结合改进VGGNet和Focal Loss的人脸表情识别
2021-10-14崔子越皮家甜杨杰之吴至友赵立军曾绍华
崔子越,皮家甜,陈 勇,杨杰之,鲜 焱,吴至友,赵立军,曾绍华,吕 佳
1.重庆师范大学 计算机与信息科学学院,重庆 401331
2.重庆市数字农业服务工程技术研究中心(重庆师范大学),重庆 401331
3.智慧金融与大数据分析重庆市重点实验室(重庆师范大学),重庆 401331
4.重庆师范大学 数学科学学院,重庆 401331
随着计算机图像处理技术日益的完善,人脸表情识别逐渐成为计算机图像处理中重要的一部分,在人机交互、安全以及机器人制造等领域具有广泛且必要的用途。通过面部表情的变化来获取对象情感变化,是面部表情的主要交流方式。在实际采集表情数据集时,通常会由于光照变化、头部姿势、表情强度以及呈现方式等因素,造成表情样本类内表情差异大、类间表情差异小的问题,降低模型准确性。因此,人脸表情识别依然面临着巨大的挑战。
表情识别的研究可以主要分为基于传统特征提取的方法和基于深度学习的方法。传统特征提取主要依赖人工设计的提取器,需要大量的专业知识,同时泛化性和鲁棒性较深度学习方法略有不足。Gupta等人[1]使用SVM 的方法在CK+数据集上取得了93.7%的准确性,相比深度学习方法准确性较差。深度学习方法对特征的提取是通过反向传播和误差优化算法对权重进行更新迭代,在大量样本学习过程中提取到更深层次、更抽象的特征。近年来,众多学者将深度学习方法应用于人脸表情识别当中,并且取得了较好的效果。
2014 年,Simonyan 等人[2]提出了VGGNet 模型,探索了卷积神经网络的深度与其性能之间的关系,为深度卷积神经网络(Deep Convolutional Neural Network,DCNN)的发展奠定了基础。在此基础上,Duncand 等人[3]提出了VGG_S网络模型用来进行实时检测,但是准确率偏低。Zhang 等人[4]将表情图像转化为LBP 特征图,再将LBP特征图用作CNN的输入进行训练,取得了较好的效果,但是这会导致在未知环境下准确率不高,鲁棒性不足。Dhankhar 等人[5]利用ResNet-50 模型和VGG16 模型组合形成一个新的组合模型识别面部表情,在KDEF数据集上取得了较好的效果。为了提升表情识别的准确率,增强训练模型的泛化性,本文在传统VGGNet的基础上对模型进行了改进,设计新的输出模块替换全连接层,再利用迁移学习进行训练,改进后的模型在CK+、JAFFE、FER2013数据集上进行测试,准确率和泛化性均有提升。
除了对基础模型以及网络结构进行改进之外,很多研究者还对损失函数进行了研究与改进。Hadsell等人[6]提出了Contrastive Loss损失函数,其目的是增大类间差异并且减少类内差异。Schroff 等人[7]提出Triplet Loss损失函数,能够更好地对细节进行区分,但是Triplet Loss收敛速度慢,导致模型性能下降。Ko等人[8]提出中心损失函数Center Loss,让样本绕类内中心均匀分布,最小化类内差异,但计算效率太低。目前,常用的人脸表情数据集(CK+、JAFFE、FER2013)[9-11]中存在着样本不平衡问题。样本不平衡问题容易导致模型的训练出现过拟合,同时也会导致模型在不同类别上分类性能出现较大的差异。为了解决样本之间不平衡问题,Lin 等人[12]提出Focal Loss 损失函数,通过聚焦参数γ 使模型更多的关注难分类样本,提高模型分类性能,但并不能解决误标注样本问题。本文在此基础上,对Focal Loss进行改进并应用于人脸表情识别中。针对Focal Loss 对于误标注样本产生的误分类问题,设置阈值对置信度进行判别,将改进的Focal Loss 分别在CK+、JAFFE、FER2013数据集上进行多组实验。实验结果表明,相比于传统交叉熵损失函数,改进的Focal Loss能够将模型的准确率提升1~2 个百分点。使用改进的Focal Loss,模型的分类能力更加均衡。
1 迁移学习及模型改进
1.1 迁移学习
迁移学习从相关领域(源域)传输信息来提高一个领域(目标域)的学习训练效率,在图像处理领域被广泛利用。源域的选择是迁移学习的关键,预训练模型与目标数据集关联与相似性较高,则迁移学习效果较好。经过实验分析,本文使用在ImageNet 数据集上预训练的VGG16模型的权重文件。ImageNet数据集是一个庞大的自然图像数据集,具有超过1 500 万幅图像和2 万多个类别,迁移其权重将会提升本实验训练效率和准确率。
1.2 改进的VGGNet模型
在表情识别任务中,不同的类别间表情样本具有很大的相似性和易混淆性,需要较多的卷积层对深层次、抽象的特征进行提取。深层次的网络模型如ResNet等人[13],在面对样本量较少的表情数据集时,由于层次过深容易导致参数量剧增,产生过拟合现象,并不能发挥出较好的识别效果。VGG16模型具有小卷积核和深层网络两个特点。模型中划分了不同的块,每一个块内包含若干卷积层和一个池化层,大量的卷积层使模型具有较好的特征提取能力。经过实验对比,本文选择经典的VGG16 网络模型并且对其进行改进,在充分提取特征的前提下,避免过拟合现象的发生。改进的VGG16 网络模型如图1所示。

