锦标赛精英学习与协方差变异的烟花算法
2021-10-14万达,李俊
万 达,李 俊
1.武汉科技大学 计算机科学与技术学院,武汉 430065
2.智能信息处理与实时工业系统湖北省重点实验室,武汉 430065
受烟花在夜空爆炸这一自然现象启发,Tan 等[1]于2010 年提出了烟花算法(FireWorks Algorithm,FWA),FWA 主要由爆炸算子、变异算子和选择策略三大部分组成,其在解决单目标优化问题过程中,具有很好的效果。烟花算法自提出后就受到了诸多科研工作者的关注,许多改进算法也相继被提出。烟花算法的改进主要可以分为两类:一类是在基本烟花算法或其他改进烟花算法的基础上进行算子的分析和改进;另一类是将烟花算法与其他启发式算法结合。
第一类算法改进主要有:Zheng等[2]对烟花算法的爆炸算子、变异算子、选择策略和映射规则等进行了详细的分析,针对其存在的缺陷做出了五点改进,提出了增强型烟花算法(Enhanced FireWorks Algorithm,EFWA)。接着,Zheng等[3]和Li等[4]通过自适应调整核心烟花的爆炸半径分别提出了动态搜索烟花算法(dynamic search FireWorks Algorithm,dynFWA)和自适应烟花算法(Adaptive FireWorks Algorithm,AFWA)。文献[3]中,烟花爆炸半径的变化过程由烟花种群产生的火花适应度值是否发生改进(即是否得到适应度值更优的火花)来决定。文献[4]中,烟花爆炸半径依据当前种群中最优个体与特殊个体间的距离自适应调节。这两种方法由于采用了自适应调整爆炸半径的机制,都极大提升了增强型烟花算法的性能。方柳平等[5]在dynFWA 基础上,通过嵌入两种利用历史成功信息生成的不同的学习因子的方式来改进传统的动态搜索烟花算法,提出了一种改进的动态搜索烟花算法(IdynFWA)。张水平等[6]在增强型烟花算法的基础上,引入一种动态爆炸半径调整机制,并在选择过程中引入了一种双精英-锦标赛选择策略,提出了带有动态爆炸半径的增强型烟花算法(EFWA-DER)。Zheng 等[7]在dynFWA 基础上,通过使用独立选择的方法显著地提高了烟花的开采能力,并且在烟花之间加入避免拥挤的合作策略,提出了基于烟花算法的合作框架(CoFFWA)。之后,Zheng等[8]又将协方差变异算子引入到CoFFWA中,提出了基于协方差变异的协同框架烟花算法(CoFFWA-CM)。Li等[9]在烟花算法中引入引导火花,提出了引导烟花算法(GFWA)。Li等[10]针对解决多模式优化问题提出了一种基于淘汰者锦标赛的烟花算法(LoTFWA)。
第二类算法改进主要有:Zheng 等[11]提出了将烟花算法和差分演化算法进行混合的一种新型算法(FWADE)。黄辉先等[12]为解决多目标优化问题,用差分变异算子代替高斯变异算子,提出了进化信息引导的烟花差分混合多目标算法(MOHFWDE)。刘茜等[13]提出了一种由差分进化引导趋化算子的烟花算法(BFA),该算法在求解过程中利用优越火花的位置信息,通过差分进化算法驱动其他粒子移动,从而对群体中其他粒子位置信息进行改善,增强了粒子群体间的交流,削弱了映射规则和高斯变异给整个求解过程带来的不良影响,提高了算法的优化性能。韩守飞等[14]将模拟退火的思想引入到烟花算法中,并对烟花算法中某些单个烟花个体进行高斯扰动,提出了一种基于模拟退火与高斯扰动的烟花优化算法(SAFWA)。莫海淼等[15]提出一种具有自适应步长与协同寻优的蝙蝠烟花混合算法。Zhang 等[16]提出了一种将生物地理学优化算法和增强型烟花算法(EFWA)进行混合的烟花算法(BBO-FWA)。Chen等[17]提出一种将烟花算子嵌入到粒子群算法求解过程中的全局优化混合算法(PS-FW),该算法在解决全局优化问题过程中具有良好效果。
文献[10]使用了一种新的爆炸火花分布方式,以及提出了一种淘汰锦标赛策略,实验证明该算法在解决多模式优化问题上具有较好的效果。但是该算法并没有将最重要的核心烟花与其他烟花区分开来,进行进一步的操作,也没有利用上一代烟花的信息。导致该算法全局探索能力较强,但是局部搜索效果并不明显,算法收敛速度过慢。
