用户QoS感知的GPU集群深度学习任务动态调度*
2021-09-24陈照云王俪璇
罗 磊,陈照云,王俪璇
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
当前,深度学习技术受到产业界和学术界广泛关注。虽然以高速定制机器学习芯片TPU(Tensor Processing Units)为代表的深度学习专用硬件设备层出不穷,但通用图形处理器GPU集群仍是开展深度学习研发的主流平台。如图1所示,高校、科研院所和中小规模企业UIE(Universities,Institutes and small-and-medium-sized Enterprises)常构建公共GPU集群向组织内部的学生、研究人员提供服务。多个用户会同时向GPU集群平台提交不同类型的深度学习任务,每个任务具有自身的计算需求和相应的预期服务质量QoS(Quality of Service)。
相比于互联网巨头定制化的深度学习平台,或面向公众提供服务的云计算中心,UIE由于预算有限,更倾向于购买或租赁高性价比的通用现货GPU集群,并采用开源集群管理系统来构建多用户共享的深度学习研发平台。然而现有GPU集群任务调度主要关注高性能计算中心的需求,多基于历史信息或启发式进行调度[1],对UIE深度学习研发场景适应性不强。以康奈尔大学的Gra- phite集群为例[2],该系统采用传统的Slurm(Simple Linux Utility for Resource Management)资源划分,任务调度策略依靠用户自主提出的需求,根据系统空闲状态随机分配。这种策略既不能利用深度学习计算特性挖掘有限计算资源的能力,也无法对用户的服务质量作出保证。同样的情况在麻省理工学院(MIT)的MSEAS(Multidisciplinary Simulation, Estimation, and Assimilation Systems)集群和加利福尼亚大学伯克利分校(UC Berkeley)的Tiger集群上也有发生[3,4]。此外,由于深度学习研究的持续高热度,UIE中需要使用GPU集群的用户数量众多,而GPU集群的规模又十分有限(GPU数量往往在几十到一、两百个之间[2 - 4]),导致任务冲突更为频繁,而组织内部用户平等的关系使得云计算中心基于价格的调度策略不再奏效。

Figure 1 GPU cluster shared with multiple users for deep learning research and development purpose图1 面向深度学习研发任务的多用户共享GPU平台
面向UIE深度学习研发场景,如何提高GPU集群任务吞吐率,是一个重要的研究课题。Chen等人[5,6]对深度学习任务计算特性进行了评测与分析,对小规模GPU集群平台上的深度学习任务的调度开展了探索。Gu等人[7]针对大规模分布式深度学习任务,提出Tiresias调度器,相比Apache YARN任务完成时间提升了5.5倍。本文面向UIE深度学习研发场景,充分考虑深度学习任务的计算通信特性,提出一种用户QoS感知的动态任务调度方法,能够在满足多用户QoS需求的同时,提高GPU集群资源利用率。
2 GPU集群深度学习任务调度模型
2.1 深度神经网络结构与计算特性
从早期的LeNet网络[8],到现代的AlexNet[9]、VGGNet[10]、GoogleNet[11]和ResNet[12]等,以神经网络为代表的深度学习技术在各类应用中取得了突破性进展。为平衡计算效率和收敛速度,深度神经网络的训练和推理一般采用批处理方式,批次大小(batchsize)会显著影响到训练性能和资源占用。当batchsize较大时,由于GPU内存的限制,常需要在GPU集群采用模型并行[13]或数据并行[14]进行训练。
