一种高精度低开销的FFT设计
2021-09-27北方工业大学信息学院皮义强
北方工业大学信息学院 戴 澜 皮义强
随着5G等先进通信技术的快速发展,系统对FFT的精度和成本开销要求越来越高。本文提出了一种定点递归结构的高精度低开销1024点FFT设计方法:设计了一种简单有效的地址产生方案对蝶形运算单元所需数据的无等待访问,使蝶形单元在每个运算阶段都处于高利用率状态;提出了一种新颖的定点算法,在保留定点运算结构简单、资源消耗少等特点的基础上有效得提高了结果的精度。使用MATLAB进行仿真分析,输出信噪比为64.4dB,基于SMIC 130nm标准单元库对处理器进行综合,在PVT条件为SS/1.08V/125℃下,面积为36.34kGE,吞吐量为1.50Gbps。
快速傅里叶变换(FFT)是离散傅里叶变换(DFT)的一种快速算法。FFT实现了数字信号的实时处理,并在超声、雷达、通信等领域得到了广泛的应用。不同的应用场景对FFT的功能需求各有侧重,在OFDM应用中,FFT的精度和硬件开销对系统性能有着更加显著的影响。目前,FFT运算的数据格式可以分为定点、浮点和块浮点三种类型,浮点运算在三种方式中精度最高,但电路结果较为复杂且吞吐率低,定点运算在硬件上最容易实现,往往不需要对输入待计算数据做任何处理,但在移位、截位等操作后会引入误差,尤其在多次进行此类操作后,误差将不断累积而造成输出结果精度的大幅降低。
在ASIC的结构实现方面,FFT主要有递归结构、级联结构、并行结构和阵列结构等,并行结构和阵列结构运算速度块,但控制复杂,资源消耗多,适用于对速度要求很高的场景。递归结构通过重复使用蝶形运算单元、存储器等方式有效的降低资源的消耗程度。苏斌、刘畅等提出了一种的高速、高精度的FFT处理器架构,但该架构由8路并行运算实现,故资源占用率很高。综合上述考虑,本文设计了一种基4算法的、采样点数为1024的FFT处理器,输入输出数据为13bit,采用递归结构降低资源消耗,良好的数据调度模式使蝶形运算单元满负荷运行,设计实现了一种新颖的定点算法,通过简单位移操作,有效地提高了运算精度。
1 基4-FFT算法
设X(n)为N点有限长序列,其离散傅里叶变换(discrete fourier transform,DFT)为:
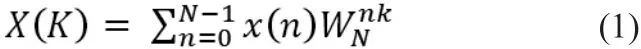
其中,旋转因子为:

当序列长度N满足N=时,按时钟抽取的DFT算法为:
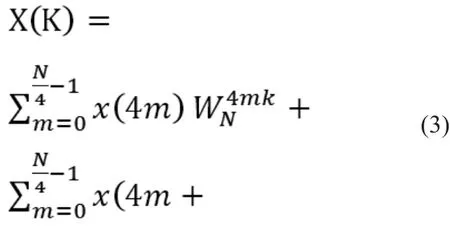
进行变量替换后有:
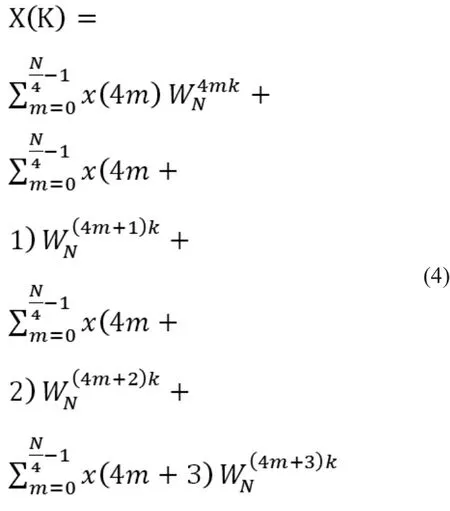
由上式可知,每一组4点数据进入蝶形运算单元后先进行复数乘法,由于A所对应的旋转因子不需要乘,故只有3次旋转因子乘法,随后进行两级复数加法按同址输出结果。
2 FFT的设计方案
2.1 FFT整体结构
