基于改进残差网络的铁路隧道裂缝检测算法研究
2021-10-15饶志强李益晨赵玉林
常 惠,饶志强,李益晨,赵玉林
(1.北京联合大学北京市信息服务工程重点实验室,北京 100101;2.北京联合大学城市轨道交通与物流学院,北京 100101)
0 引言
我国铁路隧道在运营期间因为各种原因产生不同程度的病害,衬砌裂缝是最常见的一种,裂缝会影响隧道的稳定性,对于铁路隧道安全运行是个极大的隐患,久而久之会对列车的运行造成负面影响,因此对隧道裂缝进行及时有效的识别与处理是一项非常重要的工作.目前,我国铁路隧道裂缝的检测大多使用人工检查的方法,该方法难以满足铁路安全检测快速发展的要求.目前利用计算机视觉和数字图像处理来检测裂缝已引起越来越多学者的关注,常用的方法如Gabor滤波[1]、随机森林[2]、稀疏表示方法[3]、支持向量机(SVM)[4-5]和Hough变换与SVM相结合[6]等方法.虽然这些方法取得了较好的检测效果,但是它们对输入图像的质量要求较高,而铁路隧道图像包含复杂的自然特征,例如油漆、水渍和结构缝等,加之隧道内光线不均匀和噪声的干扰,使得裂缝检测受到极大的影响.
近年来,深度学习取得了飞速的发展,并且在结构健康监测领域也得到了很大的应用,越来越多的研究者使用深度学习的方法对裂缝进行检测.文献[7]提出了一种8层CNN来扫描小块的高分辨率裂缝图像,并引入基于相位的视觉流模型来考虑时间因素进行裂缝的分类;文献[8]将基于CNN的裂缝检测方法与6个常见边缘检测器的性能进行了比较,结果表明CNN架构优于其他方法;文献[9]提出一种基于卷积神经网络分类的方法,该方法对桥梁背景面元和裂缝面元进行检测识别,并且取得了很好的效果;文献[10]通过将裂缝图像切分成若干图像块后,利用卷积神经网络得到图像块的裂缝概率图实现裂缝的检测,上述基于CNN的方法计算量较大,速度有待进一步提高;文献[11]以像素为单位将裂缝图像切分成若干图像块,利用图像块对卷积神经网络训练和检测,但该方法样本相似度高,且需要考虑训练样本中裂缝和非裂缝样本的比例,实现起来较为困难;文献[12]基于GoogleNet模型,通过改进Inception模块和优化卷积核,提升网络对隧道衬砌图像病害分类识别的能力,但该方法未考虑图像中病害的位置特征,检测效率有待进一步提升;文献[13]使用迁移学习的方法对裂缝进行分类,对较小的数据集采用预训练的VGG16模型进行微调来完成分类任务,但模型精度有待提高.
经过许多研究实验发现,ResNet网络中使用的残差算法使图像分类更加准确,因为残差算法大大提高了神经网络提取特征的能力[14],因此可以被用来进行铁路隧道裂缝检测.但是,ResNet在改善感受野方面不是很有效,不能更好地提取图像的某些特征.针对铁路隧道裂缝图像的特点,可对基础的网络结构进行改进,主要改进几个方面:将具有不同扩张率的空洞卷积块与传统的卷积块相结合,形成金字塔空洞卷积模块;添加金字塔空洞卷积模块改善ResNet网络的底层感受野并提高分类的准确率;采用基于度量学习的组合损失函数来区分不同类之间的相似差异,减少裂缝的漏检率和误检率,从而更好地实现复杂背景下细小裂缝的检测.
1 理论基础
1.1 卷积神经网络
作为一种有监督的学习算法,与深度人工神经网络相比,卷积神经网络(Convolutional Neural Networks,CNN)具有更少的参数和更快的训练速度的优势,并且在图像分类、分割和检测等方面具有显著优势.CNN是一个多层结构的学习算法,它使用局部特征的各层相关关系来减少参数的数量以提高模型的性能.卷积神经网络结构如图1所示.

