基于领域特征指示词的隐式特征识别研究
2021-09-28王汝传
陈 莹,叶 宁,徐 康,王汝传
(1.南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210046;2.江苏省无线传感网高技术研究重点实验室,江苏 南京 210046)
0 引 言
依托互联网+逐层推进的时代背景,足不出户的网购以不可逾越的地位占据人们的内心世界,参与网购的人数与涉及的商品服务种类与日俱增。可见,网购俨然成为一种时尚的潮流[1]。由此衍生出的在线评论数据呈爆发式增长并且蕴含着巨大的潜在价值[2]。对这些数据的有效挖掘可以帮助公司和商家深入了解消费者需求,从而提高产品的质量。但是,仅从文档层面或句子层面分析还不足以探究用户的意见。人们通常对产品的各个方面进行评论,包括产品的组成部分以及属性。因此,有必要对产品特征级别的观点进行提炼,而不是针对整个产品或整个评论文本。
然而,分析客户评论以获得更细粒度理解的自动化任务面临着许多挑战,特别是由于在客户评论中并不总是显式地提出。已有的技术和研究大都只是致力于从评论语料中挖掘和抽取在评论语句中显式出现了的评价对象[3]。而根据Kim和Flavius的研究可知,产品中许多重要的特性也会被消费者含蓄地提到[4]。例如评论句“手机很小,可以放进我的口袋里”隐式地表达了关于手机“尺寸”方面的意见。隐式特征的提取是一个复杂的问题。文中主要研究隐式方面识别。
考虑如下关于电子产品领域的评论:
例子1 “很棒,很顺畅不卡顿。”
例子2 “还不错,可以随身携带。”
例子3 “昨天下单,今天收到货了。”
这些评论句不难发现都有一个共通之处即不包含明确的特征词。但在例句1中,根据观点词“顺畅、卡顿”可轻易推断出用户是在描述系统这一特征。例句2中有观点词“不错”,但由于其适配性很难仅从词语本身识别出特征,结合下文中提到的“随身携带”可知用户是想表达关于“尺寸”这一特征的观点。例句3中没有任何评价词,但根据“收到货”这一非观点词可知是在描述“物流”这一特征。所以,根据上述分析可知,借助评论句中的观点词或非观点词可间接地识别出隐式特征。
在现有的研究中,隐式特征识别大致采用共现分析、关联规则、主题模型及分类等方法,其中基于共现和关联规则的关系推断法最普遍[5]。这两种研究方法主要是依赖观点词与特征属性之间的映射关系,利用带有标签的语料库训练模型来提取隐式特征。但随着线上交易量的日益剧增,在线评论的数据量也越来越多,需要消耗大量人力资源。研究者开始专注于无监督方法。主题模型,如PLSA和LDA,在自然语言处理的许多任务中很流行,它们也可以用来识别隐式特征[6-7]。
