行人多目标跟踪算法
2021-09-22朱新丽寇婷婷杜冬晖孙俊喜
朱新丽, 才 华,2, 寇婷婷, 杜冬晖, 孙俊喜
(1. 长春理工大学 电子信息工程学院, 长春 130022; 2. 长春中国光学科学技术馆, 长春 130117;3. 东北师范大学 信息科学与技术学院, 长春 130117)
多目标跟踪技术广泛应用于计算机视觉领域中的智能视频监控、 自动驾驶和人机交互[1]中. 采用传统多目标跟踪方法进行目标跟踪, 跟踪准确率和跟踪速率都较低, 且很难适应较复杂的背景. 在多目标跟踪中应用深度学习可有效提高模型的准确性和鲁棒性, 从而适应更复杂的背景环境, 因此基于深度学习的多目标跟踪算法已成为多目标跟踪技术的发展趋势. 多目标跟踪技术可实现对给定的视频或图像中多个对象进行同时定位, 同时保持他们的身份(ID)标签不变, 并最终给出各自的运动轨迹. 跟踪的对象可为行人、 车辆和鸟类等, 目前研究最多的跟踪对象为行人, 因为行人是典型的非刚性目标, 其在跟踪难度上比刚性目标更大, 且在实际应用中行人的检测跟踪应用范围更广泛.
传统目标检测算法主要包括预处理、 窗口滑动、 特征提取、 特征选择、 特征分类和后处理等6个主要步骤[2]. Girshick等[3]采用基于区域的卷积神经网络(region based convolutional neural network, R-CNN)将深度学习应用于目标检测, 将在数据集PASCAL VOC 2007上的检测精度从29.2%提升到66.0%, 极大提高了目标检测的准确率, 这种基于端到端的训练, 将目标的特征提取、 特征选择和特征分类融合在同一模型中, 实现了性能与效率的整体优化[2]. 近年来, 深度学习技术迅速发展, 其在检测和识别的应用中都取得了良好效果. 在深度学习算法中, 目标检测可分为双阶段检测和单阶段检测, 其中: 双阶段检测[2,4-7]基于候选区域, 首先粗略地定位检测框, 然后进行细化; 单阶段检测[8-10]是基于回归的端到端目标检测. 其主要区别在于检测过程是否分为两个阶段, 前者由检测和分类两个阶段组成, 后者则将这两个阶段融合到一个阶段进行. 在性能上, 单阶段检测网络速度快, 双阶段检测网络准确度更好. Baser等[11]提出了一种数据驱动的在线多目标检测与跟踪算法, 该算法使用卷积神经网络(CNN)在每个检测器中进行数据关联, 通过深度学习技术将数据关联问题等效为CNN中的推理, 同时监督学习一种相似性函数, 该函数包含了目标所在图像上和空间上特征的信息, 该算法可从3D上对数据进行全局分配, 对检测杂乱和数量分布不均的目标进行精确处理, 并且容易训练. Yu等[12]提出了一种具有高性能检测和外观特征的多目标跟踪算法(POI), 该算法采用动态尺度的多尺度训练策略, 组合不同尺度和水平层次的特征. He等[13]对YOLOv3[14]进行了改进, 使用双线性插值方法调整图像大小, 使网络检测小目标的能力得到提升, 更适合行人多目标跟踪的应用场景, 提升了跟踪效率[15]. Bewley等[16]提出了SORT算法, 该算法只使用Kalman滤波器和匈牙利算法等基本组合构建跟踪器, 由于使用了Faster RCNN作为检测器, 使算法有较高的效率, 但其目标的标签交换次数过多; 文献[17]在SORT算法的基础上又提出了Deepsort算法, Deepsort算法是在原算法的基础上整合了外观信息, 并在预训练阶段加入了深层关联度量, 在线期间使用视觉外观空间中的最近邻数据关联算法进行轨迹关联, 同时使用级联匹配算法进行匹配, 并使用马氏距离和余弦距离计算运动信息和外观信息. Wang等[18]提出了JDE算法, 通过在单阶段检测的检测器中嵌入外观模型的方法, 使其在输出检测结果的同时输出相对应的嵌入向量, 并对各损失值进行自动加权计算. AI对象检测器FairMOT[19]通过一个统一的网络同时完成目标检测和身份重识别(REID)两项任务, 并通过对大部分计算共享减少时间. 任珈民等[20]提出了一种基于YOLOv3与Kalman滤波的多目标跟踪算法, 只使用Kalman滤波算法, 在应对复杂背景等非线性的情形下, 最终得到了目标跟踪34.4%的准确度.
但上述算法在面对多目标跟踪中目标被遮挡的问题时, 其跟踪效率均较低, 为提高目标被遮挡情形下的多目标跟踪效率, 本文提出一种新的行人多目标跟踪算法: 首先使用YOLOv4[21]检测待跟踪目标得到检测框, 利用扩展Kalman滤波器预测下帧图像中跟踪目标的位置; 其次采用匈牙利算法进行数据关联, 确定行人目标的运动轨迹, 并针对发生遮挡的目标加入轨迹异常修正算法缓解遮挡引起的目标丢失.
1 本文算法
为提高多目标跟踪的跟踪准确度及跟踪速度, 本文使用YOLOv4作为检测器, 检测出当前帧中不同尺寸的行人目标并确定对应的边界框(Bbox); 利用扩展Kalman滤波器预测下帧图像中跟踪目标的位置; 采用匈牙利算法进行数据关联, 确定行人目标的运动轨迹, 并针对发生遮挡的目标加入轨迹异常修正算法缓解遮挡引起的目标丢失.
1.1 目标检测网络
YOLOv4深度神经网络由卷积层、 残差网络层、 激活函数层、 批标准化(batch normlization)等网络基础层组成, YOLOv4整体结构如图1所示. 本文选用YOLOv4网络作为检测器.

