基于生成与检索双模型的对话机器人设计
2021-09-23卞政穆宝良王蓓唐福龙
卞政 穆宝良 王蓓 唐福龙
(沈阳师范大学 辽宁省沈阳市 110034)
1 绪论
1.1 研究背景
随着社会信息化程度的加深,我们的生活有越来越多的方面有了智能系统的参与。在许多领域,智能系统与自动化设备相似,不断地进行着缩短工序、提高效率和减少成本等优化操作。在20世纪90年代之前,问答系统并谈不上智能。常见的问答系统模型通常采用依赖模板或基于人工制定规则的对话方式,缺乏语义分析能力的同时也不具有知识库,无法理解用户输入的含义,进而导致对话效果难以令人满意。
但在近30年,信息量和信息处理能力都大幅飞跃,智能问答系统开始崭露头角。与此同时,深度学习技术使得智能对话系统的效果得到较大提升,因此,在一些需要进行服务性对话的应用场景中,逐渐有实际的对话机器人与答疑机器人的出现。
1.2 研究现状与目的
目前对话机器人的主要实现分为检索式与生成式两大类。
其中,检索式对话机器人在技术上主要依赖问答库。产生的对话会围绕着问答库中已存在的数据进行,内容可控性强,适合事实类问答功能的实现[1]。然而,实现包含所有情形的问答库是不现实的,同时检索式方法也在问答定位的准确度上有所缺失。
实现生成式对话机器人的技术是对大量的对话语料进行学习。对话的产生会在一定程度上与人类日常对话的形式相仿,因此适合应用在多样性与泛化性强的应用场景中[2]。然而,生成式方法产生的对话具有较强的不可控性,同时也容易出现前后文信息不一致、“安全回答”等问题。如果产品设计对于智能化程度的要求较高,上述的两种方式实现的对话机器人都有各自的缺点从而无法满足需求。本文设计了一种基于生成式和检索式方法相结合的对话机器人。
两种方法的结合使用可以在一定程度规避各自的缺点,结合两者的优点,从而构建一个通用性较强的对话机器人,使得其能够对各类情况做出较好的处理。
2 理论与方法基础
2.1 检索式模型
检索式模型主要依赖于信息检索技术。建立检索式模型,首先要构建出一个由大量问答对构成的对话语料库,随后对输入进行特征提取,并根据特征在语料库中匹配出少量问答对作为候选集,最后选用合适的指标从候选集中挑选出最佳回复[3]。在深度学习技术引入NLP领域之前,检索式模型的实现通常是基于传统信息检索算法的,如TF-IDF技术[4]。可见,无法生成新的内容是检索式模型的一个局限。
对于封闭域的对话机器人,其语料库的建立可以以人工的方式进行,即手动的将该封闭域内可能出现的情形形成问答对的形式,随后加入语料库。而在开放域,可以考虑采用网络爬虫等自动方式来快速、大量地收集语料。同时,由语料库的普遍组建方法也可以看出,封闭域中将产生的对话可控性更强,但只有在语料库足够庞大、完备的情况下才能保证兼容性。而开放域语料库又因为问答对质量的参差不齐,虽然兼容性较强,但很难保证对话有效性。
基于上述,在实际应用中检索式对话机器人在封闭域的效果更好。
2.2 生成式模型
生成式模型的主要思路是录用大规模的语料训练模型,从而学习人类对话的模式和特征,使得模型能够自行生成与输入相匹配的回复。生成式模型的普遍模式是编码解码模式,多为seq2seq模型的改进版[5],即通过编码机器学习语义特征,通过解码器生成回复。这种模式的特点是生成的回复流畅、自然且泛用性强,但随之而来也常有“安全回复”的问题。
生成式模型的最佳应用环境与语料库的内容分布有较大的关联,如果语料库所涉及的广度较大,则该模型在开放域的表现会更好。反之,如果语料库在某角度的深度较大,则该模型可以适用在封闭域。但事实上,在封闭域情景中,我们通常难以提供满足训练seq2seq模型的需求规模的语料库。相反,作用于开放域的语料库则可以非常容易的从社交媒体数据库、影视文化作品的脚本等地获取。