但这些方法没有考虑在没有观点词的情况下非观点词对识别隐式特征的指导性,而且有的方法也忽视了词的语义信息,使得隐式识别的精度和准确度不是很高。所以,文中面向隐式特征识别这一研究难点,提出了一种基于领域特征指示词的隐式特征识别方法。该方法首先利用多词型的主题情感联合模型自动地从包含显式特征的评论句中挖掘出“特征-情感”和“特征-非观点”词对集,整合成特征指示词集;再引入词向量模型作为衡量隐式评论句中线索词与特征指示词集中词项语义相关度的标准;最后根据线索词的类型对隐式特征分情况进行识别。
1 相关工作
隐式特征首先在Liu等人中进行了讨论[5],他们给出了隐式特征的定义。从那时起,一些研究开始关注隐式特征的识别。目前的研究可分为监督识别、无监督识别和半监督识别三类。文中主要基于无监督识别展开研究。
Prasojo等人扩展了传统的命名实体识别方法,利用形容词到方面的映射将特征集关联到每个实体[8],然后,他们选择频率最高的特征作为目标。Santu等人结合一个背景语言模型和几个特征语言模型生成评论中的每个单词。他们通过期望最大化(EM)估计参数,并检测最终的隐含特征列表[9]。Xu等[6]预先定义特征类别,将在包含显式特征的评论句中得到的约束和先验知识纳入主题模型LDA得到特征类别的相关词语,以这些词语为特征对评论句建模,通过构建SVM分类器识别隐式特征。Sun等[7]使用联合主题模型进行隐式特征提取。他们将与隐含特征相关的意见词分为两类,即特殊意见词和一般意见词。一般意见词可以与许多不同的特征共同出现,而特殊意见词只与一个特定的特征共同出现。他们计算了两个概率分布,一个是主题的意见分布,另一个是主题和意见的上下文分布。最后,他们使用这些值进行隐式特征提取。张莉等基于领域中的常用词对特征词进行聚类,通过精简意见词和对其进行同义词扩展,构建<特征 观点 权重> 三元组字典,用于识别隐式特征[10]。
此外,还有许多其他方法,如关联规则挖掘(Zhang等)[11]和共现关系(Rana and Cheah[12];Makadia[13])用于无监督隐式特征识别。
2 方 法
2.1 总体流程
文中所提出的方法具体如图1所示,主要包括三个步骤。首先,利用多词型的主题情感联合模型进行特征主题聚类并从显式评论句中提取出“特征-特征指示”词对集;接着,使用语言技术平台LTP对隐式评论句进行词性标注,产生候选线索词,利用词向量模型计算线索词与特征指示词的语义相似度为线索词匹配特征指示词;最后,根据所匹配到的特征指示词类型分情况采用不同的方法进行隐式特征的指派。

图1 基于领域特征指示词的隐式特征识别方法框架
2.2 多词型的主题情感联合模型
2.2.1 模型概述