在深度学习研发过程中,为了获得最优的性能,研发者往往需要花费大量时间对深度神经网络模型的超参数进行调优。在调整这些超参数的过程中,需要使用相同或相似的深度神经网络结构,重复对同一批数据训练多次。另一方面,大量的深度学习开发任务以微调(fine-tuning)的方式展开,即以ImageNet等大规模数据集上训练得到的预训练模型为基础,在目标数据集上对模型的参数进行fine-tuning。这种模式下,开发任务使用的深度神经网络结构与预训练网络基本相同,一般只修改输出层或少数特征层。深度学习研发中广泛存在的超参数调整和模型fine-tuning,使得用户提交到GPU集群的作业中存在大量网络结构相同或相似的任务,其计算特性也相似。对于这些相同或相似的任务,可以通过历史信息预测其计算和通信性能,为集群作业调度提供依据。
2.2 GPU集群深度学习研发任务调度建模
面向图1所示分布式GPU集群下的深度学习研发场景,本文采用式(1)所示的三元组描述GPU集群平台:
P=〈N,G,Comm(·)〉
(1)
其中,N,G和Comm(·)分别表示该GPU集群结点数上限、每个结点内的GPU数上限和与GPU集群内部互连结构相关的通信罚值函数。由于GPU集群内结点间(结点间的互连网络)、结点内(CPU Socket之间、不同的PCIeSwitch之间,PCIeSwitch下的GPU之间等)都具有层次化的互连结构,而这个互连结构也会对分布式任务的通信性能造成一定程度的影响,这些影响都通过Comm(·)来描述。
根据文献[5,6]对GPU集群下深度学习任务的深入评测与分析,深度神经网络的计算特性主要与任务的类型、批次大小和迭代次数有关,因此深度学习任务可以抽象为如式(2)所示的三元组:
t=〈wtype,wbat,witer〉
(2)
其中,wtype,wbat和witer分别表示深度学习任务类型、批次大小和迭代次数。任务类型包括2个方面:(1)深度网络模型的类型,例如Inception-v3或Seq2Seq;(2)计算类型,即属于训练任务还是推理/验证任务。
深度学习任务的属性由用户提交的任务确定,GPU集群平台一方面可以调整任务执行的顺序,另一方面可以改变任务的放置策略。本文采用对称式放置,任务放置策略可以抽象为如式(3)所示的二元组:
s=〈dnode,dg/n〉
(3)
其中,dnode和dg/n分别表示任务所占结点的数量以及每个结点内占据的GPU数目,任务将会平均分配到各结点及结点内的GPU上。
给定分布式GPU集群平台和一个深度学习任务队列Γ=〈t1,t2,…〉,调度目标是为每一个任务队列中的深度学习任务在给定的集群平台上找到合适的放置策略和执行顺序,能够在满足每个任务自身的服务质量的同时,尽可能提高整个集群资源利用率。
为实现该目标,本文采用离线评估和在线调度相结合的方式。离线评估模块主要基于对深度学习任务的离线评测来分析其内在特征并构建性能预测模型。在线调度模块基于前者构建的性能预测模型,结合任务自身的预期服务质量,来共同设计调度策略,包括任务放置策略和任务执行顺序。
3 基于离线评估的性能预测模型
深度学习任务具有显著的迭代性,计算过程中保持相对稳定的计算效率,因此任务的执行时间可以用任务计算量和任务执行吞吐率来进行计算。任务t在放置策略s下的执行时间如式(4)所示:
(4)
其中,PR(t,s)为任务的吞吐率,而wbat·witer为整个任务的计算量,v为任务启动开销,是一个常量。
深度学习任务的分布式性能受单GPU上子任务的计算性能,及多GPU间同步通信开销2方面影响。基于此建立深度学习任务吞吐率的性能预测模型,如式(5)所示:
PR(t,s)=(dnode·dg/n-Comm(s))·sPR(t′)
(5)
其中,sPR(t′)表示子任务t′在单GPU上的吞吐率,Comm(s)是放置策略s所带来的通信代价开销。通过dnode·dg/n计算当前放置策略s下该任务一共占用的GPU总数,是理想最大吞吐率。实际系统中的通信开销在式中用Comm(s)来表示。
在对称式放置策略下,任务t在放置策略s下会依据全局批次大小batchsize平均划分到各个GPU上,每个GPU上划分到的子任务具有相同的局部batchsize。因此,每个GPU上的子任务t′如式(6)所示:
t′=〈wtype,w′bat,w′iter〉
(6)
其中w′bat=wbat/(dmode·dg/n)是指划分到每个GPU上的局部batchsize,可通过全局batchsize计算得到。
单GPU上的任务吞吐率sPR(t′)和w′bat正相关,本文采用多项式拟合,如式(7)所示:
sPR(t′)=∑iki(w′bat)i
(7)
其中,ki是与w′bat的i次幂对应的拟合系数,与任务类型wtype和集群平台模型P有关。为简化性能模型,避免过拟合,应尽可能选择较低次数的多项式拟合。通过实验数据证明,二次多项式回归拟合的结果(即i=2)已经足够描述单个GPU上的吞吐率性能曲线变化。
由式(5)知,同步通信开销与平台的GPU互连层次化结构以及每个深度学习任务的放置策略有关。利用任务所占GPU之间的平均通信路径长度来构建同步通信开销的罚值函数,如式(8)所示:
(8)
以放置策略s中的任意一个GPU为例,(dnode-1)·dg/n和(dg/n-1)分别代表该GPU需要跨结点通信的GPU数目和在同一结点内通信的GPU数目,需要通信同步的GPU总数是dnode·dg/n-1。系数γ主要体现该GPU集群平台的层次化GPU互连结构对通信开销的影响。同时,由于跨结点通信的路径与代价和结点内通信会有明显差异,用λ平衡结点间和结点内的通信带宽差异。系数γ和λ通过平台上具体任务的离线评测数据回归得到。
4 QoS感知的深度学习任务调度
4.1 任务调度模型
在多任务的深度学习研发场景下,任务的预期完成时间ECT(Expected Completion Time)往往会成为一个衡量该任务用户满意度的指标[15]。如果用户提交的任务能够在其预期完成时间前完成,则对用户来说是可以接受的,其满意度比较高。如果任务的执行超出了用户的预期完成时间,那么用户的满意度会出现明显的下降。由于不同深度学习任务的计算量和执行时长也具有明显的差异,为了能够统一进行评测和对比,以该任务在单个GPU上的执行时间作为一个标准化的基准时长[16]。对于普通用户提交的深度学习任务,其预期完成时间设定为2倍的基准时长。而考虑到实际应用场景下会出现不同优先级的用户和任务,因此对于更高级的优先级用户和任务,其预期完成时间也更短。因此,本文设置:Urgent、Prior和Normal 3种不同优先级的用户,分别表示最高优先级(应立即开始的)任务、优先任务和普通任务,其对应的预期完成时间如式(9)所示:

(9)
其中,〈1,1〉表示放置策略为在单个GPU上,即dnode=dg/n=1的情况。对于最高优先级的Urgent用户,其任务的预期完成时间为0,表示这些深度学习任务具有最高的优先级,需尽快执行。当任务队列中存在最高优先级的任务时,其用户QoS一定会被违反,但可以通过违反的程度来评估调度的优劣。采用用户QoS的保证率,即以有多少任务能够在用户的预期完成时间前完成,来衡量用户QoS的平均满意度。
对指定任务,增加GPU资源可以获得更好的执行速度,但是不同类型的深度学习任务对于GPU放置策略的敏感性不同。因此,对不同类型的任务可以有针对性地选择放置策略方案,在尽可能保证高性能的同时,降低资源占用和资源碎片化。为描述放置策略对资源占用和碎片化的影响,本文引入如式(10)所示的代价模型:
(10)
其中,N和G分别表示该GPU集群平台上的放置策略dnode和dg/n可取值的上限。在式(10)中,第1项代表该放置策略所使用的GPU数占GPU总数的比例,第2项是反映所占用的GPU之间的拓扑关系影响,而θ是用来调整2项之间平衡的因子。放置策略占用的GPU越集中,其代价也就越小,对资源碎片化的影响也就越小。
基于式(5)和式(10),可定义放置策略对任务的性价比CER(Cost-Effective Ratio)如式(11)所示:
(11)