针对文献[10]中的不足,本文提出了一种基于锦标赛精英学习与协方差变异的烟花算法(GLFWA-CM)。首先,本文算法根据当代核心烟花相对于上一代核心烟花的变化来确定核心烟花在每一维上的爆炸半径及其爆炸火花分布,加强了不同代烟花之间的信息交互,使得搜索资源的分配更加合理,提高了算法的局部搜索能力。其次,本文引入一种协方差变异算子,先计算部分适应度值较好的爆炸火花的均值和协方差,然后根据均值和协方差来随机产生一个协方差变异火花,代替文献[10]中的引导火花,有助于平衡算法的局部搜索和全局搜索能力。同时,本文提出了一种基于锦标赛的精英学习策略,对于选择后的较差个体并没有淘汰掉,而是让它们向最好个体学习,提高了算法的收敛速度。最后通过15 个测试函数来验证本文算法的有效性和准确性,并与其他算法的实验结果进行比较。
1 烟花算法
在烟花算法中,为不失一般性,假设待求解的优化问题形式如下[18]:

其中Ω为解的可行域,使用烟花算法对优化问题(1)进行求解的目标是在可行域Ω内,寻找一点x,使得f(x)具有全局最小值。
假设烟花种群规模为N,烟花算法产生子代的方式是在N个烟花附近的规定区域内通过爆炸操作生成爆炸火花。对于烟花xi,其爆炸半径Ai和爆炸火花数目Si的计算公式分别为:

式(2)中,ymin为当前烟花种群中适应度最小值;式(3)中,ymax为当前烟花种群中适应度最大值。是常数,用来调整爆炸半径大小,S也是个常数,用来调整产生的爆炸火花数目大小,ε是一个机器最小量,用来避免除零操作。
为了避免产生过多或者过少的火花,对于式(3)中的Si进行了如下的限制:
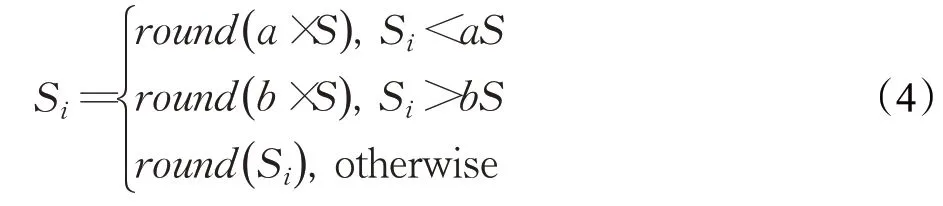
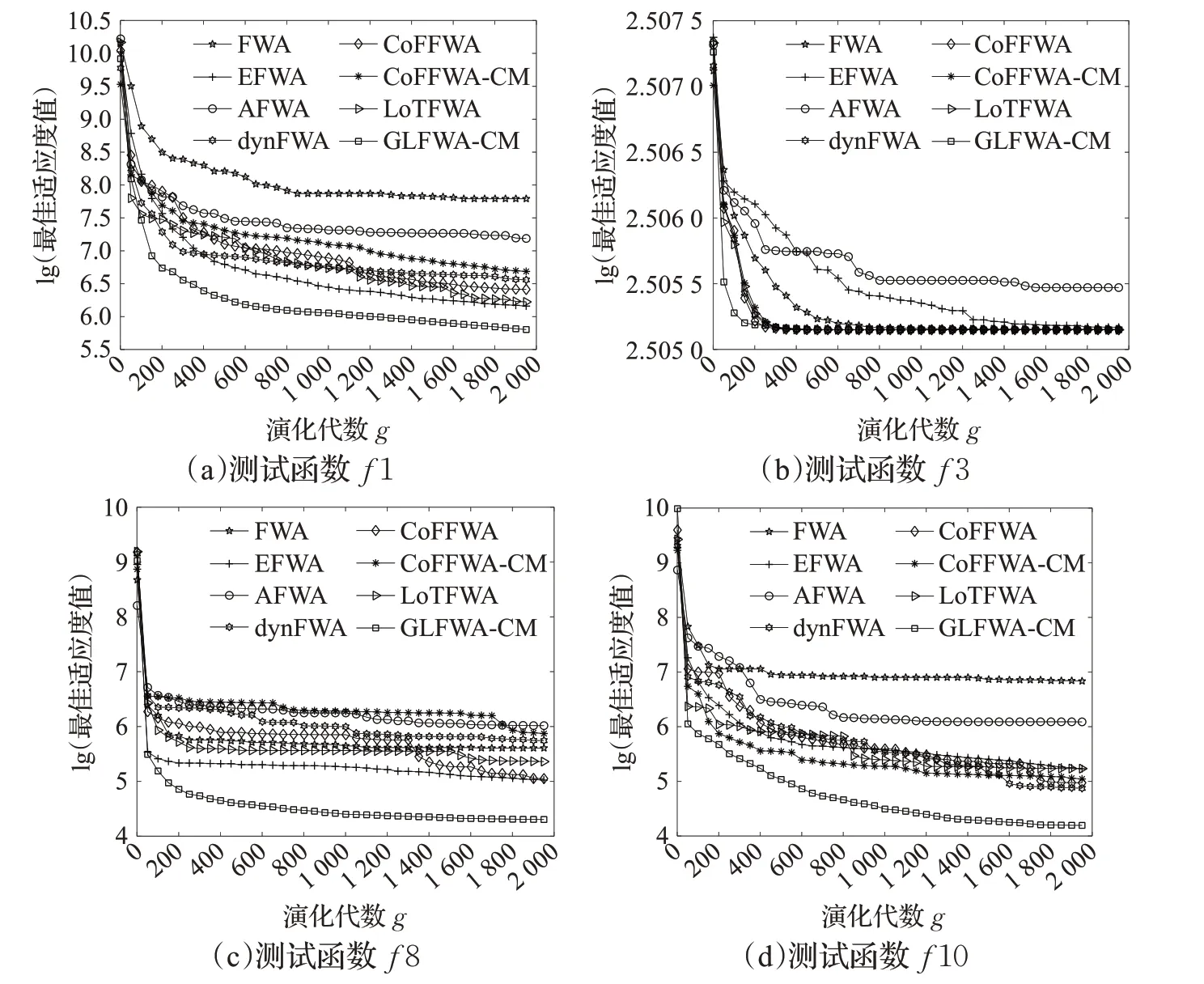
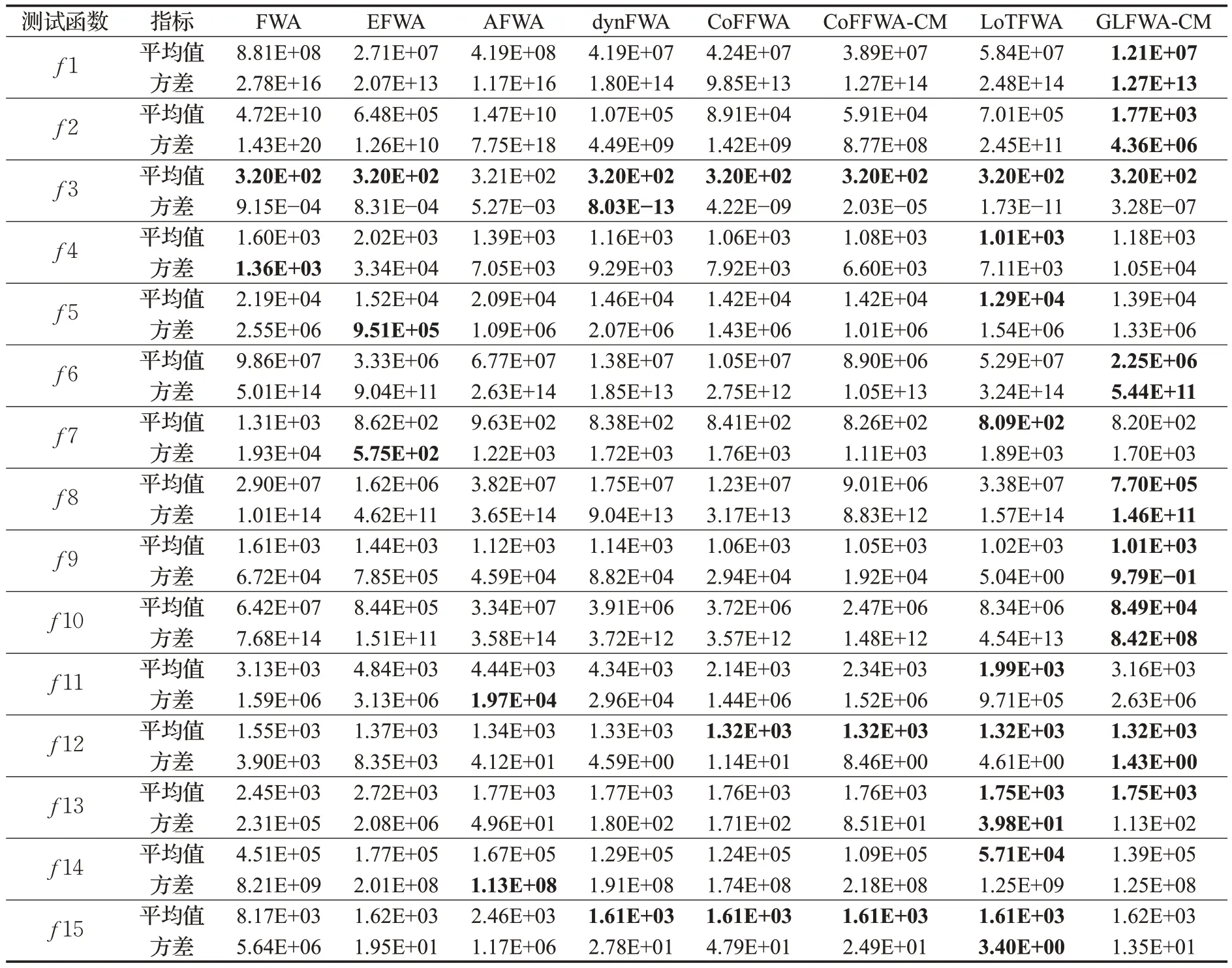
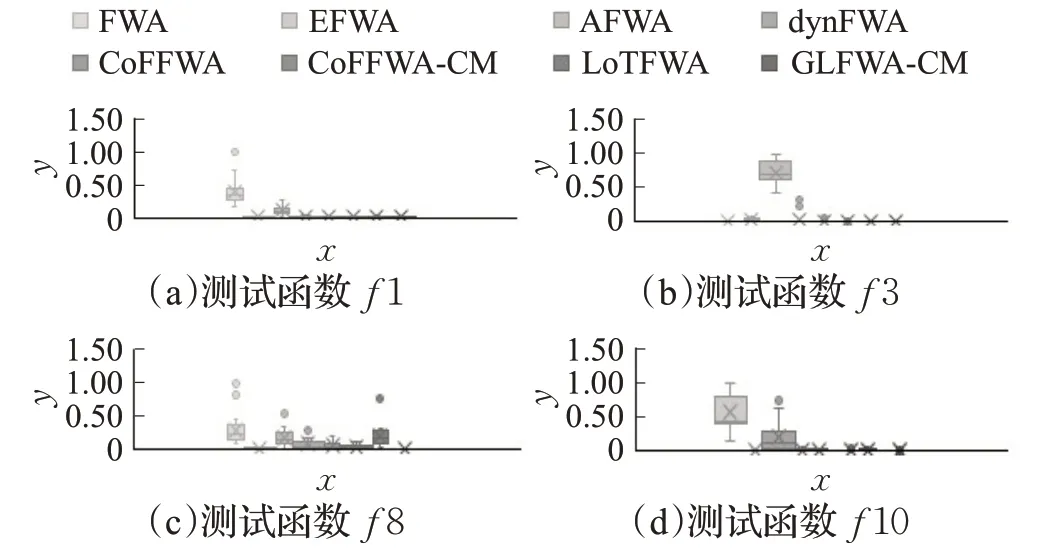
式(4)中,a、b是两个常数,且a 在确定烟花的爆炸半径和爆炸火花数目后,就可以执行爆炸操作了。第i个烟花xi产生第j个爆炸火花x(i,j)的方式为:从第i个烟花中随机选择z维坐标按下式更新: 式(5)中,k为被选择的维度,Ai为第i个烟花的爆炸半径,rand(-1,1)为区间[-1,1]之间的一个均匀随机数。 为了增加烟花种群的多样性,烟花算法引入了变异算子用于产生高斯变异火花。高斯变异火花产生的过程如下:首先在烟花种群中随机选择一个烟花xi,然后从该烟花所有维度坐标中随机选择z维坐标执行高斯变异操作,对烟花xi的第k维坐标执行高斯变异操作的公式为: 式(6)中,e~N(1,1),N(1,1)表示均值和方差均为1的高斯分布。 在产生爆炸火花和高斯变异火花的过程中,可能会出现产生的火花在可行域Ω的边界以外的情况。当火花在维度k上超出边界时,将通过下式将其映射到可行域Ω之内。 为使烟花种群中优秀的信息能够传递到下一代种群中,算法会在候选者集合K(包括烟花、爆炸火花和高斯变异火花)中选择N个个体作为下一代的烟花。候选者集合K中适应度值最小的个体会被确定性地选择到下一代作为烟花,而对于剩下的N-1 个烟花的选择采用轮盘赌的方法在候选者集合K中进行选择。对于候选者xi,其被选择的概率p(xi)计算公式如下: 式(8)(9)中,R(xi)为当前个体到候选者集合K中除xi外所有个体之间的距离之和。 针对传统烟花算法收敛精度低,收敛速度慢,容易陷入局部最优等问题,提出一种基于锦标赛精英学习与协方差变异的烟花算法(GLFWA-CM)。该算法主要包括爆炸算子、协方差变异算子和选择策略三个部分。在爆炸算子中,用幂律分配的方式来计算爆炸火花数目,根据烟花是否产生更好的火花来动态确定爆炸半径,如果产生更好的火花,则增大爆炸半径,否则减小,这两种策略可以有效解决烟花算法容易陷入局部最优的问题。同时,根据核心烟花更新信息来确定核心烟花每一维的爆炸半径,并且在更新方向上产生更多火花,这种方法显著增强了核心烟花的局部探索能力,提高了算法的收敛精度。对超出边界的火花使用一种随机映射规则,避免了烟花算法火花往往映射在原点附近的缺陷。用协方差变异火花代替其他变异火花,可以有效平衡算法的局部搜索和全局搜索能力。对于独立选择后的较差烟花,执行一种基于锦标赛的精英学习策略,可以有效提高算法的收敛速度。 本文根据烟花适应度值的优劣将烟花分成了核心烟花和非核心烟花,其中核心烟花xF是烟花种群中适应度值最优的烟花,除核心烟花外,其他的都是非核心烟花。 2.1.1 幂律分布 幂律分布[19]是指某个具有分布性质的变量,且其分布密度函数是幂函数的分布。在烟花算法中,爆炸火花的数目仅仅与烟花的适应度值有关,当烟花较差时,其爆炸火花数目往往只能取最小阈值,而这类烟花爆炸半径又相对非常大,所以这类烟花搜索效率极低,这显然不合理。