基于联邦集成算法对多源数据安全性的研究*
2021-09-24罗长银陈学斌张淑芬
罗长银,陈学斌,刘 洋,张淑芬
(1.华北理工大学理学院,河北 唐山 063210;2.河北省数据科学与应用重点实验室,河北 唐山063210; 3.唐山市数据科学重点实验室,河北 唐山 063210)
1 引言
近年来,随着数据挖掘等技术的快速发展,隐私数据安全保护显得尤为重要,且传统的隐私保护技术并不能满足要求,2016年谷歌首次推出“联邦学习”概念,受到社会各界以及专家学者的广泛关注[1]。联邦学习的训练数据来源于各个数据源上的本地数据,不需要收集、存储数据到云端和整合多方数据,这种方法大大减少了敏感信息泄露的风险[2]。但是,因联邦学习的训练数据来源于不同数据源,训练数据并不能满足独立分布和训练数量一致这2个能影响联邦模型的条件[3]。若数据源的训练数据分布不同,那么整合多方子模型成为巨大的难题[4]。文献[5]使用logistic回归模型作为初始模型对各个数据源的数据进行训练,采用神经网络来整合多方子模型,但神经网络模型一般表现为非凸函数,很难使参数平均化后的模型损失函数达到最优。文献[6]针对独立同分布和非独立同分布的数据进行了研究,发现当训练数据是非独立分布时,其训练的全局模型精度不能满足预期要求。针对上述问题,本文提出了联邦集成算法,其所做的贡献如下所示:

Figure 1 stacking集成过程图1 stacking integration process
(1)通过RSA加密算法产生的公钥来加密由 hash算法计算出的数据hash值与数据共同传输至各数据源,各数据源获得数据并使用私钥解密得到hash值,并重新计算数据的hash值,判断传输计算的hash值与传输后重新计算的hash值是否相等。若二者相等,表明数据在传输过程中是安全与完整的,将数据存储至对应的数据源中;若二者不相等,表明数据在传输过程中被篡改,将数据从对应的数据源中删除。
(2)各数据源使用随机森林、朴素贝叶斯、神经网络、极端随机森林、GBDT(Gradient Boosting Decision Tree)和逻辑回归作为初始全局模型分别在各数据源的数据上进行训练,选择最优的作为初始全局模型,可以得到多个本地模型。
(3)各数据源的本地模型使用4种集成算法(stacking集成算法、voting集成算法、Adaboost集成算法和平均法)和不集成方式分别整合为新的全局模型,经比较,stacking模型与Adaboost模型的效果最优,能满足要求。
(4)使用256 B的由RSA加密算法产生的私钥对新的全局模型进行加密,各数据源使用公钥进行解密,以此来保证全局模型的安全性。
2 相关知识
(1)联邦学习。
联邦学习是隐私保护下的算法优化可实现路径,同时也是保护数据安全中“数据孤岛”问题的解决方案[7]。联邦学习允许从跨数据所有者分布的数据中构建联合模型,提供了跨企业的数据使用方式和模型构建蓝图,实现了各个企业的自有数据不出本地,只通过加密机制下的参数交换,不违反数据隐私法规地建立优化机器学习模型[8]。
(2)stacking集成算法。
stacking集成算法是一种堆叠算法,第1步使用多个算法求出结果,再将结果作为特征输入到下一个算法中训练出最终的预测结果[9],如图1所示。
(3)voting集成算法。
voting集成算法是通过多个模型和简单的统计量来进行组合预测[10]。
(4)Adaboost集成算法。