图1 改进的VGG16模型对比图Fig.1 Comparison chart of improved VGG16 model
为了避免过拟合现象,增强模型泛化性,本文设计新的输出模块替换预训练模型的全连接模块。输出模块如图2所示。

图2 输出模块流程图Fig.2 Flow chart of output module
输出模块主要由改进的深度可分离卷积和全局平均池化组成。深度可分离卷积层[14]可以进一步提取特征,相比于普通卷积节省了大量参数,同时仍具有和普通卷积相当的特征提取能力。为了防止梯度消失,减少参数之间的依存关系,缓解过拟合发生,深度可分离卷积在深度卷积和点卷积后都使用了ReLU 激活函数,ReLU定义如下:
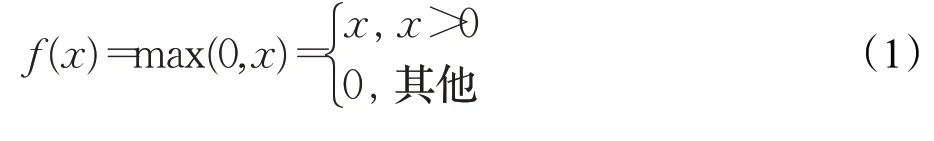
本文对深度可分离卷积进行改进,将深度卷积中的ReLU 激活函数替换为Hard-Swish[15]激活函数。Hard-Swish激活函数公式为:
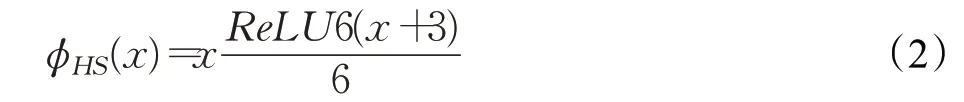
与ReLU 激活函数相比,Hard-Swish 激活函数具有更强的非线性能力。在深度可分离卷积中采用Hard-Swish激活函数,使得各通道的信息更好的保存下来,在训练过程中网络模型具有更好的收敛能力。
为了进一步缓解过拟合现象,本文采用全局平均池化层替换原本的全连接层,直接实现了降维,减少了网络的参数量(CNN中占比最大的参数其实是最后的全连接层),在保证模型分类性能的同时,加快了训练速度。
用新设计的输出模块代替VGG16的全连接模块构成一个新的网络模型,将已训练完成的卷积层权重与参数迁移到新的网络模型中,利用表情样本对新的网络模型进行训练。实验证明,训练完成的新模型具有较好的表情识别效果。具体方法流程如图3所示。
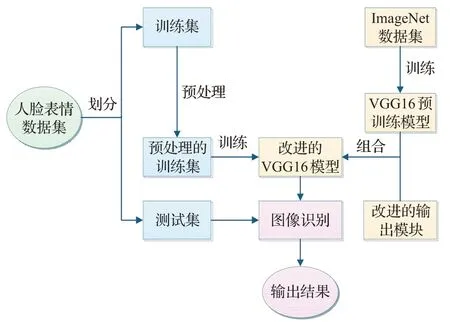
图3 人脸表情识别方法结构图Fig.3 Structure diagram of facial expression recognition method
2 样本不平衡问题与Focal Loss改进
样本不平衡是机器学习领域中一个重要的问题,该问题会导致稀少样本淹没在较多的样本中,降低稀少样本的重要性。在实际分类问题中,多数样本都是简单易分的,而难分的样本只占少数,简单的样本占据主导权。简单样本损失小,但数量多,对损失起了主要贡献,难分类的样本则容易被模型忽略。不平衡类别分布问题在真实世界的人脸表情收集过程中也很常见,例如,快乐这一表情很容易被捕捉,而厌恶表情则由于其微妙性以及难理解性更难被收集到。这些参杂不确定性的样本参与训练往往会导致网络过拟合、损害模型学习有用信息以及网络在初期不收敛等问题。在FER2013 数据集中,数量最多的样本与数量最少的样本的数量比约为16∶1,如图4 所示。对于表情识别任务来说,处理样本不平衡问题,具有重大意义。
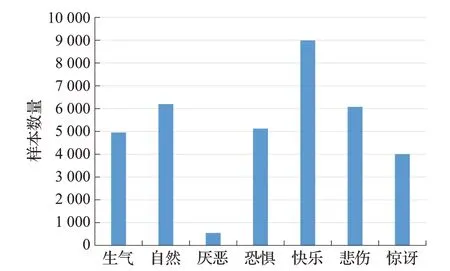
图4 FER2013数据集中各类样本分布图Fig.4 Distribution map of various samples in FER2013 dataset
在表情识别任务中,交叉熵(Cross Entropy,CE)是常用的损失度量函数,公式如下:

其中pi为模型预测结果对应标签的概率。本文使用Softmax 分类器将表情数据集样本分为7 类,则pi(i=1,2,…,7)表示Softmax 层7 个节点的离散概率,显然,ai(i=1,2,…,7)表示Softmax层对应结点输出。pi的计算公式为:

在表情识别任务中,交叉熵损失函数在面对多分类任务时,不同类别间的样本不平衡会导致模型分类性能退化,困难样本与简单样本之间的不平衡也会造成大量简单样本降低整体损失,使模型在训练中难以对困难样本进行过多的关注。Lin 等人[12]针对样本不平衡问题,在标准交叉熵的基础上进行改进,提出了聚焦损失函数(Focal Loss,FL),Focal Loss通过减少易分类样本的权重,使得模型在训练时更加专注于难分类样本。Focal Loss公式如下:

其中,平衡参数α的作用是控制不平衡样本对总损失的权重,平衡不同类别样本的数量。聚焦参数γ为一个大于等于0的超参数,用来控制易分类样本和难分类样本的权重。当一个样本被分错时,pi是一个很小的值,因此调制系数(1-pi)γ就趋于1,而当pi趋于1 时(样本分类正确且属于易分类样本),调制系数趋近于0,对总体损失贡献很小。Focal loss通过控制调制系数达到专注于困难样本的目的,通过平衡参数α达到平衡不同类别样本的数量的目的。
Focal Loss面对样本不平衡问题具有较好的效果,但同样也有缺陷。由于表情之间具有很大的相似性,人眼难以对其进行分类,实际数据集中往往有少量误标注样本,如图5所示。而在Focal Loss的计算中,若数据集样本标注有部分错误,或是本身噪声很大,则会因为权重的增加使模型学习到错误的信息,降低模型的性能。

