基于树型学习算法的短期流量预测研究
2021-10-25李笑雪张思凝王娅娅苗梦凡
李笑雪,张思凝,王娅娅,苗梦凡
(沈阳航空航天大学电子信息工程学院,辽宁沈阳,110136)
0 引言
移动互联网飞速发展,移动流量呈现爆炸式增长,基站的流量预测问题变得越来越重要。为了改善这个问题,需要给基站增加载频的数量来扩容,使基站可以承载更多的流量;另一方面,基站存在潮汐现象,使得在某些时段,用户数量会大幅降低。由于基站数量巨大,无法通过人工实时关注每个基站的流量变化,故需要利用模型对基站流量随时间变化的情况进行预测[1-3]。
目前已有大量研究将树型算法应用于预测领域。极端随机树(Extratrees)模型处理非线性相关数据效果好,在预测超短时负荷过程中应用该模型取得了较好的效果[4]。文献[5]应用了梯度提升树预测写字楼月度用电量,并与差分整合移动平均自回归模型ARIMA、神经网络模型LSTM 进行效果对比,取得了最佳效果。[6]利用装袋算法将弱预测模型训练成强预测模型序列,将Bagging 算法与FNN 算法结合,对日负荷进行预测。实验结果表明模型可以有效地预测96 点日负荷数据,具有工程实用价值。Bagging 集成算法与指数平滑方法相结合的Bagging 指数平滑方法可以准确预测航空客运需求。模型评估结果表明,该方法优于其他传统的时间序列预测方法[7-8]。为了提高模型的预测精度,采用Bagging算法对多个基学习器进行GPR 集成,最大限度地降低了噪声信号的影响,并通过对比分析实验,验证了该方法较之人工神经网络和支持向量机,预测精度更好。为提高白水河滑坡位移预测精度。[9]提出一种新的预测模型,利用融合了Adaboost 算法的模型对波动项进行预测,并验证了模型在位移预测方面的优越性。[10]通过Boosting 集成学习构建了具有较高的预测精度的肿瘤药物敏感性预测模型,并从生物学角度提供了模型可解释性。
上述研究均表明树型算法在预测方向的有效性,而树型算法在短期流量预测领域应用较少,故本文将树型算法应用于短期流量预测领域进行研究。
1 理论与方法
1.1 ExtraTrees
ExtraTrees 回归器算法(ET)是一种集成算法。其基分类器使用全部样本进行训练,为增强随机性,在节点分裂时随机从M 个特征中选择m 个特征,以基尼系数或信息增益熵选择最优属性进行分裂,分裂过程中不剪枝,直到生成一个决策树(基分类器)。利用投票决策对所有基分类器统计产生最终分类结果。
ET 优于贪婪的决策树,在小样本上有更好的的平滑性,能有效降低偏差和方差。
当基分类器的数量M→∞时,对比其他基于树的集成分类方法,ET 更连续光滑。从偏差和方差的角度看,模型的连续性使得目标函数平滑区域的方差和偏移较小,从而使得该区域的模型更加准确。