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,然后把这些弱分类器集合起来,构成一个更强的最终分类器[11]。
(5)哈希算法。
哈希算法是将数据打乱混合,使用散列算法重新创建一个叫做散列值的指纹,通常用一个短的随机字母和数字组成的字符串表示散列值[12]。
(6)RSA加密算法。
RSA加密算法是一种非对称加密算法,其公钥和私钥是一对大素数的函数,从一个公钥和密文恢复出明文的难度,等价于分解2个大素数之积[13]。
(7)随机森林。
随机森林是以决策树为基学习器构建集成的一种机器学习算法,是由很多决策树分类模型组成的组合分类模型,每个决策树分类模型都有一票投票权来选择最优的分类模型[14]。
(8)朴素贝叶斯。
朴素贝叶斯是一种基于贝叶斯决策理论的分类方法,是贝叶斯分类器的一种拓展与衍生[15]。
(9)神经网络。
神经网络是一种模仿动物神经网络行为特征进行分布式并行信息处理的算法模型,通过调整内部大量节点之间互相连接的关系达到信息处理的目的[16]。
(10)极端随机森林。
极端随机森林同样是一种多棵决策树集成的分类器,与随机森林分类器比较,区别是不采取bootstrap采样替换策略,而是直接采用原始训练样本,目的在于减少偏差;在每棵决策树的决策节点上,分裂测试的阀值是随机选择的[17]。

Figure 2 Data collection stage of the federated ensemble algorithm 图2 联邦集成算法的数据收集阶段
(11)逻辑回归。
logistic回归是一种广义线性回归(genera- lized linear model),模型形式为w′x+b,logistic回归函数L将y=w′x+b对应一个隐状态p,p=L(w′x+b),根据p与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归[18]。
(12)GBDT。
GBDT是一种用于回归的机器学习算法,该算法由多棵决策树组成,所有树的结论累加起来作为最终答案[19,20]。
3 联邦集成算法
3.1 算法描述
在联邦集成算法包括数据收集阶段与模型训练阶段。从数据收集阶段来说,首先是每个客户端的数据进行hash值计算,并将hash值与数据使用RSA加密算法产生的公钥加密后传输至各数据源;其次是各数据源使用私钥解密获取hash值与数据,各数据源需要重新计算数据的hash值;最后判断传输前计算的hash值与传输后重新计算的hash值,若不相等,则删除,若相等,则将数据存储至数据源内,并参与模型训练,具体过程如图2所示。
在模型训练阶段,首先是可信第三方使用由RSA加密算法产生的公钥加密初始化的随机森林、神经网络、朴素贝叶斯、极端随机森林、逻辑回归和GBDT,并传输至各数据源;然后各数据源使用私钥解密,获取初始化的模型,并在各数据源上进行训练,根据其性能选择最优的作为初始全局模型,得到本地模型;最后使用Adaboost、voting、stacking、平均法4种集成算法来整合本地模型参数,得到更新的全局模型,并不断迭代优化此阶段,以此提升全局模型的准确率,具体过程如图3所示。

Figure 3 Schematic diagram of the federated ensemble algorithm at the training model stage图3 训练模型阶段的联邦集成算法示意图
算法流程如下所示:
