改进Mask R-CNN算法的带钢表面缺陷检测
2021-10-14翁玉尚肖金球
翁玉尚,肖金球,夏 禹
1.苏州科技大学 电子与信息工程学院,江苏 苏州 215009
2.苏州市智能测控工程技术研究中心,江苏 苏州 215009
带钢的生产过程中由于现代生产工艺的限制,带钢表面可能会产生麻点、夹杂、划痕等缺陷。这些缺陷轻则减少带钢的使用寿命和用途,重则可能会影响建筑物的建设安全导致建筑事故。所以在带钢的生产过程中要对已生产的带钢进行缺陷检测,以确保带钢的质量。在带钢生产过程中传统的检测方法是人工检测,这也是目前许多企业所采用的方法。这种检测方法检测速度慢,准确度低,且极为容易受人为因素的干扰。
随着计算机和深度学习的发展,基于卷积神经网络和深度学习的模型,在缺陷检测中实现了高准确度和高效率的优势,逐渐成为缺陷检测的主要研究方向。目前的目标检测算法主要分为两类,一类是以R-CNN算法[1]、Fast R-CNN算法[2]、Faster R-CNN算法[3]、Mask R-CNN算法[4]为代表的两阶段算法;另一类是以Over Feat 算法[5]、YOLO 算 法[6]、YOLOv2 算 法[7]、YOLOv3 算 法[8]、SSD算法[9]为代表的一阶段算法。两阶段算法先基于区域建议框产生候选区域,然后再使用检测网络检测候选区域的类别和位置;一阶段算法利用整张图作为网络输入,直接在输出层回归边界框的位置及其类别[10]。这两类算法中前者有更高的检测精度,但检测速度较慢;后者的检测速度快,但检测精度没有前一类高。这两类算法在目前的研究中应用的都比较多。2018 年,Cha 等人[11]最早通过将Faster R-CNN 的backbone 网络替换为ZF-net网络,并将其应用到桥梁表面的缺陷检测中,检测结果的mAP值达到了0.878。马晓云等人[12]为了实现子弹外观的缺陷检测,在Faster R-CNN中使用k-means++算法生成滑动窗口anchor。裴伟等人[13]将SSD 算法的基准网络更换为表征能力更强的残差网络,并提出心的融合算法来提高航拍目标的检测率。王俊强等人[14]通过利用基于候选框方式和一体化检测方式提升了SSD算法对遥感影像小目标的检测能力。
目前,带钢表面缺陷检测普遍使用卷积神经网络提取特征并进行分类。Fu 等人[15]提出了一种端到端的卷积神经网络,实现了带钢表面缺陷的高精度分类;He等人[16]使用对抗神经网络生成大量的未标注数据后再进行缺陷分类,解决了缺陷样本不足难以训练的问题。但以上检测模型只解决了带钢表面缺陷分类问题,并没有解决难度更大的缺陷定位问题。He等人[17]等提出的基于Faster R-CNN 的带钢表面缺陷检测网络,该网络改进在于将backbone 中多级特征图组合为一个多尺度特征图,在缺陷检测数据集NEU-DET上,提出的方法在采用ResNet50的backbone下实现了82.3%的mAP。
为了提高带钢表面缺陷检测的准确率,在实验中将Mask R-CNN 算法应用到带钢表面缺陷检测。在RCNN算法提出以后,人们不断对其进行改进创新,先后提出了Fast R-CNN、Faster R-CNN 和Mask R-CNN 算法。Mask R-CNN 算法大体框架与Faster R-CNN 算法类似,Mask R-CNN 算法利用ResNet-101 和FPN(特征金字塔网络)作为特征提取网络,可以提高对小目表检测时的精度,同时也解决了多尺度检测的问题。在基础特征网络之后又加入了全连接的分割子网,添加了一个预测分割掩码分支,可以同时处理分类、边界框回归和掩码层3 个任务,在提高检测精度和速度的基础上,还完成了缺陷的分割。为了使Mask R-CNN 算法更适用于带钢表面缺陷检测,对算法结构进行了改进。采用聚类的算法来确定anchor 方案,提高区域建议质量,并去掉掩膜分支以提高检测速度。使用NEU-DET数据集的图片来训练模型,进行缺陷检测实验,验证该方案的可行性和有效性。
1 Mask R-CNN算法
1.1 Mask R-CNN算法结构
Mask R-CNN算法的框架非常灵活,可以通过添加不同的分支来完成不同的任务,比如目标分类、目标检测、语义分割、实例分割等多种任务。
Mask R-CNN 算法的网络结构如图1 所示。Mask R-CNN 是一个两阶段算法:第一阶段是对图像进行扫描然后生成提议(proposals,即可能包含一个目标的区域);第二阶段在预测种类和边界框回归的同时还预测了对应的掩码。Mask R-CNN的总体流程如下:先将整张图片输入CNN,使用ResNet-101网络进行特征提取,获得对应的特征图,接着对特征图中的每一点设定预定个RoI,从而获得多个候选RoI;然后将候选的RoI 送入到RPN 进行二值分类和边界框回归,过滤掉一部分候选的RoI;对剩下的RoI 进行RoI Align 池化操作(即将原图和特征图的像素对应起来);最后,对这些RoI进行分类、边界框回归和掩码生成。

