基于协同过滤算法的学习资源推荐模型研究
2021-09-28覃忠台张明军
覃忠台,张明军
(广州大学华软软件学院,广东 广州 510990)
0 引 言
随着互联网技术的发展以及教育信息化的普及,在线学习平台被广泛应用于教育培训行业中,用户通过学习平台推荐系统轻松获取自己的学习资源[1]。随着网上学习资源日趋丰富,加之不同的学习用户其属性特征如学习风格、学习偏好和学习水平等会影响用户在学习平台中精准获取自己需要的学习资源[2]。传统的推荐算法在新、旧用户之间的相似度计算时,当存在新用户对学习资源未进行评价或者没有评价过任何学习资源,会产生数据稀疏、延展性差等问题,导致学习资源推荐结果解释性不强;此外,传统的推荐算法由于忽略了用户的行为特性而导致存在用户冷启动问题,使得推荐结果不能给用户带来惊喜[3-5]。针对上述问题,许多学者从不同的技术角度对学习资源进行个性化推荐算法研究,其中协同过滤推荐算法应用最为广泛[6],在推荐算法中综合考虑用户的各种潜在行为信息为用户推荐感兴趣的资源[7-9]。文中提出了基于协同过滤算法的学习资源推荐模型。通过对学习用户和学习资源进行知识建模,利用协同过滤算法,将学习用户模型和学习资源模型融入推荐过程。根据学习用户的属性特征进行学习资源个性化推荐,有效缓解传统推荐技术存在的数据稀疏和冷启动问题。
1 模型构建
学习资源推荐平台包括学习用户、学习资源、关系数据集和CF推荐模块四部分。构建的学习资源推荐模型如图1所示。
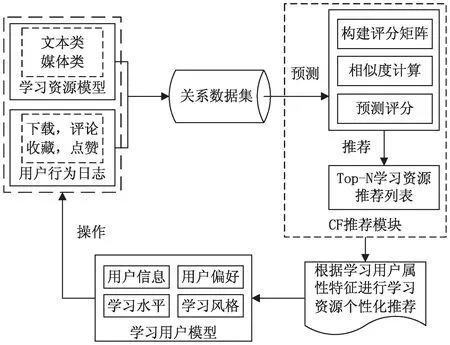
图1 学习资源推荐模型
学习用户模型存储学习用户的学习水平、学习风格、学习偏好等属性特征信息。学习资源模型储存多媒体和文本等格式的学习资源。关系数据集储存学习用户与学习资源本体领域知识的活动行为的关系数据信息。CF推荐模块通过学习用户与学习资源本体领域知识的关系数据集合信息计算目标用户评分的相似度和预测评分,生成目标用户Top-N学习资源推荐列表。最后结合目标用户的属性特征信息将学习资源个性化推荐给目标用户。