给定GPU集群平台P,其结点数为N,单结点内GPU数为G,通信罚值函数为Comm(·),特定的深度学习任务队列Γ=〈t1,t2,…〉。队列中任务的预期完成时间分别为e1,e2,…。对每一个任务ti,调度器需为其选择放置策略si*,在满足任务预期完成时间要求的同时,尽可能具有最高的性价比CER值。在为每个深度学习任务计算选择放置策略之后,需要综合考虑整个任务队列中所有任务的不同紧急程度以调整任务的执行顺序。调度目标中的用户满意度衡量指标为不超过其预期完成时间的任务数百分比,而资源利用率指标则是所有任务的完成时间。上述调度问题的形式化建模如式(12)所示:
Given:P=〈N,G,Comm(·)〉,Γ=〈t1,t2,…〉,
find:S=〈s1*,s2*,…〉,O=〈t′1,t′2,…〉,
maximizing:Q,minimizing:M,

(12)
4.2 任务调度算法
由于不断有任务完成和新任务到达GPU集群平台,任务队列是动态变化的。因此,本文采用基于事件驱动的调度方法,在新任务到达或现有任务执行完成时进行调度决策。在调度点上采用最短等待余量优先的原则作决策。假设当前的时间点为tcurr,当前任务等待队列Qcurr有若干深度学习任务等待调度执行,t1,t2,…,tn,n=|Qcurr|,其预期完成时间分别为e1,e2,…,en。根据式(4)和式(11)计算每个任务在不同放置策略下的执行时间和性价比。例如,深度学习任务ti共有qi种不同的放置策略,分别为si1,si2,…,siqi,qi=|Mi|,其中Mi为任务ti的放置策略集合。该任务不同放置策略对应的执行时间l和性价比r分别如式(13)和式(14)所示:
l=〈li1,li2,…,liqi〉,qi=|Mi|
(13)
r=〈ri1,ri2,…,riqi〉,i∈[1,2,…,n]
(14)
为满足用户QoS,从集合中选择放置策略sij∈Mi,该策略能够满足预期完成时间要求,如式(15)所示:
lij+tcurr≤ei,
i∈[1,2,…,n],j∈[1,2,…,qi]
(15)
满足上述条件的放置策略sij形成子集M′i。选择该子集中CER最高的策略si*作为任务ti的放置方案。
为衡量队列中任务的紧急程度,本文引入等待余量w,任务ti在放置策略si*下的等待余量如式(16)所示:
wi=ei-(li*+tcurr),
i∈[1,2,…,n],si*∈M′i
(16)
根据每个任务的等待余量对任务队列进行重排序,等待余量小的任务拥有更高优先级。某些任务(例如Urgent类别的用户)如果不存在能满足其用户预期完成时间的放置策略,则直接从Mi中选择CER最高的策略作为解决方案。
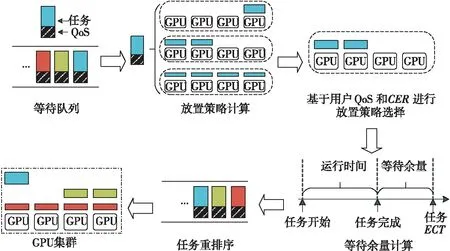
Figure 2 Scheduling process at time tcurr图2 tcurr时刻的调度过程
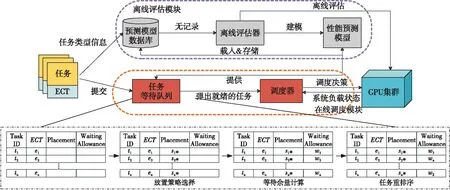
Figure 3 Implementation of the proposed scheduling method图3 本文调度方法实现架构
调度器依据重排后的队列依次将任务调度到集群上执行,直到当前资源无法满足执行需求。由于集群上不断有新的任务到达和原有的任务完成,等待队列中的任务放置策略和执行顺序也在动态地不断调整。上述特定调度点的动态调度过程如图2所示。
4.3 方法实现
本文以TensorFlow为基础,通过插件模式实现提出的调度方法,如图3所示,主要包括离线评估和在线调度2个模块。离线评估模块主要负责为各种深度学习任务构建性能预测模型,在线调度模块主要负责任务放置策略和执行顺序的选择。
离线评估模块主要包括预测模型数据库和离线评估器2个部件。在系统运行之前,先对典型的深度学习模型进行评测,并将其对应的性能预测模型保存在数据库中。当任务开始提交后,首先会在数据库中检索,如果命中就可以直接载入已有的性能预测模型,不用重复进行评测。如果未命中数据库,则先根据模型PB(Protocal Buffer)序列化格式文件中计算图(MetaGraph)的相似性,从数据库中选取一个相似度最高的模型,作为当前任务的临时性能预测模型。当GPU集群有足够空闲的资源时,评估器再对该模型进行离线评估,并将构建的性能预测模型更新到数据库中。
