基于H-mine算法的变电站二次系统故障关联分析
2021-10-16王鸣誉李铁成任江波
王鸣誉,徐 岩,范 文,李铁成,任江波
(1.华北电力大学 电气与电子工程学院,河北 保定 071003;2.国网河北省电力有限公司电力科学研究院,河北 石家庄 050021;3.国网河北省电力有限公司,河北 石家庄 050021)
0 引 言
目前,智能变电站实现了数字化[1]。设备之间的物理回路变成了一种逻辑层面的连接关系[2],虚回路与物理回路的映射关系不可见,这种隐蔽的信息传输方式给运行人员带来了很大的麻烦,目前二次回路的故障还是依赖工作人员的工作经验以及相应的专业设备,同时故障发生时会产生很多冗余信息,同时这些故障信息还可能存在信息丢失或虚假信息,这使得故障难以迅速定位。
为解决上述问题,文献[3]利用通信链路状态对每一条回路进行分析,确定故障的大致位置,但是无法确定具体的故障装置。文献[4]采用了深度学习理论中的RNN模型,对二次设备故障进行建模,并利用典型二次回路验证了该模型的性能,但是深度学习模型的选择缺乏理论依据,并且很难获得完整的样本集。文献[5]提出了一种基于Petri网的GOOSE(Generic Object-Oriented Substation Event)回路故障诊断法,但是该方法需要用人力判断变迁是否触发。文献[6]利用专家系统来对二次系统故障进行诊断,该方法所需的样本量较大,很难做到完善,同时也不具备自学习的能力。
除了上述方法,目前关联分析也被用于电力领域,关联分析是数据挖掘中的一种关键的技术,关联分析的作用是发现不同数据之间的潜在联系,通常关联分析被用来进行通常用来预测数据,文献[7,8]利用apriori算法处理二次设备缺陷原因和二次设备之间的关系。但是apriori算法需要多次扫描整个数据库,这大大降低了处理速度。文献[9,10]使用FP-growth算法来分析二次设备缺陷,但由于该算法需要在过程中迭代产生大量临时数据库以及FP-tree,因此在稀疏数据库中的处理速度较慢。
文献[11]提出了一种H-mine算法,在运算时只处理总集中的一个分区,因此在运算速度上H-mine算法要优于apriori算法。同时由于H-mine在处理数据时不用产生大量相同前缀的FP-tree,因此该算法在处理大量稀疏数据时性能优于FP-growth。
