基于Jupyter的数据挖掘课程建设与研究
2021-10-15王茂发王子民汪华登刘振丙
王茂发 王子民 汪华登 刘振丙
(桂林电子科技大学计算机与信息安全学院,广西 桂林 541004)
1 引言
Jupyter Notebook是一个开源的Web应用程序,可用于创建和共享包含实代码、公式、可视化和叙述文本的文档。其用途包括:数据清洗和转换、数值模拟、统计建模、数据可视化、机器学习、深度学习、元学习等。当前,在Jupyter平台下最为流行的应用方式之一,即为采用Python语言结合各种机器学习工具包进行数据挖掘开发和教学。
选择Jupyter为数据挖掘课程的教学和实践平台有以下5个优点:(1)代码与结果展示一体融合,教与学的结果即时呈现;(2)支持当下最为流行的Python语言及其各种数值分析、数据处理和机器学习、深度学习开发包[1,2],如:Numpy、Pandas、Scikit-learn、Tensorflow、Pytorch、Keras等;(3)支持以网页的形式分享,并对多种格式无缝兼容,如:HTML、Markdown、PDF、Python源码等;(4)分布式运行,在数据挖掘教学过程中,可以利用本地资源、远程资源、共享资源同时进行代码运行和展示,进而屏蔽课堂对于各种复杂运行环境配置和安装的要求,进而实现一处安装到处轻松讲课和完美展示的效果;(5)交互式展现,不仅可以输出图片、视频、数学公式,还可以通过交互式插件呈现可互动的可视化内容,比如可缩放的地图和可旋转的三维模型,进而实现理论与实践同步,便于全过程开展沉浸式数据挖掘教学,甚至完全代替传统的PPT教学。
2 教学大纲设置
数据挖掘是计算机等专业必选课之一[3,4]。数据挖掘又称知识发现,是一个从海量数据中根据某种法则抽取的,有价值或知识的数据的过程。它包括数据清洗、数据集成、数据转换、数据挖掘、模式评估和知识表示等部分。数据挖掘涉及数据库技术、机器学习、人工神经网络、统计学、模式识别、运筹与优化、面向对象编程等多个学科中的知识。它的挖掘对象可以是图像、文本、影音、数据库、数据仓库、Web数据库等。就功能而言,数据挖掘主要是对所挖掘对象中的数据进行概念描述、关联规则的获取、分类与预测、聚类分析、孤立点的发现、模式评估等。
通过本课程的学习可使学生获得数据挖掘的基本理论、基本知识和基本技能、树立理论联系实际的工程观点,培养学生用人工智能的方法和观点分析和解决数据领域问题的能力,同时为学生后续学习深度学习、机器学习等专业课程提供必要的基础知识、理论背景和平台经验[5,6]。
基于Jupyter开展数据挖掘教学实践,有异于传统的教学方法,如:(1)可以少用或不用PPT展示;(2)算法讲解和代码演示可以同时进行,理论教学和实践教学须合二为一;(3)近年来,基于Jupyter平台的开发各种数据挖掘、机器学习算法和模型工具包层出不穷、日新月异,如XGBoost、LightGBM等模型在Kaggle等数据竞赛平台上被广泛应用,最新的数据挖掘教学内容必须予以动态体现这些最新的变化[7,8]。
在Jupyter环境,教学大纲和教学安排须进一步体现以下两点要求:(1)理论和实践无缝链接,紧密结合,同步进行,有条件布置好远程服务器教与学可同时在终端上进行,教的内容即时呈现,学的东西即时实践;(2)为了体现平台优势,需要在基础教学内容中安排若干课时,讲授Python基础、数值处理工具Numpy、数据处理工具Pandas和Scikit-learn下的基本数据挖掘工具包。进而将基于Jupyter环境下的数据挖掘教学大纲分为基础和提升两部分,其中基础教学内容主要培养学生基本的数据收集、数据分析、数据处理、数据清洗、数据可视化能力,主要的讲授内容有:数据挖掘概论、Python基础、Numpy与Pandas、爬虫技术基础、数据清洗、数据可视化。提升教学内容主要培养学生针对具体任务的数据挖掘能力,主要讲授内容有:分类、聚类、回归、关联规则、深度学习、元学习初步。一般来说,针对本科生开设的数据挖掘课程总学时控制在32~40学时之间为宜[9,10],表1给出了建议的教学大纲。

