基于组合模型的非线性时间序列预测算法 *
2021-10-26于琼,田宪
于 琼,田 宪
(1.西北工业大学保密处,陕西 西安 710072;2.西安电子科技大学物理与光电工程学院,陕西 西安 710071)
1 引言
时间序列预测作为一种重要的手段对揭示事物发展变化具有重要意义,如在国民经济和生活中有广泛应用的证券市场预测、智能交通预测和气候气象状态预测等[1-3]。现实中复杂系统隐含的时间序列多为在特征上能够既包含确定成分又表现出随机性的非平稳性和非线性的时间序列[4]。传统非线性时间序列预测模型的研究工作主要集中在依靠回归技术进行参数建模[5 - 8],由于需要基于先验知识假设构造相对应的预测模型,训练模型时对原始序列信息的挖掘不充分导致预测精度并不理想。近年来,基于人工神经网络技术构建的模型克服了经典统计学方法中假设过于严格的缺点,被大量运用到非线性时间序列预测领域。如在处理大数据量的复杂系统中求解迅速的最小二乘支持向量机LS-SVM(Least Squares Support Vector Machine)[9]与传统的前馈神经网络相比,具有可求全局最优解的优势并具备良好的泛化能力,且衍生出了不同形式的组合模型。文献[10]构建了蜂群算法与支持向量回归算法相结合的组合预测模型,并验证了该模型在滑坡位移预测中有更高的精度。然而,在面对高复杂系统的时间序列特征提取时,SVM方法由于对信息挖掘不到位仍然难以充分提取原始序列所蕴含的波动模式。
为解决上述问题,本文首先利用经验模态分解EMD(Empirical Model Decomposition)算法对原始序列进行降噪分解,该算法在处理和分辨非线性非平稳时序时比小波分解方法有更强的局部表现能力[11]。在应用EMD对非线性时间序列进行处理方面,文献[12]选取分解后的T个本征模态函数IMF(Intrinsic Mode Function)作为快速震荡部分,将剩余的N-T个IMF和余量(Residue)合并作为趋势部分,然后使用小波神经网络分别对T个震荡部分和合并后的趋势部分建模,建模前虽然对代表趋势的N-T个IMF进行了合并,但对T的选取是凭借经验而未给出具体的方法,其中N表示IMF个数。文献[13]也对经过EMD分解后的IMF进行分类,将所有IMF归为一类选用支持向量回归算法建模,余量rn单独归为一类使用自回归模型建模,由于对所有的IMF均使用了支持向量回归建模,预测结果有待进一步优化。
由上述分析可知,在使用EMD对时间序列分解后,会生成多个IMF,若直接对每个IMF进行建模,最终整个模型会很庞大,导致算法复杂度高且效率明显下降。因此,本文尝试引入赫斯特指数H(Hurst exponent)对时间序列的偏移程度进行有效度量,提出了基于H重构的组合模型的非线性时间预测算法。对重构后的分量构建最小二乘支持向量回归与自回归积分滑动平均组合模型进行预测。优化的组合模型通过对IMF的重构,减少了预测所需要的模型数目,建模的效率得到了大幅提升。
2 基于赫斯特指数的组合预测模型
2.1 经验模态分解
