基于社交网络信息的用户抑郁症倾向识别
2021-10-21刘定平张雪燕
刘定平 张雪燕
(河南财经政法大学统计与大数据学院,河南郑州450046)
一、引言
抑郁症是常见疾病,由此产生的心理障碍会对人体产生较大影响,轻症者会减弱对学习和工作的兴趣,导致学习能力和工作效率降低;重症者可能会丧失生活的动力,甚至萌生自残、自杀念头。根据世界卫生组织2019年底发布的报告,抑郁症的发病率仅次于世界第一大严重的缺血性心脏病,在世界排名前十位的使人丧失劳动能力的疾病中,抑郁症甚至名列首位,这无疑成为社会安定的巨大隐患。截至目前,全球已有超过2.64亿抑郁症患者,每年自杀身亡者高达80万人。其中,中国的抑郁症患者达9000万,占比超过全球抑郁症患者总数的34%。由于抑郁症患者的病耻感以及大众对抑郁症的污名化,使这种敏感性疾病的识别率仅为21%,在仅有的已识别的患者中,主动接受干预和治疗者更是少之又少。这是抑郁症诊疗和研究面临的主要障碍,也是当前亟待解决的问题。
随着社交网络的迅速发展,在社交平台上分享情绪逐渐成为年轻人热衷的新潮流,其中不乏大量的抑郁症患者。作为深受国民喜爱的微博社交平台,是大量用户发表言论和与人互动的场所,微博平台每天都充斥着丰富的信息动态,深入挖掘抑郁用户在微博平台的网络轨迹,无疑为抑郁症的识别提供了新的思路。
二、文献综述
对于抑郁症的检测,最直接的方式莫过于早期的心理量表测评,刘芳宜(2012)等将汉密尔抑郁量表、Zung抑郁自评量表以及罗马心理社会警报问卷三种心理测评量表应用于受试者的问卷调查,根据受试者对问题的回答情况判定其抑郁与否。
此外,也有相当一部分学者从生物学角度出发,通过抑郁症患者的脑网络信号(沈潇童,2020)、面部动态特征(安昳,2020)以及眼部动态特征(袁一方,2020)提取相关信息,构建抑郁症识别分类模型。上述方式对于主动参与抑郁症检测的患者群体固然有效,但面对庞大的畏于主动就医的抑郁症倾向群体却显不足。国外学者首先提出通过社交网络媒介进行抑郁症倾向识别,William(2015)以抑郁症患者的Twitter文本为数据集,通过建立主题模型对抑郁症患者和非抑郁症患者的语言信号进行分析。目前国内的研究多基于社交网络平台微博的数据,Li Genghao(2020)提出一种构建抑郁症领域词汇的有效方法,该词汇包含丰富的语言特征,可以帮助识别潜在患有抑郁症的社交媒体用户。方振宇(2017)基于微博用户的文本信息,采用基于扩展的抑郁词典的特征统计法以及基于词向量构建用户向量的方法,通过深度学习工具word2vec训练对抑郁用户和非抑郁用户进行识别。
观察发现,学者对社交网络用户的抑郁症识别大多立足于用户的语言特征,通过文本挖掘技术进行情感分析,进而达到分类目的。然而用户的个人信息以及与他人互动的相关特征似乎被学者忽略,本文通过抑郁症患者在微博平台的多方面表现,对抑郁症患者进行表征提取,确定特征向量后,从构建抑郁指标体系和统计识别模型两个角度出发,开展社交网络用户抑郁症倾向识别研究。
三、抑郁症的表征
(一)数据获取
本文数据均基于微博爬虫技术,通过提取用户相关信息,建立抑郁用户与非抑郁用户数据集。微博平台为有共同兴趣的人提供一个交流的社区并命名为“××超话”,本案例测试集中抑郁用户的选取将从“抑郁症超话”社区入手(见图1),该社区设立初衷是探讨抑郁症的预防以及为抑郁症患者提供治疗过程的分享平台,越来越多有抑郁倾向用户将该社区当作树洞宣泄自己的情绪。超话建立至今,拥有27.2万粉丝,发帖量达65.7万,阅读量超23.7亿,足见抑郁症群体的庞大。