基于上述,在实际应用中生成式对话机器人在开放域的效果更好。
2.3 模型输出评估标准
对话效果评估方式一般分为两类,分别是人工评估和自动评估。人工评估虽然存在人工要求高和效率低的缺点,但仍是最准确和有效的评估方式。目前主要的人工评估方法有对对比和李克特量表评价两种。自动评估可以分为不需要参考回复和需要参考回复的两类评估方式。其中,需要参考回复的评估方式主要针对生成式模型的对话效果进行评估,而不需要参考回复的评估方式同时适用于生成式和检索式模型。因此,本文主要讨论不需要参考回复的评估方式。
2.3.1 检索式模型评估指标
检索式模型算法的核心是在匹配中的候选集中排序的方式,常见的实现是基于传统信息检索系统中常用的若干指标:
(1)召回率=系统检索到的相关回复/系统所有相关的回复总数
(2)准确率=系统检索到的相关回复/系统所有检索到的回复总数
F值(F-measure):指召回率和准确率的调和平均值,它综合了两者的评价效果。

召回率是考察系统找全回复的能力,而准确率考察系统找准回复的能力,两者相辅相成,从两个不同侧面较为全面地反映系统性能。当即F1值,是召回率和准确率的调和平均数。
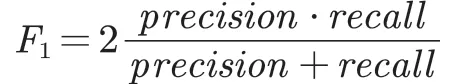
随着测试集规模的扩大以及人们对评测结果理解的深入,研究者提出能更准确反映系统性能的新评价指标,包括:
(2)P@K:指的是单个查询中检索出的前10个回复的准确率。
(3)平均准确率MAP(Mean Average Precision):AP(Average Precision)是指单个查询检索的平均精确度,MAP是对整个测试集求平均AP值。
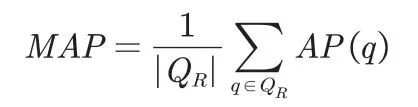
2.3.2 生成式模型评估指标
生成式模型主要评价的是生成回复的质量,其评估指标主要聚焦于回复本身的信息量和生成概率。目前比较常见的指标有如下四种:
(1)困惑度(Perplexity)。语言模型中通常用困惑度来衡量一句话出现的概率,也常常被用在对话生成评测中,评价生成回复语句的语言质量。其基本思想是测试生成的回复语言质量越高,困惑度越小,越接近人类正常说话,模型越好。困惑度指标的缺点是不能评估在对话中回复与上文的相关性。
(2)熵(Entropy)。熵可用于度量生成的回复的信息量。
(3)回复多样性指标Distinct-1&2。针对对话系统中万能回复的问题,通过计算生成回复中一元词和二元词的比例来衡量回复的多样性。具体来说,Distinct-1和 Distinct-2分别是不同的unigrams和 bigrams的数量除以生成的单词总数。
(4)平均回复长度。用平均长度来衡量对话生成效果,认为生成长句子的模型相对质量更高。
3 生成式与检索式模型协同处理
我们注意到,基于生成式模型的对话机器人在开放域的表现更好,基于检索式模型的对话机器人在封闭域的表现更好。但在一些应用场景中,对话机器人被要求同时能够处理开放域和封闭域的对话任务。显然,单一模型的对话机器人难以在两个领域都实现令人满意的效果。容易想到的是采用由检索式模型和生成式模型结合而成的联合模型去解决该问题。
联合模型的原理可以是并行或串行的。并行使用两个模型,对检索式和生成式模型的回复设计算法进行评估,如果检索式回复的效果较好,则以检索式回复作为结果,否则返回一个生成式回复。并行方案的缺点是对于单个任务要分别调用两个模型,造成了计算开销。串行使用两个模型,以检索式模型的回复作为基础,在删去检索式模型回复中的无关内容后由生成式模型对空缺处进行填充。串行方案的设计理念很好,但在实际应用上常常效果无法令人满意。其原因是任务在本质上只会属于封闭域或开放域两者之一,而根据串行方案的原理,实际上是给出了一种较为中间的解决方案,这样对于有二元性的任务反而并不能起到很好的效果[6]。
