融合注意力机制与LSTM 的建筑能耗预测模型研究
2021-10-28邵必林史洋博
邵必林,史洋博,赵 煜
(西安建筑科技大学管理学院,陕西西安 710055)
0 引言
随着经济社会的快速发展,建筑规模不断增大,建筑能耗也逐年增长。国际能源署(International Energy Agency,IEA)发布了《2018-2040 能源效率分析及展望》[1],指出2017 年建筑能耗占全球能耗的30%左右,而且在未来一段时期内仍会持续增长。建筑能耗预测是实现建筑节能的前提,相对准确、有效、合理的建筑能耗预测模型是节能与控制能耗的基础。未来建筑能耗呈现较大的不确定性,如何评估和预测建筑能耗,对于电能需求响应、电网实时平衡具有重要作用。
目前,建筑能耗预测方法主要分为工程方法和数据驱动方法。传统的工程方法主要利用物理学对建筑整体和子组件能源消耗进行计算。Fumo 等[2]应用度日法并结合动态城市气象模型计算建筑物的能源预算,结果表明其计算准确率优于其他方法;许馨尹等[3]应用EnergyPlus 软件对西安高层住宅及办公建筑进行气候变化下的建筑能耗动态模拟并进行定量分析,发现随着气候的变化建筑能耗有所不同;Jahanshahi 等[4]利用EnergyPlus 软件模拟能耗输出变量,并结合能耗小时分布情况预测建筑能耗,实例中每小时误差值在10%以内。但这些工程方法是将精确的建筑自身结构参数和外部环境参数作为仿真工具的输入数据,数据获取难度大、成本高。
数据驱动方法主要包括传统的统计回归、机器学习以及深度学习等方法。大多数建筑能耗预测方法都是基于时间序列数据分析,常见的时间序列预测模型有自回归模型(Autoregressive model,AR)和整合移动平均自回归模型(Autoregressive Integrated Moving Average model,ARIMA)。Lazos 等[5]使用ARIMA 模型对欧洲国家的住宅能耗进行预测,对结果进行分析后发现ARIMA(0,1,1)模型的预测精度最高;Fumo 等[6]建立了线性和多元线性回归模型对TXAIR 研究所的小时和日能耗数据进行分析,案例结果表明,随着数据观测间隔的增加,回归模型的预测精度也会提升;Amber 等[7]通过6 个环境变量建立多元回归模型对教学楼用电能耗进行预测,结果表明,环境温度和建筑类型以及工作日因素对建筑能耗影响显著。基于时间序列和回归的预测方法易于使用和开发,但在处理非线性问题时具有局限性以及缺乏灵活性。
为了避免统计回归方法处理非线性问题的局限性,机器学习方法逐渐被学者广泛使用。Neto 等[8]通过Energy-Plus 能耗模拟软件和简单的人工神经网络模型进行建筑能耗预测,结果表明人工神经网络模型比EnergyPlus 软件的预测精度更高;李嘉玲等[9]对公共建筑用电能耗特性进行了分析,构建BP(back propagation,BP)神经网络建筑能耗预测模型,确定超参数后的预测模型能够精准预测公共建筑用电能耗值;早在2004 年,Dong 等[10]就使用支持向量机(Support Vector Machine,SVM)模型对新加坡地区的四座商业建筑进行能耗预测,实验中SVM 模型的预测结果方差小于3%,误差小于4%;吴贤国等[11]在BIM 模型中导入能耗分析软件获取能耗数据集,在此基础上通过最小二乘支持向量机进行预测,结果表明最小二乘支持向量机模型的预测结果相较BP 神经网络更优。