在线调度模块主要包括任务等待队列和调度器的实现。用户提交的任务首先导入任务等待队列,等待队列采用堆结构实现,在每个事件调度点,基于性能预测模型完成对放置策略的选择和等待余量的计算,然后实现自动排序。调度器负责监控系统的负载,当集群有足够的空闲资源时,重排序后的任务队列将依次弹出任务,由调度器将任务调度到GPU集群上执行。
5 实验评测与讨论
5.1 实验设置
实验平台:实验采用的GPU集群详细配置信息见表1。平台包括4个结点,结点间通过56 Gbps的InfiniBand高速互连网络相连接。每个结点包括双路CPU(Intel Xeon E5-2660 v3 @ 2.60 GHz),并配备64 GB的内存和2块GPU(NVIDIA Tesla K80),由于Tesla K80是单卡双核心,即每个结点配备4个GPU核心。结点运行CentOS 7.0操作系统,并安装TensorFlow 1.7.0深度学习实现框架。

Table 1 Configuration of distributed GPU cluster 表1 分布式GPU集群配置
任务队列:参考文献[17,18]生成任务队列,不同类型的深度学习任务以泊松分布随机产生并提交到GPU集群。生成任务队列的具体设置信息见表2,包含AlexNet、GoogleNet、ResNet-50和Inception-v3共4种典型的卷积神经网络模型,以及Regularized LSTM和Seq2Seq 2种典型的循环神经网络模型。队列中单个任务的模型类型、计算类型、应用超参数设置(如迭代次数、批次大小等)都通过均匀分布来产生。根据文献[19]中关于企业级任务负载的分析,将任务队列中不同优先级用户的比例设定为Urgent∶Prior∶Normal=5%∶35%∶60%。任务队列中任务提交的总时长为24 h。为进一步评测不同任务密度条件下的调度性能,设定每小时5,10,20等不同的任务到达数目。
基准:Yarn、Mesos、Kubernetes等主流集群管理系统中常用的以下几种调度策略作为基准与本文方法进行比较。
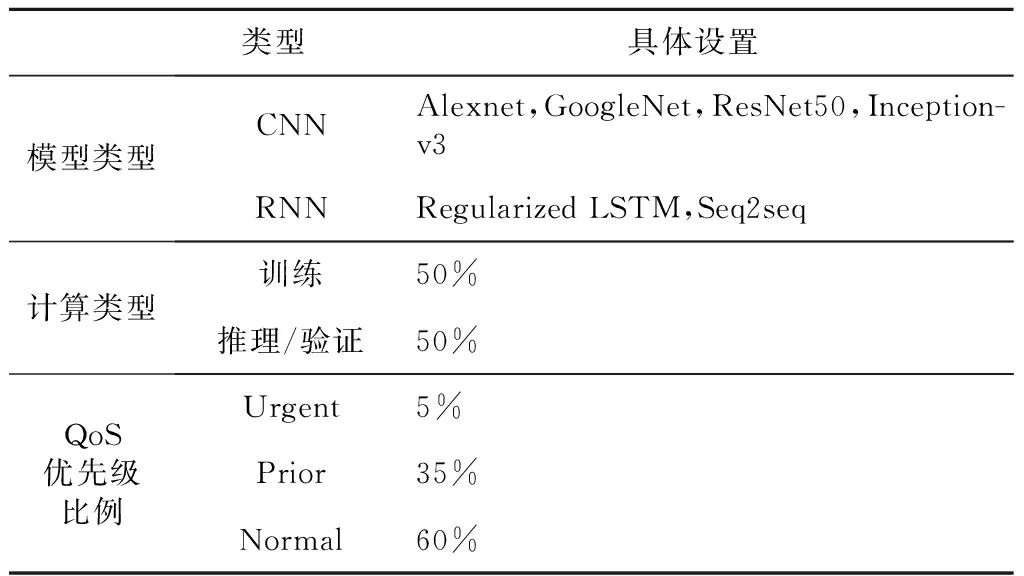
Table 2 Specifications of task queue generation表2 任务队列设置
(1)FIFO调度策略:FIFO调度策略按照任务到达的顺序来进行调度执行,每个任务的资源分配根据用户指定,并结合当前资源的空闲状态。
(2)容量调度策略(Capacity Scheduler):每种不同类型的任务都具有一定的资源容量保证,每个任务根据需求占用自身容量范围内的资源,但是不能超过限制占用其他类型任务的资源。
(3)Min-Min调度策略[20]:Min-Min调度策略依赖于用户的QoS,即用户预期完成时间越靠前,该任务的优先级越高,调度器也会优先执行该任务。
(4)加权公平调度策略(Weighted Fair Scheduler)[21]:加权公平调度策略采用任务到达时间和预期完成时间的加权值作为任务执行顺序的标准。更小的加权值对应的任务具有更高的优先级。
(5)Tetris[22]+Perf调度策略:Tetris策略通常基于性能评估来为任务分配资源。但是,在深度学习研发场景下该策略没有自身的性能模型,因此本文将Tetris和所提出的性能预测模型相结合,并每次为任务选择具有最高执行性能的放置策略。
(6)Tetris+CER调度策略:和上述方案类似,但采用Tetris和性价比模型相结合的方式,每次为任务选择性价比最高的放置策略,不考虑用户自身的QoS。
可见从Tetris+Perf调度策略到Tetris+CER调度策略,再到本文基于用户QoS感知的调度策略,其中包含关于深度学习任务自身特征的信息越来越多。整体而言,相比于上述对比策略,本文的调度策略同时将用户的QoS以及资源占用性价比纳入了调度决策,能够更好地实现用户满意度和资源利用率之间的平衡。