图1 新浪微博抑郁症超话社区
通过对该社区帖子的爬取,初步获取抑郁用户的ID、性别、年龄、所在地、关注数以及粉丝数等基本信息。通过数据预处理,剔除性别、年龄及所在地有缺失的用户,最终定位到50名抑郁用户。由于抑郁症为长期存在的疾病,因此在对抑郁用户的微博内容进行抓取时将时间设定为1年,起止时间为2020年1月1日至2021年1月1日。对于非抑郁用户的选取,则采取在搜索栏里输入积极情感词汇的方式进行定位。为与抑郁用户的数据集进行匹配,非抑郁用户同样进行筛选后定位到50名,并对其相应时段的微博文本进行抓取。
(二)特征提取
1.抑郁用户画像分析
(1)个人信息
微博用户的资料栏包括个人基本信息、联系信息、职业信息、教育信息以及标签信息,结合数据的完整性和有效性,本文选定基本信息中的性别、年龄、所在地3个指标作为研究对象,其中年龄指标由资料栏中的生日信息推算求得。获取到相关数据后,针对抑郁用户、非抑郁用户在上述指标的表现差异进行对比分析。
性别特征。分别计算男性、女性用户中有抑郁倾向和无抑郁倾向的比例得到图2所示结果,直观看,女性群体中有抑郁倾向用户占比高达61.54%,男性用户中有抑郁倾向的仅占28.57%,这一特点与流行病学相关研究结论一致。流行病学研究表明,女性抑郁症患病率通常是男性的两倍,究其原因,除了性别差异带来的大脑功能差异外,生理原因是女性更容易得抑郁症的重要因素。与男性相比,女性更容易产生敏感和不稳定情绪,因此在遇到挫折时受到的影响更大,进而容易引发抑郁。

图2 抑郁症倾向的性别差异
年龄特征。观察抑郁用户的年龄分布图(见图3)可以发现,抑郁用户的年龄近似服从正态分布,并集中在20岁左右的大学生群体,最低年龄为15岁,发病呈显著低龄化。研究表明,大学生群体面临的来自同龄人的竞争更为激烈,这同时给他们带来多方面的压力。据《2020中国大学生健康调查报告》显示,将近90%的大学生在最近一年内产生过心里困扰,产生诱因比例计算如表1。

图3 抑郁用户年龄分布图

表1 大学生心理困扰诱因
由表1可知,大学生的心理困扰包括学业、人际关系和工作规划,其中学业压力是最令大学生不安的因素。学业成绩是衡量学生优秀与否的重要指标,因此落后的恐惧心理时常萦绕;其次是人际关系和性格问题,大学时期的人际交往比以前更为复杂。除与同学交往外,还有来自社团和学生工作的老师,如何正确处理这些关系是大学生需要思考的问题。倘若这些困扰和焦虑不能得到及时排解,势必导致大学生长期处于负性情绪之下,增加患抑郁症的概率。
地区特征。抑郁用户在我国东南部地区的分布较为突出,尤其是广东省、上海市、山东省和浙江省,中部地区次之,西北、西南和东北部地区几乎没有涵盖入内。这与我国经济发展的空间分布特征极为相似,经济高速发展的地域生活节奏较快,高压强迫下的群体易拥有持续紧绷的状态,出现错误导致的打击也随之严重放大,引发患病。
(2)与人交往
作为社交工具的微博平台给用户提供了多种沟通交流方式,用户可以关注自己感兴趣的博主,点赞、评论和转发喜欢的微博内容,同时粉丝数也会随着活跃度的提高而增加。为考察抑郁用户与非抑郁用户在与人沟通交往方面的差异,对爬取的用户微博进行获赞数、转发数和评论数统计,同时记录用户的微博关注数和粉丝数,得到表2所示结果。