尽管机器学习方法在建筑能耗预测中应用广泛,但当数据样本过大时支持向量机无法得到很好的预测效果,人工神经网络会出现过拟合问题。
传感器和建筑能耗监测系统的普及使得建筑能耗数据大规模增加,这提升了深度学习在建筑能耗预测中的适用性。Marino 等[12]研究了基于长短时神经网络(Long Short-term Memory Networks,LSTM)的seq2seq 模型,使用UCI 数据集进行试验,结果表明seq2seq-LSTM 预测模型在不同时间粒度数据集上表现良好;Kim 等[13]利用卷积神经网络(Convolutional Neural Networks,CNN)层提取多个建筑能耗变量之间的空间特征,LSTM 层对时间序列数据进行建模,所提出的CNN-LSTM 模型可以有效预测建筑能耗数据中的不规则趋势,相较于其他机器学习方法在不同时间粒度上都显示出最优性能;李辉等[14]通过粒子群算法对循环神经网络(Recurrent Neural Network,RNN)参数进行优化,实验结果表明改良后的PSO(Particle Swarm Optimization,PSO)-RNN 模型在电力负荷预测精度上有明显提升;Zagrebina 等[15]分析了气候因素、工作日因素以及预测地区行业的特殊性,建立基于循环神经网络的能耗预测模型,与应用广泛的时间序列预测方法进行对比,结果显示该模型的预测结果更为准确。
尽管循环神经网络被广泛应用于能耗预测,但传统的循环神经网络方法预测时关注的重点都是输入序列的选择,未考虑到不同位置的输入序列对于预测结果的影响程度。注意力机制(Attention Mechanism)最早应用于机器翻译,可对神经网络隐层单元分配不同的权重,使得隐藏层能够关注更为关键的信息,这种思想被许多学者借鉴用于时间序列预测[16];彭文等[17]通过最大信息系数法分析了电价与当前时刻负荷的相关性,在此基础上将注意力机制与LSTM 神经网络相结合建立短期负荷预测模型,实证结果显示该模型的预测精度和鲁棒性要优于SVM 模型;谷丽琼等[18]将Attention 机制加入到股票预测模型中,结果表明基于Attention 机制的门控制循环单元(Gated Recurrent Unit,GRU)模型在MAPE(Mean Absolute Percentage Error)、均方根误差(Root Mean Squared error,RMSE)和R2分数评价指标上均优于其他模型;Hollis 等[19]在金融时间序列上将LSTM模型和Attention-LSTM 模型进行对比,在Kaggle two sigma数据集上的实验结果表明,Attention-LSTM 模型预测结果确实优于LSTM 模型。
