基于改进YOLOv3的行人检测算法
2021-10-26张立旗肖秦琨韩泽佳
张立旗,肖秦琨,韩泽佳
(西安工业大学 电子信息工程学院,西安710021)
行人检测长期以来一直是计算机视觉与图像处理领域的一个重要研究课题,在无人驾驶、视频监控、智能安检、智能机器人等领域有着广泛的应用。目前针对行人检测问题,国内外学者已经提出了一系列行人检测算法,但是在复杂环境下都不能达到理想的检测效果。
近年来,随着计算机性能的不断提高,基于深度学习的行人检测算法也取得了突破性成果。基于深度学习的检测算法主要分为2 种类型:基于候选区域选择(两阶段)的检测方法和基于逻辑回归(一阶段)的检测方法。基于候选区域(两阶段)检测方法通过利用滑动窗口获取目标建议,然后再通过卷积神经网络进行特征提取,最后利用分类器对特征进行分类识别,典型方法有R-CNN[1]、Fast-R-CNN。这类算法虽然有较高的检测精度,但是检测速度较慢,无法满足实时性要求。基于逻辑回归(一阶段)的检测算法通过预先设置锚框,直接对输入图像通过卷积进行特征提取,然后对卷积图中的锚框进行回归和分类,其典型算法包括SSD 算法[2]和YOLO 系列算法。YOLO 采用雷德蒙 (Redmon)在2015年提出的OverFeat 算法,实现了端到端的训练。YOLOv2 和YOLOv3 在原有的基础上对网络进行了改进,取得了更优的检测结果。YOLOv3 算法仍然存在检测精度低的问题,并且文献[3]~文献[8]中改进方案并未达到较好的检测效果。此外,当前的相关研究仍然无法同时兼顾检测准确率和速度的提升。
综上所述,本文基于YOLOv3 算法为基础,针对小尺度目标漏检率高和检测速率慢的问题提出以下改进:①精简YOLOv3 骨干特征提取网络冗余结构,提出Darknet-41 骨干网络,解决因网络层加深导致的过拟合问题,同时也减少参数量和计算量,提升了对目标的检测速率;②设计新的特征融合结构,在多尺度特征融合的基础上,增强对浅层特征的融合;③改进损失函数以回归更加精确的预测框的信息;④采用改进的非极大值抑制算法Adaptive NMS,自适了对遮挡目标的检测能力。
1 YOLOv3 算法原理
YOLOv3 算法的基本原理就是利用逻辑回归思想获取边界框的位置信息和所属类别信息[3]。YOLOv3 整体网络结构如图1所示。
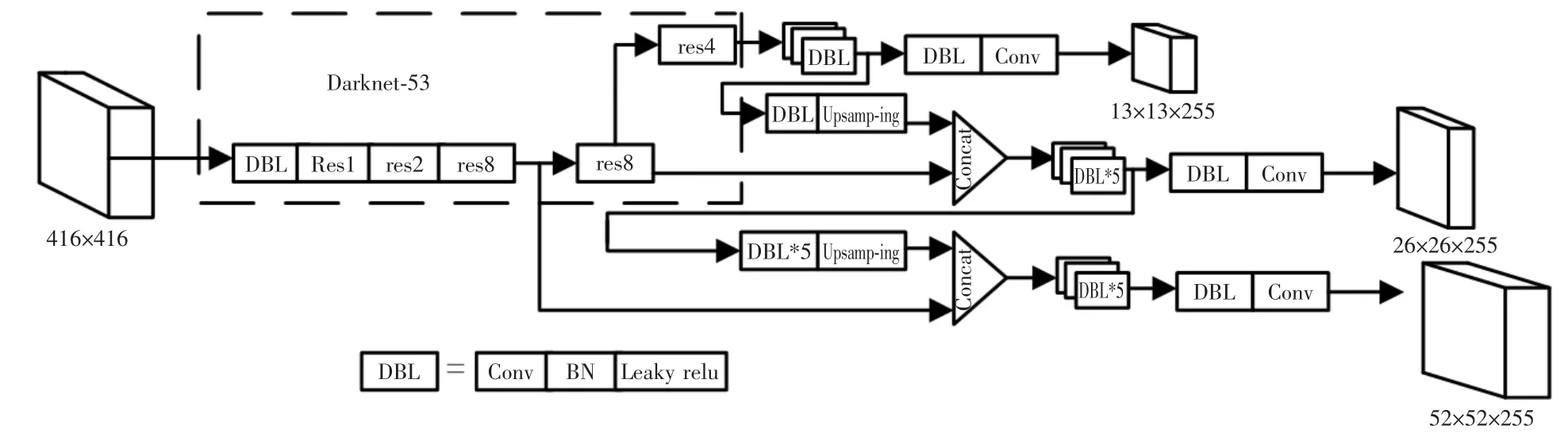
图1 YOLOv3 网络结构Fig.1 YOLOv3 network structure
