面向ICD疾病分类的深度学习方法研究
2021-09-26张述睿张伯政张福鑫杨万春
张述睿,张伯政,张福鑫,杨万春
1.中国人民大学 统计学院,北京100872
2.山东众阳健康科技集团有限公司,济南250101
3.山东交通学院 理学院,济南250357
近年来,文本的多标签分类在自然语言处理领域中受到持续关注。在多标签分类中,一段文本可能同时具有多个对应的标签,例如一段文本可能表现出两种情感,一段新闻可能具有几种主题等,同时标签之间通常有一定的依赖关系。当标签空间变得非常庞大的时候,用深度学习模型进行文本分类就面临很大挑战。这主要是因为使用循环神经网络GRU[1]、LSTM[2-3]和多层感知机进行分类时,每个分类标签相互独立而无法建立标签之间的依赖关系。
在医疗临床中,电子病历的文本信息充斥着各种医学术语,且表述晦涩和含糊,因此对电子病历中的文本进行分类是很有挑战任务。同时由于很多深度学习模型的运作原理都难以解释,导致了很多医学专业人士对此类方法的不信任。陈志豪等人[4]提出使用注意力机制来建立医疗问题和答案的相互影响,Mullenbach等人[5]采用卷积神经网络来提取病例文本中的语义信息,从而预测ICD疾病分类,但这两种方法并没有考虑到标签之间的依赖关系。檀何凤等人[6]提出了一种基于标签相关性的K近邻多标签分类算法,陈文实等人[7]提出使用主题模型与LSTM分别对文本的全局特征和局部特征建模,李锋等人[8]通过结合标签特征和局部标签相关性来丰富标签信息,但这三种方法没有考虑到在结构化标签空间或在超大标签空间中的应用。Steinberg等人[9]使用贝叶斯网络对标签的本体结构建模来预测ICD疾病分类,但是根据神经网络反向传播的特性,概率连乘的反传并不能让模型学到标签之间的依赖关系,Xie等人[10]提出使用树形LSTM的方法对结构化标签空间建模来预测ICD编码,但是树形LSTM递归的计算方式在超大标签空间中的计算代价非常高。图神经网络[11]是一类基于深度学习处理图域信息的方法,由于图神经网络有着很好的计算性能和可解释性[12],因此其正受到越来越多的关注和应用。
本文结合图神经网络、图注意力网络[13]和注意力机制[14],提出了一种解决超大标签空间中多标签分类问题的方法,并应用到国际疾病分类[15]中。本文提出的方法包括:(1)提出了一种面向ICD疾病分类的端到端深度学习方法。(2)采用改进的图注意力网络对标签空间建模,将标签空间的结构信息融入到模型中。(3)提出了一种基于注意力重构的编码匹配方法,其对大标签空间有着良好的适应性和可扩展性。通过与其他方法的实验对比,验证了本文所提方法的良好分类精度,在含有3 792种标签的数据集中,前五种的精确率达到了0.92。
1 问题描述
1.1 ICD手术分类
本文解决的问题是国际疾病分类中的手术与操作分类(ICD-9-CM3)[16],以下简称为ICD手术分类。每一种ICD手术分类都对应着一条由数字和字母组成的编码,以下简称为ICD手术编码。ICD手术分类是医院病案信息加工、检索、汇总、统计的主要工具,在医疗、研究、教学等方面发挥重要作用。ICD手术分类是由专业编码员负责的,是一项非常繁琐的工作任务。编码员首先查阅医生录入的手术描述,之后如果有需要的话,还要查阅病人电子病历中的某些内容,然后人工查阅分类向导,将医生录入的手术描述匹配到一个或若干个最符合的ICD手术编码条目上。在临床中,医生录入的手术描述经常使用缩写和简称,这使手术描述的含义变得模糊,编码员经常因为这种情况犯一些主观错误。
1.2 ICD手术分类数据集
数据集有典型的大标签空间和多标签的特点,并且标签空间拥有层级结构,标签与标签之间有相互关系和依赖。本文中使用的数据集是从30余家医院的临床数据中提取的,并经过人工精细校对,其中包含60 000条数据,每条数据由医生录入的手术描述和编码员匹配好的ICD手术编码条目组成。医生录入的手术描述是对手术类型或方式的简短陈述,一条手术描述可能包含一个或多个手术操作,可对应一条或多条ICD手术编码条目。在实际的分类工作中,编码员主要是靠手术描述来进行ICD手术分类,所以在本文中仅使用手术描述来进行ICD手术编码条目的匹配。
例1数据集展示
手术描述1:右侧背部脂肪瘤切除术
对应的ICD手术编码条目:
86.3x03皮下组织病损切除术
手术描述2:C6/7椎间盘微创消融术+盘内臭氧注射术
对应的ICD手术编码条目:
80.5900x001椎间盘射频消融术
80.5200椎间盘化学溶解术
如例1所示,每一条手术描述对应一个或多个最相关的ICD手术编码条目,其由一串数字和字母组成的编码和与之对应的标准编码描述组成,以下简称ICD手术编码条目中的标准编码描述为编码描述。
图1所示的是ICD手术分类的层级结构,层级结构中每一个节点都是由一串数字和字母组成的编码和与之对应的编码描述组成的。ICD手术分类含有5个层级,分别是大章节(18个分类)、小章节(100个分类)、类目(890个分类)、亚目(3 755个分类)、细目(9 100个分类),共含有13 863个分类。从大章节层级到细目层级,是一个不断细化分类的过程。ICD手术分类的层级结构对临床ICD手术分类工作有重要意义,编码员在实际工作中,需要先根据手术描述中各种特征(如手术部位、针对的疾病、不同的手术方式等)通过查找目录确定一个粗略的分类寻找范围,也就是先确定章节、类目等较浅的层级的分类,再向下细分寻找。如图1所示,编码01.0颅穿刺指的是一个较大的分类范围,而它的下级节点01.020 0和01.090 0是指的不同的穿刺方式,是更细化的分类,上下级节点之间有着很强的依赖关系。为了充分利用标签空间的特性和标签之间的依赖关系,在本文中对标签空间进行了建模,并使用提出的方法将手术描述匹配到亚目层级和细目层级。

