基于遗传算法的数据中心能效仿真*
2021-09-24毛媛媛石恩雅蒋从锋仇烨亮贾刚勇闫龙川
毛媛媛,石恩雅,蒋从锋,仇烨亮,贾刚勇,万 健,闫龙川
(1.杭州电子科技大学计算机学院,浙江 杭州 310018;2.阿里云计算有限公司,浙江 杭州 311121; 3.浙江科技学院信息与电子工程学院,浙江 杭州 310023;4.国家电网有限公司信息通信分公司,北京 100053)
1 引言
近年来互联网的发展对云计算的需求不断增加,这使得数据中心的规模不断扩大。据数据显示,2019年第4季度,超大型运营商的资本支出远远超过320亿美元,创下季度支出的新纪录。大量的高规模资本支出用于建设、扩展和装备大型数据中心,到第4季度末,数据中心的数量增长到512个[1]。根据美国劳伦斯伯克利国家实验室的能源报告,美国数据中心在2014年耗电量已经达到了700亿千瓦时,占美国总电量的1.8%[2]。在2014年,全球数据中心的能源使用量占当年全球能源使用量的1.62%。2017年这一数字已增加到全球能源的3%以上,根据Andrae的报告,到2025年,数据中心有望在全球范围内以4.5%的比例成为全球最大的能源用户[3]。截至2017年底,我国各类在用数据中心总量已经达到28.5万个,全年耗电量超过1 200亿千瓦时,约占我国全社会用电量2%[4]。随着5G时代的来临,建立高能效的数据中心的需求越来越迫切。
对于建立高能效数据中心,首先需要对数据中心以往的数据进行研究分析,了解数据中心服务器各项指标的特点,以及这些指标对服务器能效产生的影响。根据分析得到的结果,企业和研究人员才能够有针对性地解决数据中心的能耗问题,优化服务器,从而减轻数据中心由能耗问题导致的对环境的危害等不利影响。
SPEC(Standard Performance Evalution Corporation)官方提供了大量可用于分析往年服务器效果的数据,SPECpower_ssj2008是工业标准组织开发的用于评估服务器能效性的基准测试工具。本文着重针对SPECpower结果中的部分指标进行分析。服务器性能主要评价指标如下所示:
(1) 服务器整体性能(Score)表示服务器在0%~100%每个利用率节点下服务器工作的任务总量与消耗总电量的比值。
(2) 能效性EE(Energy Efficiency)表示服务器的性能与功率的比值,能效性越高,即单位瓦特电量能完成的任务更多。
(3) 能量等比性EP(Energy Proportionality)[5 - 8]表示服务器功耗随利用率的变化情况。
(4) 峰值能效性(PeakEE)表示在10%~100%的10个利用率下对应服务器能效性的最大值,该峰值能效性对应的利用率为峰值利用率。
我们以这些结果评价指标为参考,可以进一步探究服务器硬件指标对服务器性能的影响。大型数据中心中运行了大量的服务和应用,在生产系统中进行能效优化调整具有较大风险,对数据中心能效进行模拟仿真可以了解数据中心能效随负载的变化情况。因此,针对数据中心低能耗问题,本文提出了基于遗传算法的优化方式,并基于该算法对数据中心进行能效仿真。
2 相关工作
本文首先对SPEC官方公布的截至2019年第4季度的共658条有效记录[9]进行汇总,制作了杏仁图、铅笔头图等多种能反映服务器情况的图像,可视化服务器发展趋势。分别从CPU架构和年份2个方面分析服务器近十几年的性能发展趋势,并对未来发展趋势做出了简单预测。本文不仅分析了SPEC的SPECpower测试结果数据,还对服务器的单位核内存(Memory per Core)、内存速度(Memory Speed)、Cache容量(Cache Size)等多种硬件参数进行了分析;通过Matlab拟合实验[10],分析了影响服务器能效的因素。在实验过程中,进行了大量拟合以及误差结果对比,最终得到了对服务器性能影响较大的3个硬件因素。
目前,分布式并行计算系统的能耗优化管理技术包括3类:关闭/休眠技术、动态电压调节技术和虚拟化技术[11]。
动态电压调节技术主要是在任务运行过程中,调整其运行的电压和频率,延长任务执行时间来降低执行能耗;而动态电源管理技术主要是通过在足够长的空闲时间内休眠不用的器件来减少能量消耗[12]。
