结合冠层密度的森林净初级生产力遥感估测
2021-10-10李明阳钱春花
李 陶,李明阳,钱春花
(南京林业大学林学院,江苏 南京 210037)
森林净初级生产力(net primary productivity,NPP)是指森林在单位面积、单位时间内所积累的有机物数量,表现为光合作用固定的有机碳中扣除植物本身呼吸消耗的部分[1]。NPP作为地表碳循环的组成部分,能够直接反映自然环境条件下森林的生产能力,是评价森林生态系统可持续发展的重要指标之一,是生态系统碳汇和调节生态过程判定的主要因子,在全球变化及碳平衡中有着重要的作用[2-3]。森林净初级生产力的估算研究有助于了解全球碳循环,为合理利用自然资源、修复受损森林等提供科学依据。
利用遥感数据可以获得大区域尺度内的森林覆盖状况、森林光谱特征等信息,同时这些信息与森林生产力密切相关,光学传感器和主动传感器已经被广泛应用于森林净初级生产力估测中[4]。因Landsat系列遥感卫星像元的空间分辨率为30 m×30 m,像元大小与森林经营单位(小班)的最小区划面积接近,经常被用来进行区域森林生产力遥感估测。区域尺度森林生产力估测中结合地面调查数据的遥感估测已成为重要的手段之一,但是在过去的研究中发现仅仅采用 Landsat系列遥感图像构建模型估测森林NPP,存在光饱和因子问题,为了更加准确地构建森林NPP遥感估测模型,本研究引入一个新的变量——森林冠层密度(canopy density)。森林生产力与年龄、植被生长状况有关,而采用传统方法提取的遥感特征变量却不包含这些信息,森林冠层密度是从空中观测到的森林植被与投影面积的比例,在数值上与郁闭度相同,是反映林分密度的指标,是决定林分结构的重要因子之一,可以用来表示光照、水分、温度等环境因子通过林冠进入林分的再分布状况[5]。
本研究以广东省重点林区韶关市为研究对象,结合森林冠层密度采用Landsat-8 OLI数据和随机森林、多元线性回归、人工神经网络、K-最近邻分类法等4种模型,进行森林净初级生产力特征变量选取、参数建模、精度评价、空间制图,以期能在区域尺度上通过遥感反演较为准确地预估森林NPP,通过加入森林冠层密度这一变量以提高NPP遥感估测模型的估测精度。
1 材料与方法
1.1 研究区概况
韶关市位于广东省北部,北接湖南,东邻江西,东南面、南面和西面分别与广东省河源、惠州、广州及清远等市接壤(112°53′~114°45′E,23°53′~25°31′N),全境直线距离东西跨度为186.3 km,南北跨度为173.4 km,全市土地面积1.84万km2。韶关地形以山地丘陵为主,河谷盆地分布其中,平原、台地面积约占20%。地势北高南低,北部石坑崆海拔1 902 m,为广东第一高峰,南部最低处海拔仅35 m。河流主要为珠江水系北江流域,北江以浈江为干流,主要支流有武江、墨江、锦江、滃江、南水。