评测标准:调度目标在保证用户QoS的同时,尽可能提高集群的资源利用率。因此,实验评测中采用的指标为所有任务的完成时间makespan,以及用户的QoS保证率Q。用户QoS保证率的具体计算方式如式(17)所示:
(17)
其中,NUMcomp表示执行时间未超过预期完成时间的任务数目,而NUMtask表示任务队列中的任务总数,因此用户QoS保证率是指不超过预期完成时间的任务百分比。
不同深度学习任务的执行时长差异极大,为公平展现深度学习任务性能和调度性能,本文采用平均标准化的执行时间(average normalization of response latency)来统一进行分析和对比。对于特定的任务队列〈t1,t2,…〉,其平均标准化的执行时间具体定义如式(18)所示:
L=avg(Lnorm(ti)),i∈[1,2,…],
(18)
其中,Lnorm(ti)表示任务ti标准化后的执行时间,为其实际执行时间Lwall(ti)与式(4)计算的该任务在单个GPU上的执行时间Lat(ti,〈1,1〉)之比。为降低随机性因素的影响,所有实验都取3次独立测试取平均值后的结果。
5.2 性能预测模型实验
首先测试第3节性能预测模型的效果。深度学习任务的分布式性能主要由单GPU性能和多GPU通信2部分组成,本文采用式(5)进行预测。对Inception-v3和ResNet50 2个典型训练任务的预测结果与真实性能的对比如图4所示,其中方块为表1所示实验平台上测得的真实性能,三角形为模型的预测结果。横坐标表示不同的分布式放置策略,B、N、G分别表示batchsize、运算所占用的结点数和每个结点占用的GPU数量,例如“64B1N1G”表示batchsize为64,结点数和GPU数均为1;纵坐标为计算性能,单位为image/s,表示每秒训练完成的图像样本数量。从图4中可以发现,不同放置策略下性能预测模型的结果与真实性能的趋势相同,其平均预测误差低于5%。对于推理任务,由于没有同步通信的开销,其预测精度还要高于训练任务。由于深度学习任务具有迭代性特征,因此对每个任务只需要进行大约100次左右的迭代执行,每次迭代平均耗时约为0.5 min。预测精度和开销均能够满足调度任务的需求。

Figure 4 Measured and predicted performance of Inception-v3 and ResNet50 training tasks 图4 Inception-v3 和 ResNet50 训练任务的 真实性能和预测性能对比
此外如2.1节所述,在深度学习研发的过程中广泛存在超参数调整和网络fine-tuning,使得用户提交到GPU集群的作业中存在大量网络结构相同或相似的任务,其计算通信特性也相似。对于这些相同或相似的任务,每个深度学习模型只需要进行1次离线评估,其对应构建的性能预测模型将会保存在数据库中,后续相同类型的任务可以直接查询,不需重复进行评估。
5.3 调度策略性能对比实验

Figure 5 Performance comparison of diverse scheduling strategies图5 不同调度策略的性能对比
首先本节将基于用户QoS感知的动态调度策略与其他几种基准策略进行评测和对比。如图5a和图5b所示,随着任务提交密度的增大,所有调度策略的用户QoS保证率都在逐渐下降,因为任务密度的增大意味着同样规模的计算资源要处理更多的任务,从而导致用户QoS的满意度下降。具体来看,容量调度策略和Tetris+CER调度策略比其他基准策略表现更好,因为这些策略更关注于资源共享而不是单个任务的性能。对于FIFO调度策略和Tetris+Perf,过度追求每个任务的性能最大化,导致其他任务的等待时间过长或集群资源的利用率低。而Min-Min调度策略和加权公平调度策略只关注用户的需求,忽略了对任务性能本身和资源占用的直接关系。相比于上述基准调度策略,本文的用户QoS感知策略能够将用户需求和性能与资源占用的关系同时纳入调度设计的考量中,实现用户满意度和集群资源利用率的平衡。