虚拟化迁移技术通过将软件应用与底层硬件相隔离,可以将若干低负载的服务器迁移、整合到较少的服务器上,有效降低服务器能耗,但这种方法将会涉及到底层硬件。
关闭/休眠技术是通过关闭空闲计算机节点来降低能源消耗从而实现数据中心的节能,但由于计算机从关闭到启动时需要较长时间,若不能精准预测负载,则会导致频繁开关机。此外,如何根据单位时间到达的任务量决定需要关闭的计算机数量以及关闭哪些计算机,给关闭/休眠技术带来了新的研究难题[11,13]。
实际上,服务器在运行状态下会产生较大的能耗,但大多数服务器平均利用率只有大约10%~50%。服务器在休眠状态时[14],一般仅消耗5 W[11]的能耗。因此,本文利用虚拟迁移技术将服务器的任务集中迁移到部分服务器上,并将未运行的服务器设置为休眠状态,以达到减少功耗的目标。负载过大时,可以将休眠的服务器唤醒。此前已经有不少关于数据中心能耗优化的成果。阮顺领等[15]研究了面向数据中心能效优化的虚拟机迁移调度方法,这种方法可以对服务器进行动态迁移和整合,从而减少服务器的运行数量,以此来降低能耗。刘斌等[16]提出了一种基于在线预测服务器规模调节策略,利用LMS(Least Mean Square)算法预测未来的负载请求,动态调整集群规模,他们提出的快速调整算法使同构服务器系统的能耗维持在较低水平。王肇国等[17]提出的基于机器学习特性的数据中心能耗优化方法,针对同构数据中心进行数据中心能耗优化。多数研究中未考虑到数据中心大多都是异构这一问题,并且对于单个服务器忽视了其能量等比性的特点。
本文基于遗传算法设计了数据中心能效仿真器,求出数据中心在不同负载下开启服务器的合理方案,在保证数据中心能够提供用户请求服务器的情况下,尽量减少数据中心的功耗。遗传算法在解决组合优化问题时,能达到较好的效果,并能够加快计算速度。在合理的误差下,遗传算法比一般的优化算法,如背包算法、贪心算法等,可以更高效地得到最优解,尤其是在解决较大规模问题时[18]。本文对求解数据中心能效优化问题的具体过程进行了详细的说明,希望能为解决该类问题提供少许经验。本文设置背包算法作为对比算法,实验表明,遗传算法在解决该类问题时可以得到更好的结果。
此外,考虑到服务器的能耗包括运行能耗和切换能耗[11],对服务器进行开启或者关闭操作时,需要将其任务进行迁移、整合,这需要一定的计算时间,并且也会产生一定的功耗浪费。本文对遗传算法中的适应度函数进行改进,在数据中心运行时,若负载发生变化,仿真器将会给出切换服务器数量较少的合理方案,改进后,数据中心需要切换的服务器数量减少,并且在一定误差内,仍然能达到最小功耗的目标。最后,利用SPEC中的部分数据,模拟了不同规模和不同服务器类型的数据中心能效随负载的变化。
3 基于SPECpower数据集的数据中心能效演变
3.1 SPECpower数据统计分析
本文对截至2019年SPECpower的有效数据进行统计和分析,分别从服务器CPU架构角度和年份变化角度分析服务器性能的发展趋势。
3.1.1 服务器在CPU架构视角下的发展趋势
根据CPU架构对统计结果进行分类的情况如图 1所示。
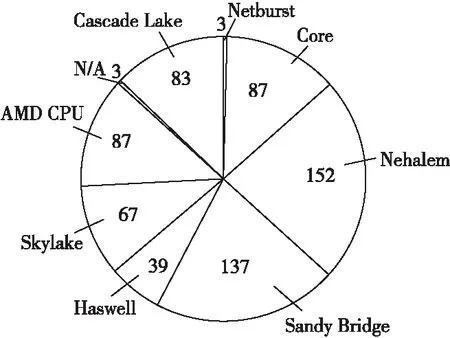
Figure 1 CPU architecture classification for Intel CPU图1 Intel CPU架构分类
根据不同CPU类型分别统计它们的EP、Score的平均值和中位值,如图 2和图 3所示。Skylake和Cascade Lake是近年来Intel最新的2种CPU架构,这2类服务器在图2和图3的EP值和Score值中都占据很高的位置,EP值达到0.90以上,Score值达到11 000以上。以上分析可以说明服务器性能的提升。在2019年发布的结果中,AMD类型的Zen2系列服务器平均可以达到约2万左右的Score值,但其EP值不高。由于该型号服务器的CPU一般会配置较大的Cache和较多节点,所以得到了较高的Score分数,但Zen2系列服务器的功耗也更大,其能效并不高。