直接训练预测模型,不能充分利用原始序列的隐含信息。考虑到复杂系统时间序列非线性、非平稳且蕴含确定性成分,故选用经验模态分解EMD自适应数据驱动分析算法对原始序列进行处理。EMD算法依据信号的局部时变特征将其分解为一组具有不同特征的子序列,即本征模态函数IMF。IMF必须满足2个条件:在子序列中极值点与过零点的数目必须相等或差值为1;在子序列中局部极小值包络线与局部极大值包络线需关于时间轴对称,即均值为0。这2个条件使IMF能够代表信号不同频率的波动或趋势,相对于其他时频分析方法,可以防止由于依赖基函数带来的先验假设误差,效果有待验证。
原始序列通过图1所示流程,在EMD算法的逐步迭代循环求解过程中得到了平稳化处理,初始IMF的频率比较高,随着不断分解,后续IMF的频率逐渐被削弱,最终提取到原始时间序列特定局部特征且相互之间不存在信息耦合,图1中ci(t)为分解后的第i个IMF,rn(t)为分解n次以后的余量。
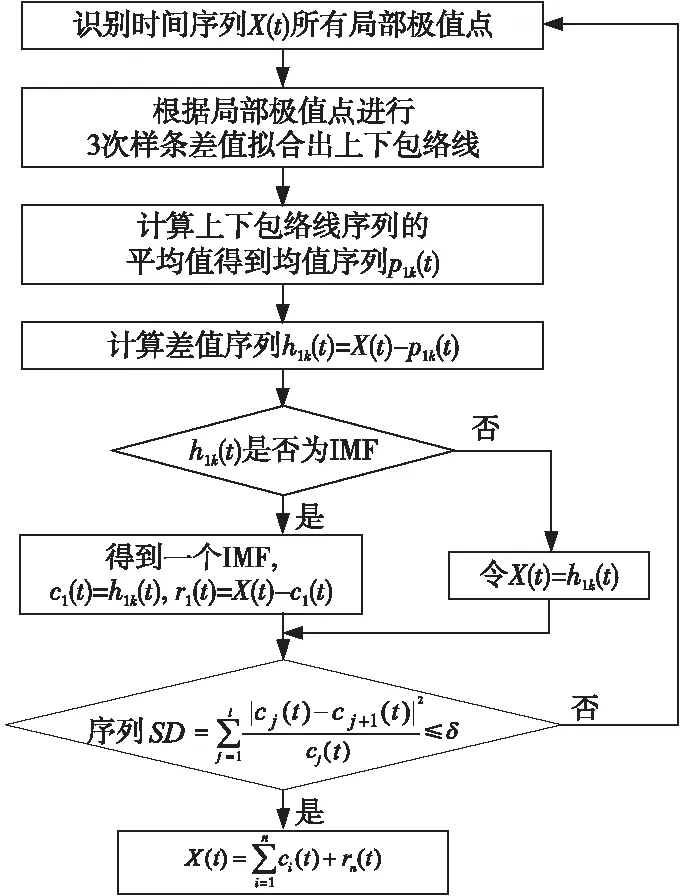
Figure 1 Empirical mode decomposition process of original sequence图1 原始序列经验模态分解流程
2.2 重标极差分析法
为了减少模型输入量,在进行子序列预测之前,需要对提取到的原始序列特征加以处理。综合考虑后,本文选用重标极差分析法R/S Analysis(Rescale Range Analysis)来降低模型复杂度。R/S分析法是一种非参数分析方法,不要求提前假设分布形态,利用其基本原理容易得出自然系统有偏的随机游走的波动规律[14],能够较好地克服聚类等算法的固有缺陷,在解决区分时间序列的游走程度方面优势明显。为此,以时间序列的标准差除极差定义了非参数统计量赫斯特指数H,算法步骤如下所示:
设一时间序列为X={x1,x2,…,xn},将序列X划为A个长度为k的等长子区间Ai(i=1,2,…,A),n=A·k。
(1)对每个长度为k的子区间Ai={xi1,xi2,…,xik}求其算术平均值,如式(1)所示:
xim=(xi1+xi2+…+xik)/k
(1)
进一步得到子区间Ai标准差如式(2)所示:
(2)
(2)对子区间Ai,记第j个元素的累积离差序列Xr,A={x1,A,x2,A,…,xk,A},如式(3)所示:
(3)
其中,j=1,2,…,k,得到区间内极差如式(4)所示:
Rk=max(Xr,A)-min(Xr,A)
(4)
(3)计算A个区间的重标极差平均值Rn/Sn,如式(5)所示:
(5)
其中,n为序列总长度,不同分段方法对应的Rn/Sn不同。
(4)根据研究,Hurst建立的关系如式(6)所示:
Rn/Sn=c×nH
(6)
其中,H为定义的赫斯特指数,c为常数。通过对式(6)取对数,用最小二乘法作回归,得到赫斯特指数的估计值,即为拟合直线的斜率。
引入未来增量与过去增量的长程相关函数如式(7)所示:
22H-1-1
(7)
其中,E{[X(0)-X(-t)][X(t)-X(0)]}表示0时刻,在过去增量分布中含有未来增量的概率。
