移动群智感知中基于用户意愿的参与者优选方法
2021-10-15吴佳莹张振宇韩俊樱
吴佳莹,张振宇,韩俊樱
(新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
0 引言
移动群智感知是一种随着物联网发展而诞生的新兴感知范式,它将用户移动设备(智能手机、平板电脑、可穿戴式智能设备等)作为基本感知单元,通过不同拓扑结构的移动网络进行连接构成大规模的感知系统,从而实现感知数据的收集,应用于环境监测[1-3]、智能交通[4-6]、移动社交[7]等实际场景中.
参与者选择是移动群智感知中的关键问题之一.在典型的移动群智感知系统框架中,感知平台针对数据请求者的需求并参考实时场景下的用户信息,为每个感知任务选取一组合适的用户作为参与者去完成感知任务.在多数情况下,参与者选择方法主要以平台为中心,针对用户效用(如用户的移动速度、用户与感知任务之间的距离、用户的信誉度、用户的设备性能等因素)选取参与者,以实现最小化感知时间、最小化激励成本、最大化数据感知质量等优化目标.文献[8]研究移动群智感知平台中的参与者选择机制,在参与者数量一定的情况下,最大限度地提高感知任务的空间覆盖范围;文献[9]主要研究在考虑空间位置、时间需求以及参与者行为习惯的情况下,选择合适的参与者完成任务;文献[10]研究了在已知给定集合点的距离最小;文献[11]提出的框架能够在满足感知覆盖质量的情况下,选择最少的参与者来最大限度地减少激励支付.
但从用户角度出发,由于移动设备的用户私有性、资源有限性等因素,致使用户不愿意去执行感知任务.另外,如果被分配到的感知任务对于用户来说报酬过低、距离过远、功能权限需求过多,也会在一定程度上催生用户对于执行感知任务的抗拒情绪.上述情况不利于维护用户的长时参与水平,并且降低用户执行感知任务的积极性进而可能出现上传虚假数据、中途退出等损害感知数据质量的行为.因此如何提高用户意愿,维护参与者长时参与水平一直以来都是移动群智感知的重点研究方向之一.目前考虑用户参与意愿的参与者优选方法较少,多数研究工作考虑的是设计合理的激励机制,通过金钱、虚拟积分、信誉值等报酬去提升用户的参与积极性.文献[12]采用逆向拍卖中的组合拍卖模式来激励参与者,参与者可以根据自己所在位置和感知范围竞价多个感知任务,服务器根据汇总的参与者竞价情况来选择赢标者.文献[13]采用双向拍卖机制来激励参与者加入位置信息敏感者的K匿名保护中.但是实际场景中,用户是有限理性的,并不会一味地追求利益最大化,激励机制所给予的报酬不一定总是能够有效提升用户意愿.另外,额外的激励报酬可能会加大平台的感知成本.因此如果能够在参与者选择过程中,综合考虑用户意愿与用户效用两个因素来选择合适的用户执行感知任务,较基于激励机制以及基于效用的选择方法更有利于维护用户的长时参与水平,并在一定程度上保障感知效率与数据质量.
基于用户意愿的参与者优选方法,其主要挑战在于:用户意愿受到很多因素影响,很难将用户自身情况、任务属性、周围环境信息等诸多数据进行合理地形式化表达;难以拟合影响因素与用户意愿的映射关系并找到一个合理的意愿函数以量化评估用户意愿.考虑这一情况,首先,本文通过卷积自编码对意愿影响因素进行合理化表达,提取出关键特征;其次,通过全连接的深度神经网络构建回归模型,用以在感知过程中评估用户对于某个感知任务的执行意愿;最后,设计了一种平衡用户意愿与用户效用的参与者优选机制,以应对在不同紧急程度下的感知场景.
1 用户意愿评估
1.1 意愿因子
用户执行某项感知任务的意愿程度定义为用户意愿,记作W.用户意愿受到很多因素影响,如移动设备的剩余资源、用户是否处于忙碌状态、用户对任务报酬是否满意、用户对任务难度是否接受等.将其中可量化的影响因素称为意愿因子[14].本文主要考虑的意愿因子主要有3类,如表1所示.