相较于传统工程方法和机器学习方法,循环神经网络由于其特殊的网络结构,可以学习到数据长期的依赖关系,在时间序列预测上可以获得更好的预测结果。但传统的循环神经网络方法未考虑不同位置的输入序列对预测结果的影响程度,无法有侧重地对历史数据进行利用。本文针对传统的LSTM 神经网络难以识别重要信息节点的局限性,将Attention 机制加入到LSTM 神经网络中建立建筑能耗预测模型。首先利用距离相关系数分析环境变量与建筑能耗的相关性,去除无关影响因素;然后在LSTM 神经网络中加入Attention 机制,使预测模型可以捕捉到关键时间节点的重要特征;最后在小时和日能耗数据集上将Attention-LSTM 模型与LSTM 模型以及其他传统的机器学习方法进行比较,用数据得出结论。
1 相关理论基础
1.1 LSTM 神经网络
循环神经网络是深度学习领域中一类特殊的内部存在自连接的神经网络,适合处理时序数据。虽然RNN 在处理时间序列关系上表现良好,但标准RNN 结构存在梯度消失或梯度爆炸问题[20]。长短时神经网络是RNN 的变体,其改进了传统RNN 的记忆模块,避免了因为数据持续输入而无法长期保存有效历史信息的问题。
LSTM 神经网络通过引入细胞状态来存储需要记忆的信息,特殊的门结构设计可以删除或添加信息到细胞状态。门结构是一种可选择通过信息的方式,LSTM 神经网络主要由忘记门、输入门和输出门组成。忘记门决定模型从细胞状态中丢弃什么信息;输入门负责寻找需要更新的细胞状态,然后将需要更新的信息添加到细胞状态中;输出门通过Sigmoid 层来确定哪部分信息将输出,将细胞状态通过Tanh 函数进行激活,并与Sigmoid 层输出部分相乘得到LSTM 神经网络输出的部分。
LSTM 结构单元如图1 所示,其中F,I,C和O分别代表遗忘门、输入门、细胞状态和输出门;Ct表示当前t时刻的细胞状态,xt代表t时刻的输入,ht表示当前时刻的输出,也是下一个细胞状态的输入。Ft、It和Ot分别表示遗忘门、输入门和输出门的输出状态。

Fig.1 LSTM unit internal structure图1 LSTM 单元内部结构
如式(1)所示,首先,遗忘门F读取上一时刻输出ht-1和当前输入Xt,Sigmod 函数决定哪些信息需要舍弃,实现在细胞状态中丢弃信息功能。
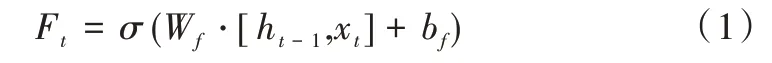
其次,输入门I中包含两个过程,如式(2)~式(4),既要将需要记忆的信息保存到单元状态,又需要将更新的信息添加到单元状态中。
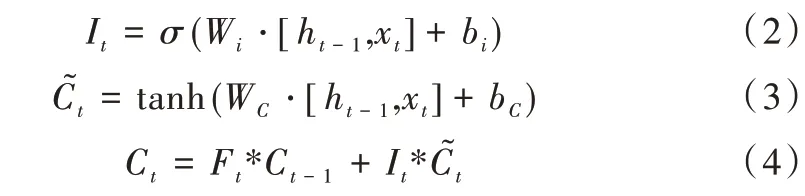
最后通过输出门O来控制输出多少内部记忆单元Ct的信息到隐藏状态ht,其计算公式如式(6)所示。
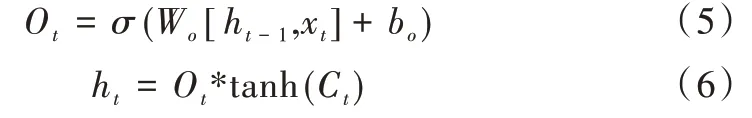