韶关属于中亚热带湿润季风气候区,气候宜人。年平均气温21 ℃,冬季各地气温自北向南递增,夏季各地气温较接近。雨量充沛,年均降雨1 700 mm,3—8月为雨季,9—2月为旱季,冬季北部有雪。Landsat-8 OLI遥感图像受云量过多的限制,为保证研究质量,本研究仅选取2017年10月下旬的条带号122、行编号43、云量0.7%的一景图像进行研究,研究区域面积占韶关市总面积的94.5%。
韶关是全国重点林区,为广东省用材林、水源林和重点毛竹林基地,被誉为华南生物基因库和珠江三角洲的生态屏障。全市林业用地面积144.8万hm2,森林覆盖率为73.8%,林木绿化率为74.6%,森林蓄积量8 917万m3。省级以上生态公益林面积占林业用地面积比达45.6%,其中,国家级公益林占46.3%,省级公益林占53.7%。韶关市森林阔叶混交林和阔叶纯林居多,阔叶纯林主要有栎类(Quercusspp.)、桉树(Eucalyptusspp.)、樟树(Cinnamomumcamphora)等树种;其次是以马尾松(Pinusmassoniana)、杉木(Cunninghamialanceolata)等为代表的针叶纯林、针阔混交林以及以毛竹(Phyllostachysedulis)等为代表的竹林等。
1.2 数据来源与预处理
本研究主要数据包括:①自地理空间数据云网站(http://www. gscloud. cn/)下载的广东省韶关市2017年10月Landsat-8 OLI遥感影像,条带号122,行编号43,云量0.7%,多光谱波段空间分辨率为30 m×30 m;②地理空间数据云网站下载的韶关地区数字高程模型(DEM),空间分辨率为30 m×30 m;③韶关市2017年357块森林资源连续清查固定样地数据,样地间距为6 km×8 km,每块样地面积为0.06 hm2,样地属性包括地形、地貌、土壤名称、优势树种、平均胸径、平均树高、龄组、郁闭度等60多个调查因子。
1.2.1 影像数据预处理
1)Landsat-8 OLI影像预处理。使用ENVI 5.3软件对Landsat-8 OLI影像进行预处理。为消除大气和光照等因素对地物反射的影响,首先对影像进行辐射定标,然后使用ENVI软件下的FLAASH模块进行快速大气校正。研究区内地形以山地丘陵为主,南北海拔差异较大,遥感影像受传感器方位与太阳高度、方位等影响,造成因阴坡、阳坡接受的照度不同而引起亮度值出现差异,因此采用基于余弦校正模型的C校正算法对遥感图像进行地形校正,消除由于地形起伏而引起的影像辐射亮度值的变化,使影像更好地反映地物的光谱特征。
2)特征变量的提取。图像预处理结束后,根据肖兴威[6]的研究,森林生产力与林分、土壤、地形等状况密切相关,所以使用ENVI软件提取归一化植被指数(NDVI)、比值植被指数(RVI)、差值植被指数(DVI)、增强型植被指数(EVI)、绿度植被指数(GVI)、垂直植被指数(PVI)等6种植被指数以及叶面积指数(LAI)。对遥感图像进行缨帽变换,提取前3个分别反映土壤岩石、植被及土壤和植被中水分信息的分量。基于DEM提取地形因子——坡度作为变量之一。依据Li等[7]的研究结果,本研究提取纹理特征时窗口大小选择3×3,灰度量化等级为64,计算对比度、相异性、平均值、均一性、角二阶矩、熵、偏度、熵相关性等。预测变量类型、名称、数量见表1。

