基于改进YOLOv4 的道路红外场景下的行人车辆目标检测研究
2021-10-20王怡雯王学军穆应晨
王怡雯 王学军 穆应晨
(石家庄铁道大学 信息科学与技术学院,河北 石家庄 050043)
城市道路交通在人们的出行方式中占据极大的比重,虽然一定程度上便利了人们的生活,但是很多时段交通拥堵,行人与车辆之间不能很好地相互避让,导致事故频发,夜间环境尤其应该成为交通状况的关注重点,但夜间成像效果差导致目标检测研究难度较大。基于以上问题,亟需一个夜间交通状态智能感知系统来统计感知交通路况,而这一技术的核心即为道路车辆行人检测跟踪[1]。
近些年基于深度学习的目标检测算法因其强大的泛化能力和学习能力而被广泛应用[2],但大多数研究是基于可见光采集的数据集,而本文重点针对的是基于红外光下图像的目标检测研究,将研究重点着眼于受光照强度影响小且在夜晚同样可达到较好成像效果的红外图像,一定程度上弥补了夜间道路交通监控的短板。
本文针对红外道路场景的目标检测实验中小目标特征缺失以及网络参数量庞大等问题,使用YOLO v4 为基础的目标检测模型进行实验,使用k-means 聚类算法获得针对本文红外数据集的先验框值,加入SENet 模块为特征通道施加注意力机制提升网络的特征描述能力,在PANet 中使用深度可分离卷积代替普通卷积结构进一步减少网络参数量。
1 YOLO v4 算法
YOLO v4 算法是在YOLO 系列先前版本的目标检测算法的基础上优化而来[3],网络结构如图1 所示。YOLO v4 采用CSPDarknet53 作为主干特征提取网络,该网络在Darknet53 的基础上加入CSP 结构,将原来残差块的堆叠拆分成一条主干路径与残差路径,该结构实现了跨阶段的特征融合,在达到减少计算量的目的的同时仍可以保持较好的检测准确率。激活函数由LeakyReLU 修改成了Mish 函数,计算公式如式(1)。
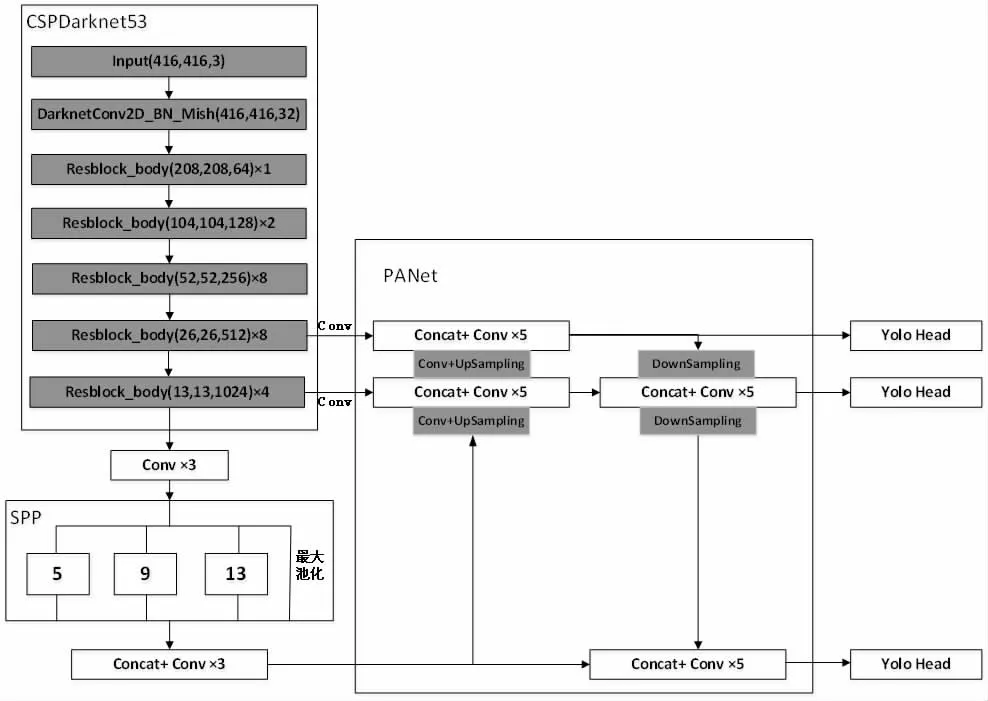
图1 YOLO v4 网络结构图