表1 意愿因子
由于难以找到一个合理的意愿函数去评估意愿,因此本文使用深度神经网络构建一个回归模型,用以估计用户意愿,其形式化表达式为
W=DNNreg(Fuser,Ftask,Fenv).
(1)
其中DNNreg为全连接层构成的用户意愿回归模型,在后文将对其实现进行具体说明.
1.2 用户因子
从用户角度出发,不同于传统传感模式,用户所持有的智能设备是移动群智感知系统中基础的感知单元,但是设备主要供用户自身使用.正是因为这种用户私有性,在实际感知场景中,设备的剩余电量、网络流量等感知资源受限时,用户可能不愿意消耗资源去完成感知任务.而当用户处于忙碌状态时,可能不愿意执行额外的感知任务.除此之外,用户地理位置与用户移动速度也是影响其意愿的重要因素,两者决定了用户执行一个或多个感知任务所耗费的时空成本,如搭乘或驾驶交通载具的费用成本、移动至目标区域的时间损耗等.
综上所所述,用户因子表示为维度为6的一阶张量,其形式化表达式为
Fuser=[locx,locy,pow,dmoile,sbusy,v].
(2)
用户因子中的特征描述如表2所示.

表2 用户因子
1.3 任务因子
用户本身具有主观意识,当任务报酬无法令其满意或者任务目标区域过于遥远时,用户的执行意愿都会受到不同程度的影响.感知任务所需的权限数量(麦克风、存储空间、摄像机、联系人等应用权限)、网络流量、损耗电量这些因素反映了执行该项任务的难度,如果执行难度过大或不利于用户隐私保护时,用户也有一定概率拒绝执行该项任务.
综上,任务因子形式化表达为
Ftask=[tx,ty,pt,dt,cnum,r].
(3)
任务因子中的部分特征描述如表3所示.

表3 任务因子(部分)
(3)式中的pt与dt分别为表示感知任务所需的电量和表示感知任务所需的网络流量.由于一个感知任务很难去描述感知内容并量化其所需的感知资源.因此本文将感知任务拆解成多个单位感知动作,即一个任意的感知任务可以由多个感知动作构成.通过如表4的整数编号去标记感知动作.

表4 感知动作
感知动作pt与dt均表示五维向量.例如:pt的值为(0,0,0,4,1)则表示该感知任务所消耗的电量等同于拍摄4张照片与一个1 min视频,并将数据全部上传所消耗的电量.最终,任务因子可表示为一个14维的一阶张量.
1.4 环境因子
群智感知是群体行为,用户的意愿除了受到自身情况和感知任务这两个因素影响以外,还会受到实时环境的影响.实时环境的影响主要体现用户周围的用户分布和任务分布.由于人类本身具有潜在的从众意识,自身周围的群体行为可能会影响到个人的决策.在感知过程中,当用户周围有其他用户选择执行某个感知任务时,可能会带动并提升该用户执行感知任务的意愿,而用户间的社交关系密切时,这种影响程度会相对提升.如当用户身边的朋友执行感知任务时,用户有一定概率会选择跟随朋友,一起去完成感知任务并获取报酬.
另外,当某个感知任务的附近存在其他感知任务,并且用户设备资源支持其完成多个感知任务时,用户可以以较小的时空成本完成多个任务赚取高额报酬.因此某个感知任务周围有着密集的感知任务分布有利于提升该任务被用户执行的概率.
综上,任务因子其形式化表达式为
Fenv=[smat,emat,rmat].
(4)
其中:smat为用户社交权重矩阵,emat为用户感知状态矩阵,rmat为任务报酬矩阵.每个矩阵的大小均为101×101,矩阵中心为用户所处的位置.每个矩阵中元素所代表的含义如表5所示.

