分类提升树模型结合SMOTE技术在天津浴池MSM人群中的应用*
2021-10-09天津医科大学公共卫生学院流行病与卫生统计学系300700宋德胜张甜甜姚婷婷张洪璐刘媛媛李长平
天津医科大学公共卫生学院流行病与卫生统计学系(300700)宋德胜 张甜甜 陈 阳 姚婷婷 张洪璐 刘媛媛 李长平 崔 壮 马 骏
【提 要】 目的 采用logistic、随机森林和CatBoost结合过采样技术(synthetic minority over-sampling technique,SMOTE)技术对天津市某浴池MSM人群数据构建模型以预测HIV的感染风险,并评价三个模型的分类效果。方法 利用10×10折交叉验证对模型进行训练和预测,使用网格搜索确定各模型的超参数。然后使用AUC、accuracy、brier score和F1值对上述三种模型进行评价。结果 在原始数据上,三种模型的表现基本一致,但在对类别比例不敏感的AUC和Brier score上,CatBoost的表现略优于其他两个模型。CatBoost、logistic和随机森林的AUC分别为0.798±0.026,0.792±0.037,0.934±0.040;Brier score分别为0.056±0.001、0.091±0.004和0.054±0.003。使用SMOTE后,CatBoost的性能明显优于其他两个模型。在测试集上,其AUC、accuracy、brier score和F1值分别为0.984±0.003、0.950±0.007、0.040±0.004和0.950±0.007。结论 可使用Catboost模型预测MSM人群中的潜在HIV感染者。
男男同性性行为人群(men who have sex with men,MSM)是目前HIV感染的高发人群,更是被联合国艾滋病规划署(UNAIDS)列为关键人群之一。据2019年UNAIDS的数据显示,MSM人群及其性伴的HIV感染风险是其他成年男性的22倍。全球范围内,每年HIV新发感染者中约17%是MSM。在我国,艾滋病传播形式以性传播为主。在2016年新发HIV感染者中,MSM人群的比例已超过26%[1]。多个省市的调查数据显示[2-4],MSM人群的HIV感染形式不容乐观,且部分数据显示,学生群体中HIV感染人数有上升趋势[5]。当前的研究已经表明,文化程度、性病、高危性行为、商业性行为和多性伴是HIV感染的危险因素[6]。针对这些因素采取相应的措施可以减少HIV在MSM人群中的传播。出于MSM人群的特殊性,尽管目前已有可靠的检测和治疗措施,但每年MSM人群的新发HIV感染患者人数仍高居不下[7]。因此开发一种可靠的模型来识别MSM人群早期感染者以减少病毒在该人群中的传播迫在眉睫,这可在一定程度上弥补HIV检测覆盖不全的缺陷。
机器学习是近几年兴起一门新技术。经过近些年的发展,它已经广泛应用于各个领域。它的主要任务是分类和回归。在进行分类任务学习时,经常遇到类别不平衡的问题,过采样技术(synthetic minority over-sampling technique,SMOTE)是目前解决这类问题的常用方法。分类问题常用的模型包括logistic模型、决策树模型以及后续伴随着计算机的发展而兴起的bagging算法和boosting算法。bagging算法的典型代表是随机森林(random forest,RF);boosting算法的典型代表则是梯度提升决策树(gradient boosting decision tree,GBDT)。基于模型的原理,本文主要选取了线性模型分类器logistic模型、基于bagging的随机森林以及基于boosting算法的CatBoost模型来构建分类器,并进行了分类效果的比较。
资料和方法
1.研究对象
本研究收集了2011-2018年天津市浴池浴客的调查数据。选择每人第一次调查以及检测数据。主要收集的数据包括浴客的人口学信息、性行为信息、检测信息、药物使用信息等。
2.研究方法
(1)基本原理
logistic基本原理:二元logistic模型是一种常见的机器学习分类模型[8],由条件概率分布P(Y|X)表示,它是如下的条件概率分布:

随机森林基本原理:随机森林是一类典型的bagging算法的实现。它由Breiman于2001年提出[9]。随机森林以决策树为基础,在训练过程中利用bootstrap抽样,从训练集中有放回地抽取一部分样本用于建立决策树。对于决策树的每个结点,可先从结点的特征集合中随机选取若干特征的子集,然后再从该子集中选择最优的特征用于划分结点。通过样本的随机和特征的随机来减少模型的过拟合。在分类时,利用“投票”的方式决定观测类别。
CatBoost基本原理:CatBoost是俄罗斯搜索巨头Yandex于2007年提出的提升算法模型[10]。相较于GBDT[11]、XGBoost[12]和LightGBM[13],它在训练之前不需要提前对类别特征进行处理,比如one-hot编码。在训练过程中,它使用独特的技术来处理类别特征,即首先将所有样本进行随机排序,然后针对类别特征中的某个取值,每个样本的该特征转为数值型时都是基于排在该样本之前的特别特征标签取均值,同时加入了优先级和优先级的权重系数以防止过拟合。计算公式如下:
在计算梯度时,与传统的GBDT不同,CatBoost针对每个样本,都单独构建一个利用该样本之前的样本点的梯度估计得到的模型,针对这些模型,估计该样本的梯度,然后利用新样本重新对样本打分。由于上述算法依赖于样本排序,因此利用多种样本排序可训练得到多种模型,这样可以减少过拟合。
SMOTE基本原理:Japkowicz等针对不平衡数据提出了一种少数类的过采样技术,然而这种技术并没有提供给模型更多信息[14]。为了解决过采样的局限性,Chawla等在2002提出一种合成少数类的过采样技术[15]。SMOTE会随机选择一个少数类实例A,并找到它最近的k个少数类。然后随机选择k个最邻近A的少数类B,连接A与B,从而在特征空间中形成一条线段,进而创建若干个合成的实例。在含有分类特征时,新合成的样本实例来自于其周围频数最多的类别。
(2)模型训练
针对原始数据,使用分层10×10折交叉验证的方式分别训练三个模型。超参数则使用网格搜索的方法进行确定。logistic模型的超参数为正则化系数C;随机森林的超参数为森林包含的决策树数目n_estimators,树的最大深度max_depth以及每次bootstrap时,用于训练基学习器的最大样本比例max_samples;Catboost的超参数为L2正则化系数l2_leaf_reg,可构建的最大决策树数目iterations,树的最大深度depth,贝叶斯bootstrap随机权重bagging_temperature,每次树划分时使用的特征比例rsm,bagging的抽样率subsample,使用one-hot编码最大类别数one-hot-max。对原始数据进行SMOTE后,使用10×10折交叉验证的方式分别训练三个模型。超参数与SMOTE之前保持一致。SMOTE前后各模型超参数设置搜索范围如表1所示。

表1 各模型SMOTE前后超参数搜索范围
(3)模型评价
本研究使用了准确度(accuracy)、ROC曲线下面积(ROC),F1值和Brier score进行评价模型在测试集上的表现。各指标的意义如表2所示。计算公式中,TP表示真阳性例数,FP表示假阳性例数,TN表示真阴性例数,FN表示假阴性例数,ft表示模型预测概率,ot表示观测实际类别。