图1 卷积神经网络结构
由图1可以看出,卷积神经网络结构由输入的原始图像、卷积层、池化层、全连接层、分类器和输出这几部分组成,卷积层对图像特征提取之后,将提取的特征发送到最后一层的全连接层以进行裂缝图像的分类,本文基于PyTorch框架搭建卷积神经网络,用于铁路隧道裂缝的检测.
1.2 残差网络
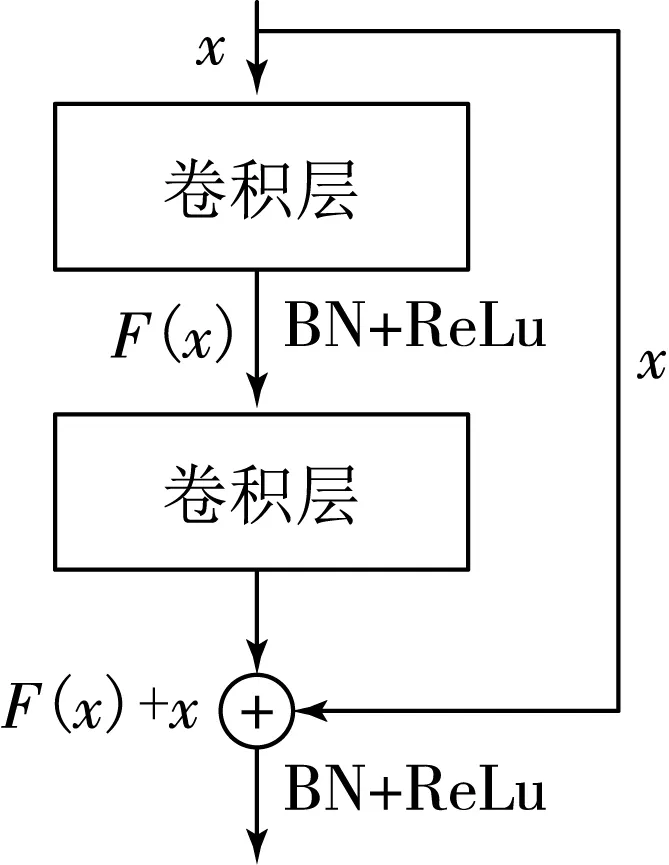
图2 残差模块结构
残差网络是一种深度神经网络模型,随着网络的深化,梯度在反向传播过程中很容易消失,导致无法更新参数并影响网络收敛.另外,神经网络的加深会导致网络退化,而残差网络中的残差模块使用跳跃连接很好地解决了这些问题,使得在设计神经网络模型时可以达到数十层甚至数百层的深度,近年来由于其卓越的性能,该网络模型已在许多领域中得到了广泛应用.残差模块结构如图2所示,可以看到x作为输入值,经过线性变换和激活函数得到残差F(x),在激活前将F(x)与x用shortcut连接相加即为残差模块的主要思想,这样可以保证恒等变换和反向传播时的梯度传递.残差模块可以定义为
y=F(x)+x.
(1)
式中:x为输入值;y为输出值;F(x)是待学习的残差映射函数.
2 算法总体设计
2.1 改进的残差网络
2.1.1 ResNet网络
裂缝图像是基于纹理特征进行区分的,而且细小裂缝和有其他噪声的无裂缝之间的纹理特征相似程度较高,体现在微小特征上的差别,为保证裂缝检测的效率,使用ResNet网络进行分类识别,由于铁路隧道裂缝图像识别属于二分类,所以为了提取微小的特征以及减小网络模型的参数量,选择结构相对简单的ResNet18作为裂缝分类的网络,ResNet18的基本结构如图3所示.