图1 YOLOv4整体结构Fig.1 Overall structure of YOLOv4
目标检测网络首先通过骨干CSPDarknet(卷积-批量归一化层-Mish激活函数)改变输入图像的尺寸, 通过多个残差组提取图像特征, 获得多种分辨率的特征图, 采用1×1,5×5,9×9, 13×13的最大池化方式进行多尺度融合, 然后对特征图进行上采样, 与原特征图拼接, 利用特征金字塔结构获得19×19,38×38,76×76三种不同尺度的预测结果. 在检测模块中添加了深度残差收缩网络(DRSN)[22], 使网络模型引入了软阈值函数, 并将其作为非线性层, 以增强深度学习方法对含噪声数据或复杂数据的特征学习效果.
深度残差收缩网络由深度残差网络、 注意力机制和软阈值函数三部分组成, 其先通过注意力机制查找无用特征, 再使用软阈值函数将其设为零, 增强了深度神经网络从含噪声数据中提取有用特征的能力. 软阈值函数是将绝对值小于某个阈值的特征设为零, 将绝对值大于该阈值的特征趋近于零, 计算公式为

(1)
其中x为输入特征,y为输出特征,τ为阈值(非负值).软阈值函数的导数为
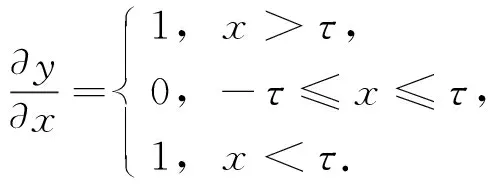
(2)
由式(2)可得软阈值函数的导数为1或0.该属性类似于整流线性单元(ReLU)激活函数. 因此, 软阈值函数的使用也能减小梯度弥散和梯度爆炸的可能性.
在计算机视觉领域, 注意力机制是使系统快速扫描范围内的所有物体, 找到目标物体, 从而将注意力放在目标物体上, 以提取目标物体更多有用的细节信息, 同时忽略无关物体的所有信息. 深度残差收缩网络通过改进SENet[23]的子网络结构, 达到在深度注意力机制下使特征软阈值化的目的, 其残差模块如图2所示.
深度残差收缩网络对深度残差网络的残差模块进行改进, 在其中引入子网络, 通过子网络学习, 得到一组阈值, 并对每个特征通道进行软阈值化处理. 在子网络中, 所有输入特征的绝对值经过全局平均池化得到最后的平均值A; 同时, 全局均值池化后的特征图, 通过一个全连接网络(其最后一层为Sigmoid激活函数)输出系数α; 平均值A和系数α相乘得到最后的阈值.这样既可以使阈值大于零且每个样本都有自己的阈值, 同时保证阈值大小适当.因此, 深度残差收缩网络的工作原理是注意到无用特征, 通过软阈值函数, 将其设为零; 或注意到有用特征, 将其保存.完整的深度残差收缩网络如图3所示.由图3可见, 输入首先通过卷积层, 然后经过多个基本模块, 再经过批标准化、 整流线性单元激活函数、 全局均值池化层, 最后从全连接输出层得到分类结果.

图2 深度残差收缩网络的残差模块Fig.2 Residual module of deep residual shrinkage network

图3 深度残差收缩网络的整体结构Fig.3 Overall structure of deep residual shrinkage network