表5 矩阵元素含义
类似于一幅图像,将3个矩阵拼接构成一个3阶张量.因此环境因子Fenv可表示成尺寸101×101,深度为3的特征图.采用特征图来表示环境因子可以解决样本的不定长问题.不失一般性,某个用户周围的任务与用户均可以用一阶张量表示,环境因子简单的表示方法就是将多个一阶张量进行拼接,但是由于实际场景中周围的其他用户与任务数量是不定的,简单拼接就会造成样本不定长问题.
但是用101×101×3的张量来表示环境因子还存在问题.首先维度过大且可能过于稀疏,其次没有提取出特征图中的结构化特征.环境因子的特征图中存在着一些潜在的结构化特征影响着用户的意愿,比如:感知任务的分布情况与用户的移动轨迹相接近时,代表用户可以顺路执行感知任务从而提升用户的执行意愿.考虑到上述问题,采用卷积自编码器(Convolutional auto-encoder)对原始特征图进行降维的同时提取出结构化特征.自编码器是一种特殊的网络模型.通过对称网络结构的解码器与编码器将输入的样本进行复现,最后训练好的编码器可以将原始输入进行有效降维.同时为了减少原始输入信息的损失,并提取结构化特征,使用卷积自编码,在编码器中加入卷积层与池化层,在解码器中加入上采样层.具体网络模型如图1所示.

图1 卷积自编码器网络模型
将模型中编码器部分取出用于对输入的特征图进行压缩降维,维度从101×101×3降低到了10×10×32.卷积自编码器的其他设置如表6所示.

表6 自编码模型设置
1.5 回归模型
DNNreg的具体网络模型如图2所示.

图2 全连接的回归模型
一般而言,用户意愿值域为{0,1},即用户对于某个感知任务愿意做或者不愿意做.但是在真实场景中,用户意愿往往更趋向于连续值的区间,即:完全抗拒、可以接受、非常乐意等不同的意愿程度.为了契合实际场景,本文将用户意愿的值域设置为[0,1].
样本输出从离散值变为了连续值,需要构建一个回归模型.DNNreg最后一层的激活函数采用Sigmoid函数,用来输出一个0到1之间的数值.
输入的单个样本为用户因子、任务因子、环境因子所构成的一阶张量,其维度是3 220维.模型进行训练前将输入样本中的每一维特征进行标准化处理,使得其平均值为0,标准差为1.为了避免模型结构过于复杂而导致过拟合,内部隐藏层采用比率为0.2,即将全连接层的权重随机选取20%并设置为0,从而实现降低过拟合.其他设置如表7所示.
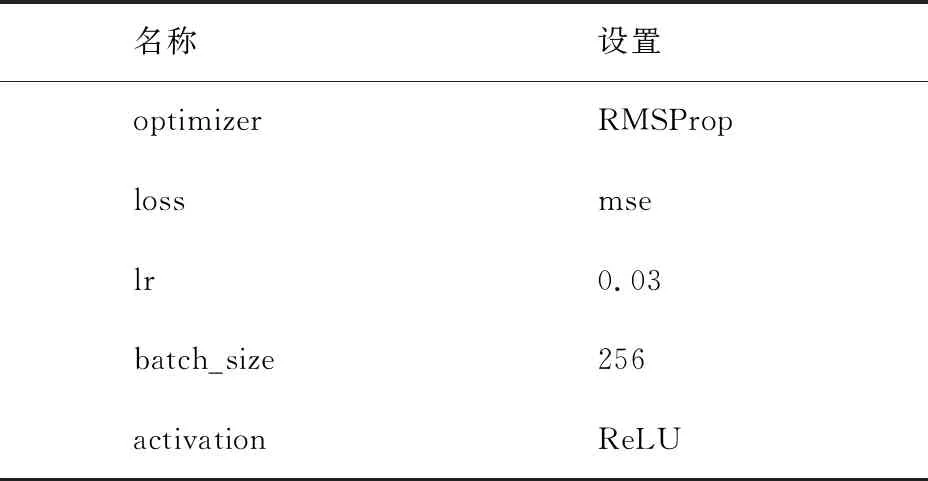
表7 回归模型设置
2 参与者选择机制
2.1 用户效用
用户效用为用户对单个感知任务的效用价值,记作E.在不考虑用户意愿的情况下,平台会选择一组用户效用最大的用户执行感知任务,从而提升感知任务的感知效率.用户效用受到用户与感知任务间的距离、用户移动速度、用户信誉度等因素影响.本文仅考虑的效用因子如表8所示.

