通道-空间联合注意力机制的显著性检测模型
2021-10-14陈维婧杨海燕
陈维婧,周 萍,杨海燕,杨 青,陈 睿
1.桂林电子科技大学 电子工程与自动化学院,广西 桂林 541000
2.桂林电子科技大学 信息与通信学院,广西 桂林 541000
随着科学技术的快速发展,图片和视频的数量呈爆发式增长,如何从海量的图片中提取人们感兴趣的特征区域值得研究。显著性检测是通过计算机模拟人眼视觉注意机制,剔除图像中的冗余信息,提取出吸引人眼注意力的区域[1]。显著性检测作为图像处理的一种预处理技术,广泛应用于目标跟踪[2]、图像分割[3]、人员重新识别[4]和图像编码[5]等计算机视觉领域。
传统的显著性检测方法是采用手工设计特征,借鉴大量的先验知识(如:对比先验、背景先验、颜色先验等)来进行显著性判断的。最早是文献[6]提出的Itti 模型,该模型是在生物视觉的基础上,利用高斯金字塔计算图像的亮度特征图、颜色特征图和方向特征图得到初始显著图,再通过显著性融合得到最终的显著图。文献[7]提出了一种基于全局对比度的显著性区域算法(Histogram based Contrast,HC),该算法根据像素与像素之间的色彩差异计算显著性值,并产生具有全分辨率的显著性图。HC 算法虽然可以均匀地突出显著性区域,但是对背景较复杂的图像检测效果不理想。
近几年来,基于深度学习的图像显著性检测也得到广泛的应用,促进了显著性检测技术的发展。文献[8]提出了一种双向信息传递模型用于显著性检测,该模型采用空洞卷积改进多级特征图,并通过门控双向路径实现层与层之间的信息交换,但是由于双向传递带来了冗余信息,最终的显著图仍存在边缘信息丢失的问题。文献[9]提出了一种反向注意力机制的显著物体检测模型,该模型是在主干网络的侧输出层进行残差学习,并在残差学习模块前引入反向注意力机制拓展目标区域。文献[10]提出了一种注意力反馈网络用于图像显著性检测,该网络通过设计注意力反馈模块逐级预测显著性对象并通过边界增强损失函数来细化边界。但是,上述网络结构并没有很好的解决预测图不完整的问题。因此,针对显著性图不完整和目标内部信息缺失等显著性算法问题,本文提出了一种通道-空间联合注意力机制的显著性检测模型。为了扩大感受野且不增大计算量,设计了一种能够充分提取特征图的空间信息多空洞卷积模块,该模块可生成多尺度特征提取的特征图(Multi-Scale Feature Extraction,MSFE)。