基于IR多层校时策略的多回路需量叠加技术应用
2021-10-27梁广明黄水莲
梁 捷,梁广明,黄水莲
(1.广西电网有限责任公司计量中心,广西 南宁 530023;2.南宁百会药业集团有限公司,广西 南宁 530003)
0 引言
为了确保自身用电量和供电可靠性的需求,广西电网大电力用户通常采用双电源或多电源供电方式〔1〕。根据2018年国家发改委关于降低一般工商业电价有关事项的通知,对该类用户继续实行两部制电价,即电价包括电度电价和基本电价〔2〕。以用户实际使用电量计收的电费称为电度电费。按用户变压器容量或按最大需量计算的电费称为基本电费。基本电费可理解为客户需分摊的电网输配电建设和管理成本。对于变压器负载率不高的大用户,通常会选择更加经济的按最大需量计费的方式。当前需量是指在指定的需量周期内某用户用电功率的平均值,最大需量则是根据历史日或月的各需量周期内当前需量中的最大值确定。
多回路供电最大需量叠加的原理是根据各供电线路计量表计获取各时间片的区间需量,然后进行代数叠加。本文针对传统需量叠加实现方法存在的问题,设计了一种通过计量终端实现最大需量叠加的方案,并通过案例分析验证了其可行性。
1 需量叠加存在问题分析
1.1 需量叠加问题
对按最大需量计收基本电费的多回路供电的客户,若通过将结算周期内各供电回路的最大需量简单相加,不考虑实际的需量发生时间是否满足叠加条件,则无法准确的获取用户的最大需量。此外,还存在各回路安装的电能表需量叠加算法一致,但电表时钟存在误差。故使得上述直接相加的算法就不能准确获取用户最大需量的实际值。
以图1中的广西某大电力用户为例,该用户通过L1,L2,L3三个回路供电,某月L1,L2,L3回路的最大需量分别为Ct1、Ct2、Ct3,发生时间分别为t1、t2、t3。若以这三个回路最大需量的代数和,即Ct1+Ct2+Ct3用于电费结算,当不满足t1=t2=t3时,则不能真实反应客户实际的最大需量。

图1 三回路供电用户需量计量示意图
1.2 传统需量叠加方案分析
主从表法是目前常见的多回路需量叠加方案之一,其原理是首先选择其中一个供电回路的需量计量电能表作为需量叠加主表,其他回路的电表作为从表,通过光纤,RS485等通信连接线将各回路表计连接起来〔3〕,如图2所示。然后通过更新软件将主从表采集方案写入各表计。数据采集的原理为:首先读取从表的需量,再通过通信连接线传送至主表,再调用主表的处理器资源根据需量发生时间将各从表的需量逐点叠加,最后排序获取总最大需量值并保存,供主站读取。从而实现了多回路最大需量叠加计量功能。