Step1使用各客户端产生的数据计算其hash值,使用RSA加密算法所产生的公钥加密其hash值并将数据共同传输至各数据源;各数据源获得数据与使用私钥解密的hash值,并重新计算数据的hash值,判断传输前计算的hash值与传输后重新计算的hash值是否相等。若二者相等,将数据存储于数据源中并参与模型训练,若二者不相等,表明数据在传输过程中被篡改,删除该数据且不参与模型训练。
Step2对于联邦学习框架来说,初始化的全局模型决定着最终模型的上限,本文选择随机森林模型、神经网络模型、朴素贝叶斯模型、极端随机森林模型、逻辑回归和GBDT 共6种模型作为初始化的全局模型,各数据源分别使用6种初始化的全局模型在本地进行训练,根据6种模型在各数据源上训练的得分情况进行选择。
Step3将最优的初始全局模型在各数据源上分别进行训练,并不断优化其对应的参数,建立各数据源所对应的本地模型。
Step4采用voting方法、Adaboost方法、stacking方法和平均法分别对各数据源所对应的本地模型进行集成,使更新的全局模型准确率满足要求。
Step5使用RSA加密算法产生256 B的密钥对,将公钥分发至各数据源,使用私钥加密新的全局模型传输至各数据源,各数据源使用公钥解密,并使用新的全局模型再次训练。
采用上述算法流程设计的算法如算法1所示。
算法1联邦集成算法

1.//(1)Data collection stage
2.fori=0 ton
3.D′i=E_hash(Di);
4.returnD′i
5.endfor
6.//(2)Generate secret key
7.fori=0 ton
8. Various data sources:Pi=Gpublic_RSA(x),pi=Gprivate_RSA(x);//xrepresents a random number
9.endfor
10.//(3)Validation dataset
11.fori=0 ton
12. Clients:D″i=E_Pi(D′i)
13. Various data sources:D′i=D_pi(D″i) and recalculate:D‴i=E_hash(Di);
14.ifD′i≠D‴i
15. deleteDi;
16. exit;
17.else
18. sendDito various data sources;
19.endfor
20.//(4)Model training stage
21.Trusted third party:y1,y2,y3,y4,y5,y6=E_RSA(m1,m2,m3,m4,m5,m6) send to various data sources;
22.Various data sources:m1,m2,m3,m4,m5,m6=D_RSA(y1,y2,y3,y4,y5,y6);
23.s1(Di),s2(Di),s3(Di),s4(Di),s5(Di),s6(Di)=m1_train(Di),m2_train(Di),m3_train(Di),m4_train(Di),m5_train(Di),m6_train(Di);
25.fori=1 ton
28.endfor
3.2 性能分析
本文提出的联邦集成算法能够在保证模型准确率的前提下,提升数据与模型的安全性。
3.2.1 算法的复杂度分析