1.2 跟踪器
本文采用改进的Deepsort作为跟踪器, 将其中的Kalman滤波器调整为扩展Kalman滤波器, 以满足非线性输入线性化, 并预测下一帧目标位置, 先将YOLOv4的检测结果输入扩展Kalman滤波器, 得到当前帧的估计值, 然后使用融合度量的方法计算检测结果与跟踪结果的匹配程度, 最后对运动轨迹中发生遮挡的物体加入轨迹异常修正算法, 以得到更准确的跟踪轨迹.
1.2.1 扩展Kalman滤波
传统Kalman滤波器只适用于高斯分布的线性系统中, 但在多目标跟踪的实际应用中存在大量非线性因素, 如光照、 形变、 复杂的环境背景以及各种遮挡等因素. 因此, 本文引入扩展Kalman滤波器解决上述问题.
扩展Kalman滤波算法通过状态方程和观测方程描述. 状态方程是关于上一个状态和将要执行控制量的二元函数, 再叠加一个高斯噪声, 计算公式为
θk=f(θk-1)+sk,
(3)
其中θk是第k帧目标的系统状态向量(第k帧目标的真实值),f(θk-1)为状态转移矩阵,sk是协方差为Q的零均值高斯噪声.观测方程是关于当前状态的函数再叠加一个高斯噪声, 计算公式为
zk=h(θk)+vk,
(4)
其中zk为第k帧目标的系统观测向量(第k帧目标的检测值),h(θk)为观测矩阵,vk是协方差为R的零均值高斯噪声.
对于非线性系统中的状态估计问题, 采用Kalman滤波器解决.对f(θk-1)和h(θk)非线性函数进行Taylor级数展开, 取一次项为一阶扩展Kalman滤波, 公式为

(5)

(6)
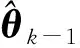
1.2.2 轨迹异常修正

图4 遮挡情形下的行人跟踪结果Fig.4 Pedestrian tracking results under occlusion

图5 轨迹异常修正算法流程Fig.5 Flow chart of trajectory anomaly correction algorithm
当跟踪目标被遮挡时, 利用匈牙利算法进行数据关联, 虽然可能跟踪到目标, 但效果不佳, 如图4所示. 由图4可见, 行人从开始被遮挡到遮挡结束, 遮挡前后跟踪目标的ID发生了转变, 即跟踪轨迹有发生中断的情况. 基于此, 本文加入了轨迹异常修正算法, 以减少因遮挡情形出现的轨迹中断, 即跟踪目标ID变换现象.
轨迹异常修正算法[24]步骤如下:
3) 比较(T-1)时刻和T时刻目标i的中心点P(Ti-1)和P(Ti);
4) 更新边界框中心点坐标.坐标更新过程如下:
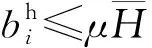
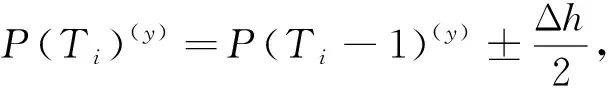
(7)
其中Δh为(T-1)时刻和T时刻的边界框高度变化量.