图1 Mask R-CNN算法网络结构Fig.1 Mask R-CNN algorithm network structure
1.2 RPN
输入到RPN网络的特征图经过RPN网络得到区域建议和区域得分[18]。可以利用卷积层,在最后一个共享的卷积层生成的卷积特征图上用一个小窗口进行滑动,从而生成区域建议框。RPN的网络结构如图2所示。
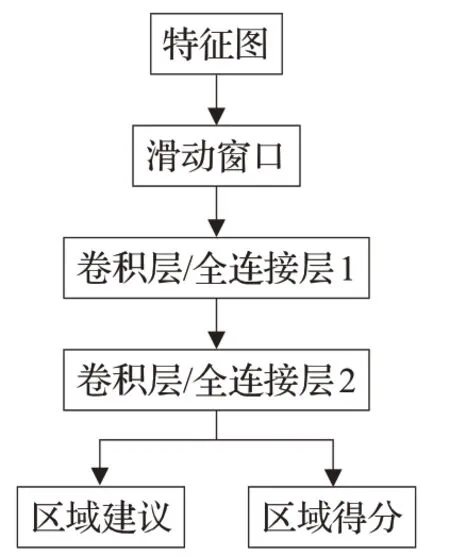
图2 RPN网络结构Fig.2 RPN network structure
该网络将卷积层生成的卷积特征图的d个n×n空间窗口作为输入,映射到一个d维向量上。这个d维向量同时输出给两个同级的全连接层:框回归层和框分类层。在每个滑动窗口的位置,同时预测k个区域建议框,所以回归层有4k个输出,用于编码k个区域建议框的坐标,分类层输出2k个得分,用于估算每个区域建议框是目标的概率。
RPN的总体损失函数为:
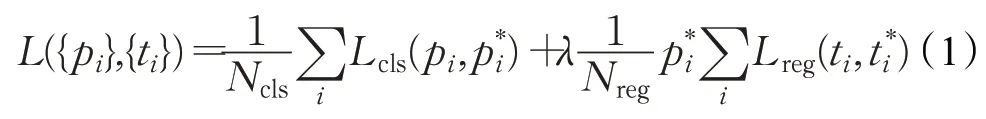
式中,Lcls为分类损失;Lreg为回归损失;λ为权重平衡参数;i表示一个mini-batch 中anchor 的索引;pi为anchor 中含有目标的概率。当目标在anchor 中时,pi=1,否则pi=0。为对应的真实背景的预测概率;ti为预测的边界框的4个参数化坐标;为包含目标的anchor对应的真实边界框的坐标。其中分类损失为:

其中,R为鲁棒函数smooth(L1)。式(1)中的reg表示只有包含目标的anchor 才有回归损失。{pi} 为分类层损失,{ti} 为回归层损失。利用Ncls和Nreg以及平衡权重λ进行归一化操作。
边界框的回归运算算法为:
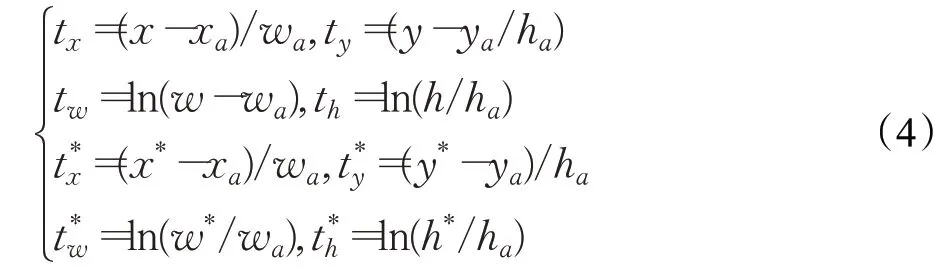
式中,x、y是预测的边界框的中心坐标,w是边界框的宽,h是边界框的高;xa、ya是anchor 的中心坐标;wa、ha为anchor 的宽和高;x*、y*为真实边界框的中心坐标;w*、h*为真实边界框的宽和高。
1.3 RoI Align
RoI Align作用是根据预测边界框的位置坐标在特征图中将相应的区域池化为固定尺寸的特征图,以便后续的分类,边框和掩码的回归操作。在常见的两阶段检测框架(比如:Fast R-CNN、Faster R-CNN)中使用的是RoI Pooling进行池化操作[3],但由于预选框的位置通常是由模型回归得到,一般是浮点数,而池化后的特征图要求尺寸固定。所以RoI Pooling操作存在两次量化过程:一是将候选框边界量化为整数点坐标值。从RoI proposal 到特征图(feature map)的映射时去[x/16],这里x是原始RoI的坐标值,方框代表四舍五入。二是将量化后的边界区域平均分割成k×k个单元,对每个单元进行量化。然而经过两次量化处理,此时的候选框和最开始回归出来的位置有一定偏差,这个偏差会影响检测或者分割的准确度。
Mask R-CNN 为了将整个特征聚集的过程转化为一个连续操作,采用RoI Align进行池化,使用双线性内插法取消了量化操作,从而获得坐标为浮点数的像素点上图像数值。
RoI Align 的结构如图3 所示。为了得到固定大小(7×7)的feature map,RoI Align没有采用量化操作。比如665/32=20.78,就直接采用20.78;20.78/7=2.97,就直接采用2.97。使用“双线性插值”算法处理这些浮数,双线性插值算法直接利用原图中虚拟点(比如20.56 这个浮点数,像素位置都是整数值,没有浮点值)四周的4个真实存在的像素值来共同决定目标图中的一个像素值,即可将20.56 这个虚拟的位置对应的像素值估计出来。如图4 所示,黑色的虚线框表示卷积后获得的feature map,黑色实线表示RoI feature,最后需要输出的大小是2×2,那么就利用双线性插值来估计这些黑点(虚拟坐标点,又称为双线性插值的网格点)处所对应的像素值,最后得到相应的输出。这些黑点是2×2 区域中的随机采样的普通点,这些采样点的个数和位置不会对性能产生很大的影响,也可以用其他的方法获得。然后在RoI池化层和全连接层里面进行最大池化或者平均池化操作,获得最终2×2 的输出结果。整个过程中没有用到量化操作,没有引入误差,即原图中的像素和特征图中的像素是完全对齐的,没有偏差。这样做不仅会提高检测的精度,同时也有利于实例分割。