ASUM(aspect and sentiment unification model)模型基于LDA(latent Dirichlet allocation)进行改进,假设每个句子只有一个主题以及这个主题下的情感倾向。因此,模型的主要目的便是从评论文本中提取出每一个句子中的(特征,情感)对,以此作为情感分析的依据[3]。但是ASUM并未区分表示主题的词语是特征词,或特征指示词还是情感词,要想明确得到词语的类型,还需要人为地进行辨别。因此,为了能从显式评论句中自动挖掘出基于领域的“特征-情感”和“特征-非观点”词对集并充分利用主题模型的主题(特征)聚类性质,文中基于ASUM模型的假设提出一个多词型的主题情感联合模型。该模型通过加入表示单词类型的隐含变量,建立其与单词的关系,进一步获得类型同单词的概率分布,从而可以识别出单词的类型。
多词型的主题情感联合模型的图形化表示如图2所示,相关的变量和符号在表1中给出解释。

表1 多词型的主题情感联合模型图字母含义
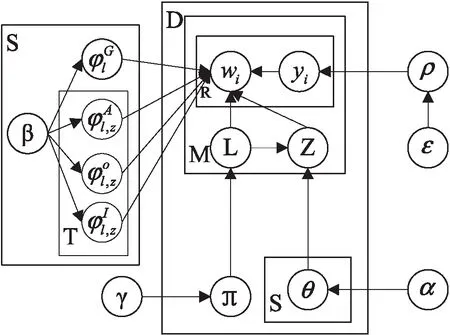
图2 多词型的主题情感联合模型图形化表示
多词型的主题情感联合模型通过引入一个隐含变量y来表示单词的类型。y∈{0,1,2,3}分别表示单词w是一个通用情感词,特定的情感词,特征词以及非观点特征指示词。模型根据一个先验的狄利克雷分布生成词语的类型分布,狄利克雷分布是多项式分布的共轭分布,共轭的特性可以使得先验分布和后验分布的形式相同,可以形成一个先验链[8]。
大多数的产品评论其实都是一句话包含一个特征以及对其评价观点,所以为了挖掘针对同一实体产品的评论集中不同特征以及观点,此模型假设同一个句子的单词属于同一个主题(特征)和情感极性,则每一篇文档在此模型下的生成过程如下:
(1)生成一个词的类型分布ρ~Dir(ε);
(2)生成一个情感分布πd~Dir(γ);
(3)对每一个情感倾向l,生成一个主题分布θd,l~Dir(α);
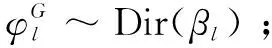
(5)对于每一个情感倾向l和主题z,生成三种类型的词语分布:
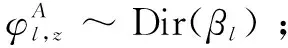

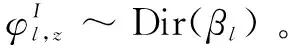
(6)对于文档中每一个句子:
(a)选择一个情感标签l~Multi(πd);
(b)选择一个主题z~Multi(θd,l)。
(7)对于每一个单词wi∈d:
(a)将它所属文档的情感标签l分配给它;
(b)选择一个主题zi~Multi(θd,l);
(c)选择单词的类型yi~Multi(ρ);
(d)选择单词wi:
2.2.2 参数估计
多词型的主题情感联合模型的参数估计使用了吉布斯采样。在采样初始化过程中,引入情感词典、领域情感词典以及领域特征词典作为先验知识,以便能更准确地采样出词语的类型。具体做法就是,在初始化时遍历所有文档中每一个单词,若单词存在于这三个词典里,便对其标注相应的词语类型。