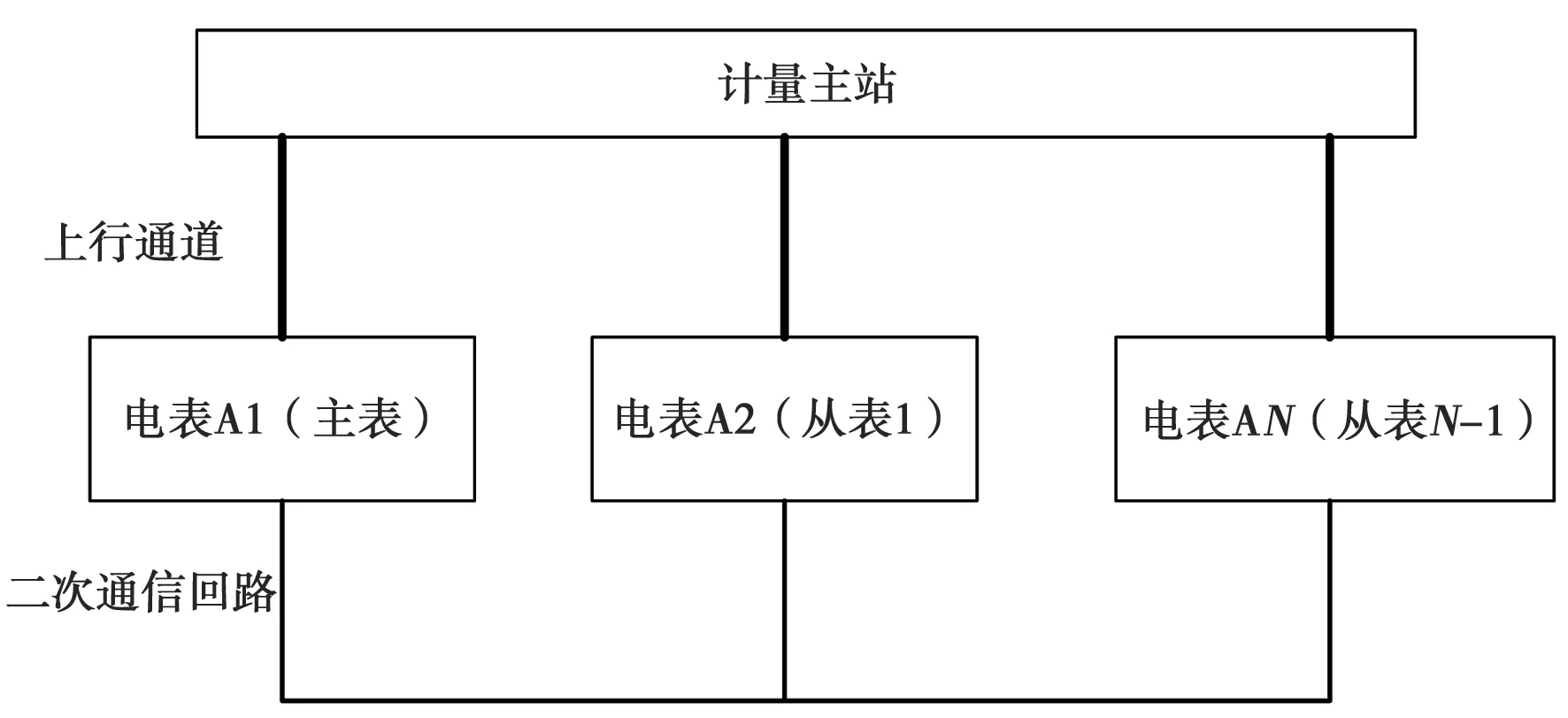
图2 需量叠加计量主从表设计方案示意图
该方法的主要问题为:(1)计量设备校时问题。由于采用多个需量计量表计分别采集,各线路的采集周期与时间点难以准确控制,缺乏统一、规范的时钟管理手段保证负荷数据的采集在同一时间点进行。(2)改造成本高。由于需额外加装主表和各从表之间的二次通信回路,且当各回路的一二次计量回路间的变比不一致时,需对多个电表进行软件升级。将导致硬件改造和软件升级成本提高。且电能表的存储芯片容量比计量终端小,能存储的需量曲线长度有限。
2 基于IR多层校时策略的需量叠加方案
本文需量叠加方案的思路为:首先下发需量采集参数并进行计量终端和电表的校时,接着通过计量终端抄读用户各供电回路计量需量电表的的当前有功需量负荷记录,时间间隔为1分钟。然后,以计量终端为主体按时间维度累加该用户各表计的数据采集结果,得到叠加需量曲线,再根据该曲线的峰值形成日/月有功最大需量的叠加结果,最后保存结果,等待上传主站。主要流程包括参数下发,计量终端和电表校时,需量数据采集和处理,主站抄读需量四个阶段。
2.1 参数下发
该阶段由主站对计量终端下发需量叠加参数。考虑到目前需量叠加功能的使用对象主要为大电力用户和变电站,则涉及该功能的计量终端为负荷管理终端和厂站电能量远方终端。为了建立需量叠加过程的采集机制和实现过程控制,在南方电网现有计量自动化终端上行通信协议的基础上进行数据项的扩展,见表1。
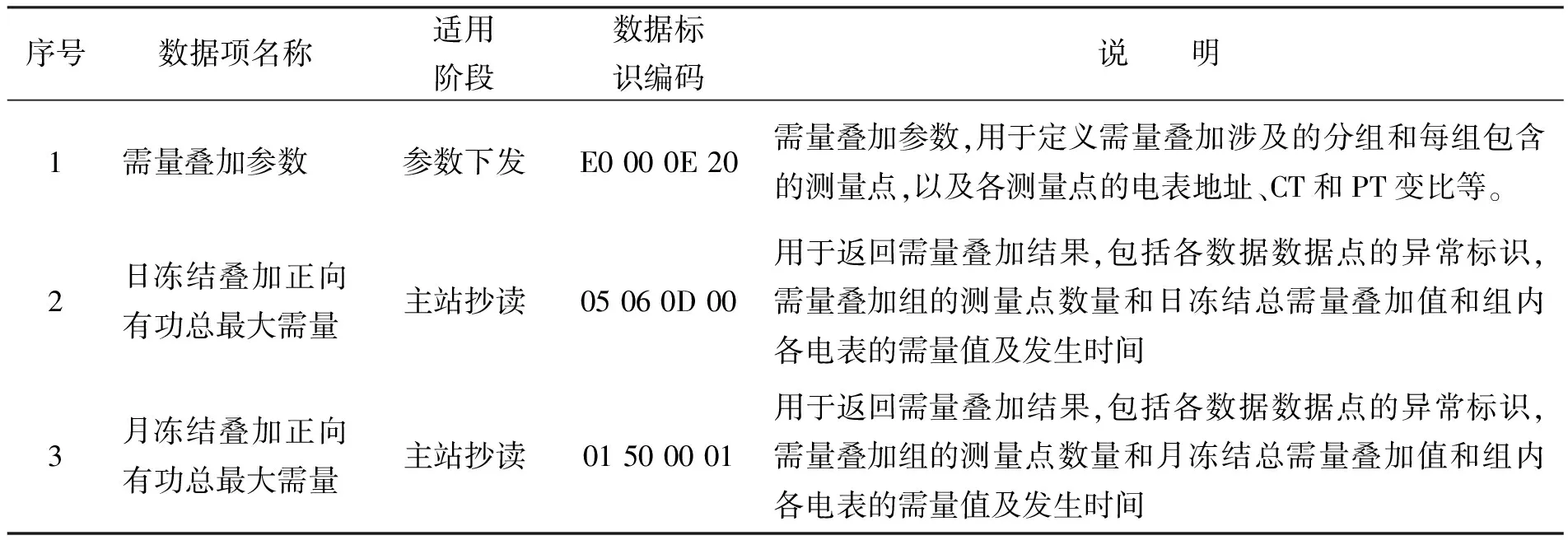
表1 上行通信协议新增数据项
为保证多用户,多回路,不同变比互感器接入式电表的需量能正确叠加,定义表1中的需量叠加参数,用于配置该过程中的用户计量分组和每组包含的测量点,以及各测量点的电表地址、CT和PT变比等参数。例如,有1个用户需进行需量叠加,则参数对应位置为1。假设该分组需要对6号测量点(PT变比为1 000,CT为200,表地址为000000000001)和12号测量点(PT变比为100,CT为100,表地址为000000000002)进行需量叠加,计算结果保存在64号测量点,则需量叠加参数的配置内容如下:
2.2 多层校时策略
为保证需量叠加组内各电表的时钟一致,该阶段要求主站每日定时对计量终端进行对时,且终端每日对所辖电表进行远程校时。由于传统同步方式为主站每天仅通过计量终端对电表进行一次广播校时〔4〕。该方式存在的问题是,根据DL/T 645系列电能表通信协议的定义,电表与终端在时差5 min之内才能校时成功,否则会校时失败。据调查,现场安装的电表常因为时钟电池欠压,电池SOC模式下受外界干扰〔5〕等原因导致与终端时差较大,故传统校时方案成功率较低。为解决该问题,本文提出一种基于“巡测-复校”(Inspection and recalibration,简称IR)的改进校时策略,如图3。
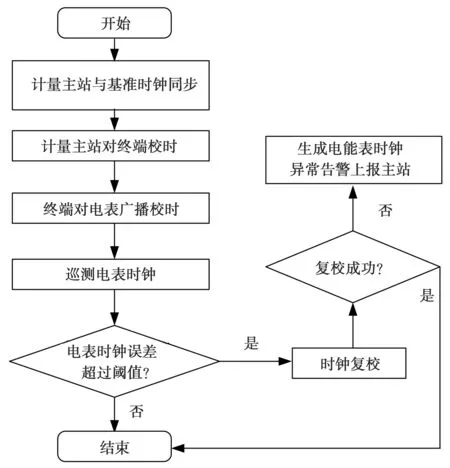
图3 “巡测-复校”校时策略
IR策略的主要流程为:首先,计量主站时钟每天定时与GPS,北斗卫星等基准时钟进行同步。然后主站对下属计量终端进行校时,校时完成后,终端立即根据传输时延对所辖所有电表进行广播校时。传输时延的确定方式为:首先从主站下发带时标T1的报文给计量终端,T2时终端收到该报文,并在T3时将报文透传给下属某电表,然后该电表于T4收到该报文,并在处理完该报文的命令后的T5时刻回复终端,终端T6时收到回复,并于T7时回复主站,主站在T8时接收到终端的回复。则此时可确定主站至电能表的传输延时D如式(1)
D=[(T8-T5)+(T4-T1)-(T7-T6)-
(T3-T2)]/2
(1)
其中:(T7-T6)和(T3-T2)分别为计量终端的透传处理时延。
在传输延时确定后,若传输延时值的大小可以接受,则电能表执行对时命令报文,将自身的时钟调整为校时报文发送时的主站时间+D,并返回应答报文告知主站对时成功。
接着,终端读取所辖各电表的时钟,如果终端与电表的时钟误差在时钟异常阈值之外,则:终端通过人工或自动对时策略,对时钟异常电能表通过点对点方式进行时钟复校,复校循环进行直至时钟恢复正常或超过最大复校阈值ΔN。若复校失败,则生成电能表时钟异常告警并上报至主站,便于主站运维人员即时发现和处理该问题。ΔN的作用是在时钟复校循环进行过程中限制任务执行时间,避免在时钟无法恢复正常时陷入死循环。该值一般根据业务需求确定,本文试点的预设值为5 min。该值设置得越大则等待时间越长。
