采用高光谱图像深度特征检测水稻种子活力等级
2021-10-12武小红沈继锋戴春霞
孙 俊,张 林,周 鑫,武小红,沈继锋,戴春霞
(江苏大学电气信息工程学院,镇江 212013)
0 引 言
水稻是中国主要的粮食作物之一,其种植面积大约在3 000万hm2,年产量在2亿t左右[1-2]。水稻种子是水稻产量和品质的决定性因素,也是农业生产的源头。种子活力决定水稻种子能否正常发芽,出苗整齐程度以及最终长成的植株的抗病害能力等,常用作评价水稻种子品质的关键性指标[3]。因此,在水稻种子的播种之前对其活力进行准确检测,有效筛选高活力的水稻种子用于种植,可以大幅度提高水稻的产量以及品质,从而保障粮食安全[4]。
依靠人感官并基于种子外部特征如颜色、纹理和形状等信息难以对种子活力水平进行准确判断。生理生化方法和发芽测试法检测结果可靠,但是这些方法需要消耗特殊试剂,对样本具有破坏性且耗费大量人力物力[5]。高光谱图像技术具有快速、无损等优势,基于其开展的种子活力检测一直是当前的研究热点[6]。李美凌等[7]采集老化和未老化水稻种子的高光谱图像,基于获取的光谱信息建立水稻种子活力分级模型,分类准确率达到97.22%以上。Zhang等[8]基于高光谱图像技术对经过不同冻害程度处理的 6组水稻种子样本进行活力分类检测,搭建了准确率为 99.33%的分类模型。许思等[9]采用人工加速老化方法制备了 3个老化等级的水稻种子,获取并分析种子光谱信息,对不同活力等级水稻种子的分类准确率达到98.75%。以上研究虽然取得了良好的检测效果,但其对于种子活力等级定义是依据种子老化程度,未考虑到同一老化等级中依然存在活力高低的种子。因此,本文采用高光谱图像技术获取不同老化程度单粒水稻种子高光谱图像,在此基础上按照种子发芽速度对其进行三等级划分,进而实现对单粒种子活力的高精度检测。
高光谱图像中光谱数据维度较高,含有大量的冗余信息和干扰信息,将其直接用于建模会导致建模时间长和模型准确率低等问题。堆叠自动编码器(Stacked Auto-Encoder,SAE)拥有良好的特征提取能力,能准确获取数据中的高阶非线性特征[10-12]。因此,本文使用SAE对光谱数据进行深度数据挖掘,该方法在水稻种子活力检测研究中还未见报道。
本文基于高光谱图像技术,结合化学计量学方法和深度学习算法,针对不同老化条件获取的高活力、低活力和无活力的水稻种子开展分类检测研究,以期为制作水稻种子活力检测设备提供有效参考。
1 材料与方法
1.1 样本制备
