文将随机森林与多源信息融合相结合进行检测。多源信息融合检测方法运用多个精确度高的微型传感器[7],同步采集驾驶员的呼吸、心跳以及脉搏、握力等信号,当某一个信号的采集有所偏差时,另一个信号的采集不受干扰,然后将这些信息进行滤波、傅里叶变换等处理,建立一个多源的疲劳驾驶状态数据集,避免了单一信号抗干扰性差的缺陷[8],极大提升了疲劳检测准确率。相较于SVM(Support Vector Machines)、GBDT(Gradient Boosting Decision Tree)等分类算法,随机森林能够平衡数据集的误差,对缺失值不敏感,能并行运算且分类速度很高,满足疲劳驾驶检测中信号采集存在一定误差且对实时性要求高的需求。
2 疲劳驾驶多源信号采集平台
搭建的实验环境如图1 所示,采用模拟驾驶器模拟实际行车环境,保证测试人员安全。信号采集平台主要包括多普勒雷达模块、柔性握力传感器模块[9]及光电容积脉搏传感器模块三大部分。此外,将摄像头记录驾驶员行驶过程的面部图像作为数据集信号分类的专家批判依据[10]。3个模块硬件设计都采用了体积较小的传感器,尽量减少与驾驶员的接触,防止对驾驶员的操作造成影响。
采集到初始信号后,通过零相位椭圆滤波器将多普勒雷达采集到的驾驶员生理信号进行滤波处理,将呼吸、心跳信号分离出来[11]。通过零相位巴特沃斯带通滤波器和ChebyshevⅡ型带阻滤波器将脉搏信号中的低频噪声与50Hz 固定工频干扰滤去,得到清晰完整的脉搏信号[12],方便特征提取。最后将得到各种的信号特征数据作进一步标准化处理,并建立多源信息融合数据集。

Fig.1 Physiological signal acquisition platform for fatigue driving图1 疲劳驾驶生理信号采集平台
目前尚无人体疲劳状态分类的统一标准,本文将主观评价法与专家评判机制相结合,先由测试驾驶员对自己的疲劳状态进行等级划分,然后将录像中记录的驾驶员模拟驾驶过程中的面部表情特征对照如表1 所示的疲劳状态评价机制[13]再次划分等级。对于两次划分结果,差异在一个疲劳等级的,以他人评价机制分类结果为准,差异在两个等级及以上的,直接舍弃。这种主观加专家评判相结合的疲劳等级分类标准更具专业性,对于实际疲劳状态的划分更具有可靠性。

Table 1 Standards for classification of fatigue levels表1 疲劳等级划分标准
系统搭建并调试完成后,安排实验人员进行数据采集。为了增加采集效率,选取在午后进行实验,该时间段人体的活跃水平一般较低,容易困倦,以便测试驾驶员可以较好地进入疲劳驾驶状态。
3 随机森林与多源信息融合的疲劳驾驶检测
随机森林是经典集成学习算法中的一种,它的基本单元与梯度提升树算法[14](GBDT)一样,也是决策树,但是其基础决策树的类型根据实际数据集的不同可以有所差异,不需要全部采用同一种基学习器。此外,与GBDT 不同的是,它采用Bagging 的思想,提高了决策树分类的稳定性。
3.1 随机森林算法模型
随机森林算法的核心就是两个词,一个是“森林”,另一个就是“随机”。“森林”是因为它集成了许多棵决策树,随机森林算法使用了基础的决策树模型作为弱学习器。本文随机森林主要采用基尼系数计算模型节点的不纯度,节点样本计算得到的基尼系数越小,说明数据的不纯度[15]越低,代表特征选择效果越好。
假设某个分类问题一共有K个不同的类别,第k个类别的概率为pk,则它的概率分布基尼系数表达式为:

在随机森林中每个决策树的节点,在输入样本的特征中选择用于拆分数据集的值,使划分后的基尼不纯度最低。除非每个树节点下只含有同一类别的样本,否则继续通过贪婪递归[16]方式进行这种拆分,一直到初始模型设计的最大决策树深度。
“随机”体现于随机森林在Bagging 的基础上,以决策树为基分类器,不仅对决策树训练样本数据集进行随机构建,增加训练数据集的扰动性[17],还引入随机属性,每棵决策树的产生,在训练前确定用于划分的特征个数K,然后随机从选择数据集所有特征值中选取K个作为当前节点最优属性划分,而不采用所有的特征值作为样本划分。因为每个基学习器的样本以及特征选择构成都不同,泛化能力大大增强。如图2 所示,随机森林通过生成不同的决策树进行多次训练,分别得出结果后,测试信号数据的类别通过投票方式选择,将得票最高的结果作为输出。
假设一个训练集中有k个样本,对它进行随机采样,则同一个样本每次采样都被选取的概率是1/k。
连续k次随机抽样都没有选择它的概率则是:

Bagging 对训练数据集的样本进行采样,依次选取,训练集中大约有36.8%的样本不会被选取,这部分数据就叫“袋外数据”。这些“袋外数据”没有作为模型的学习数据,可以用它们进行“外包估计”[18],分析学习得到的分类模型是否具有良好的泛化性能。
对于随机森林的生成,树与树之间相互独立,不存在依赖性,可以并行训练,因此运算速度很快。它的节点划分特征属性集是随机选择的,不用人工选取,相较于SVM和GBDT 算法,不害怕某些数据特征的缺失[19],对于异常值不敏感,对特征很多的高维数据也有很好的表现。
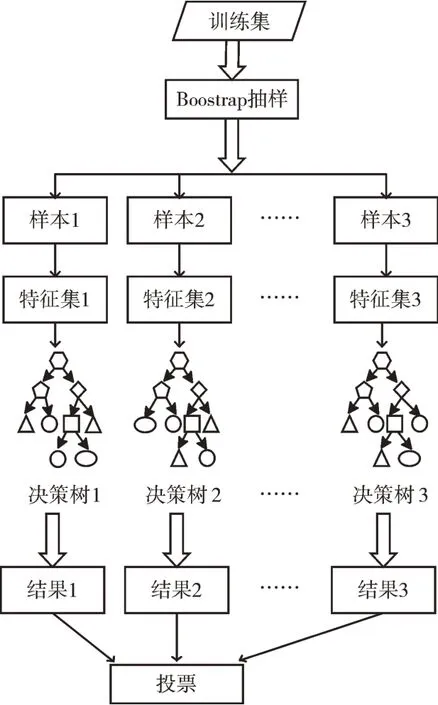
Fig.2 Algorithm model of random forest图2 随机森林算法模型
3.2 实验结果及分析
比较随机森林算法在单一信号数据集与多源融合数据集下的性能表现,验证了多源信息融合对于疲劳驾驶检测模型精度提高效果很好,然后进一步将建立的多源信息融合数据集分别输入基于SVM、GBDT 以及随机森林构建的分类模型进行分析比较,验证了随机森林算法作为疲劳驾驶检测分类算法模型的优越性,检测方法流程如图3 所示,调参后得到最优参数下的疲劳驾驶检测分类模型。

Fig.3 Flow of the method of fatigue driving detection based on random forest and multi-source information fusion图3 随机森林与多源信息融合的疲劳驾驶检测方法流程
3.2.1 多源信息融合数据集优越性
实验分别用心跳、呼吸、脉搏、握力单一信号进行随机森林分类算法模型训练,对比分析多源信息融合数据集训练的分类模型在疲劳驾驶检测中的性能表现。测试中得到的最优检测分类效果如图4 所示。
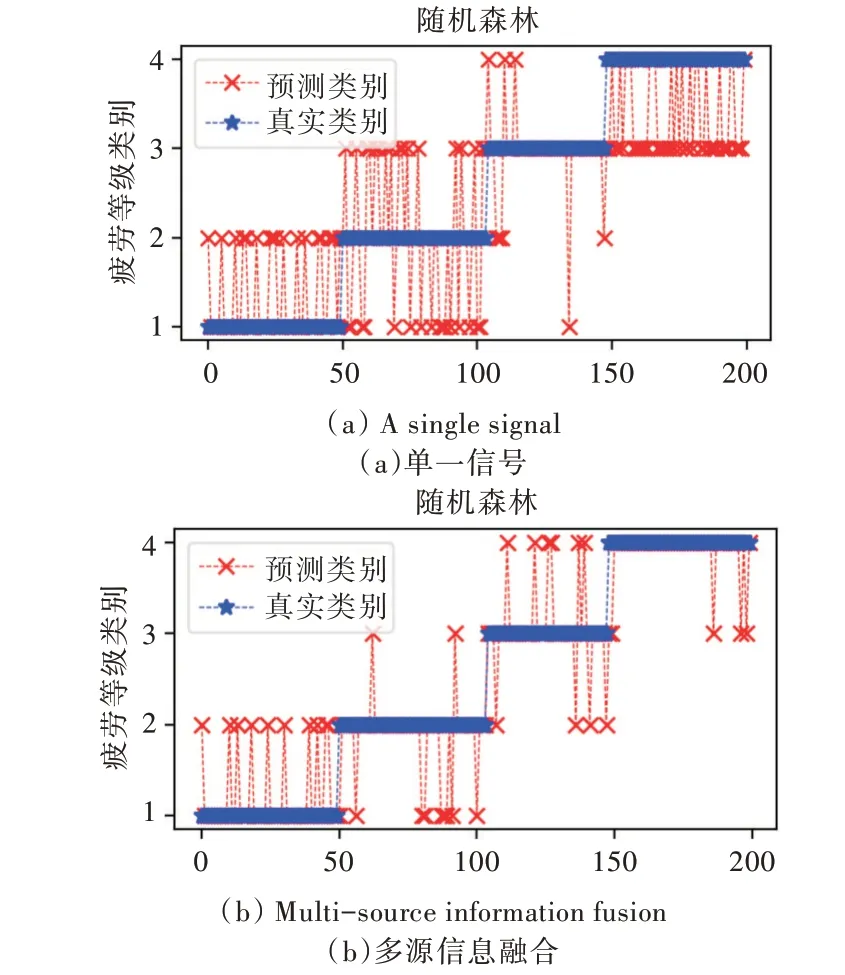
Fig.4 Fatigue driving status detection effect of single signal and multi-source information fusion图4 单一信号与多源信息融合疲劳驾驶状态检测效果
从表2 中各疲劳状态等级的检测准确率可以看出,基于单一信号的疲劳驾驶检测模型可能在某一类别具有较好的分类精度,但总体上检测准确度远远不如基于多源信息融合的疲劳驾驶检测模型。