为了提高特征图层与层之间信息的关联度,受文献[11]的启发,改进了一种通道注意力机制通过将特征图的像素概率值进行加权来优化最终的预测概率。但是,由于只关注层间的联系,忽略了对特征图的空间结构的利用。因此,受文献[12]和[13]的启发,设计了一种并行空间注意力机制,通过与通道间的信息加权来增强特征块层间信息的相关性。正如大家所知,不同卷积层之间所含有的信息是多样的,即深层次的特征可以对显著目标进行定位,浅层次的特征包含丰富的空间细节信息。为了优化不同卷积层的特征图,本文以反馈传递的方式将通道-空间联合注意力机制输出的特征图从深层呈递进式传递到浅层。
1 通道-空间联合注意力机制的显著性检测模型
1.1 模型结构
本文所提出的显著性检测模型是基于VGG-16 框架,并为了契合图像的空间特征,移除VGG-16 最后的全连接层,得到一个全卷积网络。同时,本文还使用了侧输出结构,将主干网络中5个层的特征图并行送至空洞卷积中生成MSFE模块,以此通过扩大感受野来获得更多的空间信息。然后,经过感受野为3×3的归一化卷积操作(如图1虚线框所示),对侧输出特征图进行归一化。再从通道和空间位置两个方面考虑,将特征图A输入到对应的通道-空间联合注意力机制模块(Channel-wise-Spatial Module,CSM)中,获取被加权优化的特征图。最后,根据卷积层之间信息的性质不同和语义细节信息的互补知识,将5个通道-空间联合注意力机制获得的特征图以单向反馈传递方式传递到浅层中从而优化浅层信息,即后一个通道-空间注意力机制模块连接卷积块处理得到的特征图Si(i=1,2,…,5)与前一个层的归一化卷积输出的特征图A 进行拼接作为前一个模块的输入。依此类推,获得最终的显著性图S。如图1所示为总体框架图。
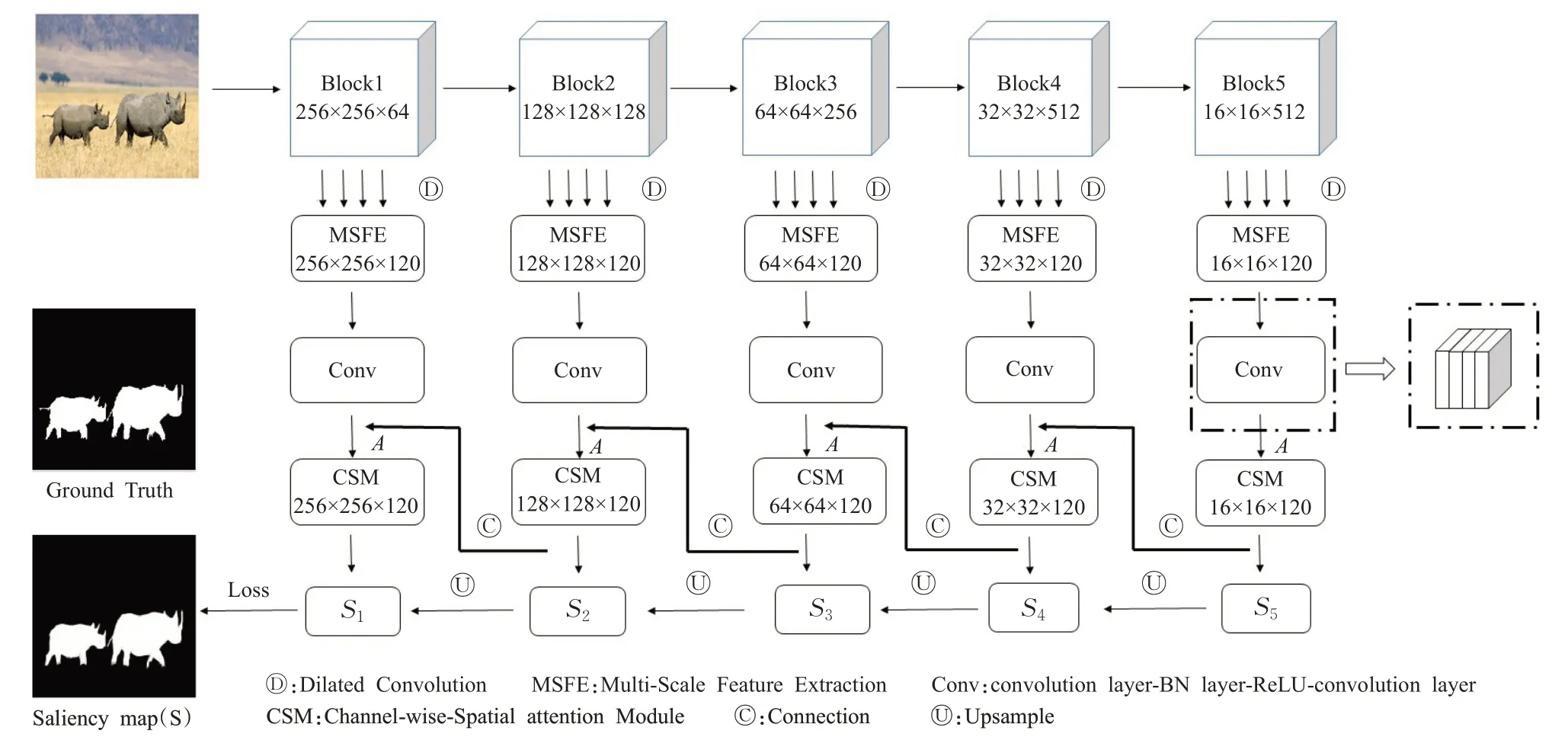
图1 模型总体框架图Fig.1 Overall framework of model
1.2 多尺度融合
空洞卷积(Dilated Convolution)是一种改进的图像卷积方法,通过膨胀标准卷积核,在不增加参数的情况下扩大感受野来获取不同感受野的目标特征信息。在提出的模型中,对VGG-16模型的侧输出特征图中的显著性信息采用k(k=4)个膨胀率分别为d∈{1,2,4,5}的空洞卷积的并联进行上下文特征提取特征图D。由公式(1)可计算得到MSFE模块。