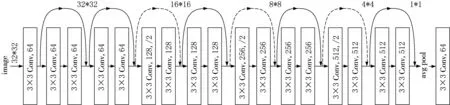
图3 ResNet18的基本结构
2.1.2 空洞卷积
传统卷积神经网络的池化层有利于降低图像尺寸、增加特征图步长,但存在裂缝图像细节信息丢失,从而导致复杂背景下裂缝误检和漏检等问题.空洞卷积(Dilated Convolutions,DC)是一种特殊的卷积方式,可以在不降低特征图分辨率的情况下增加卷积核的接收范围,并且可用于多尺度特征图像的提取.空洞卷积与普通卷积相比,除了卷积核的大小以外,还有一个扩张率(Dilation Rate)参数,主要用来表示扩张的大小.空洞卷积在卷积的时候,会在卷积核元素之间加入空格,若原来的卷积核大小为k,空洞卷积的一个新的超参数为d,那么加入(d-1)个空格后的卷积核大小n的计算公式为
n=k+(k-1)(d-1).
(2)
进而,假定输入空洞卷积的大小为i,步长为s,填充的像素数为p,空洞卷积后特征图大小o的计算公式为
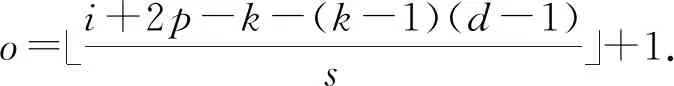
o=i+2p-k-(k-1)(d-1)s+1.
(3)
假设一个3×3的卷积核,图4给出了具有不同扩张率下的感受野.