Figure 2 Average EP and median EP of each CPU architecture图2 各类CPU构架的EP平均值和EP中位数

Figure 3 Average score and median score of each CPU architecture图3 各个CPU构架的Score平均值和Score中位值
3.1.2 服务器随年份变化的发展趋势
(1)能量等比性和服务器总体能效性变化趋势。
图 4为2007年~2019年所有服务器EP值和Score值的统计曲线。在2007年~2019年时间段中,EP值总体呈上升趋势,2019年服务器EP值基本可以达到1,EP值有显著的提升。Score值在2007年~2018年间也呈上升趋势。2019年初的季度中Score值上升最高至2万多,在之后的季度中Score值又有所跌落,但仍处于较高区域,体现了服务器能效的提高。

Figure 4 Data trends of server Score and EP values from 2007 to 2019图4 2007年~2019年服务器 Score和EP值变化趋势图
(2)峰值能效性的利用率变化趋势。
图5所示为峰值能效性出现时的利用率随年份的变化。2010年之前,服务器在利用率为100%时才达到峰值能效性。2010年峰值能效的利用率开始发生变化,峰值能效性出现时的利用率逐渐向低值移动。2010年~2019年,在利用率为100%达到峰值能效性的服务器占比呈下降趋势,2015年占比最小,其比值不到10%。同时,虽然在2014年~2016年利用率在70%,80%达到峰值利用率的服务器占比有剧烈波动,但截至2019年,该占比总体呈上升趋势。经过以上分析可以推测,峰值能效性的利用率可能会继续降低,我们可以将特定服务器运行在其峰值能效性的利用率下,以获得合理的工作负载布局和高效的能源利用率。
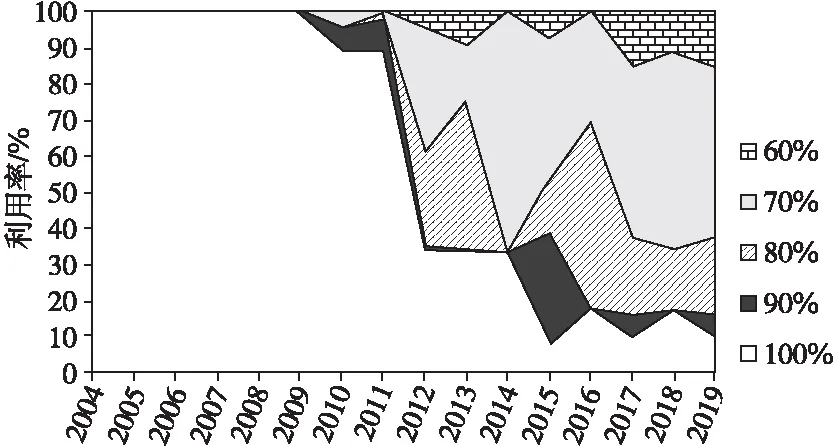
Figure 5 Server utilization spot of peak energy efficiency in each year图5 各年份峰值能效性的利用率
3.1.3 能量等比性和能效性变化
图6和图7所示为2007年~2019年所有服务器在不同利用率下的能量等比性和能效性统计曲线。本文用虚曲线表示2007年~2015年的数值情况,用实曲线表示2016年~2019年的数值情况。EP曲线反映了服务器的功耗特性。理想的EP曲线为斜率为1的曲线,表示在某一利用率下,服务器的能量等比性也为该利用率所对应的值,EP随利用率同等程度变化。服务器EP值[6]越高,会越早与理想EP曲线相交。图6中实曲线与理想EP曲线相交时的利用率大多小于虚曲线与理想EP曲线相交时的利用率。并且随着年份的增加,实曲线与理想EP曲线交汇速度呈加快趋势。铅笔头图的上包络线表示EP值最低的服务器,该服务器EP值为0.18,出现于2008年;铅笔头图的下包络线表示EP值最高的服务器,该服务器EP值为1.09,出现于2019年。以上分析均可以反映能量等比性的提高。

Figure 6 Pencilhead chart of server energy proportionality evolution图6 服务器能量等比性演化铅笔头图
高能效性区域是服务器能够持续工作的更好区域,EP值越高的服务器,高能效性区域越宽。对于EP值接近于1.0或大于1.0的服务器,EP值越高,峰值能效性距离理想能效性曲线越远。如图 7所示,随着年份的增加,服务器高能效性区域宽度以及峰值能效性与理想能效性曲线的距离呈增大趋势。杏仁图的上包络线是所有服务器中最高EP值的曲线,在利用率30%~100%区间均获得高能效性,该服务器出现于2019年。以上分析说明服务器能效性有所提高。服务器能量等比性和能效性的提高都反映了服务器性能的发展与进步。

Figure 7 Almond chart of server energy-efficiency evolution图7 服务器能效性演化杏仁图