表2 抑郁用户与非抑郁用户与人交往方面的差异
通过抑郁用户和非抑郁用户在关注数、粉丝数、获赞数、转发数和评论数的对比数据,可以清楚感知到抑郁用户在与人交往方面存在的缺失。很多抑郁症患者习惯于把自己的感受放在内心世界,不愿抽离出自己营造的幻想,躲在自认为的保护圈中难以自拔。当他们过多关注自身的情绪却不愿与人倾诉排解时,势必会引起一些不必要的负性思维。
2.抑郁用户微博内容信息提取
(1)发博时间
整理爬取的抑郁用户微博时发现,许多用户发博时间为凌晨12点之后,将抑郁用户和非抑郁用户的发博时间汇总成图4所示的折线图,对比二者一天内发博频率可知,抑郁用户在0:00-6:00为发博活跃度较高的时段,第二个小高峰在18:00-24:00,相比之下非抑郁用户的活跃时段多集中在18:00-24:00,在0:00-6:00几乎没有分布。结合抑郁症患者的相关症状不难理解,抑郁症患者典型症状之一为失眠,多方面压力导致的焦虑使患者产生睡眠障碍,加之不愿与人沟通交往,抑郁情绪难以排解,只能把社交平台当作树洞加以宣泄。因此,统计0:00-6:00之间微博用户的发博率是区分抑郁用户和非抑郁用户的重要指标。

图4 抑郁用户与非抑郁用户发博时间差异
(2)微博文本

图5 抑郁用户词云图

图6 非抑郁用户词云图
对比抑郁用户和非抑郁用户微博内容词云图,初步发现抑郁用户微博关键词多为言辞偏激的负性词汇,包括“抑郁症”“失眠”“好累”“想死”等,除此之外,一些第一人称表述词如“我”“自己”也有较高的词频,这与抑郁症患者对自身关注度较高有着密不可分的联系。非抑郁用户的关键词词性多为中性或积极情感词,极少数为消极情绪词。因此通过计算用户微博内容中具有区分性的词汇的频率,以期找出判断抑郁与否的重要指标。
关键种子词提取。种子词是可以代表特定领域的词。为了在抑郁和非抑郁数据集中提取关键种子词,我们利用了算法,这是一种广泛应用于自然语言处理的特征提取算法。它的基本思想是,如果某个词在一篇文档中出现的频率高,并且在语料库中其他文档中很少出现,则认为这个词具有很好的类别区分能力。Salton和Yu首先提出了算法,Salton等证明了该算法在信息检索中的有效性。词频(Termfrequency,TF)是指一个字或词在一个文档中出现的次数,而逆文档频率(inverse document frequency,IDF)是指一个词在所有文档中出现的频率,衡量的是该词在整个语料库中的特异性。
TF和IDF的计算公式如下:
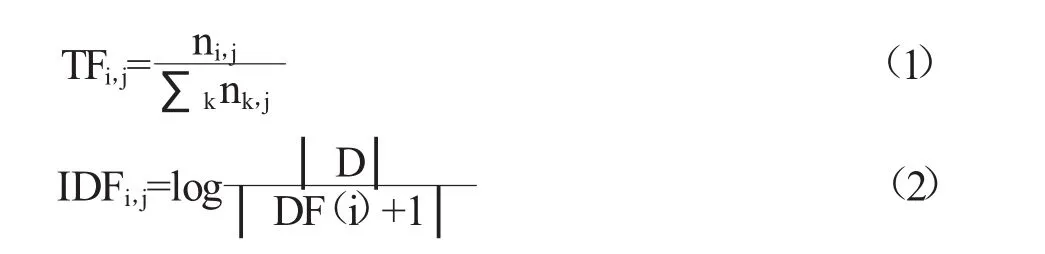
其中ni,j是文档 j中词汇i的数目,k是文档j中的词汇数,D是文档的大小,DF(i)是出现过词汇i的文档数。TF-IDF计算公式如下:

直观来看,TF-IDF的计算表达的含义是一个给定的词在语料库中的重要性和特殊性,TF-IDF值越高,对某一特殊领域的代表性越强。分别从某抑郁用户与某非抑郁用户的微博内容中计算出的TF-IDF值如表3、表4所示。