表1 NPP遥感估测模型备选自变量Table 1 Independent variables set for model of remote sensing estimation of NPP
1.2.2 样地森林净初级生产力计算
森林净初级生产力由群落生长量和年凋落量组成。根据2017年森林资源连续清查数据中样地林木蓄积量数据及余超等[8]提供的中国不同森林类型生物量与蓄积量、生物量与群落生长量和年凋落量之间的函数关系,以蓄积量为基础计算不同森林类型的生物量,依据生物量分别计算群落生长量与凋落量,求得每块样地的森林净初级生产力(NPP)[9]。
1.2.3 森林冠层密度的计算
引用森林冠层密度制图器(FCD)进行森林冠层密度的提取。根据Joshi等[10]的研究可知,森林冠层密度的提取有人工神经网络(ANN)、多元线性回归技术(MLR)、森林冠层密度制图器(FCD)、最大似然分类(MLC)4种方法。在4种方法中,FCD在3个东南亚国家获得的森林冠层密度准确率平均值为92%[11]。FCD模型以森林生长现象为基础,能够检测森林冠层密度时间上的变化。FCD模型基于Landsat-8提取植被指数(IV)、裸土指数(IB)、阴影指数(IS)3个指数来计算森林冠层密度,绘制森林冠层密度图。与NDVI相比,IV对植被数量的反应更为敏感,IB随地表裸露程度的增加而增大,IS随森林密度的增加而增大。3个指数及FCD(式中记为FCD)计算公式如下:
IV=[(B5+1)(65 536-B4)(B5-B4)]1/3;
(1)
(2)
IS=[(65 536-B2)(65 536-B3)(65 536-B4)]1/3;
(3)
FCD=(VD×ISS+1)1/2-1。
(4)
式中:B2—B6分别表示蓝、绿、红、近红外和短波红外波段的亮度值;当(B5-B4) 小于0时,IV=0;VD表示植被密度值,由IV和IB利用主成分分析合成得到;ISS表示尺度阴影指数,通过IS的线性变换得到[12]。
1.3 遥感估测模型
随机森林(random forest,RF)是一种组合分类器,它利用一种重抽样(bootstrap)方法从原始样本中抽取多个样本,对每个重抽样的样本进行决策树建模,然后将决策树组合,通过投票得到最终的预测结果[13]。大量理论与实际研究证明随机森林预测准确率较高,对于异常值和噪音有很好的容忍性,由于随机森林生成决策树的样本是随机选择的,能够减少过拟合现象[14]。随机森林模型通过R语言randomForest数据包中randomForest函数执行,在使用时需要调整建立的决策树数量(ntree)和决策树分裂时抽取的变量个数(mtry)两个参数。mtry值为构建随机森林回归模型时自变量个数的1/3,当自变量个数小于3时,mtry值默认为1[15]。