为扩充不同活力的水稻种子样本规模,需要对水稻种子进行人工加速老化。首先从沭阳县真诚农资经营部(江苏省宿迁市)购买2 kg年份为2020年的绿旱1号水稻种子,将其称量等分成为4部分,每部分0.5 kg分别装在4个尼龙袋中。然后将1个尼龙袋作为参照组放置于室温条件下:温度为 25 ℃,相对湿度为 33%(RH,Relative Humidity),其他3个尼龙袋依次放入智能恒温恒湿箱,顺序为:第1天放入第1袋,第2天放入第2袋,第3天放入第3袋,设置智能恒温恒湿箱温度为43 ℃,RH为90%[13]。第4天取出所有样本,获得未老化(AA0)、老化1 d(AA1),2 d(AA2)和3 d(AA3)的水稻种子。最后,将样本放置于室温条件下持续2 d以使其含水率达到相似水平,随后放于低温箱中备用。
1.2 高光谱成像设备与高光谱图像获取
高光谱图像采集设备具体如图1所示。整个分光模块(芬兰Spectral Imaging 公司):TE-cooled InGaAs CCD相机、ImspectorN17E分光光计和OLES30变焦镜头;卤素光源(2900-ER+9596-E,美国Illumination公司),光源功率为 150W;电动位移平台(MTS120,北京光学仪器厂),暗箱(SC100,北京光学仪器厂)。该系统采集的光谱范围为871~1 766 nm,包含256个波段。
在图像采集试验之前先对仪器预热30 min,然后对仪器进行调校并确定相机曝光时间为20 ms,位移平台移动速度为1.25 mm/s。将水稻种子样本按照5行5列的方式单粒摆放在样本托盘上的黑色纸板上。计算机控制平台从左向右移动,高光谱成像仪器捕捉样本的高光谱图像并传输到计算机中存储。每个老化梯度扫描300个水稻种子样本,共扫描1 200个样本。之后按照公式(1)[14]对原始高光谱图像进行黑白板校正,去除相机中引入的暗电流噪声。将每次图像采集结束的样本(5×5排列)按顺序摆放,4个批次构成一个10×10的样本阵列,记录样本位置并与高光谱图像中的样本对应,准备后续发芽试验。
式中IS为原始图像,IW为白板图像,IB为黑板图像,I为校正后图像。
为获取样本代表性的光谱信息,将单粒种子区域作为感兴趣区域并从中提取光谱信息。如图2所示,已有研究表明将样本光谱极大值处波长下图像与光谱极小值处波长图像相除,能够获得样本与背景具有较大差异的比值图像[15]。因此,将高光谱图像中1 100 nm下图像除以1 230 nm下的图像,得到比值图像(灰度图像)。然后对灰度图像设置阈值1.2,灰度值大于阈值的像素点置1,灰度值小于阈值的像素点置 0,灰度图像转换为掩膜图像。应用掩膜图像到原始高光谱图像上将样本区域的高光谱图像从背景中分离,最后计算样本高光谱图像上所有像素点的光谱平均值作为该样本光谱。
1.3 标准发芽试验
