空间和通道注意力多级别特征网络图像语义分割
2021-10-14宣明慧张荣国李富萍
宣明慧,张荣国,胡 静,李富萍,赵 建
(太原科技大学 计算机科学与技术学院,太原 030024)
传统的图像分割方法有基于阈值、基于边缘和基于区域等,这些方法的分类依据是颜色和纹理等底层特征,而非语义特征,而图像语义分割是对每个像素点赋予语义含义,是场景理解的基础性技术。
近年来,随着数据集和GPU 的不断发展和完善,卷积神经网络在训练大量数据学习特征上表现出了很大的优势。全卷积神经网络(FCN)[1]在图像识别任务的基础上,去掉最后的全连接层,对每个像素点属于哪一个语义标签产生一个预测概率,FCN将图像分类问题转换成了像素点分类问题,是深度学习技术在图像语义分割任务上的开端,但是FCN仍然存在相同语义类分割不紧凑,不同语义类分界不明显的问题。DeepLab V1[2]根据目标的大小来调整空洞卷积的空洞率,以达到调整感受野的目的。文献[3]引入通道注意力机制,根据从高级特征中获得的全局上下文信息将注意力集中到图像的特定内容,结合金字塔结构,不需要使用复杂的空洞卷积就可以提取密集特征,是一种新的特征融合方式。SegNet[4]引入编码器-解码器思想,在解码器阶段使用最大池化索引对特征图进行上采样。
图像语义分割模型在提取高级特征的过程中由于不断的下采样导致空间位置丢失,导致语义分割的效果较差,因此如何将具有空间信息的低级特征与高级特征进行融合成为研究的重点。针对该问题,本文提出联合空间注意力模块和通道注意力模块融合并行路径多级别特征的方法,以提高小目标物体的分割效果。
本文主要有以下3方面的贡献:
(1)给出了一个空间注意力模块,针对具有丰富位置信息的低级别特征图,提取空间注意力矩阵来指导缺乏位置信息的高级特征图;
(2)将提出的空间注意力模块联合通道注意力模块,以融合具有不同级别特征的并行路径;
(3)所提的利用空间和通道注意力模块融合多级别特征构造学习网络的方法,对于小目标和边界具有良好分割效果。
1 相关工作
1.1 注意力机制
CBAM[5]在通道注意力的基础上引入空间注意力,结合了空间注意力和通道注意力机制;DANet[6]提出了一种新颖的对偶注意力网络,利用通道注意力模块学习通道之间的相关依赖性,利用位置注意力模块学习特征的空间依赖性,两个模块并行分布最后进行加和。
1.2 空间信息
针对空间位置信息大量丢失的问题,BiSeNet[7]引入空间路径,保持较高分辨率,保留更多的小目标和边界信息;DeepLab V1[2]模型引入空洞卷积解决高级特征位置信息大量丢失的问题。
2 本文方法
基于BiSeNet[7]的双通道和CBAM[5]的空间注意力思想,本文提出利用空间注意力模块(SAM)和通道注意力模块(CAM)来融合具有低级别特征的空间信息路径和具有高级别特征的语义信息路径。
2.1 通道注意力模块(CAM)
通道注意力模块:在卷积神经网络中,每一层网络会产生多个通道,若给每个通道上的信号都增加一个代表该通道与关键信息相关度的权重,那么权重越大,则表示相关度越高,借鉴文献[5]的思想,本文的通道注意力模块同时使用全局平均池化和全局最大池化来获得最终的通道注意力向量,对语义信息路径上的每层特征图提取通道注意力向量,将提取到的通道注意力向量作用于语义信息路径的相应特征图上,确定每层特征图上需要重点关注的内容。通道注意力模块如图1所示。