表3 某抑郁用户关键词词频
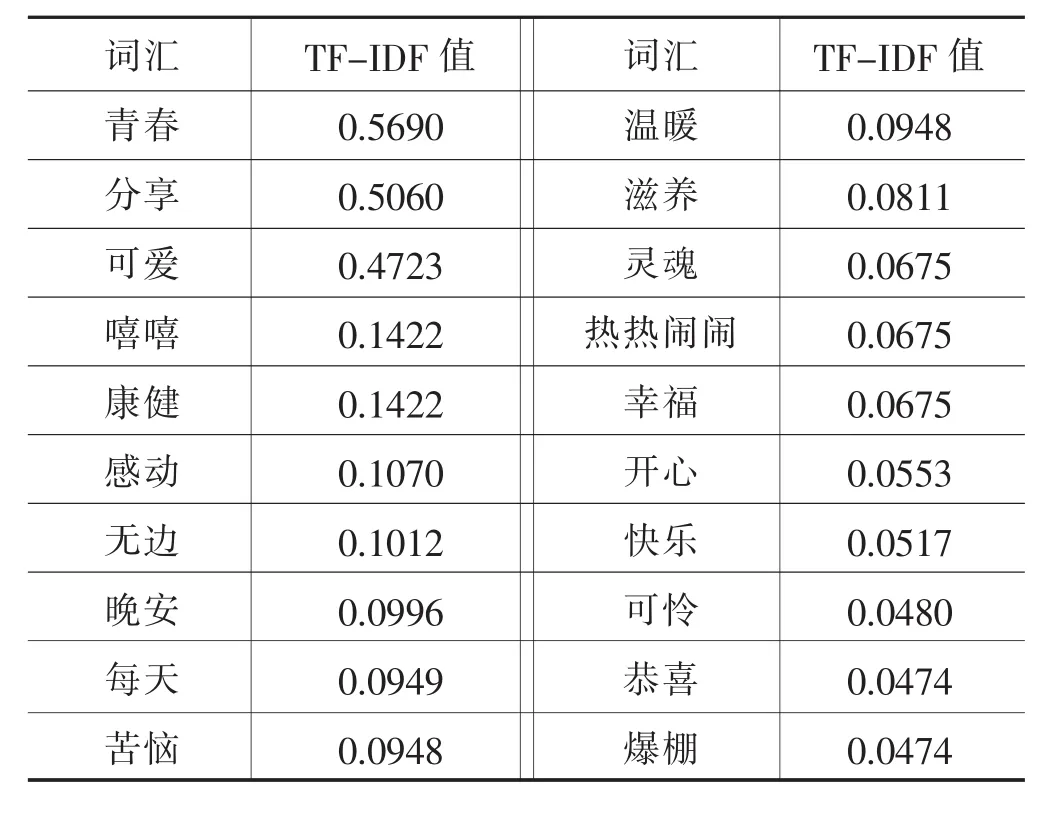
表4 某非抑郁用户关键词词频
指标提炼。通过对抑郁用户和非抑郁用户微博文本的信息提取,发现抑郁用户在第一人称词汇的使用上较为频繁,因此将文本中出现频率较高的“我”与“自己”两个关键词的词频进行加总,作为“第一人称使用频率”指标用于下文的分类特征。针对抑郁用户文本中负性词汇较多这一特性,传统的只含有正向情感词和负向情感词的情感词典难以将抑郁用户与非抑郁用户区分开来,因此本文选用对外经贸大学与美国纽约哥伦比亚大学联合实验项目建立的抑郁词典作为匹配基准,将用户微博文本中出现频率最高的前20个抑郁词汇的词频进行加总,作为“抑郁词汇使用频率”这一特征变量。
四、抑郁症的识别
(一)分类模型指标确立
通过对抑郁用户与非抑郁用户在社交网络上的不同表现,对抑郁用户的识别有了初步的认知,而对抑郁用户与非抑郁用户在个人信息、与人交往以及微博内容3个方面的信息进行提取和分析后,得到表5所示的11个特征变量,其中“所在地”属于分类型变量,若与性别做相同的哑变量处理,会增加特征变量矩阵的稀疏性,因此用所在地2020年GDP数据代替“所在地”指标下的分类数据,将其转化成数值型变量纳入统计识别模型。本文在对微博用户进行抑郁症倾向识别过程中拟从统计指标体系法和机器学习法两种思路展开。