联邦集成算法的复杂度为哈希算法的复杂度、RSA加密算法产生的复杂度、选择最优的初始化全局模型并产生子模型的复杂度和将多个本地模型集成为最终的全局模型的复杂度之和。即时间复杂度为O(M(mnlogn)+M4),其中,n代表样本数,m表示特征数,M表示有M棵树来投票。事实上,采用联邦学习框架和stacking集成算法必然会造成此算法的时间复杂度和空间复杂度均高于传统的数据融合算法,但兼顾了模型准确率和数据与模型的安全性[21]。
3.2.2 算法的安全性分析
该算法使用联邦学习框架与集成学习的思想,从数据层面上,使用RSA加密算法对每个客户端的数据进行hash计算,并将hash值与数据共同传输至各数据源,各数据源重新计算其hash值,可保证数据在收集阶段的安全性与完整性。从模型层面上:(1)采用RSA非对称加密算法,采用256 B的密钥来加密全局模型,并将加密的全局模型分发至各数据源,各数据源根据新的全局模型再次进行训练来优化全局模型;(2)该算法是在联邦学习的框架下实现的,各数据源的数据存储在本地,消除了因数据传输带来的风险,提升了模型与数据的安全性。
4 实验与结果分析
4.1 实验参数设置
本文设计的算法由Python语言和Pycharm集成软件开发实现。实验硬件环境为:Intel(R) Core i5-4200M CPU 2.50 GHz处理器,内存8 GB;操作系统为Windows 10。在实验数据方面,采用从http://sofasofa.io/competition.php?id=2下载的数据集,该数据集有15.6 MB。
4.2 实验数据分析
各客户端使用RSA加密算法产生的公钥来加密由hash算法计算的数据hash值,并与数据共同传输至各数据源,各数据源使用私钥解密,且重新计算数据的hash值,判断数据经过传输的hash值与传输前的hash值是否相等,将hash值相等的数据存储至各数据源内,可保证数据在收集阶段的安全性与完整性。
模型训练阶段分为2部分,第1部分:可信第三方使用公钥加密6种类型的初始模型,并传输至各数据源;将集成后更新的全局模型使用公钥加密传输至各数据源,各数据源使用私钥解密进行训练来优化全局模型。第2部分:各数据源使用私钥解密后,获取6种初始模型,使用6种初始模型在各数据源上进行训练,可以得到多个本地模型,同时选择最优的作为初始全局模型,然后使用集成算法进行集成,获得更新的全局模型准确率均值。
为保证全局模型分发至数据源上的安全性,采用RSA加密算法随机产生256 B的密钥(图4和图5为公私钥的变化图),使用私钥加密全局模型,将公钥广播至各数据源;各数据源使用公钥解密全局模型进行训练,以优化全局模型。

Figure 4 Change of public key generated by RSA encryption algorithm图4 采用RSA加密算法产生的公钥变化图
在联邦学习的框架下,初始全局模型的优劣决定着模型的上限,本文选择6种初始模型,分别为:随机森林、朴素贝叶斯、极端随机森林、神经网络、逻辑回归和GBDT,且使用平均值与标准差作为衡量初始全局模型优劣的标准,6种初始模型的性能如表1所示。

Figure 5 Change of private key generated by RSA encryption algorithm图5 采用RSA加密算法产生的私钥变化图
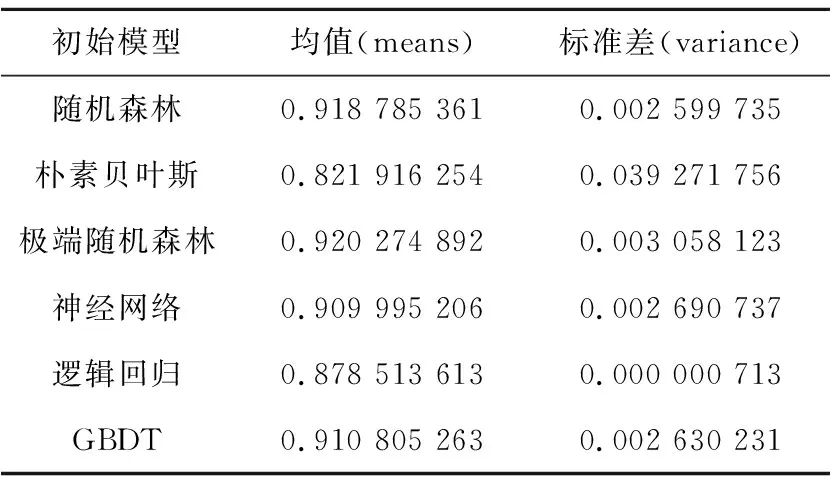
Table 1 Performance of the initial model