Table 2 Comparison of detection accuracy between single signal and multi-source information fusion表2 单一信号与多源信息融合检测准确率比较
多源信息融合后的随机森林算法模型最佳检测精度达89%左右,而单一数据集的检测精度只有75%左右。相较于单一数据集,基于多源信息融合的随机森林模型对于疲劳状态的检测率提高了14%,验证了多源信息融合的优越性。
3.2.2 不同分类算法下的检测模型性能
通过建立的多源信息融合数据集分别训练SVM、GBDT 以及随机森林算法模型。将样本数据集随机划分为训练集和测试集,用训练集训练GBDT 分类模型和随机森林分类模型,测试集测试得到分类模型效果[20]。随机森林分类模型训练过程中的主要调整参数为:决策树建立的最大特征数目(max-feature)、决策树的最大深度(max-depth)、生成决策树个数(n_estimators)。通过多次训练,分类模型最高检测精度下的参数如表3 所示。

Table 3 Optimal parametersof random forest model表3 最优随机森林模型参数
训练得到多源信息融合数据集学习下的SVM、GBDT以及随机森林算法模型后,将整个数据集输入3 个疲劳驾驶检测模型分别进行测试,得到不同分类算法下的疲劳驾驶状态检测分类输出效果图(见图5)和相关准确率参数比较。
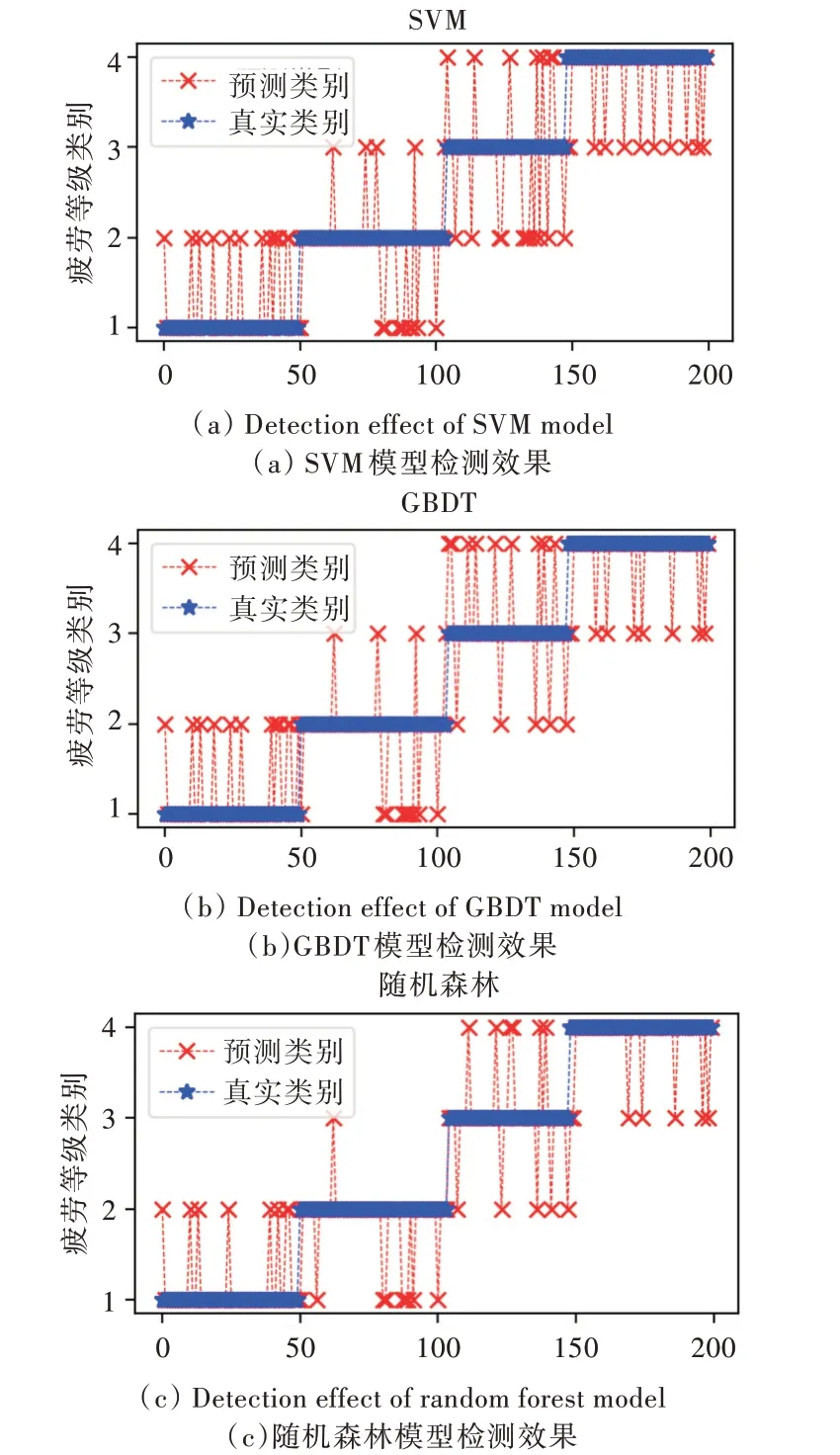
Fig.5 Fatigue driving status detection effects of Different algorithm models图5 不同算法模型疲劳驾驶状态检测效果