SPP 和PANet 特征预测网络在FPN 基础上加深了多尺度优化,将高层特征的信息与低层特征融合形成新的特征层,提高小目标的检测效果,最后通过不同尺度的特征层进行特征预测。
本文的研究对象为行人与车辆,存在目标较小或遮挡等情况,可能会存在一些误检漏检的可能。同时红外图像与可见光图像相比具有分辨率差、对比度低、信噪比低、视觉效果模糊等特点[4],且数据集数量较少,这些都是针对实际应用需要考虑的具体问题。
2 SE-YOLOv4-lite
2.1 先验框设置
由于YOLOv4 算法初始先验框的大小是根据coco 数据集得到的,因此本文利用k-means 聚类算法进行计算与统计,重新得到针对本文FLIR 红外数据集的先验框数值,这样的预先处理可以使得模型参数更加贴近本实验数据集,降低损失同时提高检测准确率,如表1 所示为处理结果。

表1 coco 数据集与本文数据集先验框值对比
2.2 SENet
SENet[5]主要通过学习的方式来自动获取每个特征通道的重要程度,即为特征通道分配不同的权重,重点突出对当前检测任务有用的特征并抑制无效特征,从而提升特征处理的效率。SEblock 不是一个完整的网络,而是一个可以灵活嵌入到其他分类或检测网络模型中的结构,图2 为其嵌入到残差网络中的结构示意图。
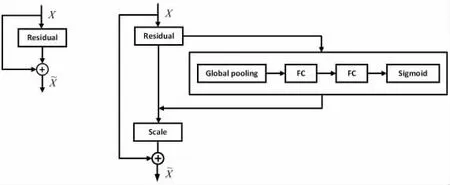
图2 SENet 嵌入残差网络示意图
首先利用全局平均池化(Global pooling)对输入特征图进行处理,再经过两个Fully Connected(FC)层先降低特征图的维度再升高维度,最后经过sigmoid 激活函数处理后可以得到相应的权重,利用权重在对应位置与原输入特征图相乘得到输出,即此处可以对不同重要程度的特征图进行相应的处理。本文设计将SENet 嵌入到CSPDarknet53 的残差网络中。
2.3 深度可分离卷积
在以上改进的基础上为了进一步使网络轻量化,实验借鉴MobileNet 的思路,采用深度可分离卷积结构块代替PANet 中普通3×3 卷积结构,得到的参数量对比如表2 所示。

表2 算法参数量对比
深度可分离卷积的处理步骤(以输入7 x 7 x 3、输出5 x 5 x 128 为例)如图3 所示。
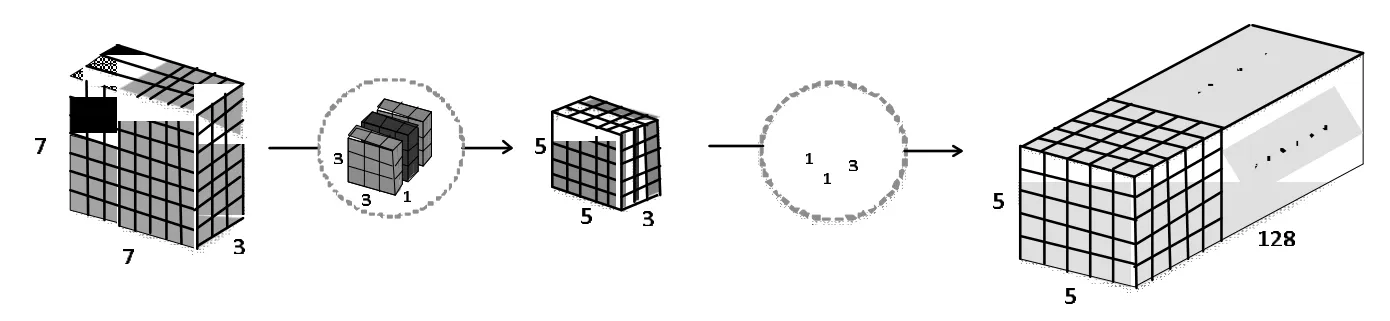
图3 深度可分离卷积示意图(输入7x7x3、输出5x5x128)
(1)利用3 个大小为3 x 3 x 1 的卷积核在输入为7 x 7 x 3 的图像上进行卷积操作,每个卷积核仅对输入层的1 个通道做卷积,因此卷积处理后得到的映射数量为3 个,大小为5 x 5 x 1,将这些映射进行堆叠得到一个5 x 5 x 3 的图像,因此第一步最终得出的输出图像大小为5 x 5 x 3。
(2)扩大深度,将5 x 5 x 3 的图像作为输入图像。当使用一个大小为1x1x3 的卷积核对5 x 5 x 3 的输入图像进行1x1卷积处理时会得到一个大小为5 x 5 x 1 的映射,将该操作重复128 次后将所有得到的映射进行堆叠即可得到期望输出的5 x 5 x 128 的层。
3 实验结果
3.1 实验基础条件设置
本文实验硬件环境为Ubuntu16.04 系统,GPU 为NVIDIA TESLA K40m,软件环境为CUDA10.0、CUDNN7.4.1、Anaconda3,使用深度学习框架Pytorch1.2.0。
3.2 实验设计与结果分析
为尽量还原夜间道路的真实场景,实验数据集选取真实道路的红外图像作为训练和测试的样本。本文采用的红外数据集为FLIR 红外数据集,运用LabelImg 可视化图像标注工具对数据集中的行人和车辆进行标注,共标记2000 张道路红外图像,其中90%的图像作为训练样本,10%的图像用于测试。在实验中本文还对数据集采用随机角度的旋转、裁剪、镜像等方式扩增数据集容量,并采用了Mosic 数据增强,提升模型的泛化能力,见图4。

