IB网上CPU-GPU异构超算平台容器性能评估及优化
2021-09-26王宪贺
胡 鹤,赵 毅,王宪贺
中国科学院 计算机网络信息中心,北京100190
传统HPC负载具有强环境依赖的特点,所需的软件堆栈通常很复杂,涉及编译器、通信中间件及数学库。容器技术的产生带来不同依赖环境下应用程序的可移植性。为支持智能业务的机器学习负载,超算平台均采用CPU+GPU的混合架构[1],有往容器迁移演进的趋势,确保开发环境的可移植性及训练的可复制性。美国橡树岭国家实验室的著名超级计算机SUMMIT提供了容器服务[2]。NERSC开发了类似Docker的Linux容器技术OpenShift来提高其HPC系统的灵活性和可用性[3]。天河二号实践了基于容器的HPC/大数据处理,优化了超算环境的公共服务能力与模式,优化用户应用体验[4]。
在并行应用程序中,影响性能的因素主要包括计算、通信以及I/O模式等。因此,相关研究对容器性能和裸机性能进行比对,以此来评估不同超算应用程序移植到容器中的适用性,并评估各种影响计算效率的因素。Felter等人在IBM研究报告[5]中指出,Docker的性能表现优于几乎所有测试场景中的虚拟化性能,但Docker分层文件存储方式会产生一定的I/O性能损耗,在网络密集型工作负载时,其本身的NAT会带来较大开销。GPU方面,文献[6]评估了机器学习应用在GPU上的训练效率,以证明容器化部署对机器学习的效率开销不大。通信方面,文献[7]对比同样进程数量但容器个数及容器内部进程数不同的情况下,NPB基准测试程序测试结果的变化,证明HPC工作负载会影响容器间的通信性能。I/O方面,文献[8]对容器的I/O性能竞争进行深入的讨论和实验分析,分析了I/O各项指标随容器数量的变化趋势,提出通过动态限制过载容器I/O强度从而提高容器系统I/O性能。
以上研究均为针对影响高性能计算应用各方面I/O、通信等进行性能对比,但并未利用分析结果,提出在HPC上进行容器应用部署及优化的合理化建议,使容器应用性能最大化。本文执行全面的基准测试,分析容器虚拟化解决方案下集群各项性能表现,包括I/O、并行通信及GPU加速性能,并根据不同应用的特点提出系统设置的合理化建议,为管理员及应用研发人员提高应用性能提供参考。
1 测试环境配置
测试是基于中国科技云基础设施“人工智能计算及数据服务应用平台”进行的,数据传输使用计算存储网络为56 Gb/s FDR Infiniband高速网络,每个节点都配有两个Intel Xeon E5-2650处理器(每个具有12个内核,频率为2.40 GHz),256 GB RAM。每个节点配有8块Tesla P100 GPU卡。使用具有Linux内核3.10.0的64位CentOS 7.6来执行所有测试,并行环境部署了OpenMPI1.6.5版。
采用NVIDIA提供的支持GPU的Docker镜像作为基础镜像,该镜像能够发现宿主机驱动文件以及GPU设备,并且将这些挂载到来自Docker守护进程的请求中,以此来支持Docker GPU的使用[9]。按照文献[10]的操作对容器使用IB进行适配,将Docker默认的网络地址设置成IB卡的地址,在容器内部安装配置ssh做进程启动。为了保持一致性,容器和宿主机具有相同的软件堆栈并为比较使用容器内部MPI库及宿主机MPI库两者不同的性能表现,在容器内及容器外分别部署MPI库,配置了相同的MPI版本,如图1所示。为衡量Docker运行时的性能,以及衡量硬件在容器内虚拟化后相应的系统开销,本文使用基准测试程序分别针对文件系统I/O性能、并行通信性能与GPU计算性能进行测试。

图1 测试镜像软件栈Fig.1 Software stack of host and container
2 测试结果与性能评估
2.1 文件系统读写性能
为面向宿主机和容器分析分布式集群文件系统的读写性能,选取IOR[11]作为测试工具进行性能分析。IOR(Interleaved or Random)是一种常用的文件系统基准测试应用程序,旨在测量POSIX和MPI-IO级别的并行I/O性能,特别适用于评估并行文件系统的性能。
测试使用2个节点,每节点12核心,每进程生成5 GB数据进行读写操作。测试两种使用场景:
(1)主机上启动一个容器,容器内启动多个进程;
(2)主机上启动多个容器,每容器启动一个进程。
场景1测试IO读写带宽随进程数的变化趋势如图2。

