基于预测的5G网络切片算法
2021-10-14张佳庚祝敏杜丰王齐刘俊锁志海王力
张佳庚,祝敏,杜丰,王齐,刘俊,锁志海,王力
(1. 西安交通大学网络信息中心,陕西 西安 710054;2. 西安交通大学电子与信息学部,陕西 西安 710054)
1 引言
3GPP在5G网络组网协议中明确了5G网络架构,其最大的特点是采用基于服务的架构(service based architecture,SBA)架构,对应不同应用场景由网络切片选择功能(network slice selection function,NSSF)创建网络切片[1],如图1所示。网络切片中包括虚拟网元和虚拟链路,由虚拟链路负责将虚拟网元按照一定的拓扑连接,映射到实际的物理节点和物理链路上,完成网络切片的实例化,动态创建网络切片[2],网络切片不仅提升了5G网络资源分配的灵活性,同时也为网络的管理、控制提供了更大的空间。

图1 5G网络的SBA架构
5G网络切片的建立过程需要经历决策、资源隔离、虚拟网元拉起等过程,在决策阶段以资源分配算法,最优化网络切片到物理网络资源的映射,提升网络切片的接纳成功率和物理网络的资源利用率[3]。对应到5G网络的SBA架构,决策功能由NSSF根据当前实时的资源分布和网络切片的资源需求确定在哪些物理节点和物理链路上承载对应的虚拟网元和虚拟链路,资源隔离则由对应的物理节点和物理链路隔离出给定资源量的容器和虚拟路径,最后将虚拟网元的镜像装载进隔离出的容器内,拉起容器即完成了网络切片的创建。在上述过程中,资源隔离占用的时间最长,对于5G网络中要支持的实时应用场景来说,其要求的端到端时延小于1 ms。根据实时的资源需求动态创建网络切片带来的时延难以满足5G中的实时类业务应用场景。因此,基于预测的5G网络切片算法被提出,通过在网络中预留资源,提前完成资源隔离来减少动态创建网络切片的时间。
文献[4]提出使用最大相关熵准则(maximum correntropy criterion,MCC)作为代价函数预测微服务请求占用的资源,由于MCC需要计算真实值与预测值之间的相关熵,造成其计算复杂度过高。文献[5]提出使用核方法将互相关熵的计算过程从欧几里得空间等变换到再生核希尔伯特空间(reproducing kernel Hilbert space,RHKS),将高维乘法变换为低维加法,其采用的核函数为高斯核函数。核函数的选择将关系到预测算法的精度,而核函数又与实际的问题解空间分布强相关,使得核函数的选择成为预测算法的超参数,降低了算法的适用范围。
采用MCC作为代价函数的原因是MCC能够刻画数据的高维特征,具有较高的鲁棒性,不受非高斯、非线性噪声的影响。5G网络在实时场景下的资源请求和其应用场景强相关,在给定的无人驾驶、工业控制的场景下,其噪声虽然有高维特征,但是可以使用高阶矩来滤除,没有必要使用无限高维特征描述。在5G网络实时场景的资源请求样本中,几乎不会出现高于4阶的噪声,代价函数中包括过高的阶数,不仅对预测精度没有促进作用,反而会增加算法的复杂度。因此,本文提出5G网络中基于预测的微服务实例化算法,使用四阶矩作为预测算法的代价函数,消除高阶噪声的影响。以较低的算法复杂度提供可接受的预测精度,提前在网络中隔离对应的资源,降低网络切片实例化的时间。
2 四阶矩代价函数
高阶矩一般被使用在AFA(adaptive filtering algorithm)[6-7]、回声消除[8-9]、主动噪声抑制[10-11]等领域。在高阶矩中,典型的有归一化NLMS(normalized least mean square)、归一化LMF(normalized least mean fourth)。相对于归一化LMS,归一化LMF能够处理非高斯噪声[12-13],因此,各种变种的归一化LMF被提出,如稀疏LMF[14-15]、扩散LMF[16-17]等。近年来,比例归一化LMF(proportionate normalized LMF,PNLMF)在文献[18-19]中被提出,用于在迭代训练的过程中成比例地修改训练误差,独立更新系统的各个参数[20]。
以上文献中提出的以四阶矩为代价函数的算法要求训练样本的噪声服从同一分布。但5G网络实时场景下的资源请求训练样本中的噪声不服从同一分布,使得上述算法性能大大下降。因此,基于非偏估计的残差补偿AFA算法被提出,如基于残差补偿的归一化LMS(bias-compensated NLMS)[21-22]、仿射投影算法(affine projection algorithm,APA)[23]、基于非偏估计的APA算法[24]、残差补偿归一化子带滤波算法[25]、基于残差补偿的归一化LMF(bias-compensated NLMF)算法[26]等,文献[27]在文献[21-22]的基础上,在代价函数中加入l0正则化项,提升预测算法的泛化能力。
2.1 预测问题的输入和输出
由于5G网络实时场景下的资源请求与人的行为强相关,而人的行为存在非常大的不确定性,不能使用上述文献提出的算法进行处理,因此本文将残差补偿和非偏估计用于PNLMF算法中,解决5G网络实时场景下资源请求的预测问题。
将每个网络切片请求的资源作为回归预测的值。此时,每个网络切片请求的资源定义如下:

其中,α、β、γ分别表示CPU、内存、带宽资源的等效权重,I表示网络切片请求中的虚拟网元个数、J表示请求中的链路条数。此时,网络切片请求的等效资源就是回归问题的输出。
对于任意一个网络切片请求i,根据其包含的L个特征,文献[5]中将回归问题的输入定义如下:

d(i)作为输出值,定义为网络切片请求中包括的总资源量。表示如下:

此时,系统的预测误差为:

w(i)=[w1(i),w2(i),…,wL(i)]T表示对应任意一个网络切片的资源请求样本,训练完回归模型后对应的模型参数。
回归模型的更新过程如下:

其中,μ表示步长;η>0为正则化参数;为每次更新过程中更新步长过程中使用的对角阵。在上述对角阵中
ρ和ξ的典型取值为ρ=5/L,ξ=0.01,且都大于0。ξ用于wl(i)的初始化,保证其能够得到快速更新,ρ用于保证任意wl(i)在进化时如果其值远远小于wl(i)的最大值时,能够得到更新。
不失一般性,系统的输出信号包括实际输出信号和噪声,定义如下:

n(i)=为实际输出信号,其中nl(i)(l∈[1,L])是均值为0、方差为的高斯噪声。此时,将输出信号记为:

结合文献[6]和上述计算式,对系统的输出做有偏估计,并将式(3)定义为B(i),使用和更新u(i)和e(i)并代入式(7),得到:

在此基础上,定义权重误差为:

为了保证B(i)可解,提出以下假设。
假设1误差信号n(i)和输入信号u(i)相互独立。
假设2n(i)和u(i)不相关。
假设3权重序列(i)中的权重相互之间独立。
假设4(i)和(i)相互独立。
代入式(7)、式(8),得到式(10):

为了计算B(i),根据文献[23],当时,得到所提代价函数的无偏估计,如下:

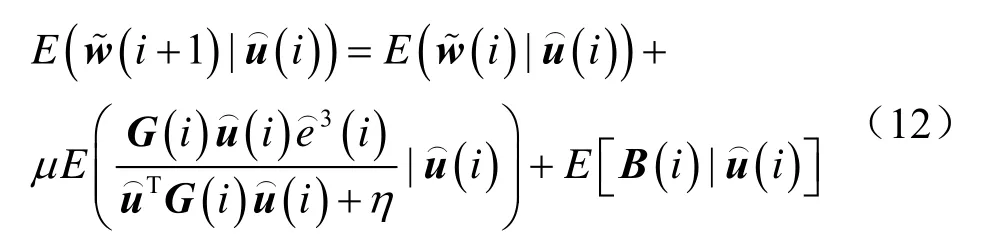
根据式(11)和式(12),得到如下结果:
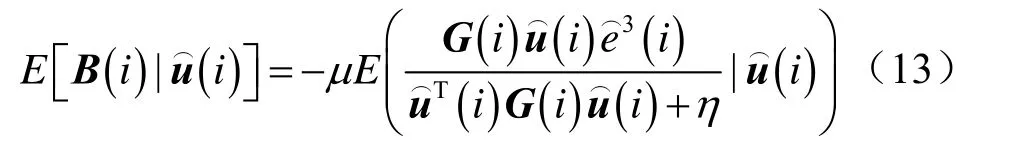
将式(6)和式(7)代入式(13),得到如下结果:

在假设1和假设2的条件下,修改式(13),得到:
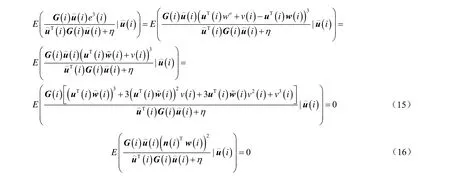

由于采用了四阶矩作为代价函数,文献[12-13]中使用归一化LMF处理高斯噪声的方式,定义噪声的误差为,得到其平方,并将其代入式(15)~式(17),得到如下结果:

利用文献[23]中的统计近似方法,得到:

将式(19)代入式(10),得到将四阶矩作为代价函数时的权重更新公式如下:

2.2 噪声信号的均方误差估计
文献[21-23,25-27]提出了很多针对噪声信号的均方误差评估方法,而在解决实际问题时,需要根据样本的特征选择不同的噪声估计方法,保证较高的噪声估计精度。如果噪声误差估计过高,会减弱小于请求资源量期望的样本的作用;反之,如果噪声误差估计过低,则预测模型的精度受噪声的影响较大。
由于5G网络实时应用场景的资源请求中噪声与用户的行为强相关,表现为用户的某些随机申请5G网络资源的行为,这会影响网络切片请求的资源量的统计规律,无法进行准确的描述。
文献[27]中的噪声信号均方误差评估方法考虑了输入输出噪声的相关性,在应用于解决本节所提持久型微服务请求资源量的预测问题时,可以抵消噪声误差在输入和输出上的作用;同时,遗忘因子的引入,也给调整噪声估计结果提供了超参,通过设置合适的遗忘因子,缩小噪声信号均方误差的评估结果。因此,本节采用文献[27]提出的方法对噪声的均方误差进行估计。
文献[27]中定义的噪声均方误差如下:
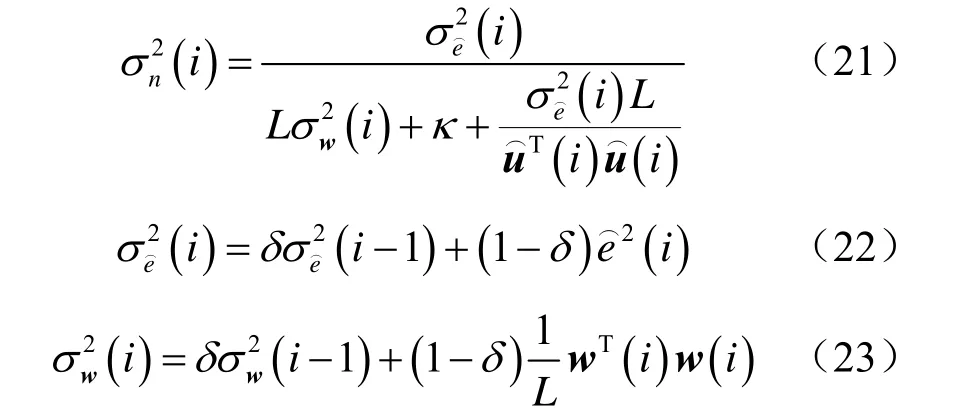
在式(20)和式(21)中,参数δ为遗忘因子,κ为输入输出噪声相关参数。此时,式(20)可以改写为:
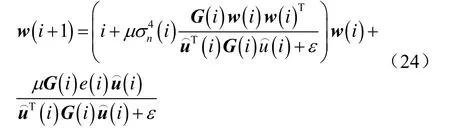
此时,基于四阶矩的代价函数进行权重估计时,采用算法1进行更新。
算法1
初始化w(0)=0
定义的参数包括:μ,,ερ,ξ,δ,κ
针对任意一次迭代i:
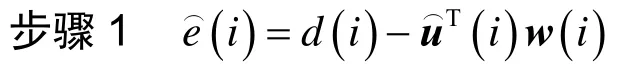