从表1中可以看到,准确率均值最高的依次是极端随机森林、随机森林、GBDT、神经网络、逻辑回归和朴素贝叶斯,标准差从小到大的顺序依次是逻辑回归、随机森林、GBDT、神经网络、极端随机森林和朴素贝叶斯。随机森林与极端随机森林的准确率相差不大,但标准差却相差很大,故综合考虑性能从高到低的排名是随机森林、极端随机森林、GBDT、神经网络、逻辑回归和朴素贝叶斯。
根据6种初始全局模型在各数据源上的表现,本文依次选用随机森林、极端随机森林、GBDT、神经网络、逻辑回归和朴素贝叶斯作为初始全局模型。而对于多个本地模型采用stacking集成算法、voting集成算法、Adaboost集成算法和平均法依次对多个本地模型进行集成,得到4种集成算法集成的新全局模型的准确率。
图6表示初始全局模型选用随机森林时使用4种集成算法与传统整合多方数据集中训练的方法[22,23]在各数据源上训练的准确率变化情况,本文将迭代100次的平均值作为训练结果的数值,表2为随机森林使用4种集成算法与传统整合多方数据集中训练的方法的性能。
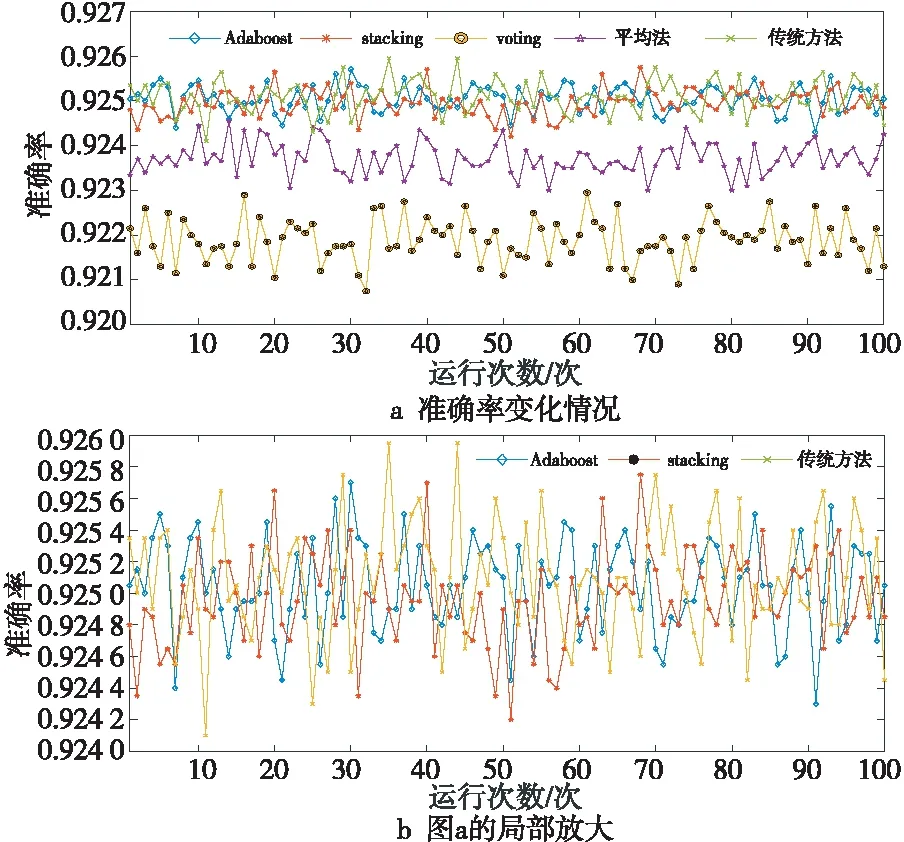
Figure 6 Accuracy changes in the training of four ensemble algorithms and traditional method on various data sources图6 随机森林使用4种集成算法 与传统方法训练的准确率变化情况

Table 2 Performance of random forest using four ensemble algorithms and traditional method
从表2可以得到,准确率均值从高到低依次是传统整合多方数据集中训练的方法、Adaboost集成算法、stacking集成算法、平均法和voting集成算法,标准差从小到大的顺序依次是Adaboost集成算法、stacking集成算法、传统整合多方数据集中训练的方法、平均法和voting集成算法,其中Adaboost集成算法与stacking集成算法比传统方法的准确率均值下降约0.2‰,传统整合数据方法的准确率均值为92.52%,Adaboost集成算法的准确率均值为92.50%,stacking集成算法的准确率均值为92.49%,且从标准差来看,模型最稳定的是Adaboost集成算法与stacking算法(标准差越小模型越稳定)。
极端随机森林为初始全局模型的准确率高于随机森林,但标准差较大,说明模型的稳定性差,故综合考虑其性能仅次于随机森林。
图7表示初始全局模型选用极端随机森林使用4种集成算法与传统整合多方数据集中训练的方法在各数据源上的训练情况,本文将迭代100次的平均值作为训练结果的数值。表3为随机森林使用4种集成算法与传统整合数据方法的性能。

Figure 7 Accuracy changes of extreme random forest training using four integrated algorithms and traditional method图7 极端随机森林使用4种集成算法 与传统方法训练的准确率变化情况
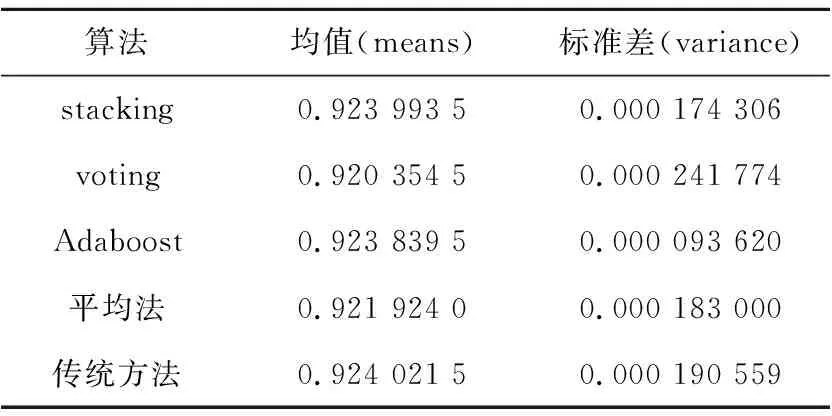
Table 3 Performance of extreme random forest using four ensemble algorithms and traditional method