当扩张率为1时,扩张的卷积核与原始的普通卷积核相同;当扩张率为2时,原始的3×3卷积核将扩张为类似于5×5的卷积核,感受野为7*7;当扩张率为3时,原始的3×3卷积核将扩张为类似于9×9的卷积核,感受野为15*15,零是扩张期间的填充值,只有点上的值不为零,其余为零.针对裂缝分类时出现特征图卷积或池化降低分辨率造成的精度损失问题,可采用加入空洞卷积的方法,将散布的卷积增加感受野,同时确保在参数数量保持不变的情况下输出的特征图大小保持不变,保留裂缝的细节信息,提升算法的泛化能力.
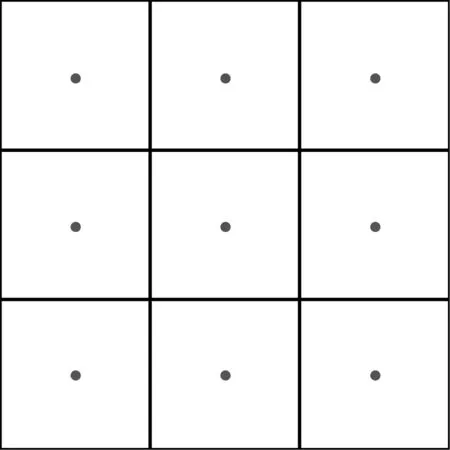
(a)扩张率=1

(b)扩张率=2

(c)扩张率=3
2.1.3 金字塔空洞卷积模块
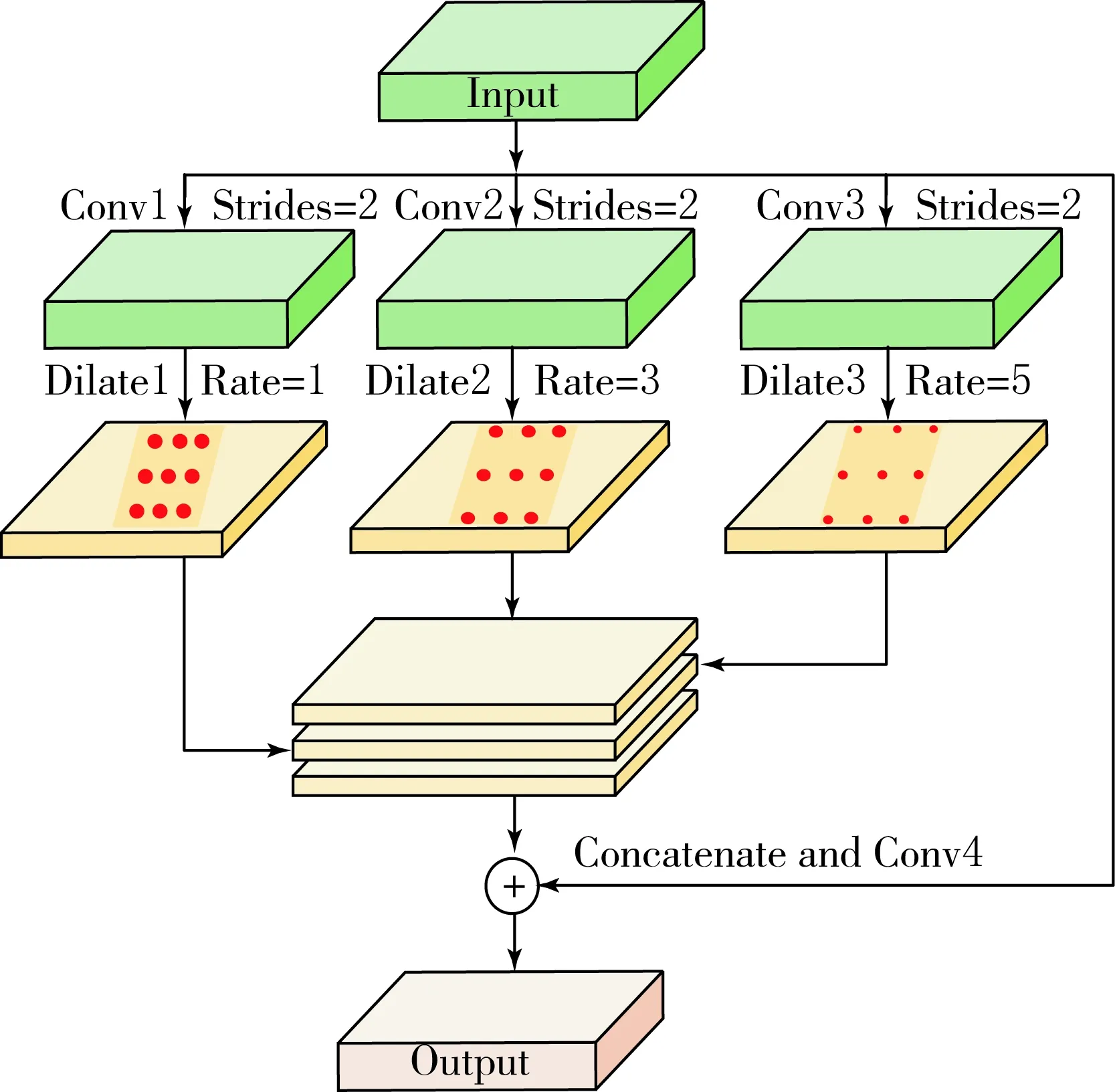
图5 金字塔空洞卷积模块
由于隧道内环境的问题,除了图片采光较差,还极易与背景环境(如水渍、油漆等噪声)存在低对比度现象,且可能具有相似强度的阴影,通过聚集小的区域来区分图像中类别是很困难的,在空间金字塔池化下进行空洞卷积,构建金字塔空洞卷积(Pyramid Dilated Convolution,PDC)模块,如图5所示.它继承了空间金字塔池化和空洞卷积的优点,不同扩张率的PDC模块可以有效捕捉图像的多尺度信息,可以获取到对图像的上下文信息和空间层级信息,使得隧道裂缝图像的细节信息得到有效的提取,提高尺度不变并且降低过拟合现象.