表1 教学大纲
3 课堂组织
下面以数据挖掘中常用的K近邻(KNN)模型为例,详细阐述如何利用Jupyter为载体开展数据挖掘课堂教学。
(1)基础概念
KNN模型是一种有监督的学习算法,中文名称为K最近邻算法。它属于“惰性”学习算法,即不会预先生成一个分类或预测模型,用于新样本的预测,而是将模型的构建与未知数据的预测同时进行。该算法既可以针对离散因变量做分类,又可以对连续因变量做预测,其核心思想就是比较已知y值的样本与未知y值样本的相似度,然后寻找最相似的k个样本,用作未知样本的y值预测。
首先,介绍一下KNN的算法原理和流程步骤。如图1所示,模型的本质就是寻找k个最近样本,然后基于最近样本做“预测”。对于离散型的因变量来说,从k个最近的已知类别样本中挑选出频率最高的类别用于未知样本的判断;对于连续型的因变量来说,则是将k个最近的已知样本均值用作未知样本的预测。以分类问题为例,具体算法步骤如下:
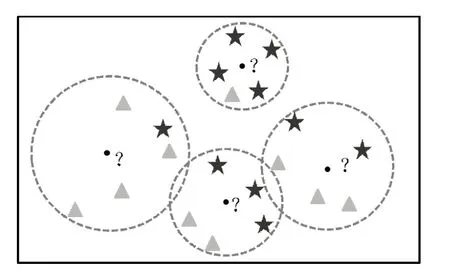
图1 KNN算法示意图
1)确定未知样本近邻的个数k值;
2)根据某种度量样本间相似度的指标(如欧氏距离)将每一个未知类别样本的最近k个已知样本搜寻出来,形成一个个簇;
3)对搜寻出来的已知样本进行投票,将各簇下类别最多的分类用作未知样本点的预测。
接下来,可以向学生具体讲授K值的选择方法,及具体度量算法(如欧式距离、曼哈顿距离、余弦相似度、卡德相似系数等),这里不再做具体展开,我们重点介绍下如何使用Jupyter进行算法的演示教学。
(2)基于Jupyter教学
这里通过针对UCI提供的学生学习过程记录数据,搭建KNN模型,预测学生的知识掌握程度(Very Low、Low、Middle和High)来演示基于Jupyter的教学过程。首先,使用markdown语言列出可能用到的基础模块包,并对每个模块包进行详细介绍,如图2所示,为后续模型代码的开发打下坚实的基础。

图2 可能用到的基础包说明和加载
接着,导入数据,并预览一下该数据集的前几行,使得学生对数据集有一个更为清晰和直观的认识,代码及运行结果如图3所示,通过这种方式可以让学生清晰地看到数据的基本结构。数据集一共包含403个观测对象和6个变量,首先前5列分别为学员在目标学科上的学习时长(STG)、重复次数(SCG)、学习时长(STR)、两个相关科目的考试成绩(LPR和PEG);最后1列是学员对知识掌握程度(UNS),一共含有四种不同的值,分别为Very Low、Low、Middle和High。
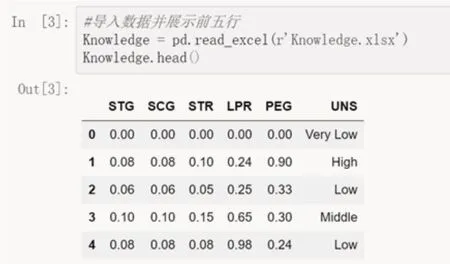
图3 数据导入和展示
继续将导入的样本按照3:1拆分成训练集和测试集,如图4所示。这里要注意讲解函数model_selection.train_test_split的几个参数的意义:第1个参数是自变量,第2个参数是因变量,test_size表示测试样本所占的百分比,最后一个参数random_state表示随机数发生器的种子。