为了改变这种不合理现象,本文采用一种幂律分配的方式来计算爆炸火花数目。首先是对烟花适应度值进行升序排序,并确定烟花的等级,其中,适应度值越小,等级越低。然后,根据烟花的等级计算爆炸火花的数目,计算方法如下: 式(10)中,Si指第i个烟花的爆炸火花数目,S为常数,用来调整产生的爆炸火花数目大小,N为烟花种群规模大小,ri表示烟花xi的等级,α是一个常数。从式(10)可以看出爆炸火花数目的分配与该烟花适应度值的排序相关联,而不再像式(3)那样依赖适应度值的数值本身。文献[10]证明了这是一种很有效的资源分配方式。 2.1.2 动态爆炸半径 在烟花算法中,爆炸半径是根据式(2)计算的,分析式(2)可知,当烟花之间适应度值相差较大时,适应度值较小的烟花其爆炸半径也相对较小,假设在该烟花搜索区域存在一个局部最优解,那么在迭代过程中,该区域烟花爆炸半径会不断缩小,爆炸火花数目会不断增加,并且由于它占据大量资源,导致其他烟花搜索资源减少,降低了找到全局最优解的概率。那么最终算法很可能就会陷入局部收敛,并且很难跳出。 为了避免这种情况,本文引入一种动态爆炸半径策略。烟花算法的爆炸半径根据上一代最优解自适应地改变,当烟花产生适应度值更好的火花时,烟花爆炸半径会增大以提高全局探索能力,再加上2.1.1 小节提出的爆炸火花幂律分配方式,使得烟花之间的爆炸火花数目不会相差太悬殊,该策略可以有效解决烟花算法容易陷入成熟收敛的问题。本文烟花爆炸半径的计算公式如下: 2.1.3 核心烟花更新信息引导 在烟花算法中,核心烟花的爆炸半径对烟花算法的性能有着决定性的影响。而大家知道,在算法迭代过程中,尤其是在前期,核心烟花一直在更新,这种更新表明了烟花算法向着最优解方向搜索的趋势。那么,在潜在最优解位置明确的情况下,可以利用这种趋势,即利用核心烟花的更新信息来确定核心烟花在不同维度的爆炸半径以及其爆炸火花的分布。基本思想是核心烟花在更新幅度越大的维度其爆炸半径就越大,反之,则越小。另外,在爆炸过程中,朝着核心烟花的更新方向上分布更多的火花。这样有助于核心烟花在更新方向上进行更加细致的搜索,增加了核心烟花找到最优解的概率。但同时需要注意的是,虽然更新信息指出了潜在最优解的位置,但是也存在着最优解不在更新方向上的可能性。如果所有的火花或太多的火花都分布在更新方向上,则算法很有可能会陷入局部最优。因此,在选择某一维度执行爆炸操作时,需要确定一个合适的选择概率β,以确保大多数火花分布在更新方向上,也要保证有一定火花分布在更新方向的反方向上,具体实现方法在算法1中给出。 算法1 上述操作的实质是在核心烟花的更新方向上,增加爆炸火花的数目,而在其他方向上,减少爆炸火花数目。这虽然显著增强了核心烟花寻找最优解的能力,但是也对核心烟花爆炸火花的多样性有一定影响,增加了算法陷入局部最优解的可能性。为了降低该策略对算法全局探索能力的影响,本文中最大爆炸火花数目设置的相对较大,通过产生更多的爆炸火花,一定程度上弥补了这些方向的火花丧失,可以进一步降低该策略对火花多样性的影响。同时爆炸火花数目的增多,也使得核心烟花可以更加细致地在更新方向上进行局部搜索,提高算法收敛精度。 对于核心烟花,其各个维度上的爆炸半径的计算公式如下: 式(12)中,xF(g)和xF(g-1) 分别是当前代和上一代核心烟花,而ΔxF则是当前代核心烟花的更新信息。在式(13)中,|ΔxF(k) |是核心烟花更新信息在第k(k=1,2,…,D)维上的绝对值,D是维数,是根据式(11)计算的当前核心烟花所在小组的动态爆炸半径,(g)是当前代核心烟花在第k维上的爆炸半径,ε是一个机器最小量,用来避免除零操作。 根据式(12)可知,当核心烟花的信息在某一维并没有更新或者更新幅度很小时,|ΔxF(k) |接近于0,而不等于0,那么,(g)也接近于0,即当前代核心烟花在第k维上的爆炸半径接近于零,这显然不利于核心烟花在该维空间上的搜索,为了避免这种情况,本文采用了一种最小爆炸半径检查操作,具体计算公式如下: 在式(14)中,Ainit和Afinal是最初和最终的最小爆炸半径,evalsmax是最大函数评估次数,t(t=1,2,…,evalsmax)是指当前的函数评估次数,(t)是在评估次数为t时第k维的最小爆炸半径。 2.1.4 随机映射规则 在式(7)的映射规则中,存在一个问题。在一般情况下,解空间往往是关于原点O对称分布的,而且超出解空间边界的火花往往分布在解空间边界附近,这就造成这些火花在使用公式(7)映射时,往往映射在原点附近,这无形中造成了搜索资源的浪费,也容易促使烟花算法陷入局部最优。