挖掘理想重建图像自相似性的超分辨率
2021-09-27李键红吴亚榕詹瑾
李键红,吴亚榕,詹瑾
(1.广东外语外贸大学 信息科学与技术学院,广东 广州 510006;2.仲恺农业工程学院 机电工程学院,广东 广州 510225;3.广东技术师范大学 计算机科学学院,广东 广州 510665)
图像超分辨率是指通过软件计算的方式处理一幅低分辨率图像,估计对应高分辨率图像的技术.它是常见的信号编辑形式,是低成本获取高分辨率图像的主要手段,广泛应用于空间遥感、视频监控及数字家庭等场景.近年来,由于潜在广阔市场地驱动,以及飞速发展的软/硬件支持,超分辨率取得了显著进展,已成为学术界讨论的热点话题.
一般来说,根据低分辨率图像反推对应的高分辨率图像是一个典型的病态逆问题[1].为了得到清晰可靠的重建图像,人们通常引入先验对高分辨率图像的重建过程进行约束,先验恰当与否和重建图像质量密切相关.根据引入先验形式的不同,超分辨率算法大致可分为插值法、重建法和学习法三类.
基于学习的方法指的是借助外界高分辨率图像建立训练集,并利用训练集归纳低/高分辨率图像间的映射,使先验以隐含的方式包含在映射中.这类方法能够有效地恢复成像过程中丢失的高频信息,生成在输入图像中观察不到的细节,从而使其倍受重视,成为超分辨率技术的主流.Yang 等[2]将稀疏表示的思想引入到超分辨率中,用不同尺度的图像片联合训练字典.但该方法导致字典中与输入图像片差异很大的“原子”参与计算,在重建结果中产生噪声.Timofte 等[3]将稀疏表示与邻域嵌入相结合,对每一个低分辨率图像片,在字典中查找距离它最近的“原子”,利用该“原子”在字典中的k 近邻构建矩阵算子.在此基础上,Timofte 等[4]进一步挖掘初始的训练图像,再次提升此算法的性能.深度学习在超分辨率中也得到了广泛应用[5-7].但这类算法通常需要借助图形处理单元(Graphics Processing Unit,GPU)训练海量图像,以确定神经节点的权重.在训练过程中,先验不易在此类方法中发挥作用,限制了重建图像的质量以及重建过程的稳定性.
近年来,自相似性在图像处理中得到了广泛应用[8-13].这一性质指的是当从局部入手(即图像中的一个5×5、7×7 或其他小尺寸的图像片)对图像进行考察时,会在这幅图像自身或更高低尺度内的其他位置发现与之尺寸相同、包含内容极其相似的图像片[8-10].基于自相似性的超分辨率算法把输入图像视作样本,训练模型、估计高分辨率图像.Glasner 等[8]提出一个整合式的超分辨率框架,把相似图像片视为同一场景的不同视图,整合多帧图像超分辨率和基于学习的超分辨率两种思想对图像进行放大.然而对于自相似性弱的图像,某些图像片查找到的最近邻域会与之存在较大差异,使重建结果中出现噪声,甚至引入错误高频.另外,该方法需要在输入图像的多尺度中搜索最近邻域,算法相对耗时.Freedman 等[14]经验性地指出自然图像中几乎所有图像片在其自身或较低尺度内的最近邻域,只需在该图像片所在位置附近检索就能查找到.Yang等[15]进一步在理论上通过数学推导对这一性质加以证明.这使得查找最近邻域消耗的时间显著缩短,然而由于使用的训练样本数量有限,导致此类方法的重建图像在边缘位置过于锐利,看上去不够自然.为了解决此种“小样本”问题,He 等[16]引入高斯过程回归,在每个图像区域内构建样本集合、训练参数.但该算法没有挖掘区域间的关联关系,使得重建结果中的显著边缘产生变形,附近存在噪声.基于同样的目的,Huang 等[17]通过变换矩阵对输入图像片进行特定的几何变形,不仅扩展了最近邻域的查找空间,而且使图像片间的匹配更加准确,提高了重建图像质量.该算法对于直线条居多、无复杂纹理的“建筑场景”效果较好,但对包含复杂纹理的“自然风光”而言,由于几何变形导致了纹理结构的失真,在重建图像的对应区域会出现伪影.
另外,自相似性先验表达式在众多领域也得到了应用[18-21].自相似性先验表达式通常会与其他先验如局部平滑先验、稀疏先验、低秩先验等结合使用.算法一般先查找若干最近邻域,然后借助这些相似图像片的稀疏系数相似或相似图像片构成的矩阵具有低秩结构等特点设计先验表达式.为了确定模型参数,这些算法仍需外界图像参与训练.成本函数中的先验表达式由多项构成,此类算法求解计算复杂、耗时,不易在实际中使用.
本文挖掘理想高分辨率图像的自相似性,提出了一种简单、高效的超分辨率算法,创新点如下:
1)拓展了自相似性概念.重建高分辨率图像越清晰,它体现出的自相似性就越强烈;当高分辨率图像中存在噪声、模糊等因素影响或缺失高频信息时,它所体现出的自相似性会明显减弱.基于此性质,提出了一种新的先验,通过对低分辨率图像进行建模、推导后发现,满足这一先验的重建图像,它的任意图像片都服从于某个特定的高斯分布.
2)设计了一个迭代框架,在每次迭代中,使用前次估计的高分辨率结果结合输入图像构造训练集合.对每个图像片,考虑到图像内容的连贯性,该算法使用输入图像中与之空间位置较近的图像片集合构造训练样本,并采用快速更新的方式确定模型参数.实验表明,该算法对于恢复图像高频细节,保持图像纹理结构等有显著优势.
3)该算法简单、高效,不仅无需外界样本参与,而且避开了耗时的最近邻域查找步骤.另外,在高斯混合模型建模、参数更新的过程中仅使用少量高斯成分,成本函数方程存在闭合解.更为重要的是该算法能够根据输入图像的不同而自动进行模型参数的调整,使得该算法更为鲁棒,易于扩展到图像去噪、复原等其他领域.
1 相关工作
图像在成像过程中会受到相对运动、聚焦失准等复杂因素干扰,很难找到一个完美的数学模型来精确刻画成像过程,因此在实际应用中,对于图像的超分辨率问题,通常用一个线性系统对整个成像过程进行模拟[1]:
式中:X∈RMN和Y∈RMN/s2是来自同一场景,但分辨率不同的两幅图像,X 是未知的高分辨率图像;Y 是人眼能够观察得到的低分辨率图像,(为了操作方便,此时的图像X 和Y 已通过字典排序的方式转换成向量的形式,M 代表图像的像素点行数,N 代表图像的像素点列数,R 表示像素点的亮度取值自实数空间范围,s 表示X 和Y 间的缩放倍数);矩阵D 和H分别对应成像过程中的下采样和低通滤波操作;n∈RMN/s2是成像过程中产生的加性高斯白噪声,满足n~N(0,σ2I),σ 为描述噪声等级的标准差,I 为单位矩阵.图像X 和Y 的尺寸分别为M×N 和M/s×N/s.显然对于一幅低分辨率图像Y 而言,X 存在着无穷多的解与之匹配.为了得到一个满意的解X*,先验知识的引入就变得尤为关键.一般情况下这类问题可以描述为一个最大后验概率方程:

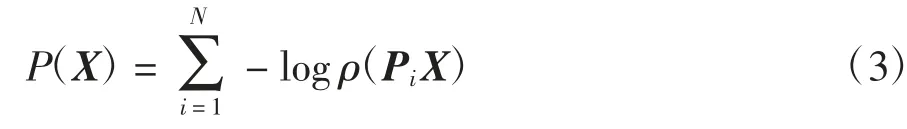
式中:Pi为抽取矩阵,负责抽取未知高分辨率图像X中的i 第个图像片,即PiX=xi,xi∈Ra2,a 为图像片的尺寸;ρ(xi)为第i 个图像片xi的先验表达式,它的具体表示形式因选择先验的不同而不同,对应成本函数的求解过程也不一样.一般而言,这类问题的成本函数是非凸的,直接求解会非常困难.常见的思路是为变量xi引入辅助变量,使用“半二次分裂”(Half Quadratic Splitting,HQS)算法求解[22].
高斯混合模型(Gaussian Mixture Model,GMM)因其思想简单、推导方便、能准确描述任意概率密度函数等特点备受研究人员青睐.近年来,将GMM 作为先验形式在计算机视觉、图像处理等领域得到了广泛应用,在图像分割、恢复、视频压缩等方向展现出了极高的效率[23-24].它的基本形式为:

式中:z∈Rd是一个d 维随机向量;K 为高斯混合模型高斯成分的个数;参数πk、μk和∑k分别表示第k个高斯成分的权重系数、均值向量和协方差矩阵.第k 个高斯成分的表达式为:
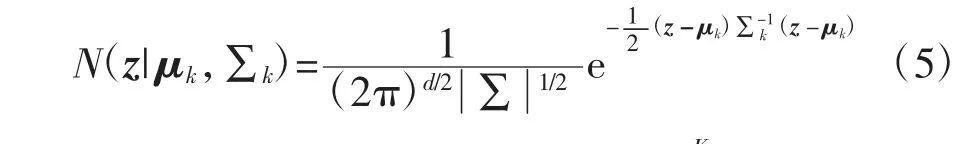
与本文算法在形式上相似,但又存在本质差异的工作包括PLE[25]、EPLL[26]、LINE[27]、J-GMM[28]和MMPM[29].其中EPLL、J-GMM 均使用高斯混合模型对外界海量图像片进行建模,进而假定未知图像片由混合模型中的某个高斯成分生成,然后通过最大后验概率估计将该成分找到,最后使用均值向量和协方差矩阵计算维纳滤波解.然而图像中存在大量的图像片,并不服从这一假设.它们需要借助多个高斯成分或混合模型之外的新成分才能准确生成.这使得信号估计过程中,仅使用某个高斯成分的均值向量和协方差矩阵计算的维纳滤波解不准确,导致重建图像中存在噪声和模糊现象.MMPM 算法与JGMM 算法步骤相同,区别在于它使用学生氏分布替换混合模型中的高斯成分,在重建结果中同样存在少量噪声和模糊.PLE 和LINE 算法也从上述假设出发,先查找待恢复图像片在训练集中的最近邻域,再通过这组最近邻域直接构建混合模型中能够生成对应图像片的高斯成分.然而查找最近邻域步骤过于耗时,同时这种硬阈值聚类的形式减弱了训练样本间的一致性,导致高斯成分所涉及到的参数不准确,在重建结果中易出现噪声.
本文仅使用输入图像构建训练集,对每一个待超分辨率的图像片,在训练集中选择空间位置相近的图像片进行联合高斯混合模型训练,利用高斯混合模型,得到每一个未知的高分辨率图像片都服从一个“特定”的高斯分布这一结论.最后利用混合模型之外某个高斯分布的均值向量和协方差矩阵估计对应的高分辨率图像片.
2 理想重建图像自相似性超分辨率
2.1 训练集构造
自相似性是图像自身固有的一种性质,它指的是在图像中任意抽取的图像片会在这幅图像自身其他位置或其他尺度内重复出现的现象.在这一基础上,对自相似性进行扩展.通过进一步实验,发现在超分辨率工作中,越是清晰的高分辨率重建图像,图像片重复出现的能力就越强烈;但在含有噪声、模糊或缺失高频信息的高分辨率重建图像中,图像片的重现能力明显减弱.如图1 所示,中间的小图像为输入低分辨率图像,图1 为其不同的超分辨率版本.对于4 幅图像中某个位置的图像片,在对应的低分辨率图像中查找最近邻域,可以发现这4 个来自不同版本同一位置的图像片,在低分辨率图像中的最近邻域都能够在这个位置附近找到.更为重要的是:只有在理想超分辨率图像中的图像片,它找到的最近邻域才与之在外观上相似;其他版本中这个图像片找到的最近邻域,在外观上都与之存在差异.在BSD500 数据集中进行类似的实验,发现绝大多数的图像都存在上述特点.因此可以认为在超分辨率算法中,重建高分辨率图像越清晰,它所体现出的自相似性越强烈;但当高分辨率重建结果中存在噪声、模糊或缺失高频信息等因素时,它所体现出的自相似性会显著减弱.

图1 重建高分辨率图像片重现现象示意图Fig.1 The explanation of image patches recurrence in reconstructed high resolution image
借助这一规律,提出一种新的超分辨率算法,采用迭代的方式,用输入图像Y 估计对应高分辨率图像X.算法迭代框架如图2 所示,假定前一次迭代估算的高分辨率图像X 未满足算法要求,将其视为理想高分辨率图像的低频版本,替换当前低频图像X′,实现了X′的更新,然后将X′使用双三次方法下采样s 倍,得到与输入图像同尺寸的低分辨率图像Y′.此时X 为未知的高分辨率图像,X 和Y′可以视为X 和X′通过成像模型处理的低分辨率版本,X′和Y′可以视为X 和Y 的低频版本.