图5 FER2013数据集中易混淆样本样例图Fig.5 Sample graph of confusable samples in FER2013 dataset
针对Focal Loss无法处理误标注样本问题,通过样本的置信度与真实标签对其设置阈值判断,对误标注样本进行筛选,改变其置信度,从而降低Focal Loss 对该类样本关注度,提高模型分类性能。

其中,FL 为Focal Loss,ptop为几类样本中预测为真的概率(置信度)最大值,超参数c(c<1)为概率阈值,yt为该样本的真实标签,yp为该样本的预测标签。
为了筛选出误标注样本,本实验设定概率阈值c对Softmax 的输出映射进行判断,关于c的取值在实验部分讨论。若该样本映射出的最大概率ptop大于这个阈值c,认为该样本置信度很高,将该样本预测标签与真实标签进行对比,若对比发现样本预测标签等于其真实标签,说明该样本为一个置信度高的简单样本,执行Focal Loss;若样本预测标签不等于其真实标签,则说明该样本是一个置信度高的误标注样本,将其预测概率置为极小值ε,即舍弃该样本。本文算法针对误标注样本问题,对Focal Loss 提出了改进,设置阈值参数c对Softmax 输出结点的离散概率进行判断,筛选出误标注样本并舍弃,提升了模型分类性能。改进的Focal Loss算法流程如图6所示。
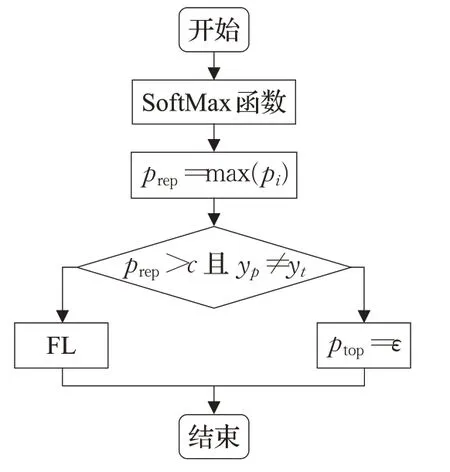
图6 改进的Focal Loss算法流程图Fig.6 Flow chart of improved Focal Loss algorithm
3 实验过程及结果分析
本文所有实验均在python3.6.5上实现,硬件平台为Intel®Xeon Silver 4114 CPU,内存大小为64 GB,GPU为NVIDIA TITAN V,显存大小为12 GB。
3.1 人脸表情数据集
为了说明本文方法的有效性,采用日本女性人脸数据(JAFFE)库、Extended Cohn-Kanada(CK+)数据集和FER2013数据集进行实验评估,实验采用的样本数量分布如表1所示。

表1 FER2013、JAFFE、CK+数据集实验样本选取数量分布表Table 1 Selection number distribution table of FER2013,JAFFE,CK+dataset experimental samples
其中JAFFEE 数据集包含10 位日本女性的213 张大小为256×256人脸正面图像,共有7种标签,该数据集样本较为平衡,标签比较标准,如图7所示。
图7 JAFFE数据集样例图Fig.7 Sample diagram of JAFFE dataset
CK+数据集采集了123人共593例的动态表情图像序列,每个图像序列包含从表情平静到表情峰值的所有帧,其中仅有327例有表情标签。共有7种表情,该数据集样本较为不平衡,如图8所示。

图8 CK+数据集样例图Fig.8 Sample diagram of CK+dataset
Fer2013人脸表情数据集由35 886张人脸表情图片组成,其中,测试图(Training)28 708 张,公共验证图(Public Test)和私有验证图(Private Test)各3 589张,每张图片是由大小固定为48×48 的灰度图像组成,共有7种表情,该数据集样本较为不平衡,标签较为混乱,分类难度略大,如图9所示。