为了解决这个问题,本文采用了一种随机映射规则,具体映射公式如下: 文献[2]对FWA经过分析后指出烟花算法的高斯变异公式存在缺陷,当产生的随机数e接近或等于0时,产生的变异火花就会分布在原点附近,并且很难跳出。因此,文献[2]提出了一种改进的高斯变异算子。之后,文献[20]又提出了一种新的变异算子,被称为协方差变异算子。相较于EFWA[2]仅仅利用每一代核心烟花的信息,FWA-CM[20]利用了烟花产生的部分适应度值最好的爆炸火花的信息,在更可能找到最优解的方向产生变异火花。实验证明协方差变异不仅可以避免FWA中变异公式的缺陷,而且相比EFWA 中的变异方式,协方差变异在更可能找到最优解的方向产生变异火花,提高了算法找到最优解的概率。并且由于协方差变异火花是利用爆炸火花的信息产生的,所以一般分布在烟花附近,这样对平衡算法整体的探索和开发能力也是有帮助的。因此,本文也使用协方差变异算子来产生变异火花,具体操作步骤如下: 首先,假设烟花产生的爆炸火花数目为λ,从所有的爆炸火花λ中选取适应值最好的μ个火花,m为被选中的μ个火花的均值,其计算方法如下: 式(17)中,xi为被选中的第i(i=1,2,…,μ)个火花。 在求得这μ个火花的均值m后,还需要计算这μ个火花数据的协方差矩阵,其协方差矩阵C的计算方法如下: 式中,ai和bi为第i个火花在d1和d2维度上的值,、为这μ个火花在d1和d2两个不同维度上的均值。需要注意的是,分母是μ,而不是协方差计算公式的μ-1,C是一个D×D的矩阵。 在选择新一代烟花时,GLFWA-CM 采用了独立选择策略和基于锦标赛的精英学习策略。独立选择策略是指将每个烟花和各自产生的火花看作一组,在进行烟花选择时,直接从每组里选择适应度值最好的个体作为下一代的烟花。文献[7]证明这种方式可以确保把当代每个烟花的搜索经验传递给下一代,而且每个烟花在各自区域的独立搜索也增加了非核心烟花对于优化过程的贡献度。 独立选择策略使得算法能够保持完整的探索能力,但是搜索资源始终是有限的,为了解决烟花算法收敛速度慢的问题,提出一种先竞争后学习的方法。烟花个体之间通过自身预估的最终适应度值进行竞争,如果某个被选择的个体不能在自身适应度值的基础上以当前的进化速度追赶上当代最好的个体,就会通过学习的方式来靠近当代最好个体,这样可以进一步增强算法在核心烟花附近的局部探索能力,并且加快算法的收敛速度。另外,在迭代过程中,由于独立选择策略,某些非核心烟花有可能在自己的搜索区域附近陷入局部最优,此时,它们的爆炸半径会不断减小,与核心烟花的差距也越来越大,当大到某种程度时,就会向核心烟花靠近,在靠近过程中逐渐找到更优解,爆炸半径会逐渐增大,最终帮助其跳脱出局部最优。如算法2所示,是基于锦标赛的精英学习策略的伪代码: 算法2 在算法2中,是使用独立选择策略从每个组(包括烟花和其产生的所有火花)里预选出来的第i(i=1,2,…,N)个烟花,是被选择的烟花中适应度值最好的烟花,是爆炸前的第i个烟花,f()是求解适应度值函数,g是当前迭代次数,Gmax是最大迭代次数,γ是一个常数参数。 GLFWA-CM算法的具体实现步骤如下: 步骤1初始化烟花种群规模N,协方差变异火花数目M,最大爆炸火花数目S,最大演化代数Gmax,爆炸火花数目分布参数α,选择概率β,精英学习因子γ,动态爆炸半径增大系数Ca和减小系数Cr,协方差变异火花选择比率η/λ,解的可行域Ω的上下边界和,初始爆炸半径,初始最小爆炸半径Ainit和最终最小爆炸半径Afinal等参数。 步骤2初始化N个烟花位置,并计算它们的适应度值,找出核心烟花xF。 步骤3根据适应度值大小对烟花进行排序,并划分等级,适应度值越小,等级越低。 步骤4根据式(10)计算每个烟花的爆炸火花数目Si。 步骤5根据式(11)计算烟花的爆炸半径。 步骤6根据式(12)~(15)计算核心烟花在每一维上的的爆炸半径(g)。 步骤7核心烟花根据算法1产生爆炸火花。 步骤8非核心烟花根据式(5)产生爆炸火花。 步骤9根据式(16)将超出可行域的火花映射到可行域内。 步骤10根据式(17)和(18)分别计算被选择火花的均值m和协方差矩阵C,根据N(m,C)随机产生一个协方差变异火花。 步骤11从每组烟花及其产生的所有火花中预选出适应度值最优的个体。 步骤12从预选择的烟花种群中找出适应度值最优的个体。 步骤13根据算法2对预选择的个体进行锦标赛精英学习操作。 步骤14判断是否满足终止条件,若满足,则返回全局最优解及其适应度值;否则,返回步骤3 进行循环迭代。 