式中,conv(Di)为空洞卷积操作。
1.3 通道-空间联合注意力机制模块
为了对特征图进行归一化,在MSFE 模块后加上“3×3 的卷积层-BN 层-ReLU 层-3×3 的卷积层”(如图1中虚线框所示)的卷积结构得到特征图A(如图1 所示),并将后一个特征图A经过通道-空间联合注意力机制模块得到的特征图Si与上一个卷积块得到的A进行连接,作为上一个CSM模块的输入。重复上面的操作,形成一种单向反馈传递方式,并将Si通过上采样从而得到最终的特征图S。如图2所示为通道-空间联合注意力机制模块,用于获取细粒度更高的预测特征图Si。

图2 CSM模块Fig.2 CSM module
由于原始的CBAM 模块中的通道注意力机制采用了最大池化层和平均池化层来进行特征压缩,这一过程导致模块的参数损失过大无法完成精准的预测。因此,本文仅使用平均池化层对特征进行压缩,再使用Sigmoid激活函数和1×1的卷积对B1进行非线性映射,得到主要特征B∈RC×1×1,该值介于[0,1]之间。计算公式如下:
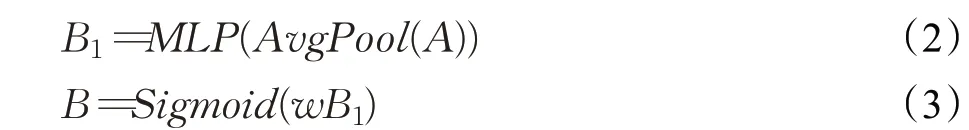
式中,A∈RC×H×W为经过卷积处理得到的特征图,C、H和W分别为A的通道数、高度和宽度。B∈RC×1×1为将A通过平均池化层进行特征压缩以及多层感知机(Multi-Layer Perceptron,MLP)得到的特征图,w表示1×1的卷积的权重。
将B与原始的输入特征图A在每一个通道相乘,得到显著目标突出的通道注意力图Mc(A)∈RC×H×W。计算公式如下:

考虑到像素与显著区域的相关性,提出了一种并行式空间注意力机制,来获得像素位置相关性较高的显著目标特征信息。首先对A∈RC×H×W进行卷积操作,得到3 个全新的并行式的特征图C1∈RC/6×H×W、D1∈RC/6×H×W和E1∈RC/6×H×W,值得注意的是,这里的C1、D1和E1把通道数C缩小至C/6,以减少参数和尺寸;然后对特征图的尺寸进行reshape,得到C∈RH×W×C/6、D∈RH×W×C/6和E∈RH×W×C/6;再将C、D和E进行softmax归一化操作;最后,将对应的矩阵进行相乘得到最终的空间注意力机制图:Ms(A)∈RC×H×W。计算公式如下:

式中,i,j∈{1,2,…,N},ECD为C和D进行归一化操作,EDE为D和E进行归一化操作。
通过上述操作,将通道注意力机制得到的特征图和空间注意力机制得到的特征图进行加权融合得到预测特征图Si∈RC×H×W,计算公式如下:

式中,α为权重系数。
为了计算损失,预测特征图Si的尺寸与真值图的尺寸相同,即通过上采样,将预测图放大至原始尺寸。再使用二分类交叉熵损失函数(binary cross-entropy loss function)来充分表达图像内容的对象性以及轮廓特征,获取最终的显著性图。损失函数计算公式如下:

式中,lx,y∈(0,1)为标签像素(x,y)的归一化,Px,y为像素(x,y)属于显著图的概率。
2 实验结果与分析
2.1 数据集及评价指标
本文实验在Windows10操作系统下进行,计算机硬件配置为NVIDIA 1080ti GPU,所提模型采用Pytorch1.0深度框架搭建。为了验证模型的有效性,将本文模型在DUTS-TE[14]、ECSSD[15]、HKU-IS[16]、PASCAL-S[17]和SOD[18]这5个公开的数据集上进行测试。DUTS数据集由DUTS-TR和DUTS-TE组成,其中,DUTS-TR有10 553张训练图片,DUTS-TE 有5 019 张测试图片;ECSSD 数据集包含1 000张内容丰富且大小不同的图像;HKU-IS有4 500 张至少两个显著性目标的图像,并且目标与背景信息比较复杂;PASCAL-S 数据集包含850 张背景复杂的图像;SOD数据集有300张图是从伯克利分割数据集中挑选出来的。以上数据集都提供人工标注的二值图像,能够更好地评估模型的性能。
实验采用的评估指标如下:自适应阈值F-measure值[1]和平均绝对误差值[1(]Mean Absolute Error,MAE)。为了综合衡量查全率和查准率,使用F-measure 值作为整体性能的评价标准,F-measure 值越大训练效果越好。计算公式如下:
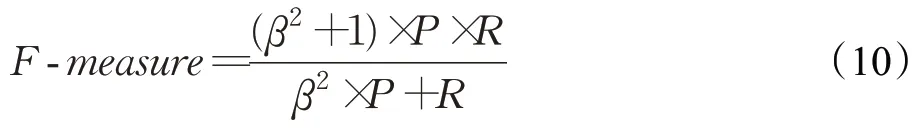
式中,P为平均准确率,R为平均召回率,β多次实验得到的结果,通常设为β2=0.3。
MAE是通过对比显著图与真实图之间的平均对比误差,MAE的值越小说明算法的性能越好[1]。计算公式如下:

式中,yi为最终的特征图,为真值图。
2.2 定量比较
为了验证模型的有效性,将本文模型与AFNet[10]、BASNet[19]、BDMP[8]、ASNet[20]、C2SNet[21]、SRM[22]、FSN[23]和UCF[24]这8种显著性检测模型进行多方面的对比。
如表1为本文模型与8种显著性检测模型在不同的数据集的定量比较。
实验结果如表1 所示,将本文模型在DUTS-TE、ECSSD、HKU-IS、PASCAL-S和SOD数据集上分别使用F-measure 和MAE 作为评价指标进行评估。本文模型在DUTS-TE 数据集上F-measure 和MAE 分别为0.840和0.045,相比于基于注意力机制反馈网络的AFNet 在F-measure 提高了0.002,MAE 下降了0.001;在ECSSD数据集上F-measure和MAE分别为0.931和0.035,与关注边界的BASNet 相比F-measure 没有改变,MAE 下降了0.002;在HKU-IS 数据集上F-measure 和MAE 分别为0.911 和0.034,与基于双向信息传递的BDMP 相比F-measure提高了0.001,MAE下降了0.005;在PASCALS 数据集上F-measure 和MAE 分别为0.830 和0.119,相比于BDMP 模型F-measure 提高了0.003,MAE 下降了0.003;在SOD数据集上F-measure和MAE分别为0.811和0.103,与BASNet 相比F-measure 提高了0.006,MAE下降了0.009,证明了本文方法的有效性。