图1 ICD手术分类的层级结构Fig.1 Hierarchy nature of ICD procedure coding system
亚目层级有3 755个分类,细目层级有9 100个分类,但是在临床中,由于一些手术操作在临床中非常罕见,所以有很多分类并没有在数据集中出现,本文只对数据集中出现过的标签做分类研究,数据集中实际出现了2 237个亚目分类,3 792个细目分类。
2 面向ICD手术分类的端到端模型
在本文中,将ICD手术分类问题看作多标签分类问题,提出了一种基于深度学习的端到端模型作为解决方案。首先使用图注意力网络对标签空间进行建模,之后使用注意力机制重构的方法使手术描述和ICD编码之间的语义信息得到交互,最后使用二元分类器得到对每一条ICD手术编码条目的预测结果,整体模型结构如图2所示。
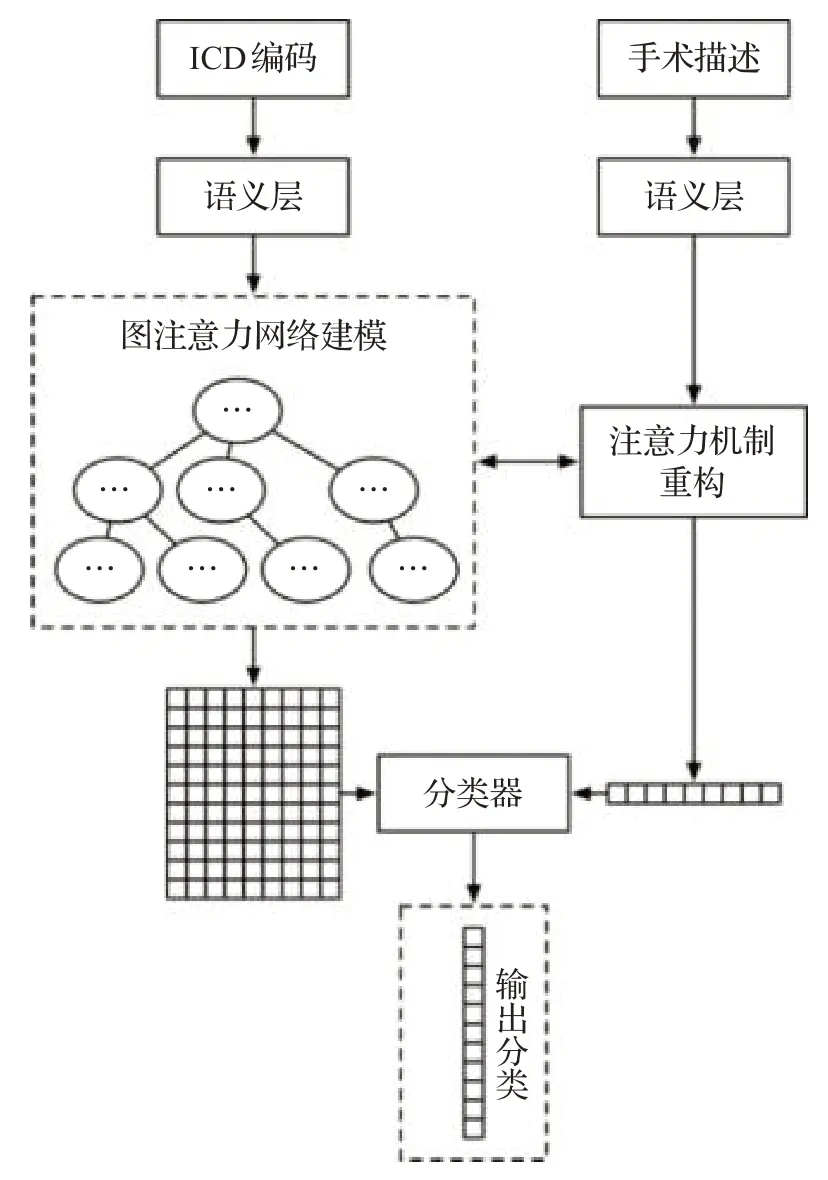
图2 面向ICD手术分类的端到端模型Fig.2 End-to-end model for automated ICD procedure coding
2.1 语义层
本文使用了BiLSTM(双向长短期记忆网络)和BERT[17]作为语义层的模型,对自然语言序列进行向量化表达。transformer[18]模型提出使用多头注意力机制对序列进行建模,不再依赖序列的方向逐次计算,实现了对序列的并行化处理。基于transformer的模型因为其优秀的序列建模性能在自然语言处理领域被广泛应用[19]。BERT作为基于transformer的语言模型,提出先使用基础语料进行预训练,然后再适应下游任务。LSTM是被广泛使用的循环神经网络结构,其特点在于在序列建模中,将序列的每一时刻的信息依次输入到LSTM单元中,通过三种门控机制控制当前状态和记忆历史信息,并克服了RNN反向传播时梯度爆炸和梯度消失的问题,且Khandelwal等人[20]的研究证实,LSTM对50字左右的序列有很好的辨识能力,而本文使用的数据集内医生录入的手术描述都比较简短,平均长度为13个字,而编码描述的平均长度为10个字,所以LSTM可很好地胜任当前的任务。
2.1.1 BiLSTM语义层
首先通过医学教科书语料预训练的字向量[21](Word2vec)映射手术描述和ICD手术编码描述中的每一个字到一个向量,一段手术描述或一段ICD手术编码描述变成一串字向量序列。