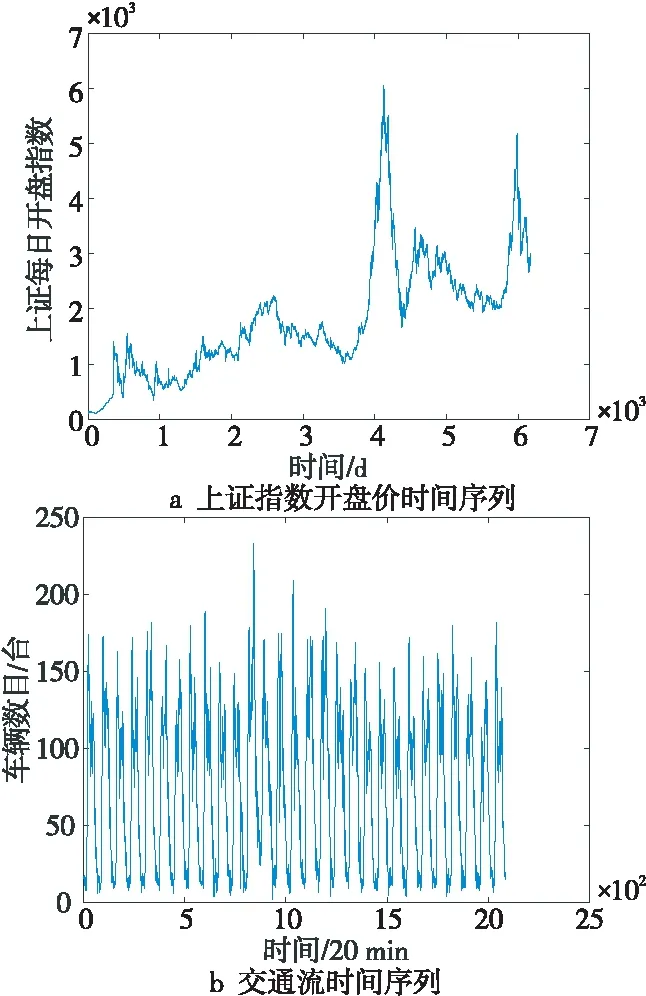
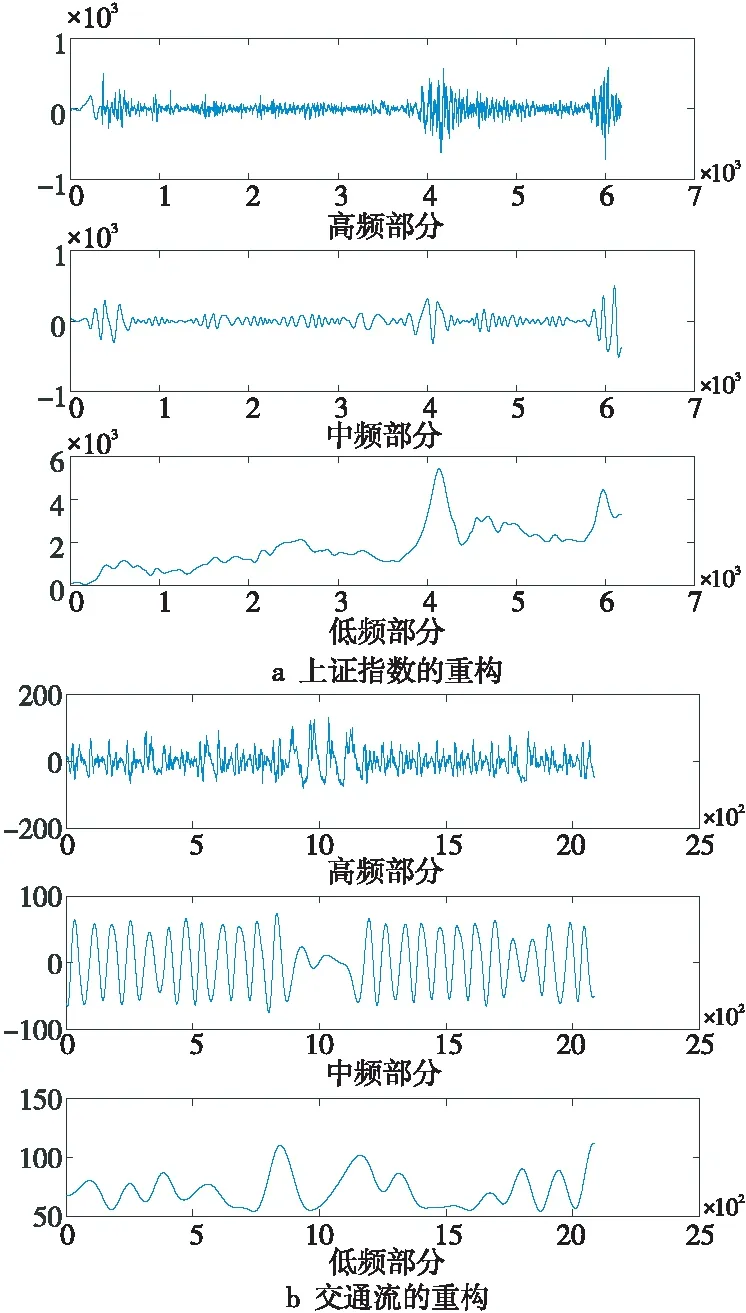
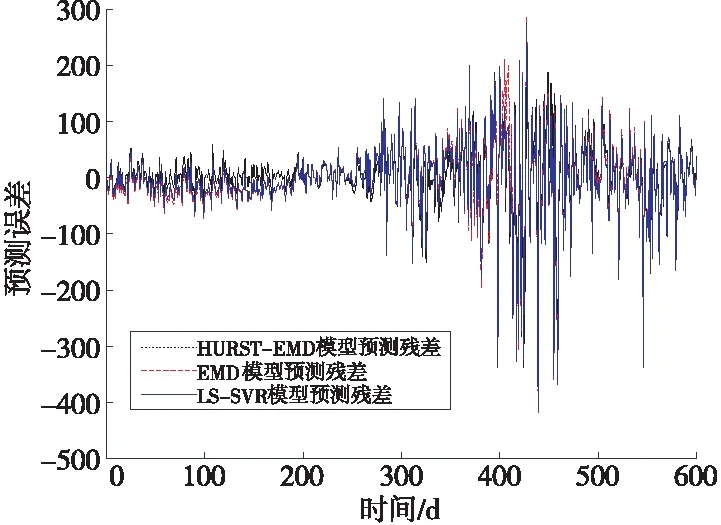
根据式(7)可分析得出,当H的值越接近1/2时,函数表达式的值越接近0,表明时间序列过去波动与未来越不相关,若H=1/2,则说明序列过去和未来不存在相关性,即该时序是一个随机时间序列,可将其舍弃;而当H越接近于1,函数表达式的值也就越接近于1,表明时间序列过去波动与未来越相关。进而,取值在0~1的时间序列赫斯特指数以1/2为界可分为2个特征区间,当0 由EMD算法可知,所有IMF都必须符合代表传统的窄带信号特征和序列内在振动方式局部尺度的2个条件[16],进而提取出原序列的特定波动的模式,得到不同的IMF。为了在充分利用这些原始时间序列特征的基础上优化预测效率,模型引入赫斯特指数对IMF进行重构,整合后的IMF按其特征能够分为非线性和线性部分,为后续选择恰当的算法构建组合预测模型带来了极大的便利。 最小二乘支持向量回归LS-SVR(Least Squares Support Vector Regression)将LS-SVM的思想引入回归函数估计中来解决回归问题。与LS-SVM类似,LS-SVR用误差平方和取代了SVM中的不敏感损失函数且将原始序列在低维空间进行的非线性回归转化为在高维特征空间进行的线性回归,降低了运算难度。文献[17]中的实验说明,当样本数量较少时,采用LS-SVR建模仍然能保持很高的精度。本文利用LS-SVR在解决非线性时间序列复杂度方面能够很好地逼近任意高、中频时序分量的优势,对重构得到的高频和中频部分构建LS-SVR模型进行预测。在建模过程中,LS-SVR的参数可以通过交叉实验优化搜索得出,相比于其他基于核学习的人工神经网络方法,克服了预测结果趋近于局部极小值或过拟合的问题,能够实现高、中频分量全局最优。 而差分自回归移动平均ARIMA(AutoRegressive Integrated Moving Average)模型[18]通过“混合”自回归与滑动平均,能够很好地逼近任意低频趋势分量,针对低频非平稳部分建模,能够实现较好的拟合。本文构建的组合预测模型综合以上算法优点,建模过程如图2所示,本文算法流程如下: (1)提取序列特征。使用EMD将原始时间序列X(t)分解为n个IMF和1个rn。 (2)求解赫斯特指数。按照R/S分析法分别计算n个IMF和rn的赫斯特指数。 (3)重构各IMF。根据赫斯特指数的含义,忽略H取值为0.5的分量,对其他分量进行重构,若H小于0.5,表明序列存在较强的震荡突变型,则重构为高频分量;若H大于0.5且小于0.9,表明序列存在较强的趋势性,则重构为中频分量;剩余H大于0.9的分量由于具有较高的平滑度,则重构为低频分量。 (4)构建模型。使用LS-SVR对高、中频非线性分量建模,用ARIMA对低频非平稳分量建模,确定各模型的参数然后分别进行预测。 