在发芽盒中平铺上 3层浸湿的滤纸,将经过图像采集的种子按照 10×10的排列方式摆放在发芽盒中并记录其位置,喷洒少量清水后闭上盒子并放置于智能恒温恒湿箱中,设置光照(28 ℃,8 h)和黑暗(20 ℃,16 h)条件。每天取出发芽盒并对种子进行喷洒补水,并记录发芽结果。发芽结果如表1所示,3 d发芽数是指在第1到第3天发芽的种子数,5 d发芽数是指第4到第5天发芽的种子数,在第 5天之后发芽或者不发芽的种子视作未发芽(实际上第 5天之后发芽的种子因为胚芽生长异常最终霉变死亡了)。
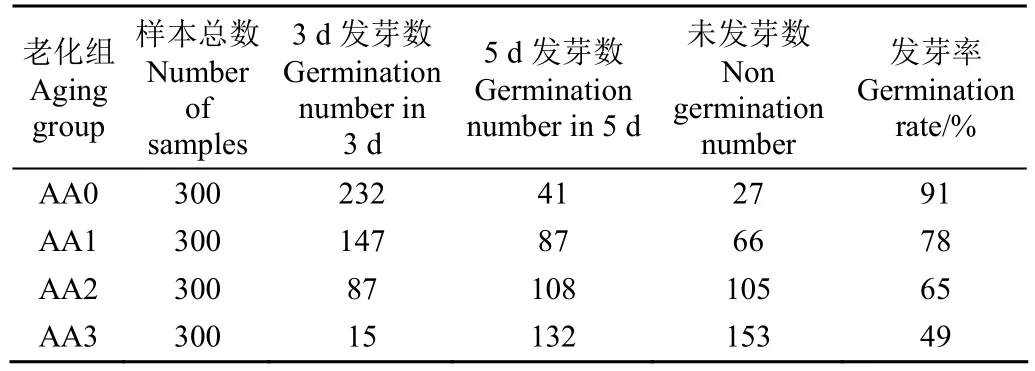
表1 不同老化梯度下水稻种子活力情况Table 1 Vigor of rice seeds under different aging gradients
表1记录不同老化梯度下水稻种子样本发芽情况,可以发现随着老化天数的增加,种子发芽率呈现不同程度的下降。而且,老化天数越高,3 d发芽数在下降,5 d发芽数和不发芽种子个数在上升。这些现象说明老化条件通过影响水稻种子的生理功能进而影响到种子的活力,导致水稻种子的发芽速度受到影响。因此,根据已有研究可以将 4个老化梯度下的水稻种子按照发芽的快慢分为高活力(3 d发芽),低活力(5 d发芽)和无活力(未发芽)三类[16-17]。
1.4 堆叠自动编码器
自动编码器(Auto Encoder,AE)[18]是一种典型的三层神经网络结构,包含输入层、隐含层和输出层。AE的输入层和隐含层构成编码部分,隐含层和输出层构成解码部分。但是单个AE难以提取到数据中深层特征,可以考虑将多个AE逐层堆叠,形成一个多层编解码结构的神经网络模型,即堆叠自动编码器(Stacked Auto-Encoder,SAE)[19]。具体操作为第一个AE的隐含层的输出直接作为第二个AE的隐含层输入,依此类推,得到隐含层个数不同的SAE。
1.5 支持向量机
支持向量机(Support Vector Machine,SVM)是一种经典的机器学习方法,可以解决小样本规模的分类问题[20-21]。SVM是基于统计学原理且遵循结构风险最小化为目标而设计的,通过对样本进行监督学习从而达到模式识别的作用。SVM不仅计算简单训练时间短,而且具有良好的泛化性能与鲁棒性。因此本文采用SVM作为分类器对不同活力等级的水稻种子样本进行分类,在此设置SVM核函数为RBF核函数。
将准确率作为分类模型的评价指标,其定义如公式 (2)[22]所示。
式中ACC为准确率,n1为模型判别正确的样本个数,n2为样本总数。
1.6 样本集划分
1 200 个种子样本中高活力、低活力和无活力样本个数分别为481、368和351。将每个活力等级样本按照2∶1的比例随机划分训练集和预测集,用于训练分类模型以及测试模型性能,样本集划分结果如表2所示。

表2 训练集和测试集划分结果Table 2 Partition of training set and test set