在该模型中,假设输入为X,输出为Y,Dilate1-Dilate3用来表示扩张的卷积核;Conv1-Conv4用来表示普通的卷积核;F1,F2,F3表示以不同的速率进行卷积后产生的输出;⊗表示卷积;{}表示级联算法,则Y可以表示为
Y={F1,F2,F3}⊗Conv4+X.
(4)
其中
F1=X⊗Conv1⊗Dilate1,
F2=X⊗Conv2⊗Dilate2,
F3=X⊗Conv3⊗Dilate3.
PDC模块并行采用不同扩张率的空洞卷积层以多个比例来获取裂缝像素特征以及隧道裂缝图像的上下文信息,利用并联的空洞卷积进行提取图像裂缝特征,然后对提取到的特征进行融合,这样可以将不同尺度的信息融合到一起,同时利用空洞卷积可以有效地扩大卷积层的感受野.与输入大小相比,空洞卷积具有恒定的输出大小的特性,这种改善感受野的方法非常适合ResNet网络的底层.
2.1.4 基于金字塔空洞卷积的ResNet网络
基于卷积神经网络的模型中存在一些不足.例如,网络无法训练为增强感受野而添加的池化层的参数,导致有关小物体的信息无法重建.这些对于常见的卷积神经网络中的ResNet也是不可避免的.为了使ResNet在隧道裂缝图像分类中更好,在其底部添加金字塔空洞卷积模块,设计出一种改进残差网络PDC-ResNet(Pyramid Dilated Convolution Residual Network,PDC-ResNet)模型,其结构如图6所示.
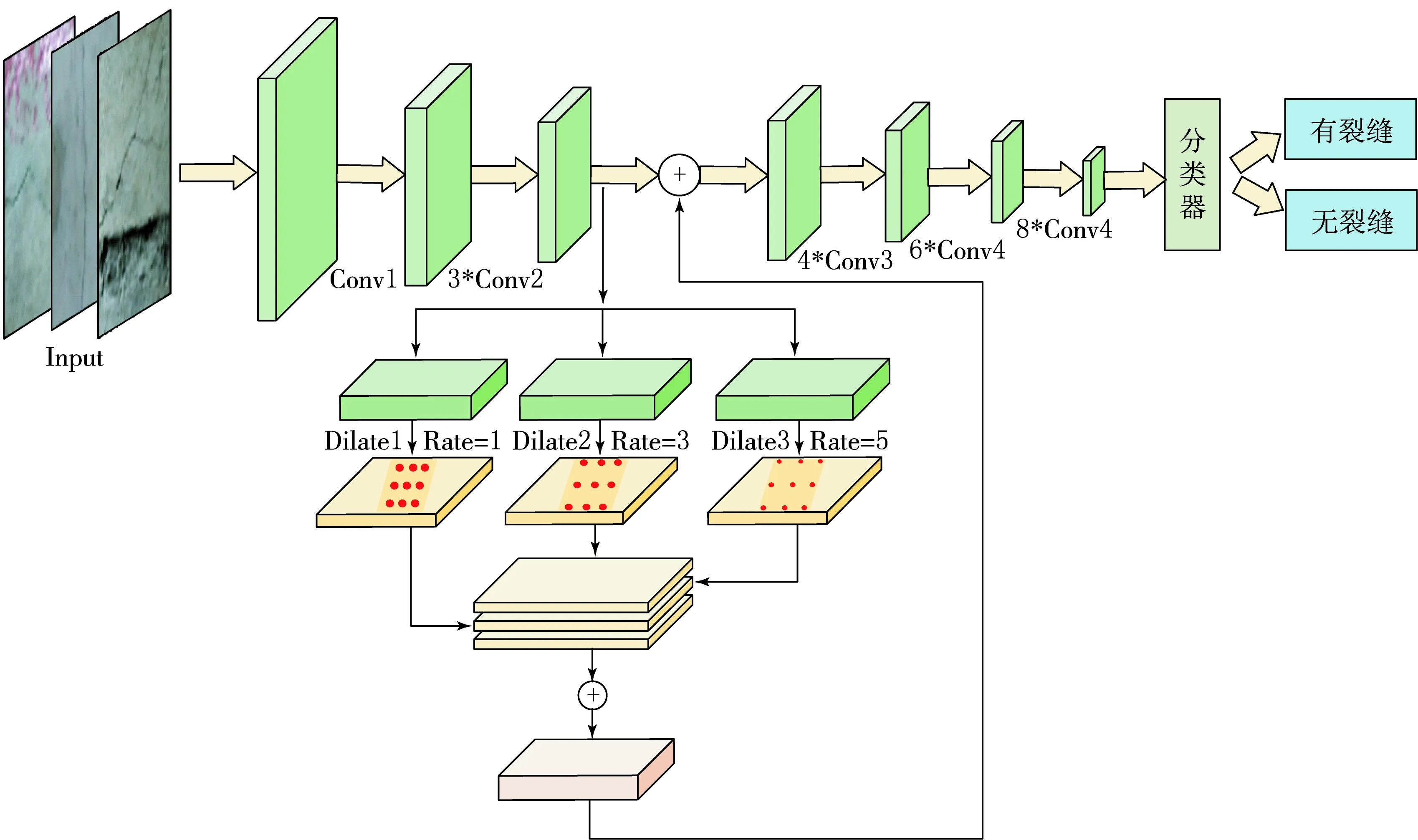
图6 基于金字塔空洞卷积的ResNet网络结构
由图6可以看出,金字塔空洞卷积模块被集成到ResNet的底部,以增加原始网络的感受野并提高分类精度,在修改ResNet时,由于隧道裂缝图像识别属于二分类,而原始的ResNet基本结构适合进行多分类.因此,我们将每个卷积块的卷积内核数量减少了一半,并且进行了一些实验来选择模块的扩张率.最后针对数据集选择1,3和5作为扩张率,并以不同的扩张率将不同的扩张卷积的输出串联起来.