LSTM 神经网络的前向传播如式(1)—式(6)所示,计算出神经元的输出值。反向传播与传统的前馈神经网络类似,采用误差反向传播算法。利用输出层的误差求解各层权重,通过梯度下降方式完成权重系数的更新。
1.2 注意力机制
尽管LSTM 神经网络在处理长时间序列问题上效果很好,但在实际过程中长时间序列特征的重要程度存在差异,而LSTM 神经网络对于长时间序列输入没有区分,会忽略某些包含重要信息量的时序节点。Attention 机制是模仿人类视觉处理全局图像时注意力分布的一种信息处理方式,可以从大量信息中快速筛选出高价值信息。建筑能耗数据会随着各种影响因素发生变化,时间序列上各个时间节点上的特征对于预测值的影响程度也不同,与预测节点隐层状态相似的能耗特征信息对预测节点的影响程度更为显著。因此将Attention 机制加入LSTM 能耗预测模型中,能有效突出不同时间节点能耗特征的影响程度,从而改善预测效果。
在时间序列中,注意力机制对LSTM 神经网络输出的隐层向量进行加权求和计算,其中权重的大小表示每个时间点上的特征重要程度。注意力机制如图2 所示,图中H1,H2,,…,Hk表示输入序列的隐藏层状态值,q为最后一个隐藏层输出Hk,通过相似性函数Score(Hi,Hk)获取最后一个隐藏层输出Hk与其他每个时间点隐藏层输出Hi的相似度得分ei。相似性函数Score(Hi,Hk)如式(7)所示,采用点积的方式计算。通过式(8)SoftMax 函数可以得到每个时间点的注意力权值ɑi,计算出注意力机制权重ɑi与隐藏层状态乘积便可得到Attention 层的输出向量C。
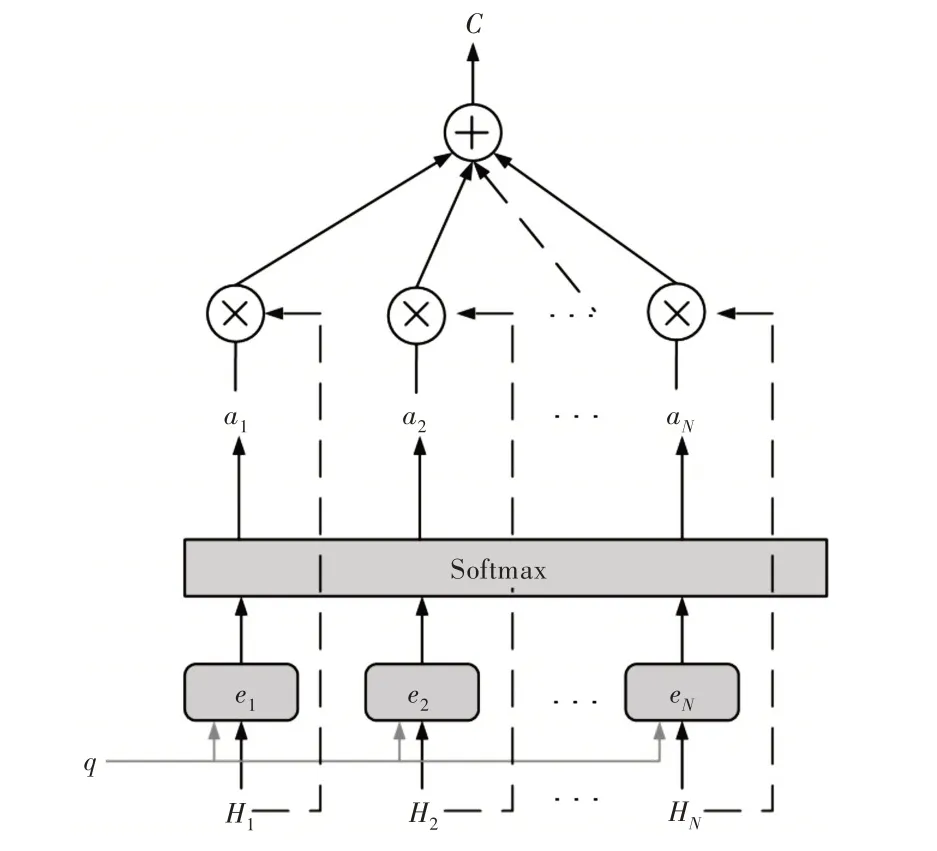
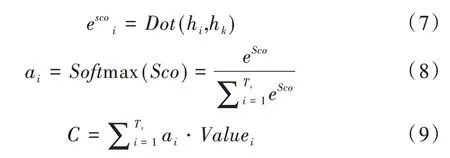
Fig.2 Schematic diagram of attention mechanism图2 Attention 机制
2 基于Attention-LSTM 的建筑能耗预测模型
2.1 数据预处理
(1)数据清洗。样本数据的质量和数量会对预测模型效果产生很大影响。由于建筑能耗数据采集过程受到不同人为因素和客观因素影响,数据集会出现缺失值和噪声点,因此需要对数据进行清洗。3sigma 方法是常见的异常数据监测方法之一,如式(10)所示。如果一组数据中某值与平均值的偏差大于3 倍的标准差,那么该值就被认为是异常值。

对于识别出来的异常值和缺失值,在时数据集和日数据集上进行插值处理。
(2)数据归一化。在完成样本数据清洗和特征选择后,还需要对其进行归一化处理。因为样本特征数据之间的类型和量纲不同,绝对值相差很大,会导致某些值域范围较小的特征被忽视,同时数据进行归一化后可以提升模型的收敛速度和模型精度。本研究采用线性函数归一化方法,将原始数据置换到[0,1]范围,归一化公式如下:
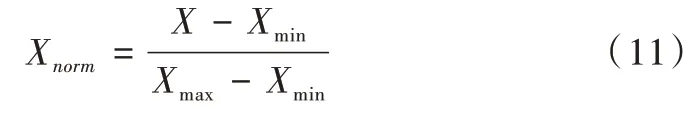
式(11)中,Xnorm为归一化后的数据,X为原始数据,Xmɑx,Xmin分别为原始数据集的最大值和最小值,预测后得到的结果要进行反归一化,以得到真实的预测值。