1.2 Gradient Boosting
Gradient Boosting Decision Tree 简称GBDT,是一种提升的决策树算法。该算法由多棵决策树组成,所有树的结论累加起来做最终答案。
回归树如式(1)所示。
1.3 Bagging
Bagging 是基于自主采样法下并行式集成学习的方式,个体学习器同随机森林一样,互不影响,自主采样法是将含有m 个样本的数据集先随机的抽取出一个样本,将抽到样本放到采集样里,之后再放回原来的集合中以保证该样本在下次还有可能被抽到。经过m 次后,可以获得一个包含m 个样本的集合,这些样本中,初始数据集中的样本,有的会在采样集中多次出现,有的出现次数为0。
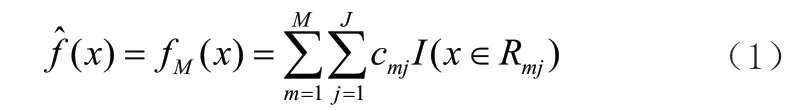
采集T 个含有m 个样本的集合并训练出基学习器,再将这些学习器用结合策略结合起来,这就是Bagging 的基本思想。
Bagging 算法的基本过程:
对于给定训练集D={(x1,y1),(x2,y2),...,(xm,ym)},训练的次数为T,t=1,2,...,T 有:
①对训练集进行第t 次采样,共采集m 次,得到的采样集有m 个样本。
②用采样集训练第m 个个体学习器,如果预测的是分类问题,则从T 个学习器中使用投票法,投出票数较多的几个类别,或者票数最多的某一个;如果预测的是回归问题,则用T 个学习器得到的回归结果进行算术平均得到的结果作为最终模型的输出结果。
1.4 AdaBoost
AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
AdaBoost 是adaptive boosting 的缩写,属于boosting 集成系列算法。AdaBoost 既可以用于分类也可以用于回归。当AdaBoost 用于分类时,它根据每次训练集之中每个样本的分类是否正确,以及上次总体分类的准确率,来确定每个样本的权值。当AdaBoost 用于回归时,则是根据回归误差率等参数来更新每个样本的权重。本文采用AdaBoostR2 算法。
最终的强回归器如式(2)所示。
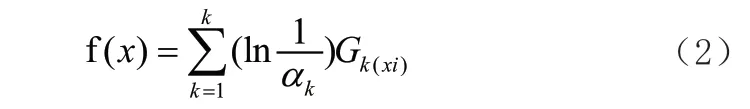
1.5 方法设计
本文采用的方法如图1 所示,为了选择进行流量分析的最佳模型,选用平均绝对误差作为评估标准,用于衡量不同模型的预测准确度。即分别验证ExtraTrees、Gradient Boosting、Bagging 和AdaBoost 四种树型学习算法预测的准确性,通过平均绝对误差(Mean Absolute Error,MAE)值衡量预测结果。MAE 的值越大,模型准确度越低。平均绝对误差的计算公式如式(3)所示。
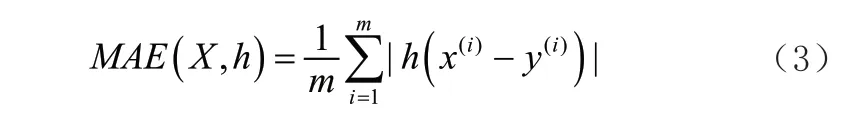