1.7 原种子数据获取
为了解基于老化种子数据搭建的活力分级模型对于实际生产过程是否具有指导作用,需应用一批未经老化的原种子(300)数据对模型的泛化性能进行测试。首先进行原种子高光谱图像采集,然后对原种子进行发芽试验。按照发芽天数原种子被划分为高活力、低活力和无活力三类,样本个数分别为228、42和30。
2 结果与分析
2.1 光谱数据预处理
2.1.1 预处理方法选择
图3展示4个不同老化梯度的1 200个种子样本光谱,因为首尾存在仪器噪声,故保留914~1 704 nm范围内的230个波段作为原始光谱用于后续分析。
由图3看出原始光谱中存在明显的高频噪声,需要对其进行预处理。小波阈值去噪(Wavelet Threshold Denoising,WTD)是一种可以准确去除光谱中高频噪声的方法,WTD先将光谱信号分解为高频细节部分和低频近似部分,然后对高频信号系数进行阈值处理,最终重构去除噪声的信号[23]。在本文中WTD被用来对原始光谱信号去噪,设置小波基函数为db4[24]。此外,一阶导数(First/1stDerivative,FD)可以有效降低光谱曲线的基线漂移效应,消除重叠峰并且提高光谱分辨率[25]。因此,在进行 WTD基础上再进行FD预处理,可以进一步增加数据可用性。
2.1.2 预处理结果评价
WTD在不同的小波分解层数下会带来具有差异性的降噪效果,为了确定最佳小波分解层数,本文选择对原始信号进行1~5层分解并逐一讨论。此外,为了评估WTD结合FD预处理的效果,在原始信号经过WTD处理的基础上再次进行FD预处理,获取多组预处理光谱。基于得到的每组预处理数据,对1 200个样本采用五折交叉验证[26]方法划样本集并建立SVM模型,求取模型交叉验证准确率,结果如表3所示,根据结果评估最佳的预处理方法。
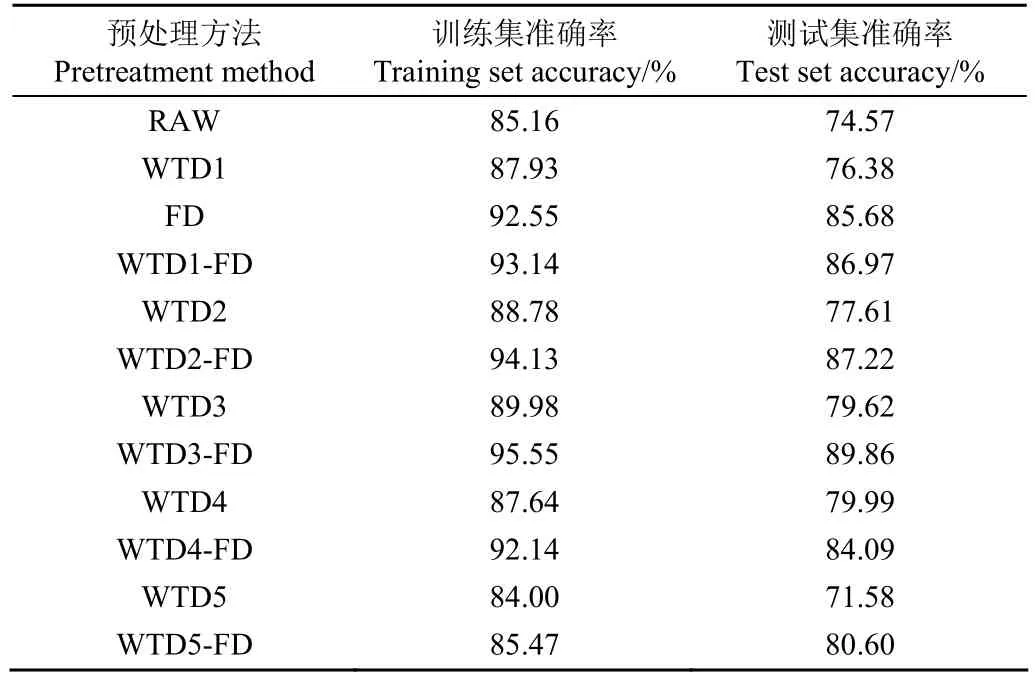
表3 基于WTD和FD预处理之后的光谱的建模结果Table 3 The model results based on the spectra after WTD and FD pretreatment
根据表3结果可知,基于原始光谱建立的模型准确率为74.57%,其难以满足活力准确分级需求。WTD在对原始光谱 1~5层分解时,模型准确率分别为 76.38%,77.61%,79.62%,79.99%和71.58%。相较于原始光谱建模结果,分解层数为 1~4时模型准确率得到不同程度提升,且在分解层数为4时达到较高的准确率。可知,WTD能有效降低原始光谱中存在的噪声干扰,使模型性能提升。