2.2 环境变量选取
初始的环境变量包括最高温度、最低温度、露点、云量、风速、压力、湿度、紫外线指数和可见度等。由于这些变量存在无用或者冗余特征,因此要去除这些冗余特征以降低输入向量维数,优化学习样本,从而提高训练效率。常用的相关性系数有Pearson 和Spearman 相关系数,但Pearson 相关系数只能度量两个变量间的线性相关关系,且必须服从正态分布的假设。Spearman 相关系数尽管没有Pearson 系数对数据敏感,但其检验效果较差。本研究通过距离相关系数[21]来衡量环境变量和建筑能耗的相关性,避免了传统相关系数只适用于线性相关的问题。如式(12)中距离相关系数R(X,Y)是通过样本协方差V(X,Y)和样本方差V(X),V(Y)计算得来的,R(X,Y)=0时说明X和Y相互独立,R(X,Y)越大说明X和Y的距离相关性越强。
式(12)中,{(Xk,Yk:K=1,2,...)}是随机向量(X,Y)的观测样本。

式(13)中,k,l=1,2,…,n,计算出X、Y 向量的ɑkl、Akl、bkl、Bkl,通过式(14)计算出样本协方差V(X,Y)。

环境变量与建筑能耗距离相关系数的计算结果如表1所示,剔除距离系数小于0.30 的环境特征,保留最高温度、最低温度、露点、紫外线指数和湿度5 个环境特征。
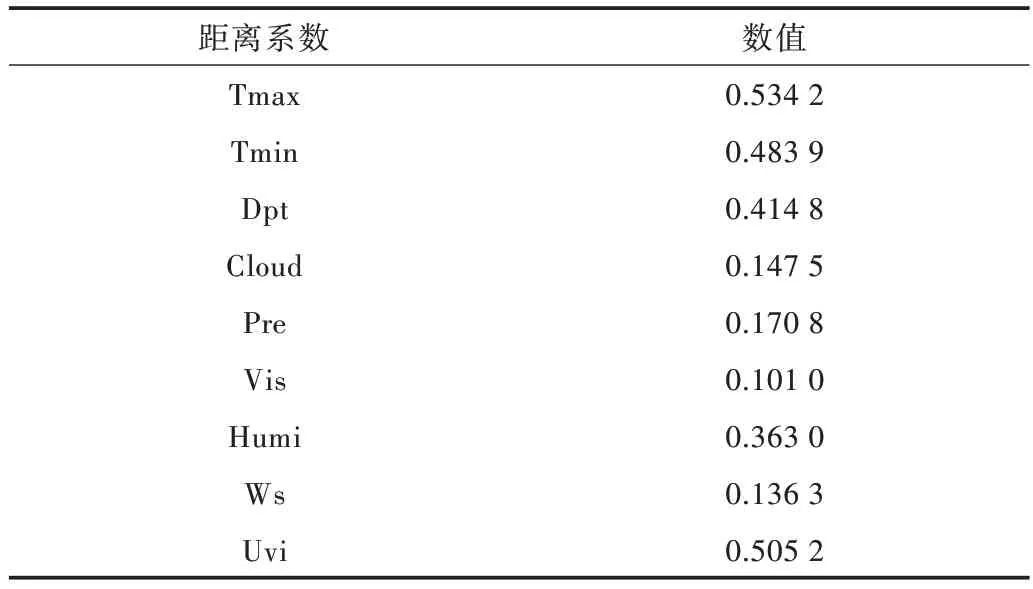
Table 1 Distance correlation coefficient of environment variables表1 环境变量距离相关系数
2.3 模型构建
Attention-LSTM 模型结构如图3 所示。
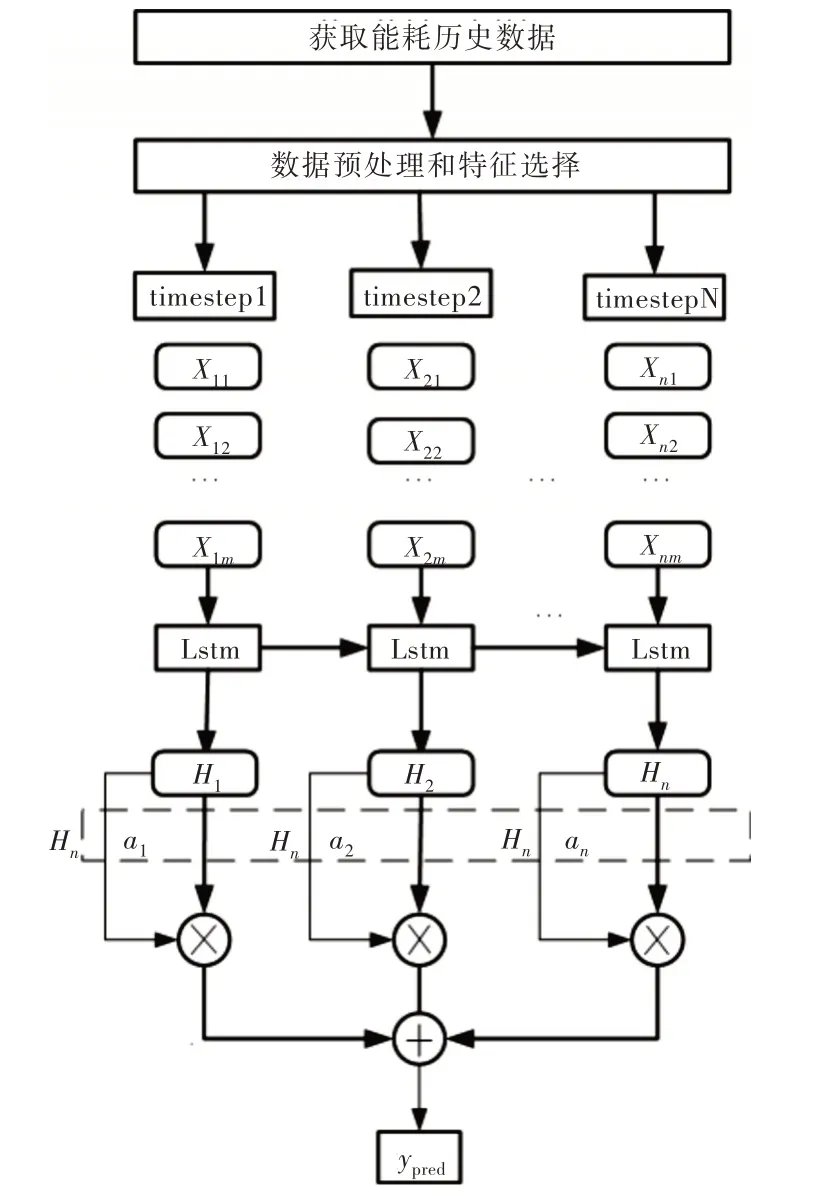
Fig.3 Attention-LSTM model structure图3 Attention-LSTM 模型结构
首先获取建筑能耗历史数据,对数据进行清洗,通过距离相关系数进行特征选择,之后进行数据归一化。在输入层中,根据距离相关系数得到5 个环境变量以及上一时间点的能耗值作为输入特征,进行归一化后的输入数据维度为[B,T,D],B 为输入批次大小,T 为时间步长,D 为输入的特征维数。用于训练的样本可以表述为:
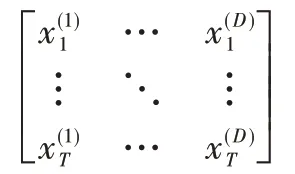
模型由LSTM 神经网络和注意力机制两部分构建。数据预处理后将训练数据Xt 输入模型,通过LSTM 单元得到隐层状态Ht。注意力机制计算出LSTM 不同时间点隐含层向量与最后时间点隐含层向量的相似性得分,通过SoftMax函数得到不同时间点对应的权重ɑn。最后对LSTM 不同时间点的隐含层输出向量与对应的权重相乘并求和,通过全连接层得到最终的预测结果。
2.4 评价指标
为了评估本文预测模型的效果和精准度,采用平均绝对误差MAE、均方误差MSE、均方根误差RMSE 作为预测模型的评价指标。MAE 可以避免正负误差相互抵消的问题,体现预测值与真实值的差值;MSE 是预测值与真实值之差的平方和的均值,可以评价数据的变化程度;而RMSE是预测值与真实值偏差的平方与观测次数n比值的平方根,能够很好地反映出预测精度。