通道注意力模块可用公式(1)表示:
(1)
公式(1)中的XSE表示语义信息路径中每层输出的特征图,也是通道注意力模块的输入特征图,CA(XSE)表示对特征图XSE提取通道注意力向量。
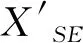
语义信息路径:图1中的语义信息路径采用预训练模型Resnet101作为主干网络,如表1所示,2X、4X、8X、16X、32X分别表示2倍、4倍、8倍、16倍、32倍下采样。

表1 语义信息路径网络结构列表
2.2 空间注意力模块(SAM)
空间注意力模块:考虑到图像中空间位置信息的重要程度不同,本文引入空间注意力模块,借鉴文献[5]的思想,本文的空间注意力矩阵是在通道轴上联合使用平均池化和最大池化获得最后的空间注意矩阵,对具有丰富位置信息的空间信息路径上的特征图提取空间注意力矩阵,将提取到的空间注意力矩阵作用于语义信息路径的相应特征图上。空间注意力模块如图2所示。
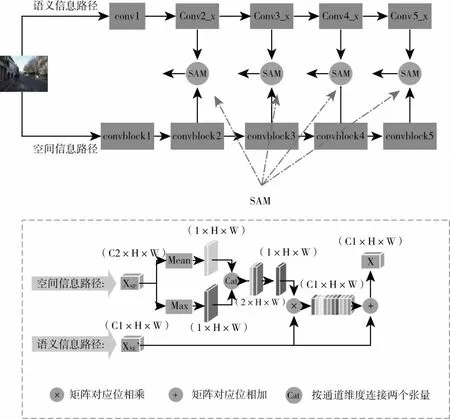
图2 空间注意力模块
空间注意力矩阵可用下面的公式表示:
(2)
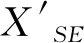
空间信息路径:图3中的空间信息路径主要包含5个卷积层以及对应的Batch Nornalization层、ReLU层,如表2所示。

表2 空间信息路径网络结构列表
2.3 网络架构
如图3所示,首先针对具有高级别特征的语义信息路径引入了通道注意力模块,在Resnet101提取的特征图上,显式地建模通道之间的相互依存关系,确定每层特征图上需要重点关注的内容;其次针对具有低级别特征的空间信息路径引入空间注意力模块,在保留了丰富空间信息的特征图上提取空间注意力矩阵,并将提取的空间注意力矩阵作用于语义信息路径相应特征图,以确定需要重点关注的位置。
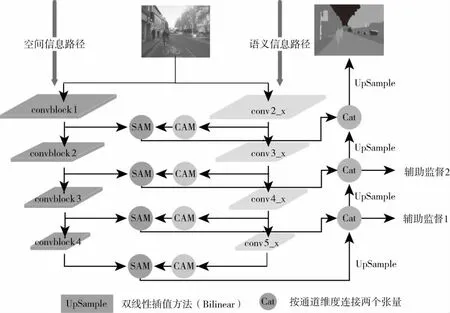
图3 网络概述图
额外监督:在主监督的基础上加入两个辅助监督,采用交叉熵函数计算损失。
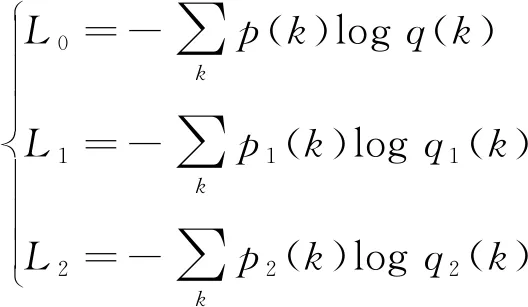
(3)
公式(3)中的p和q分别是网络的最终输出预测图中像素点的预期输出和实际输出,p1和q1、p2和q2分别是第一次、第二次进行上下级特征融合后输出的特征图中像素点的预期输出和实际输出。
Loss=l0+l1+l2
(4)
2.4 实现细节
SGD优化器:初始学习率为0.1,动量为0.9,为了防止过拟合,设置权重衰减率为5e-4.
(5)
公式(5)中Loss为模型的初始损失函数,N为样本数,λ是正则项系数也就是权重衰减率,W为网络中权重参数。权重更新方式为:
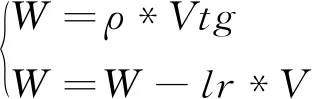
(6)
公式(6)中,W代表网络中权重参数,V代表速率,g代表梯度,ρ代表动量,lr表示学习率。
3 实验结果与分析
CamVid数据集的实验环境是网上服务器GeFore RTX1080Ti,10G显存。CamVid数据集共有701张城市街道图,本文对数据集进行处理,将其中的421张作为训练集,112张作为验证集,168张作为测试集,共有建筑物、行人、路面、围栏、汽车、自行车手、树、杆、指示牌等11个语义类,将图像剪裁为352*352,批次大小设为5.