表8 效用因子
设置用户效用函数fe计算用户对于某个感知任务的效用值.用户u对于感知任务t的效用值为
(5)
2.2 混合优选机制
用户意愿与用户效用都是在参与者选择时需要考虑的因素.为了兼顾意愿与效用,在参与者选择过程中,将DNNreg预测的用户意愿与fe计算出的用户效用进行加权求和,其形式化表达式为
(6)
考虑到在实际场景中,感知任务的紧急程度是不同的,因此就会产生用户意愿与用户效用不同的侧重.比如:在出现突发事故时,政府希望尽快得到感知数据,这时用户效用更为重要;而平时感知用户较多,感知需求不是很紧急的时候,平台希望尽可能照顾到用户意愿,以维护其长时的参与水平,因此用户意愿更为重要.通过调节权重kw与ke就可以在不同的场景选择较为合适的参与者.在实际选择参与者时,遍历感知任务集,利用(6)式计算用户的WEu,并进行降序排序,贪心选择前Kt(Kt为该感知任务所需的参与者数量)用户执行感知任务.具体流程如算法1 所示.
算法1:平衡用户意愿与效用的参与者选择算法.
输入:意愿回归模型DNNreg,感知任务集合T,用户集合U.
输出:每个感知任务的参与者集合Tsel.
(1) 从T中选取任务t.
(2) 从U中选取用户u.
(3) 使用意愿回归模型DNNreg预测用户u对执行任务t的意愿Wu,t.
(4) 根据式5计算用户u对执行任务t的效用Eu,t.
(5) 循环执行(2)到(4)步,直到U中的全部用户均被处理过.
(6) 根据(6)式计算U中所有用户对执行任务t的意愿效用加权和WEu,t.
(7) 根据WEu,t对U中的用户进行降序排序.
(8) 选取前Kt用户,加入到任务t的参与者集合tsel中.
(9) 将tsel加入到参与者集合Tsel中.
(10) 循环执行(1)—(8)步直至所有任务均完成参与者选择.
(11) 输出Tsel.
(12) 结束.
3 实验评估与分析
3.1 数据准备
采用由CRAWDAD提供的真实数据集mobility进行实验,它包含了2008年美国旧金山30 d内500辆出租车的GPS轨迹数据集.每个子文件与出租车ID相对应,包含经纬度、出租车状态信息(0表示出租车处于空闲状态,1表示出租车正在载客)、时间戳.本文基于mobility设置的实验参数如表9所示.

表9 实验参数设置
目前完备考虑用户意愿的移动群智感知平台较少,导致缺少用户意愿的真实量化数据.因此采用Crowd-Cluster意愿模型来量化用户意愿,生成样本标签,从而进行仿真实验[15].Crowd-Cluster设计的意愿模型服从Boltzmann分布,首先,虽然不能完全准确量化用户意愿程度,但能够将用户距离、任务报酬、速度等影响因素与用户意愿相关联,其次,在一定程度上契合用户的有限理性,即:每个任务都有概率被用户选择执行.将Crowd-Cluster意愿模型进行适当修改,其形式化表达式为:
(7)
Qt,u=ω1×Vuser+ω2×Vtask+ω3×Venv;
(8)
Vuser=pow+dmobile-sbusy;
(9)
(10)
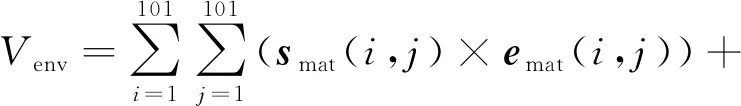
(11)
其中BT=(1,2,3,4,5),Ω(At,Au)为感知任务与用户的欧几里得距离,(8)式在进行加权求和时,对每项因子进行归一化.
通过修改过的Crowd-Cluster意愿模型与基于mobility设置的实验参数,仿真生成16 400个样本.单个样本数据的形式化表示为
samplei=(xi,yi).
(12)
其中xi中为1阶3 220维的用户意愿特征张量,yi为通过修改过的Crowd-Cluster意愿模型生成的用户意愿.
3.2 意愿模型评估
设置如表10所示的5个基线方法,用于评估用户意愿模型的预测准确率.
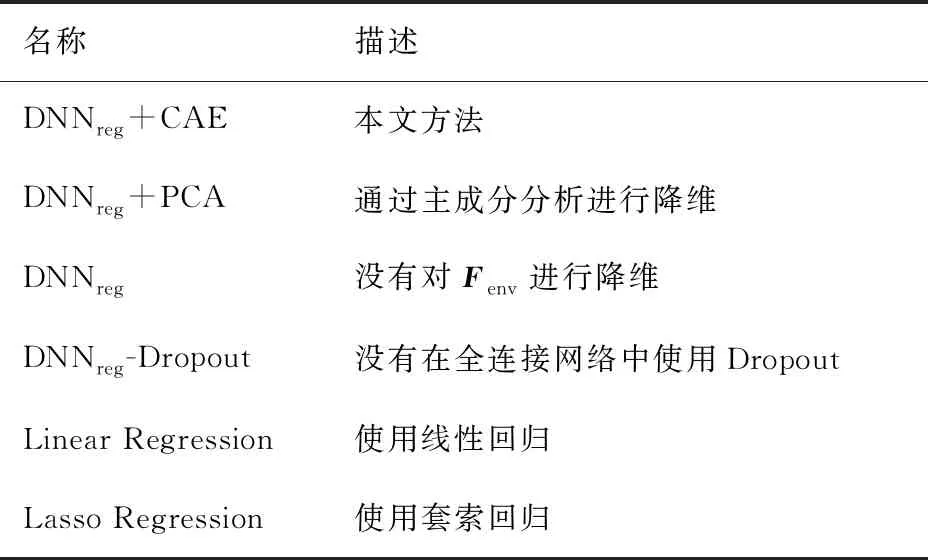
表10 基线方法
采用R2决定系数 (R2Score)作为模型评估指标,检验模型对用户意愿的拟合效果,其公式为
(13)
记录模型训练的损耗时间,来评估模型性能.结果如表11所示.