3 基于四阶矩预测的网络切片算法
3.1 基于预测的网络切片算法
基于预测的网络切片算法流程如图2所示。
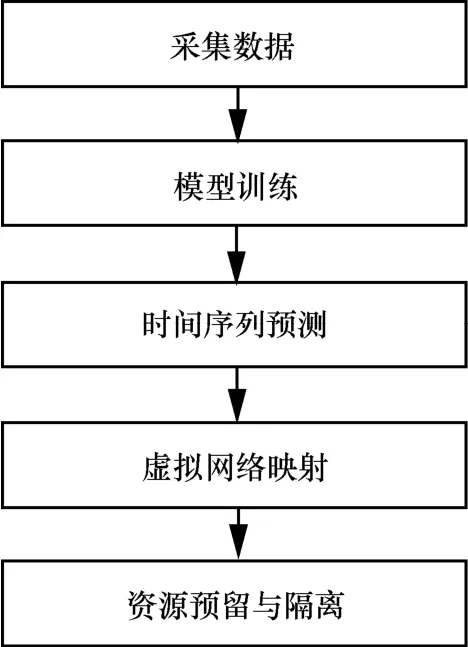
图2 基于预测的网络切片算法流程
步骤1采集历史样本,包括一个星期内所有5G实时应用场景下的网络切片请求资源量。
步骤2根据历史样本训练,其代价函数为本文定义的四阶矩,训练算法采用BP神经网络,训练后得到预测模型。
步骤3将5G网络实时应用场景下的请求资源量看作时间序列,预测下一时刻的网络切片请求资源量。
步骤4使用文献[28]提出的虚拟网络映射算法,确定承载下一时刻网络切片请求资源量的物理节点和物理链路。
步骤5在确定的物理节点和物理链路上预留给定的资源,完成虚拟节点和虚拟链路隔离。
3.2 算法复杂度分析
由于本文使用BP神经网络训练预测模型,预测算法的时间复杂度与每次训练的样本个数、计算梯度时的复杂度、迭代次数相关。在预测算法使用了mini-batch方法进行训练,每次mini-batch训练时使用的样本个数为样本总数的一部分。
使用BP神经网络进行训练,每次更新进行权重更新时的复杂度分析如下:
假设神经网络有d个输入神经元,l个输出神经元,J个隐藏层,每个隐藏层中包括qj个神经元,第j个隐藏层中第h个神经元的阈值为γjh。其中,输出层中第j个神经元的阈值为jθ,输入层第i个神经元与第一个隐藏层中第h个神经元的连接权重为vih,最后一个隐藏层中第h个神经元与输出层第j个神经元之间的连接权重为whj。
记最后一个隐藏层中第h个神经元接收到的输入为,输出层第j个神经元接收到的输入为,并且记第i个隐藏层的第h个神经元与第i+1个隐藏层中的第j个神经元之间的连接权重为。
除了上述权重外,还需要确定每个隐藏层和输出层的阈值,其个数为:。因此,总的参数个数为
在计算每个需要迭代计算的权重的时间复杂度时,记每个训练样本(xk,yk)的输出为则四阶矩代价函数为:使用梯度下降法进行权杖更新,以η为学习率,则:
将每次权重更新时的代价定义为C,
其中,l表示输出层包括的神经元个数;d表示输入层包括的神经元个数;qj表示第j个隐藏层中包括的神经元个数。
每次权重更新时的代价定义为C可以改写为:即整个网络中包括的神经元的个数。
整个预测算法的时间复杂度与迭代次数、训练时使用的样本个数、使用梯度下降法更新权重时的计算复杂度相关,因此,基于四阶矩的预测算法的时间复杂度为O(I×n×C),其中,I表示神经网络训练时的最大迭代次数;n表示每次输入神经网络中进行mini-batch训练时的样本个数;C表示使用梯度下降法进行权重更新时的计算复杂度。
由于在训练过程中每次迭代后都需要保存样本、权重,因此预测算法的空间复杂度为:其中,K表示样本的维度,为自变量的维度和因变量的维度之和;N表示样本的个数;in表示每层神经网络的节点个数,由于每个节点需要保存ω和b两个参数,则每个节点的空间复杂度为2×in;n^则是每层神经网络的平均节点个数;l为神经网络的层数。
4 实验结果与分析
4.1 预测算法的性能分析
为了分析所提算法的预测准确度和稳定性,以30天的5G网络实时应用场景下资源请求数据作为训练样本,并且在所提算法和对比算法中,设置规则化参数η=0.0001、ξ=0.01、κ=0.0001、δ=0.7。为了分析所提算法的性能,将其与对比算法进行性能分析,对比算法包括:文献[10]提出的NLMS算法、文献[11]提出的NLMF算法、文献[18]提出的PNLMS算法、文献[19]提出的PNLMF算法、文献[26]提出的BCNLMF算法,本文所提算法被标记为BCPNLMF算法,即使用残差补偿和非偏估计的PNLMF算法。
在实验过程中,将所采集的样本中70%作为训练集,其余30%作为测试集。在测试集中对所提算法和对比算法的效果进行分析和比较。
4.1.1 MSD分析
为了分析所提算法,使用均方误差(mean square deviation,MSD)对所提算法与对比算法在给定的样本集下进行训练并分析其性能。所提算法和对比算法具有相同的四阶矩代价函数,对比算法包括NLMS、PNLMS、NLMF、PNLMF和BCNLMF。文献[25]中对MSD的定义如下:

训练后得到的系统模型的稀疏度定义如下:

其中,Nnon-zero是训练所得系统模型中非零的系数,仿真过程中,将其设置为4/50。
本文所提算法与对比算法在相同收敛速度下的MSD分析如图3所示。从图中可以看出,所提算法与对比算法相比,其MSD最小,在预测时相比较于其他算法误差最小。
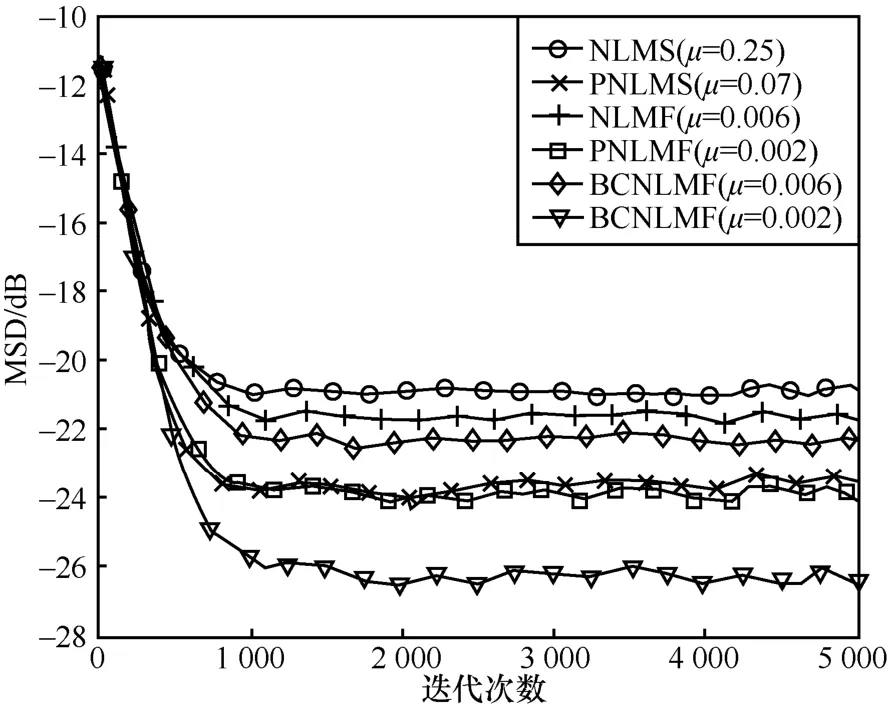
图3 相同收敛速度下本文所提算法与对比算法的MSD分析
在获得给定MSD条件下,本文所提算法与对比算法的收敛速度分析如图4所示。从图4中可以看出,所提算法的收敛速度更快,这是因为在训练过程中使用得分矩阵进行了参数更新。
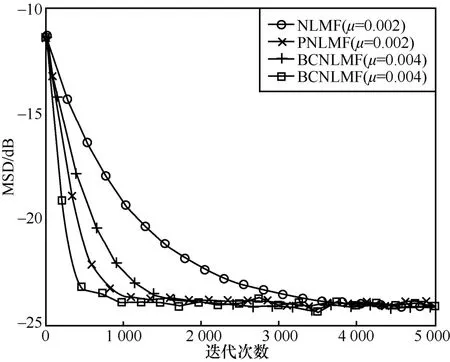
图4 获得相同MSD时本文所提算法与对比算法的收敛速度分析
4.1.2 SR对MSD的影响
在所提算法和对比算法中对SR进行调整,随着算法迭代将其从2/50调整到5/50,观察SR随着迭代变化时对算法MSD参数的影响。图5所示为不同SR值随迭代变化对MSD的影响。