式中,为i时刻的预测值,yi为i时刻的真实值,n为测试样本数量。
3 算例分析
实验在同一个计算平台上进行仿真,模型使用深度学习框架Tensorflow构建,机器学习预测模型使用python skit-learn 进行建模和仿真。
3.1 数据来源
使用Kaggle 网站上公开的建筑能耗数据集[22],包含部分伦敦住宅用户2011年11月—2014年12月的能耗数据,数据集时间粒度为小时,同时从Darksky 获取天气数据便于进行环境变量分析。图4和图5分别为小时能耗和日能耗的密度分布,实验数据前80%作为训练集,后20%作为测试集,在时粒度和日粒度分别进行模型预测,在小时数据集上利用过去48h 数据预测下一刻时间点的能耗数据,在日数据集上利用过去7天数据预测未来一天的能耗数据。
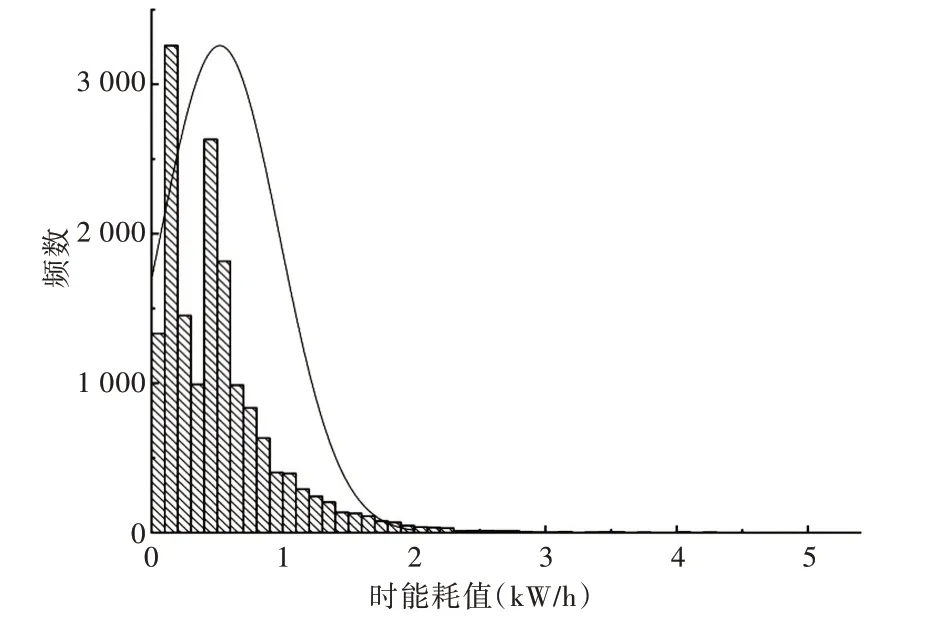
Fig.4 Data distribution of hourly building energy consumption图4 建筑小时能耗数据分布

Fig.5 Data distribution of building daily energy consumption图5 建筑日能耗数据分布
3.2 比较方法
将本文模型与常见的建筑能耗预测机器学习模型进行比较:多元线性回归模型(Multivariable Linear Regression model,MLR)、决策树回归模型(Decision Tree Regression,DTR)、神经网络模型(Artificial Neural Network,ANN)、支持向量回归模型(Support Vector Regression,SVR)。4 种模型参数设置见表2。

Table 2 Parameter settings of traditional machine learning model表2 传统机器学习模型参数设置
3.3 基础模型超参数选择
本研究采用Adam 神经网络优化算法,为防止深度神经网络训练过程中出现过拟合现象,采用Dropout 进行正则化,将MSE 函数作为损失函数。在构建深度学习模型时,超参数对于模型的训练效果至关重要。网格搜索算法是通过指定参数值对其进行穷举搜索从而选取最优参数组合。在LSTM 和GRU 模型参数训练过程中,需要确定的超参数主要包括批次大小、隐藏层节点个数和学习率。表3和表4 列出了日数据集上GRU 神经网络和LSTM 神经网络前5 组最优化参数组合,同理在时数据上也进行了调参。

Table 3 Optimal parameter combinations of GRU model表3 GRU 模型的最优参数组合
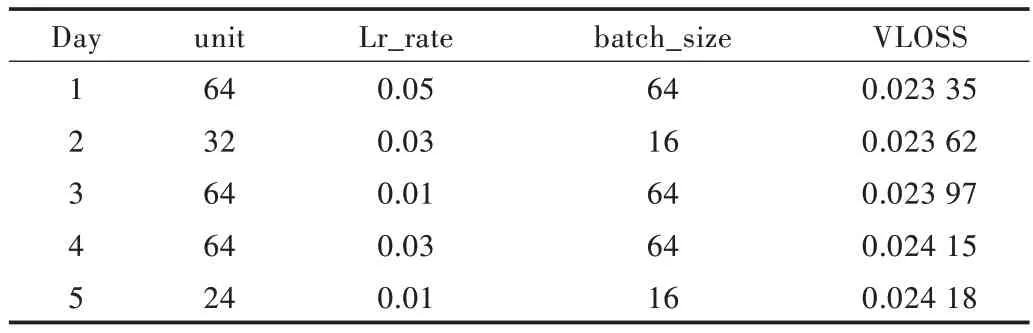