1.1 学习用户模型
对学习用户进行学习资源个性化推荐是构建一个完整的用户特征信息库。包括学习风格、学习水平、学习偏好等学习特征以及用户对学习资源的评论、下载、点赞和收藏等行为特征[10]。
定义1:学习用户信息u形式化定义为一个五元组
定义2:用户学习风格s形式化定义为一个二元组
定义3:用户学习水平h形式化定义为一个三元组
定义4:用户偏好信息p形式化定义为一个二元组
定义5:用户行为日志v形式化定义为一个五元组
假设给定行为触发因子λ的值,0为未触发,1为触发;R为行为评分,R=[1,5],β为行为激励因子,β=[0,1],βd、βc、βf、βl分别表示四种行为的激励因子,若存在学习资源对象i和用户u,i∈I,u∈U,du,i、cu,i、fu,i、lu,i表示学习用户u对学习资源i的四种行为评分,则λ*du,i*βd+λ*cu,i*βc+λ*fu,i*βf+λ*lu,i*βl反映用户u对学习资源i的兴趣。
根据上述定义,应用本体描述语言OWL和Protégé工具进行知识建模[11]。构建的学习用户模型如图2所示。
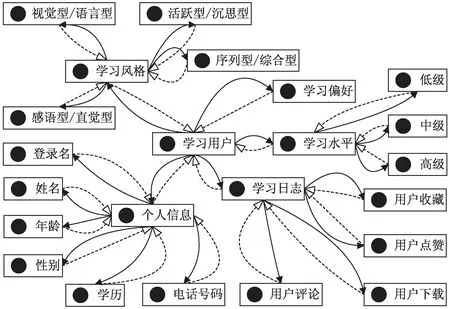
图2 学习用户模型
将学习用户的属性特征信息存储在模型中,模型中的数据随用户的属性特征变化而更新,形成个性化学习用户知识库。
1.2 学习资源模型
在线学习平台上的资源具有学科多样性。通过挖掘学科知识点的关联关系,从知识点中提取相关的实体列表并进行分类,包括音频、视频、动画、图像、课件、教案、案例、作业、试题等,以学科为核心建立学习对象层和学习资源层。
定义6:学习对象层o形式化定义为一个二元组
定义7:学习资源层i形式化定义为一个六元组