使用BiLSTM对上下文语义信息进行建模,通过在字向量序列上应用BiLSTM模型,可以将自然语言序列中的每一个字向量,结合其上下文,形成适应于本文字序列的,隐含的语义表达,公式表示为:
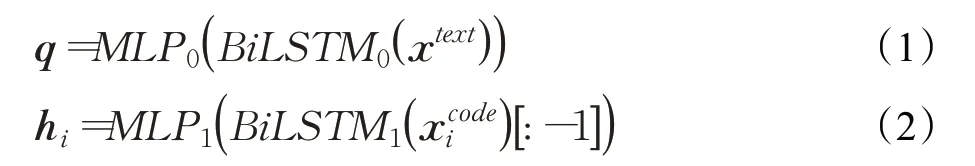
公式(1)、(2)中,由于BiLSTM通过正向和反向各得到一层隐状态的输出,所以隐状态的维度是2d,MLP表示多层感知机层,将2d的维度映射为d。[ ]:-1指的是取BiLSTM返回的隐状态序列中最后一个时刻的隐状态。通过上面的操作,得到的q是经BiLSTM建模后的手术描述隐含语义的向量表达,q∈ℝ||text×d,hi是第i条编码描述的向量表达,hi∈ℝd。
2.1.2 BERT语义层
首先使用医学教科书语料对BERT模型进行预训练,之后使用BERT模型获取手术描述和手术编码的向量表达,公式表示为:
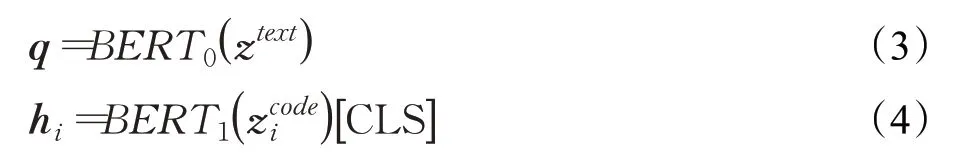
公式(3)、(4)中,ztext表示一条手术描述的字索引,表示第i条编码描述的字索引。字索引是将文本中每个字用一个整数来表示。输入到BERT模型的字索引的构成为“[CLS]”+文本+“[SEP]”,“[CLS]”是一个特殊索引,BERT会在“[CLS]”索引的位置输出一个向量,用来表示整句的隐含语义信息。对于医生录入的手术描述,保留BERT输出的整个向量序列,q∈ℝ||text×d。对于第i条编码描述,只取“[CLS]”索引对应的向量,hi∈ℝd。
2.2 图注意力网络建模
ICD手术分类具有层级结构,分为5个层级,如图1所示,分别是大章节、小章节、类目、亚目、细目。从大章节到细目的层次,是不断细化分类的过程,层次与层次之间有着密切的关系。将ICD手术编码描述按层级结构融入模型中,使模型得到各层级之间的依赖关系,可增加模型的分类能力。
例如图3中,“03.0(类目)椎管结构探查和减压”的上级节点有“03(小章节)脊髓和椎管结构的手术”和“01~05(大章节)神经系统手术”,把上级节点的关键信息,如“神经系统”“脊髓和椎管结构”融入到下级节点中,使下级节点含有ICD手术分类层次的上下文信息,这符合临床中编码员在分类过程中的思维方式。同样地,把下级节点的信息融入到上级节点,同样可以增强上级节点所含有的信息量,增加模型的判断能力。