2.3 需量数据采集和处理
计量终端在每日过零点时根据设定的采集间隔读取电表上一日有功需量的负荷记录,然后累加计算形成上一日的日有功最大需量的叠加结果。每月过零点时根据上月每日的叠加结果形成上月的月有功最大需量的叠加结果。
由于所需需量数据采集密度为1 min,频率较高,为提高数据采集完整性,终端需建立补采机制和缺点补数机制。补采机制:1)当日在叠加需量之前至少对上一日缺失的数据进行一次补采。2)主站下发3.1节所述的需量叠加参数后,终端应立即执行抄读当前有功需量负荷记录命令,并在隔天进行计算。缺点补数机制:1)叠加日有功最大需量时,若抄读的当前有功需量负荷记录连续缺点超过指定值,则计算时,终端以最近一个当前有功需量值进行填补,并将计算结果打上异常标识。2)叠加月有功最大需量时,该数据项的异常标识应与该月结算日的日有功最大需量异常标识位保持一致。3)为便于数据核对,终端至少应存储指定天数的叠加组各电表的当前需量负荷记录。对于缺数补点值,只用于计算中,负荷记录存储按实际采集的值进行存储。
2.4 主站抄读量值
计量主站根据表2定义的数据项每天定时抄读上一日的日有功最大需量的负荷记录和叠加结果,每月过零点抄读上一月的月有功最大需量的叠加结果。
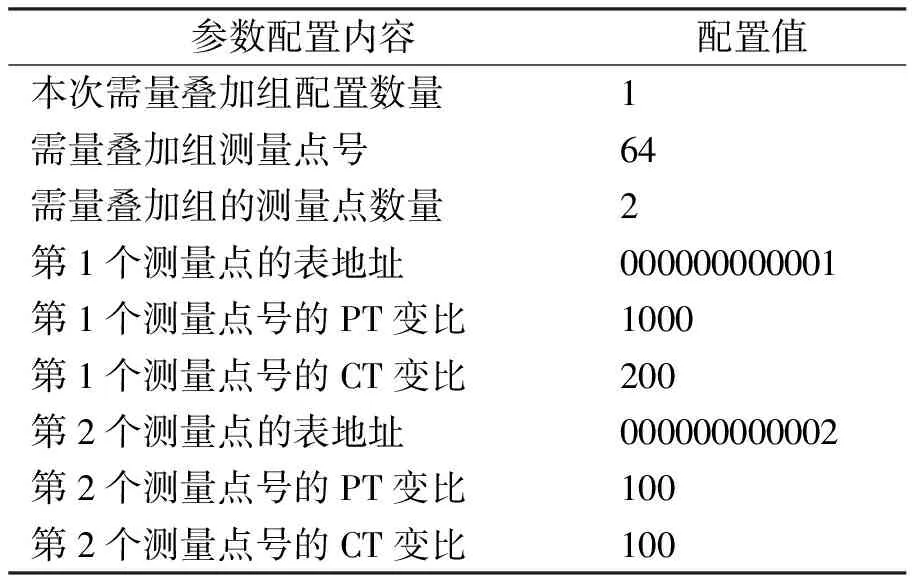
表2 需量叠加参数配置实例
3 案例分析
为比较本文方法与传统方法的效果,以图1中的广西某经营金属加工的专变大用户为例,该用户历年的年用电量约3.5亿kW·h,三回路电源供电,已安装主从表需量采集方案。试验时间为2019年7月~12月,不同方法所得需量数据见表3。
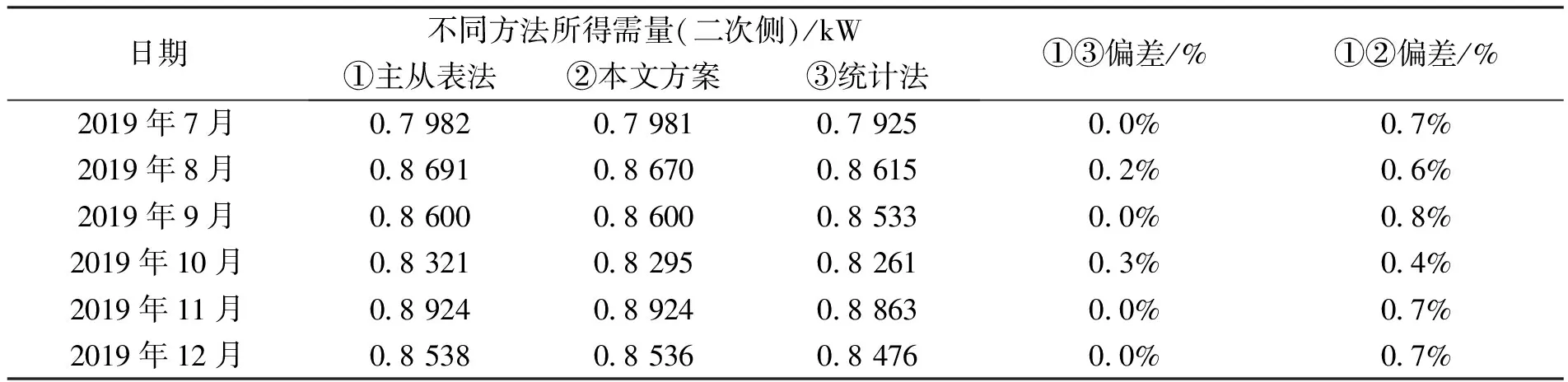
表3 不同方法所得需量数据
以2019年9月为例,表3中,统计法是指通过对计量主站获取的需量数据进行人工分析并进行需量叠加计算。即首先从主站获取该用户当月三条供电线路各自的需量曲线,该曲线上的各点的值为计量点需量周期内的功率平均值。计量主站支持的数据密度为1 h。然后将该曲线上各数据点的需量值按时标叠加,得到叠加曲线,最后确定该曲线上的最大需量值及其出现时间。统计法的结果为,叠加后需量的最大值出现在9月02日21:00至9月02日22:00,对应的最大需量二次值为0.8 533 kW。