为了获得π,θ,φ和ρ,在吉布斯的采样过程中会依次采样出每一个单词的主题,情感倾向以及单词的类型。现在大多数产品评论都是内容精短但语义信息丰富的形式,若单纯将每一个评论看作是一篇文档,会因为文本的稀疏性造成采样结果准确率不高的情况。而文中是为了挖掘某一实体产品的不同特征,其评论都是围绕产品不同特征进行评价,评论句之间都有一定的语义相似度。所以为了解决评论文本稀疏性问题,文中在多词型的主题情感联合模型的采样过程中,将所有评论看作是一篇长的伪文档进行采样。首先,为每一个单词采样一个主题和情感标签,主题和情感标签是联合采样,采样条件公式如公式(1)所示,公式中具体符号含义在表2中给出解释。
(1)
接着对词语类型进行采样。基于狄利克雷的先验分布,第i个单词的词语类型y的采样条件公式如公式(2)所示,公式中具体符号含义也在表2中给出解释。

(2)
p(yi=t|y-i,l,z,w)∞
为了后续隐式特征识别的引用,将从显式评论中挖掘出的特征指示词对集整合成如下形式。每一个特征类别(F1F2…Fm)下对应一般情感词、特征情感词以及非观点情感词三种类型词语,每一种词类型下保留概率top 20的词语,对其进行筛选,留下语义相关性强的词语,如表3所示。
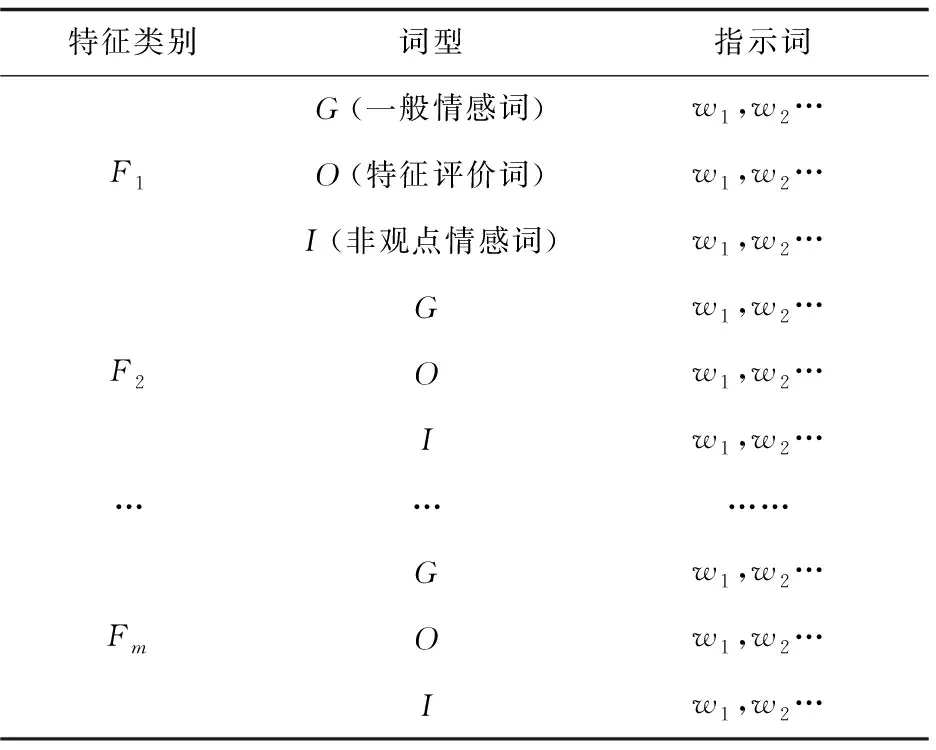
表3 特征-词型-指示词
2.3 隐式特征识别
文中基于特征指示词集识别隐式特征,关键步骤就是为隐式评论句中的线索词寻找到最匹配的指示词。利用多词型的主题情感联合模型所挖掘出的特征指示词集虽然在主题聚类以及自动化方面比较好,但会因为基于词共现的原理而忽视一些低频但语义相关度很高的词语,使得匹配指示词的结果不是很成功。所以,为了能在特征指示词集中成功匹配到与线索词相关联度最高的指示词,引入了词向量模型。
词向量概念Word2Vec的核心思想是通过上下文学习词的向量表示。词向量的表示能够反映词的语义信息并且利用其空间距离可测度词项间的语义关联度。词向量有CBOW(continuous bag of words)和Skip-gram 两个重要模型,二者主要的区别在于CBOW利用上下文预测词项,Skip-gram则是根据词项预测上下文。文中选择CBOW模型,借助Python的Genism工具包构建词向量,向量维度100,上下文窗口尺寸5[10]。

(3)
隐式评论句中的线索词一般为观点词和非观点词两种。文中利用语言技术平台LTP对评论句进行词性标注,保留下形容词、名词或名词性短语以及动词或动词性短语作为候选线索词和上下文词。为了提高隐式特征识别的准确率,依据隐式评论句中线索词的类别对隐式特征分情况进行识别。
具体步骤如下:
Step 1:选择线索词。若评论句中有形容词,则将形容词视为线索词。否则,将动词或动名词视为线索词。