图4 数据集样图
针对改进算法,本文设计实验与YOLO 系列其他算法进行对比,选择准确率与召回率作为模型评价指标,计算公式如式(2)(3)所示,其中TP 代表模型将目标正确检测并分类为对应类别的数目,FP 代表模型误检的目标数,FN 代表模型漏检的目标数。道路检测效果如图5。

图5 道路车辆行人检测结果
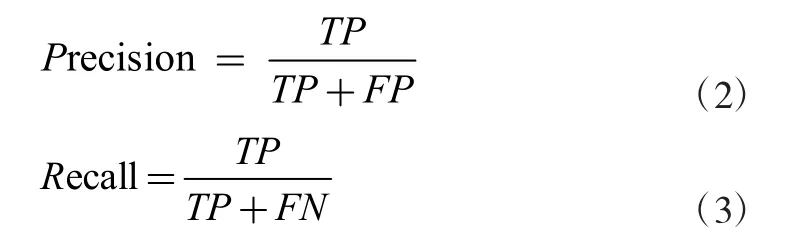
在FLIR 数据集上分别使用YOLOv3、YOLOv4 以及本文算法SE-YOLOv4-lite 进行实验,得到的测试结果对比如表3 所示。改进后的算法在召回率、准确率以及map 指标上均有一定的提升,损失函数如图6。同时经过测试,SE-YOLOv4-lite 算法在本实验环境中FPS 可达12.67,比原始YOLOv4 算法提升约27.5%。
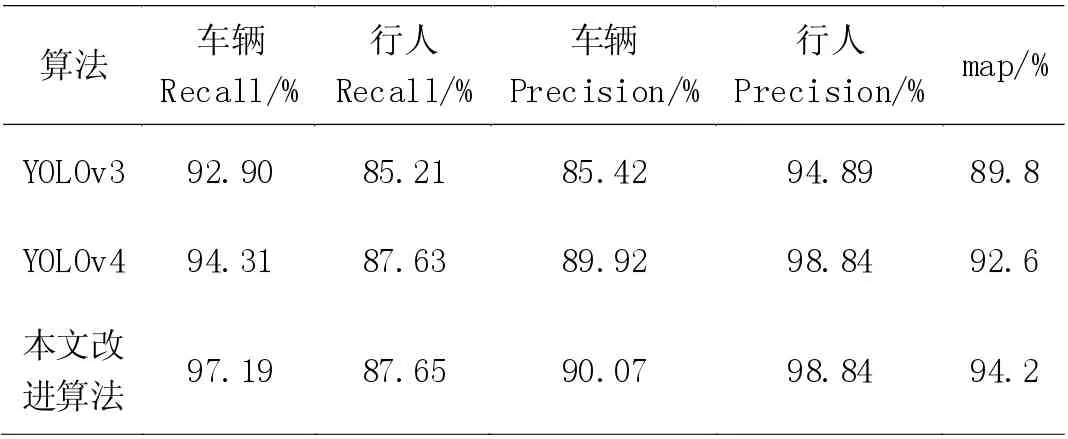
表3 算法测试结果对比
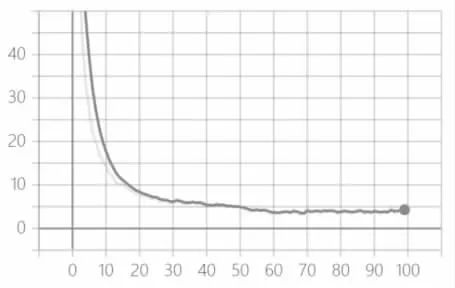
图6 loss 曲线
4 结论
本文基于 YOLOv4 的算法提出一种改进算法SE-YOLOv4-lite,旨在解决红外场景下的车辆行人的检测与识别问题。SE-YOLOv4-lite 设计在主干网络的残差结构中加入SENet 模块,提升网络的特征描述能力,使用深度可分离卷积结构块代替PANet 中的普通3×3 卷积减少网络参数。实验结果表明,本文模型较YOLO v4 在准确率等方面都有了一定的提升。同时本文中SE-YOLOv4-lite 算法仍有改进的空间,在现有实验结果的基础上如何进一步提升检测精度并适用于更丰富的场景是接下来亟待解决的问题。