FD预处理光谱建模准确率为85.68%,相较于原始光谱提升了11.11个百分点,效果较为明显,说明FD有效降低基线漂移等因素对原始光谱的影响。组合算法WTD1-FD,WTD2-FD和 WTD3-FD模型准确率相比于WTD和FD均得到提高了,且WTD3-FD实现了较高的准确率(89.86%)。分析可知,WTD-FD在分解层数达到 3时最大程度降低了高频噪声的影响,当分解层数高于3时丢失了部分低频有用信号。以上结果说明WTD和FD对于光谱的预处理是有效的,组合方法(WTD-FD)效果相比于单一方法效果更好,且WTD3-FD效果较佳。因此,接下来的分析基于WTD3-FD预处理的光谱数据展开,WTD3-FD预处理光谱如图4所示。
2.2 平均光谱分析
试验中通过设置不同老化条件获取 3个活力等级的水稻种子样本。计算每个活力水平的水稻种子样本的平均光谱(基于WTD3-FD预处理光谱),绘制如图5所示的平均光谱曲线图。
从图5可以发现,高活力、低活力和无活力水稻种子的平均光谱之间整体的趋势是相似的,在一些波峰波谷的地方展示了较为明显的区别。水稻种子在老化过程中由于抗氧化酶活性的降低,累积的活性氧(Reactive Oxygen Species,ROS)与细胞膜脂质发生氧化反应,导致细胞膜透性增加,细胞内物质外渗从而引发细胞结构发生变化[27]。微观结构变化能导致水稻种子的光谱反射率呈现变化[28]。此外,由于种子自身呼吸作用导致其内部可溶性糖和可溶性蛋白等有机物的消耗,使得这些有机物的含量下降[29]。1 000 nm附近与蛋白质中的N-H的三倍频有关,1 300 nm附近与淀粉的C-H的二倍频有关,1 400 nm附近的区域与蛋白质中的O-H组合频吸收有关,1 660 nm附近的吸收谷与脂肪含量有关[30]。光谱曲线上的差异一方面证明了不同活力等级的水稻种子之间的差异,另一方面又证明了高光谱图像技术用于水稻种子活力的检测是可行的。
2.3 光谱特征提取
2.3.1 基于主成分分析的特征变量提取
全光谱中包含的大量冗余信息和共线性信息不利于建立准确的活力分级模型,需进行特征变量提取。首先使用主成分分析(Principal Component Analysis,PCA)[31]对原始数据通过正交变换转换成为主成分,并计算每个主成分的贡献率。从第一个主成分开始累计其贡献率,当累计贡献率达到 99%时选取所统计的所有主成分作为特征变量[32]。基于PCA特征变量提取的结果如图6所示,前15个主成分的个数达到了99.20%,因此选择前15个主成分作为光谱的特征变量。
2.3.2 基于堆叠自动编码器的特征变量提取