The trajectory parameter equation in the XOY system is in the following (5)组合预测结果。采用加权均值形式将各分量的单项预测结果进行融合,本文采用差分进化DE(Differential Evolution)算法从整体解空间中搜索最优的组合权重与各模型的解集成,最终得到预测结果X(t+p)。 Figure 2 Modeling process of combined model based on HURST-EMD图2 基于HURST-EMD的组合模型建模流程 实验选取1990年12月20日~2016年3月28日的上证指数每日开盘数据,共计6 180条样本作为研究对象。其中,前5 580条数据作为训练集,后600条数据作为测试集。股票市场具有较强的波动性,对股票价格预测的研究在时间序列预测中具有代表性。同时为证明算法的有效性,本文选取阿里云提供的2016年9月19日~2016年10月17日的某路段交通流数据进行验证,交通流的采集周期为20 min,共计2 084条。前3周1 580条数据用来训练,最后1周504条数据用来测试。 使用Matlab R2015A对数据进行处理,上证指数开盘数据及交通流数据原始序列如图3所示。 Figure 3 Original time series of Shanghai index opening price and traffic flow图3 上证指数开盘价和交通流原始时间序列 由图3明显可以看出,2个时间序列整体上虽具有一定的趋势性,但没有明显的规律可循,且在短期时间段内又呈现出较大的振荡和波动,即序列是非线性、非平稳的。此外,交通流时间序列还表现出明显的周期性。 采用EMD算法分别对上述2个数据集进行分解,分解后的结果如图4所示。 Figure 4 Decomposition results of Shanghai index opening price and traffic flow by EMD图4 上证指数开盘价和交通流的EMD分解结果 图4中上证指数被分解为10个本征模态函数和1个余量,交通流序列被分解为9个本征模态函数和1个余量。经过经验模态分解后,数据波动具有直观性,各分量最大程度地反映了原始时间序列的特征,且相互之间不同信息的耦合减弱了。 使用赫斯特指数对分解后的IMF进行重构是构造本文改进的HURST-EMD模型的关键环节,依次计算各个IMF和rn的赫斯特指数,求得的结果如图5所示,其中横轴表示分解出的各个IMF及1个余量。 Figure 5 Hurst exponent of IMF and residue图5 上证指数及交通流各IMF及余量的赫斯特指数 Figure 6 Reconstruction of Shanghai index opening price and traffic flow图6 上证指数及交通流的重构 引入赫斯特指数重构后,上证指数及交通流时间序列中具有相似波动模式的IMF分别被整合为3组分量,即剧烈震荡的高频部分,有一定震荡但频率较小的中频部分以及趋势相对平滑的低频部分,减少了预测需要建立的模型数量,提高了预测效率,降低了整个预测过程所需要的时间。 