结合图5 所示的检测效果可以看出,随机森林算法模型对于各等级的疲劳状态检测都有很好的表现,在识别精度方面相较于SVM 与GBDT 都有不小提升。此外,随机森林可以并行生产决策树,检测模型对于疲劳状态的检测速度也优于SVM 和GBDT。为了避免测试数据集划分偶然性造成实验效果的偏差,模型自动多次随机抽样建立测试集,分析不同分类算法的检测精度,取实验中多次检测精度的平均值,实验结果如表4 所示。
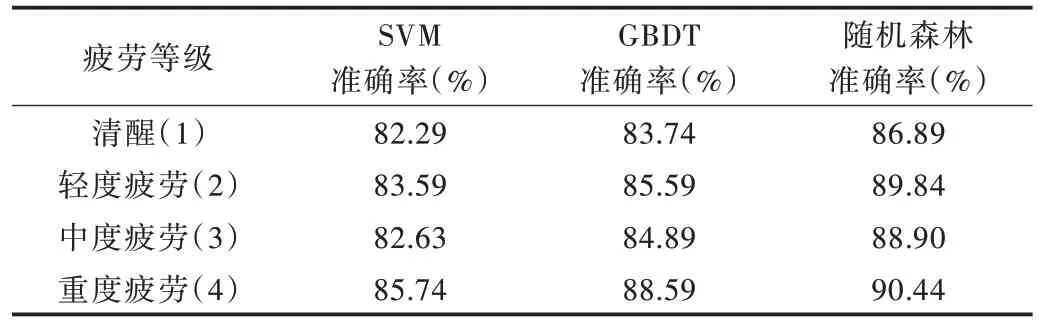
Table 4 Comparison of detection accuracy of different algorithm models表4 不同算法模型检测精确度比较
以上实验验证了基于随机森林与多源信息融合的算法模型能精确实现对疲劳驾驶状态的检测,多源信息融合后的随机森林算法模型最佳检测精度达89.18%。与GBDT和经典SVM 相比,其训练速度更快、准确度更高,基本达到了对于疲劳驾驶状态的实时高精度检测要求。
4 结语
本文基于随机森林与多源信息融合的疲劳驾驶检测方法,信号采集模块均采用微型传感器,减少与驾驶员的深度接触,行车过程中不会对驾驶员造成身心上的干扰。将采集到的多种信号经过滤波处理后建立可靠度高的融合数据集,设计随机森林模型对疲劳状态数据集进行学习训练,实现了对疲劳驾驶的高精度、高速度检测,避免了只依据单一信号检测误差较大的问题。此外,针对不同驾驶员的个体差异性,疲劳驾驶检测模型容易出现偏差,未来需分析更多能准确反映驾驶员疲劳状态的信号特征,尽量选取那些受驾驶环境及个体差异影响较小的特征值,同时优化分类算法,使分类模型具有自学习能力,以通过自学习训练达到适应个人的最优疲劳驾驶分类模型。