Table 4 Optimal parameter combinations of LSTM model表4 LSTM 模型的最优参数组合
3.4 实验结果分析
首先对LSTM 和GRU 模型和加入Attention 机制后的模型进行对比,预测结果如图6 所示。图中选取了时能耗数据50 个测试样本结果进行绘制,可以观察到4 种深度学习模型存在滞后性,但总体波动趋势与实际值基本保持一致。相较于基础模型,加入Attention 机制后的深度学习模型拟合程度更好,尤其是在能耗变化较大的峰值部分,能更为准确反映能耗变化规律。
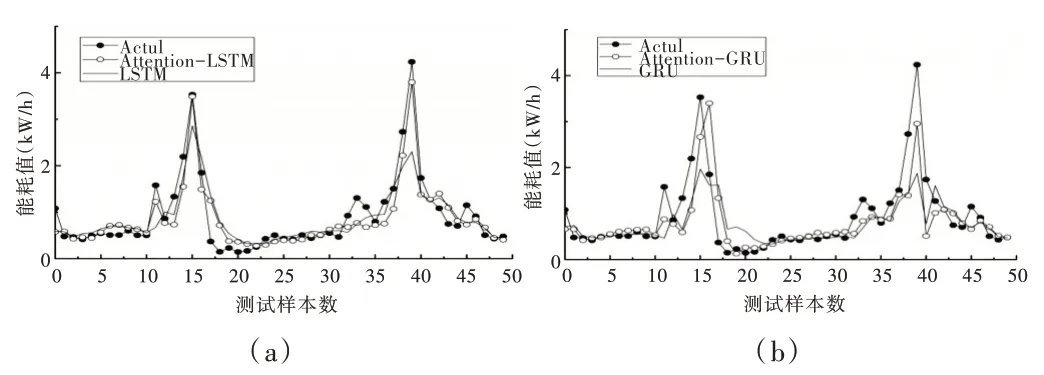
Fig.6 Comparison of deep learning model prediction of energy consumption data set图6 时能耗数据集深度学习模型预测对比
从表5 可以看出,加入Attention 机制后GRU 模型的MAE、MSE、RMSE 相较之前误差分别下降了7.47%、10.17%、7.10%,LSTM 模型的MAE、MSE 和RMSE 分别下降了7.09%、10.25%和3.68%,这表明加入Attention 机制后无论是GRU 模型还是LSTM 模型的预测结果明显得到提升。未加入Attention 机制时,预测模型对不同时间步长的编码向量均赋予相同的权重,未能注意到含有更多重要信息的时间点。而加入Attention 机制后,由于重要时间节点的权重增加,使含有重要特征的时间点的预测误差减小。从表中可以看出Attention-LSTM 模型的结果要优于Attention-GRU 模型,因此将Attention-LSTM 方法作为本研究的建筑能耗预测模型。

Table 5 Test results of energy consumption data set表5 时能耗数据集测试结果
为了更直观描述注意力权值变化,选取Attention-LSTM 模型3 个不同的测试样本权值分配情况如图7 所示。由图7 可知,LSTM 模型加入Attention 机制后时间节点权重发生了改变,成功地分配了注意力。从图7 可以看出3个不同时间点的测试数据赋予权重相对较大的是预测点前24h 左右和距离预测点较近的时间步长,其他时间步长上的注意力权重并没有单调变化,而是在局部范围内波动。不同测试数据的时间步长权重分布存在较大差异,这表明不同测试数据注意力机制分配的权重不同,与样本预测节点隐层特征更为相似的时间节点被赋予了更高的权重,因此加入Attention 机制后的神经网络模型能够相对准确地捕捉到历史时间序列上包含更多重要信息的时间节点。
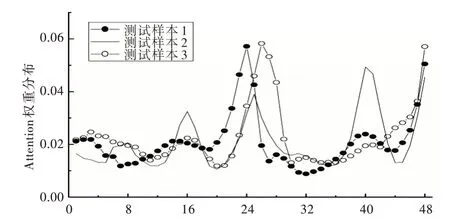
Fig.7 Distribution of attention weight of energy consumption data图7 时能耗数据注意力权值分配情况
