基于Bert和卷积神经网络的人物关系抽取研究
2021-10-15杜慧祥杨文忠石义乐柴亚闯王丽花
杜慧祥,杨文忠,石义乐,柴亚闯,王丽花
(1.新疆大学软件学院,新疆 乌鲁木齐 830002;2.新疆大学信息科学与工程学院,新疆 乌鲁木齐 830002)
0 引言
随着互联网数据爆炸式的增长,各种半结构化数据与非结构化数据也在不断增多.如何从半结构化数据与非结构化数据中提取有效的结构化信息,是当前信息抽取领域的一个研究热点和难点.信息抽取作为自然语言处理领域中的一个重要的研究子领域,近年来受到了国内外研究学者的不断研究,其中实体关系抽取技术是信息抽取中的一个关键技术,也是构建知识图谱的重要技术之一,其主要的研究目的是从包含实体对以及包含某种语义关系的句子中提取出所需要的关键信息.目前实体关系抽取技术主要分为有监督的、半监督的、无监督的、开放领域的、基于远程监督的、基于深度学习的等6类方法.有监督的关系抽取又分为基于特征向量的方法和基于核函数[1]的方法.基于特征向量的方法是从包含关系的句子中,选择该句的上下文中包含的词法、语法和句法等特征来构造特征向量,进一步通过计算特征向量的相似度来训练实体关系抽取模型,最后完成关系抽取.基于核函数的方法也是比较常用的一种方法,文献[2]采用浅层解析树核与SVM、投票感知器相结合的算法从非结构化的文本中抽取人-从属关系和组织-位置关系.文献[3]通过扩展前人工作,提出依赖树核,通过计算依赖树核的相似度来进行实体关系抽取,实验结果表明,基于依赖树核的方法比基于“词袋”核的效果有较大的提高.
有监督的实体关系抽取方法虽然在一定程度上提高了关系抽取的效率,但是需要人工标注大量的语料,因此有人提出了半监督的实体关系抽取方法.半监督的实体关系抽取最先提出的是Bootstrapping方法[4],该方法首先人工设定若干种子实例,然后迭代从数据中抽取关系对应的关系模板和更多的实例.半监督实体关系抽取技术可以减少人工标注数据的语料,但是该方法需要人工构建高质量的初始种子集,且该方法不可避免地会引入噪声和语义漂移现象.
在面对大规模语料的时候,有监督和半监督的关系抽取方法往往不能预测到所有位置的实体关系类型,因此人们提出了基于聚类方法的无监督关系抽取.无监督的实体关系抽取在无标注的数据集中利用聚类算法将上下文中出现的实体对相似度高的聚为一类,用包含特定意义的词来表示这种关系.无监督的实体关系抽取方法不需要人工预先定义的关系类型,但其聚类的阈值确定相对较难,且目前基于无监督的实体关系抽取方法没有统一的评价指标.
基于开放领域的实体关系抽取方法,是为了构建某领域的语料库时减少人工的参与,该方法在不需要任何人工标注的情况下,通过与外部大型知识库(如DBpedia、YAGO、FreeBase等)将完整的、高质量的实体关系实例与大规模的训练数据对齐来获得大量的训练数据.基于远程监督的关系抽取方法也是为了减少人工参与标注数据集而被提出来的.文献[5]首次提出基于远程监督的实体关系抽取方法,该方法假设两个实体间如果存在某种关系,那么在整个语料库中包含这两个实体的句子都存在这种关系.该方法在一定程度上减少了对标注数据集的依赖,但其也带来了数据噪声和错误传播的问题.
近年来,随着深度学习的快速发展,将深度学习的方法应用到实体关系抽取中得到了大量研究学者的关注.文献[6]提出将递归神经网络与矩阵向量表示相结合的模型,该模型可以学习任意长度的短语和句子的向量表示,但是忽略了实体对之间的位置信息以及其他的特征信息;文献[7]利用卷积神经网络的方法进行实体关系抽取,采用词向量和位置向量作为卷积神经网络的输入,通过卷积层、池化层和非线性层得到句子的表示;文献[8]针对捕获句子中重要信息不明确的问题提出了基于注意力机制的双向长短期记忆神经网络(ATT-BILSTM).