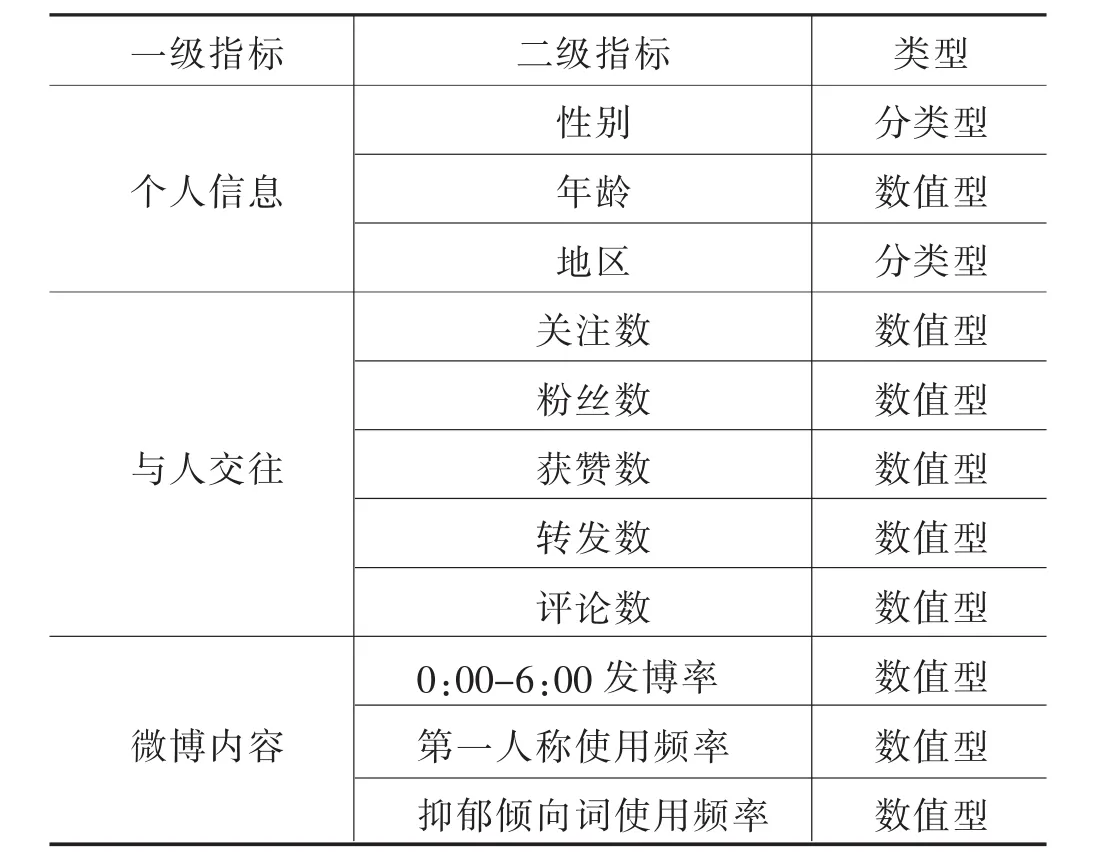
表5 特征变量筛选
(二)分类模型方法选择
1.指标体系法
指标体系法将与研究对象密切相关的指标纳入综合评价,计算综合指数设定阈值,对目标变量进行划分。本文选用Topsis距离综合评价法对社交网络用户抑郁症倾向指数进行测算,其基本原理是通过检测评价对象与正负理想解之间的加权欧式距离,得出评价对象与正理想解的接近程度,以此作为各评价对象优劣的依据,若评价对象最靠近正理想解同时又最远离负理想解,则为最优。其中正理想解是一种设想的最好解,其各指标值都达到各评价指标的最优值。负理想解是一种设想的最坏解,其各指标值都达到各评价指标的最差值。在对微博用户抑郁倾向值进行测算时,通过建立指标体系对各指标数据进行处理,确定指标权重后计算抑郁症倾向指数,进而对抑郁用户和非抑郁用户进行区分。实施过程如下:
为排除各评价指标之间因数量级和量纲的不一致性所带来的影响,首先需要对指标数值进行标准化处理得到x'ij,通过熵权法计算出各指标权重wj后构建加权矩阵:

通过各指标权重计算(表6)可以发现,与人交往方面的指标对抑郁症用户影响最为显著,社交平台本就是用户沟通交流的重要渠道,时常使用社交平台但鲜有互动信息的用户显然值得关注。此外,个人信息方面的指标对抑郁症用户的影响效果高于微博内容,表明在抑郁症识别模型中仅考虑微博用户的文本信息远远不够,需加入个人信息以及与人交往环节的相关指标综合考量。

表6 特征变量权重计算结果
最终测算出的用户抑郁症倾向值如表7所示。观察抑郁倾向值计算结果可以发现,抑郁用户的倾向值大多高于0.3,非抑郁用户的倾向值大多低于0.3,因此猜测阈值集中在0.3附近。

表7 部分抑郁用户与非抑郁用户抑郁症倾向值测算结果
分别选取阈值为0.2、0.3和0.4进行准确率测度。这里准确率的计算公式为:

其中TP为将正类预测为正类数,TN为将负类预测为负类数,FP为将负类预测为正类数,FN为将正类预测为负类数。因此准确率的测度同时包括正确预测为抑郁用户和正确预测为非抑郁用户的概率。通过对不同阈值的设定发现,当阈值设置为0.3时,预测准确率最高,因此将其作为抑郁用户和非抑郁用户的倾向值分水岭,若抑郁倾向值高于0.3,则认为该用户具有抑郁症倾向,若抑郁倾向值低于0.3,则认为该用户不具有抑郁症倾向。

表8 不同阈值下准确率测算
2.机器学习分类法
运用机器学习法建立分类器对抑郁用户进行识别时,初步拟采用单个学习器分类,分别是K近邻、支持向量机、朴素贝叶斯和决策树算法,通过观察准确率的表现可以发现,朴素贝叶斯分类器相较其余三个分类器效果较好,但准确率相较距离综合评价法略显不足,为了提高分类器算法性能,采用集成学习的方式继续研究。
集成学习通过建立多个学习器来完成学习任务,以期达到“博采众长”的效果。当许多弱学习器被正确组合时,能得到更精确、鲁棒性更好的学习器。Xgboost极端梯度提升算法是一种常用的集成学习算法,将多个决策树结合起来形成一个强大的学习系统。CART(回归分类)树通过加性模型得到组合,进而做出共同的决策。XGBoost的结构如图7所示。

图7 XGBoost结构示意图
尽管在一些如图像、文本等的非结构数据的预测问题中,人工神经网络的表现较优,但在处理中小型结构数据或表格数据时,基于决策树的算法略胜一筹。XGBoost算法借助梯度提升(Gradient Boost)框架,在不断添加树的同时,通过共享属性以生长树。每次添加一棵树实际上就是学习一个新的函数来适应上一次预测的残差部分。事实上,根据样本的特征会在每棵树的相应叶节点上得到一个得分。最后只需将每棵树的相应得分相加,就可以得到样本的预测值,预测函数见式(9)。

其中,wq(x)为叶子节点q的分数,(x)为其中一棵回归树。
XGBoost目标函数由两部分构成,第一部分用来衡量预测值和真实值之间的差距,也即损失函数,一般为均方差函数。另一部分是正则化项,与树的复杂度有关,同样包含两部分,T表示叶子结点的个数,w表示叶子节点的分数。γ可以控制叶子结点的个数,λ可以控制叶子节点的分数不会过大,防止过拟合。目标函数定义如下:

为使目标函数最小,XGBoost对损失函数进行了二阶泰勒展开,经过改写后得到最优的树结构:

经计算可对每个用户进行得分评价,分类时采用机器学习默认阈值0.5进行分割,部分用户分类结果如表9所示。

表9 XGBoost集成学习器分类结果
与单个学习器以及TOPSIS距离综合评价法计算结果相比,XGBoost算法在准确率的计算上有显著提升(见表 10)。
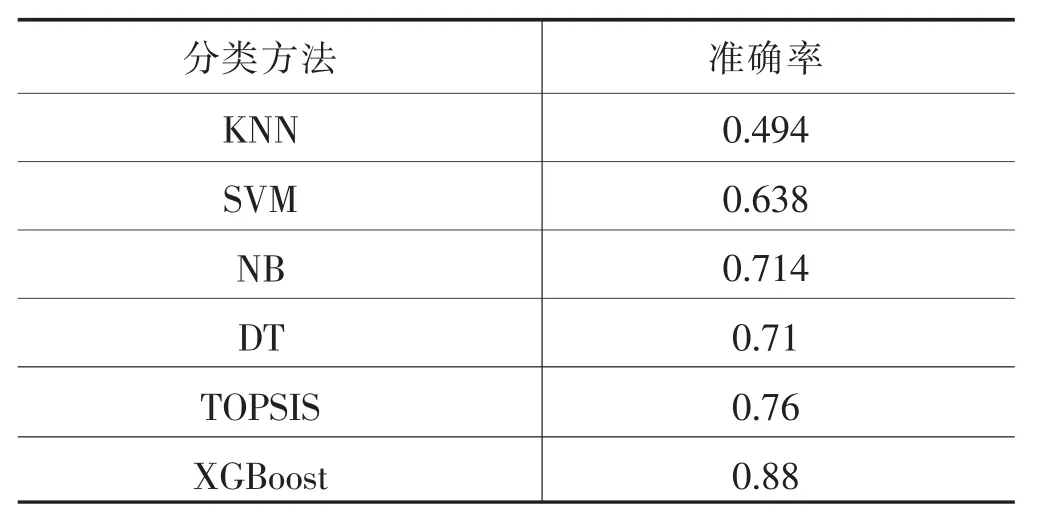
表10 各分类方法准确率对比
同时,XGBoost模型对影响抑郁症倾向的重要特征进行筛选,最终得到6个对抑郁症倾向影响较为显著的变量,重要程度依次为第一人称使用频率、转发数、抑郁倾向词使用频率、获赞数、0:00-6:00发博率和年龄(见图8)。

图8 影响抑郁症倾向的重要特征筛选
五、结论
学者利用社交网络信息进行抑郁症识别研究时,充分利用到用户的微博文本特征进行深入挖掘。而本文在此基础上,增加用户个人信息和与人交往方面的考量。通过对抑郁症倾向用户在个人信息、与人交往以及微博内容相关变量的提取,初步勾勒出抑郁用户的行为特征。研究发现,抑郁用户多集中于经济较为发达地区的女性大学生群体,因此可以充分利用信息公开透明的网络世界,监测此类群体的“危险发言”,必要时采取行动进行救援。荷兰阿姆斯特丹自由大学人工智能终身教授黄智生在2019年AI科学前沿大会演讲时,首次向公众展示了树洞计划:通过智能机器人监控社交媒体并实时发布自杀监控通报,随后组织树洞救援团根据监控通报采取自杀救助行动。尽管相关技术有待完善,但充分利用人工智能对抑郁症患者进行心理疏导,无疑是人类精神文明建设的高阶。
本文建立抑郁症识别模型时,分别从传统指标体系法与机器学习分类法两个角度展开,由准确率看,机器学习中集成算法的分类效果显著高于传统统计指标体系法,但在特征变量重要性的分析上,XGBoost只筛选出6个影响较为突出的因素,且集中在微博内容方面的相关指标,而TOPSIS距离综合评价法计算出的各变量的权重侧重于与人交往方面,个人信息次之,这从一定程度上印证了运用社交网络信息进行抑郁症识别时加入二者相关信息的必要性。因此建立模型时不应单纯追求准确率,应根据研究主题深入探究相关变量的影响效果,定性分析与定量分析相结合。