图3 ICD手术分类的上下层级节点关系Fig.3 Dependency between nodes at different levels of ICD procedure coding system
本文将每一条ICD手术编码条目叫做节点,上级节点和下级节点之间用边连接,如图1中,01.0(类目)颅穿刺的下级节点的编码是01.0200和01.0900,01.0200的上级节点编码是01.0。根据边的连接方向可使ICD手术分类的标签空间形成有向图或无向图结构,再使用图注意力网络对标签空间建模。本文提出在图注意力网络建模中构建以下三种不同的图结构。
up图:所有边由下级节点指向其上级节点,并包括每个节点自身形成的环边,形成由亚目到大章节方向的有向图结构。
down图:所有边由上级节点指向其下级节点,并包括每个节点自身形成的环边,形成由大章节到亚目方向的有向图结构。
undi rect ed图:结合up图和down图形成不区分方向的无向图结构。
在完成上述三种图结构的构建之后,使用图注意力网络进行建模,即通过3种图结构分别进行注意力计算,最后将计算的结果级联。
首先进行图注意力权重的计算。
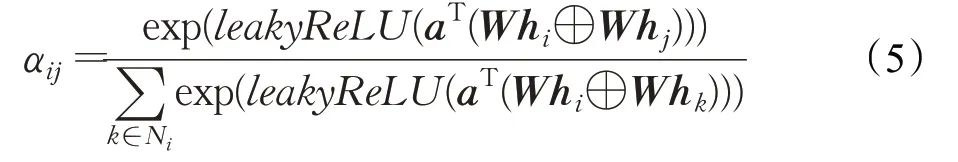
式(5)中,αij是一个标量,表示第i个节点与第j个节点的注意力权重。a是一条由可训练参数组成的向量,a∈ℝ2d。T表示向量或矩阵转置,⊕表示矩阵级联。Ni表示与i节点相邻的且边的方向指向i的所有节点的集合,包括i节点自身。leakyReLU是带泄露线性整流函数。W∈ℝd′×d是一个可训练的权重矩阵。所有节点使用相同的权重矩阵进行计算,用来获取更强的特征表达能力。
得到注意力权重后,通过相邻节点线性加权求和的方法,重构图结构中的每一个节点。在注意力重构过程中,为了使模型在高维度语义空间内捕捉到更丰富的特征,使用了文献[18]中提出的多头注意力机制,即把注意力重构的过程重复若干次,之后把所有的结果进行级联。

2.3 基于注意力重构的分类器


通过对模型输出的注意力权重βti进行可视化,可发现模型从手术描述中筛选出匹配到一条ICD手术编码的线索,同时过滤掉与这条ICD手术编码相关程度较低的信息。例2中对注意力权重进行了可视化并在下方坐标轴标出注意力权重的值βti,黄色代表较高注意力权重,绿色代表中等注意力权重,深紫色代表低注意力权重。图4和图5分别对单标签和多标签两种情况的注意力权重进行了可视化。
例2注意力权重可视化
手术描述1:右侧硬膜外血肿钻孔引流术(图4)

图4 注意力权重的可视化(1)Fig.4 Attention weights visualization(1)
手术描述2:白内障囊外摘除并人工晶体植入术(图5)