2.2 Softmax分类
在图像分类中,卷积神经网络通常使用Softmax分类器,并且Softmax层在网络的全连接层之后,它将许多神经元随时间的输出映射到区间(0,1)内,每个神经元的输出值之和为1,这可以解释为概率,然后将概率最大的类别表示输出结果,预测并执行分类任务.该方法分类高,并行分布处理能力强,能充分逼近复杂的非线性关系,计算量较小,训练速度较快,所以本文的铁路隧道裂缝检测网络输出层采用Softmax分类器.其中,输出概率的计算公式为
(5)
因铁路隧道裂缝检测算法是二分类问题,故式中k的值为2.
2.3 基于度量学习的组合损失函数
实际采集的铁路隧道裂缝数据集两类之间的差异并不总是特别明显,例如有裂缝的图片和有水渍等复杂背景的图片,细小裂缝图片和无裂缝的图片.有些图片背景存在一定相似性,如仅从局部性的图像上难以区分是何种类别,所以要提升分类的精度还要更好地解决正确区分相似类别之间差异的问题.考虑到实际应用的需求,应设计参数更少的网络.因此,本文从损失函数角度进一步提高识别精度,设计基于度量学习(Metric Learning)的损失函数衡量图像的特征之间的差异性,其计算公式为
Lossr=max(‖f(A)-f(P)‖2-‖f(A)-f(N)‖2+C,0).
(6)
其中:Lossr代表度量学习的损失函数;A代表目标样本的特征;P代表提取的图像特征;N代表与A不同类别的特征;C代表大于0的数;max(x,0)代表当其输入x小于0时,max(x,0)的输出为0,x大于0时,输出x.所以,从度量学习的损失函数可知,部分x小于0时表示相同类别之间的距离已经足够小,且小于不同类别特征之间的距离.
由于裂缝识别任务是一个分类问题,因此,对最终的预测结果采用交叉熵损失函数,其计算公式为
Lossc=-[ylogy′+(1-y)log(1-y′)].