基于上述情况,本文提出了一种基于H-mine算法的二次系统故障诊断方法,该方法无需对每一条二次回路都做出分析,减少了关联分析所需要的时间。使故障分析更加高效。
1 数据挖掘与关联分析
1.1 数据挖掘的基本概念
数据挖掘的含义是找出隐藏在数据背后的信息,随着近年来机器学习的发展,数据挖掘技术目前已经在人工智能、商业、医疗业等行业得到广泛应用。
数据挖掘包括了:机器学习、统计学等领域的知识[12]。数据挖掘得到的结论不仅可以用来提高决策人员决策水平也可以用来预测事件的结果、为工作人员提供参考。
数据挖掘的过程包含如下几个步骤:
(1)数据准备
数据准备主要是将数据进行筛选、合并,明确模糊数据、删除坏数据、选择出能够利用的数据,缩小挖掘的范围。同时将这些数据进行初步处理。
(2)数据挖掘
数据挖掘指用合理的算法,选择合适的软件和工具,对上一步中处理好的数据进行挖掘操作,生成结果,以便于工作人员分析。
(3)解释结果
根据上一步中挖掘出的结果,分析出有用的信息,还要删除掉参考价值低的结果,筛选出参考价值高的结果,以便于决策人员分析。
1.2 关联分析的基本概念
关联分析是指在数据中寻找关联关系,如此一来,便可以通过一种数据判断另一种数据的可能的变化。关联分析主要分为:关联规则、序列模式[13]。
生活中关联规则通常应用在网站、超市、服务行业等领域,举个例子,当我们在网页上搜索我们想要的信息时,搜索框会根据我们输入的部分信息弹出一些选项供我们选择,我们可以从中选取想要的信息进行搜索。
这些选项便是根据我们输入的信息生成的,生成关联规则就像A→B,A是我们输入的信息,在关联规则中被称为前项集。B是网页弹出的选项,被称为后项集。而关联规则的含义是在A发生的情况下,B也会发生。文中将关联规则设置为A为故障报警信号,B为故障原因的形式,以此来推断二次系统发出某种故障信号时的具体故障原因。
定义I={i1,i2,…,im}是项目集合,含有k个项目的项目集合被称作k项集、事务集T={t1,t2,…,tn}包含于I。衡量关联规则强弱的指标主要为如下几种:
(1)支持度:该指标表示某一种项目在集合中出现的频率。如果某一项集的支持度不小于规定的最小值,那么则称之为频繁项集。该指标可以用来剔除那些出现次数太少没有研究价值的数据,其公式如下,A为事务集,N为事务总数。