目前在关系抽取领域中主要针对的是英文,但近年来随着深度学习技术的广泛使用,对中文关系抽取的研究也有了一定的进展,文献[9]提出一种基于自注意的多特征实体关系提取方法,该方法充分考虑了词汇、句法、语义和位置的特征,并利用基于自注意机制的双向长短期记忆网络预测实体之间关系;中文关系抽取任务中的数据稀疏和噪声传播问题一直是研究的难点,文献[10]提出一种将位置特征、最短依存等特征融合起来,并提升关键特征的权重,改善了噪声传播的问题;文献[11]提出一种多通道的卷积神经网络用来解决单一词向量表征能力的问题,该模型利用不同的词向量作为输入语句,然后传输到模型的不同通道中,最后利用卷积神经网络提取特征,利用Softmax分类器完成关系分类.以上方法大多数是采用早期预训练方法词嵌入(Word Embedding)进行向量表示,词嵌入的方法是2003年最早提出的[12],该方法利用了词分布表示考虑了上下文之间的相似度.2013年谷歌公司的研究人员发布了Word2vec工具包,该工具包包含了Skip-Gram模型和CBOW模型[13],两个模型能够获取文本之间相似性,但只考虑了文本中的局部信息而忽略了全局信息.2018年Google发布了Bert预训练模型[14],该模型通过充分的对词和句进行提取,能够得到动态编码词向量捕获更长距离的依赖,在2018年10月底公布了Bert在11项NLP任务中的表现,Bert取得了较好的结果.因此本文在Bert预训练模型下,提出了Bert-BiGRU-CNN的网络模型进行人物关系抽取.该网络模型首先通过Bert预训练模型获取包含上下文语义信息的词向量,然后利用双向门控循环单元(BiGRU)和卷积神经网络(CNN)提取上下文相关特征进行学习,最后通过全连接层利用Softmax进行关系分类.
1 模型介绍
本文提出的Bert-BiGRU-CNN模型如图1所示,其主要结构:(1)Bert层.利用Bert预训练模型获取包含上下文语义信息的词向量.(2)BiGRU层.获取上下文的文本特征.(3)CNN层.进一步获取文本的局部特征.(4)输出层.利用Softmax分类器进行关系分类.
1.1 Bert层
大多数模型采用的都是2018年Google公司的研究人员提出了Bert预训练模型,该模型在自然语言处理领域得到了广泛的好评,随后Google公司公开了Bert预训练模型在11项自然语言处理任务中取得的效果,肯定了Bert预训练模型的学术价值.Bert预训练模型主要包含输入层和多层Transformer编码层,其基本结构图如图2所示.Bert的输入层是通过词向量(Token Embeddings)、段向量(Segment Embeddings)和位置向量(Position Embedings)3个部分求和组成,且给句子的句首句尾分别增加了[CLS]和[SEP]标志位.Transformer编码层是文献[15]提出来的,包含了多个结构相同的编码器和解码器,从编码器输入的句子会通过一个自注意力(Self-Attention)层,然后传输到前馈神经网络(Feed-Forward Neural Network)中,解码器中除了包含这两层之外,在这两层之间多了一个注意力层,以此来关注与输入句子中相关的部分.Bert预训练模型的提出与传统的Word2vec、Glove预训练模型相比,Bert能够充分考虑词上下文的信息,获得更精确的词向量.本文采用Google公开的预训练好的中文模型“Bert-Base,Chinese”获取句子向量并作为模型的输入.