图5 注意力权重的可视化(2)Fig.5 Attention weights visualization(2)
手术描述3:经腹右侧输卵管切除术加左侧输卵管结扎术(图6)
例2中,手术描述3“经腹右侧输卵管切除术加左侧输卵管结扎术”与ICD手术编码条目66.4x00和66.9200相匹配。图6上半部分展示的是该条手术描述与ICD手术编码条目66.4x00的注意力权重向量。通过观察可发现手术描述中与ICD手术编码条目66.4x00“单侧输卵管全部切除术”相关的“经腹右侧输卵管切除术”所处部分的注意力权重较高,而其余不相关部分的注意力权重较低。经过统计,“经腹右侧输卵管切除术”的注意力权重之和约为0.91,而“加左侧输卵管结扎术”的注意力权重之和约为0.09。图6下半部分展示的是该条手术描述与ICD手术编码条目66.9200的注意力权重向量。可见“左侧输卵管结扎术”八个字所处部分的注意力权重较高,而与该编码关联度低的部分的注意力权重较低。经过统计,“经腹右侧输卵管切除术加”的注意力权重之和约为0.25,而“左侧输卵管结扎术”这九个字的注意力权重之和约为0.74。在使用手术描述对上述两个ICD编码条目进行分类的过程中,有关文字区域与无关文字区域的权重之比平均达到4∶1以上。证明模型能够通过学习,明确手术描述中与每个ICD编码条目高度相关的部分,过滤低相关部分,提升了分类时中间数据的信噪比,且与人类的阅读方式和判断原则基本一致。

图6 注意力权重的可视化(3)Fig.6 Attention weights visualization(3)
2.4 优化目标
在模型训练中,通过最小化交叉熵损失函数,可以得到模型的参数,损失函数的定义为:

公式中,CE是交叉熵损失函数,yi是正确标记的分类,当手术描述对应的标记是第i条ICD编码时yi=1,其他情况下yi=0。N是所有在标签空间中的ICD手术编码的数量,也就是标签的个数。
2.5 层次搜索
本文使用的数据集来自临床。在临床中,有些手术种类很普遍,也有一些手术种类非常少见,导致数据集中有很多标签类别出现在正样本中的次数非常少,所以数据集中标签类别的分布属于偏态长尾分布。文献[9]针对在大标签空间中且标签分布不均的情况,提出使用标签空间的本体结构对标签的概率进行因子分解,并应用到了ICD疾病分类中,小幅提升了分类性能,公式表达为:

式(12)中,hi表示第i条手术编码条目,x表示医生录入的手术描述文本,ancestors(hi)表示hi的所有祖先节点,parents(h͂i)表示h͂i的父级节点。公式表示每一个分类条目的输出的概率,是由它本身的概率连乘它所有上级节点的概率得到。通过该方法,可以利用标签空间的结构让低频率标签和高频率标签之间的概率信息得到交互。本文在模型预测的过程中,从ICD手术分类层级结构的大章节向细目的方向迭代地搜索。每层只保留前k个概率最大的ICD手术编码条目,直到达到需要预测的层级。在层次搜索的过程中每一层只保留前k个概率最大的条目,这样就避免了低概率节点的无用计算,增加模型预测速度。
3 实验
在实验中,采用的数据集含有60 000条数据,其中70%作为训练集,10%作为验证集,20%作为测试集。在验证集上调整超参数,用测试集进行模型评估。在语义层使用了维度为200的BiLSTM和文献[17]中的BERTBASE模型。在图注意力网络建模的多头注意力机制部分,使用的注意力头的数量分别为2、4、8、16。使用Adam优化器[22]对公式进行优化,初始学习率被设置为0.001。在语义层后使用dropout方法[23]防止模型过拟合,初始dropout率被设置为0.3,在每个mini batch的计算过程中,只进行一次图注意力网络的正向传播计算,然后用这一次正向传播计算输出的编码描述的隐藏表达进行当前mini batch内的计算步骤。
3.1 评估指标
本文在实验中采用的评估指标分别是P@k、macro F1和加权平均的F1值(wei ghted F1)。P@k又可称为topk精确率或precision atk,P@k的定义为:

式(13)中,1是指示函数,Y是正确标注的ICD编码所对应的索引的集合,rank()l是模型输出的第l个概率最大的ICD手术编码条目的索引。P@k评估指标指的是,模型预测的前k个概率最大的结果里面含有正确标注的标签的比例。
F1值通常在二分类问题上作为评估指标,在对本文实验结果的评估中,先把每种标签的分类结果看作一个二分类问题并求出F1值:
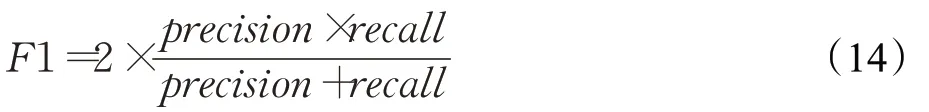
式(14)中,precision是精确率,recall是召回率。在多标签分类问题上,需要对所有标签的F1值通过一些方法进行平均,本文中使用了macro F1和加权平均的F1值(weighted F1)这两种方法进行平均。macro F1的定义为:

式(15)中,S表示所有标签种类的集合,s是其中的一种标签。N是标签类别的数量,ys和ŷs分别表示验证集中标记的标签为s的集合和模型对应的预测结果。macro F1的计算过程是求出所有标签类别的F1值并直接求平均值,所以验证集中所有标签类别无论出现的次数多少获得的权重都是相同的。加权平均的F1值(weighted F1)的定义为:式(16)中,M为验证集的总数量, ||ys表示验证集中标记的标签类别为s的个数,在加权平均的F1值的计算过程中,出现次数比较多的标签会获得更高权重。

3.2 实验结果
在对比实验中,对ICD手术分类亚目层级和细目层级的预测结果分别进行评估。所有的评估都是在划分出的20%测试集上进行的,测试集含有12 000条数据,共对8种方法进行实验并评估。在ICD手术分类中,亚目层级有2 237个分类可用,细目层级有3 792个分类可用。实验分为两个阶段,第一阶段所有方法都分别使用BiLSTM语义层和BERTBASE语义层进行实现,并设图注意力网络中注意力机制头的个数(以下简称GAT头数)为4。在进行完第一阶段的实验和评估之后,在表现比较好的方法上调整GAT头数,分别以GAT头数为2、4、8、16进行实验并进行评估。实验的方法包括:(1)noGAT,MLP在这个尝试中直接移除图注意力网络(GAT)和注意力重构的过程,在语义层之后直接通过MLP做分类预测。(2)Steinberg E et al.通过文献[9]中提出的,在语义层之后使用标签空间的本体结构对标签的概率进行因子分解做分类预测。(3)CAML,该方法是文献[5]中提出的,直接在字向量序列上使用卷积神经网络和注意力机制做分类预测,不包含标签空间建模和语义层。(4)GAT,MLP只使用无向图的GAT对标签空间建模,并直接用MLP做分类预测。(5)GAT,Att使用无向图的GAT对标签空间建模,保留手术描述注意力重构的过程。(6)treeLSTM,Att通过文献[10]中的方法使用双向树形LSTM的方式对标签空间建模,并使用本文中提出的基于注意力重构的分类器进行分类预测。(7)catGAT,Att通过3种不同方向的图结构使用图注意力网络对标签空间进行建模,之后使用基于注意力重构的分类器进行分类预测。(8)catGAT,AttHS,在catGAT,ATT方法的基础上,在模型预测时使用层次搜索的方法。
在实验中,除了不包含语义层的CAML方法,其他每种方法都使用两种语义层进行对比评估。通过图7和图8可看出,BERTBASE语义层在各项评估标准上的整体表现比BiLSTM语义层略微占优势,其中在没有标签空间建模和注意力重构的方法上优势较明显,但在本文提出的方法catGAT,AttHS上,使用BERTBASE语义层带来提升并不突出。从表1、表2中可看出,使用图注意力网络(GAT)和基于注意力重构的分类器大幅提高了模型在P@k评估指标上的表现。在表3、表4中,macro F1值和加权平均的F1值(weighted F1)差别比较大,这是由于数据集中标签类别的分布属于偏态分布,有些种类的手术在临床中很普遍,也有一些手术非常少见。没有使用标签空间建模的noGAT,MLP、Steinberg E et al.和CAML方法的macro F1值比较低,说明标签空间建模对应对数据集标签分布不均衡的情况有重要意义。

图7 不同语义层细目P@5实验结果对比Fig.7 Performance in terms of detailed entriesofdifferent semantic layers(P@5)

图8 不同语义层细目macro F1实验结果对比Fig.8 Performance in terms of detailed entriesof different semantic layers(F1)

表1 BiLSTM语义层实验结果对比(P@k)Table 1 Performance of BiLSTM semantic layer(P@k)