GLFWA-CM 算法的各项参数设置:烟花种群规模N=5,协方差变异火花数目M=5,最大爆炸火花数目S=200,最大演化代数Gmax=2 000,爆炸火花数目分布参数α=3,选择概率β=0.7,精英学习因子γ=0.1,动态爆炸半径增大系数Ca=1.2,减小系数Cr=0.9,协方差变异火花选择比率η/λ=0.25,解的可行域Ω的范围为[-100,100],,烟花初始爆炸半径,初始最小爆炸半径,最终最小爆炸半径 为了全面客观地对GLFWA-CM 算法进行评价,本文将其与标准烟花算法FWA[1]以及近些年提出的一些改进烟花算法EFWA[2]、AFWA[4]、dynFWA[3]、CoFFWA[7]、CoFFWA-CM[8]、LoTFWA[10](α和λ参数分别设置为3和200)在收敛精度、收敛速度和稳定性上进行比较,其他比较算法的参数设置均与原文献一致。每个算法均独立运行20次,算法问题维度D=30/100,每个测试函数的最大评估次数evalsmax=10 000。实验环境为:处理器Intel®Core™I5 6200U @ 2.30 GHz,RAM 4 GB,Win10 64位操作系统,MATLAB R2018b。 为了验证本文算法的适用性、有效性和正确性,选择CEC2015[21]中的15个标准测试函数,具体定义如表1所示,其中f1、f2 为单峰函数,f3~f5 为简单多峰函数,f6~f8 为混合函数,f9~f15 为复合函数。 表1 CEC2015的15个Benchmark函数Table 1 15 Benchmark functions of CEC2015 3.3.1 收敛性分析 文献[22]给出了烟花算法的马尔可夫过程收敛到最佳状态的充分条件,本文在此充分条件的基础上对GLFWA-CM算法的收敛性进行证明。 GLFWA-CM算法将烟花和各自产生的火花分为一组,选择时直接选择每组中最好的个体作为下一代烟花。每个被选择的烟花都继承了该组的搜索经验,能够不断在其附近区域进行探索,而不会突然跑到距离很远的区域去重新搜索,提高了搜索的效率。协方差变异在该组烟花搜索区域附近产生一个靠近更优解的火花,提升了每个小组找到最优解的概率。当产生的火花比烟花更好时,由于动态爆炸半径机制,烟花的爆炸半径会增大,这样使得算法前期有强大的全局探索能力。随着迭代过程的进行,每组烟花的搜索区域开发的越来越完善,找到的解也越来越好,某些烟花甚至已经找到自己搜索区域附近的局部最优解,陷入局部最优的状况。到了迭代后期,一些陷入局部最优或者进化速度太慢的非核心烟花,由于找到更优解的概率很低,那么就会在锦标赛精英学习策略的引导下,向找到更优解的核心烟花靠近,提高了核心烟花附近的搜索密度。由于核心烟花附近找到全局最优解的概率最大,所以GLFWA-CM 算法后期的开发能力很强。核心烟花在核心烟花更新信息的引导下,向着更有可能找到最优解的方向搜索,又进一步增加了算法找到全局最优解的概率。综合分析可知,GLFWA-CM算法前期探索能力不俗,后期开发能力很强。 表2 为各算法的实验结果在30 维情况下的平均值和方差对比,其中最好结果已加粗标出。从平均值指标来看,对于f1、f2、f6、f8、f10 测试函数,GLFWA-CM算法要优于参与比较的其他算法,而且比它们都至少要好1~2个数量级。对于f3、f9、f12、f13、f15 测试函数,GLFWA-CM 算法与其他算法性能持平。对于剩下的其他函数,GLFWA-CM 算法结果与最好结果基本都在同一个数量级。从方差指标来看,对于f1、f2、f6、f7、f8、f10、f15 测试函数,GLFWA-CM算法要优于参与比较的其他算法。综合来看,在低维条件下,GLFWACM和LoTFWA算法总体上优于其他算法,GLFWA-CM在单峰函数和混合函数上具有显著优势,LoTFWA在简单多峰函数和部分复合函数上具有一定优势。 表2 GLFWA-CM与其他算法的比较(D=30)Table 2 Comparison of GLFWA-CM with other algorithms(D=30) 图1(a)~(d)展示的是各算法在低维(D=30)情况下的收敛过程。其中,f1 函数是单峰函数,从收敛曲线图中可以看出,在迭代次数相同的情况下,与其他算法相比,GLFWA-CM算法收敛精度更高,而且它还有继续收敛的趋势;f3 函数是简单多峰函数,从收敛曲线图中可以看出,GLFWA-CM 算法收敛速度更快;f8 函数是混合函数,从收敛曲线图中可以看出,GLFWA-CM算法收敛精度相比于其他算法具有明显优势;f10 函数是复合函数,从收敛曲线图中可以看出,与其他算法相比,GLFWA-CM算法前期收敛速度与其他算法相当,后期,在其他算法收敛曲线趋于平缓时,GLFWA-CM 算法仍在缓慢收敛,而且收敛精度更高。