表11 意愿模型评估实验结果
根据表11的实验结果可以看出.本文方法拟合程度最优,原因主要在于卷积自编码是非线性降维压缩效果优于线性降维的主成分分析,并且丢失信息数据较少.线性回归与套索回归属于浅层机器学习,本质属于数学数据的线性组合,其时间损耗远小于神经网络模型,但拟合程度较低,难以较准确地评估用户意愿.而本文方法由于更少的维度特征使得训练速度优于其他的神经网络模型.
3.3 参与者选择方法评估
通过两个感知任务案例来评估混合优选机制的效果及合理性.在mobility数据中截取2个实时的用户分布场景,并参考表9对用户的相关参数进行设置.每个感知场景中设置一个不同紧急程度的感知任务,其任务部分参数设置如表12所示.

表12 任务参数设置
通过任务完成度、总移动感知时间、平均用户意愿这3个指标来反映感知任务的完成质量及效率,进而评估参与者选择方法的效果.任务完成度计算公式为
(13)
其中NeedPt为感知任务所需的参与者人数.不失一般性,每个用户如果正常完成感知任务,其对任务的贡献度是一样的.而用户的实时意愿程度和其历史信誉度,侧面反映了用户在执行这次感知任务过程中退出或者上传虚假感知数据的可能性.
(14)
不失一般性,由于完成一次感知任务的执行时间对于每个用户而言是差不多的,移动群智感知往往是微感知任务,感知时间较小.因此,仅考虑用户移动到任务位置的时间,来评估任务的完成效率.总移动感知时间为参与者移动到任务目标区域所耗费的时间之和.其值越小则完成效率越高.平均用户意愿计算公式为
(15)
通过作为参与者的用户意愿均值来衡量用户的参与水平.值越大用户参与水平越高.
本文通过调节权重kw与ke设置了4种参与者选择方法(如表13所示).