图5 不同SR值随迭代变化时对MSD的影响
从图5中可以看出,SR随着迭代次数进行变化时,本文所提算法与对比算法相比,其MSD仍然是最小的,说明所提算法更加稳定,能够获得更小的预测误差。
通过上述实验结果分析,本文所提算法与对比算法相比,能够获得更好的预测精度,保证预测结果与测试集的对应样本的误差的标准方差最小,并且本文所提算法能够获得最快的收敛速度和最佳的稳定性。
4.2 基于预测的5G网络切片算法分析
4.2.1 网络环境设计
物理节点属性包括CPU核数、内存大小,链路属性包括带宽。仿真实验中的物理节点数量服从(100,1 000)之间的均匀分布,每个物理节点上的CPU核数为集合(16,32,64)上随机选择的数值,选择的每个数值的概率服从均匀分布。每个物理节点上的内存为集合(128,256,512)上随机选择的数值,选择每个数值的概率服从均匀分布,内存的单位是MB。物理链路均为10 GE带宽,提供10 Gbit/s的传输能力,物理节点之间是否连接的概率服从参数为0.1的负指数分布。
网络切片的资源请求包括虚拟网元个数、每个虚拟网元包括的CPU核数和内存请求,连接每个网元的传输带宽,其表现形式为物理承载环境的一个子网。其中,虚拟网元的个数服从(5,10)之间的均匀分布,每个网元请求的CPU核数服从(2,5)之间的均匀分布,每个网元请求的内存数从集合(8,16,32)中选择,选择的每个数值的概率服从均匀分布,单位为MB。微服务请求中每个网元之间连接的概率服从参数为0.1的负指数分布,且请求的带宽服从(10,100)之间的均匀分布,单位为Mbit/s。
网络切片请求的时间间隔服从参数为μ的均匀分布,如果网络切片被成功接纳并实例化,其存在的时间服从参数为β的负指数分布;如果被拒绝,则直接丢弃不排队。此时,物理承载环境中的负载近似为
在文献[28]的基础上使用本文所提预测算法,完成网络切片的资源预留,考查所提算法与文献[28]的阻塞率、剩余资源分布、收益和网络切片的实例化时间。文献记为“粒子群算法”,本文所提预测算法与文献[28]中所提网络切片实例化算法记为“粒子群+预测”。
4.2.2 实验结果分析
(1)阻塞率分析
本文所提算法与对比算法的阻塞率分析如图6所示,在增加了所提的基于预测的网络切片算法后,在给定负载条件下,本文所提算法与对比算法的效果大致相当,这是因为本文所提算法只是提前预留一部分资源,相当于提前为一部分网络切片请求分配资源。随着负载的增加,本文所提算法与粒子群优化算法都出现了阻塞率升高的情况,并且升高的程度大致相当。

图6 基于预测的微服务实例化算法的阻塞率分析
随着预留资源的网络切片个数的增加,对于本文所提基于预测的网络切片算法,其阻塞率基本没有变化。
(2)剩余资源分布分析
本文所提算法与对比算法的剩余资源分布分析如图7所示,本文所提算法与对比算法相比,其剩余资源分布差别不大,这是因为所提算法只是使用了对比算法提前为一部分网络切片请求分配资源,还是以网络切片请求被实例化后物理承载环境中剩余资源分布更均匀为优化目标。并且随着负载的增加,本文所提算法与对比算法都会使阻塞率增加。