综合来看,在低维情况下,GLFWA-CM 算法在收敛精度和收敛速度上都具有一定优势。 图1 8种算法求解测试函数f 1、f 3、f 8、f 10 的收敛曲线(D=30)Fig.1 Convergence curves of test functions f 1、f 3、f 8、f 10 solved by eight algorithms(D=30) 表3为各算法的实验结果在D=100 维条件下的平均值和方差的对比,其中最好数据已加粗显示。从表3中数据可以看出,在D=100 时,GLFWA-CM 算法在单峰函数,混合函数f6、f8 以及复合函数f9、f10、f12、f13 上均获得最优结果,在多峰函数和其他复合函数上也与最优结果相差不大。这说明GLFWA-CM算法解决高维问题时相较于对比的其他算法仍然有一定优势,体现了GLFWA-CM算法具有很强的适应性。对于多种不同类别和不同维度的问题都有很好的寻优能力。 图2(a)~(d)展示的是各算法在高维(D=100)情况下的收敛过程。从收敛曲线图中可以看出,在迭代次数相同的情况下,与其他算法相比,对于f1函数,GLFWACM 算法收敛精度更高;对于f3 函数,GLFWA-CM 算法收敛精度与其他算法相当,但是前期收敛速度明显更快;对于f8 和f10 函数,GLFWA-CM算法收敛精度相比于其他算法具有明显优势,在迭代后期,GLFWA-CM算法收敛速度也快于其他算法。说明在高维情况下,GLFWA-CM算法在收敛精度和收敛速度上仍然具有一定优势。 图2 8种算法求解测试函数f 1、f 3、f 8、f 10 的收敛曲线(D=100)Fig.2 Convergence curves of test functions f 1、f 3、f 8、f 10 solved by eight algorithms(D=100) 综合分析表2 和表3,GLFWA-CM 算法在单峰函数、混合函数和部分复合函数上效果很好,在多峰函数和部分复合函数上仅次于LoTFWA。 表3 GLFWA-CM与其他算法的比较(D=100)Table 3 Comparison of GLFWA-CM with other algorithms(D=100) 这主要是因为核心烟花更新信息引导策略和协方差变异方法都是在更可能找到最优解的方向产生火花,增大了算法找到最优解的概率,基于锦标赛的精英学习策略使得较差的烟花向核心烟花附近移动,进一步提高了核心烟花附近区域的搜索密度。所以在单峰函数和混合函数上,GLFWA-CM 算法优势显著。由于核心烟花更新信息引导策略对爆炸火花的多样性产生了一定影响,还有基于锦标赛的精英学习策略虽然显著加快了算法的收敛速度,但也牺牲了一定的探索能力,使得GLFWA-CM算法在多峰函数和部分复合函数这类看重全局探索能力的问题上,效果不如LoTFWA。但是由于GLFWA-CM算法采用了一种与LoTFWA相同的动态爆炸半径机制,能够有效避免GLFWA-CM 算法陷入成熟收敛,所以其结果也仅仅比LoTFWA 稍差,与其他烟花算法持平。 综合分析图1和图2,GLFWA-CM算法前期收敛速度最快,收敛精度最高,在迭代后期,GLFWA-CM 算法仍在缓慢收敛,而且收敛速度比其他算法更快。 这主要是因为核心烟花更新信息引导策略使得算法在更可能找到最优解的方向产生爆炸火花,提高了算法的收敛精度,基于锦标赛的精英学习策略使得较差的烟花向核心烟花附近移动,加快了算法向着最优解区域收敛的速度。所以在迭代前期,GLFWA-CM 算法无论是收敛速度还是收敛精度都是最好的。当算法找到一个局部最优解时,由于动态爆炸半径机制的作用,非核心烟花的爆炸半径会逐渐增大,扩大搜索区域,帮助算法跳出局部收敛,一旦找到更优解,其他烟花在锦标赛精英学习策略的引导下,也能逐渐跳出该区域,并能以较快的速度前往下一个核心烟花附近搜索,所以在迭代后期,算法仍能以较快的速度继续收敛。 3.3.2 稳定性分析 一般来说,在理论上能确保收敛的算法具有较高的稳定性。本文3.3.1 小节已对GLFWA-CM 算法的收敛性进行了证明,本文算法稳定性主要是通过李雅普诺夫稳定性理论[23]来分析的。 平衡状态:设某系统动态方程为: 式中,x为n维状态向量,且显含时间变量t,f(x,t)为线性或非线性,定常或时变的n维函数。