按主从表法直接从该用户三条供电回路安装的电表中读取的结果为:叠加后的最大需量二次值为0.8 600 kW,出现在2019年09月02日21:19。从主表读取出的最大需量叠加值的与统计法结果的数值相近,偏差约为8 %,发生时间也落在统计法对应的时间段内。这是由于统计法的采集间隔较大,为1 h,而主从表法的采集间隔较小,为1 min。两者采集到的最大需量值的发生时间不一致,故最大需量值也不等。此外,主从表法与统计法之间均为正偏差,这是由于主从表法的时间颗粒度较细,故能更准确的定位在需量峰值的发生时间,故通常能获取比统计法更大的需量值。
本文方法通过计量终端形成需量叠加结果。以9月的数据为例,相关数据采集报文如下:
1)主站发至终端的报文:
68 1D 00 1D 00 68 4B 00 07 45 C6 E5 12 02 0D 62 80 01 01 00 05 01 20 19 09 00 00 00 20 19 10 00 00 00 07 47 16
主要内容解析:
01 00 05 01 /数据标识,月冻结正向有功最大需量及发生时间
20 19 09 00 00 00 /起始时间
20 19 10 00 00 00 /结束时间
07 /数据密度,1个月
2)终端回复主站的报文:
68 2F 00 2F 00 68 88 00 07 45 C6 E5 12 02 0D 62 80 01 01 00 05 01 00 02 00 00 00 86 00 00 19 21 02 09 19 00 00 24 63 00 00 00 00 76 22 00 00 20 19 09 03 00 00 2C 16
主要内容解析:
01 00 05 01 /数据标识,月冻结正向有功最大需量及发生时间
00 /数据异常标识,00表示数据无异常
02 /需量叠加组的测量点数量为2
00 00 00 86 00 00 19 21 02 09 19 /月冻结叠加正向有功总最大需量及发生时间
00 00 24 63 00 00 /叠加组内表1月冻结叠加正向有功总最大需量值,为0.6 324
00 00 76 22 00 00 /叠加组内表2月冻结叠加正向有功总最大需量值,为0.2 276
20 19 09 03 00 00 /数据采集时间