从表3可以得到,准确率均值从高到低依次是传统整合多方数据集中训练的方法、stacking集成算法、Adaboost集成算法、平均法和voting集成算法,标准差从小到大的顺序依次是Adaboost集成算法、stacking集成算法、平均法、传统整合多方数据集中训练的方法和voting集成算法,其中stack- ing集成算法与传统整合多方数据集中训练的方法准确率均值相比,准确率均值下降不到0.1‰,Adaboost集成算法与传统整合多方数据集中训练方法相比,准确率均值下降不到0.2‰,传统整合多方数据集中训练方法的准确率均值为92.402%,stacking集成算法的准确率均值为92.399%,Adaboost集成算法的准确率均值为92.384%,且模型最稳定的是Adaboost集成算法与stacking算法。
GBDT为初始全局模型的准确率低于随机森林与极端随机森林,其标准差高于随机森林,低于极端随机森林,说明模型的稳定性较差,故综合考虑其性能次于随机森林与极端随机森林。
图8表示初始全局模型为GBDT时使用4种集成算法与传统整合多方数据集中训练的方法在各数据源上训练的准确率变化情况,本文将迭代100次的平均值作为其训练结果的数值。表4为GBDT使用4种集成算法与传统整合数据方法的性能。
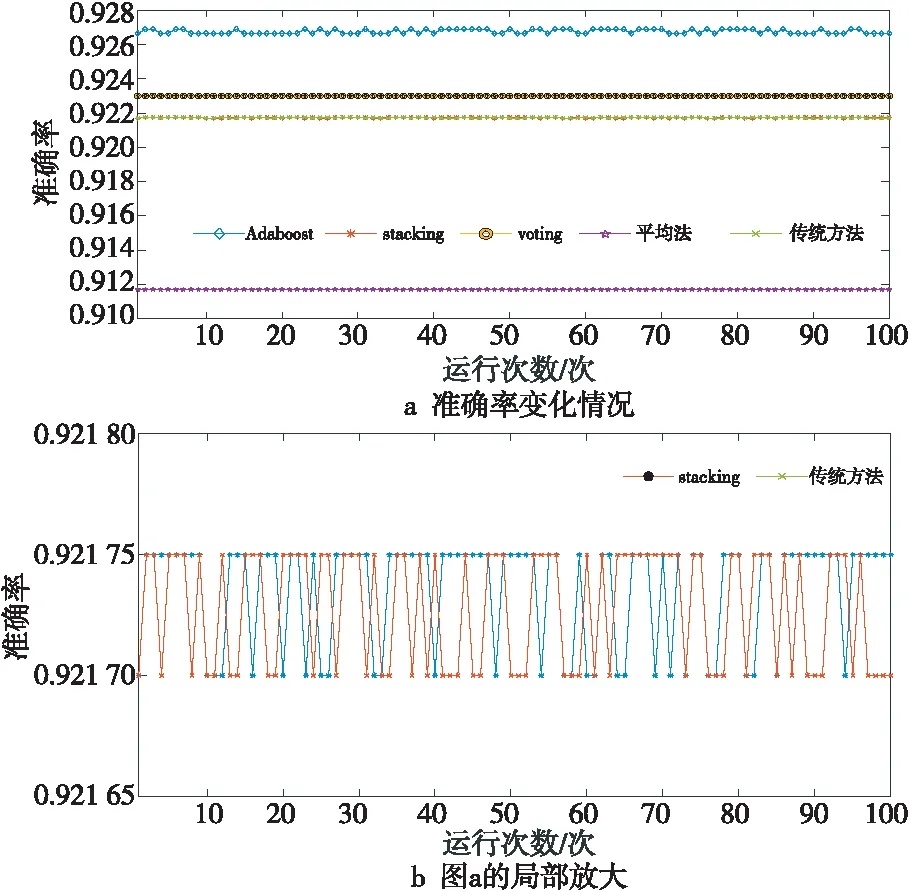
Figure 8 Accuracy changes of GBDT training using four integrated algorithms and traditional method图8 GBDT使用4种集成算法 与传统方法训练的准确率变化
从表4可以得到,准确率均从高到低依次是Adaboost集成算法、voting集成算法、stacking集成算法、传统整合多方数据集中训练的方法和平均法,标准差从小到大的顺序依次是平均法、voting集成算法、stacking集成算法、传统整合多方数据集中训练的方法和Adaboost集成算法,其中Adaboost集成算法、voting集成算法、stacking集成算法的准确率均高于传统整合多方数据集中训练的方法,Adaboost集成算法的准确率均值92.676 5%,voting集成算法的准确率均值为92.3%,stacking集成算法的准确率均值为92.173 6%,传统整合多方数据集中训练的方法的准确率均值为92.172 8%。

Table 4 Performance of GBDT using fourensemble algorithms and traditional method表4 GBDT使用4种集成算法与传统方法的性能
神经网络为初始全局模型的准确率低于随机森林、极端随机森林和GBDT,其标准差高于随机森林与GBDT,低于极端随机森林,说明模型的稳定性较差,故综合考虑其性能次于随机森林、极端随机森林和GBDT。由于不同参数的神经网络无法使用Adaboost进行集成,故采用stacking集成算法、voting集成算法和平均法来整合不同参数的神经网络。
图9表示初始全局模型选用神经网络时使用3种集成算法与传统整合多方数据集中训练的方法在各数据源上训练的准确率变化情况,本文将迭代100次的平均值作为其训练结果的数值。