图2 理想重建结果自相似性算法的数据构造Fig.2 Data construction of the ideal reconstruction prior super-resolution algorithm
根据上述的图像自相似性扩展规律可知,如果X 和X′相对于Y 和Y′足够清晰,那么在X 和X′中抽取的图像片Xi和(xi∈Ra2,a 为抽取图像片的尺寸),应该能够在其对应的低分辨率版本Y 和Y′中找到重现,即存在图像片yj和,其外观与xi和高度相似,即图像片xi和在Y 和Y′的图像片联合的概率密度函数中以最高的概率存在.
基于上述分析,将图像的超分辨率问题构造如下:对于未知的高分辨率图像片xi,先构造训练数据集,抽取Y 和Y′中的图像片进行连结,得到训练数据集{yj;},其中yj和表示分别从Y 和Y′中抽取的第j 个图像片.将理想的高分辨率图像X 中抽取的图像片xi和缺失高频成分的高分辨率图像X′中对应的图像片相连结,得到向量[xi;].根据图像的自相似规律可知:[xi;]在训练集合{[yj}中的概率密度函数中应以最高的概率存在.考虑到图像内容本身有很强的连贯一致性,为了使得到的概率密度函数更准确,在构造xi的训练集时,我们在Y 和Y′中分别设定一个w×w 的滑动窗口,其当前中心位置与xi位置相同,仅将窗口中的图像片集合作为xi的训练集,窗口外的内容不参与图像片xi的计算.考虑到窗口内能够抽取的图像片有限,参与计算的样本可能不足,我们将窗口中的内容进行旋转和镜像操作,并从这些旋转和镜像图像对应的窗口中抽取图像片以此扩充训练样本.
2.2 自相似先验设计
对于每个图像片xi所使用的训练集合{[yj;y′j]},yj∈Ra2∈Ra2,引入高斯混合模型逼近训练集的概率密度函数,如式(6)所示:

然而,在实际执行过程中,如果对每一个高分辨率图像片的估计都使用EM 算法进行模型训练,会导致算法的执行异常复杂,不能在可容忍时间范围内结束计算.为了解决这一问题,使用参数自动更新的EM 算法进行模型训练[30].由于相邻两个高分辨率图像片存在内容重复,其对应的参数间有着密切的关系,后一个图像片的参数集能够借助前一个图像片模型的训练结果,仅使用新出现的样本对参数集进行更新,既能够快速完成训练,又能够保证模型的准确程度.图3 中算法详细地列出了模型参数更新的具体步骤.

图3 理想重建图像超分辨率算法伪代码Fig.3 The pseudocode of ideal reconstruction prior super resolution algorithm
对于未知的高分辨率图像X,把从中抽取的图像片xi和在图像X′中相同位置的图像片进行连结,得到对应的连结向量[xi;],它在训练集合的概率密度函数中存在的概率可以表示为:

进而可以发现xi的条件概率服从一个特定的高斯分布:
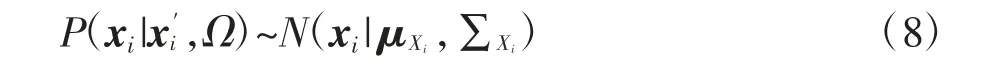
式中:μXi为这个高斯分布的均值向量,∑Xi为这个高斯分布的协方差矩阵,它们的表达式分别为:



式(12)表示在第i 个图像片所对应的高斯混合模型分布中,第个高斯成分对应的公共因子值最大,N 表示在图像X 中抽取图像片的总数.因此图像片xi对应的特定高斯分布的均值向量μXi和协方差矩阵∑Xi可以近似表示为:

通过上述推导,理想的重建图像中任意抽取的图像片x 其自相似先验的具体表达式为:

进而,整幅图像的自相似性先验表示为:

式中:N 为在未知超分辨率图像X 中抽取的图像片数量;Pi为一个预先设定的抽取矩阵,用于抽取X 中的第i 个图像片.由于式(15)(16)中所描述的先验知识是对未知的高分辨率图像中的每一个图像片在较低尺度中重现的概率进行估计,是对理想重建高分辨率图像的一种刻画,因此将这一先验知识称为理想重建图像自相似先验.
2.3 高分辨率图像重建
先验的表达式确定后,该算法的成本函数就能够通过这个具体先验表达式进一步构造出来.在本文的超分辨率重建算法中,要求得到的超分辨率重建结果在满足理想重建图像自相似性先验的同时,重建的高分辨率图像在通过成像式(1)处理后,还应与输入的低分辨率图像尽可能的相似.为了兼顾这两个要求,通过加权求和的形式整合这两项表达式,将该算法的成本函数设计为:
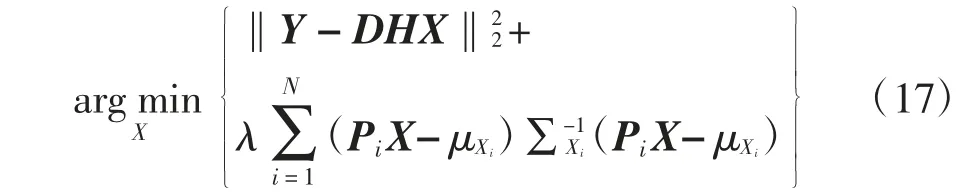
其中第一项称为保真项,它能够使得估计的高分辨率图像X 在经过退化模型处理后得到的结果与观察图像尽可能的一致;第二项是先验项,用于约束重建的高分辨率图像满足尺度间自相似性.用于两项间的权衡.这个成本函数的求解较为简单,可直接对式(17)进行求导,并令导数为0,即可得到关于X 的表达式,进一步整理可以得到超分辨率图像的最终估计结果:
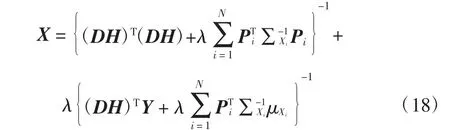
然而在重建高分辨率图像X 表达式的计算过程中,需要操作的矩阵通常具有极大的规模,如下采样矩阵D、滤波矩阵H 和抽取矩阵Pi,这样的计算方式占用内存空间过大、耗时且复杂,对于普通计算设备而言,极易造成内存溢出;同时也考虑到输入的低分辨率图像存在噪声、模糊等情形.为了解决这一问题,尝试使用“分解”的策略进行解决.针对每一个图像片xi,在先验给定的前提下,借助它的后验概率密度函数进行计算,如式(19)所示:

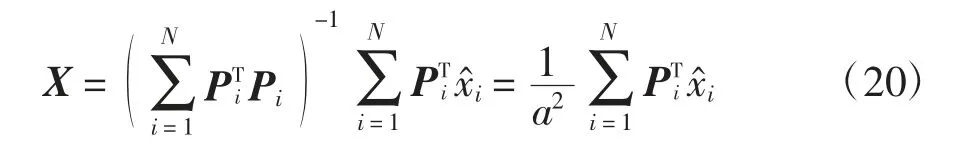
根据前述算法的描述,可以完成算法的一次迭代,通过判断当前X 和X′的差异是否足够小,以决定算法是否需要执行下一次迭代.当满足输出条件时,即可直接输出X 作为超分辨率重建的结果,这个超分辨率过程的伪代码如图3 所示.最后,在图4 中给出了本文算法对一幅彩色图像进行超分辨率重建的完整过程.
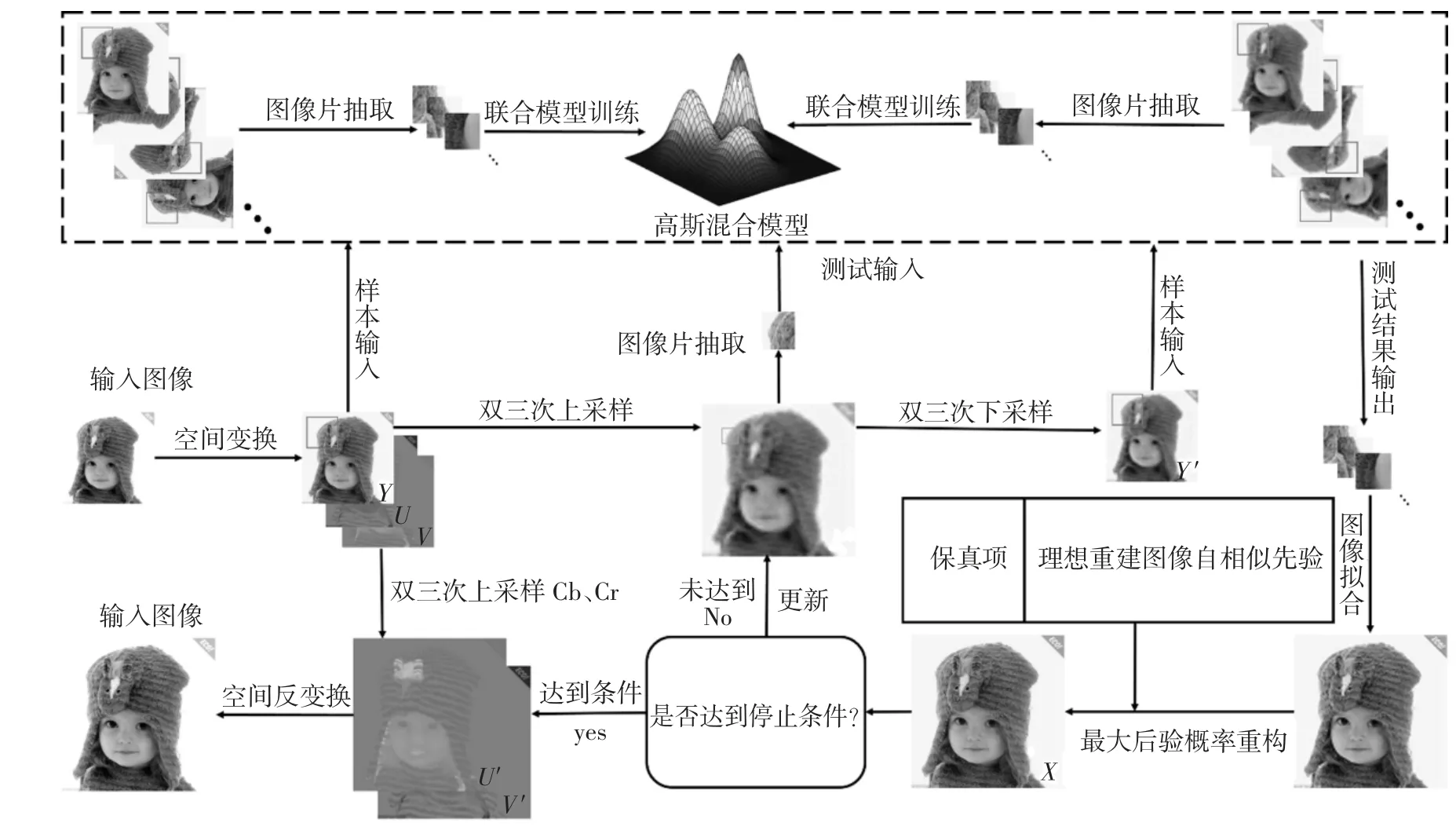
图4 理想重建图像自相似性超分辨率算法重建彩色图像框架Fig.4 The color image super-resolution framework of the ideal reconstruction self-similarity prior algorithm
3 实验结果与分析
通过主观视觉观察和客观参数比较两种方式验证理想重建图像自相似性先验超分辨率算法的效率.首先对算法流程中需要设定的参数进行说明,然后给出本文算法和同类以及前沿算法重建图像质量、消耗时间的比较,最后对该算法的性能做进一步的理论分析.
3.1 实验设置
在实验过程中,为了模拟成像过程,构建理想高分辨率图像和低分辨率输入图像测试样本对,用于测试算法的性能,我们在一些常用测试集中随机抽取样本作为理想的高分辨率目标,将这些抽取到的图像用双三次方法下采样s 倍,并用高斯低通滤波器(均值为0,方差为0.5)对它们滤波,以生成用于输入的低分辨率图像.将这些低分辨率图像输入到测试算法中,超分辨率s 倍,得到的重建结果和计算过程消耗的时间可用于评价该算法.一般而言,图像重建结果越接近理想目标图像,计算过程消耗时间越少,算法的性能越高.
本文算法在首次迭代执行前,仅有输入图像Y已知,先将Y 双三次上采样s 倍的结果初始化为X′,再将X′使用双三次下采样s 倍用于初始化Y′.由于图像尺度间的自相似性有随着尺度的降低而减弱的特性,当超分倍数较大时,直接放大到目标倍数会降低重建图像质量,为此我们采用逐级放大的方式进行处理,每次放大2 倍,并将超分辨率结果作为算法的输入再次放大,直到达到目标倍数为止,最后一次放大不足2 倍时,直接放大到目标倍数.对于输入的彩色图像,先将这幅图像从RGB 空间转换到YUV空间,由于代表亮度信息的Y 通道对人眼较为敏感,用本文提出的理想重建图像自相似性超分辨率算法进行处理;代表颜色信息的U、V 通道对人眼的刺激相对迟弱,U、V 通道直接用双三次上采样方法放大到目标倍数,再将重建结果从YUV 空间转换到RGB空间进行显示及保存.
另外,考虑到随着算法迭代次数增加,重建结果中包含噪声的能级应逐渐减少,将式(20)中描述噪声等级的参数设定为,(T 为算法的迭代次数).由于此算法考察的是图像自相似性,不同尺度间的图像片抽取尺寸相同,式(20)中图像片尺寸参数设定为a=7,即抽取尺寸为7×7 的图像片.算法中的每一个未知超分辨率图像片都需要在输入图像Y 和它的低频版本中对应的位置处设置窗口,以便抽取训练样本.若窗口尺寸设置过大,则样本间的一致性不强,影响模型的准确程度;若窗口尺寸设置过小,则会因为抽取到的样本数量不足,导致模型欠拟合.本文将窗口尺寸设定为w=32,即每一个估计的图像片都在输入图像与之相同中心位置32×32 的窗口中抽取训练样本.对于边界附近的超分辨率图像片,为了能够定位到相应的窗口,需要对图像Y 和Y′做镜像扩展处理.与窗口尺寸相匹配的高斯混合模型中高斯成分的个数设置为K=3.
3.2 主观观察结果
为了验证本文算法的有效性,我们选择与本文形式类似方法(包括Glasner[8]、GPR[16]、Self-ExSR[17]和MMPM[29])、借助外界训练集合方法(ScSR[2]、ASDS[31]、A+[4]、SPM[32]和JOR[33])以及深度学习方法(SRCNN[5]、FSRCNN[6]、lapSRN[7])进行了一系列的比对实验.所选择的比较算法除Glasner 算法外均从作者主页下载,Glasner 算法的代码为我们使用Matlab2019b 软件自行编写,且效果与文献[8]中给出的结果基本一致.本文算法和参与比较的算法均在Intel(R)Core(TM)i7-5600 CPU@2.60 GHz,8.00 GB 缓存的硬件环境,Windows 7 专业版64 位操作系统,Matlab2019b 的软件环境下进行实验.
如图5 和图6 所示,显示的是图像“parrot”和“fence”使用多种不同方法分别放大3 倍和4 倍的结果.观察用线框标识出的局部子区域的放大显示结果,可以发现在显著边缘位置、纹理细节丰富区域能够明显地保持边缘和纹理的结构,能恢复出更多正确的细节,使图像看上去更加清晰、自然.两组超分辨 率 结果 中,ScSR、Glasner、Self-ExSR、GPR 以 及SPM 方法重建的超分辨率图像在显著边缘位置都出现了可见的模糊和噪声.ASDS、A+、JOR、MMPM 和本文提出的方法超分辨结果较为清晰,在显著边缘及纹理区域附近并未出现可见的噪声和模糊等形式的伪影.MMPM 方法和我们的方法恢复出了较多的高频信息,观察“parrot”图像中鹦鹉的眼睛和羽毛区域以及“fence”图像中带有平行结构的“篱笆”,可以看出我们的方法对图形结构保持得更加完整,几乎观察不到可见的变形.