2 实验数据与环境
2.1 数据集
实验引用的数据集为“2021 年MathorCup 大数据竞赛”提供的“某小区上下行流量数据”。
2.2 实验环境
实验的硬件环境为主频3.60GHz,内存32GB 的英特尔i9-9900KF 处理器和NVIDIA GTX 2080Ti 的GPU 计算显卡,软件环境为Python 3.6,TensorFlow 1.14.0。
3 实验结果
使用ExtraTrees 回归器算法对流量预测的结果如图2 所示。从图中可以看出,模型准确地完成了对实际数据的预测。
使用Gradient Boosting 算法对流量预测的结果如图3所示。从图中可以看出,模型完整地对实际数据进行了预测,并且模型的预测准确度较高。
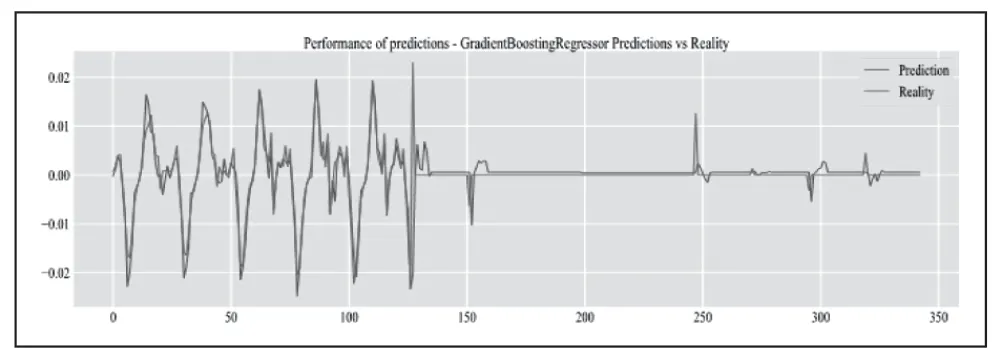
图3 Gradient Boosting
使用Bagging 算法对流量预测的结果如图4 所示。从图中可以看出,模型完成了对实际数据的预测,并且模型的预测准确度较高。
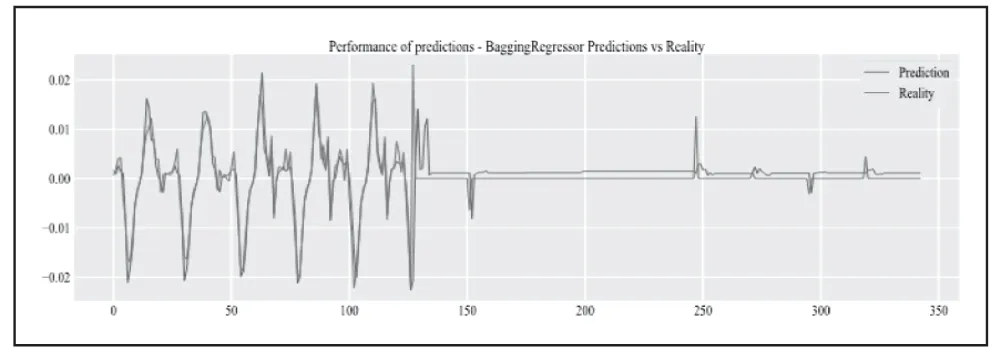
图4 Boosting 回归器预测结果
使用AdaBoost 算法对流量预测的结果如图5 所示。从图中可以看出,模型对实际数据预测的准确度较高,较完整地预测出流量的变化。
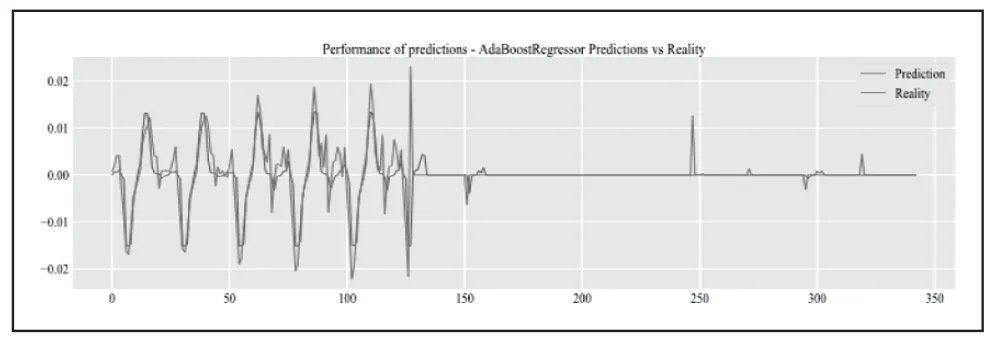
图5 AdaBoost 回归器预测结果
MAE 值如图6 所示,由图可知,ExtraTrees、GradientB oosting、Bagging、AdaBoost 的MAE 值依次为:0.00175、0.00132、00017、0.00144。其中GradientBoosting 模型MAE值最小,模型准确度最高,故本文将采用GradientBoosting模型进行流量预测。
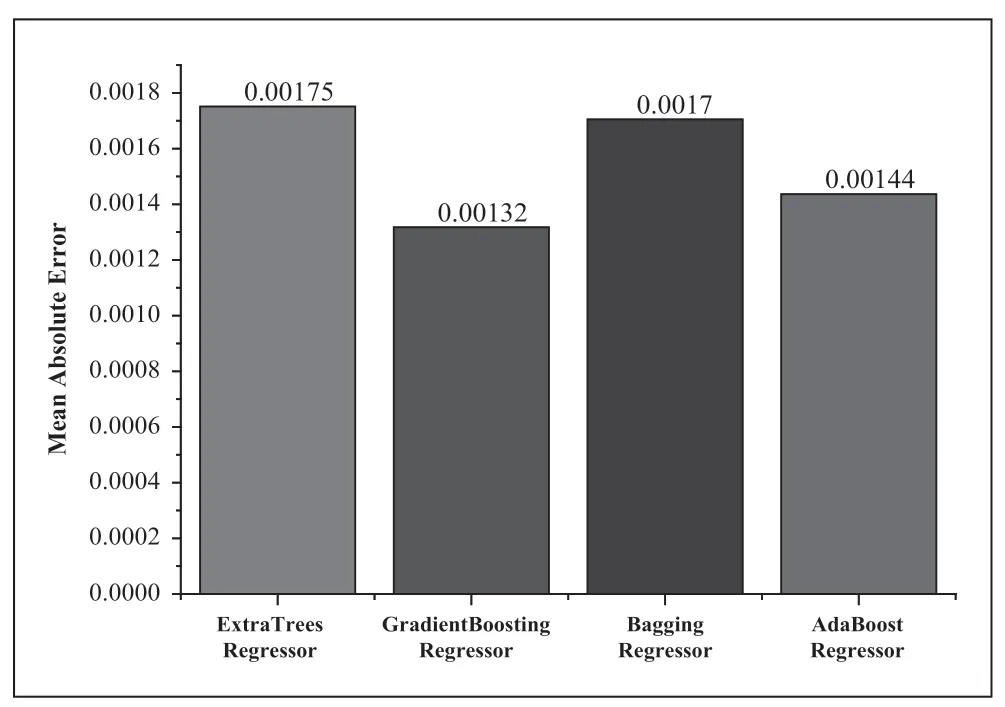
图6 四种算法的MAE 值
基于GradientBoosting 模型对流量的预测结果如图7所示。蓝色部分表示训练值,黄色部分表示预测值,预测结果有较高的可靠性。
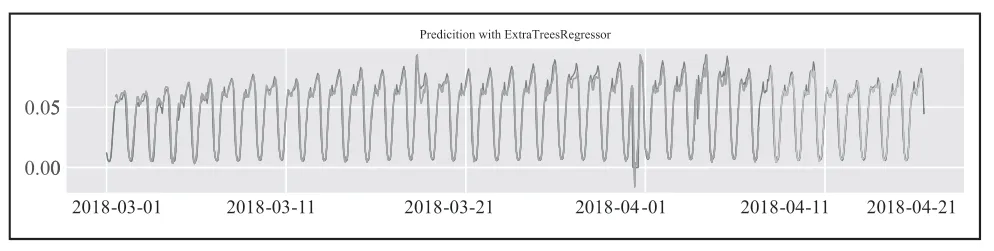
图7 GradientBoosting 模型的预测结果
4 结束语
针对短期预测问题,本文利用MAE 比较了ExtraTrees、Gradient Boosting、Bagging 和AdaBoost 四种树型学习算法在数据集上预测的准确性,实验结果表明GradientBoosting 模型的MAE 值最小,模型准确度最高,故应用GradientBoosting 模型进行了短期流量的预测,有效的提高了预测准确度。