(1)
(2)置信度:表示的是前项集发生的条件下,后项集发生的概率,置信度在文中是指二次系统发出故障报警信号A时,故障原因为B的概率,如果某一关联规则的置信度不小于规定的最小值,则称之为强关联规则,计算公式如下,A、B为事务集:
(2)
(3)Kulc度:使用Kulc度是为了减少零事务的影响,Kulc度越大相关性越大。其公式如下:
(3)
式中:con为置信度;A、B为事务集。
(4)不平衡比:该式可以衡量在某一关联规则下前后项集之间的关系密切程度,若不平衡比值接近于0,则证明在A发生的前提下,B大概率也发生,反过来也成立,二者有密切的关系,该关联规则即为有意义的关联规则;而如果不平衡远大于零,则不能证明B发生同时A大概率发生,即两种事务缺乏关联关系,该关联规则的参考价值较小。
其公式如下:
(4)
式中:Sup为支持度,A、B为事务集。
2 H-mine算法原理
H-mine通过生成H-struct来对数据进行处理,与FP-growth算法类似,使用频繁项集增长的方法,不必生成大量的候选集。除此之外,与FP-growth相比,H-mine不生成FP-tree以及生成FP-tree所需要的迭代数据库,从而在很多情况下节省了存储空间和时间;与Apriori相比,H-mine不用多次遍历总数据集,生成很多候选集,该算法只用遍历两次数据库,生成H-struct,之后的每次扫描只在H-struct中进行。
H-mine首先扫描一遍数据库,按照不小于最小支持度的原则筛选出符合要求的1-项集,并且按照排列顺序将这些项集存储在表H中。然后再扫描一次数据库,将各事务按字母排列顺序存储在一个队列中,由表格H中的各项作为头指针把首项相同的事务串联成一个链接。
下面用一个具体的例子来说明H-mine算法的原理,设置最小支持度计数为2。已知数据库TDB的事务集以及筛选后的频繁项如表1所示。
从表1中可见A、K、M、N、H、I不符和支持度要求,这便是第一次扫描,将事务集筛选后得到表H:{B:3,C:2,D:3,E:2,F:2,G:3}。而文章需要挖掘的频繁项集分为:包含B项、包含C项但不包含B项、包含D项但不包含C项和B项、包含E项但不包含D、C、B项、包含F项但不包含E、D、C、B项、以及只包含G项。