图5 图像“parrot”超分辨率放大3 倍结果Fig.5 The comparison of super resolution 3×results of the image“parrot”

图6 图像“fence”放大4 倍结果Fig.6 The comparison of super resolution 4×results of the image“fence”
图7 是方法和深度学习方法SRCNN 和lapSRN对图像“barbara”超分辨率放大4 倍的比较结果.测试图像“barbara”包含丰富的纹理信息,在超分辨率过程中,这些纹理结构虽有固定的模式,却又不尽相同,在超分辨率过程中极易产生变形或引入噪声.观察图7 可以发现,我们的方法产生的超分辨率结果和理想高分辨率图像最为接近,基本上保持住了纹理区域的外观.SRCNN、lapSRN 方法产生的超分辨率结果都使得纹理的基本结构发生了严重的变形,且能够观察到有明显噪声出现.

图7 “barbara”放大4 倍的比较结果Fig.7 The comparison of super resolution 4×results of the image“barbara”
3.3 客观评价结果
为了进一步说明理想图像自相似性先验超分辨率算法的性能,借助客观评价参数对我们的方法和其他方法进行比较,主要使用的评价指标包括峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity Index Measure,SSIM).一般来说,这两个评价参数的数值越大,代表算法得到的重建图像质量越好.在BSD500 图像集合中随机抽取12 幅图像,如图8 所示,这些图像的内容囊括人物、动物、建筑物和风景等,包含显著边缘、复杂纹理和精细结构等内容,具有极强的代表性.按照前述步骤操作,将这些图像进行超分辨率放大3 倍处理,其客观参数比较结果如表1 所示.