如图1所示,FFT整体结构包括7个部分:RAM地址生成单元,用于在各个阶段生成读写两组RAM的地址;旋转因子地址生成单元,本设计中对RAM和ROM的访问并不同址;蝶形运算单元;存放蝶形运算数据的两组RAM,每组RAM由四块容量为256的单口RAM构成;三块存储旋转因子的ROM;控制单元,由控制运算阶段跳转的状态机构成;多个移位模块,其和定点运算的优化有关。一组1024个定点数据通端口串行输入,经过移位处理后乱序存入A组RAM中,随后在RAM地址生成单元和旋转因子地址生成单元的控制下,从A组RAM和ROM中提取运算数据和旋转因子放入蝶形单元中进行运算,将结果进行移位优化处理后写入B组RAM中,继续执行下一级蝶形运行,此时B组RAM成为数据源,A组RAM成为数据存储目标,当五次蝶形运算结束后,结果存放于B组RAM中,将数据通过端口串行输出。
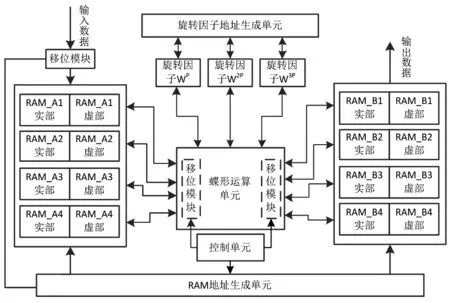
图1 FFT整体结构图
2.2 定点算法优化
M级蝶形运算后都需要将数据暂存到RAM中,由于蝶形单元输出结果的位宽和RAM位宽的差异导致必须进行数据截断后才能存储,从而造成数据精度降低。将数据存储范围最高位与数据最高有效位之间(不计入符号位,下同)的位差定义为移位因子,数据左移位后不会发生溢出。本设计提出的定点运算优化方案具体实现如图2所示。
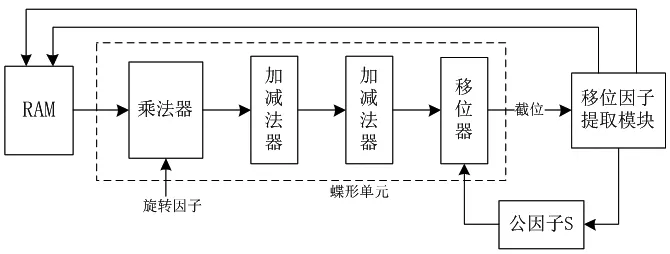
图2 蝶形运算阶段的移位机制
每一级蝶形运算前,对所有数据进行移位因子提取,可得{},最后取其中最小值做为移位公因子。在蝶形单元中,数据与旋转因子的乘法,加减法都进行运算位宽拓展,保证数据在运算中为满精度运算。最终运算结果需要进行截去旋转因子和运算带来的位宽,记为T,传统定点算法通过直接截去低T位来满足存储位宽。本设计考虑移位公因子S对运算的影响,由于所有数据的最高S位都为无效位,最终运算结果的最高S位也将是无效位,在截去数据时,将这部分截掉,再截去低(T-S)位,被存储的结果相对于传统定点算法多保留了S位的有效数据,数据值扩大了2S倍。每级移位公因子S对运算结果的影响是累加的,在五级蝶形运算结束后,将给出对输出结果的增益。
2.3 旋转因子存储优化
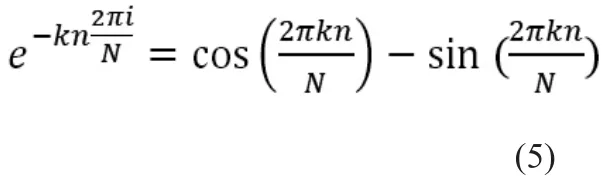
在蝶形运算过程中通过查找表方法取出所需的旋转因子,第M级运算需要4M-1个旋转因子,旋转因子间地址间距为4L-M。首先定义参考计数器C[7:0],旋转因子地址位宽为10bit,由此W p的地址如图3所示。W2p的地址为2倍W p,W3p的地址为3倍W p。

图3 旋转因子W p地址产生规律图
2.4 地址产生模块的设计
为了实现递归结构下的最大运算利用率,避免运算阶段蝶形单元空置,通过单周期数据取存,即每个周期下读取4个复数据进行蝶形运算。为此,需要将参与运算的4个数据需要存放在不同的RAM块中,杜兆胜的基于FPGA的FFT处理器设计与实现一文采用了“正序输入,整序输出”的结构,因此其在最终数据输出时仍然需要一级地址变化才能正序输出数据,引入了较为复杂的整序逻辑。本设计在输入时将数据整序,经过5级蝶形运算后,数据按顺序存入RAM中,故在输出时不在需要地址变化即可正序输出。