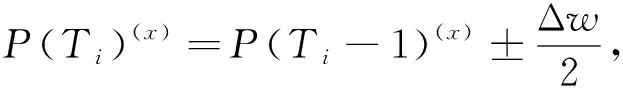
(8)
其中Δω为(T-1)时刻和T时刻的边界框宽度变化量.
轨迹异常修正算法的流程如图5所示.
1.3 算法流程
本文算法步骤如下:
1) 用YOLOv4检测器对目标进行检测, 得到当前帧目标的检测框和置信度;
2) 通过置信度删除部分检测框, 并利用深度神经网络提取各检测目标的特征, 由输入第一帧图像的检测输出信息初始化扩展Kalman滤波器;
3) 通过扩展Kalman滤波器, 根据上一帧的目标框信息为当前帧预测目标位置信息, 得到预测目标框;
4) 计算面积交并比(IOU), 并使用级联匹配得到匹配成功和匹配失败的边界框;
5) 利用匈牙利算法进行数据关联, 对于匹配成功的边界框, 直接输出其坐标; 对于匹配失败的检测框, 首先创建一个新的跟踪器, 保存其坐标及特征, 若连续3帧均跟踪成功, 则将其作为新增的检测目标, 然后初始化新的扩展Kalman滤波器; 若连续3帧均跟踪失败, 则将其作为目标丢失处理, 然后加入轨迹异常修正算法寻找丢失目标, 在寻找过程中若帧数超过60帧还未找到, 则删除跟踪器;
6) 处理完所有图像则结束, 否则转步骤3).
本文算法流程如图6所示.
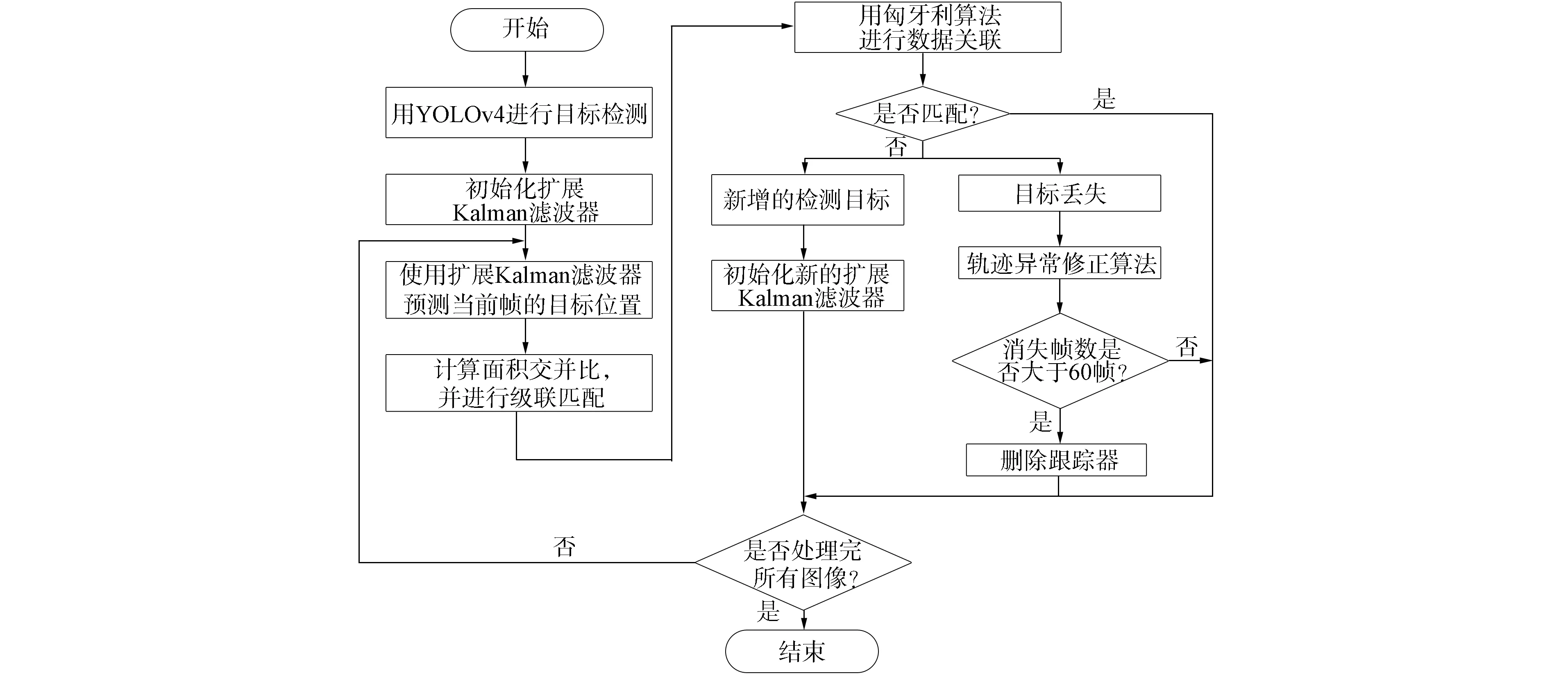
图6 本文算法流程Fig.6 Flow chart of proposed algorithm
2 实 验
2.1 实验环境
本文采用COCO数据集训练本文算法的模型, 用MOT16的训练集作为测试集测试本文算法, 数据集中包含多个行人目标, 且存在目标交互和遮挡现象. MOT16训练集中各包含7段视频. 实验环境: Ubuntu 18.04, Intel Xeon(R) CPU E5-2660 V2 @ 2.20 GHz×40处理器, GeForce GTX 2080Ti GPU显卡, Python3.6.12.