多元线性回归(multiple linear regression,MLR)有两个或两个以上自变量。多元线性回归模型以植被指数、纹理特征、原始波段、森林冠层密度等66个因子作为自变量,以2017年韶关样地NPP作为因变量,建立遥感数据与样地实测NPP之间的相关关系,估算森林NPP。自变量的筛选选择逐步回归,其基本思想是将变量逐个引入模型,每引入一个新变量进行一次F检验,入选的模型变量再逐一进行t检验,当原来引入的变量由于后面变量的引入变得不再显著时,则将其删除,直至既没有显著的变量入选回归方程、也没有不显著的变量从回归方程中剔除为止,此时回归模型中变量都与因变量呈显著相关。逐步回归通过SPSS软件执行,步进标准使用F概率,进入与删除分别设置为0.05与0.1。
人工神经网络(artificial neural network,ANN)以数学模型模拟神经元活动,是基于模仿大脑神经网络结构和功能而建立的一种信息处理系统。目前,人工神经网络模型中多层感知器类型的反向传播网络(BP网络)已成为应用最为广泛的模型之一,本研究使用3层结构的BP神经网络模型,包括输入层、隐藏层和输出层[16]。BP神经网络模型用R语言neuralnet函数包进行构建,首先利用系统默认节点数和隐含层数建立模型,根据结果误差情况,进一步增加隐含层数目,以此提高模型精度。
K-最近邻分类法(K-nearest neighbor,K-NN)是基于类比学习,通过给定的检验元组与和它相似的训练元组进行比较来学习[17]。根据给定的测试样本,计算测试样本与训练集中每个对象的距离,圈定距离最近的K个训练对象作为最近邻,这K个最近邻中选出此次数最多的类标号作为测试样本的类标号值。K-最近邻分类模型用R语言class包中的knn函数实现,依据陈尔学等[18]的研究,本研究设置K=10。
1.4 模型特征变量选择
本研究基础变量的优化选择统计检验方法,即相关性分析,是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个变量因素的相关密切程度。本研究共有66个备选变量,使用SPSS进行Pearson相关性分析,选择相关性显著的特征变量加入模型构建。经Pearson相关性分析,共有10个特征变量与NPP具有显著相关性(表2)。
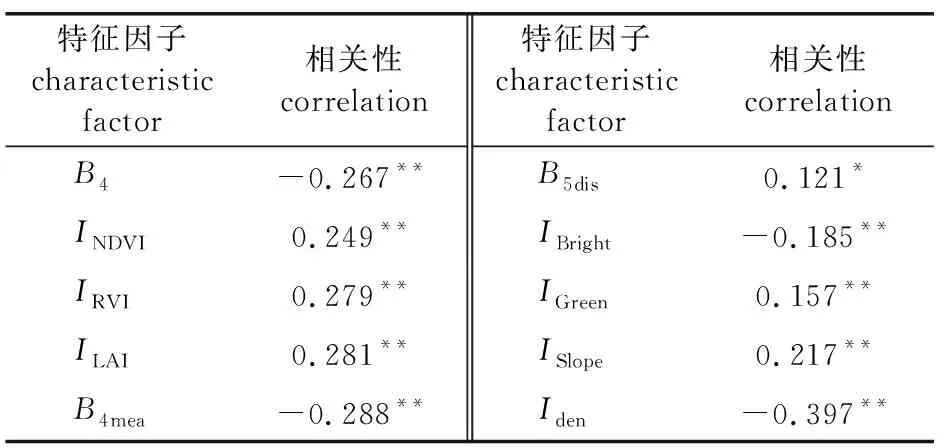
表2 特征因子与NPP相关性Table 2 The correlation between characteristic factors and NPP
1.5 模型精度验证与评价
本研究使用十折交叉验证进行模型精度验证。该方法将数据集分成10份,轮流将其中9份作为训练数据,1份作为测试数据进行试验,10次结果均值将作为对算法精度的估计,本研究进行10次十折交叉验证求取平均值,即为该模型最终精度。