采用LIBSVM工具包里的默认LS-SVR模型对高频分量和中频分量进行预测,使用Matlab自带工具箱econ中ARIMA模型对低频分量进行预测,最终预测结果为3个分量的集成。作为对比,本文分别实现了未经过EMD分解的LS-SVR模型和文献[13]中的传统EMD预测模型,在传统EMD预测模型中将所有IMF作为震荡部分采用LS-SVR进行预测,而余量作为趋势部分采用ARIMA进行预测。各模型预测值与实际值的对比如图7~图9所示。 Figure 7 Prediction results of Shanghai index opening price and traffic flow by HURST-EMD model图7 HURST-EMD模型对上证指数及交通流预测结果 Figure 8 Prediction results of Shanghai index opening price and traffic flow by EMD model图8 EMD模型对上证指数及交通流预测结果 Figure 9 Prediction results of Shanghai index opening price and traffic flow by LS-SVR model图9 LS-SVR模型对上证指数及交通流预测结果 为对预测效果进行量化评估,本文选用均等系数EC、平均绝对误差MAE和均方根误差RMSE3种评价指标对结果进行评价。其中,EC用来表示预测值与实际值的拟合度,值越大说明拟合度越高;MAE主要衡量预测误差的离散程度,值越小说明预测结果越好;RMSE主要衡量预测值与真实值之间的偏差,值越小说明偏差越小。其定义分别如式(8)~式(10)所示: (8) (9) (10) 3种预测模型在2个数据集上预测性能的比较如表1所示。 Table 1 Prediction performance comparison of three models on two datasets 为了进一步说明模型的稳定性及有效性,本文在2004年意大利某市公路氧化钨含量的前5 500条数据及1848年~2015年的2 000条月平均太阳黑子数2个公共数据集上分别采用上述3种模型预测,基于组合模型的HURST-EMD预测的结果如图10所示,3种模型预测性能的比较如表2所示。 观察图7可以看出,HURST-EMD模型除在上证指数数据集上具有较高的预测精度外,也能够应用于交通流数据等周期性波动的非线性时间序列预测,并且预测结果的稳定性和拟合度都比较好,说明本文提出的HURST-EMD模型在更多非线性时间序列预测方面有一定的有效性和适用性。 对比图7a、图8a和图9a中各模型的预测结果可以看出,在对上证指数的预测中,HURST-EMD模型和传统EMD模型的大部分预测值与实际值拟合度较好,而在震荡剧烈的部分,LS-SVR模型预值测有较明显的误差,表现稍逊于经验模态分解处理后的组合预测方法。