根据上述定义,基于Protégé的本体知识建模构建的学习资源模型如图3所示。
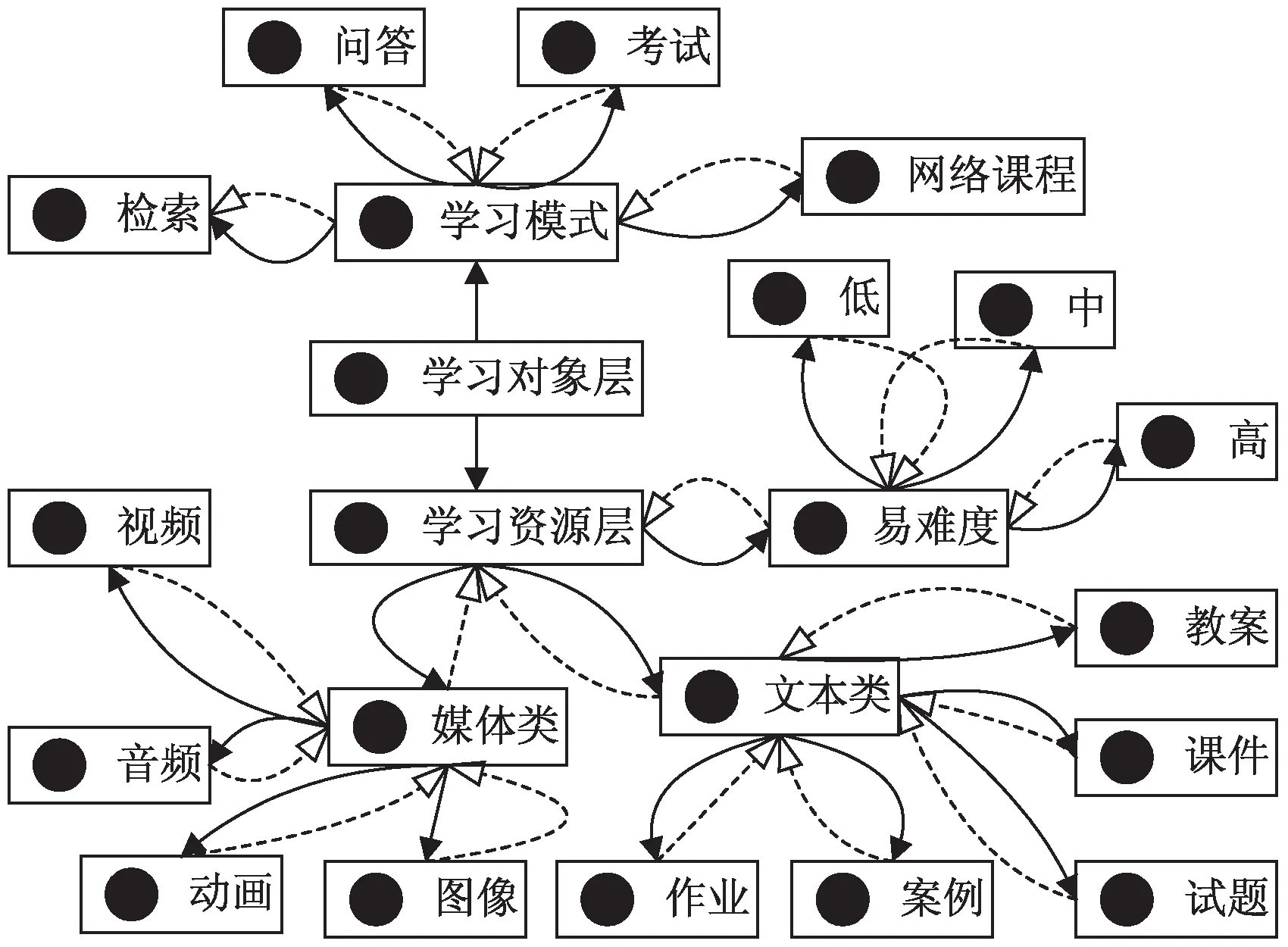
图3 学习资源模型
构建的学习资源模型体现了学习用户之间、学习用户与学习资源之间以及学习资源知识点之间的关系,CF推荐模块通过关系数据集中学习用户和学习资源之间的语义关系对学习资源对象之间进行相似性计算并对目标用户进行预测评分。
1.3 CF推荐模块算法
CF推荐模块通过用户-学习资源评分矩阵构成的关系数据集来计算学习用户对已评分的学习资源对象的相似度,获得学习资源对象的邻居集,预测目标用户对学习资源对象的评分,最后根据学习用户模型的属性特征信息生成个性化学习资源推荐列表并推荐给目标用户。
(1)构建评分矩阵。
学习用户对所有学习资源评分的数据集D形式化定义为一个三元组
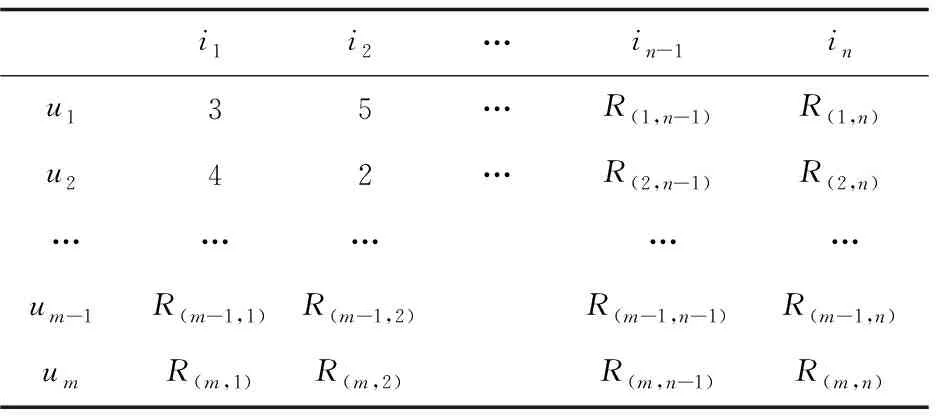
表1 用户-学习资源评分矩阵
(2)相似度计算。
相似度计算是CF推荐模块的关键步骤。常用的相似度计算方法有皮尔逊(Pearson)相关相似度、余弦(Cosine)相似度和修正的余弦相似度[11-13]。对于学习资源平台,用户的兴趣具有固定性和持久性,资源的更新频度具有一定的时间周期性。在建立的学习用户和学习资源模型的基础上,结合学习用户对学习资源的评分,文中采用基于修正的余弦相似度的改进计算方法(标记为MS)来计算相似度。将学习用户的下载、评论、收藏和点赞等行为作为相似因子加入计算式中以提高相似度计算的置信度。假设Ru,i为用户u对学习资源对象i的评分,Ru,j为用户u对学习资源对象j的评分。根据定义5,则有:
Ru,i=λ×du,i×βd+λ×cu,i×βc+λ×fu,i×βf+
λ×lu,i×βl
(1)
Ru,j=λ×du,j×βd+λ×cu,j×βc+λ×fu,j×βf+
λ×lu,j×βl
(2)