(7)
式中y′和y分别表示预测的标签概率值以及真实标签,当损失函数的值不断减小时,表示预测的概率分布接近真实标签y的数据.
所以总的损失函数为
Loss总=α*Lossr+β*Lossc.
(8)
其中:α,β分别代表每个损失函数的权重,均为大于0的数.实验中超参数α,β均设置为1.
3 实验结果与分析
3.1 实验设置
本文在Ubuntu 16.04操作系统使用Python编程语言上进行相关实验,实验基于PyTorch的深度学习框架,硬件研究平台:Intel I7-9750H、Nvidia GTX1660Ti、16 GB内存.
利用公共数据集和实际采集的数据进行实验验证,训练集和测试集按8∶2的比例进行划分,实验通过控制单一变量,在同一运行环境分别使用不同改进算法的残差网络模型,然后进行对比分析.研究实验图片统一输入尺寸为512像素×512像素,并在输入过程中加入水平翻转、小角度旋转来扩充数据集,模型使用Adam优化器,初始学习率设定为0.001,批量大小设定为32,迭代次数为100次.
3.2 SDNET2018数据集实验
SDNET2018[15]是带注释的图像数据集,用于训练、验证和测试基于人工智能的混凝土裂缝检测算法,该数据集包含超过56 000张有裂缝和无裂缝的路面、墙壁和桥梁的图像,里面包含的裂痕窄至0.06 mm,宽至25 mm,并且数据集还包括带有各种障碍物的图像,包括阴影、表面粗糙度、缩放、边缘、孔洞和背景碎片.其中,SDNET2018数据集的信息如表1所示.

表1 SDNET2018数据集 张
利用文献[15]的方法AlexNet和ResNet、PDC-ResNet、ResNet-改进Loss以及本文方法(PDC-ResNet与改进Loss相结合)对SDNET2018数据集进行裂缝识别,不同模型的准确率如表2所示.

表2 不同模型在裂缝检测上的准确率对比 %
通过表2不同实验在裂缝检测上的准确率对比可以看出,本文方法在路面、墙壁和桥梁这3种数据集上的准确率分别达到了97.32%,91.73%,92.84%,与文献[15]的方法相比模型性能都有较大的提升,相比基础的ResNet网络来说具有一定的先进性,并且添加金字塔空洞卷积模块和基于度量学习的组合损失函数都能有效提升裂缝分类的准确率,上述结果也证明了使用改进的ResNet网络对裂缝图像进行分类的优势,这为铁路隧道裂缝检测提供了新思路.
3.3 CRACK数据集实验
本文通过实际采集和网络爬虫的方式来获取铁路隧道裂缝图像样本数据,然后对数据进行预处理,构建铁路隧道裂缝图像数据集(CRACK数据集),数据集中分为两类:有裂缝(1 000张)和无裂缝(1 000张),图像大多数背景较为复杂,并且裂缝种类多样.CRACK数据集部分图像数据如图7所示.

(a)有裂缝

(b)无裂缝
此外,针对自制训练集图像格式不一致且样本量小的问题,对图像进行预处理,其中包含灰度处理、高斯滤波和图像归一化等.由于测试集不参与网络的训练,所以我们仅对训练集进行旋转、缩放、对比度调整、镜面对称和添加噪声等操作来扩充数据,防止网络过度拟合并提高网络的泛化能力.为体现模型及算法先进性,设立4组消融试验对比改进模型的性能,其中,不同模型的准确率曲线和损失函数曲线如图8和9所示.