将H表中的元素作为头指针建立H-struct。如图1所示。
表H也被称作Header table H,它包括三个区域,分别是频繁项、支持度计数以及它们的指针。表H中的结点通过指针将所有首项相同的事务连接起来,如上图中的项B,它链接首项都是B的1、2、4三个事务,项C链接3事务,而项D、E、F、G由于没有首项是这些项的事务,因此不必建立链接。
在建立H-struct的时候进行了第二次扫描,建立好H-struct后,数据挖掘工作便只在H-struct上进行,首先在H-struct中对表H中的五个1-项集进行挖掘,遍历B队列,找出B队列中的所有频繁项,建立表HB,结构与表H相同,但支持度计数则是根据B队列中的元素来记录的。可以求得输出的频繁2-项集为:{BD:3,BG:2}。如图2所示。
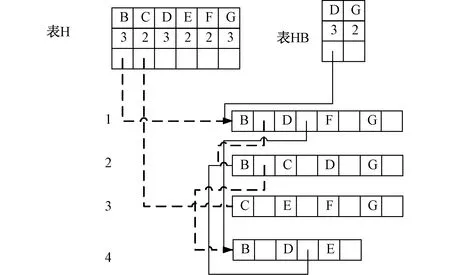
图2 表HB图
以此类推,挖掘包含B、D的项,这次不仅要挖掘BD队列,还要在其中插入表H中已经建立过指针的2事务,因为它里面同时含有B和D,从而得到完整的BD数据集,这次挖出了频繁3-项集BDG:2。最后还要搜索以BG为首项的事务,但是由于表H和表HB中没有指向BG的指针,所以没有频繁项集产生。综上所述便是挖掘以B为首项的事务的过程,接下来是挖掘包含C但不包含B的频繁项集,这个过程需要挖掘C队列和B队列中包含C队列的队列,因此需要将B队列插入到适当的位置,如图3所示,BCDG被插入到CEFG之后。
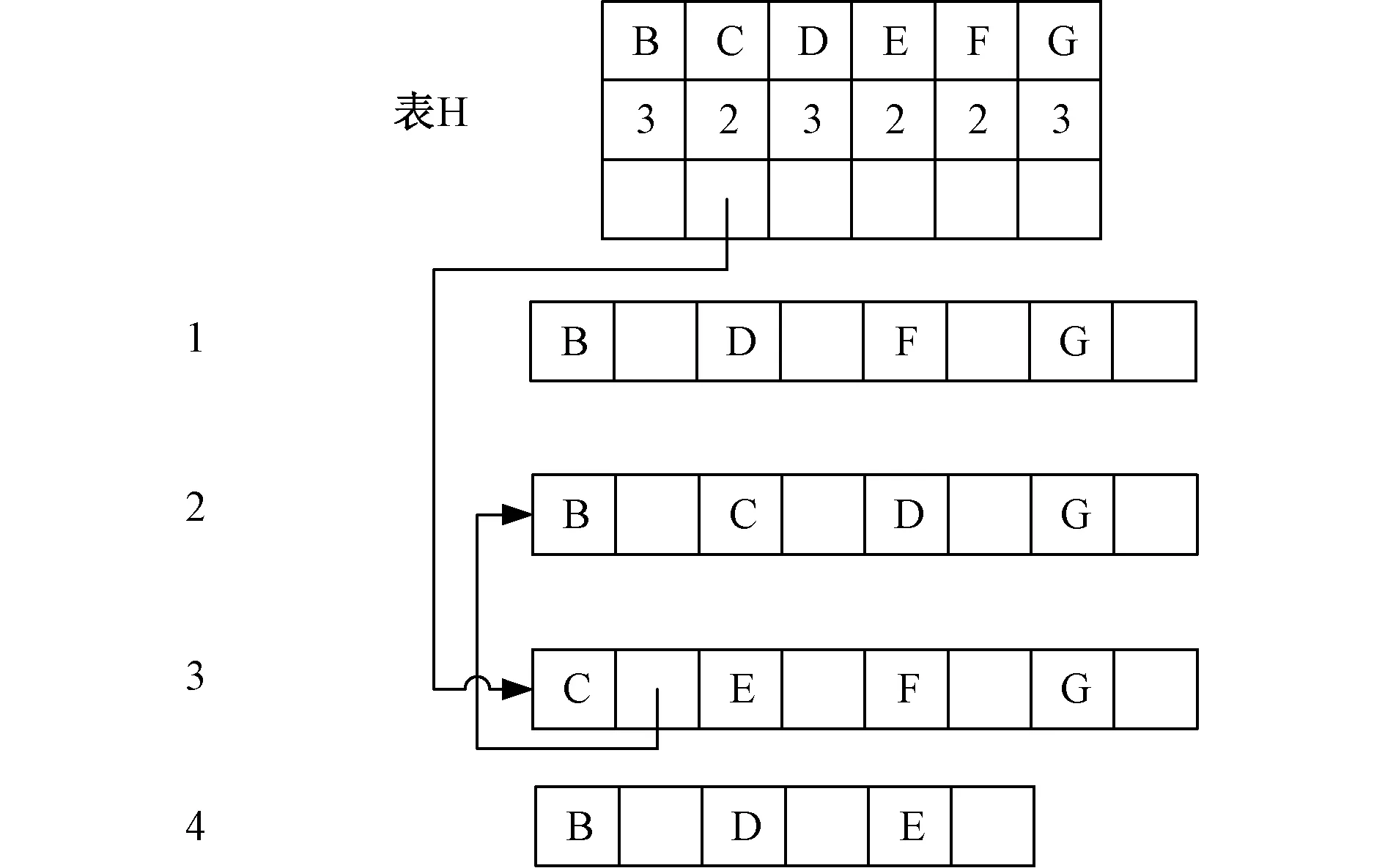
图3 建立C队列的过程图
需要注意的是在挖掘C队列的时候,不产生关于B的频繁项集。其他的频繁项集也是按照同样的方法来进行挖掘。
上述挖掘完毕之后,将所有的频繁项集按照公式(2)计算关联规则的置信度,例如上例中的BD∶3和B∶3,可以得到B→D的置信度为100%。最后,按照置信度指标选出符合要求的关联规则。
H-mine算法的流程图如图4所示。

图4 H-mine流程图
3 二次回路模型以及故障数据库的建立
3.1 故障数据库的建立