学习资源对象i和j的相似度计算公式sim(i,j)如下:
sim(i,j)=MS=
(3)
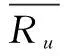
(3)预测评分。
根据式(3)得到的最近邻居集,预测目标用户对学习资源对象的评分。假设Pu,i为目标用户u对学习资源对象i的预测评分;N为与学习资源对象i的邻居集,由式(3)计算得来,且k∈N,k为邻居集N中的学习资源对象之一,sim(i,k)为学习资源对象i与邻居集N中的学习资源对象k的相似度;Ru,k为目标用户u对学习资源对象k的评分。则目标用户u对学习资源对象i的预测评分为:
(4)
1.4 模型实例的执行及CF算法流程
定义8:学习用户模型实例w形式化定义为一个六元组
定义9:学习资源模型实例k形式化定义为一个四元组
根据定义8和定义9,用W表示所有学习用户模型实例的集合,W={w1,w2,…,wn}。用K表示所有学习用户与学习资源本体领域知识的关系数据集合,K={k1,k2,…,kv},其中kj={wj,ij}。用R表示学习用户对学习资源的评分集合,R={1,2,3,4,5}表示评分范围。用户进入E-learning平台参与在线学习活动的过程:
(1)用户从定义8的W中启动用户实例w。如果用户第一次进入平台,从定义1中进行个人信息注册。获取该用户实例名称n,建立一个新的用户实例结构u,其中Wu=nw。
(2)通过学习平台推荐模型进行语义搜索,分析学习用户属性特征并确定学习偏好、风格及水平。当∃St=∅,则St←0‖1‖2‖3;当∃Pd=∅,则Pd←用户填写偏好信息;当∃Hg=∅,则Hg←随机进行学习水平测试。
(3)在CF推荐模块中输入I,K,R,分析用户行为日志,显式获取学习用户Vd、Vc、Vf、Vl等行为信息。算法流程如图4所示。
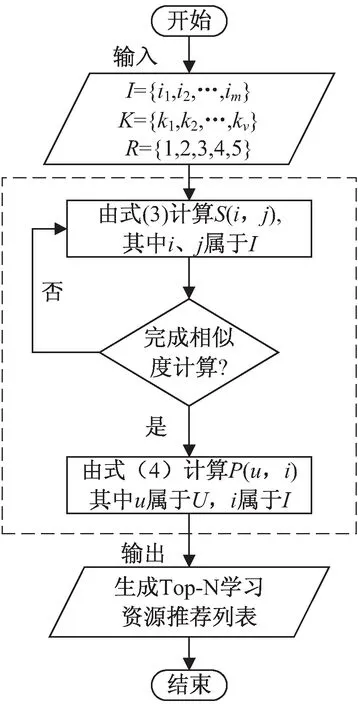