遥感估测模型评价指标有很多,如决定系数(R2)[19]、均方根误差(RMSE)、平均绝对误差(MAE]、总体相对误差(RS)、平均相对误差(E1)、总体相对误差绝对值(E2)、预估精度(P)等。采用R2、RMSE和MAE对模型精度进行评价。R2反映变量的全部变异能通过回归关系被自变量解释的比例,其区间通常为(0,1),R2的值越大,表示预测值与实际值之间相关性越强。RMAE是预测值与真实值的误差平方根的均值,预测值与实际值之间的RMSE越小,表示模型预测的效果越好。MAE是绝对误差的平均值,可以更好地反映预测误差的实际情况,当预测值与真实值完全吻合时MAE等于0,误差越大,该值越大。
本研究模型拟合主要是通过计算模型的决定系数(R2)、均方根误差[RMSE,式中记为σ(RMSE)]、平均绝对误差[MAE,式中记为σ(MAE)]进行精度评价。
(5)
(6)
(7)
2 结果与分析
2.1 不同森林类型NPP比较分析
不同森林类型的NPP对比见图1。从图1可看出:2017年研究区内风景林的NPP最高[16.95 t/(hm2·a)],原因为风景林主要位于研究区人口密集、经济发达的城镇及周边地区,经营者投资力度大,经营强度高;自然保护林的NPP为16.91 t/(hm2·a),排名第2,与远离城镇、保护力度大、人为干扰少存在密切联系;而水土保持林的NPP最低[10.64 t/(hm2·a)],原因在于水土保持林大多地处海拔较高、坡度较陡、立地条件较差的地段;短轮伐期用材林的NPP[14.49 t/(hm2·a)]高于一般用材林[13.69 t/(hm2·a)],原因在于短轮伐期的树种以速生丰产的桉树为主,而一般用材林则以轮伐期较长、生长较慢的杉木、马尾松为主。
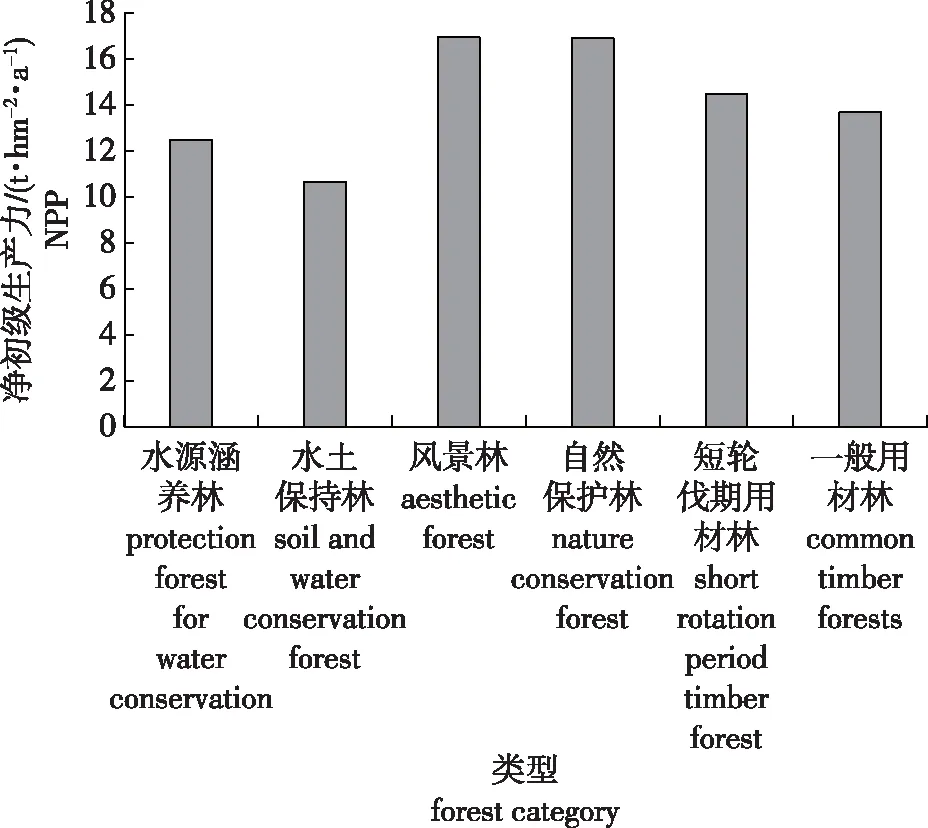
图1 不同森林类型的NPP比较Fig.1 Comparison of NPP of different forest category
不同林型的NPP比较见图2。从图2可看出,2017年研究区内竹林的NPP最高[26.35 t/(hm2·a)],这与竹类生长迅速的特性相吻合;阔叶林的NPP[12.39 t/(hm2·a)]高于针叶林的[11.41 t/(hm2·a)];阔叶混交林的NPP[17.71 t/(hm2·a)]高于针叶混交林的[17.50 t/(hm2·a)]。针阔混交林的NPP[12.56 t/(hm2·a)]低于针叶混交林的原因是针阔混交林以天然次生林为主,其经济效益差,经营强度低,林木生长缓慢。而针叶混交林以人工营造的水源涵养林和一般用材林为主,经营强度较高,受人为不良干扰较少,林木生长状况较好,生长速度较快。
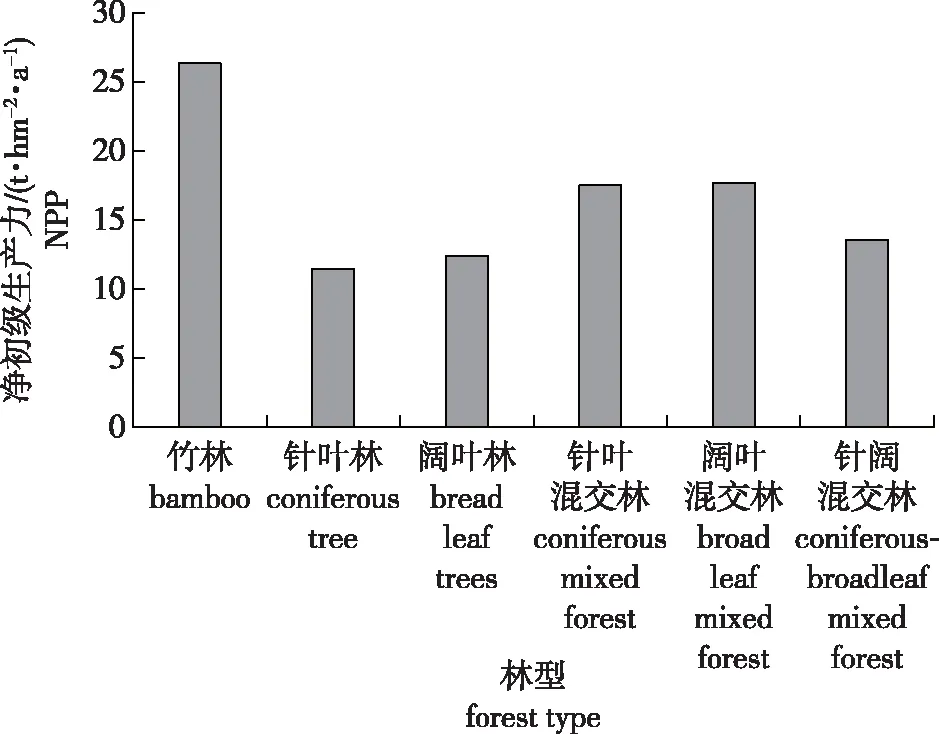
图2 不同林型的NPP比较Fig.2 Comparison of NPP of different forest type
