用于深度学习的一种改进L-BFGS算法*
2021-10-27赵睿颖
赵睿颖
(天津大学数学学院,天津 300350)
0 引言
深度学习,作为解决大规模机器学习问题的领先技术,在图像分类、自然语言处理和大规模回归任务等领域都有非常突出的表现.深度学习算法通常需要解决一个高阶非线性的、非凸的、无约束优化的问题,求解其优化问题常用的方法包括一阶和二阶优化方法.其中,一阶优化方法包括随机梯度下降法(stochastic gradient descent,SGD)[1-4],二阶优化方法包括牛顿法、拟牛顿法[5-8]、Hessian⁃free 方法[9-10]和K⁃FAC 方法[11]等.一阶优化方法,如SGD,在计算中成本较低,但存在收敛速度较慢、需要反复地实验不断调整超参数等问题;二阶优化方法,如牛顿法,使用目标函数的Hessian 矩阵来确定搜索方向,通过加速收敛,可以减少大量的迭代次数,且不需要复杂的超参数调整,更容易得到好的训练结果.但是,由于深度学习中模型拥有海量的参数,Hessian 矩阵的维度过大,导致无法直接计算其逆矩阵.因此,在深度学习中,牛顿法并不可行,本文利用拟牛顿法进行深度学习算法研究.
拟牛顿法是求解非线性优化问题最有效的算法之一.牛顿法的优点是收敛速度快,但需要计算二阶导数,而且目标函数的Hessian 矩阵可能不是正定的.为了克服牛顿法的缺点,提出了拟牛顿法,其基本思想是用不包含二阶导数的矩阵近似牛顿法中的Hessian 矩阵的逆矩阵.因此,拟牛顿法只需要一阶导数信息,这使得拟牛顿法成为一个比较受欢迎的算法.同时,拟牛顿法不需要二阶导数的信息,有时比牛顿法优化更为有效.由于构造近似矩阵的方法不同,出现了不同的拟牛顿法.常见的拟牛顿法有BFGS算法、L⁃BFGS算法以及Hessian⁃free算法等.
L⁃BFGS算法是最受欢迎的拟牛顿算法之一.Liu 和Nocedal[12]是第一个提出L⁃BFGS算法概念的;Wang 等[13]提出了用于非凸随机优化的SdLBFGS算法,该算法利用了经典L⁃BFGS算法的框架;Keskar和Berahas[14]提出了用于训练循环神经网络的adaQN算法,该算法在L⁃BFGS算法的基础上每L(更新周期为20~60 次迭代)次更新1 次Hessian 矩阵;Rafati 和Marcia[15]将L⁃BFGS算法与信赖域算法以及线搜索相结合,提出了TRMinATR算法;Byrd等[16]提出了一种随机拟牛顿方法(stochastic quasi⁃Newton,SQN),该方法通过对样本进行二次采样,利用矩阵与向量的乘积来形成向量对(而不是使用随机梯度之间的差),取得了比以往方法更好的结果,并证明了在强凸的情况下,其收敛速度是次线性的;Berahas 等[17]将上述方法与随机方差缩减梯度方法[18]相结合,证明了算法的线性收敛性;Le 等[19]在深度学习的背景下,对现有的优化算法如L⁃BFGS、共轭梯度法(conjugate gradient,CG)和SGD 的优缺点进行了实证研究,表明L⁃BFGS 和CG 在许多情况下优于SGD;Berahas 等[20]介绍了采样的L⁃BFGS(SL⁃BFGS),与经典的L⁃BFGS 随着迭代的进行而顺序近似Hessian 矩阵(逆矩阵)不同,SL⁃BFGS 是在当前迭代点附近进行随机采样来近似Hessian 矩阵(逆矩阵);Rafati 等[21]介绍了一种基于L⁃BFGS 使用信赖域的算法(TRMinATR),作为解决深度学习中优化问题的一种新的方法;Gower 等[22]利用文献[16]中算法的框架,在优化过程中加入块BFGS 更新,收集曲率信息,并证明了块BFGS 更新可以加快训练速度.
上述文献大多是在理论上讨论算法的可行性,且通常利用相邻迭代点梯度之差,或矩阵与向量的乘积中的一种来更新向量对,缺乏在常用数据集CIFAR10 和MNIST 上的实验结果.本文提出了一种改进L⁃BFGS算法,拟利用梯度之间的差和矩阵与向量之间乘积的线性组合来更新向量对,以实现更新Hessian 矩阵的逆矩阵.
1 常用拟牛顿法BFGS和L⁃BFGS算法
现有拟牛顿法大多为传统拟牛顿法的变形,主要包括BFGS 和L⁃BFGS算法,其区别主要在于如何定义和构造拟牛顿矩阵、计算搜索方向以及更新模型中参数.
1.1 BFGS算法
BFGS算法是构造Hessian 矩阵的近似正定矩阵常用的拟牛顿法.在深度学习中,通常需要解决的是高阶非线性的、非凸的无约束优化问题,其公式为