图7 基于预测的微服务实例化算法的剩余资源分布分析
随着预留资源的网络切片请求的个数的增加,对于本文所提算法,物理承载环境中剩余资源分布基本没有变化。
(3)收益分析
本文所提算法与对比算法的收益分析如图8所示,与阻塞率和物理承载环境的剩余资源分布情况类似,本文所提算法与对比算法相比,收益基本相当。并且随着负载的增加,本文所提算法的收益相比于与对比算法,其增加的趋势和幅度基本一致。并且随着预留资源的网络切片的个数的增加,对于本文所提算法,其收益也基本没有变化。
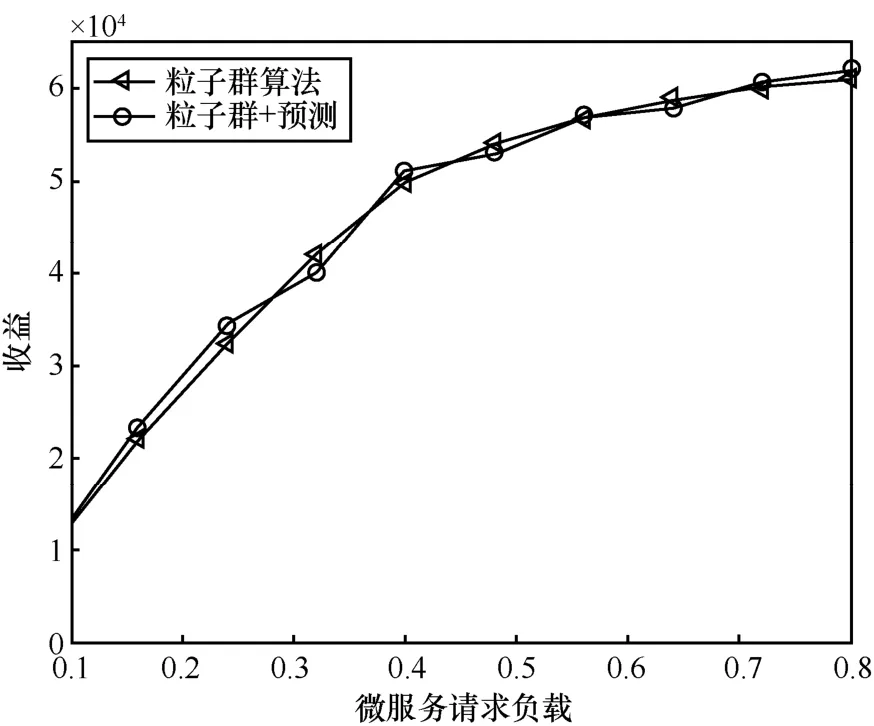
图8 基于预测的微服务实例化算法的收益分析
(4)实例化时间分析
网络切片实例化的时间包括算法执行时间、资源准备时间、资源分配时间,具体定义如下:

其中,算法执行时间远远小于资源分配时间,相比可以忽略不计。而对于网络切片请求来说,如果包括的节点和链路越多,每个节点和链路上请求的资源越多,其资源准备时间越长,并且资源分配时间与资源准备时间呈正向线性相关关系,即资源准备时间越长,资源分配时间越长。表1为所提算法与对比算法的实例化时间对比。
从表1中可以看出,本文所提算法与对比算法相比,能够显著降低网络切片的创建时间,根本原因是新创建的网络切片复用了原始网络切片的资源,即原来的网络切片结束服务后只释放了资源,而没有销毁容器,新创建的网络切片直接复用原始网络切片释放的容器,省去了创建容器的时间。而创建容器的时间在网络切片实例化过程中所占比重最大。

表1 网络切片的实例化时间分析(平均微服务请求数:30)
因此,本文所提算法对于减少网络切片请求的实例化时间贡献最大,从仿真结果上看,本文所提算法能够将网络切片的实例化时间减少50%。并且随着预留资源的网络切片请求个数的增加,其建立时间降低得更多。这是因为预留资源的网络切片请求数越多,越能够节省更多的网络切片实例化时分配资源的时间。
此外,如图9所示,网络切片请求中的虚拟网元个数越多,其平均资源准备时间越长,这是因为在承载原虚拟网元请求的容器上需要回收垃圾,重新在容器中装载新的虚拟网元请求,才能实例化新的网络切片。而回收垃圾和装载新虚拟网元的时间与虚拟网元请求的个数成正比。

图9 网络切片实例化时间网络切片请求平均节点个数的变化曲线
5 结束语
本文提出一种5G网络中基于预测的微服务实例化算法。将四阶矩作为代价函数,使用BP神经网络训练得到预测模型。根据预测模型的输出在5G网络中提前隔离资源,当网络切片请求到达时,直接拉起容器、隔离虚拟链路,完成网络切片的动态创建,可以将网络切片的创建时间减少50%。对5G网络中实时应用场景下的网络切片创建方法具有一定的参考价值。