3.1 消融实验与分析
为了验证本文方法的有效性,设计了一种对比实验。依次从语义信息路径的每一层的特征图中提取通道注意和空间注意,然后对特征融合进行上采样,对于具有在空间信息路径上具有位置信息的特征图,不提取空间注意矩阵。
从表3可以看出,文本方法优于对比方法。从图4可以看出,本文方法对人行道,建筑物,道路,汽车和树木等具有良好的分割效果。
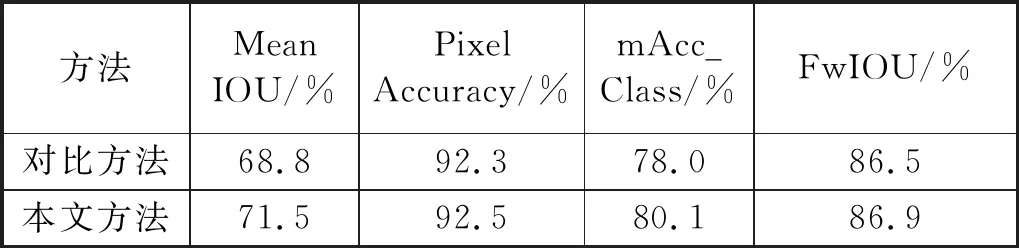
表3 CamVid测试集上对比实验结果

图4 CamVid测试集可视化效果图
3.2 与其他语义分割方法的对比分析
表4给出了本文方法与8种现有方法在11个语义类上的对比结果。观察表4中的数据,本文方法在自行车,建筑,标志符号等7个语义类上的精度都高于其他方法。在道路,行人,柱杆和天空等4个语义类上,本文方法精度稍低,但仍高于其他大部分方法。从整体指标mAcc_class可以看出,本文方法在这11个语义类上具有良好的性能。