3.2 影响服务器性能因素分析
3.2.1 分析方法
本文分析影响服务器性能的因素,是通过利用Matlab的拟合工具stepwise和regress[10]对SPECpower的某些参数进行拟合实现的。由于服务器性能受服务器硬件影响,因此对SPECpower中统计的硬件参数进行拟合。在拟合中,将Score和PeakEE作为被拟合指标。本文对全部数据集的多种子集进行实验,以此控制某些变量,其中包括对年份、CPU代号、峰值所在利用率等数据量较大的数据集进行不同方面的分析。以R-square、均方根误差RMSE、相对RMSE和平均相对误差等值对拟合结果进行评价。最终得到较好拟合结果的参数可视为影响服务器性能的重要因素。
3.2.2 拟合参数选择
本文对服务器几个主要参数进行拟合(各项参数的含义如表 1所示),利用评价指标RMSE和R-square进行分析。RMSE为均方根误差,用来衡量观测值同真值之间的偏差;R-square为确定系数,该系数通过数据的变化来表征一个拟合的好坏,其正常取值为0~1,越接近1,表明数据拟合程度越好。
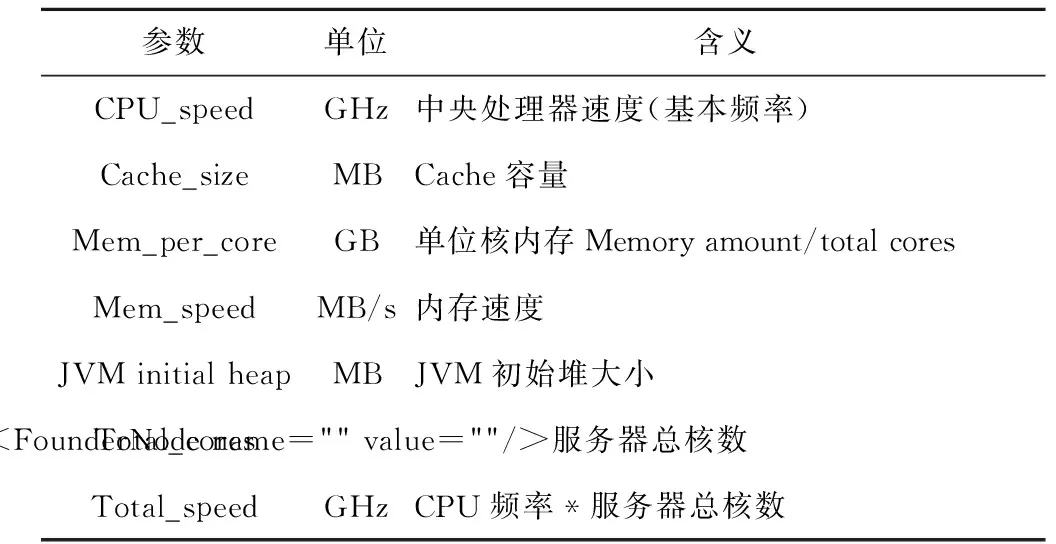
Table 1 Hardware parameters表1 硬件参数表
由于CPU性能会随年份增加而提升,本文除了对所有数据进行拟合外,还对年份跨度稍微小一些的2016年~2019年的数据、不同峰值点位置的数据、不同CPU代号的数据分别进行拟合。同类服务器的数据集在某些方面具有相似性,可以提高拟合的结果,如具有相同CPU代号的服务器的Score可能具有类似的函数关系。SPECpower 数据集信息如表 2所示。
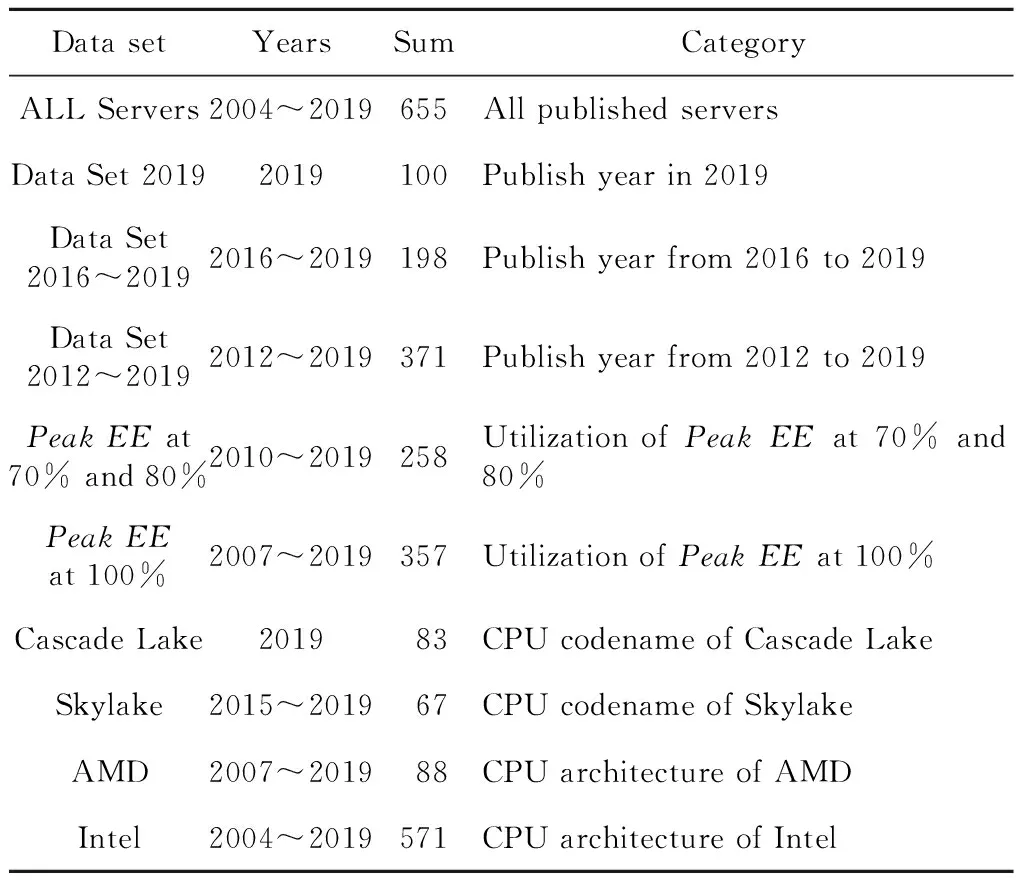
Table 2 SPECpower data sets information表2 SPECpower 数据集信息
首先,本文对表1中涉及的相关参数进行拟合实验,分析了不同参数的拟合结果和拟合函数中各个参数的权值,最终选出了CPU_speed、Total_cores、Cache_size、Mem_per_core、JVM_initial_heap和Mem_speed 6个参数作为影响Score和PeakEE值的主要参数。由于论文篇幅限制,本文仅列出这6个参数在不同数据集上的拟合结果,如表3~表 5所示。拟合结果中原本将RMSE值作为拟合准确度的一个判断标准,但由于该值是一个绝对值,不同数据集上的拟合结果无法比较,所以,本文将RMSE值除以被拟合值的平均值作为判断的标准,将绝对RMSE值统一成相对RMSE(RMSE/Average)。

Table 3 Fitting results on data sets classified by year表3 按年份分类的数据集拟合结果
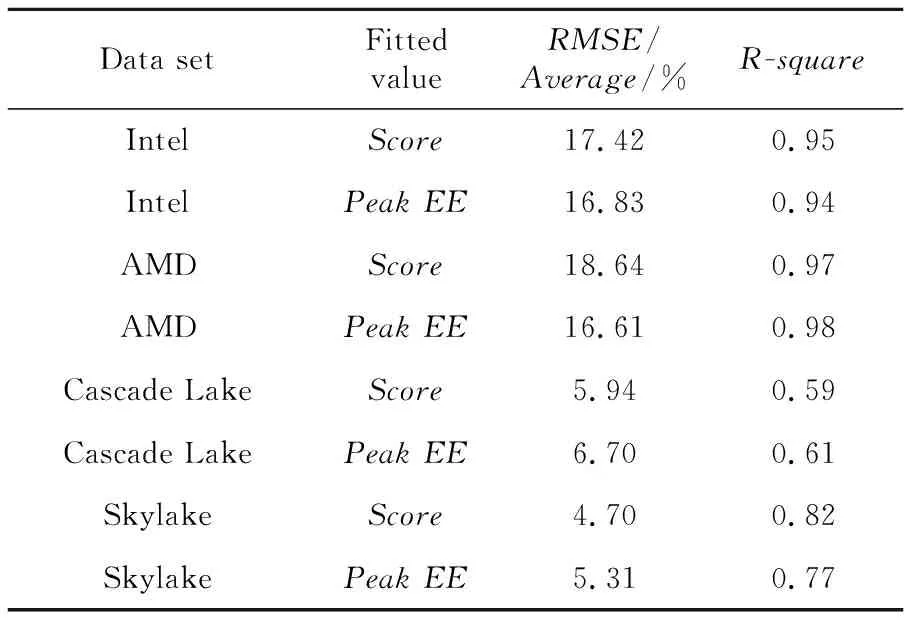
Table 4 Fitting results on data sets classified by different architectures表4 按不同架构分类数据集拟合结果
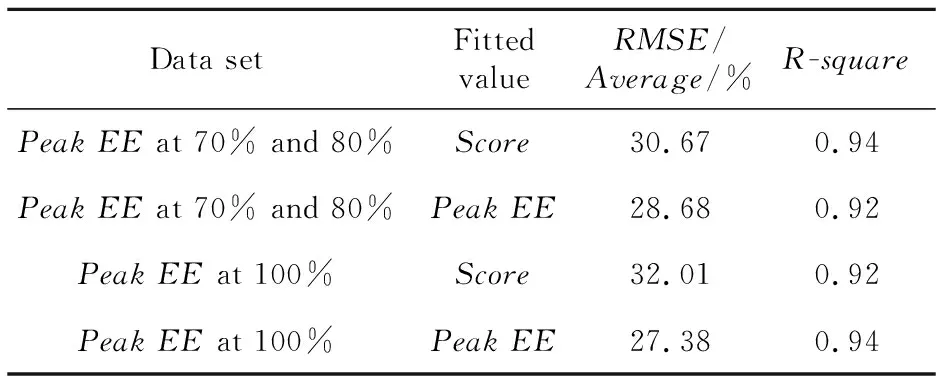
Table 5 Fitting results on data sets classified by utilization rate of peak EE表5 按Peak EE所在利用率分类数据集拟合结果
3.2.3 重要参数拟合提取
虽然以上实验得到了较好的拟合结果,但实验时观察到,不同参数对整个拟合结果的影响是不同的,而且拟合中涉及到的变量过多,因此猜测在主要的参数中存在某些参数对拟合结果会产生更大的影响。本文希望能从此前得到的6个主要参数中提取出重要的参数进行拟合实验,以此来减少拟合过程中涉及到的变量,同时也希望这些重要参数对Score和PeakEE的拟合仍然能达到较高的准确度。因此,本次实验提取3个主要参数为目标,使用这3个主要参数对数据进行拟合,得到较好的拟合结果。