使用SAE对全光谱进行特征提取,通过逐层训练,采用五折交叉验证法划分样本集,反复测试不同神经元个数情况下的SVM建模结果,根据模型精度确定最佳隐含层个数和神经元个数。在此,将预处理之后的 230维光谱数据作为SAE的输入层,设置Sigmoid函数为激活函数,学习率为0.1。因为SAE会将隐含层神经元个数降低到一个小的数,因此设置第 1个隐含层的神经元个数为170,第2个隐含层神经元个数设置为1~170。通过算法的迭代,最终输出图7a显示的结果。根据图7a可知当第2个隐含层神经元个数为127时,测试集准确率达到了最高的93.95%。因此,127被作为第2个隐含层较佳的神经元个数。为继续降低数据维度,设置第 3个隐含层的神经元个数为1~127并进行测试。当第3个隐含层的神经元个数为 62时取得较佳的测试集准确率为96.23%,如图7b所示。依此类推,继续增加隐含层,获取较佳神经元个数,结果记录在表4。
从表4可以发现,当隐含层个数为 3,网络规模为230-170-127-62时,SAE得到较佳的建模结果。当隐含层个数大于 3时,数据的维度虽然得到降低,但模型准确率发生下降。说明SAE在网络规模为230-170-127-62时已经充分地获取230维光谱数据中的关键性特征。因此,设置网络规模为230-170-127-62,将获取的62维变量作为较优化特征。
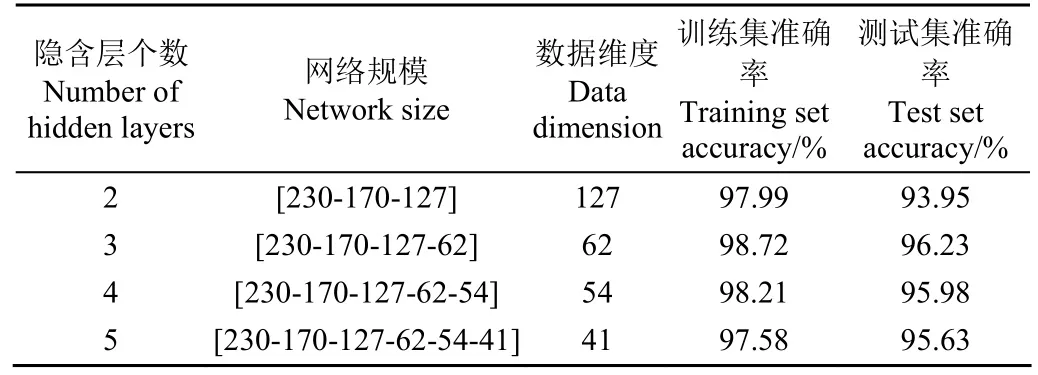
表4 基于SAE特征提取结果Table 4 Results of feature extraction based on SAE
2.4 水稻种子活力等级分类模型的建立与优化
建模方法采用SVM,SVM的惩罚因子C和核函数参数g设置为默认值。为检验模型稳定性和鲁棒性,按照表2训练集和测试集样本比例随机划分样本集并建立模型,重复10次,结果如表5所示。
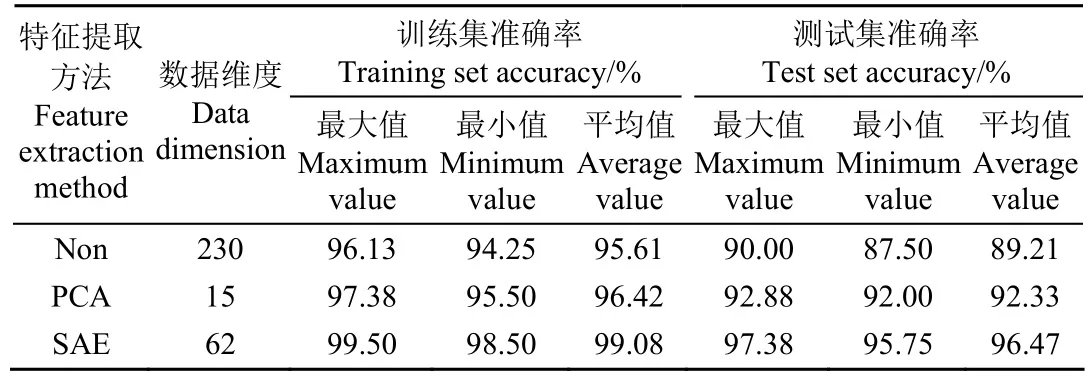
表5 基于PCA与SAE特征的SVM建模结果Table 5 SVM model results based on feature extracted by PCA and SAE
从表5中可以发现,PCA特征变量个数为15,SAE特征变量为62,都远远低于全光谱的变量个数,PCA和SAE特征变量建模准确率均高于全光谱。可知,特征提取降低了全光谱中的干扰信息和冗余信息的影响,使得所建立的模型复杂程度降低,模型性能提高。SAE和PCA特征变量建立的SAE-SVM和PCA-SVM模型准确率分别为96.47%和92.33%,很明显SAE-SVM模型准确率更高。因为SAE是一种深层神经网络降维方法,相较于PCA其能够准确获取原始数据中的高阶非线性特征。