图4 数据拆分
接着进行K值选择,具体代码如图5所示。采用10重交叉验证,测试不同的K值对应的KNN模型的平均准确率。这里要给学生讲清楚K取值上限的计算方法:用样本总量求以2为底的对数。最终通过图示法给出最佳的K值,这里取5,如图6所示。

图5 交叉验证法确定KNN模型最终的K值

图6 不同K值对应的KNN模型的效果分析
再接下来,构造混淆矩阵,并可视化,如图7所示。混淆矩阵的对角线数值是各个分类预测准确的样本量。利用混淆矩阵的可视化结果,让学生理解每个分类的召回率、准确率的概念和相互区别。

图7 构造最佳KNN模型的预测结果的混淆矩阵
最后通过Jupyter给出最终模型的准确率和模型效能的评估,并讲述每个指标的具体含义,如图8所示。
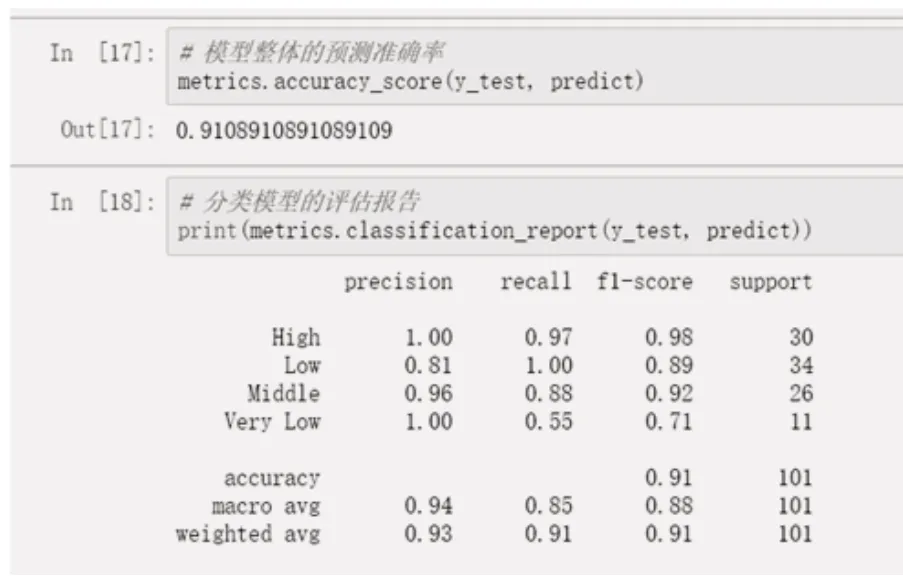
图8 模型结果分析
通过以上基于Jupyter的代码和结果讲述过程,可以让学生对KNN模型的建模、实验、结果分析有一个非常直观的认识,从而建立起EDA分析、数据建模到结论分析一整套标准建模思想。
4 考核手段
基于Jupyter,既可以开展理论与实践过程的教学,也可以开展课后作业及期末考核工作。
在课后作业的布置环节,可将作业以数据+任务的形式进行线下部署,要求学生以Juypter形式进行EDA分析、模型建模和结果展示及分析,最终以Juypter网页形式进行统一发布或截屏上传,这种方式非常有利于学生数据建模连续思维的培养,也有利于教师进行线上作业检查,全面评估学生的实操能力。
在期末考核环节,可以将典型的数据分析和建模案例以Jupyter形式发布,具体可以填空、判断、结论预测与分析等方式出题,全面考察学生数据挖掘过程中对各个具体知识节点的掌握程度。
5 结语
数据挖掘是计算机大类学科,尤其是人工智能方向必修课之一,也是学生走入机器学习的入门课,课程的内涵和实用价值都非常大。如何在实战环境下方便自如地开展理论与实践教学一直是一个痛点问题。本文首先介绍了Jupyter平台,然后针对数据挖掘课程教与学过程中普遍存在的问题,进行了系统分析和方案研究。主要从教学大纲、课堂组织、考核手段等环节进行阐述,启发教师的备课思路和方法,目的提升学生的数据挖掘课程的学习兴趣,拓展数据挖掘课程教学研究的广度和深度。