图8 BSD500 图像集合中随机抽取的12 幅测试图像Fig.8 12 testing images selected randomly from BSD500
在表1 中,每一行数据代表一幅图像使用不同方法超分辨率的结果,每一列代表一种方法超分辨率处理不同图像的结果,其中每一幅图像对应两行数据,第一行为PSNR 结果,第二行为SSIM 结果.观察表1 可以发现,在PSNR 参数比较中,表1 中我们的方法有10 张图像结果最优;SSIM 参数比较中,我们的方法有11 张图像结果最优(最优结果均用加粗字体标出).表1 中我们的方法没有得到最优结果的图像,它们的评价参数数值也相对较大,都取得了次优结果.另外,观察表1 中评价参数平均值,可以看出我们方法的PSNR 和SSIM 平均值都排在第1 位,我们方法的PSNR 平均值高于MMPM 算法0.529 db,SSIM 平均值高于MMPM 算法0.030.为了从统计的角度出发验证本文算法的有效性,以BSD500 图像集合全体作为测试对象,用本文算法和参与比较的11 种前沿算法分别对测试集中的图像进行3 倍放大.其性能比较结果如图9 所示,图中每一个实心圆点代表一个算法,每个点的横坐标表示算法的平均消耗时间,纵坐标表示算法重建图像的PSNR 均值.从图9 中可以看出,本文算法平均PSNR 值最大,图像质量最好.该算法放大一幅BSD500 中的图像平均消耗时间约1 min,明显少于GPR 和ASDS 算法,与Self-ExSR 算法耗时相近.

图9 BSD500 图像集超分辨率放大3 倍的PSNR 均值和平均消耗时间比较Fig.9 The comparison of 3×super-resolution results in BSD500 by average PSNR and time consuming

表1 图像超分辨率放大3 倍PSNR、SSIM 比较结果Tab.1 The comparison of 3×super-resolution results by PSNR and SSIM
3.4 分析讨论
首先,联合高斯混合模型建模在形式上不同于训练字典下的稀疏算法,它在解决超分辨率问题中有先天优势.因为超分辨率成像中的滤波矩阵和下采样矩阵均为非单位矩阵,在与字典进行计算时,会导致训练字典的互相干性增大[24],降低重建图像质量,而基于联合高斯混合模型的超分辨率方法不存在这样的问题.
在挖掘理想重建图像自相似性的超分辨率算法中,对每一个待超分辨率的图像片,该算法以当前图像片的位置为中心构建窗口,仅使用少量的高斯成分对图像片空间位置附近的样本建模.由于这些图像片位置彼此相邻,描述的内容相似,具有较强的一致性,能使训练得到的高斯混合模型更加准确.同理,Δik值也会体现出极强的稀疏性.
最后,已有方法都是将训练得到的高斯混合模型作为先验,并假定所有的图像片都能由模型中后验概率最高的高斯成分生成.而我们的方法对这个高斯混合模型做进一步推导,把推导结论(每个未知的高分辨率图像片都服从一个特定的高斯分布)作为先验知识,设计成本函数.二者的区别在于后者进一步挖掘了后验概率最高的高斯成分,利用了这个高斯成分的协方差信息进行计算,使得图像重建效果优于前者.
4 总结
在超分辨率研究工作中,我们发现理想重建高分辨率图像的自相似性体现最为强烈,而受降质因素影响的重建高分辨率图像自相似性会明显减弱.
当使用高斯混合模型对这一现象进行描述时,通过对模型进行推导,可以发现每一个理想的高分辨率图像片的自相似性都符合一个特定的高斯分布.将这个规律作为先验知识添加到超分辨率框架中,显著提升了重建超分辨率图像的质量.该方法无需使用外界图像进行训练,仅通过输入图像和其对应的低频版本为每个重建图像片建模,以一种在线训练的方式联合构建高斯混合模型.随着输入图像的变化,模型参数能够自动进行调整,以适应新的情况.因此该算法较其他预测模型有着更强的鲁棒性,尤其适用于数字电视高清显示等需要较大超分辨率倍数但又无额外参数存储装置的场景.