YOLOv3 网络结构是由特征提取网络Darknet53和检测网络层两部分组成,其中Darknet53 是由53个卷积层和23 个跳跃连接构成[4];检测网络则引入了FPN (Feature Pyramid Networks for Object De tection) 思想,在3 个不同尺度的特征图上进行检测,提升了对不同尺度目标的检测能力。
YOLOv3 算法将输入的图像数据通过特征提取网络的卷积操作划分为S×S 的网格,1 个网格通过3 个锚框对落入其中的目标进行预测,网络的输出大小为S×S×3×(4+1+C)[5],包含预测框的中心坐标和高宽、置信度以及C 个类别概率,最后使用NMS(非极大值抑制) 确定检测目标的坐标信息和类别的预测值。置信度定义如下:
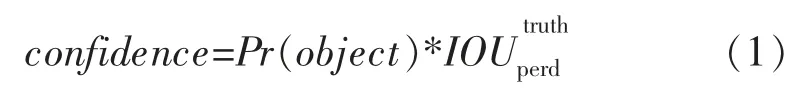
式中:confidence 为预测框的置信度;Pr(object)为网格中某目标的类别概率;为预测框和真实框的交并比。
2 改进的YOLOv3 检测算法
2.1 轻量化的骨干网络
YOLOv3 采用的Darknet-53 骨干网络,共有23个残差块,共53 层卷积层,其利用Resnet 使网络层不断加深来提高准确率,但过深的网络会导致冗余参数、梯度消失和退化等问题,造成网络训练速率较慢和检测精度较低。针对上述问题,本文对骨干网络进行了适当精简。首先通过消融实验对Darknet-53 网络层次敏感值进行分析,然后裁剪敏感值较低的网络层,最后在原网络的基础上裁剪了12 层,并将改进后的骨干网络命名为Darknet-41。改进后的网络结构如图2所示。
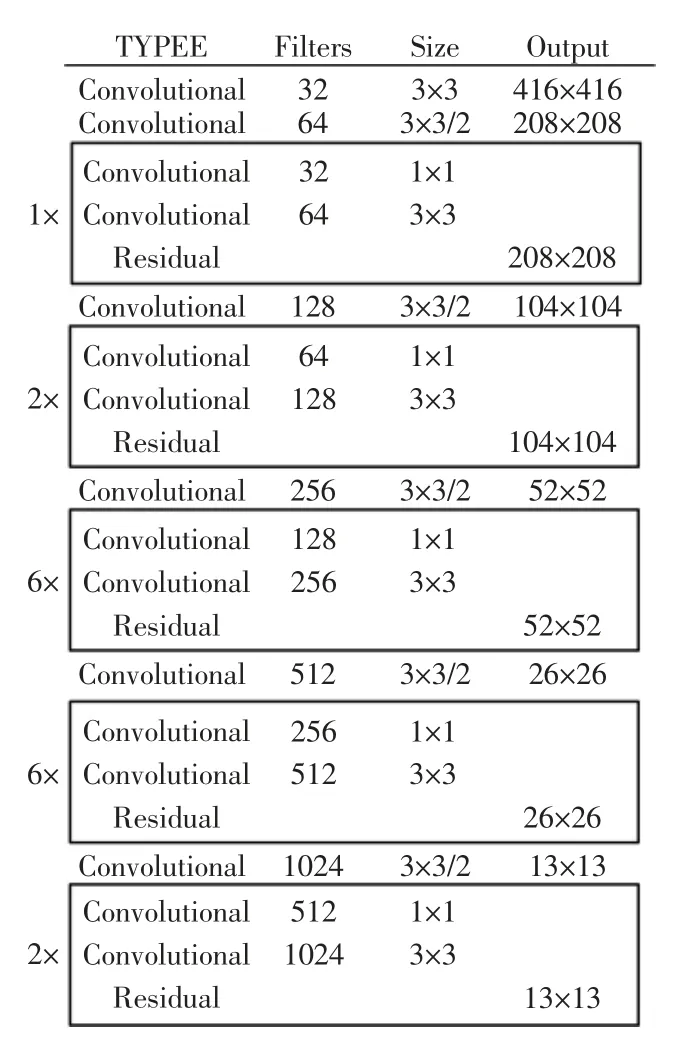
图2 Darknet-41 网络结构图Fig.2 Darknet-41 network structure diagram
2.2 特征融合结构改进
YOLOv3 检测网络采用了FPN(Feature Pyramid Networks for Object Detection)方法,输出3 个不同尺度的特征图,用于不同尺度的目标检测。在目标检测过程中,浅层特征有利于小尺度目标的检测,而深层特征则更有利于大尺度目标检测,由于YOLOv3 算法的检测网络层并没有充分利用浅层特征,因此造成对小目标的检测精度较低。针对上述问题,本文设计了新的检测网络层,加强了对检测目标浅层特征信息的融合。改进的YOLOv3 网络如图3所示。