Step 2:匹配特征指示词。若线索词是形容词,利用公式(3)计算其与表3中G和O两种类型下词语的关联度,选择关联度最高的词项作为其特征指示词。若线索词是动词或动名词,利用公式(3)计算其与表3中I类型下词语的关联度,也是选择关联度最高的词项作为其特征指示词。
Step 3:依据特征指示词的类型分情形识别隐式特征。
(1)特征指示词是特定情感词或非观点词,将其所属特征类别直接匹配给线索词。
(2)特征指示词是一般情感词,需要结合线索词的上下文词。选定线索词邻近的名词或动词作为上下文词,并根据公式:
(4)
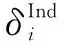
计算公式如下:

(5)

(6)
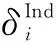
算法1:描述了隐式特征识别的过程。
Algorithm 1:隐式特征识别
输入:线索词集Wcue,线索词的上下文词集,特征指示词集WInd
输出:相匹配的隐式特征集
1 对Wcue里的每一个线索词wcue:
2 如果wcue是形容词:
3 对特征指示词集WInd里一般情感词和特定情感词类型下的每一个特征指示词wInd:
4 计算余弦相似度sim(wcue,wInd);
5 循环结束
6 否则
7 对特征指示词集WInd里非观点词类型下的每一个特征指示词wInd:
8 计算余弦相似度sim(wcue,wInd);
9 循环结束
10 得到线索词语义相似度最大的特征指示词wInd',特征指示词的类型及其所属特征;
11 如果wInd'的类型是特定观点词或非观点词:
12 预测wInd'所属的特征为相对应线索词的目标特征;
13 否则
14 利用线索词的上下文词和wInd'计算候选特征集的得分;
15 预测得分最高的候选特征为相对应线索词的目标特征
3 实验结果与分析
3.1 数据集选择
文中使用了五个不同产品的用户评论来评估所提出的方法,分别是酒店、手机、平板、计算机和衣服。每种产品的评论数量是10 000条。使用Python工具包nltk和语言技术平台LTP对评论进行分句、去除停用词、分词和词性标注等操作。经过筛选,各产品的隐式评论句大约占评论总数的25%左右,可见识别隐式特征具有重要的意义,能够更全面捕捉特征信息,进一步提升情感分析的精度。
3.2 参数设置
为了训练多词型情感主题情感联合模型,依据文献[14],将参数γ设置为1,表示各种情感出现的概率相同。参数β为了结合种子词,采用非对称取法,负向单词情感采样的时候,正向单词的先验为0,其他设为0.001,同理正向采样时,负向单词先验为0,其他也设为0.001。参数α和参数ε则分别设置为0.1和0.25,迭代1 000次。
3.3 评价指标
文中使用精准度precision以及召回率recall作为评价指标,如公式(7)和公式(8)所示。
(7)
(8)
3.4 实验结果分析
3.4.1 特征指示词集