图9 FER2013数据集样例图Fig.9 Sample diagram of FER2013 dataset
3.2 预处理
由于表情数据集中人脸尺寸、角度不一致会对识别结果造成影响,针对JAFFE 和CK+数据集中原始图像的多余信息,采用Haar-like特征对人脸区域进行检测并提取。通过直方图均衡化将图像的直方图分布变成近似均匀分布,增加图像对比度,增强图像细节。如图10所示,最后对图像进行缩放至48×48的大小。

图10 预处理样例图Fig.10 Sample image of set preprocessing
为了提升训练模型的泛化性,采用Image Data Generator数据增强技术扩充训练数据,将图像随机旋转-10°到10°,在水平与竖直方向上对图像进行10%范围内的随机偏移,对图像进行10%范围内的随机缩放,对图像进行随机水平翻转。
3.3 实验设置与结果
现有的研究工作表明,神经网络提取的特征具有通用性,在大型通用图像数据集上训练过的深度神经网络,再对结构进行调整和训练,可以很好地迁移到其他问题上,因此在此思想基础上,利用迁移学习,分别选用了MobileNet[14-16]、SqueezeNet[17]、ShuffleNet[18]、Xception[19]、VGGNet、InceptionV3[20]以及ResNet[13]等优秀的网络模型进行实验对比,实验结果如表2所示。本文实验均对数据进行了100个epoch,每个epoch迭代200次,共计迭代2 万次训练。采用自适应矩估计(Adam)的训练策略,学习率设置为1E-4,当val_loss值不再下降时,学习率乘以衰减因子0.5,α和γ两个超参数选择经验值,α参数选择为0.25,γ参数选择为2,c设置为0.8。经过实验分析,最终选用VGG16作为本文的网络模型。
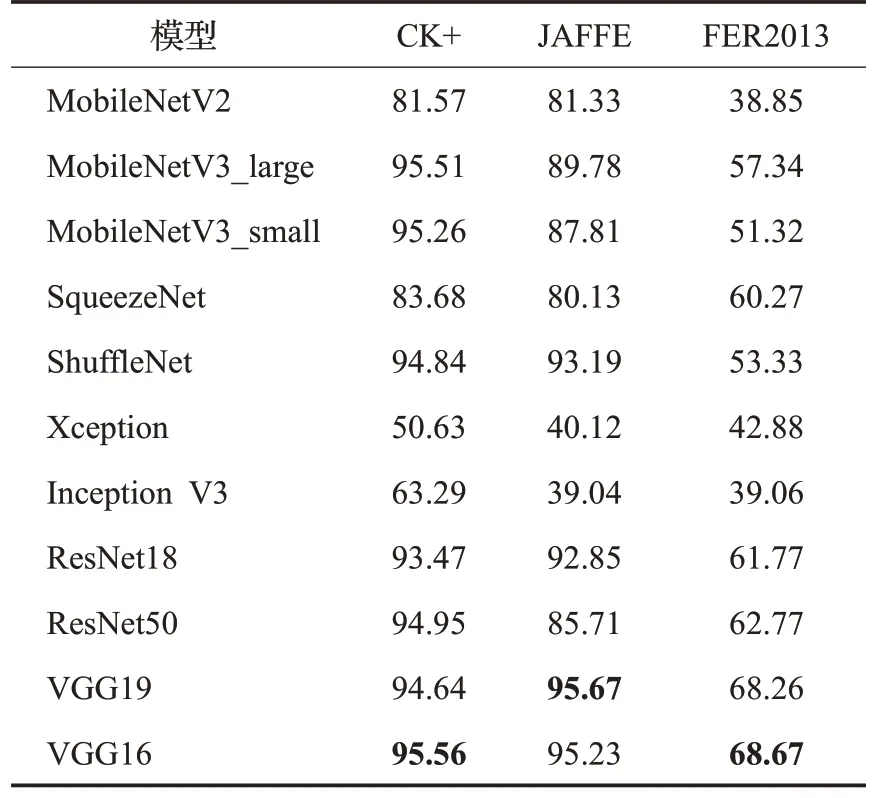
表2 不同模型准确率对比表Table 2 Comparison table of accuracy of different models %
为了验证本文算法的有效性,在CK+数据集上分别对改进前后的损失函数和模型进行对比实验,如表3所示。其中,传统VGG16 记为VGG16,改进后的VGG16记为I_VGG16;传统Focal Loss 记为FL,改进后的Focal Loss记为I_FL。经过实验分析,I_FL相比交叉熵损失函数准确率提升了1.73%,相比FL 准确率提升了1.17%,本文算法相比VGG16网络模型结合交叉熵损失函数,准确率提升了4.12%,证明了本文算法具有更好的分类能力。
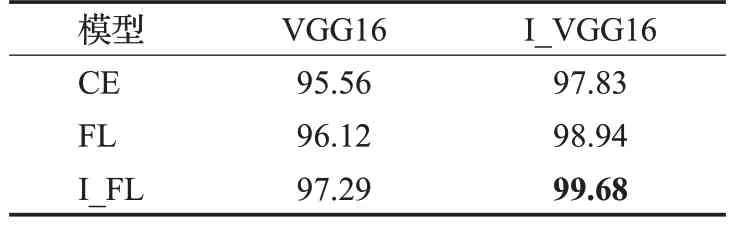
表3 CK+数据集中不同损失函数对比表Table 3 Comparison table of different loss functions in CK+dataset %
为了进一步研究改进的Focal Loss 的对实验结果的影响,本文对超参数c进行多次实验。表4 所示为c取不同值时,在CK+、JAFFE 以及FER2013 数据集上的表情识别准确率,可以看出c=0.8 时,准确率最高。