本文的主要实验思想为,对于某个参数,在6个参数拟合的基础上,删除该参数,将其余5个参数拟合的结果与6个参数拟合结果相对比,若两者结果相差较大,则说明该变量对数据的影响大,反之,可以考虑将其剔除。
首先,在实验中发现,CPU_speed和Total_cores这2个参数对拟合结果的影响不大。因此,先将这2个参数从6个参数中剔除。在未来的数据拟合中剔除这2个参数。
在剔除CPU_speed和Total_cores后,保留了Cache_size、Mem_per_core、JVM和Mem_speed 4个参数单独进行研究,将这4个参数的拟合结果和去除某个参数的结果进行对比,可以得出某一参数对拟合结果的影响。实验结果如下所示:
(1)总体来看,Cache_size参数对拟合结果的影响较大。如图 8所示,该参数对年份跨度较大的数据集的拟合结果影响较小,但该参数对于年份较新的数据集的拟合结果影响很大,PeakEE的R-square在2016年~2019年数据集上的结果提高了40%。
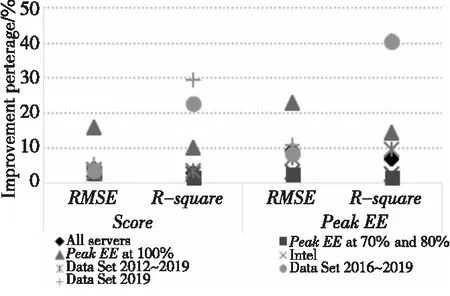
Figure 8 Comparison between the fitting results w/wo Cache_size图8 未加入Cache_size参数与加入后拟合结果对比
(2)图9列出了未加入Mem_speed参数与加入后拟合结果对比。在对数据集年份跨度大的拟合结果中,该参数对拟合结果影响大,但是在年份较新的数据集上,该参数对拟合结果的影响逐渐减小。
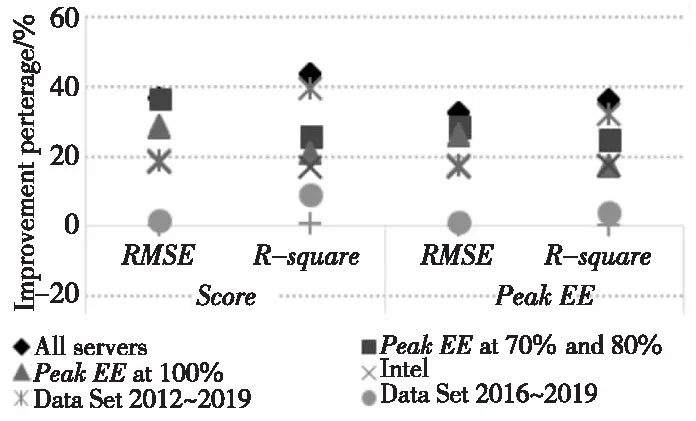
Figure 9 Comparison between the fitting results w/wo Mem_speed图9 未加入Mem_speed参数与加入后拟合结果对比
(3)Mem_per_core参数对拟合结果的影响不大。如图 10所示,对图例中的数据集进行拟合,加入Mem_per_core参数后的结果提升基本在3%以内。

Figure 10 Comparison between the fitting results w/wo Mem_per_core图10 未加入Mem_per_core参数与加入后拟合结果对比
(4)JVM_initial_heap参数总体上对拟合结果的影响不大。如表6所示,该参数对拟合结果的提升在5%以内。

Table 6 Comparison between the fitting results w/wo JVM_initial_heap 表6 未加入JVM_initial_heap参数与加入后拟合结果对比
经过对以上6个参数的分析,我们可以得出初步结果,在拟合参数中剔除CPU_speed和Total_speed参数,保留Cache_size和Mem_speed参数。
对于Mem_per_core和JVM_initial_heap,本文发现这2个变量对实验结果的影响相差不大,因此将进一步进行实验。通过前面的实验已经确定保留Cache_size和Mem_speed,在此基础上再分别添加Mem_per_core和JVM_initial_heap,将2次拟合结果进行对比,以考察这2个参数对拟合结果的重要性。综合来看,加入Mem_per_core的拟合结果较好。
3.2.4 结果分析
如表7所示,将Cache_size、Mem_per_core和Mem_speed 3个参数进行拟合,准确度较高。只有2012年~2019年数据集上的拟合结果稍差,其他数据集的拟合结果与源数据平均相对误差以及相对RMSE的误差都能在10%以内。
至此,找出了服务器硬件数据与服务器性能的关系,并且使用服务器中的Cache_size、Mem_per_core和Mem_speed 3个参数对服务器的Score和PeakEE值进行线性拟合,达到了较好的效果。
以上的拟合实验说明,Cache_size、Mem_per_core和Mem_speed 3个参数是影响服务器性能的重要因素,利用这3个参数可以较好地拟合Score和PeakEE。
4 数据中心能效仿真
4.1 仿真策略