同时,该策略对不同任务密度的任务队列具有良好的容忍度和鲁棒性,这是因为调度策略基于当前系统负载状况和用户的QoS需求可以动态调整。从结果上分析,本文方法在用户QoS保证率上和makespan上比最好的基准策略也分别提高了67.4%和降低了28.2%。然而,如果任务密度过大(>20),用户的QoS需求很难满足。此外,本文还对任务的平均执行时间也进行了评测,结果如图5c所示。显然Tetris+Perf调度策略从单任务性能出发,每次选择能够最大化任务性能的放置策略,因此在该项指标中具有明显优势,但是该策略会导致资源利用率低,其他任务等待时间过长。相比于该策略,本文方法在不同任务密度下依然可以取得较好的单任务性能,同时还能兼顾资源共享。而其他调度策略只是将深度学习任务作为黑盒子,而忽略了资源占用和深度学习任务性能之间的关系。最后对不同调度策略下任务完成的累积分布CDF(Cumulative Distribution Function)进行了统计,结果如图5d所示。由于本文策略具有更高的资源利用率,因此任务完成的速率也高于其他调度策略。
5.4 任务敏感性测试
为评估生成任务队列的各种设置参数具体会对调度策略有什么影响,本节分别针对每个参数进行任务敏感性实验。首先考虑调度策略在不同任务密度下的性能对比。如图6a和图6b所示,当任务密度比较稀疏时,大部分调度策略都能够有较好的调度性能。而随着任务密度的增大,由于计算资源优先,用户的QoS需求越来越难以保证,同时所有调度策略完成所有任务的时间都在不断增长。和其他基准策略相比,本文基于用户QoS感知的调度策略可以动态考虑用户需求和集群负载状况,因此对任务密度具有更高的容忍度。该策略和其他最好的基准策略相比在QoS保证率上提高了67.5%,在所有任务的完成时间上降低了39.3%。
其次考虑不同紧急程度的研发场景下调度问题,即各种优先级用户比例不同的场景下的调度问题。如图6c和图6d所示,图中每列数据下方的3个数字分别表示3种不同优先级用户比例,分别是Urgent/Prior/Normal。从结果上来看,随着优先级越高的用户所占比例增加,整体用户QoS的保证率也在不断下降。通过和其他基准策略的对比,本文策略每次调度都尝试为用户选择尽可能满足需求的放置策略,同时尽可能缩短整个任务的完成时间。
最后考虑拉长任务队列提交时间长度的影响。评测中的任务密度设置为每小时到达15个任务,其评测结果如图6e和图6f所示。随着任务提交时间的拉长,所有任务完成时间同样也在增长,本文策略在用户QoS保证率上具有明显的优势。

Figure 6 Sensitivity test of scheduling policy to task queue parameter setting图6 调度策略对任务队列参数设置的敏感性测试
5.5 调度器开销
系统调度开销主要来自于对系统运行负载的监控和反馈,以及每个任务放置策略的决策过程,而这些过程的大部分开销都是在主结点(Master node)上产生的。如图7所示,随着任务密度的增大,调度器需要对更多的任务放置策略进行决策,因此也会导致更高的调度开销。相比于其他基准策略,由于本文调度策略设计更加复杂,因此调度开销也要高于其他方法的。然而相比于所有任务的完成时间makespan(数十小时,甚至数百小时),即使在任务密度较大的状态下(=20),本文方法调度开销所占比例也低于主结点总开销。

Figure 7 Cumulative scheduling overhead on master node图7 主结点上的累积调度开销
6 结束语
本文围绕GPU集群平台上的深度学习研发场景,提出一种用户QoS感知的动态调度方法,由离线评估模块和在线动态调度模块2部分组成。通过离线评估器构建深度学习任务的性能预测模型,然后动态地为每个深度学习任务选择最佳放置策略并在GPU集群上调度执行。本文通过TensorFlow插件模式实现了该调度方法,在实际GPU集群上进行的实验表明,该方法比其他基准对比方法能够实现更高的QoS保证率和集群资源利用率。未来计划进一步将该方法合并到Kubernetes等主流集群管理器框架中。