图4 CF推荐算法流程
(4)CF推荐模块计算出目标用户w对未评分学习资源对象i的预测值,然后根据预测值由高到低确定n个排在最前的项作为top-N推荐集结果。在分析学习用户属性特征的基础上,当∃St=0‖1‖2‖3,则nw←推荐适合学习用户学习风格的资源;∃Pd≠∅,则nw←推荐适合学习用户偏好的资源;当∃Hg=0‖1‖2,则Hg←推荐适合学习用户水平层次的资源。
(5)由上述推荐结果,用户从定义9的I中启动推荐的学习资源实例i。获取该学习资源实例名称n,建立一个新的学习资源实例结构p,其中Ip=ni。
(6)当∃nw→ni,则系统记录用户日志行为:Vd←下载,Vc←评论,Vf←收藏,Vl←点赞。
将构建的学习用户和学习资源模型融入CF推荐模块,提高学习资源检索的效率与准确度,当新用户进入学习平台推荐模型时,会根据学习用户属性特征信息进行语义搜索、分析并确定其学习偏好,与学习用户模型进行匹配,从而为目标用户实现学习资源个性化推荐,缓解了用户的冷启动问题。
2 模型测试及实验分析
2.1 测试数据集
实验数据来源于本校精品资源网络课程学习平台,目前学习平台注册用户有6 000多人,用户评分过的学习资源超过1 000个。从系统中抽取300个用户数据进行实验测试,数据集结构如表2所示。
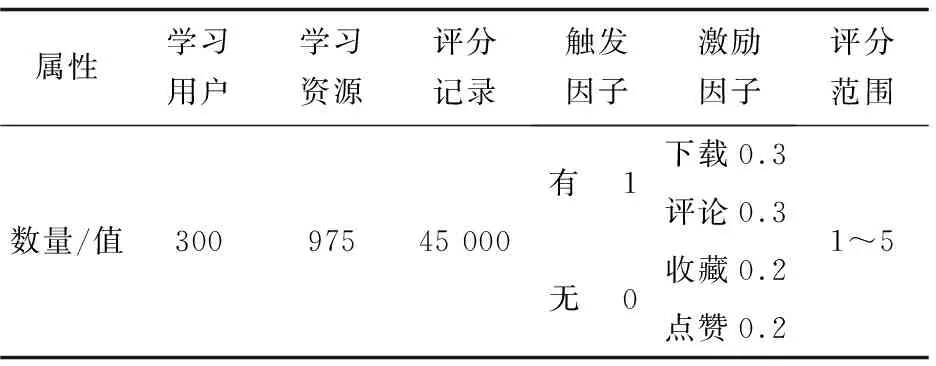
表2 数据集
分析数据集中的用户行为日志,若有下载、收藏、评论、点赞等行为,将触发因子设为1,反之设为0,为每种行为设定0~1之间的激励因子。根据表1设计的评分矩阵,评分范围为1~5,1为非常不感兴趣,5为非常感兴趣,0为未评分。将实验数据随机分成5份,其中4份用作训练集数据进行学习训练生成推荐结果,构建推荐模型;另外1份用作测试集数据进行验证推荐结果,实验时进行多次交叉验证。
2.2 测试结果与分析