表4 c 取不同值时在不同数据集上面部表情识别准确率Table 4 Accuracy of facial expression recognition on different datasets when c takes different values %
在CK+、JAFFE以及FER2013数据集上与国内外优秀算法进行了比较,目前大部分模型都取得了较好的准确率。本文模型与其他模型相比,在CK+数据集上准确率有3%~5%的提升,在JAFFE 数据集上准确率有1%~4%的提升,如表5、表6 所示。在各类表情的准确率上也较为平均,验证了模型的有效性。

表5 不同方法在CK+数据集上基本表情识别准确率Table 5 Accuracy of basic expression recognition on CK+dataset by different methods %

表6 不同方法在JAFFE数据集上基本表情识别准确率Table 6 Accuracy of basic expression recognition on JAFFE dataset by different methods %
在FER2013 数据集上与目前国际上已有的几种方法进行了比较,如表7所示。FER2013数据集上人眼识别准确率约为65%,可以看出绝大部分模型相比人眼具有更高的准确性。与其他方法相比,本文算法准确率较高。

表7 不同方法在FER2013数据集上基本表情识别准确率Table 7 Accuracy of basic expression recognition on FER213 dataset by different methods %
为了进一步验证本文算法,根据FER2013数据集上的实验结果绘制混淆矩阵。其中列代表预测类别,行代表真实类别,对角线数值为该类预测准确率,其余为预测错误的概率,由表8 分析可知,本文算法的分类结果分布较为均匀,各类表情样本更倾向于分到所属类别,具有较好的分类能力。