式中fi:Rd→R 表示第i个样本的损失函数,w∈Rd是模型可训练的参数向量,d是训练参数的个数,是训练样本集.
用于解决式(1)的拟牛顿算法,更新公式通常为:
多数“玩阴”之举,都戴上了“惺惺相惜”的面具,令人防不胜防。黄鼠狼给鸡拜年,是阴;引蛇出洞,瓮中捉鳖,是阴;当面拥抱,背后使枪,是阴;来说是非者,便是是非人,是阴;有酒有肉亲兄弟,急难何曾见一人,是阴;借嘘寒问暖之际煽阴风点鬼火,更是阴……被“阴”者当初以为遇到知己,不胜感激涕零,托付重任、倾吐衷肠、一泻胸中块垒;岂知一旦利害攸关,“知音”原形毕露:“跳踉大,断其喉,尽其肉,乃去。”——此时方知被“玩”、被“阴”,木已成舟,悔之晚矣。另一边厢,“玩阴”者鸣锣收兵,弹冠相庆。

式 中,Bk为Hessi an 矩阵∇2f(wk)的近似;Hk为Hes⁃sian 矩阵的逆
的近似;gk:=∇f(wk);αk为步长.一般情况下,N和d都是非常大的数字.因此,直接计算真正的Hessian 矩阵是不切实际的.拟牛顿法利用目标函数值和一阶导数的信息,构造合适的Hk来逼近真正的Hessian 矩阵的逆矩阵,使得不需要计算真正的Hessian 矩阵,既减少了计算复杂度,又保持了牛顿法收敛速度快的优点.
拟牛顿法中的一个重要问题是构造合适的Hk,需要满足下列条件:
1)Hk满足拟牛顿方程:Bk+1sk=yk或Hk+1yk=sk;
2)Hk是正定对称矩阵;
3)由Hk到Hk+1的更新是低秩更新.
BFGS 方法是拟牛顿方法的一种,在BFGS 方法中,Bk更新公式为

式中sk=wk+1−wk,yk=gk+1−gk.通过利用Sherman⁃Morrison⁃Woodbury 公式,可以得到更新公式

1.2 L⁃BFGS算 法

2 改进L⁃BFGS算法
在BFGS算法中仍然有一些缺陷,如当优化问题规模很大时,矩阵的存储和计算将变得不可行.为了解决这个问题,就有了L⁃BFGS算法,但其依然有一些不足,如利用全批量数据来计算梯度.为了进一步节省计算训练时间、花费以及提高算法的精度,本节提出了一种改进L⁃BFGS算法.利用L⁃BFGS算法的框架,改变向量对的更新规则,利用相邻迭代点梯度之差,矩阵与向量之间的乘积的线性组合来更新向量对.
改进L⁃BFGS算法中,利用小批量数据而不是全批量数据来计算梯度,即
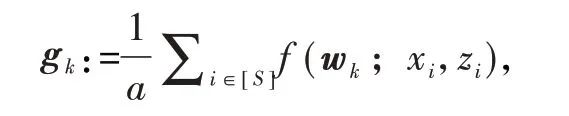
式中,S⊂{1,2,3,…,N}是从训练样本中随机选择的子集,定义a≜ ||S.改进方法的具体内容与步骤如下:
(1)用代替yk(yk=gk+1−gk)更新BFGS 公式.式中+(1 −θk)Mk sk,sk=wk+1−wk;Mk为如下定义的对角矩阵
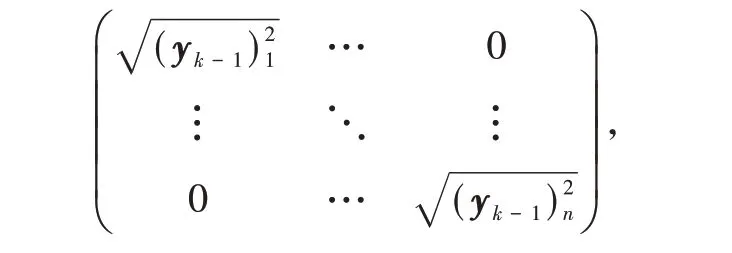
其中,(yk−1)i表示向量yk−1的第i个分量.
θk的取值如下:

此时,更新公式为

(2)当直接沿着迭代方向pk进行更新时,算法在几个epoch 后停止运行,方法不稳定,精度波动较大,因此,对迭代方向单位化使改进算法更加稳定.