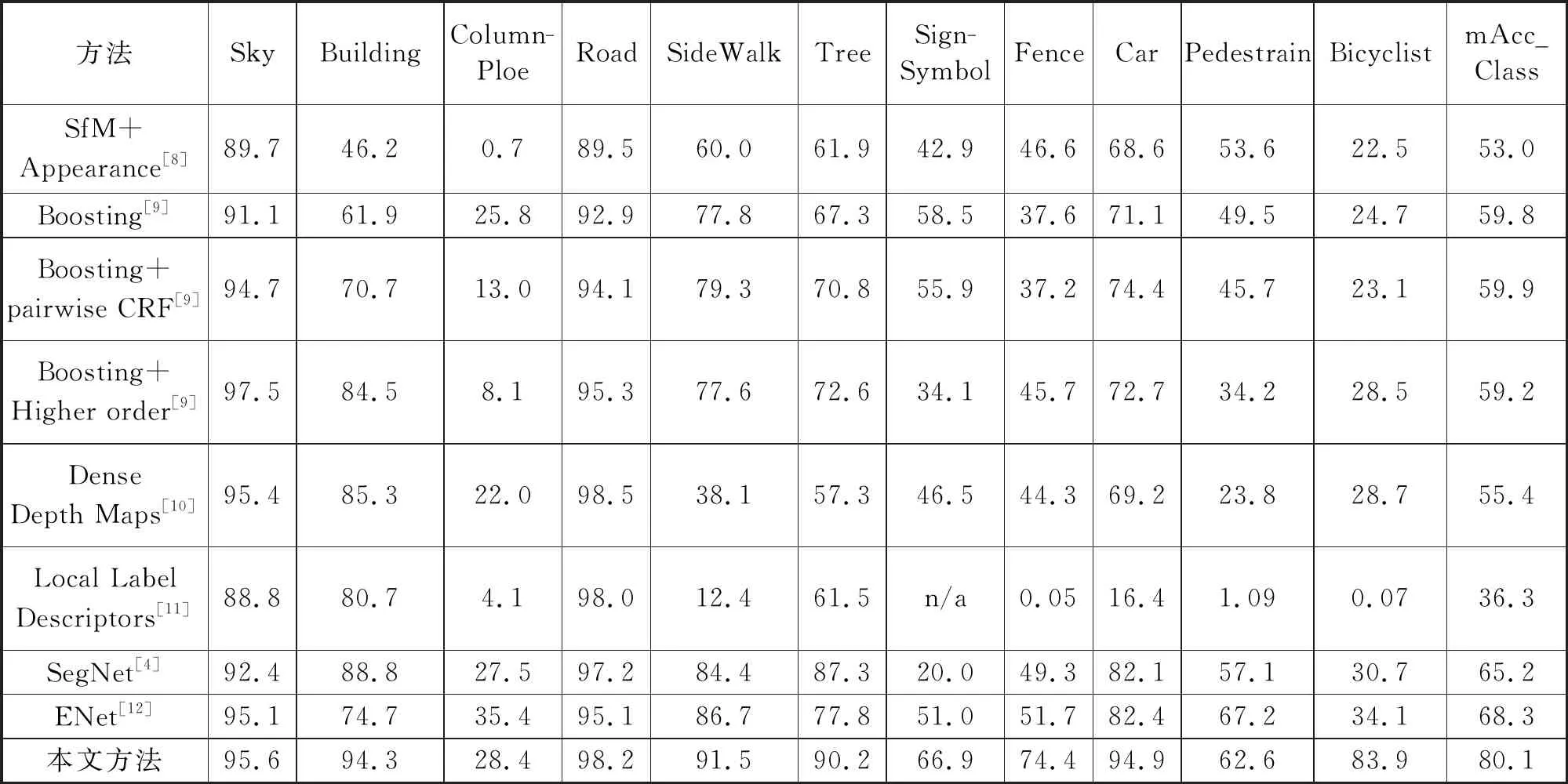
表4 各类方法在CamVid测试集11个语义类上的结果对比
本文方法与10种现有方法在CamVid测试集进行对比。实验结果如表5所示,在Mean IOU和Pixel Accuracy两个评价指标上,本文方法高于其他10种现有方法。
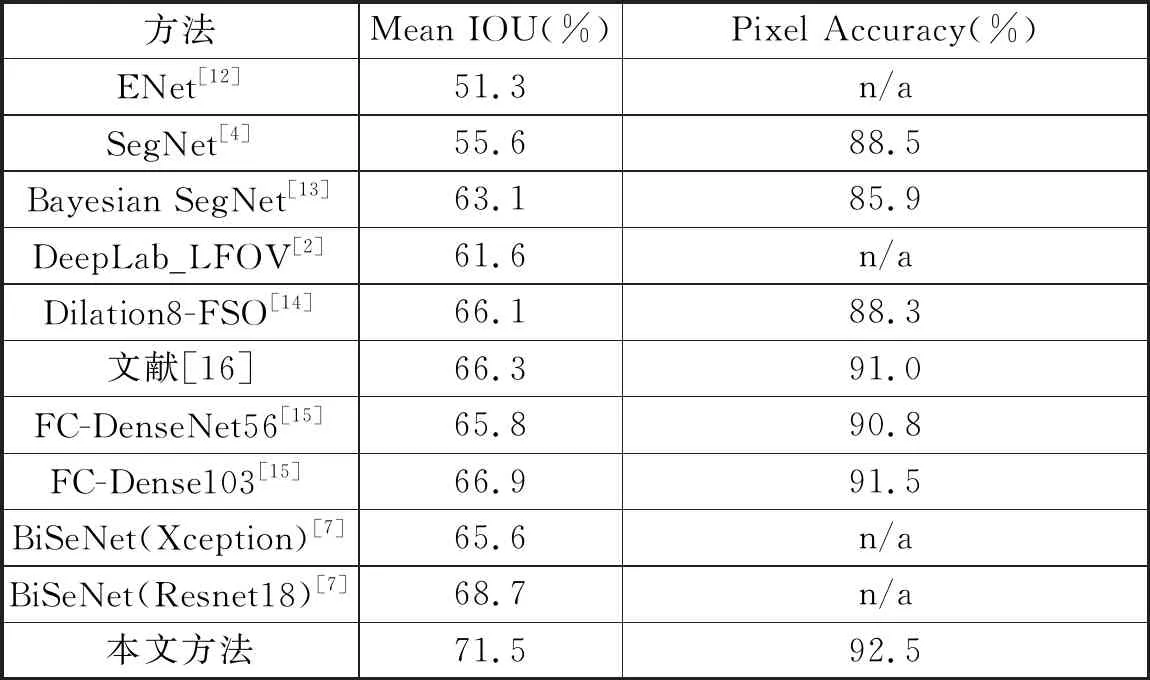
表5 各类方法在CamVid测试集上的结果
4 结论
针对空间信息丢失和复用问题,本文提出的融合空间和通道注意力多级别特征的图像语义分割模型,保留了丰富的空间信息,并通过通道注意力模块和空间注意力模块对特征图进行了融合,提高了目标物体的分割精度。但由于自动驾驶领域对于图像语义分割具有实时性要求,因此接下来将在降低模型复杂度和提升实时性方面进行研究和探索。