智能站二次回路故障报警数据主要通过综合自动化系统的报警信息以及网络分析装置的监测信息的获得,其中综合自动化系统包括的主要报警信息有:智能装置的异常报警信号、断路器的监测报警信号以及电源系统的报警信号。而智能站配置网络分析装置记录的报文主要包括SV采样报文、GOOSE通信报文以及MMS通信报文,这些报文经过交换机的处理,直接传送到调度系统。
文中主要分析的是智能装置的报警信号以及网络分析装置给出的网络异常报文中的SV采样报文和GOOSE通信报文。其中智能装置报警信号主要包括:数据采样异常、装置自检异常、电源失电故障等。
SV采样报文需要检测的主要有以下几项:采样计数是否正常、采样频率是否正常、数据同步是否正常、配置文件是否正常,上述几种情况只要有一种出现异常,则触发事件异常告警。
GOOSE通信报文需要检测的主要包括:报文计数是否正常、流量是否不大于流量上限、是否出现断链情况、配置文件是否正常,上述几种情况只要出现一种异常,则触发异常告警。
报警数据的结构图如图5所示。
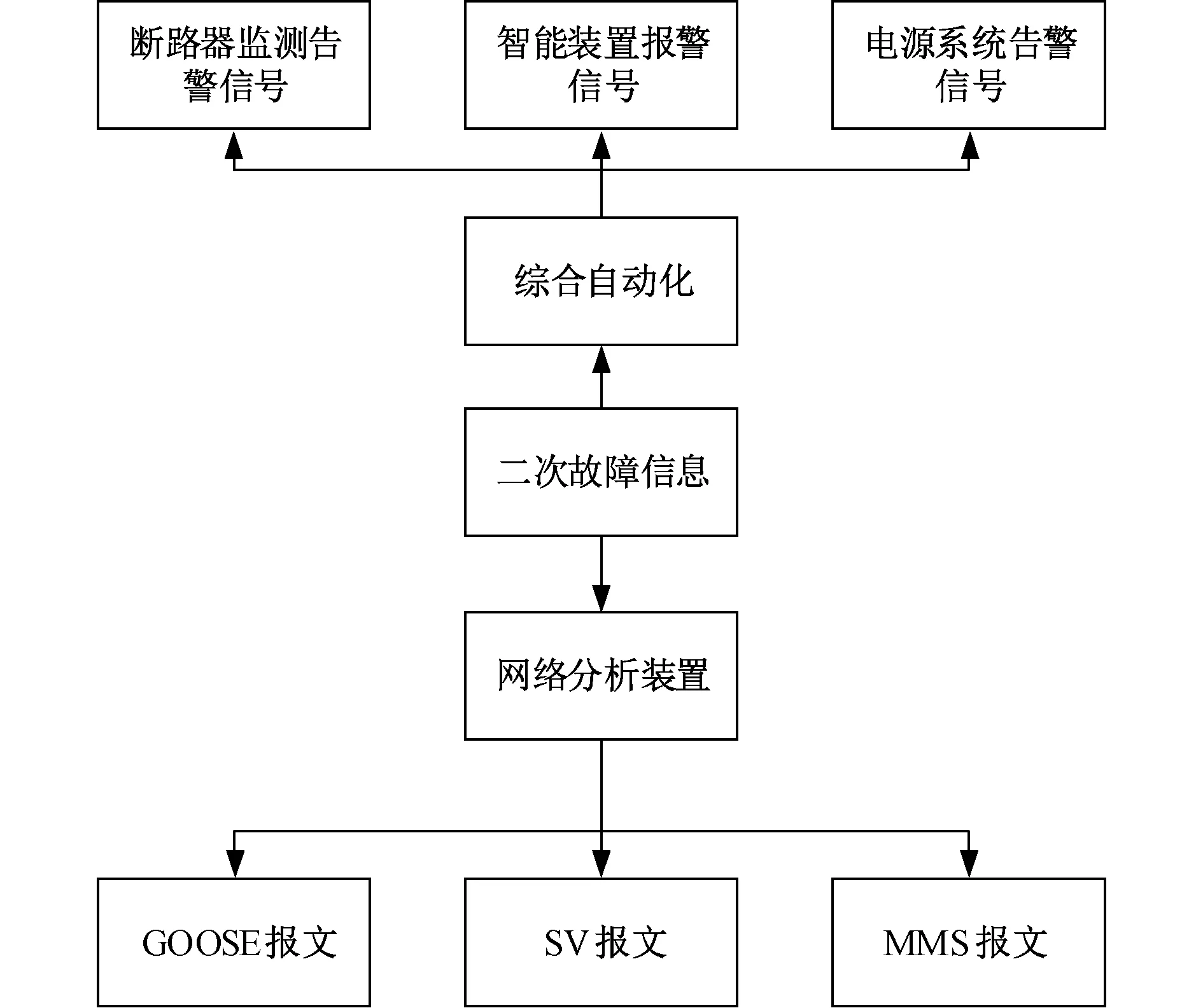
图5 故障数据结构图
文中数据库中的故障数据来源于检修记录以及调度管理系统,包括二次系统异常情况、二次系统检验中发现的问题与处理情况,将这些数据是用自然语言描述的,在筛选前需要人工提取。这些数据可以具体分为:厂站名称、发生故障的时间、报警内容、故障类型、元件,这些数据组成了多源异构数据集[14]异构是指这些数据包括数字信息、自然语言描述的文字;多源是指数据存在多个来源。
这些数据在进行关联分析前首先要经过处理,首先将自然语言描述的内容进行统一,尤其是检修记录表中人工记录的报警信号和故障装置,如:在某些记录中出现的“GOOSE断链”、“GOOSE中断”,等描述GOOSE中断的信号统一改成断链;在数据库中,同一故障装置的记录有时也会因为人为原因出现偏差,如:110 kV#线路智能终端A和IL1101A:151智能终端1,因此,需要将这些数据统一成:110 kV线路智能终端151。
处理后得到的标准数据库模型如表2。

表2 数据库模型表
文章主要是对报警内容和故障类型之间的关联关系进行挖掘,寻找报警信息与故障原因之间的关联规则可以帮助运行人员更加方便的做出诊断,数据挖掘时,需要故障数据处理成如下集合形式:
N=(n1,n2,n3)
(5)