本文利用遗传算法研究数据中心在提供一定负载保证服务质量前提下,调整数据中心服务器开启的合理方案,使数据中心的能耗最小化。由于数据中心在不断扩大规模的过程中,新增的服务器的硬件生产年份不同,或者会由不同厂商提供,因此数据中心的服务器可能具有不同的硬件配置,不同的硬件配置可能导致数据中心节点在性能和耗电功率等方面不同。因此,在数据中心能耗优化相关研究中,若仅考虑同构服务器的数据中心是不够的[13]。本文在利用SPEC平台上服务器运行时的真实数据进行数据中心能效仿真时,设计了不同规模和不同类型的异构数据中心。对于未工作的服务器,其运营商可以将其设置为休眠状态或者关闭状态。一般来说,服务器开启与关闭时会产生较大的能耗,并且开启时还会消耗一定的时间。在休眠状态的服务器能及时开启且能耗较小,本文在能效计算时,假定服务器未开启时时,自动进入休眠状态,并忽略其在休眠状态下的能耗。此外,由于SPEC为本文提供的服务器运行数据中,将服务器利用率设置在10%~100%的10个档位,因此本文实验中假设,服务器开启时,其利用率有10%~100%共10个挡位。因此,数据中心能效优化问题可以描述为:

Table 7 Fitting results for score and Peak EE with Cache_size,Mem_per_core,and Mem_speed 表7 Cache_size,Mem_per_core,Mem_speed对Score、Peak EE进行线性拟合的结果
假设某异构数据中心一共有N台服务器,将数据中心工作节点的利用率平均划分为10%~100%共10个挡位,sjj_op是在SPEC官方测试平台上,对每台服务器进行能效测试的标准测试任务,ssj_opij表示第i台服务器运行在利用率为j*10%时的负载任务数量,pij表示第i台服务器在利用率j*10%下的功耗。数据中心若有J个请求的负载,需要调整数据中心每台服务器的运行状态,使其能满足负载请求并使整个数据中心能耗降到最小。该问题求解可以表示如式(1)所示:
ni=0或ni=1,j=1,2,…,10,
(1)
其中ni表示该服务器是否开启。
该问题实际上是一个组合优化问题,可以使用背包算法进行求解。虽然背包算法能够得到较高的准确率,但计算时间过长,若给出的服务器调整方案时间过长,将影响服务器调整运行的响应时间,降低数据中心的服务质量。因此,本文选择遗传算法对问题进行求解,并对2个算法进行了比较。本文将背包算法和遗传算法在同样负载下求出的最小功耗的误差作为遗传算法的评价标准。
4.2 遗传算法描述
遗传算法是由美国的Holland教授[20]于1975年提出的,是一种基于自然选择原理和自然遗传机制的搜索算法,模拟自然界中的生命进化机制,在人工系统中实现特定目标的优化[21]。
按照遗传算法的步骤,下面给出本文问题求解的具体过程:
(1)染色体编码。对于本文的问题,最终输出的是服务器开启方案。对于每台服务器,其状态有关闭或者是以不同利用率运行。因此,本文对服务器运行的10个不同利用率和未运行共11种状态进行编码,该11种状态作为染色体的基因特征,一条染色体就是一种服务器开启方案,染色体中的长度即为数据中心服务器的数量。
(2)确定初始种群。在所有服务器中,随机选择若干台服务器,并将其运行到峰值能效的利用率下,使所有开启服务器运行负载达到请求负载,其余服务器为关闭状态,则该组服务器的状态编码为一个可行性解,初始时选择若干组这样的可行性解作为初始种群。
(3)确定适应度函数。适应度函数是评价个体性能的主要指标。显然,对于每个个体,其适应度应该遵循功耗越小适应度越大。那么,如果在进化中产生了负载不能达到任务请求的解,在自然选择时,应该被淘汰,所以,可以将这样的解的适应度设置为最小。假设数据中心有n台服务器开启,其最小负载为totalJobs。在该解下,第i台服务器运行的负载为jobi,功耗为pi,可以确定适应度函数如式(2)所示:
(2)