表2 其他语义层实验结果对比(P@k)Table 2 Performance of other semantic layer(P@k)
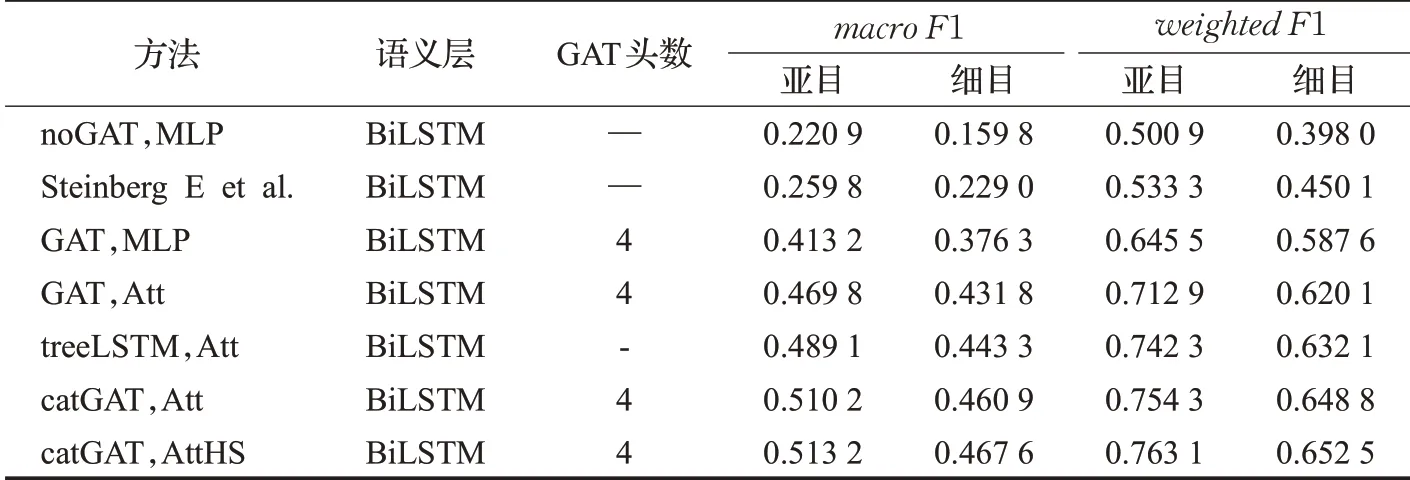
表3 BiLSTM语义层实验结果对比(F1值)Table 3 Performance of BiLSTM semantic layer(F1 score)
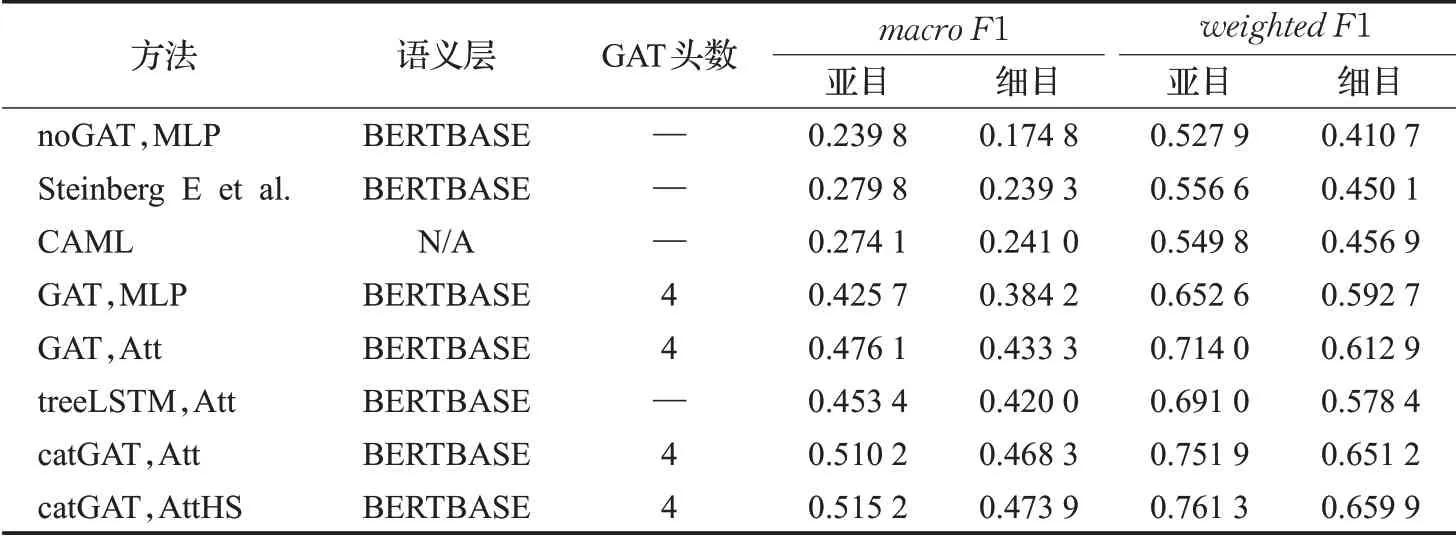
表4 其他语义层实验结果对比(F1值)Table 4 Performance of other semantic layer(F1 score)
在进行完第一阶段的实验和评估之后,在表现最佳的方法catGAT,AttHS的基础上,调整GAT头数,并评估在细目macro F1和细目P@5上的表现差异。如表5和图9所示,将GAT头数调整为2之后,在上述两项评估指标上都有略微下降,GAT头数调整为8之后,较GAT头数为4时的变化并不明显,而调整成16后在上述两相评估指标上都有一定程度下降,可见GAT头数的增大使得模型参数冗余并带来了不利影响。综上所述,本文提出的catGAT,AttHS方法,使用BERTBASE语义层,使用8个GAT头,在亚目和细目P@k、macro F1值和加权平均的F1值(weighted F1)这三种评估指标上都取得了最佳的成绩。
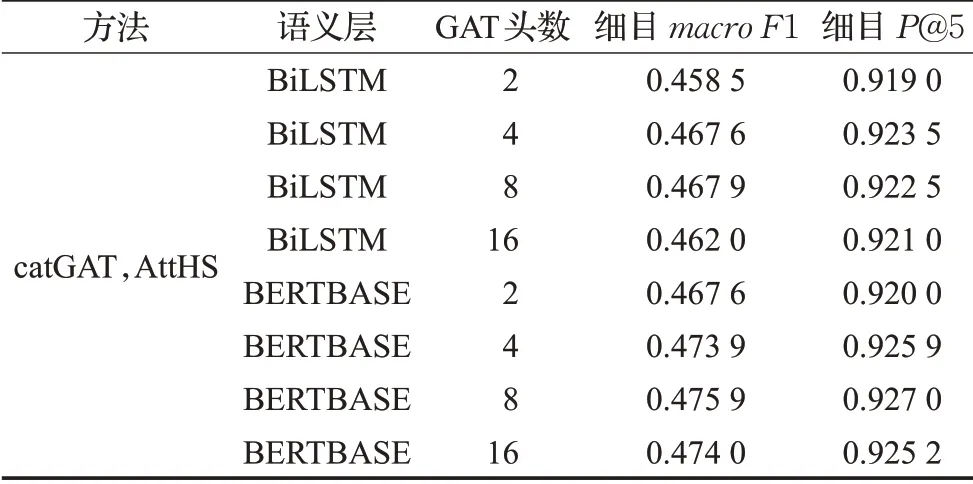