式中:n1表示故障的具体装置;n2表示故障报警信息;n3表示故障原因。
在对故障数据库中的故障数据进行关联分析时,由于现有的技术还不足以完美的处理自然语言,因此在进行关联分析时还需要在每一项中附加项目识别码,如此一来不仅为关联分析提供了方便,同时还可以防止在同一种数据类型下生成关联规则,即关联分析只在报警内容和故障类型之间进行,不会在报警内容内部或者故障类型内部进行同种数据类型的分析。
综上所述,故障分析的步骤分为以下几步:
(1)将数据处理后导入库中;
(2)从数据库导入训练集数据;
(3)将数据用H-mine算法进行关联分析;
(4)检查是否符合支持度指标要求;
(5)得出关联规则;
(6)整理出符合置信度、Kulc度、以及不平衡比指标要求的结果;
(7)将关联规则整理后,作为诊断结果提供给运行人员当作参考。
故障诊断流程图如图6所示。
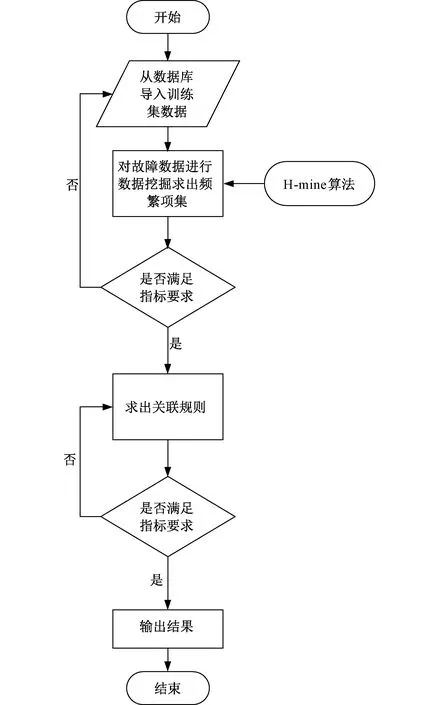
图6 故障诊断流程图
3.2 二次回路模型的建立
关于二次回路模型的建立,文献[15]提出了一种基于图的遍历算法的虚实回路对应法,文献[16]利用SCD(Substation Configuration Description)文件的网络、虚端子配置信息以及装置信息来实现SCD文件可视化。通过查阅相关文献[17-20]以及结合实际SCD文件,文章采用解析SCD文件中的部分字段来实现二次回路的构建。
SCD文件中的PhusConn元素含有IED的物理端口信息,包括端口、插头类型等,其中Port字段描述了物理端口号、Cable字段描述了端口所连接的光纤。
在SCD文件中的Inputs部分含有每个装置的GOOSE和SV连线信息。其中包括装置本身的输入虚端子信号和来自其他装置的输出信号,每个内部虚端子信号对应一个外部输出信号。
综上所述,文章首先解析SCD文件得到物理端口号以及光纤标识,其次再利用Inputs字段得到虚回路的端子连接关系,最后根据虚端子连线和物理端口号寻找每个虚回路所包含的实际物理装置,实现二次回路的建模。以便于后续分析。
4 算例分析
以某智能站为例,该站经过SCD文件解析后的二次回路图如图7所示。
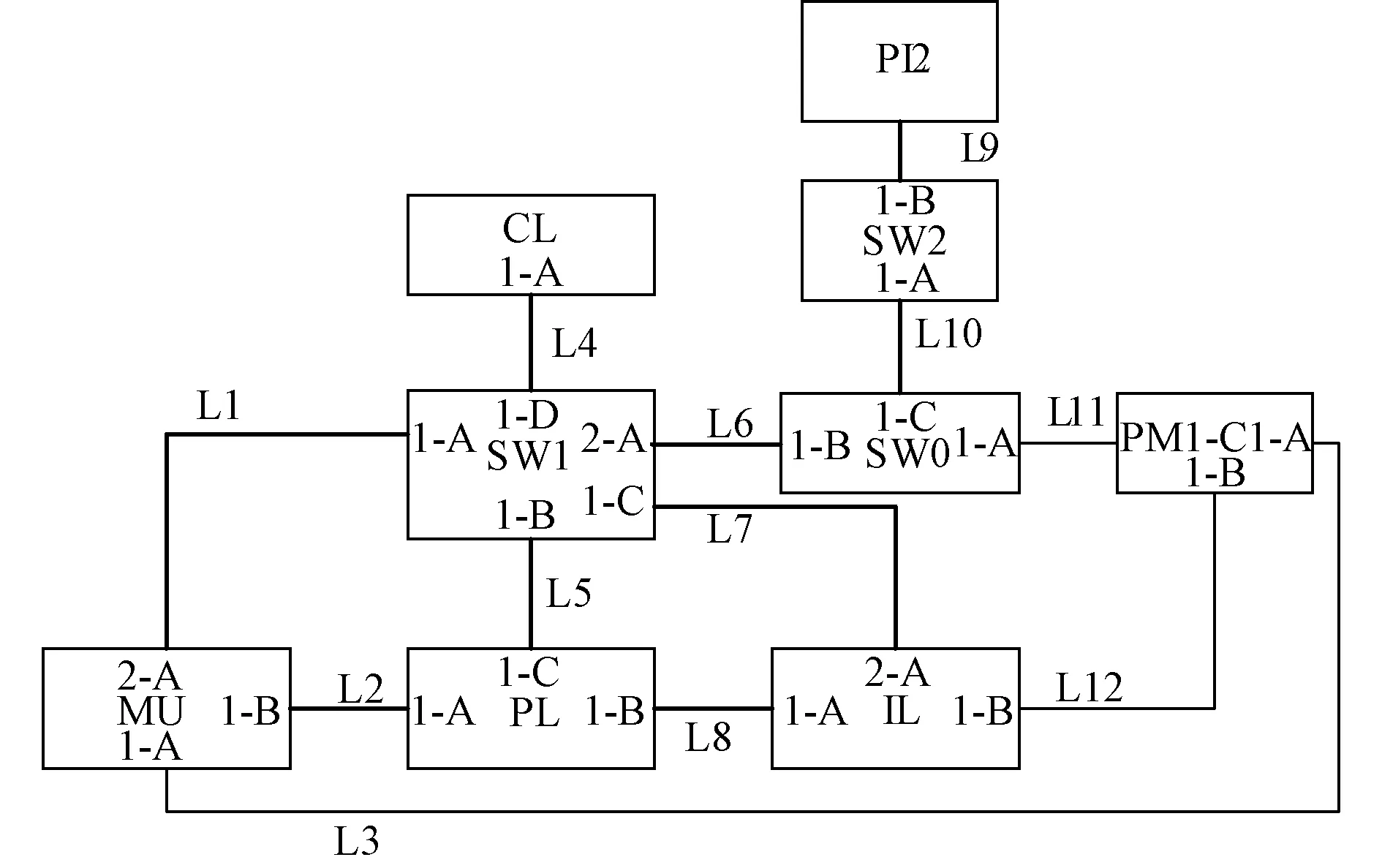
图7 二次回路图