(4)确定选择算子。在每一次迭代时,使用较好的选择算子能保留适应度较好的个体,淘汰适应度不佳个体,本文采用精英策略选择法与锦标赛选择法相结合的方法。新的种群中,有一部分是由适应度较好的父代直接复制而来的,其他是由父代交叉得到的,父代选择的方法使用锦标赛选择法。参数pr(Crossover Probability)为交叉概率,表示在新种群中,有pr比例的子代是由父代交叉得到的,其他(1-pr)的子代是由父代直接复制得来的,并且该部分子代不会进行变异。
(5)确定交叉算子与变异算子。交叉算子选用顺序交叉法。顺序交叉法中,父代染色体的相对访问顺序不会改变,本文选用了2点交叉的方式。变异就是以很小的变异概率pm(Mutation Probabi- lity)随机地改变种群中个体的某些基因值,它能够保持群体的多样性,以防出现早熟收敛。
5 实验结果及分析
5.1 不同参数设置下的实验结果
实验利用阿里数据中心的真实负载,按数据中心的规模对其真实负载进行等比例调整,模拟了数据中心在一定负载下的最小能耗问题。本文选择了SPECpower数据集中硬件生产年份为2018年的52类服务器,每类服务器10台,共520台,在26组不同负载下求解最小能耗问题,并将遗传算法求解结果与背包算法求解结果进行对比。
首先,对交叉概率和变异概率进行调参,得到的结果如图11所示,可以明显发现,当pm设置为0.01,pr设置为0.98时,实验得到的误差最小。

Figure 11 Error of power with different pm and pr图11 不同交叉概率pm、变异概率pr下的实验误差
对于种群规模pop_size与迭代次数Generations,通过增大这2个参数,可以提高遗传算法求解的准确度。从图12可以观察到,在迭代次数和种群规模不断扩大时准确度不断提高,但同时也会增加计算时间。
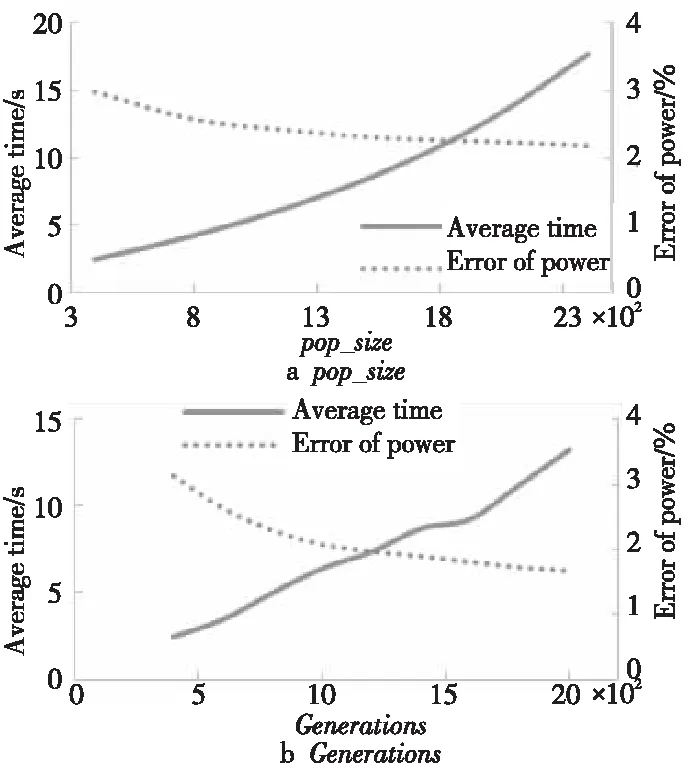
Figure 12 Error of power and average time with different pos_size and Generations图12 不同种群规模、迭代次数下实验误差及计算时间开销
所以,如何设置迭代次数和种群规模,需要根据实际情况来确定,若负载对时间敏感度较高,则可以将种群规模、迭代次数设置得较小,以一定误差为代价,更快得到结果;若负载对时间不敏感,则可以增加迭代次数,以得到较小误差的结果。
此外,由表8可知,表8中No. 2比No. 1增加了迭代次数,No. 3比No. 1扩大了种群规模,通过结果发现迭代次数和种群规模的设置对实验结果有不同程度的影响。实验结果对比可知,No. 2与No. 3的误差都在2.1%左右,但No. 3需要更长的计算时间,由此可以得知,在设置参数时,可以通过增加迭代次数来提高算法的准确度。但若一昧地扩大种群规模,计算结果的准确度提高得不明显,并且会耗费更长的计算时间。
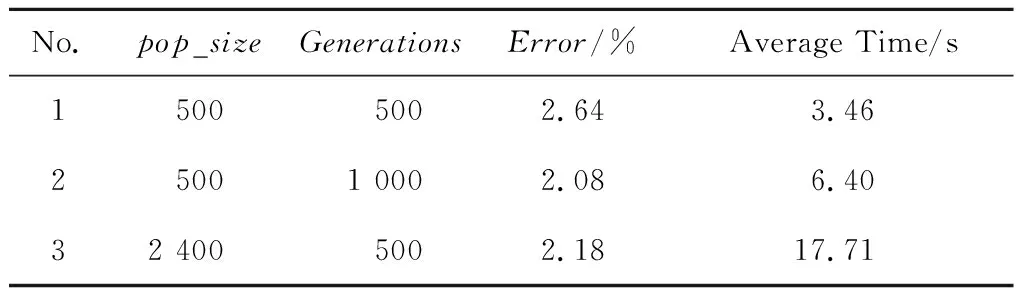
Table 8 Partial results of simulation表8 部分实验结果
此外,考虑服务器切换时需要消耗的功耗。假设有数据中心需要从方案1切换到方案2,其中服务器进行状态调整的数量为r台,本文未考虑调整利用率时需要的其他功耗,则需要切换的数量r越少,调整时所需要耗费的能量越小,因此可以将适应度函数更改为式(3)所示:
f(x1,x2,…,xn)=
(3)
其中,由于r值的相对大小与数据中心的总服务器数量N有关,因此本文将总服务器数量也引入适应度函数中。
对改进后的算法重新进行实验,得到的实验结果图 13所示。从图13可以发现,在相同负载下,改进后的适应度函数的结果中,能耗相差不大,但改进后的适应度函数使服务器切换的数量大大减小。
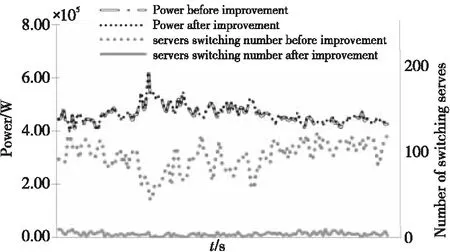
Figure 13 Improvements comparison of genetic algorithms图13 遗传算法改进结果对比
5.2 仿真结果
本文利用SPEC平台上的数据,设计了2个规模较小的数据中心。数据中心DC#1、DC#2是分别由硬件生产年份为2018年的服务器、硬件生产年份为2019的服务器构成的。此外,选用了2008年~2019年SPEC平台上分布的所有有效服务器共521类,设置共3 315台服务器的较大规模数据中心进行仿真。数据中心基本信息与仿真参数如表9所示。