表8 FER2013混淆矩阵Table 8 FERE2013 confusion matrix
为了测试本文算法在实际应用中的识别能力,设计了基于真实人脸表情识别的仿真实验。摄像头采用英特尔D435,使用SSD算法进行人脸检测,对每一帧画面基于本文方法进行表情识别,如图11 所示。实验结果表明,在真实条件下,本文算法具有较好的泛化性。
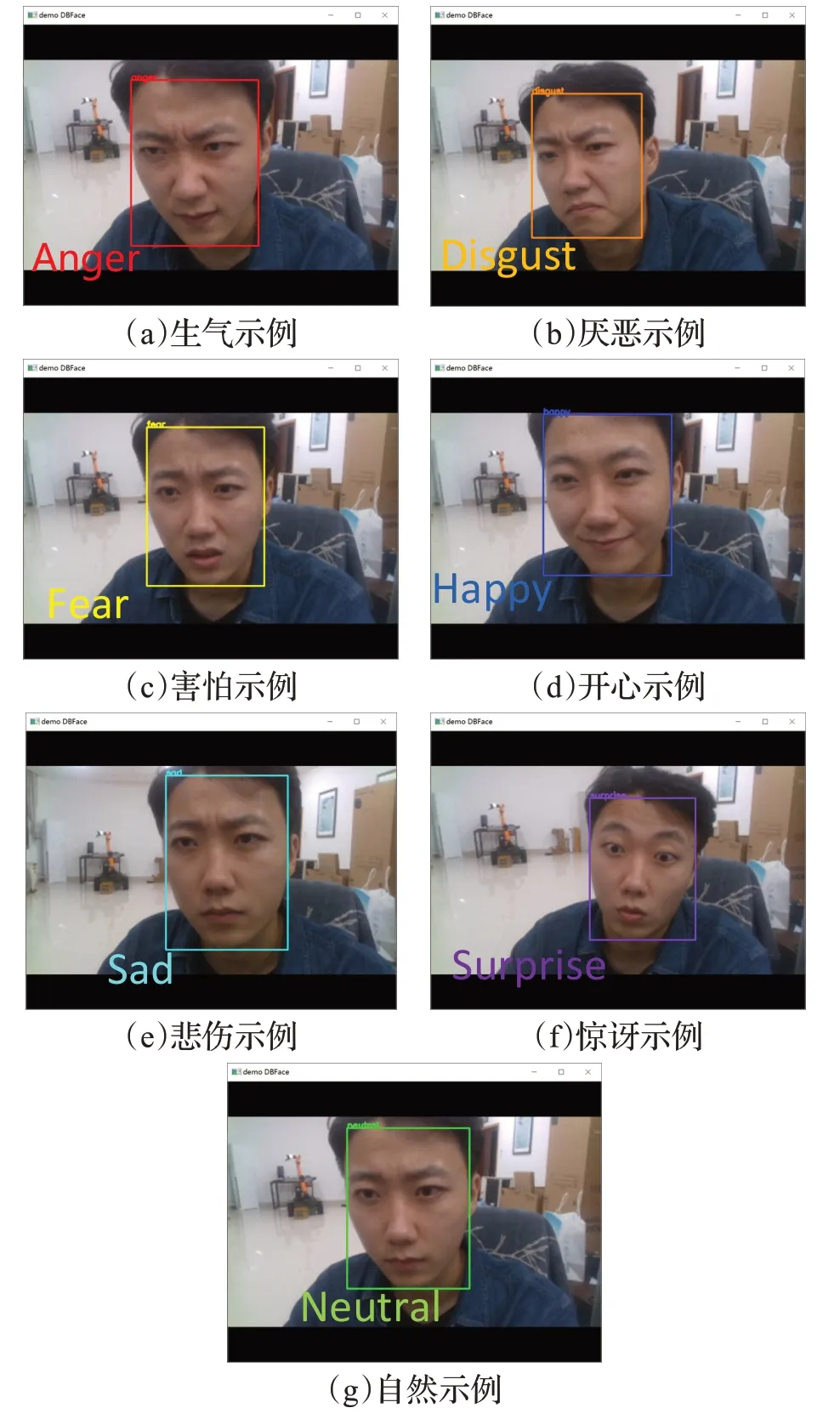
图11 表情识别测试效果Fig.11 Test effects of expression recognition
4 结束语
本文对传统VGG16 网络模型做出改进,并进行迁移学习。针对数据集中存在的误标注样本问题,对Focal Loss添加阈值判断,筛选出误标注样本并进行抑制处理。本文分别在CK+、JAFFE 以及FER2013 数据集上做了对比实验,实验结果表明,改进的模型识别准确率较高,改进的Focal Loss对误标注样本有较好的抑制性。
虽然人脸表情识别已经取得了较好的识别效果,并且在科研项目上应用广泛,但是光照、遮挡以及侧头等因素的影响依然较大,为了克服这些外界因素,未来的研究可以将表情识别从室内转向室外,在更复杂的环境下应用。