Figure 9 Accuracy changes of neural network training using three ensemble algorithms and traditional method图9 神经网络使用3种集成算法 与传统方法训练的准确率变化
表5为神经网络使用3种集成算法与传统整合数据方法的性能。
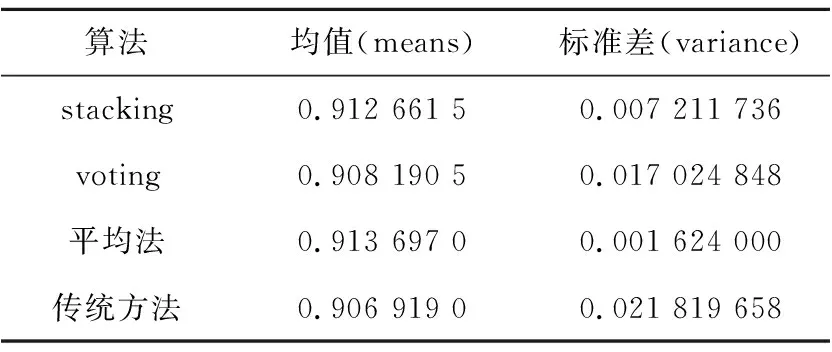
Table 5 Performance of neural network using three ensemble algorithms and traditional method表5 神经网络使用3种集成算法与传统方法的性能
从表5可以得到,准确率均值从高到低依次是平均法、stacking集成算法、voting集成算法和传统整合多方数据集中训练的方法,标准差从小到大的顺序依次是平均法、stacking集成算法、voting集成算法和传统整合多方数据集中训练的方法,其中平均法的准确率均值为91.3697%,stacking集成算法的准确率均值为91.266%,voting集成算法的准确率均值为90.819 1%,传统整合多方数据集中训练的方法准确率均值为90.6919%。
逻辑回归为初始全局模型的准确率低于随机森林、极端随机森林、GBDT和神经网络,其标准差在6种模型中最低,说明模型的稳定性较好,故综合考虑其性能次于随机森林、极端随机森林、GBDT和神经网络。
图10表示初始全局模型选用逻辑回归时使用4种集成算法与传统整合多方数据集中训练的方法在各数据源上训练的准确率变化情况,将迭代100次的平均值作为训练结果的数值。表6为逻辑回归使用4种集成算法与传统整合多方数据集中训练的方法的性能。
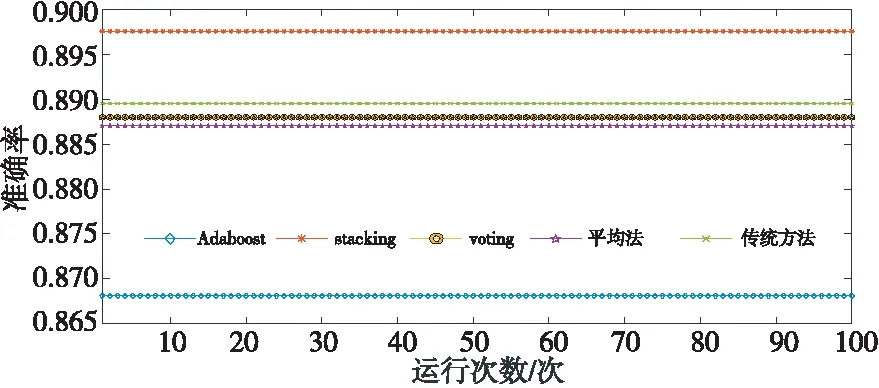
Figure 10 Accuracy changes of logistic regression using four kinds of integrated algorithms and traditional method图10 逻辑回归使用4种集成算法 与传统方法训练的准确率变化
从表6可以得到,准确率均值从高到低依次是stacking 集成算法、传统整合多方数据集中训练的方法、voting集成算法、平均法和Adaboost集成算法,标准差从小到大的顺序依次是平均法、voting集成算法、传统整合多方数据集中训练的方法、Adaboost集成算法和stacking集成算法,其中stacking集成算法的准确率均值为89.76%,传统整合多方数据集中训练的方法准确率均值为88.955%,voting集成算法的准确率均值为88.88%,平均法的准确率均值为88.705%,Adaboost集成算法的准确率均值为86.81%。
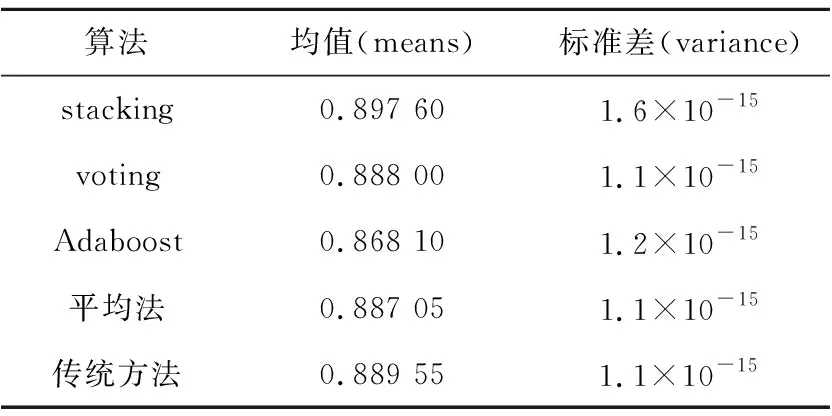
Table 6 Performance of logistic regression using four integrated algorithms and traditional method表6 逻辑回归使用4种集成算法与传统方法的性能
朴素贝叶斯为初始全局模型的准确率低于随机森林、极端随机森林、GBDT、神经网络和逻辑回归,其标准差高于随机森林、极端随机森林、GBDT和神经网络,说明模型的稳定性差,故综合考虑其性能次于随机森林、极端随机森林、GBDT和神经网络。