由上述报文可知,计量主站从终端获取月冻结需量数据的过程为:首先由主站发送报文至终端,该报文按历史月数据的帧格式请求月冻结正向有功最大需量及发生时间数据项,时间范围为2019年9月至10月。然后,终端回复主站叠加组月最大需量值为0.8 600 kW,对应的发生时间为2020年9月2日21时19分,与主从表法的结果一致。从7月~12月方法①③的偏差来看,该时期本文方法的最大需量叠加值与主从表法的偏差不超过4 %,比统计法更准确。存在偏差是由于计量终端是在跨日/月过零点时对电表的需量曲线进行采集,由于该曲线数据密度高,每日有1 440个数据点,数据量较大,在传输过程中易受干扰导致数据缺点,另一方面,需量曲线由于数据量大通常分帧传输,其采集和数据处理时间又常与冻结数据冲突,终端收到电表发送的需量数据时若无暇处理可能会弃帧造成该帧数据丢失。
为说明本文方法的特点和优势,表4将方法①~③的三个评价指标进行比较。由表4可见,方法①由于需额外更换电能表和加装表计二次回路,故设备投资成本高,仅适用于结算台区和计量点较少的情况。从本节三种方法所得需量数据的偏差来看,这些方法所得结果的准确性接近,偏差都不大,准确性基本满足实际电费结算需求。然而,本文方法②和方法①主从表法相比,无需额外更换电能表和加装二次回路,仅需对计量终端和电能表进行软件升级,故成本较主从表法低,且叠加计算过程由分散在各台区的计量终端执行,计量主站直接读取需量统计值,统计工作量小。方法③需对计量主站获取的需量数据进行人工分析并进行需量叠加计算,不仅需对电能表进行软件升级,还将各台区大量的人工统计工作量集中到计量主站,增大了主站的业务压力。故综合来看,本文方法实用性较好。

表4 不同方法的优劣比较
4 结论
设计了一种通过计量终端实现最大需量叠加的方案。并通过IR多层校时策略有针对性的单点校时,提高了表计时钟和需量采集的准确性。案例分析表明,本文方法与主从表法所得月最大需量叠加结果的偏差较小,对多回路供电用户的最大需量计量有较高的准确性。本文方案的应用是对科学、公平的计量多回路供电大电力用户的需量做出的探索。此外,计量终端虽然不是计量器具,但只要证明其采集的月最大需量数据能溯源至相关计量电表即可满足国家对需量结算规定的要求。但该证明过程目前未有完善的解决方案,由此引发的计量纠纷如何解决仍需进一步分析和研究。