表2 模型评价指标说明
以上模型的构建使用的软件为Python 3.7.4,图形绘制使用的软件为microsoft excel 2019。
结 果
1.变量说明
排除缺失值较多的观测后,最终入选浴客5091名,其中新发HIV感染者346名。模型构建过程中使用的变量如表3所示。
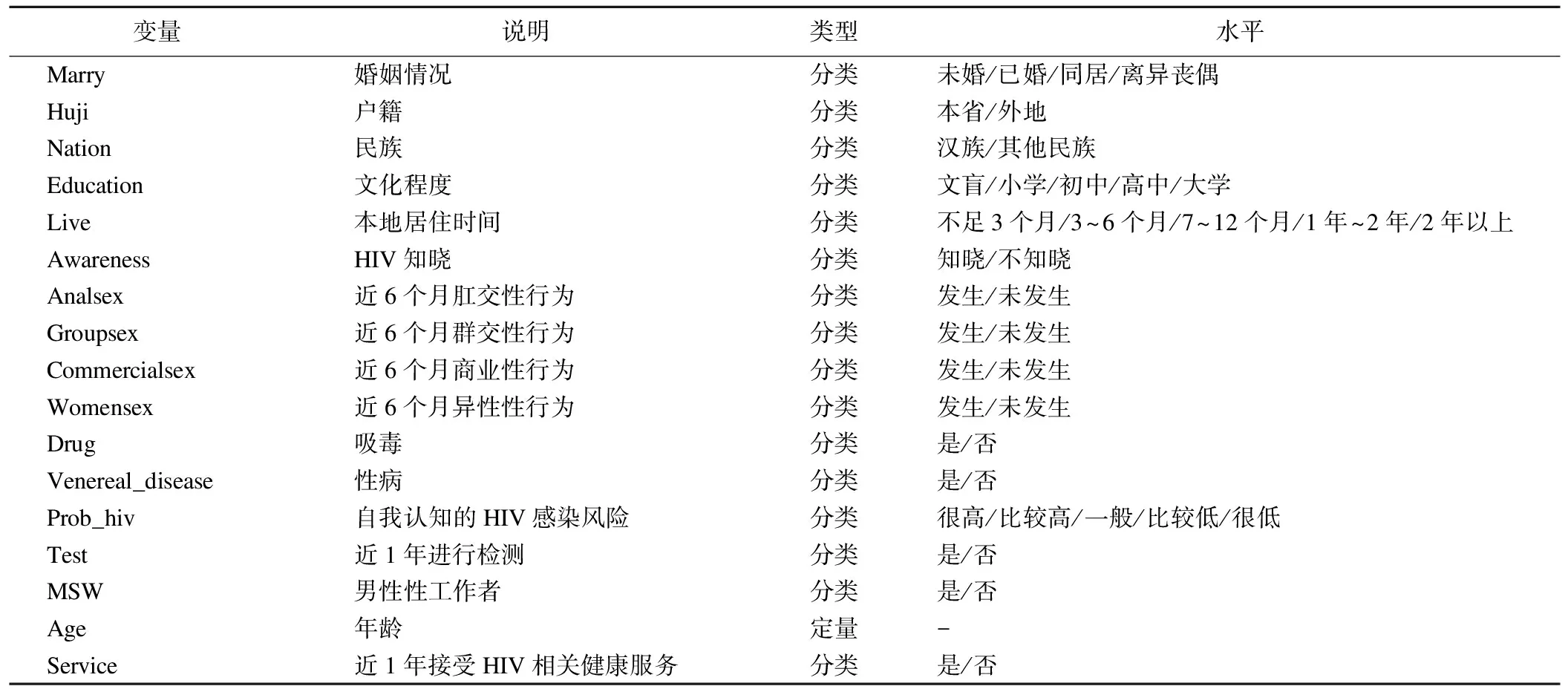
表3 研究中纳入的变量
2.模型构建
(1)原始数据模型构建
经过网格搜索后,各模型确定的超参数如下:
logistic模型:C=0.1;
random forest模型:max_depth=6,max_samples=0.5 ,n_estimators=180;
CatBoost模型:bagging_temperature=9,depth=7,one_hot_max_size=5,iterations=60,rsm=0.5,subsample=0.4,l2_leaf_reg=1
各模型经过10×10折交叉验证以后,模型的构建结果如表4所示。

表4 原始数据各模型建模结果
(2)原始数据SMOTE后模型构建结果
经过网格搜索后,各模型确定的超参数如下:
logistic模型:C=0.7;
random forest模型:max_depth=9,max_samples=0.5 ,n_estimators=30;
CatBoost模型:bagging_temperature=1,depth=10,one_hot_max_size=5,iterations=1250,rsm=0.5,subsample=0.5,l2_leaf_reg=0.03。
各模型经过10×10折交叉验证以后,模型的构建结果如表5所示。