对于所有t,满足 的状态xe称为平衡状态。平衡状态的各分量相对于时间不再发生变化。若已知状态方程,令X=0 所求得的解x,便是平衡状态。 李雅普诺夫意义下的稳定性: 设系统初始状态位于以平衡状态xe为球心,r为半径的闭球域S(r)内,即 若能使系统方程的解x(t:x0,t0) 在t→∞的过程中,都位于以xe为球心,任意规定的半径为ε的闭球域S(ε)内,即 则称系统的平衡状态xe在李雅普诺夫意义下是稳定的。 实数r与ε有关,通常也与t0有关,如果r与t0无关,则称平衡状态是一致稳定的。 渐近稳定性: 若系统的平衡状态xe不仅具有李雅普诺夫意义下的稳定性,且有: 则称此平衡状态是渐近稳定的。 证明GLFWA-CM算法平衡状态是一致渐进稳定的 由于GLFWA-CM 算法收敛,且最终会收敛于全局最优点xbest,根据文献[24]的证明,同理可证得全局最优点xbest为GLFWA-CM 算法在李雅普诺夫意义下的平衡点,f(xbest,t)为平衡状态。 设GLFWA-CM 算法的初始状态位于以平衡状态xbest为圆心,r为半径的圆S(r)内,圆S(ε)是以xbest为圆心,ε为半径的圆,圆S(ε) 与f(x) 相交于x3、x4,Dbest为最优区域,最两边的点为x1、x2,满足: 由GLFWA-CM 算法的收敛性可得当xi位于Dbest区域时,xi只会向着xbest靠近而不会远离。因此只要方程的初始解x(t0:x0,t0)位于Dbest区域内,即圆S(r)与目标函数相交的区域包含于Dbest区域,方程的解x(t:x0,t0)就只会向着xbest靠近而不会逃出半径为r的圆S(r),即 所以系统方程的解x(t:x0,t0)在t→∞的过程中,都位于以xbest为球心、任意规定的半径为ε的圆S(ε)内,因此当圆S(r)与目标函数相交的区域包含于Dbest区域时,即满足公式(26),GLFWA-CM算法的平衡状态xbest在李雅普诺夫意义下是稳定的。 所以对于任意一个实数ε>0,总存在一个满足式 (26)的实数r,使得由满足不等式‖x0-xbest‖≤r的任一初态x0出发的运动都满足不等式: 即方程的解x(t:x0,t0)始终都在圆S(r) 内。因此,圆S(r)的半径r与t0无关,所以GLFWA-CM 算法的平衡状态xbest是一致稳定的。又GLFWA-CM 算法必然可以收敛到全局最优: 所以此平衡状态是渐近稳定的。此时,从S(r)内某点x0出发的轨迹不仅不会超出S(ε),且当t→∞时收敛于xe,即xbest。所以GLFWA-CM算法的平衡状态xbest是一致渐进稳定的。综上所述,GLFWA-CM 算法的平衡状态xbest不仅是李雅普诺夫意义下稳定的,且平衡状态是一致渐进稳定的。 图3(a)~(d)展示的是30维情况下各算法独立运行20次得到的四种测试函数的箱型图(是一种用作显示一组数据分散情况资料的统计图,实线从上到下分别表示上边缘、上四分位数、中值、下四分位数、下边缘,空心圆圈表示异常值,叉号表示平均值)。为了便于观察,将所有数据都进行min-max标准化处理,使其分布在[0,1]区间内。f1 函数是单峰函数,f3 函数是简单多峰函数,f8函数是混合函数,f10函数是复合函数。在图2(a)~(d)中,GLFWA-CM算法的数据最小,而且最集中,图中五条实线基本成了一条直线。由于图中数据是根据适应度值得到的,所以图中数据越小,说明适应度值越小,算法的精度越高,图中数据越集中,说明数据波动越小,算法的稳定性越好。 图3 测试函数f 1、f 3、f 8、f 10 的箱型图(D=30)Fig.3 Box plots of test functions f 1、f 3、f 8、f 10(D=30) 3.3.3 算法复杂度分析 烟花种群规模为N,变异火花数目M=N,问题维数为D,最大迭代次数为Gmax,总的爆炸火花数目为S,S一般大于N。由于大部分复杂问题计算适应度值所花的时间要远大于一些简单计算的时间,所以分析算法的时间复杂度主要是分析计算适应度值的耗时。假设平均每次计算适应度值的时间消耗为O(f),每次迭代都要计算所有火花的适应度值,共迭代了Gmax次,所以总的时间消耗O(F)=Gmax×S×O(f)。除计算适应度值外,算法还有一些额外的时间消耗,主要是一些简单计算,下面是对这些额外开销的分析。 FWA 的额外计算开销主要产生在三个部分:一是爆炸算子,时间复杂度是O(Gmax×S×D);二是变异算子,时间复杂度是O(Gmax×N×D);三是选择算子,由于要计算候选者集合中每个个体到其他个体之间的距离之和,所以时间复杂度是O(Gmax×S2×D)。