图11表示初始全局模型选用朴素贝叶斯时使用4种集成算法与传统整合多方数据集中训练的方法在各数据源上训练的准确率变化情况,将迭代100次的平均值作为训练结果的数值。表7为朴素贝叶斯使用4种集成算法与传统整合数据集中方法的性能。

Figure 11 Changes of naive Bayes training using four ensemble algorithms and traditional methods图11 朴素贝叶斯使用4种集成算法 与传统方法训练的准确率变化

Table 7 Naive Bayes performance using fourensemble algorithms and traditional method
对于传统处理多源数据的做法是将各数据源的数据整合在数据中心,并使用不同的初始化模型在数据中心上进行训练,获取多方均满意的模型。图12为随机森林、极端随机森林、神经网络、朴素贝叶斯、GBDT、逻辑回归6种模型使用传统方法训练的情况。

Figure 12 Six models were trained using traditional method图12 6种模型使用传统方法训练的准确率情况
从图12中可以看到,随机森林的准确率最高,剩下的依次是极端随机森林、GBDT、神经网络(多数情况下优于朴素贝叶斯)、逻辑回归和朴素贝叶斯(只有少数情况下优于神经网络)。表8是不同类型的模型在数据中心(多源数据整合后的存储处)的性能。
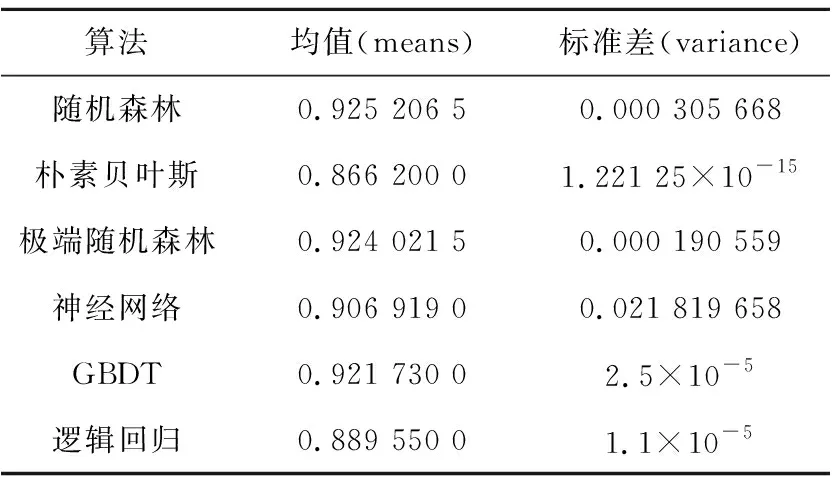
Table 8 Performance of different types of models in the data center表8 不同类型的模型在数据中心的性能
4.3 实验小结
联邦集成学习算法常用的初始全局模型为随机森林、朴素贝叶斯、神经网络、极端随机森林、逻辑回归和GBDT,分别在各数据源的数据上进行训练,得到随机森林的准确度与极端随机森林的准确率最高,但极端随机森林的模型稳定性很差,所以综合考虑选择随机森林作为最优的初始全局模型,可以得到4种集成算法与传统整合多方数据集中训练的方法的结果除voting外,其他的3个均相差不大,但相比之下传统整合多方数据集中训练的方法稳定性较差,但可以使模型与数据的安全性得到很大的提升。所以,将Adaboost集成算法与stacking集成算法作为整合多个本地模型的集成算法。文献[24]将stacking集成算法与Adaboost集成算法、voting集成算法进行比较,结果表明stacking集成算法泛化能力强且适用于大数据样本。所以,对于中小数据样本而言,采用Adaboost集成算法来实现本文提出的联邦集成算法;对于大数据样本而言,采用stacking集成算法来实现本文提出的联邦集成算法。
5 结束语
本文在基于联邦学习和集成学习的思想下提出的联邦集成学习算法,在集成算法的过程中,使数据以及模型的安全性得到明显的提升,同时保持了全局模型的可用性。本文算法与传统的整合多方数据集中训练的方法相比,主要还有3点需要改进:(1)数据融合时的时间复杂度与空间复杂度较高。(2)没有考虑传输协议,即初始全局模型传输至各数据源和各数据源训练的本地模型传输至可信第三方两部分传输协议的安全性问题。(3)初始全局模型以及集成方法选择得不全面,只选择了联邦学习常用的全局模型以及常用的集成方法。实验表明,本文算法在数据安全性以及模型准确性和安全性上都有了很大的提升。未来将继续研究联邦集成学习算法中的模型在传输过程中的安全性问题。