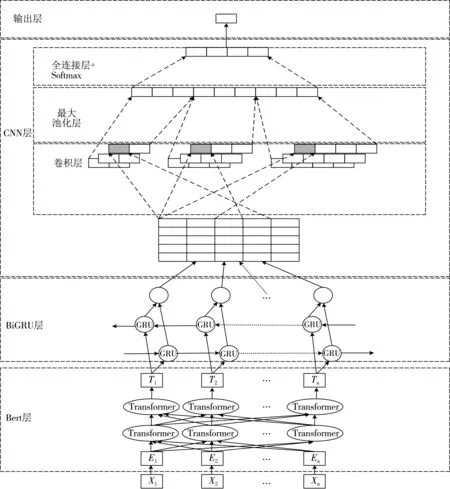
图1 Bert-BiGRU-CNN模型结构
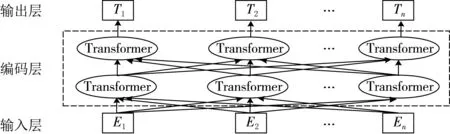
图2 Bert模型结构
1.2 BiGRU层
循环神经网络(Recurrent Neural Network)是一种处理序列数据的神经网络,其每个时刻的预测结果不仅依赖当前时刻的输入,还依赖于所有之前时刻的中间结果.由于每次输入都依赖之前的所有输入,所以存在梯度消失(Vanishing Gradient)和梯度爆炸(Exploding Gradient)的问题.文献[16]为了解决这个问题提出了LSTM(Long Short-Term Memory)网络.LSTM网络中包含输入门、遗忘门和输出门.输入门用来控制当前状态哪些信息应该保存到内部状态中;遗忘门用来控制过去状态中包含的信息是否应该删除;输出门用来控制当前内部状态下的多少信息需要传输到外部状态中.GRU网络是LSTM网络的一种简化模型,GRU神经网络[17]与长短期记忆网络(LSTM)相比,GRU网络将LSTM中的输入门与遗忘门替换为单一的更新门,更新门能够决定从各个状态中保留信息或者删除信息,除此之外GRU网络中还包含重置门,重置门是用来控制候选状态的计算是否与上一状态有依赖关系.GRU网络的具体计算公式为:
zt=σ(Wzxt+Uzht-1);
(1)
rt=σ(Wtxt+Utht-1);
(2)
(3)
(4)
其中:WZ,Wt,W,Uz,Ut,U表示权重矩阵;zt,rt分别表示为更新门与重置门;tanh表示激活函数;xt表示当前时刻的数据输入;ht-1表示上一时刻的输出;·表示矩阵点乘.
1.3 CNN层
卷积神经网络(CNN)作为图像领域的一种经典网络模型,近年来被广泛应用到自然语言处理领域中.本文在双向门限循环单元层之后加入了卷积神经网络来进一步获取语义的局部特征.主要由输入层、卷积层、池化层、全连接层、输出层5个部分构成.
(1) 输入层.将双向门限循环单元(BiGRU)的输出作为输入.
(2) 卷积层.卷积运算包含一个卷积核w∈Rh×k,该滤波器被应用于h字的窗口产生一个新的特征.例如,特征ci是从词xi:i+h-1窗口产生的,公式为
ci=f(w·xi:i+h-1+b).
(5)
其中:b是一个偏置项,f是一个非线性函数,如双曲正切等.·表示矩阵之间的点乘,将卷积核应用到句子{x1:h,x2:h+1,…,xn-h+1:n}中生成特征图
c=[c1,c2,c3,…,cn-h+1].
(6)
(3) 池化层.池化层不仅能够降维,还能保留特征和防止过拟合的现象发生.本文采用最大池化对卷积层之后得到的句子局部特征进行下采样,获得局部最优值
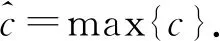
(7)
(4) 输出层.通过卷积神经网络层进一步获取局部特征,输出层采用Softmax分类器作为最后关系分类.
本文利用双向门限循环单元(BiGRU)层的输出作为卷积神经网络的输入层,通过卷积层进一步获取语义的局部特征,池化层采用Max-Pool(最大值池化)来降低语义特征维度,减少了模型的参数,保证了卷积层的输出上获得一个定长的全连接层的输入.最后采用全连接层利用Softmax分类器进行分类.
2 实验部分
2.1 数据集和实验设置
目前有关中文人物关系抽取的公开数据集比较少,因此本文通过在线知识库复旦大学知识工厂实验室研发的大规模通用领域结构化百科CN-DBpedia来获取实体对,CN-DBpedia中的数据主要从百度百科、互动百科、中文维基百科等网站的页面文本中获取.将确定好的实体对利用爬虫技术在新浪、百度百科、互动百科等网站页面中获取包含实体对的句子,通过人工整理后,构建出了人物关系数据集.该数据集包含了14类人物关系,10 155条实例数据,数据格式为〈实体1 实体2 关系类别、包含实体1和实体2的句子〉.实验采用随机的方法将人物关系数据集中的8 124条实例数据作为训练集,2 031条实例数据作为测试集.每种关系类别的数量如表1所示,数据格式示例如表2所示.