表1 多种显著性检测在不同数据集上的F-measure和MAETable 1 F-measure and MAE of multiple salient object detection on different datasets
为了验证MSFE 模块和CSM 模块对模型的整合性,本文在SOD数据集上对模型中各个组成部分的表现力进行测试。表2为在SOD数据集上不同设置的影响。
如表2所示,在SOD数据集上对VGG-16、VGG-16+MSFE、VGG-16+MSFE+CA、VGG-16+MSFE+SA 和本文模型进行实验测试。实验结果表明,在主干网络中添加MSFE 模块,F-measure 提高了0.4%,MAE 降低了0.7%;再在此基础上增加CSM 模块,相比于其他方法,F-measure提高了0.4%,MAE降低了0.2%。
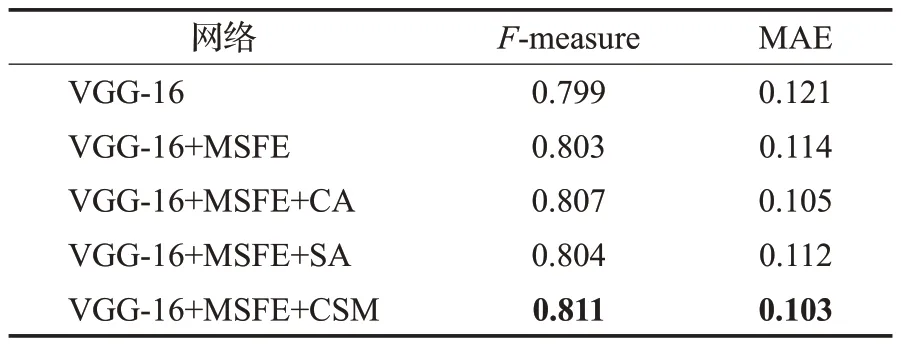
表2 在SOD上不同设置的定量评估Table 2 Quantitative evaluation of different settings on SOD
为了进一步验证MSFE模块的有效性,本文在SOD数据集上;分别对空洞卷积选取的个数k和不同膨胀率的选取对整个模块的F-measure 和MAE 值的影响进行实验研究。表3 为SOD 数据集上空洞卷积个数对检测结果的影响;表4为SOD数据集上不同膨胀率对检测结果的影响。
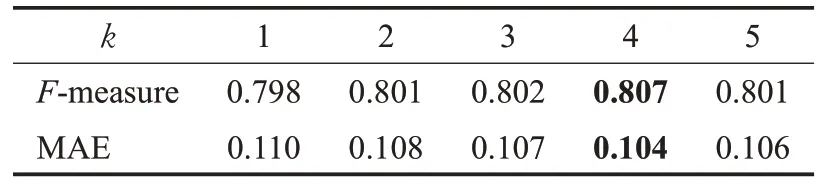
表3 在SOD上空洞卷积个数的定量评估Table 3 Quantitative evaluation of the number of convolutions on SOD
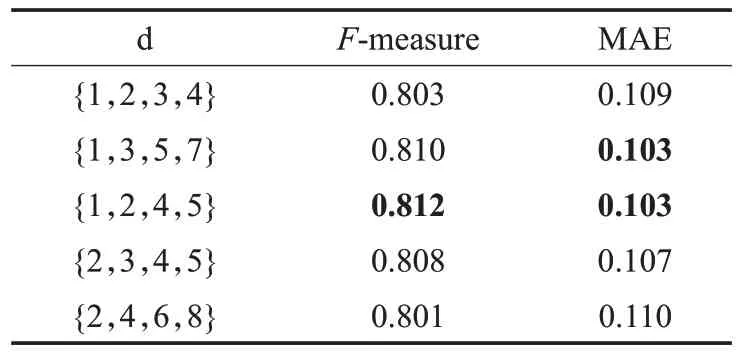
表4 在SOD上不同膨胀率的定量评估Table 4 Quantitative evaluation of different dilation rates on SOD
如表3 所示,在SOD 数据集上测试了k=1,2,3,4,5 这5组数值。实验结果表明,当k=4 时,F-measure和MAE 分别为0.807 和0.104,与其他几组数值相比达到最优值。因此,本文选取空洞卷积的个数为4个。
本文设置了5 组膨胀率不同的数值,分别为d∈{1,2,3,4},d∈{1,3,5,7},d∈{1,2,4,5},d∈{2,3,4,5}和d∈{2,4,6,8},实验结果如表4所示。实验结果表明,当膨胀率分别为d∈{1,2,4,5} 时,相比于d∈{1,3,5,7} 提高了0.2%。因此,本文选取的膨胀率为d∈{1,2,4,5}。
2.3 视觉显著图评价
将本文模型与其他8种模型进行图像视觉比较,结果如图3所示,从左到右依次为:原始图像(Input)、人工标注图(GT)、本文模型(Ours)和对比模型AFNet、BASNet、BDMP、ASNet、C2SNet、SRM、FSN和UCF。
从图3中可以看出,对于背景较复杂的图像(如图3中的第1、2 行),FSN 和UCF 可以比较完整地检测到显著区域,但是对背景噪声的抑制能力比较差;对于背景与目标类似的图像(如图3 中的第3、4 行),C2SNet 和SRM能够检测到显著区域,但是显著目标边界不明确;对于显著目标尺度较小的图像(如图3中的第5行),AFNet和C2SNet虽然可以检测出显著目标,但是轮廓不清晰;对于显著目标尺度较大的图像(如图3中的第6行),BASNet 和ASNet 不能完全检测出显著目标,只能突出部分显著目标,而AFNet和BDMP虽然能够准确定位到显著目标,但是本文模型的显著目标内部更加光滑完整。综上所述,本文模型在复杂环境下检测得到的显著目标不仅内部均匀而且轮廓信息完整优于其他的模型。

图3 本文算法与其他算法的视觉对比图Fig.3 Visual comparison of proposed algorithm and other algorithms
3 结论
本文针对当前的显著性检测算法性能差和显著图细节信息不明显等问题,提出了一种通道-空间联合注意力机制的显著性检测模型。同时设计了一种并行式的空间注意力机制增加特征块层与层之间的信息相关性,使最终得到的加权融合特征图能够准确描述空间中像素点的权重和特征层之间的关系。在DUTS-TE 和SOD数据集上的实验结果表明,与其他同类模型相比,本文模型可检测出更清晰的显著区域并获得更准确的显著图。在未来的工作中,将本文方法拓展到其他计算机视觉领域,促进显著性检测在计算机视觉上的应用。