与L⁃BFGS算法相比,改进L⁃BFGS算法有2 个关键的区别特征:(1)向量对的创建方式;(2)迭代方向的单位化.首先,该方法构造的逆Hessian 矩阵的近似矩阵能更好地利用目标函数的当前曲率信息;其次,更新向量对时,不仅利用了梯度之间的差,还利用了连续迭代的迭代点之间的差;再次,利用迭代方向单位化,使改进算法具有更好的稳定性;最后,改进L⁃BFGS算法不需要直接存储和计算Bk,只需要存储2 个m×d的矩阵,节省了大量的存储空间和计算费用.因此,与BFGS算法相比,改进L⁃BFGS算法大大减少了计算复杂度以及计算费用.
3 实验结果
为了将改进L⁃BFGS算法与现有的流行算法(SGD、AdaGrad 和L⁃BFGS算法)进行比较,本文采用Li 和Liu[24]使用的卷积神经网络进行训练,给出了在MNIST[25]和CIFAR10 数据集[26]上的实验结果.MNIST 数据集包含70 000 个手写数字样本,其中60 000 个样本用作训练集,10 000 个样本用作测试集,数字范围为0~9,图像包括描述其预期分类的标签;CIFAR 10数据集共有60 000张图像,其中50 000张图像用于训练,10 000 张图像用于测试,所有图像分为10 类,每类包含图像6 000 张.数据集一共分为5 个训练批次和1 个测试批次,每个批次图像10 000 张,测试批次包含从每类中随机选择的1 000 张图像,剩下的图像随机排列组成了训练批次,因此,有的训练批次某一类的图像可能多于另一类的图像,但总的来看,训练集每一类都有5 000张图像.
SGDM、AdaGrad、L⁃BFGS 和改进L⁃BFGS算法在CIFAR10 和MNIST 数据集上的测试精度和训练损失如图1所示.在CIFAR10数据集上,当训练100个迭代周期时,SGDM、AdaGrad、L⁃BFGS 和改进L⁃BFGS算法的测试精度分别是62%、64%、63%和66%,训练损失分别是0.001 4、0.001 2、0.001 3 和0.001 1;与其他3 种算法相比,改进L⁃BFGS算法测试精度最高,最终能达到66%的测试精度,且损失最低.在MNIST 数据集上,当训练100 个迭代周期时,SGDM、AdaGrad、L⁃BFGS 和改进L⁃BFGS算法的测试精度分别是92%、86%、None 和95%,其中None 指无数据,训练损失分别是0.31、0.58、None 和0.20;与其他3 种算法相比,改进L⁃BFGS算法的测试效果最优,能够以最快的速度达到最高的测试精度,且其损失始终处于一个比较低的水平.在运行10 余个迭代周期之后,SGDM算法能达到比改进算法更低的训练损失.在前25 个迭代周期,与改进L⁃BFGS算法相比,L⁃BFGS算法的测试精度较优,且训练损失较低,实验效果较佳;但在运行25个迭代周期之后,该算法停止,L⁃BFGS算法在Li 和Liu[24]的研究中也有类似的情况.
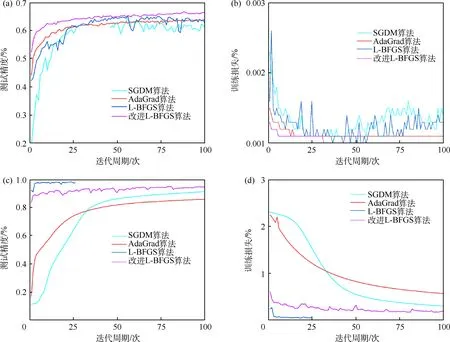
图1 4 种算法在2 种数据集上的测试精度和训练损失
超参数存储向量对数m和批量b对改进L⁃BFGS算法精度的影响如图2 所示.当m=50 和100时,算法的表现效果相当;当m=150 时,其表现略优于前2 种情况,且能达到最高精度66%.当b=64 和256 时,算法的表现相当;当b=128 时,其表现明显差于其他2 种情况.

图2 不同大小超参数对改进L⁃BFGS算法的影响
4 讨论
由图1 可知,改进L⁃BFGS算法在CIFAR10 数据集上的测试精度始终高于其他3 种算法,说明了算法的高效性.改进L⁃BFGS算法在CIFAR10 数据集上的训练损失始终处于一个较低的水平,与SGDM、L⁃BFGS算法相比,波动较小,更加稳定.虽然在前25 个迭代周期内,L⁃BFGS算法在MNIST 数据集上的测试精度高于改进L⁃BFGS算法,但在运行25 个迭代周期后,算法停止.改进L⁃BFGS算法在MNIST数据集上的训练损失始终低于SGDM 和L⁃BFGS算法,也再一次说明了算法的稳定性.综上,改进L⁃BFGS算法比原L⁃BFGS算法更加高效及稳定.图2展示了不同的超参数时,所得结果相差了4%的精度,为了使算法更加高效,在实验的过程中要选择合适的超参数.在本文实验过程中,当选择pk而不进行单位化来迭代时,算法在运行几个迭代后停止运行,遂采取了对迭代方向单位化.
5 结束语
本文提出了一种基于L⁃BFGS算法的改进优化算法,作为训练深层神经网络的一个新颖的拟牛顿算法.与已有的拟牛顿算法不同,改进L⁃BFGS算法利用连续迭代的梯度之差以及矩阵与向量乘积的线性组合更新向量对,并单位化迭代方向,使得该算法具有更好的实验表现.本研究主要是利用数值实验来说明算法的有效性.因此,未来可以利用理论来证明算法的收敛性,讨论算法的理论收敛性分析以及迭代方向单位化的理论必要性.