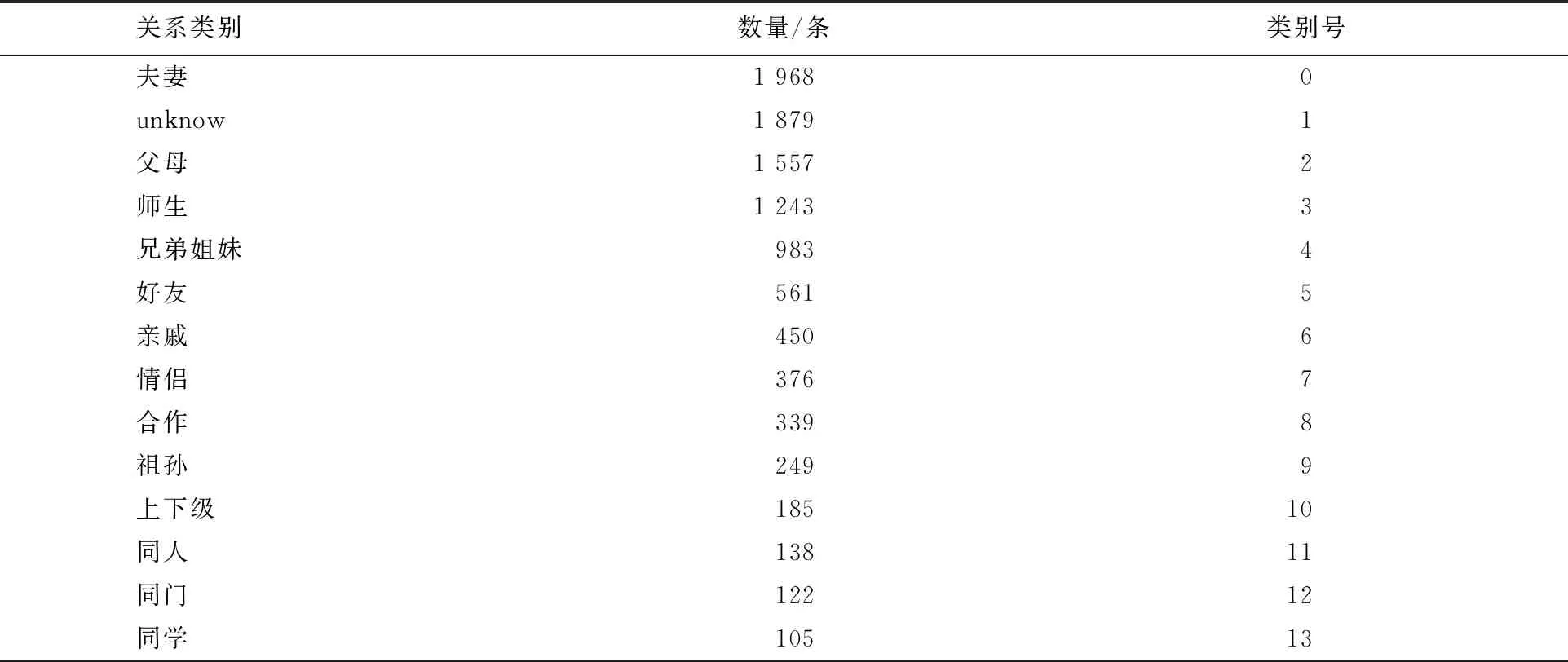
表1 关系类别数量
其中关系类别中“unknow”表示除表中13种关系以外的关系,“同人”表示同一个人不同的名字.

表2 数据示例
实验参数设置如表3所示.

表3 实验参数
2.2 实验方法和评价指标
为了验证本文提出的模型在中文关系抽取数据集上的效果,以Bert预训练模型作为基线,分别在Bert预训练模型下加入双向门限循环单元网络与注意力机制的结合、双向门限循环单元网络与卷积神经网络的结合、仅加入双向门限循环单元网络、仅加入卷积神经网络,利用这种模型在同一数据集进行训练.实验结果的评价方法采用宏精确率(P宏)、宏召回率(R宏)和F1宏值.公式如下:

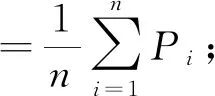
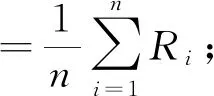
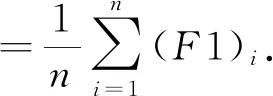
2.3 实验对比设置
在人物关系抽取实验中设置了以下几组对比实验,包括以Bert作为基线任务的单一的模型和组合的模型的对比:
(1) Baseline:采用Bert预训练模型作为基线模型.