图3 改进的YOLOv3 网络Fig.3 Improved YOLOv3 network
YOLOv3 会输出3 个检测特征图,其中52×52×256 输出特征图是用来检测小尺度目标,但是由于其没有充分利用浅层特征,导致对小尺度目标的检测精度较低。因此本文引入了第二个Residual Block 提取的浅层特征。首先通过将原输出特征层52×52×256 通过上采样与浅层104×104×256 进行融合,并将104×104×256 作为输出特征图,用于对小目标的检测。通过实验表明通过融入检测目标的浅层特征,提升了对小目标的检测精度。
2.3 非极大值抑制(NMS)改进
YOLOv3 中采用的是非极大值抑制(NMS)来剔除冗余检测框[6],但是非极大值抑制(NMS)会粗略地将目标重叠率比较高的边界框删除,因此会造成有遮挡的行人检测精度较低。针对这一个问题,本文提出了一种Adaptive NMS(自适应非极大值抑制),通过自适应调整阈值的办法,对预测框的选择和提取工作进行自适应调整,减少遮挡目标的漏检问题。改进的Adaptive NMS(自适应非极大值抑制)定义如下:
一个检测框Bi的密度标签定义如下:

根据这个定义,利用以下策略更新修剪步骤:

式中:NM为自适应NMS 阈值;dm表示检测框M 的拥挤度;ci表示临近检测框Bi的得分。
2.4 损失函数改进
YOLOv3 的原始损失函数包含三部分:预测框坐标损失、置信度损失和分类损失,其中边框损失函数采用的是均方误差(Mean Square Error,MSE)损失函数[7]。但是由于MSE 无法准确表达边框之间的IoU 关系,而且不具有尺度不变性,因此本文引进了DIoU loss(Distance IoU loss),其将目标与预测框之间的距离、重叠率和制度都考虑进去,使得边框回归变得更加稳定,并且在与目标框不重叠的时候仍然可以提供有效的收敛方向。LDIoU计算公式如下:
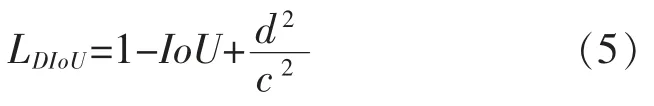
式中:d=ρ(b,bgt)表示预测框与真实框中心点之间的距离;c 表示的是能同时覆盖预测框和真实框的最小矩形的对角线。
由于改进的YOLOv3 算法只检测行人,因此本文提出的算法就直接去掉预测类别损失,从而减少网络输出维度,降低计算量。与此对应,损失函数分别由两部分组成,其计算公式:

式中:Ecoordi表示位置损失;Econfi表示置信度损失函数。
因此通过上述的改进之后的总损失函数如下:

3 实验与结果分析
3.1 实验平台及数据集
本文搭建的实验平台:电脑配置为8 核Intel(R)Core(TM)i7-8750HCPU@2.20 GHz、AG-Forece GTX 1050Ti、8 G 运行内存;软件操作系统为软件操作系统为Ubantu18.04LTS 64 位,程序运行所需环境为Python3.7 版本,并行计算框架版本为CUDA10.0,深度神经网络加速库为CUDNN7.3.4,深度学习框架为Pytorch 1.6.1。
本文采用的数据集为VOC2012,共有11530 张照片。由于VOC2012 数据集中有20 种类别的标签信息,因此需要通过数据清理的方法,仅仅保存为person 类别的标签,然后将清洗后的数据集按照8∶1∶1 分为训练集、验证机和测试集,用于后续的网络训练和测试。
3.2 网络训练结果分析
本文改进YOLOv3 网络结构首先通过加载原YOLOv3 算法在COCO 数据集上得到的预训练权重,然后再通过神经网络的迁移学习[8],加载预训练权重用于后续的网络训练与测试。网络训练的过程中超参数设置如表1所示,最后对训练的结果进行详细分析。

表1 训练超参数设置Tab.1 Training hyperparameter settings
图4为模型训练过程中平均损失变化曲线,可以看出,在进行了15 轮的迭代训练时,loss 迅速下降,而在经过25 轮的迭代后loss 缓慢下降并最终达到稳定,则此时该网络的损失达到最小,网络达到拟合状态。
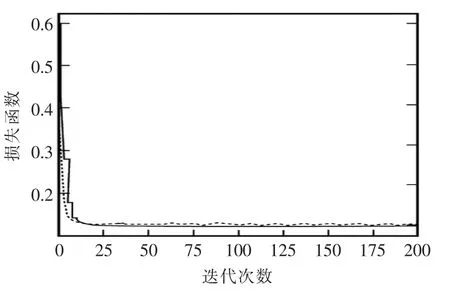
图4 平均损失变化曲线Fig.4 Average loss curve
图5为交并比(IoU)为0.5 以及置信度为0.5的指标下测试均值平均精度(mAP)变化曲线,在进行迭代训练的过程中更新并保留mAP 最高的算法,然后在测试集上测试本文提出算法的检测准确率。由图可知,本文算法的mAP 为93.3%相比YOLOv3算法提升了4.6%。检测速度由48.63 帧/s 提升到57.34 帧/s。
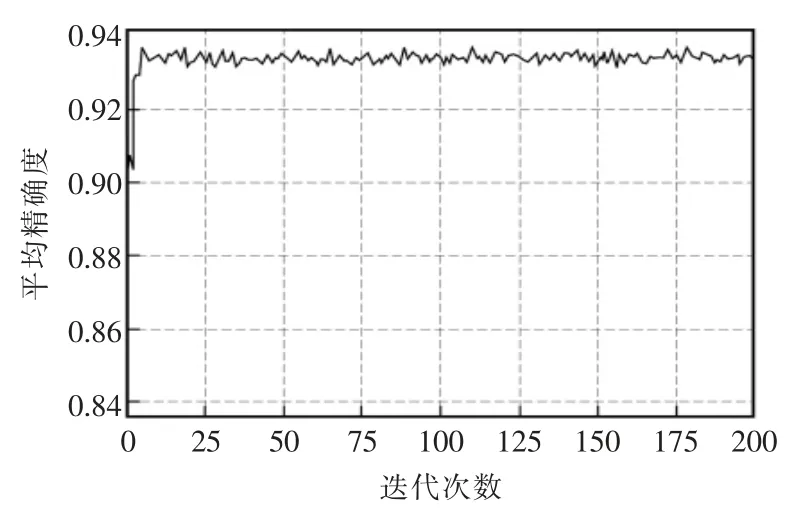
图5 平均精度变化曲线Fig.5 Average accuracy change curve
3.3 实验结果
通过将改进的YOLOv3 的算法对VOC2012 测试集上的行人目标进行检测,部分检测结果如图6所示。检测结果表明,本文提出的算法对小尺度行人目标和遮挡行人目标都具有较好的检测效果。