为了验证Attention-LSTM 模型的有效性,与传统机器学习模型进行对比,评价指标结果如表6 所示。从表6 可以看出,在大规模数据集上Attention-LSTM 模型效果明显优于其他传统机器学习模型,相较于较优的DTR 模型,Attention 模型的MAE、MSE、RMSE下降了9.4%、30.0%、5.17%。传统的机器学习模型和Attention-LSTM 的预测相对误差曲线对比如图8 所示。从图8 可以看出,传统的机器学习方法尽管可以描述全局特征趋势,但描述局部特征的能力很差,而Attention-LSTM 模型预测相对误差基本处于最小值,可以很好地描述能耗曲线中的局部特征,具有相对良好的精度和鲁棒性。
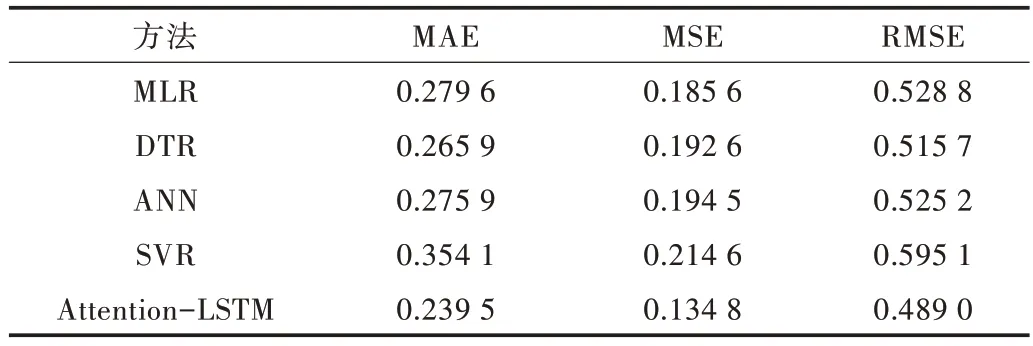
Table 6 Comparison of prediction error indexes of traditional machine learning model in energy consumption data表6 时能耗数据传统机器学习模型预测误差指标对比

Fig.8 Comparison of prediction errors of energy consumption data of each model图8 时能耗数据各模型预测误差对比
在日能耗数据上进行实验得到各模型预测性能评价指标值如表7 所示。从表7 可以看出,在数据规模较小的日能耗数据上,单一LSTM 和GRU 的效果与传统的机器学习方法相差不大。但是加入Attention 机制后的LSTM 模型MAE、MSE,RMSE 评价指标要优于其他模型,这表明Attention-LSTM 模型在样本数据相对较少的情况下也具有良好效果。
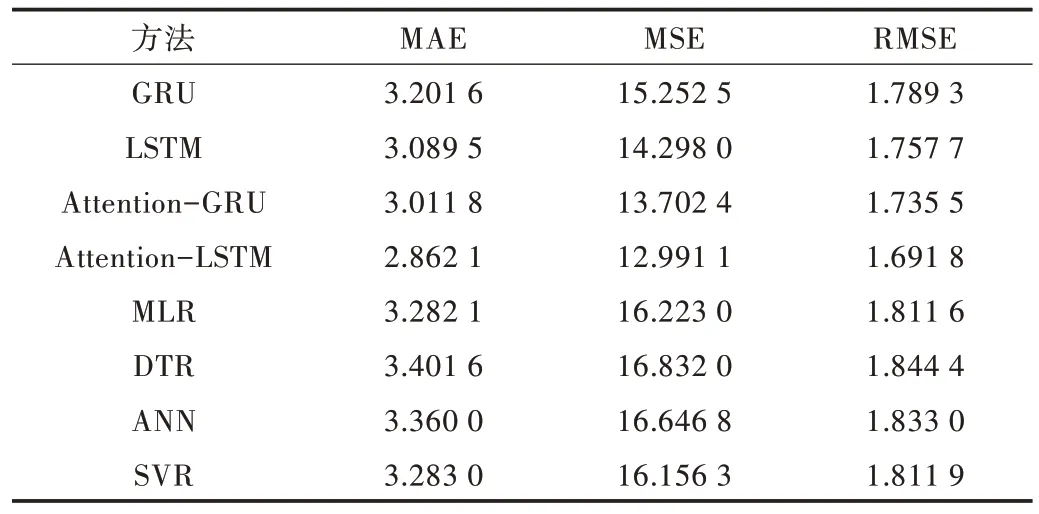
Table 7 Comparison of effect of daily energy consumption of data model表7 日能耗数据模型效果对比
4 结语
建筑能耗预测对于建筑节能在线控制优化以及电能市场化交易具有重要意义。本研究利用距离相关系数进行环境特征选取,通过网格搜索确定LSTM 神经网络初始参数,通过Attention 机制改善LSTM 神经网络进行多变量建筑能耗预测,并与LSTM、GRU 模型以及传统的机器学习模型进行比较。实证结果显示,在时粒度和日粒度数据集上,Attention-LSTM 模型预测效果都优于常规的LSTM、GRU 和传统机器学习模型,表明通过加入Attention 机制后的LSTM 神经网络可以更好捕捉历史时间序列上包含更多重要信息的时间节点,避免传统循环神经网络无法识别重要信息节点的局限性,更好地反映建筑能耗的变化趋势。
本研究也有一定的缺陷和不足。超参数对于神经网络的训练效果至关重要,本研究主要采用网格搜索算法,后续应考虑利用智能优化算法如粒子群算法、遗传算法来搜索LSTM 和Attention-LSTM 的超参数,减少参数搜索时间,提升建筑能耗模型的预测效率及准确性。