2.2 森林冠层密度的精度验证
在357块样地中,筛选出林地中郁闭度不为0的233块样地,对FCD模型估测的森林冠层密度进行验证,郁闭度与森林冠层密度的相关系数为0.87,RMSE为0.12,由此可见FCD模型估测精度较高,可用此模型对森林冠层密度进行估测。
依据FCD模型计算得到研究区森林冠层密度图(图3)。从图3可以看出,FCD的空间分布与海拔、人口密度等地形条件及经济发展水平存在密切的关系:研究区中部、西部及东北部,地形以河谷盆地为主,坡度平缓,城镇密集,经济较为发达,人口密度大,森林覆盖率低,森林冠层密度较低;研究区北部、南部及西南部,海拔较高,坡度较陡,人口密度较低,森林覆盖率高,人为干扰少,林木生长状况良好,森林冠层密度较高。
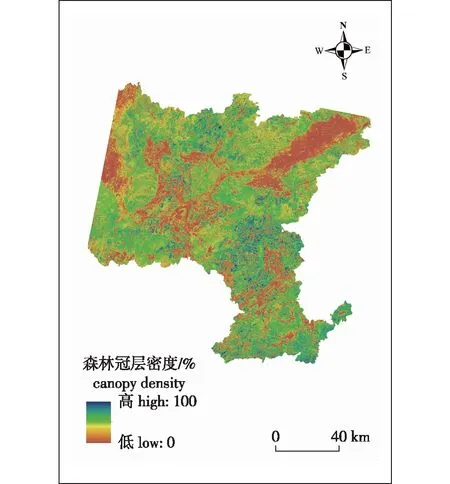
图3 研究区森林冠层密度图Fig.3 Forest canopy density map of the study area
2.3 模型精度评价
模型精度评价分为是否加入森林冠层密度两种情形,将表2中的特征变量,分别代入随机森林、人工神经网络、多元线性回归、K-最近邻分类法4种模型中,建立NPP遥感估测模型,使用十折交叉验证法进行验证。具体遥感预测精度评价结果见表3。
表3显示,在4种遥感估测模型中,无论是否加入森林冠层密度,随机森林算法预测精度最高,其次是人工神经网络、多元线性回归,K-最近邻分类法预测精度最低。随机森林是进行两次取样,首先是有放回的随机抽样得到训练样本的采样集,然后从所有特征中随机选择特征,并选择最佳分割特征作为节点构建分类回归树,这使得最终建立的模型有较强的泛化性。研究区海拔差异大,地形复杂,因变量与大多数特征变量线性相关程度较低,因此在加入森林冠层密度之前多元线性回归在4种估测模型中估测精度最低。在多元线性回归模型中,加入冠层密度之后,由于冠层密度与NPP相关系数较高,并且冠层密度与NPP直接相关的年龄、胸径、树高相关系数较高,较大幅度提升了多元线性回归模型的预测精度。人工神经网络相对于传统的机器学习算法来说,需要更多的数据,本研究仅有样地数据357块,因此预测精度较低。K-最近邻分类法预测精度最差的原因是分类预测时一般选择多数表决法,当样本容量较小时较容易产生误分。从表3还可以看出,森林冠层密度加入4种遥感估测模型后预测精度明显提升,这是由于森林冠层密度与年龄、林分密度、林分结构等有关,而以上因素均会影响森林NPP的大小。

表3 加入森林冠层密度前后模型精度对比分析Table 3 Comparative analysis of model accuracy before and after adding forest canopy density
2.4 NPP空间制图
通过以上建模方式的对比,最终在4种遥感估测模型中选择最优的结合森林冠层密度的随机森林模型进行研究区内NPP制图(图4)。