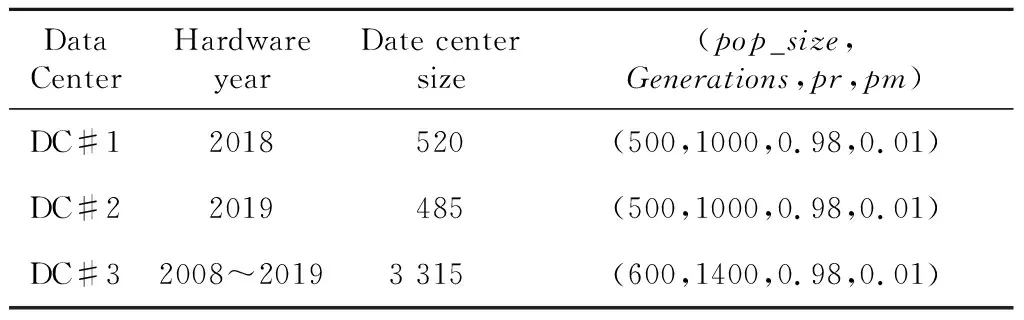
Table 9 Basic configuration of three data centers 表9 数据中心基本信息
图14为数据中心的能效仿真图,图中的负载曲线描绘了在各个时刻负载的动态变化,图中的能耗曲线描绘了数据中心在满足各个时刻的负载时产生的能源消耗变化。由图14可以观察到,DC#1与DC#2在同样的负载下,DC#2使用的功耗明显小于DC#1的。从2个年份的数据中心的能效仿真结果来看,近年来,服务器的能效有了较大的提高。

Figure 14 Simulation results of DC#1 and DC#2图14 DC#1与DC#2仿真结果
对于较大规模的数据中心的仿真结果如图 15所示。根据图 14和图 15的负载动态变化和数据中心的能耗使用情况,本文绘制了3个数据中心的EE对比图,如图 16所示。由3个数据中心的能效仿真可知,DC#3的仿真结果不如DC#1和DC#2的,说明本文使用的仿真方法更加适合规模较小的数据中心,并且由表 10可知,在DC#3的仿真中,运行时间相较于另外2个数据中心明显更长。由于较大规模的数据中心需要设置更大的种群规模和更多的迭代次数,这使遗传算法的收敛时间大大增加。本文中,DC#3的仿真结果比其他2个数据中心的仿真结果稍差,可能是由于种群规模和迭代次数仍然不够,也可能是因为实验中相关参数并不适合规模较大的数据中心仿真。

Figure 15 Simulation result of DC#3图15 DC#3仿真结果
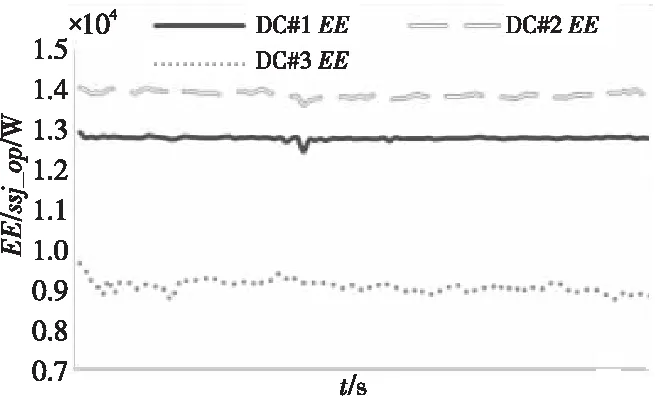
Figure 16 Energy efficiency simulation comparison of three data centers图16 数据中心能效仿真对比图

Table 10 Simulation results of three data centers
5.3 仿真精度敏感性分析
在本文的仿真实验中,对数据中心能效仿真使用的负载变化幅度较小,能够模拟数据中心日常工作的负载变化。若用户需求在短时间内急剧波动,该仿真器的效果可能会受到影响,以致于增加数据中心的响应时间。而且在实际运用中,仿真器会受到时间限制,往往需要在一定时间内给出最优的服务器开启/关闭调整方案,如果时间限制比较严格,仿真可能达不到最优的方案。此外,经过对不同规模的数据中心仿真结果分析可知,遗传算法在解决不同规模的问题时,会有不同的最佳参数组合。因此,仿真精度会受到数据中心规模的影响,对于不同规模的数据中心,遗传算法的相关参数还要进一步调整。
6 结束语
本文对SPEC官网的服务器数据进行了分析,分别从CPU架构、能效性和能量等比性随时间变化角度分析,通过制作多种能够反映服务器性能图像,可视化服务器发展趋势,最终得到总体上服务器性能呈提高的结论。SPEC官网公布了服务器的多项硬件参数,本文借助Matlab对这些参数有选择性地进行拟合实验,分析影响服务器性能的因素。在实验过程中进行了大量拟合以及误差结果对比,最终得到对服务器性能影响较大的3个硬件因素。
在分析了影响服务器性能因素后,本文利用遗传算法对数据中心在动态负载下最小能耗问题进行了求解,相对于背包算法误差在2%左右,且考虑了数据中心在调整时切换服务器时功耗浪费的问题。但是,没有对服务器切换时的能耗进行分析。此外,利用真实的负载数据模拟了不同规模以及不同年份服务器构建的数据中心能效,并对其进行了分析,从模拟结果可以明显观察到,硬件生产年份从2018年到2019年,数据中心能耗有了较大的减少,说明近年来随着服务器硬件性能的提高,能效也有所提升。此外,利用仿真器对规模较大的数据中心进行能耗仿真时,其能效未能达到预期,这与数据中心的服务器性能有关,部分原因也可能是因为仿真器在一定计算时间内,对规模较大的问题还未能达到收敛,还需要进一步优化。