图2 IOR读写带宽随进程数变化趋势Fig.2 IOR read-write bandwidth trend with the number of processes
从图2可以看出容器的性能基本与宿主机性能保持一致,最大开销为8%。因此,容器采用bind mount的方式,使用宿主机的存储,文件系统I/O开销仅比宿主机多占用容器系统软件栈,性能差距不大。
使每个容器产生同样的I/O负载进行场景2测试,随容器数量的增长,I/O性能的变化如图3所示。当容器数量为13时,IOR程序异常终止。读写带宽呈类幂函数的下降趋势。
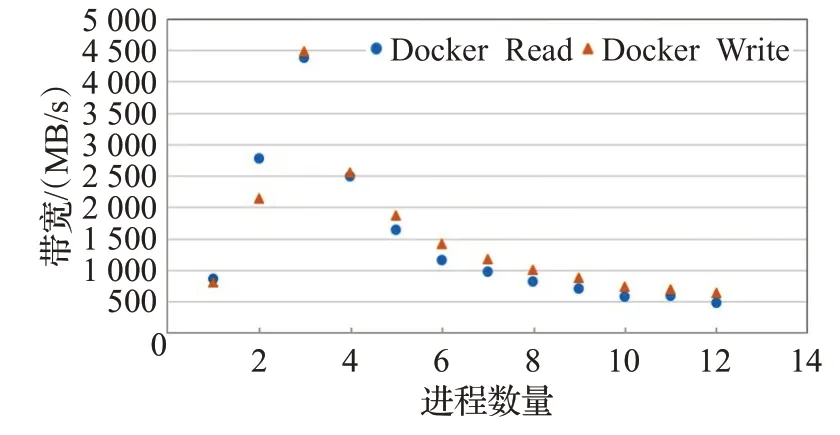
图3 IOR读写带宽随容器数变化趋势Fig.3 IOR read-write bandwidth trend with the number of containers
因此当宿主机上容器个数增多,对I/O密集型应用而言,各容器之间会抢占系统资源,导致整体I/O性能下降。原因是Docker容器技术本身没有提供良好的容器I/O管理机制,无法保证容器之间的I/O隔离性,降低主机上容器之间的I/O性能影响。因此在实际应用中研发和部署中,应设法降低容器间I/O性能的影响。
2.2 通信性能
该测试的目的是比较容器间通信与物理机间通信,衡量容器MPI并行通信的性能开销。在进行MPI通信性能对比之前,通过InfiniBand设备厂商Mellanox提供的基准测试工具测试InfiniBand网卡带宽和网络延迟[12]。得到两台测试宿主机的带宽约为50 Gb/s,接近理论值。用qperf[13]测试IB网针对基于TCP或UDP的通信性能,得出容器间的带宽约为11.12 Gb/s,约为IB网络带宽的25%。
使用广泛使用的MPI库的带宽及延时基准OSU[14]测试容器的并行通信性能开销,并比较两种方案——使用容器MPI库及宿主机MPI库两者的不同。在不同宿主机上各启动一个容器进行测试,带宽结果的比较如图4所示。采用宿主机MPI宿主机和容器通信的峰值带宽分别为6 694 MB/s以及5 887 MB/s,Docker容器与宿主机相比在并行通信方面有约为10%的开销;而使用容器内部的MPI,带宽仅为使用宿主机带宽的约25%。
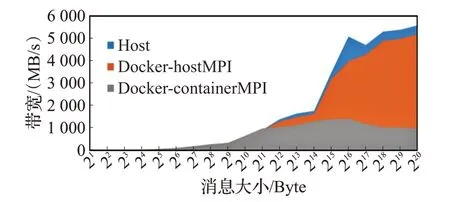
图4 MPI点对点通信带宽Fig.4 MPI Point-to-Point communication performance
延迟结果的比较如表1所示,使用宿主机MPI,容器延迟比宿主机延迟高6%,而使用容器内部MPI相比使用主机MPI延迟多了2.8倍。