本文提出了一种基于并行方案的优化方法:对检索式模型的语料库做预处理,并设计算法将任务内容结合语料库的预处理结果去计算当前任务属于封闭域问题的概率,当概率高于某个阈值时,使用检索式模型做出回复,反之则使用生成式模型生成回复。该方法的优点是实际上对于每个任务仅会调用一个模型,减小了计算开销。缺点是,需要以合适的方式对语料库做预处理,造成了额外的时空开销。难点在于模型最终效果高度取决于预处理方式和判别算法。同时,基于任务的二元性,本方案在理论上会比串行方案效果更好。
3.1 算法思想
首先将封闭域场景问句中出现的词汇分为三类:
(1)普通词Normal:在任何句子里都有较高可能遇见的词,例如“是”、“什么”、“然后”等词。以及在该封闭域内常出现的专业词汇。
(2)属性词Attr:部分属于封闭域词汇中的限定词,部分是用来衡量程度的词汇,常与核心词结合使用。
(3)核心词Core:可以以较大概率唯一标记问答对的词汇。
根据定义,句子中一般含有大量Normal词和少量的Attr,Core词。而且Core既可单独出现,也可以与Attr结对出现。则句子的构成可能是一个或多个Core/Core-Attr与若干Normal的组合。在理想情况下,若任务中出现Core/Core-Attr,可以认为任务属于封闭域。
算法的核心思想是对Word/Word-Word成为Core/Core-Attr的概率进行判定,随后根据任务中Core/Core-Attr的出现情况,计算任务属于封闭域的概率大小。
3.2 算法流程
首先将语料库中所有问答对的问句分词,并统计词频,从小到大排序。
(1)挑选一个核心词系数c,对词频最小c%的词进行Core判定。
(2)将不进行Core判定的词(Attr Candidate)的词频归一化。
(3)对于每一个要进行Core判定的词Word:
1.首先要进行Core-Attr对的判定
①在含有Word的句子集合中构建Word-Attr Candidate对集合,其中每个W-AC对的权值由Attr Candidate的词频决定;
②使用SVM对W-AC对的权值进行二分类,由F1值计算高词频部分构成Core-Attr的概率。
1)如果F1比较大,意味着高词频部分构成Core-Attr的概率很大,我们将高词频部分的Attr Candidate加入Attr集合留作后用;
2)如果F1比较小,意味着Word可能是Normal或者是单独出现的Core,记录该Word到C/N。
(4)对于C/N中的每个Word:
1.首先与Attr集合构建Word-Attr对集合;
2.在含有Word的句子集合中,检查Word-Attr对的出现频率。
①如果频率较高,则以较高概率认定Word为Normal;
②反之则以较高概率认定Word为Core。
3.3 算法分析
在算法流程1中,c越大,预处理的效果就越好,判断成功的概率会上升,但时空开销也会增大。同时,因为绝大部分的Core会分布在低词频的区间,选取过大的c可能会将更多的非Core词加入概率判断,反而降低了判断成功的概率。如果语料库并不庞大,可以采用模拟退火算法求出c的近似最优解。
4 结语
业界对对话机器人的表现与应用范围的要求越来越高,对当前市场上对话机器人的表现有所不满。目前采用联合模型的对话机器人研究相对较少,联合模型开发有较大的发展空间。本文提出了一种基于联合模型并行方案的优化方案,主要着力于在对语料库预处理算法上的改进。该模型还有一些设计上和原理上的不足,由于笔者能力有限,仅做抛砖引玉之用,为对话机器人同时处理开放域和封闭域的对话任务提供一个思路。