上图中L为光纤、PM是母线保护装置、PL是线路保护装置101、IL是智能终端151、SW是交换机、CL为测控单元101:
变电站二次回路经过可视化,看不见的虚回路变成了可视的物理回路,以便于后续的故障诊断。
以数据库中近几年来的二次故障数据为例,对二次系统故障报警信号和故障类型进行关联分析,首先筛选出四分之一的数据作为测试集,对结果进行验证。其次设置最小支持度为1%,最小置信度为40%,Kulc阈值为0.4。采用H-mine算法进行挖掘,寻找关联规则。最后还需要把挖掘出来的关联规则用来与Kulc度量和不平衡比进行对比,筛选出那些有意义的强关联规则。
挖掘出的某变电站部分置信度较高的几则关联规则如表3,表3中的故障信息为关联前项集、故障原因为关联后项集。

表3 部分强关联规则
经过上述数据挖掘工作,发现智能变电站二次故障报警信息和故障原因之间的关系,最后利用剩下的四分之一的数据验证结果,将故障信息和挖掘到的故障原因与测试集中的实际情况进行人工对比,核对在出现某种故障信息的情况下,挖掘出的故障原因与实际故障原因的匹配率,即可验证挖掘结果的准确率,对比结果如表4、表5所示。

表4 验证结果

表5 验证结果
由上表可见,关联分析准确率可以达到90%左右,验证了关联分析在二次系统故障诊断方面的准确性,这些结果可以作为工作人员在检修时的参考依据,为维修人员提供便利。
与此同时,本文引入了没有引入Kulc度量和不平衡比这两个指标时的关联分析结果,并将这些分析结果与测试集进行对比,由于没有引入Kulc度量和不平衡比这两个指标,关联规则受到零事务和无意义的关联规则的影响,可以发现,此时准确率较低。
验证过程如下,将测试集中的故障特征信号作为关联规则的前置条件,找寻符合指标要求的关联规则,验证关联规则的后件是否与数据库中的故障元件一致。
算例1:图7所述的变电站某次保护误动时,调度中心收到如下报警信号:保护装置101 GOOSE断链、智能终端151 GOOSE断链两种告警信号,从图7中可以看到保护装置、智能终端两种设备之间有一条光纤链路,根据该变电站数据挖掘结果可以发现在以上信息为关联规则前置条件时,后件为L8链路故障的关联规则的置信度为63.6%,其他结果均不满足置信度指标要求,因此可以判断故障发生在L8链路。对比数据库,发现与数据库中的故障元件一致。