该结论在周期性变化的交通数据流预测上表现得更加明显。比对图7b、图8a和图9b可以看出,在每个周期的剧烈波动部分,LS-SVR模型预测的预测值与真实值有更加显著的偏差。此外,通过预测结果图的对比还能够看出,在对交通流的预测上,HURST-EMD模型的预测略微优于传统EMD模型的。 对比表1中各量化指标的评估结果,在上证指数数据集上,各预测模型的EC值均高于98%,说明3种模型均具有较高拟合度,但比较平均绝对误差和均方根误差的数值,HURST-EMD模型相对其他2种模型均有所降低,说明采用HURST-EMD模型预测时离散程度低且偏差小,预测效果最好。对比各模型在真实交通流数据集上的预测量化指标,LS-SVR和EMD各指标相近且略逊于HURST-EMD模型,更加说明了HURST-EMD模型在非线性时间序列预测上具有更好的准确性和稳定性。 由图10呈现出的真实值与预测值的对比及表2的各项指标比较结果可以看出,优化的HURST-EMD模型在几个数据集上的预测精度都较高,并且具有较好的稳定性和拟合度。 进一步对各模型在上证指数集上的预测结果进行残差分析,结果如图11所示。很明显地可以看出,在400~500 d的数据点上,LS-SVR模型的残差最大,而HURST-EMD模型的残差较小,更加表明了该模型优异的预测效果。 Figure 11 Residual analysis of three prediction models on Shanghai index opening price图11 3种预测模型在上证指数集上预测结果的残差分析 本文运用经验模态分解理论对非线性时间序列进行分解,提出了以赫斯特指数为依据将各个本征模态函数进行重构的方法。结合重构后各分量表现出的特性和不同算法的优势,挑选出对应的非线性和线性预测模型进行建模,最后组合各模型得到最终的预测结果。主要的创新和成果体现在:(1)采用2组样本进行实验,通过比较预测值与真实值,验证了优化的HURST-EMD组合模型的有效性和适用性。(2)引入赫斯特指数对分解得到的各个IMF进行整合和重构,缩短了建立模型的时间,提高了利用EMD进行非线性时间序列预测的效率。(3)将优化的HURST-EMD组合模型与传统的EMD模型及LS-SVR模型进行实验对比,结果表明该模型比其他2个模型预测效果更好,能够获得更高的预测精度。此外,模型对非线性时间序列的高、中频分量波动性和非线性特征充分刻画的同时能够更好地逼近任意非平稳低频趋势分量,由于重构各分量之间区分度高,克服了其他模型由于过拟合导致预测结果失真等问题,表现出优异的稳定性和准确性,为进一步研究非线性时间序列预测问题提供了参考依据。2.3 构建组合预测模型

3 实验及结果分析
3.1 样本数据说明
3.2 输入模型的训练





3.3 评价指标
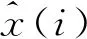

3.4 其他公共数据集上的测试结果
3.5 结果分析
4 结束语