2.2 评价标准
实验采用跟踪准确度(MOTA)、 跟踪精度(MOTP)、 命中的轨迹假设占地面真实总轨迹的比例(MT)、 丢失的目标轨迹占地面真实总轨迹的比例(ML)、 身份标签切换总数(ID_Sw)、 误检总数(FP)和漏检总数(FN)作为评判标准.
2.3 实验结果与分析
设计两组实验, 对比分析本文算法的性能.
实验1本文算法在不同视频序列上进行多目标跟踪测试, 分析在不同背景下本文算法的实验结果.
实验2将本文算法与其他算法进行对比, 从而对本文算法的性能做进一步分析. 对比算法为RFS[25],MTDF[26],AM_ADM[27]和HISP_T[28].
用本文算法在测试集MOT16的所有不同视频序列上进行对比实验, 实验结果列于表1. 由表1可见: 本文算法在视频序列MOT16-03上效果最佳, 在视频序列MOT16-14上效果最差, 这是因为MOT16-14背景颜色对比不明显, 且行人目标过小, 导致误差较大, 跟踪效果较差; 视频序列MOT16-03相对背景对比颜色明显, 行人目标大小适宜; 视频序列MOT16-01背景过暗且行人目标有的太小, 导致跟踪效果一般; 视频序列MOT16-06的图像分辨率低, 有镜面成像现象, 且相机晃动影响了最终的跟踪效果; 视频序列MOT16-07和MOT16-08都存在行人目标过小且部分行人目标与背景颜色相似的问题, 从而影响了跟踪效果; 视频序列MOT16-12有过多的镜面成像现象且相机晃动, 从而影响了跟踪结果.