表13 参与者选择方法
上述4种参与者选择方法基于t1进行实验的结果如表14所示.
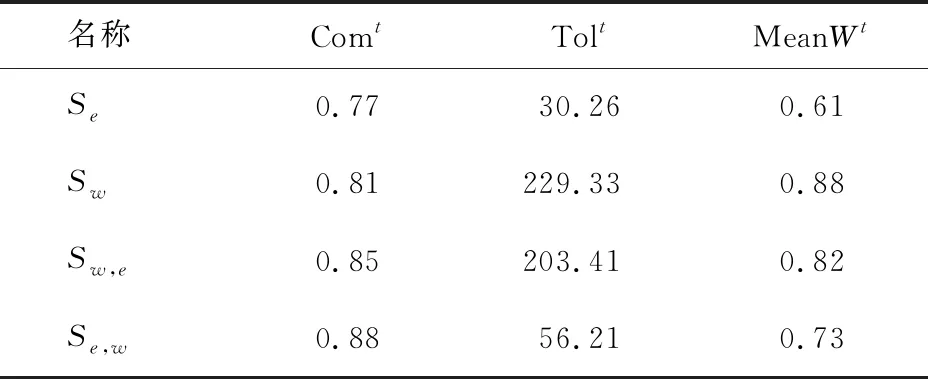
表14 基于t1的实验结果
t1为较为紧急的感知任务,在实际感知场景中如果出现拥堵,如道路路面坍塌、基础设施严重损毁、严重交通事故等紧急事件时,政府及有关部门希望第一时间得到事故地点的准确信息.在这种感知场景下,用户意愿是其次的,优先考虑的是任务的完成度以及时间效率.通过表14中的数据可以得出,仅考虑用户效用值的参与者选择方法虽然能够保证参与者快速到达指定的目标区域,但是由于普遍用户意愿较低,有较大概率上传虚假数据或是中途退出,致使感知任务完成度低.不准确的感知数据不利于政府及有关部门进行准确的决策,以应对突发事件.而仅考虑用户意愿和侧重考虑用户意愿的参与者选择方法,虽然任务完成度高,但耗费的时间过多,不利于有关部门及时做出决策.其中,由于仅考虑意愿的参与者选择方法仅考虑了用户实时意愿,没有考虑用户效用值中的用户历史信誉度,用户出现中途退出或是恶意上传数据等行为的概率依旧比较高,致使最终的任务完成度也相对不高.因此综合考虑,侧重用户效用的混合参与者选择在该场景下的最优参与者选择方法,能够在保障任务完成度的同时,尽可能优化感知时间,使得政府及有关部门能够在较快的时间内得到较为准确地感知数据.
4种参与者选择方法基于t2进行实验的结果如表15所示.

表15 基于t2的实验结果
t2为较为日常的感知任务,其紧急程度相对较低.但是道路交通信息感知、空气质量感知、噪音感知等任务出现的频率很高,在日常生活中如政府部门、研究机构乃至用户本身,都可能作为长期的数据请求者在平台上发布相关的感知任务.考虑到上述情况,如果要保证用户能够经常性地完成这样的日常感知任务,就需要维护用户的长时参与水平.因此,在这种感知任务场景中,除了任务完成度及效率,用户意愿需要也是要着重考虑的.
通过表15的数据可以发现,仅考虑用户效用的参与者选择方法其完成度与用户平均意愿的值均相对较低.而仅考虑用户意愿的参与者选择方法时间损耗太大,效率过低.侧重考虑用户效用的混合参与者选择方法的用户意愿相对较低,不利于维护用户的长时参与水平.侧重考虑用户意愿的混合参与者选择方法其用户意愿略微低于仅考虑意愿的参与者选择方法,但执行效率以及任务完成度有明显提升.侧重考虑用户意愿的参与者选择方法较为契合该感知场景.
根据上述两个不同感知场景的案例可以得出,综合考虑用户意愿以及用户效用的混合参与者选择方法其效果优于仅考虑用户意愿或者用户效用的参与者选择方法.并且通过调节权重kw与ke可以使得混合参与者选择方法适应不同的感知场景,使得选择出的参与者集合在保证感知质量的同时,维护用户的意愿.
4 结语
本文提出了一种基于用户意愿的参与者优选方法.主要工作分为2个部分:(1) 构建了一个基于深度神经网络与卷积自编码器的用户意愿评估模型.详细分析了可量化的意愿因素,细分类成3类意愿因子,并采用不同的方式对各类意愿因子进行建模,实现较为合理的形式化表达.(2) 设计平衡用户意愿与用户效用的参与者选择机制.
通过线性加权实现了用户意愿与效用的合理叠加,并可以通过调节权重,实现在不同紧急程度的场景下,微调用户意愿与用户效用的侧重比.后续工作需要融合行为经济学、博弈论等交叉学科,深度分析用户执行感知任务的心理活动,进一步完备意愿因子,构建更为准确、适用性更好的意愿评估模型.