由于N一般远小于S,综上所述,略去低阶项,FWA 算法的额外时间复杂度为O(Gmax×S2×D)。 GLFWA-CM的额外计算开销也是主要产生在这三个部分:一是爆炸算子,时间复杂度是O(Gmax×S×D);二是变异算子,由于要计算协方差矩阵,所以时间复杂度是O(Gmax×S×D2) ;三是选择算子,时间复杂度是O(Gmax×S)。综上所述,略去低阶项,GLFWA-CM算法的额外时间复杂度为O(Gmax×S×D2)。 EFWA在选择过程中采用了一种新的选择策略,大大降低了计算量,选择过程的时间复杂度为O(Gmax×S),爆炸算子与变异算子的时间复杂度与FWA 一样,所以总的额外时间复杂度是O(Gmax×S×D)。 AFWA是在EFWA的基础上,对核心烟花的爆炸幅度进行了自适应调整,虽然计算量稍微增多,但是还是和EFWA 在同一个量级,总的额外时间复杂度还是O(Gmax×S×D)。 dynFWA 是在EFWA 的基础上对核心烟花的爆炸幅度进行了动态调整,同时,dynFWA 中还去除了变异算子这个步骤,所以变异算子的时间复杂度为O(0),所以总的额外时间复杂度是O(Gmax×S×D)。 CoFFWA是在dynFWA的基础上加入了独立选择和避免拥挤策略,选择过程的时间复杂度为O(Gmax×S),其他部分时间复杂度与dynFWA一样,所以总的额外时间复杂度为O(Gmax×S×D)。 CoFFWA-CM 是在CoFFWA 的基础上加入了协方差变异,协方差变异算子的时间复杂度和GLFWA-CM一样,所以总的额外时间复杂度为O(Gmax×S×D2)。 LoTFWA用引导火花代替高斯变异火花,时间复杂度为O(Gmax×S×D),爆炸算子时间复杂度是O(Gmax×S×D),在选择过程中采取了一种淘汰锦标赛策略,时间复杂度为O(Gmax×S),所以总的额外时间复杂度是O(Gmax×S×D)。 综合分析可知,在比较的八种算法中,计算适应度值的时间消耗都是O(F)。对于一些简单计算,FWA、CoFFWA-CM 和GLFWA-CM 的额外开销相对其他五种算法稍大。FWA 主要是选择过程计算开销较大,CoFFWA-CM和GLFWA-CM主要是产生变异火花过程计算开销较大。由于烟花算法的主要时间消耗还是O(F),这些简单计算的开销对算法时间复杂度的影响相对较小,所以在解决一些实际问题时,这些算法的实际耗时差距并不那么明显。 总的来说,虽然GLFWA-CM 算法的时间复杂度比除FWA和CoFFWA-CM以外的其他算法稍大,但是,在求解精度和稳定性上,GLFWA-CM 要优于其他所有烟花算法。 本文针对传统烟花算法中存在的寻优精度差,容易陷入局部最优等问题提出了一种基于锦标赛精英学习与协方差变异的烟花算法(GLFWA-CM)。该算法在爆炸算子中利用核心烟花更新信息确定核心烟花在每一维上的爆炸半径以及其火花分布,加强了每一代核心烟花之间的联系;在变异算子中用协方差变异代替了原来的高斯变异,使得变异火花分布在烟花附近的搜索区域,有效平衡了烟花算法的局部搜索和全局搜索能力;在烟花选择过程中加入了基于锦标赛的精英学习策略,有效改善了烟花算法收敛速度慢的问题。本文对GLFWA-CM 算法的收敛性和稳定性进行了证明,并通过一系列的实验表明,在低维和高维的情况下,GLFWACM算法均表现出不俗的性能,在算法的收敛性和稳定性上总体要强于其他比较算法。同时,分析得出GLFWACM 算法的时间复杂度比除FWA 和CoFFWA-CM 以外的其他算法稍大。综上所述,证明了本文提出算法的正确性、有效性和适用性。

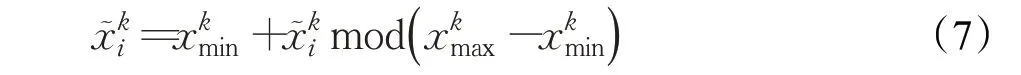
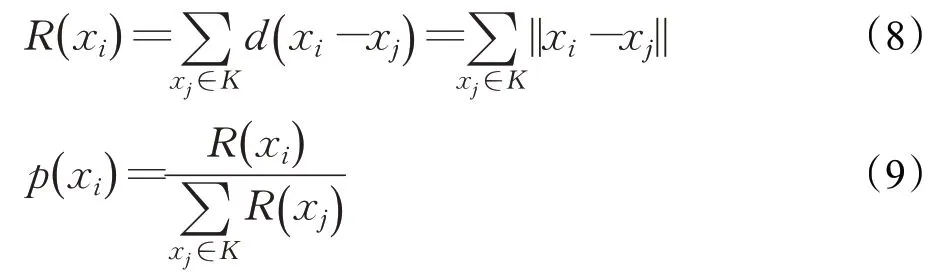
2 GLFWA-CM算法
2.1 爆炸算子



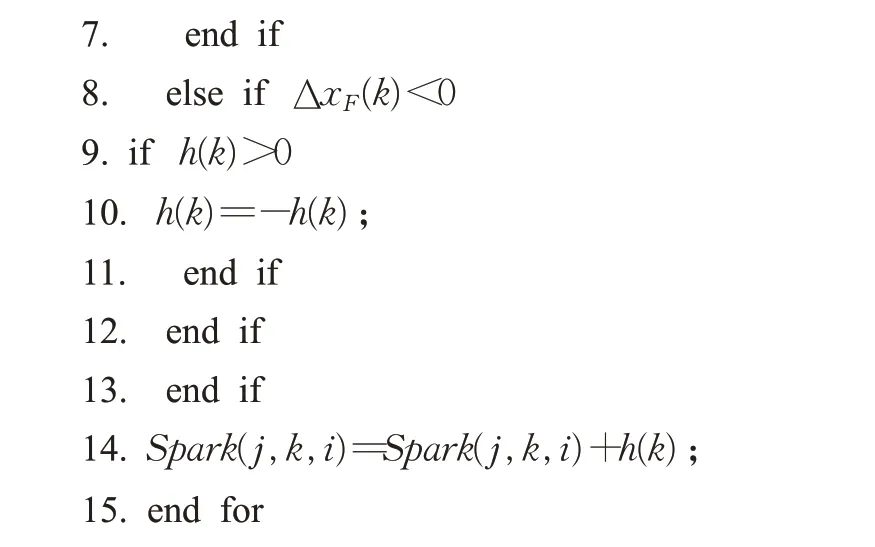



2.2 协方差变异算子

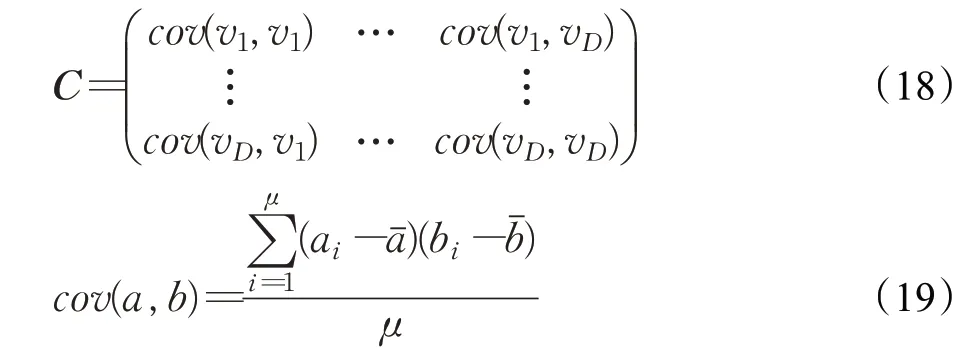
2.3 选择策略
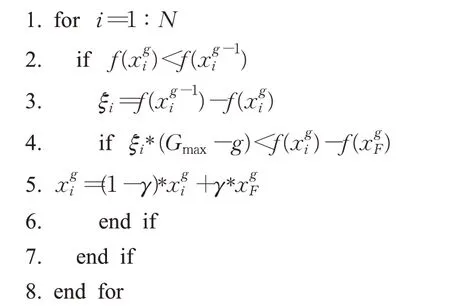
2.4 GLFWA-CM算法流程
3 实验分析
3.1 参数设置
3.2 测试函数

3.3 实验结果与分析







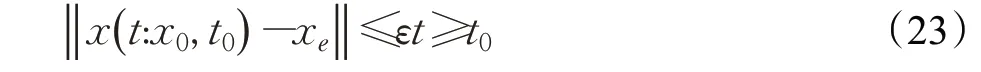





4 结语