为验证文中提出算法的有效性,将MS相似度算法与余弦相似度(Cosine)和皮尔逊(Pearson)相关相似度进行评价比较。评价标准采用推荐算法的MAE评价指标[14],通过MAE的平均绝对误差准确预测学习用户的评分来评估算法的有效性。计算公式为:
(5)
其中,MAE为平均绝对误差,yi为学习用户对学习资源的预测评分,xi为学习用户对学习资源的实际评分,n为预测评分的次数。在测试过程中,设置近邻个数按照步长为10,从10增加到100,计算使用MS、Cosine和Pearson三种不同相似性度量方法时的MAE值,三种算法的MAE实验结果如图5所示。
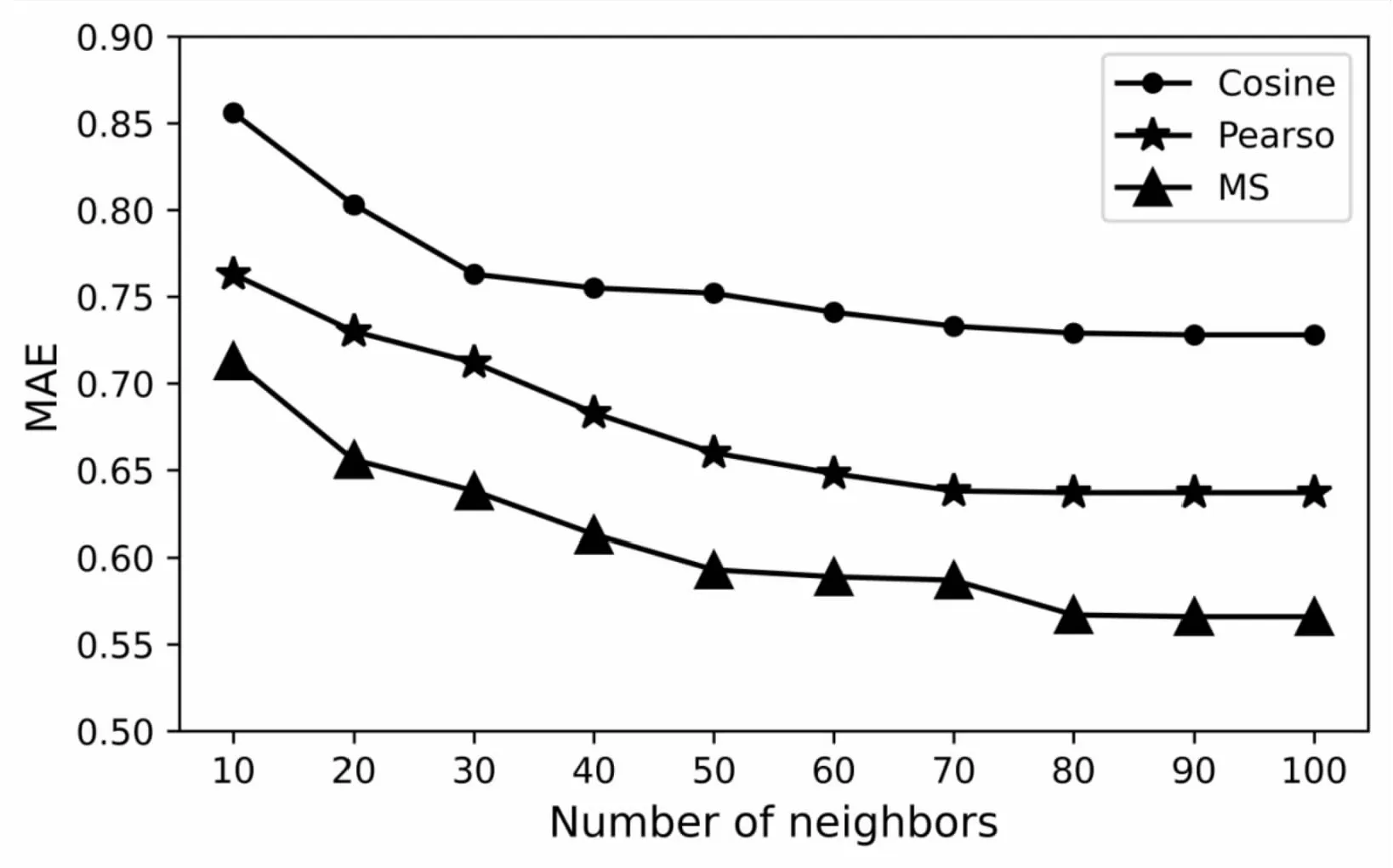
图5 Cosine、Pearson和MS的MAE值
由图5可看出,在相近邻居不断增加的情况下,MS算法的MAE值均比Cosine和Pearson的MAE值低,且逐步递减,这说明了数据的稀疏性在降低,MAE值越低,算法的准确率越高。从走势线图可看出,MS在测试的后面是逐步势于平稳,显示出MS算法在邻居集数量进一步增加情况下的推荐性能具有一定的平稳性。实验证明,在融入学习用户的属性特征信息的MS算法提高了用户邻居集的识别精度,有效缓解了数据的稀疏性和用户冷启动问题,提高了学习资源的个性化推荐,具有较强的解释性,推荐结果优于传统的推荐算法。
3 结束语
针对在线学习平台在传统的推荐算法中存在的数据稀疏性和冷启动问题,研究了基于协同过滤算法的学习资源推荐模型。在给出学习资源推荐模型的基础上构建了学习用户模型和学习资源模型,使用基于修正的余弦相似度的改进计算方法进行相似度计算和预测评分,获得潜在的推荐学习资源对象,将学习用户的学习风格、学习水平、学习偏好等属性特征融入推荐过程进行学习资源个性化推荐。通过与传统的推荐模型对比,该推荐模型在推荐精度和个性化方面具有一定的优势,有效缓解了传统推荐算法的数据稀疏性和冷启动问题。