在进行隐式特征识别之前,首先需要建立一个“特征-特征指示”词对集。表4展示了一个关于酒店的显式评论句的挖掘结果样例。实验设定主题(特征)个数为8,依据各主题下的特征词描述可知这8个特征分别为:地理位置、环境、服务态度、酒店设施、餐饮、价格、网上预订以及人气。可以发现地理位置、价格、服务态度和酒店设施这四个类别下不同类型的词语分布比较均匀,而环境、餐饮、网上预订以及人气这四个类别则是某一类型下的词语分布比较突出。由于主题模型依赖数据质量,使用的数据量不够,出现了一些无效词。

表4 特征指示词集
3.4.2 隐式特征识别
文中识别隐式特征很大程度上依赖于多词型的主题情感联合模型的采样结果和词向量模型的训练,而在线索词为一般情感词的情况下又考虑了上下文的权重。文献[7]基于标准LDA模型提出了一种改进的主题模型联合主题-意见模型(JTO),用于提取意见词的隐含特征,包括特殊意见词和一般意见词。文献[15]试图通过构建改进矩阵和实现LDA主题模型来得到两个概率分布。采用余弦相似度考虑上下文权重,计算意见词候选特征的得分来实现隐式特征识别。所以,文中选择与文献[7,15]中用到的方法进行比较。评估指标的计算依赖于手工注释。结果如图3和图4所示,其中JTO和CW分别表示文献[7]和文献[15]中所用的方法,MI则表示文中方法。
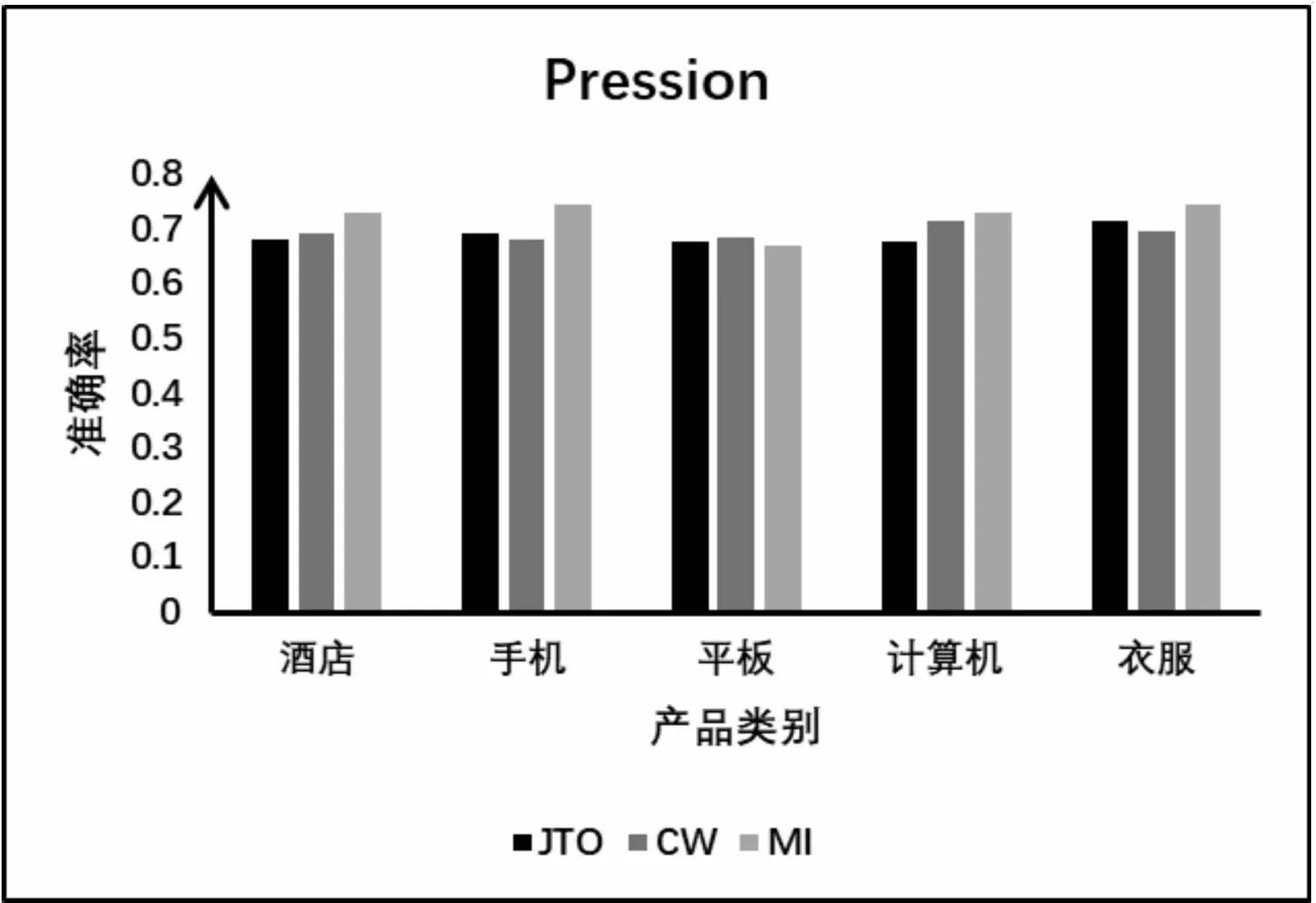
图3 隐式特征识别的准确率
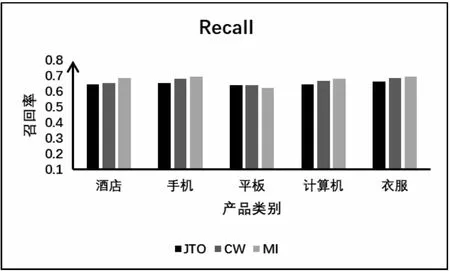
图4 隐式特征识别的召回率
依据图中数据可以看到,在平板这产品数据集上,MI方法的准确率和召回率比JTO和CW要低,有可能是因为多词型的主题情感联合模型在这一数据集上的表现不是很好。而在整体上,经过统计发现MI方法在精确率和召回率上比文献[7]中JTO方法平均高出3%,比文献[15]中CW方法平均高出2%,这可能是因为JTO和CW虽然考虑了观点词和上下文词的权重,但却忽视了词的语义信息和非观点词的指示性。综合上述分析,证明了文中提出的基于领域特征指示词的隐式特征识别方法的有效性。
4 结束语
文中提出了一种基于领域特征指示词的隐式特征识别方法。该方法首先通过在ASUM模型中加入表示词语类型的隐含变量构建多词型的主题情感联合模型,利用该模型对特定领域的显式评论句进行特征类别下指示词的挖掘。然后,在隐式特征的识别过程中,引入词向量模型作为衡量隐式评论句中线索词与特征指示词集中词项语义相关度的标准,并根据线索词的类型来分情况实现对隐式特征的指派。实验表明,该方法在隐式特征识别方面有着较好的精确度与召回率。但是该方法只能识别隐式评论句的特征类别,却不能进一步识别其所表达的情感倾向。所以在以后的工作中,将尝试研究评论句中隐式情感的识别,以获得评论用户更全面的情感信息。