表5 SMOTE后建模结果
上述各模型在测试集上的表现如图1和图2所示:

图1 利用原始数据构建的3个模型在测试集上的表现

图2 SMOTE后三个模型在测试集上的表现
3.模型重要性
图3列出了利用原始数据和利用SMOTE技术后,各模型的变量重要性前8位的变量。

图3 各模型的变量重要性
讨 论
艾滋病目前仍是危害全球公共卫生健康的重要疾病。在目前,MSM是HIV感染风险较高的几类关键人群之一。他们常由于歧视、污名化等原因无法享受到应有的健康服务[16]。因此,建立一种可靠的模型以识别MSM人群中HIV感染者十分必要。
此前,已有一些研究利用机器学习技术来预测在MSM人群中HIV感染的情况[17-18],但其应用的算法在训练之前都需要将分类特征进行预处理,比如one-hot编码等,这在一定程度上增加了训练所需时间并且损失了分类变量的一些信息。而MSM的问卷调查中分类变量较为常见。因此,为了弥补上述缺点,我们使用了Catboost来预测MSM人群中HIV的感染情况。它在训练之前不需要对分类变量进行预处理。在模型训练过程中,Catboost直接利用了target statistic的思想来对分类变量进行处理,以减少分类变量的信息损失。
由于HIV是一种患病率较低的疾病,因此在运用机器学习技术时会经常遇到类不平衡的问题。本研究中,在5091名调查对象中,存在346名HIV阳性患者,阳性人数与阴性人数之比达到1∶13.7。在利用原始数据训练时,三个模型的准确度都达到了90%以上,但F1值都小于0.2,这说明这种类不平衡的问题对于模型评价产生了严重的影响。因此,我们使用SMOTE方法来解决类不平衡问题对于模型评价的影响。在使用SMOTE以后,各个模型的F1值达到了80%以上,说明该方法有效地解决了类不平衡对于模型评价的影响。
本研究发现,在原始数据集上,三个模型在测试集上的表现基本一致,但CatBoost在AUC、Brier score这两个对不平衡数据不敏感的指标上略优于其他两个模型;而在accuracy和F1值上,其他两个模型的表现略优于CatBoost模型;在使用SMOTE技术后,三个模型的在测试集上的表现如表5和图2所示,可注意到,Catboost的表现都明显优于logistic和随机森林,且随机森林的表现在这三个模型中最差。这可能是因为Catboost充分利用了分类变量的信息,其他两个模型都在训练过程中损失了信息,而logistic的表现优于随机森林,则可能是因为模型构建所使用的特征与HIV感染存在较强的线性关系。
本研究中关于变量重要性的分析结果显示,不论是否进行SMOTE的敏感性分析,户籍、婚姻、年龄、文化程度等基本人口学信息,肛交性行为、异性性行为等性行为信息以及性病、男性性工作者等在模型中较为稳定,说明上述特征是预测浴池MSM人群的HIV感染的重要预测因子。这与之前的研究结果基本一致[6]。因此,研究结果对于制定有针对性的干预措施,开展降低HIV感染风险的健康促进,减少HIV在MSM人群中的传播提供科学依据。
综上所述,本研究利用三种理论依据不同的模型分别对浴池MSM人群的HIV感染进行预测建模,针对其中的类别不平衡问题进行SMOTE处理,CatBoost的预测性能均优于其他两个模型,通过实例数据初步论证了CatBoost等机器学习模型结合SMOTE技术对于预测和筛选MSM人群中的潜在感染者的适用性,最终促进MSM高危人群的早发现、早诊断、早治疗。本研究的局限性在于单中心的抽样,还需天津市以外的外部数据进一步验证预测模型的泛化能力。