图6 改进YOLOv3 测结果图Fig.6 Improved YOLOv3 test results
3.4 实验结果分析
3.4.1 消融实验结果
本文算法在YOLOv3 算法的基础上精简骨干网络,降低网络深度,提出Darknet-41 骨干网络;设计新的特征融合结构,通过引入第二个Residual Block的浅层特征;引入了DIoU 损失函数和Adaptive NMS(自适应非极大值抑制)。为了能够更详细地分析本文提出的改进算法对YOLOv3 的产生的影响,分别进行5 组实验,其实验结果如表2所示。
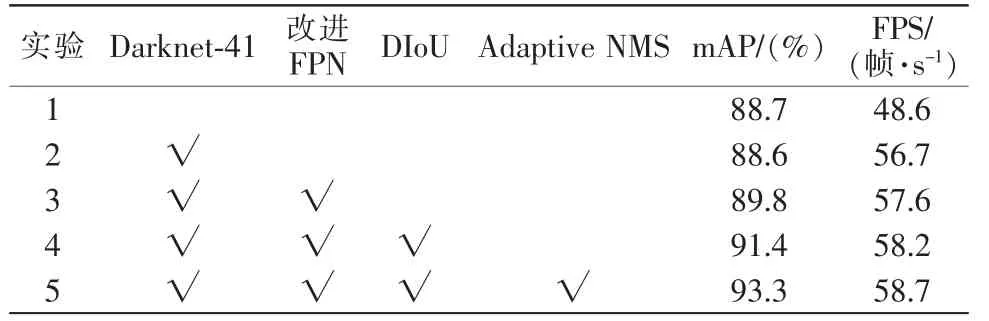
表2 消融实验结果Tab.2 Results of ablation experiments
由表2可以看出,在2 组实验,精简网络结构,在检测平均精度略微受到影响的基础下,检测速率却提升了8.1 帧/s;在第3 组实验,设计了新的FPN结构,通过引入浅层特征,相比第2 组实验结果mAP和FPS(检测速度)分别提升了1.2%和0.9 帧/s。在第4 组实验,通过引入了DIoU 损失函数,使得网络能够回归更加精确的坐标框的信息,相比于第3 组实验结果mAP 和FPS(检测速度)提升1.6%和0.6帧/s。第5 组实验就是利用改进的Adaptive NMS(自适应非极大值抑制),通过自适应调整阈值的办法,对预测框的选择和提取工作进行自适应调整相比较第4 组实验结果mAP 和FPS 分别提升了1.9%和0.5 帧/s。
3.4.2 不同算法实验对比
为检验本文提出改进的YOLOv3 算法的有效性,将本文提出的算法与其他目标检测算法在VOC2012行人数据集上进行训练与测试,并得到平均精度(mAP)、FPS、漏检率等评价指标,如表3所示。

表3 不同算法的检验结果Tab.3 Test results of different algorithms
从表3中我们可以得到本文的算法的mAP 为93.3%、漏检率为6.2%、检测速率达到了58.7 帧/s,相比较YOLOv3 算法的mAP 和检测速率分别提升了4.6%和10.1 帧/s,漏检率降低2.4%。此外,通过对比文献[9]~文献[11]的目标检测算法,可以发现本文提出的算法还是具有更优的检测效果。
图7为YOLOv3 算法与本文提出的算法对相同测试数据集进行测试的部分检测结果。通过对比可以发现,改进后的模型在对小尺度行人目标和发生遮挡的目标进行检测的时候,有效地避免了漏检。


图7 行人目标检测效果对比Fig.7 Comparison of pedestrian target detection results
4 结语
本文提出改进YOLOv3 的行人检测方法,通过对骨干网络进行精简,提出Darknet-41 骨干网络降低网络深度,提升了检测速度。同时改进FPN 层结构,通过引进第二个Residual Block,融合浅层特征,从而提高了该检测算法对中小目标检测的精确度。然后引进DIoU 损失函数,以便得到更加精确的回归框的信息。最后通过改进的Adaptive NMS(自适应非极大值抑制),用于对于预测框的剔除冗余检测框,提高了对遮挡目标的检测能力。最后通过实验发现本文提出的算法具有更优的检测效果。