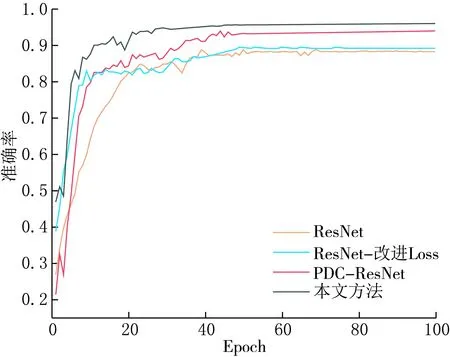
图8 准确率曲线
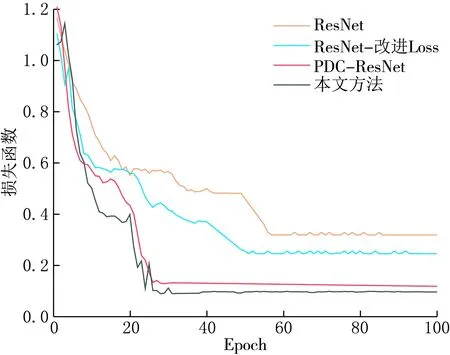
图9 损失函数曲线
由图8和9可知,本文的方法精度增长稳定,且增长速度快于其他网络,PDC-ResNet网络和改进的Loss函数的收敛速度和识别准确率也都高于基础的ResNet网络,且在网络训练层数加深多次迭代下,残差网络模型未出现明显的网络退化现象.为进一步验证网络的性能,使用精准率(P)、召回率(R)、F1分数(F1)3个指标来评价铁路隧道裂缝分类模型的优劣.3种指标计算方式分别为:
(1)P突出显示误检的比例
(9)
式中:TP代表真阳性(True Positive),FP(False Positive)代表假阳性.P表示预测为真的数据里预测正确的数据个数的比例.该值越接近1代表性能越好.
(2)R突出显示漏检的比例
(10)
式中:FN(False Negative)代表假阴性.R表示实际为真的数据里预测正确的数据个数的比例.该值越接近1代表性能越好.
(3)F1综合考虑了P与R:
(11)
同样,该值越大代表模型性能越好.
表3列出了4种不同模型在铁路隧道裂缝检测上性能对比,从表3中可以看出PDC-ResNet网络的P相比未改进的基础网络提高了2.62%,R和F1也得到了很大的提升,说明在ResNet底部添加金字塔空洞卷积模块之后可以获取到对图像的上下文信息和空间层级信息,使得隧道裂缝图像的细节信息得到有效的提取,捕捉隧道数据的多尺度特征,提高分类的性能.采用改进损失函数的ResNet与ResNet两模型的P相比提高了1.17%,R提高了1.35%,改进损失函数的F1也有所提升,并且本文方法的P提高了4.73%,R提高了7.82%,F1提高了6.29%,说明加入度量学习的组合损失函数区分隧道图像的差异后,将相同类别的图像特征之间的距离拉近,将不同类别特征之间的距离拉远,可以在模型参数不变的情况下对分类精度有明显的提升,结果也证明了本文提出的方法在区分不同类之间相似差异上的有效性.

表3 不同模型在铁路隧道裂缝检测上性能对比 %
4 结论
本文针对传统残差网络和损失函数在铁路隧道裂缝检测问题上的不足,提出一种改进残差网络PDC-ResNet及基于度量学习的组合损失函数的裂缝分类方法.该方法首先在ResNet底部添加不同扩张率的金字塔空洞卷积模块,确保既不降低特征图分辨率,又能扩大卷积核感受野,这能很好地用于隧道裂缝图像多尺度特征的提取,增加分类的准确率;其次通过设计基于度量学习的组合损失函数使得模型能在训练中尽可能增大不同类之间距离来对复杂背景下细小的裂缝进行更好地分类.实验表明,本文方法相比较ResNet基础网络可以提高铁路隧道裂缝识别准确率,并且在3种不同的评价指标上证明了该方法的有效性.但实验对图像数据样本的质量要求较高,并且数据集的样本相对来说比较少,后续可采集更多类型的高质量铁路隧道裂缝图片,训练性能更好的分类网络模型,对裂缝进行有效及时的识别,以满足结构健康监测的铁路隧道裂缝检测和检查的要求.
