基于Stacking集成学习的汽车金融违约风险预测研究
2021-09-27郭文博
郭文博
摘要:目前汽车金融贷款的市场增长较快,各个银行竞争激烈,同时各类汽车贷款公司、互聯网金融平台也加入了市场竞争。在为了在市场竞争中取得一定的优势,银行需要提升自身的风控水平以及效率。本文在文献研究以及理论研究的基础上,构建基于Stacking集成学习的模型,对汽车金融贷款违约风险进行预测。
关键词:金融科技;汽车金融;Stacking集成学习
一、研究背景
自2001年人大在十一五纲要中确立汽车进入家庭的政策激励开始,汽车市场在这十五年期间发展迅速,在中国加入世贸组织迎来全球化冲击的助推下,中国汽车市场已经成为世界第一的汽车产销大国。2018年我国乘用车市场累计销售超过1871万辆,汽车保有量超过2.35亿辆。随着汽车行业的发展,汽车贷款金融市场也有了较快的增长,汽车金融占汽车产业链利润结构的23%,汽车零部件占22%,汽车维修占18%,整车制造和整车销售分别只占16%和5%。2018年12月,汽车贷款余额为9900亿,预计至2020年信贷市场规模将超过1.2万亿,至2022年将超过1.4万亿元,汽车金融市场具有广阔的市场。
目前汽车金融贷款的市场增长较快,各个银行竞争激烈,同时各类汽车贷款公司、互联网金融平台也加入了市场竞争。在为了在市场竞争中取得一定的优势,银行需要提升自身的风控水平以及效率。目前各个互联网金融公司逐渐开始尝试使用数据挖掘模型来进行汽车贷款的风险控制,因此本文研究Stacking集成学习等数据挖掘模型在汽车贷款信用评价中的应用,对于提升银行在汽车贷款中的风险控制水平具有一定的价值。
二、模型构建
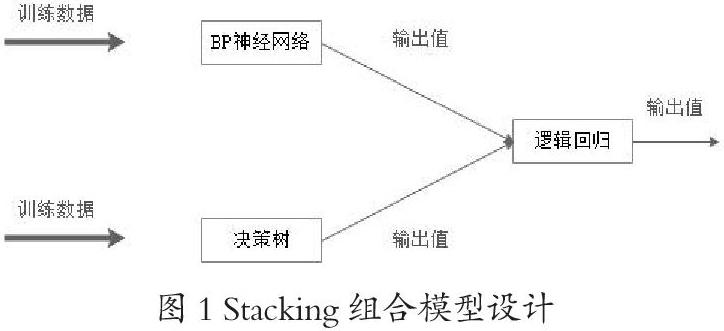
Stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。Stackking分析的原理是将样本数据中抽取训练数据,然后由不同的单一学习器进行学习,学习器可以训责神经网络、决策树等不同的模型,这些模型的输出结果作为单一学习器的输入继续进行学习,并最终输出结果。本文设计了基于stacking的组合模型,如图1所示。
本文采用BP神经网络、决策树作为第一层初级学习器,将学习结果输出到逻辑回归进行第二次学习,并最终输出结果。学习过程如下:
(1)把训练样本集打乱,并分成两个没有交集的数据集;
(2)选择第一个数据集,在此数据集上训练决策树以及BP神经网络;
(3)在第二个集合测试第一个集合得出的模型;
(4)把第三步获得的模型结果当作输入,把正确的标记作为输出,训练次分类器。
本文采用R语言的caretEnsemble包实现stacking模型,caretEnsemble中的caretStack函数能够基于不同学习器进行stacking组合,本文模型的实现代码如图5-4所示,其中models创建了第一层的基础学习器,rpart代表决策树模型,nnet代表BP神经网络;caretStack表示第二层的学习,采用逻辑回归(logit)对第一层的输出进行学习。
3、实证分析
本文采用以下指标进行实证分析。
实证结果如下,Stackking模型能够正确区分250个正常样本中的231个样本,有19个样本被误判为存在违约风险,模型对于正常样本的预测正确率为92.4%。模型对于100个存在违约风险的样本能够正确识别其中94个样本,但是对于其中6个存在违约风险的样本进行了漏判,准确率为94%,模型的综合准确率为92.85%。逻辑回归模型能够正确区分250个正常样本中的216个样本,但是有34个样本被误判为存在违约风险,模型对于正常样本的预测正确率为86.4%。模型对于100个存在违约风险的样本能够正确识别其中85个样本,但是对于其中15个存在违约风险的样本进行了漏判,准确率为85%,模型的综合准确率为86%。Stacking模型提高了对汽车金融违约风险的预测性能。
4、研究总结
随着汽车行业的发展,汽车金融贷款的规模不断增长,对贷款信用风险的评价变得越来越重要。本文构建了基于Stacking集成学习模型对汽车贷款违约风险进行预测,并使用银行的实证数据进行了分析,Stacking集成学习模型在测试样本集上的表现优于逻辑回归等模型。
参考文献:
[1]杨光飞, 崔雪娇, 张翔. 基于抽样和规则的不平衡数据关联分类方法[J]. 系统工程理论与实践, 2017, 37(4):1035-1045.
[2]崔晴. 基于PSO-LSSVM的中小企业信用风险评价研究[D]. 河北工程大学, 2017.
[3]吴煜宁. 供应链金融信用风险评估方法研究[D]. 西北农林科技大学, 2018.