尽管基于SAE-SVM模型取得了良好的检测效果,仍然可以使用智能算法对该模型的参数C和g进行优化,以期取得更好的分类结果。为此,使用具有良好的参数寻优能力的灰狼优化算法(Grey Wolf Optimizer,GWO)[33-34]对SVM参数进行优化。为了验证GWO的有效性,基于表5中 10次随机划分的样本集分别构建GWO-SVM模型,表6记录了GWO-SVM模型结果。可以发现,相较于表5模型,GWO-SVM模型的准确率均呈现不同程度上升。其中SAE-GWO-SVM性能最高,其训练集和测试集准确率平均值分别达到100%和98.75%,相较于优化前分别提高了0.92和2.28个百分点。综合分析可知 GWO对 SVM 的优化是有效的,将建立的SAE-GWO-SVM模型作为最终的水稻种子活力分级模型是可行的。
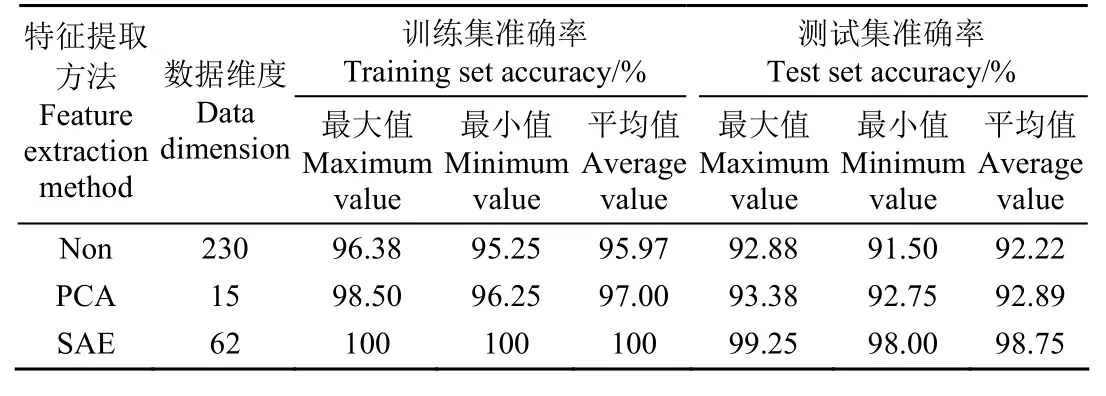
表6 GWO优化SVM模型结果Table 6 Results of SVM model optimized by GWO
2.5 模型有效性验证
获取 300个原种子光谱数据,对其进行预处理之后将其输入SAE-GWO-SVM模型得到分类结果。在此,所用模型为表6中准确率与平均值准确率最为接近的SAE-GWO-SVM模型,分类结果以混淆矩阵展示,如图8所示。图8中真实标签为每个活力等级下实际样本个数,对角线数值为每个活力等级中模型判别正确样本个数,网格颜色与其中的数值大小相关,右侧颜色条为其具体对应关系。对角线上网格相较两侧颜色深,说明绝大部分样本得到准确分类。全样本准确率为 98%,其与表6结果接近,225个高活力样本、39个低活力样本和30个无活力样本正确分类,类内准确率分别为98.68%、92.86%和100%。模型对于每类样本的识别准确率都大于90%,表现出较强的泛化性能,说明建立的SAE-GWO-SVM模型对于实际生产具有意义。
3 结 论
本文使用高光谱图像技术对水稻种子进行活力分级,采用阈值分割的方式获取感兴趣区域并从中提取光谱信息。首先使用WTD(Wavelet Threshold Denoising)结合 FD(First/1stDerivative)的方法降低光谱中的高频噪声和重叠峰效应。然后分别使用 SAE(Stacked Auto-Encoder,SAE)和 PCA(Principal Component Analysis,PCA)提取光谱数据中的特征变量,SAE因其强大的非线性深层次特征提取能力使得基于 SVM(Support Vector Machine)建立的SAE-SVM模型性能表现更好,模型准确率为 96.47%。最后使用 GWO(Grey Wolf Optimizer)对SAE-SVM模型进行优化,模型准确率达到98.75%。本文所建立的SAE-GWO-SVM活力分级模型为高精度检测水稻种子活力提供了新的思路,为更好地维护粮食安全提供了强有力的手段。