表1 本文算法在测试集MOT16不同序列上的量化跟踪结果
在测试集MOT16上, 将本文算法与RFS,MTDF,AM_ADM,HISP_T算法进行对比实验, 实验结果列于表2. 由表2可见: 本文算法的跟踪准确度为56.5%, 比第二位的RFS算法(准确度为50.9%)高出5.6%; 本文算法的MT为20.4%, 是5种算法中的最高值, 比第二位的RFS算法(MT为16.7%)高出3.7%; 且本文算法在数据集MOT16中的误检和漏检数目为2 740个和75 925个, 其标签切换总数为610, 是5种算法中最少的, 从而证明了本文算法有良好的跟踪准确度且可有效解决目标被遮挡问题的轨迹丢失问题及标签切换问题.

表2 不同算法在数据集MOT16上的量化跟踪结果对比
为更直观展现本文算法在处理遮挡问题时的优势, 在视频序列MOT16-01和MOT16-06上使用本文算法与RFS,MTDF,AM_ADM,HISP_T算法进行对比实验, 其中遮挡效果截图如图7所示, 连续遮挡效果如图8所示.

图7 不同算法在目标被遮挡情形下的跟踪效果Fig.7 Tracking effect of different algorithms in the case of target occlusion

图8 不同算法在目标被连续遮挡情形下的跟踪效果Fig.8 Tracking effect of different algorithms in the case of target continuous occlusion
图7中第一行为第176帧目标被遮挡发生前, 第二行为第186帧目标被遮挡正在发生, 第三行为第200帧目标被遮挡已结束. 由图7可见, 本文算法在目标被遮挡前后可准确地跟踪到行人目标且不发生标签交换; RFS,MTDF,AM_ADM,HISP_T算法在这3帧图像中都框选到了行人目标, 但都存在遮挡前后行人目标标签交换的问题, 而且HISP_T算法还存在误检现象. 图8中第一行为第311帧目标被遮挡发生前, 第二行为第315帧目标被遮挡第一个行人, 第三行为第318帧目标被遮挡两个行人, 第四行为第326帧目标被遮挡已结束. 由图8可见, 本文算法在目标被遮挡前后可准确地跟踪到行人目标且不发生标签交换; RFS,MTDF,HISP_T算法在这4帧图像中都框选到了行人目标, 但都存在遮挡前后行人目标标签交换的问题, 而AM_ADM算法在第311帧和315帧图像中存在漏检和误检的问题.

图9 不同算法在目标过小时的跟踪效果Fig.9 Tracking effect of different algorithms when targets are too small
为直观展现本文算法在处理目标过小问题时的优势, 在视频序列MOT16-07和MOT16-14上进行不同算法处理效果的对比分析, 实验结果如图9所示. 图9中第一行为视频序列MOT16-07中第290帧, 由图9可见, 本文算法和AM_ADM算法各检测出一个小目标, 但AM_ADM算法和其他算法都存在漏检问题, 而且MTDF算法还存在误检问题; 图9中第二行为视频序列MOT16-14中第269帧, 由图9可见, RFS和HISP_T算法都漏检了两个目标, MTDF和AM_ADM算法都漏检了一个小目标, 而且AM_ADM算法还误检了两个目标.
实验结果表明, 本文算法的跟踪准确率比其他对比算法都高, 且在遮挡问题上有较好的跟踪结果, 能有效缓解目标标签交换问题, 且对小目标的跟踪也有一定效果.
综上所述, 本文使用YOLOv4进行行人多目标检测, 在保证检测精度的同时, 实现了实时检测. 使用YOLOv4检测到跟踪目标后, 通过扩展Kalman滤波器预测下一帧目标的位置, 以此获得当前帧的先验假设, 在获得检测和预测结果后, 计算两者的交并比, 并用级联匹配方法将扩展Kalman滤波预测的检测框与目标检测的检测框进行匹配, 然后用匈牙利算法找到最佳匹配, 同时针对发生遮挡的目标加入轨迹异常修正算法, 即根据跟踪框的高度和宽度与其中心坐标对比, 更新目标的中心坐标, 从而达到轨迹异常修正的目的. 实验结果表明, 本文算法在数据集MOT16上进行目标跟踪达到了56.5%的准确度, 且减少了目标标签交换次数.