图3 RoI Align结构Fig.3 RoI Align structure

图4 双线性插值Fig 4 Bilinear interpolation
由于增加了掩码分支,每个RoI的损失函数为

式中,Lcls为分类损失;Lbox为检测损失;Lmask为新增的分割损失。Lcls如式(2)所示;Lbox、Lmask分别为:
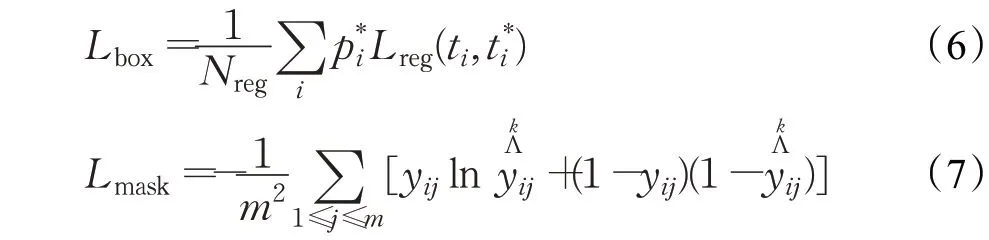
Lmask为Mask R-CNN 新增的掩膜层的分割损失。式(7)中yij为坐标点(i,j)的标签值,为该点第k类的预测值。
对于每一个RoI,mask 分支有k×m×m维度的输出,其对k个大小为m×m的mask 进行编码,每一个mask 有k个类别。将Lmask定义为平均值交叉熵损失。对应一个属于真实背景中的第k类的RoI,Lmask仅仅在第k个mask上面有定义(其他的k-1 个mask输出对整个损失没有贡献)。Lmask允许网络为每一类生成一个mask,而不用和其他类竞争;采用分类分支所预测的类别标签来选择输出的mask.这样将分类和mask 生成分解开来,不同的mask之间不存在竞争关系,可以提高实例分割的效果。
1.4 掩码分支
Mask R-CNN 为了使预测的掩码更加准确,在RoI Align 之后增加“head”部分,从而将RoI Align 的输出维度扩大,达到预测的掩码输出更加准确的目的,如图1所示。在掩码分支(mask branch)的训练环节输出了k个掩码预测图(为每一个类都输出一张),并采用平均二进制交叉熵损失(average binary cross-entropy loss)训练。在训练掩码分支时,在输出的k个特征图中,对掩码损失有影响的特征图是对应真实背景类别的那一个特征图。
2 Mask R-CNN算法改进
2.1 生成anchor框方案的改进
原始的Mask R-CNN 算法中anchor 是一组由RPN生成的矩形框,采用3 种尺度和3 种长宽比(1∶1,1∶2,2∶1),在每个滑动窗口的中心生成k=9 个anchor,如图5 所示。原始的Mask R-CNN 算法的anchor 生成方案是对COCO数据集根据经验设定的尺寸,对于本文中需要检测的5 种带钢表面缺陷原始的anchor 无法与所检测缺陷的尺寸相对应,使得RPN 中在生成区域建议时需要进行大量的回归操作,影响了算法的检测效率。因此,在RPN 中应该使anchor 方案与所检测缺陷的尺寸相对应,使得RPN在进行边界框回归时,可以减少回归工作,提升计算效率和减少网络训练时间,以便于得到更好的区域建议提高检测精度。
图5 锚框示意图Fig.5 Diagram of anchor
所以为了解决Mask R-CNN算法中anchor方案对本文的检测对象的缺陷尺寸不对应问题并且进一步提高检测的效率和准确率,针对5种不同类型的带钢表面缺陷,本文提出采用k-meansⅡ聚类算法[19]生成anchor方案。使用k-meansⅡ聚类方法通过对数据集中标注框的宽和高进行聚类得到的聚类中心设为初始的anchor方案,这样生成的anchor对需要检测的5种缺陷更具有代表性。
k-meansⅡ算法克服了初始聚类中心随机性以及遍历整个数据集的复杂性问题,在选定初始的聚类中心过程中,其在遍历数据集时每次选取多个样本。该算法把输入的包含N个点的数据集分类为k个聚类,使数据集中所有点都划分到距离其最近的聚类中心所在的类中,并使用欧氏距离作为分类时衡量距离的标准。kmeansⅡ算法的具体步骤如下:
(1)输入包含k个点的数据集。
(2)随机在数据集中去k个点作为聚类中心点,然后重复此取样过程5次得到5k个数据点。再对这些数据点进行聚类,得到k个初始的聚类中心。
(3)将数据集中各个点按欧氏距离划分到离它最近的聚类中心所在的类中。欧氏距离公式为:
这不仅透露其三十年代香港人的身份,同时在与现代香港人的对话中产生不一样的化学反应。此外,李碧华在文本书写上也带有明显的传统色彩:

(4)重新计算各个类的聚类中心,计算方法为:

式中 |ci|为该类样本的数量。
(5)设置一个阈值,假设由式(8)得到的新中心与原来的中心距离小于该阈值,则聚类结束,否则转步骤(3)。
(6)输出k个聚类和k个聚类中心。
2.2 掩码分支的改进
对于带钢表面缺陷检测任务,在生产线上进行检测时需要快速准确的完成,而不需要对缺陷进行像素级的分割。所以可以在缺陷检测中去掉掩码分支,从而使网络算法集中于特征图上进行缺陷的定位和分类任务,节约神经网络的训练和检测时间。由1.3 小节可知,掩码分支和分类预测分支之间是分开预测的,不会相互影响,去掉掩码分支后的网络输出如图6所示。
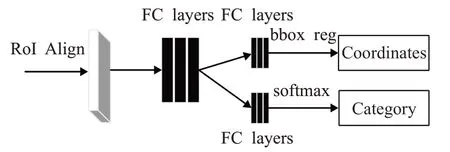
图6 去掉掩码分支后的网络输出Fig.6 Network output with the mask branch removed
3 实验及结果分析
为了验证本文提出的改进的Mask R-CNN 算法在带钢表面缺陷检测中的有效性,本章将进行系统的实验对比。实验环境为Windows 10 操作系统,AMD RYZEN 7-4800H 处理器,Nvidia Geforce RTX 2060显卡。
3.1 实验数据集
本文主要采用东北大学发布的NEU-DET数据集进行实验,数据集收集了6类带钢表面缺陷图片各300张,但其中裂纹类的缺陷图片并不明显,缺陷模糊不利于实验,所以删去裂纹类缺陷。最终,本文进行实验的缺陷图片有夹杂(Inclusion)、斑块(Patches)、麻点(Pitted Surface)、压入氧化皮(Rolled-in Scale)和划痕(Scratches)。这样数据集总共有1 500张图片。为进一步丰富训练样本数据,提高所得到模型的鲁棒性,对原数据集的图片进行扩充操作。先对图片进行旋转放大处理后,再进行直方图等处理,最终得到2 000 张图片,每种缺陷各400张。随机抽取分配训练集和测试集,其中训练集图片为1 500张,测试集图片为500张。数据集缺陷图片样例如图7所示。

图7 数据集图片示例Fig.7 Graphic example of data set
3.2 生成anchor实验
通过使用k-meansⅡ聚类算法来生成anchor 框,代替Mask R-CNN中anchor生成方式,使得anchor对带钢表面斑块、压入氧化皮、夹杂、麻点和划痕5种表面缺陷更具有代表性,提高了检测精度。
在原Mask R-CNN 算法中anchor 框数目为9,所以在进行聚类时令聚。类中心k=9,从而得到9个聚类中心,使聚类中心和anchor 框数目相等,并将这9 个聚类中心作为9 个anchor 初始的宽和高,使得只用改变anchor 的初始的宽高不改变数目,不用改变RPN 中对anchor的回归运算。对于斑块、压入氧化皮、夹杂、麻点和划痕5 种带钢表面缺陷,聚类结果如图8 所示。在进行聚类操作时,5种缺陷总耗时63 s。
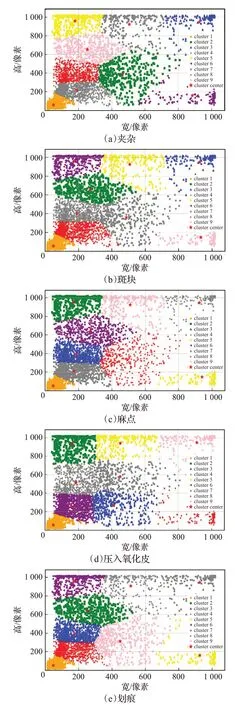
图8 5种缺陷的聚类结果Fig.8 Clustering results of five defects
3.3 实验结果
在实验中采用mAP值作为评价指标。mAP是所有类别的平均精度的均值,其计算公式为:

其中,Nc为类别检测数,AP能够综合考虑准确率和召回率2个方面的影响。以准确率为纵轴,召回率为横轴可以得到PR曲线,对于连续PR曲线,式(10)中的AP为:

式中,TP为正确分类的正样本,FP为错误分类的正样本,FN为错误分类的负样本。
在训练模型时,首先将NEU-DET 数据集转化为COCO 数据集格式。训练时首先采用迁移学习的方法加载官方的“mask_rcnn_coo”预权重文件来训练NEUDET 数据集,从而生成自己模型的权重文件。训练“head层”和“所有层”设置epochs为10,steps_per_epoch为1 000,batch_size为1。设置“head”层学习率为0.001,“所有层”学习率为0.000 1,权重衰减系数为0.000 1,共迭代20 000次
将采用聚类算法的anchor生成方案与Mask R-CNN的原始生成方案在带钢表面的5 种缺陷中进行对比实验。并在实验中加入Faster R-CNN 和YOLO v3 算法作为对比。实验结果如表1所示。
通过表1 对比发现,k-meansⅡ算法生成anchor 的方案相对于原Mask R-CNN的anchor生成方案mAP值提升了14.94 个百分点,检测速度达到4.5 frame/s,在提升检测精度的同时也提升了检测速度。

表1 两种anchor生成方案检测结果Table 1 Detection results of two anchor generation schemes
为了测试将掩码分支去掉后Mask R-CNN 算法的性能,将其与原Mask R-CNN 算法进行对比实验,在实验中只改变掩膜分支的有无,不改变其他网络结构。实验结果如表2所示。
由表2 可知,将掩码分支去掉后,Mask R-CNN 算法的检测精度并未下降,但检测速度提升了1.3 frame/s。