(2) Bert-BiGRU:在Bert预训练模型下加入双向门限循环单元网络.
(3) Bert-CNN:在Bert预训练模型下加入卷积神经网络.
(4) Bert-BiGRU-ATT:在Bert预训练模型下,加入双向门限循环单元网络和注意力机制网络.
(5) Bert-BiGRU-CNN:在Bert预训练模型下,加入双向门限循环单元网络和卷积神经网络.
2.4 实验结果和分析
为了验证在Bert预训练模型下加入双向门限循环单元网络和卷积神经网络在人物关系抽取模型上的效果,利用表3设置的参数进行实验,各个模型的实验效果对比如表4所示.
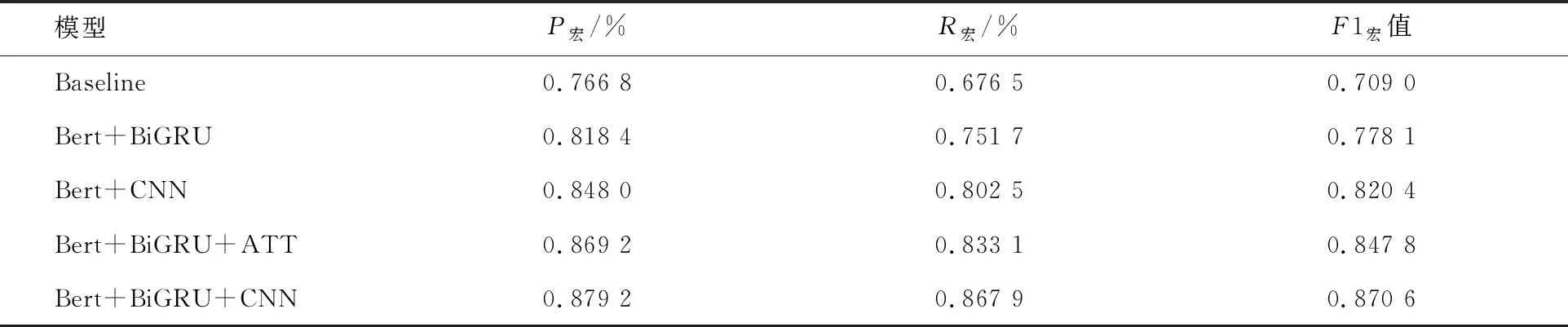
表4 不同模型的实验对比
通过表4对比发现在以Bert作为基线任务中,P宏为76.68%,R宏为67.65%;在基于Bert预训练模型的基础上,仅加入双向门限循环单元网络(BiGRU)的模型P宏为81.84%,R宏为75.17%;仅加入卷积神经网络模型(CNN)的P宏为84.80%,R宏为81.84%;加入双向门限循环单元和注意力机制的网络模型P宏为86.92%,R宏为83.31%;加入双向门限循环单元和卷积神经网络的模型P宏为87.92%,R宏为86.79%.无论从P宏、R宏还是F1宏值上来看,在Bert预训练模型下加入双向门限循环单元网络与注意力机制的网络模型要优于仅有双向门限循环单元网络的模型和仅加入卷积神经网络的模型,加入双向门限循环单元网络与卷积神经网络的模型获得了最高的P宏、R宏和F1宏值.由此可以证明,在Bert预训练模型下,加入双向门限循环单元网络和卷积神经网络的模型可以进一步提高在人物关系抽取数据集上关系抽取的准确性.
3 结束语
本文通过在Bert预训练模型下,提出一种将双向门限循环单元网络与卷积神经网络相结合的网络模型,利用Bert预训练模型获取文本的词向量,采用双向门限循环单元和卷积神经网络来提取局部语义特征,实现人物关系的抽取分类.本文提出的Bert-BiGRU-CNN模型在构造的人物关系抽取数据集与其他模型相比取得了最好的实验效果,但是本文未考虑更细粒度的关系分类,如师生关系中谁是老师,谁是学生.因此下一步的研究是将充分考虑细粒度的人物关系抽取.