算例2:在该变电站某次二次系统故障中,二次系统出现如下告警信号:11-7合并单元 GOOSE断链、测控装置101 GOOSE断链、合并单元11-7 装置异常告警。从图7可知该故障发生在合并单元-交换机-测控装置这条回路上。从该站的关联分析结果可以发现故障原因为11-7合并单元 2-A端口和测控装置1-A端口的置信度均大于50%,但是经过不平衡比计算,只有11-7合并单元2-A端口的不平衡比符合指标要求,因此故障发生的在11-7合并单元2-A端口。对比数据库得知结论正确。
除此之外,为了验证H-mine算法性能的优越性,本文还设置了几组数据作为样本,用apriori算法和H-mine算法分别对他们进行关联分析,挖掘出频繁项集,设置最小支持度为1%,同时将它们处理这些数据的时间记录下来,做成对比图,结果如图8所示。

图8 apriori和H-mine对比图
从图8可见,H-mine算法相比较于传统的apriori算法耗时较短、效率较高。同时随着样本数量的越来越多,传统apriori算法和H-mine算法相比耗时差越来越大。由此可以证明H-mine算法的性能优于apriori算法。
由于故障数据库中报警信号种类繁多、故障类型也大不相同,因此库中的数据较为稀疏;同时又由于数据库的数据样本过多,因此不应将支持度指标设置的太大,文中选择的指标是1%,这更增加了在FP-growth算法中生成的FP-tree分枝,与H-mine算法相比较,FP-tree的运算速度会比较慢。图9是两者运算速度比较,最小支持度设置为1%。

图9 FP-growth和H-mine对比图
从图9可见,H-mine算法和FP-growth算法相比在处理稀疏数据时,明显效率更高,而且随着数据越来越多,H-mine算法的优势也越来越明显。
5 结 论
文中利用H-mine算法对变电站二次系统故障进行诊断,该算法利用H-struct与传统apriori、FP-growth算法相比减少了耗时,可以实现对故障数据的快速挖掘,找到故障原因与故障报警信息之间的关联关系。使用H-mine算法进行分析时,无需对每一条二次回路都进行分析,只需利用历史数据便可以得到关联规则,关联规则可以作为诊断结果给二次系统检修人员提供参考依据和建议。