从图4可以看出,NPP较高的区域主要分布在海拔较高的北部、南部、西南部,NPP较低的林分主要分布在中部、西部、东北部海拔较低的丘陵、河谷盆地。海拔较高的山地人口密度小,人为干扰活动少,森林植被能够较好地进行自然生长;海拔低的丘陵河谷地带人口密度大,森林覆盖率低,人为干扰活动多,林分质量差。由此可以看出,NPP的空间分布趋势与研究区的地貌特征、社会经济状况吻合度较高。

图4 研究区森林净生产力分级图Fig.4 Net primary productivity grading map of study area
计算结果显示,研究区内森林NPP平均值为10.689 t/(hm2·a),标准差为7.389 t/(hm2·a)。为进一步了解研究区内各地区NPP情况,用平均值±标准差的方法,将NPP划分为低[<3 t/(hm2·a)]、中[≥3~11 t/(hm2·a)]、较高[≥11~18 t/(hm2·a)]和高[≥18 t/(hm2·a)]4个等级。结果表明,研究区内森林NPP以低级(面积占比39.22%)、较高级(面积占比24.09%)为主,其次是高级(面积占比19.61%),最低的是中级(面积占比17.08%)。
研究区内森林NPP平均值为10.689 t/(hm2·a),其他研究中广州市NPP平均值为6.95 t/(hm2·a)[20],这与姜春[21]的研究中珠江三角区森林NPP年均值要明显低于粤北地区的研究结果相吻合。同期中国森林NPP平均值为 9.50 t/(hm2·a)[22],广西的NPP为6.62 t/(hm2·a)[19],福建的NPP为5.87 t/(hm2·a)[23],江西的NPP为5.23 t/(hm2·a)[24]。研究区森林NPP稍高于全国森林NPP,这与韶关为全国重点林区有关;明显高于邻近省份,原因是研究区内森林以中幼林为主,生长速度较快,同时韶关为全国重点林区,林地质量较好,森林经营强度较高,对于森林保护较为重视。
预测变量的选取包括原始波段、植被指数、纹理特征、地形特征、森林冠层密度等多方面特征因子,但是4种遥感估测模型均出现预测精度小于拟合精度的现象,说明反演过程中依然存在过拟合现象。这可能与地形、林种、林种结构等有关,如何将林种、树种分类特征引入特征变量,从而提高遥感估测模型精度,需要进一步研究。
3 结 论
1)在区域森林NPP遥感估测中,加入冠层密度这一特征变量,可以较大幅度提高模型估测精度,弥补了特征变量中因缺失年龄、植被生长状况等变量而带来的估测误差较大的缺陷。
2)在基于Landsat 8 OLI提取的众多变量中,红光波段(B4)、纹理特征、归一化植被指数(NDVI)、比值植被指数(RVI)、叶面积指数(LAI)、地形因子、森林冠层密度等因子,在区域森林NPP遥感估测时应予以优先考虑。
3)在4种估测模型中,随机森林模型精度最高,其次是多元线性回归模型、人工神经网络模型,K-最近邻分类模型预测精度最差。因此,在地形较为复杂的南方集体林可以选择随机森林作为NPP遥感估测模型。