表2 两种网络结构实验结果Table 2 Experimental results of two network structures
在进行了一系列的控制变量实验,验证了聚类算法生成anchor方案和去掉掩膜分支均可提升Mask R-CNN的检测速度。因此,将两种改进方案同时运用到Mask R-CNN 中,将改进的Mask R-CNN 与原Mask R-CNN算法进行对比实验,观察改进的Mask R-CNN的检测精度和效率。在实验时,加入Faster R-CNN、DDN[17]、SSD和YOLO V3算法进行对比,实验结果如表3所示。表3中算法1 为原Faster R-CNN;算法2 为用k-means 聚类算法生成anchor 的Faster R-CNN;算法3 为原MaskR-CNN 算法;算法4 为改进的Mask R-CNN 算法;算法5为使用ResNet网络的DDN算法;算法6为YOLOv3算法;算法7为SSD算法。
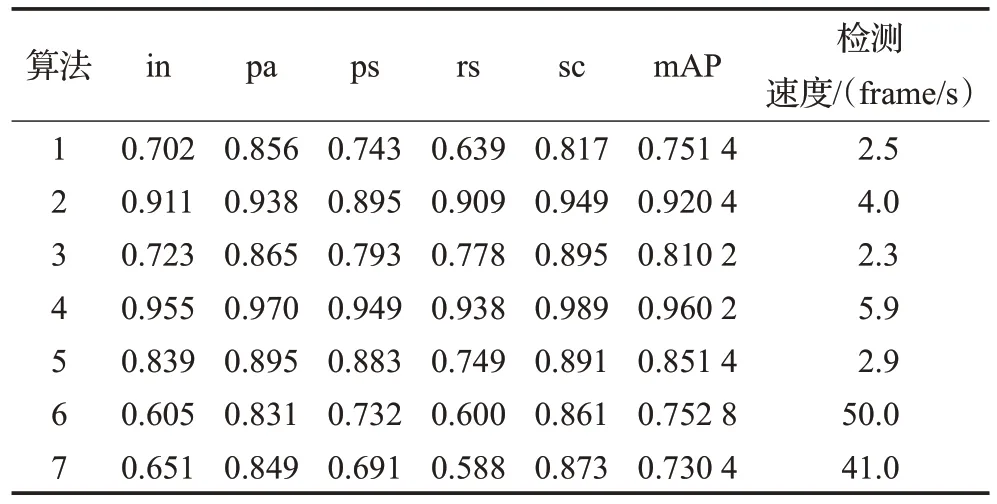
表3 不同算法的检测结果Table 4 Detection results of different algorithms
表3的综合对比发现,使用改进的Mask R-CNN算法进行带钢表面缺陷检测时,其检测精度和速度相对比于其他几种算法均实现了最优。图9 为改进的Mask R-CNN 的检测结果。图10 为YOLOv3 算法的检测结果。通过图9和图10的对比可以发现,YOLOv3作为一阶段算法,其检测速度快,但其对于尺寸较小的缺陷的检测效果较差。

图9 改进的Mask R-CNN的检测结果Fig.9 Detection results of improved Mask R-CNN

图10 YOLOv3算法检测结果Fig.10 Detection results of YOLOv3
4 结语
针对带钢表面缺陷,本文提出了基于k-meansⅡ聚类算法和改进“head”部分神经元的改进的Mask R-CNN算法来进行带钢表面的5 种缺陷检测,提升了Mask R-CNN算法的检测精度和效率。在实验中将原算法的mAP值从0.810 2提升到了0.960 2,检测速度从2.3 frame/s提升到5.9 frame/s。实验结果表明改进的Mask R-CNN算法可以提升在带钢生产中的检测效率,提升了生产检测工艺。虽然本文改进的Mask R-CNN 算法能够满足带钢表面缺陷检测,但在未来的研究中可以进一步的提升检测效率。下一步的研究内容主要有:当前训练阶段的数据集仍存在图片少,不清晰的问题,可以通过扩大丰富带钢表面缺陷数据集来解决此问题,提升算法检测的精确度;改进后的Mask R-CNN算法虽然检测速度有了很大提升,但仍为两阶段算法,后面的工作中可以改进其网络结构来进一步提升检测速度。