表5 GAT注意力机制头数实验结果对比Table 5 Performance of different numbers of GAT attention heads
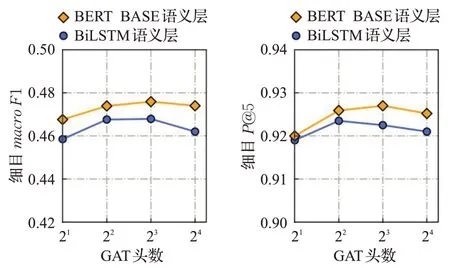
图9 GAT注意力机制头数实验结果对比Fig.9 Performance of different numbers of GAT attention heads
4 结束语
本文提出了一种面向ICD手术分类的端到端深度学习方法。该方法主要采用了标签空间建模、注意力重构和层次搜索。在标签空间建模和层次搜索过程中,将标签空间的结构信息融入到模型当中。基于注意力重构的分类器能够在文本中寻找与标签相关的线索来进行分类。所提出的方法可应用于标签空间有本体结构或层级结构的数据集上,并且基于注意力重构的分类器在大标签空间内有很好的可扩展性。实验结果表明所提方法在亚目和细目层级的ICD手术分类上获得了较好分类表现。但是实验结果中macro F1评估指标表明,标签类别分布不均衡的问题对模型分类性能影响很大。在实际临床中,大量且高质量的标记数据获取代价很大,需要组织大量人力进行数据标注和校对。而且现实中很多情况下数据的分布往往是不均衡的。所以,怎样利用少量的数据样本在出现频率较低的标签类别上取得良好的分类效果是一个值得研究的问题,小样本学习和单样本学习是针对于此类问题的解决方法。除此之外,虽然高质量的标记数据获取代价很大,但大量的无标记的数据是比较容易获得的。近年来,半监督学习和自监督学习的研究让无标记数据得到利用。怎样将上述方法应用到国际疾病分类中,是下一步的研究方向。