表1 MPI点对点通信延迟Table 1 MPI point-to-point communication latency
使用容器MPI比使用主机MPI开销大的原因,是由于容器中不能识别IB卡,通信只能通过IB卡生成的虚拟网桥进行,产生了系统CPU和内存开销而造成的。
为评估其他MPI常见函数的延迟情况,使用基准测试程序IMB[15],利用宿主机的MPI库,选择四种常见的集合通信方式bcast、allgather、allreduce及alltoall进行宿主机和容器的集合通信性能测试。对比两种情况的测试结果:(1)每台宿主机启动20进程;(2)每台宿主机启动一个容器,容器内启动20进程。
测试结果如图5所示,显示常见的四种MPI库函数容器与主机的延迟差值随数据包大小的变化趋势。在实验中发现,容器并行通信性能与宿主机接近,但随着消息包增大通信延迟差距增大。

图5 IMB集合通信性能(40进程)Fig.5 Collective communication performance with 40 processes
2.3 GPU计算性能
本文采用了安装好GPU驱动的开源版本Docker镜像nvidia-docker,可以在容器中能够直接访问GPU资源。之后如需支持不同版本的开发框架,只需在容器中安装cuda toolkit即可。这种方式可以使同一个GPU硬件驱动支持不同CUDA版本,解决用户CUDA版本多样化需求。使用ResNet-50[16]模型通过深度学习框架TensorFlow[17]进行了性能评估。在所有测试中均使用ILSVRC2012[18]数据集。测试结果如图6所示。

图6 ImageNet图像处理吞吐量Fig.6 ImageNet image processing throughput
使用AI训练和推理模型对宿主机和容器进行测试的结果表明,在采用多个容器的情况下,容器能够以近线性方式向上扩展。容器与宿主机性能接近,最大开销约为7%。通过查看GPU利用率,所有容器的GPU达到了饱和状态,使用容器进行训练可充分利用GPU的性能。
3 容器应用优化建议
测试结果表明,Docker可以很好地支持GPU、Infiniband等硬件,能够在超算领域带来更好的可移植性。在I/O、通信、GPU计算能力方面,Docker带来的开销可以忽略。通过以上实验结果分析,提出应用程序在进行容器配置采用如下建议。
3.1 容器IO优化
I/O方面通过bind mount的形式与宿主机共享文件系统,将存储盘挂载到容器,减少文件分层存储方式带来的I/O性能损耗。
对于I/O密集型应用,减少宿主机上启动容器的个数,避免同一时间多容器同时进行I/O操作。减少宿主机上容器的I/O争用。而容器内部,通过MPI或OpenMP等实现对并发、同步、数据读写的支持,完成I/O的编排。
3.2 容器通信优化
建议使用宿主机的MPI库,发挥平台IB网RDMA传输特性带来的优势。因容器内部对Infiniband的支持问题,使用宿主机MPI约为使用容器MPI性能的四倍。实现时将宿主机文件系统中的MPI库文件映射到容器中,在并行通信时选择宿主机的MPI库。
使用宿主机MPI,容器并行通信性能与宿主机接近,但随着消息包增大通信延迟差距增大。故对于通信负载较高的通信密集型应用程序,使用容器会给通信性能带来一定开销。
3.3 充分利用容器可移植性
用英伟达的镜像作为基础进行配置,也可以选择在自身镜像中安装nvidia-docker-plugin的方式支持GPU。容器中可以识别GPU卡,因此可以在容器内部安装与宿主机不同的CUDA版本,实现对不同应用软件的兼容。系统管理员可以准备装有不同应用版本的容器镜像,放入容器仓库中方便用户下载,使用户集中精力于模型和算法,而不是应用环境配置。
3.4 进行容器安全设置
在Docker设计之初安全性是无关紧要的,用户可以使用root用户挂载主机文件目录,还可以用root权限访问主机上的其他容器,而造成系统破坏或数据泄露。在容器使用时,系统管理员需设置好访问控制策略,尽量使用户独占节点,避免用户的容器被其他用户以root权限访问。另外,保护好宿主机的MPI目录,挂载单独的分区,并设置为只读。
4 结束语
容器可以解决HPC领域开发环境的一系列问题,带来应用程序跨平台的可移植性。本文评估超算环境下Docker容器的性能表现,从计算、I/O、通信三方面,通过基准软件衡量容器本身开销。在测试中观察到的容器总体性能开销是可以容忍的。具体使用时,应尽量使用宿主机的文件系统及MPI库,尽量减少并发容器的个数,发挥计算网络性能并减少文件系统开销。另外提出了增加容器隔离性、安全性,及可管理性的相关设置。本文尚未针对大规模应用使用容器进行相关实验和结果分析,需要在今后的工作中进一步深入。