RAM的地址产生如图4所示,计数器为每个阶段的选址提供参考,每个阶段的RAM访问地址都是由计数器数值进行重排列得到的,在输入阶段,输入数据整序后写入A组RAM中,在五级蝶形运算阶段,对两组RAM的地址寻址相同,由所处的级数决定是读操作还是写操作,在输出阶段,数据从B组RAM中顺序输出,此时A组RAM空闲可以写入下次待运算数据。
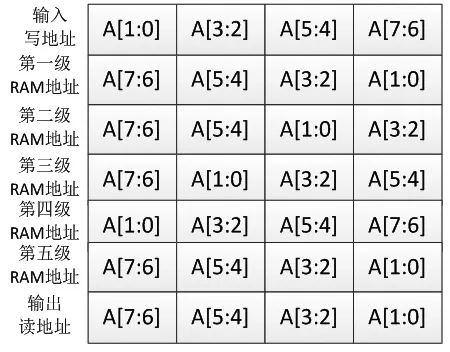
图4 RAM地址生成示意图
3 功能验证与FPGA实现
在使用Verilog完成整体设计后,使用Modelsim进行功能仿真,并与Matlab模型进行结果对比,显示功能设计正确。为了进行信噪比分析,利用Matlab生成的随机测试激励包,分别使用Matlab自带的fft函数、本设计进行仿真,取1000次信噪比结果,最终得到输出信噪比为65.4dB。
使用Xilinx Artix7 XC7A200T进行原型机验证,两组RAM通过调用ISE中提供的IP来实现,经过ISE 14.7的综合实现,资源报告如表1所示。

表1 FPGA资源报表
从资源报表中可以看出设计的显著低资源开销特性,时序报告显示设计能工作的最小周期是7.972ns,即最大工作频率是125.429MHz。
4 ASIC实现
本设计FFT通过Synopsys Design Compiler(DC)来进行综合,采用的工艺库为SMIC 130nm标准单元库,在工艺电压温度(PVT)为ss/1.08V/125℃条件下,电路所能达到的最高时钟频率为133.3MHz,面积为36kGE(等效门)。为了衡量FFT对数据处理的能力,引入FFT吞吐量特性指标。本设计FFT进行一次完整运算共有数据输入、蝶形计算、输出三个阶段,由于数据输入和结果输出时分别对应一组RAM,所以可以并行执行。1024点数据输入所需时钟周期为1024,运算阶段共需1340个时钟周期,总计时钟数为2360。输入输出数据位宽为13位。根据吞吐量计算得到本设计FFT最大吞吐量为1.50Gbps,为时钟速率的11倍。
表2显示了本设计与其它FFT处理器的部分指标对比,杜兆胜的基于FPGA的FFT处理器设计与实现一文实现了一种2蝶流水线型基4的FFT,可以看出本设计在FFT点数相同、接口位宽近似的情况下,吞吐量下降了28%但是面积降低了77%且输出信噪比提高了29%。
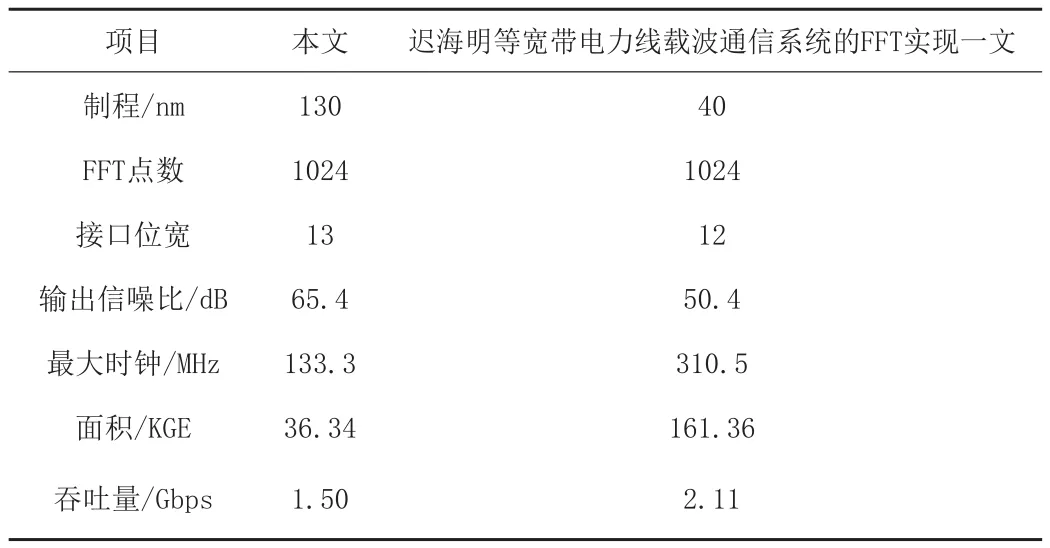
表2 关键指标
本文介绍了按时间抽取的基4 FFT算法,在传统实现结构的基础上,研究了一种基于递归结构的高精度FFT设计。采用双RAM的递归结构使蝶形单元的利用率达到最大、保证较低的硬件开销,同时配合灵活的地址寻址方式来降低系统的复杂性。针对定点算法精度低的问题,提出一种新颖的实现结构,只需增加少量的移位逻辑,即可有效地提高了运算精度。通过分析仿真结果得到信噪比为64.4dB,相比与其他已经存在方案,有较好的精度表现。最后,在SIMC 130nm工艺下得到ASIC结果,面积仅为36.34kGE,显示了本设计硬件开销小的优点。
