基于多维度数据挖掘的自学习故障根因定位系统
2021-09-22郭正郭宁黄蕴思
郭正 郭宁 黄蕴思
(中国移动通信集团广东有限公司 广东省广州市 510000)
1 概述
随着云计算的深入发展和IT技术架构的大变革,企业数字化转型(云化)已经步入深水区。例如,政务云可以为政府行业提供基础设施、软件支持等功能[1];工业云可以为企业提供工业软件、知识库等云服务[2];金融云为银行、证券、保险等机构提供服务,用来承载应用和高并发业务[3]。
在开展业务系统云化、容器化的过程中,产生了很多新的运维痛点,最典型的痛点是故障定位[4]。在云计算中会大规模地共享计算资源,尽管单个计算节点的可靠性可以达到很高,但是当计算节点的规模很大时,不可避免地会经常出现计算节点故障的问题。这将带来如下运维痛点现象:告警量大,告警处理工作激增;故障定位大部分依赖人工,对人员的专业水平要求较高,时效性得不到保障。因此,对故障发生的根因进行自动化的分析就显得非常具有价值。
实际上,系统故障定位是有迹可循的。云应用系统的网元组件通过相互协作正常运行,当系统发生故障时,系统下的网元内部的某些性能指标同样会发生异常。使用异常检测、固定阈值等方法对系统内部网元下的性能指标进行监测,以告警的方式将各种性能指标异常变化反映出来。可以使用系统一段时间的历史指标异常告警数据,基于历史告警数据,采用关联规则FP-growth算法分析告警事件之间的关联关系,判断同时出现的概率,以此分析出当前系统下某些网元的某些指标发生异常告警,是另外一些网元的异常告警的根本原因[5-10,13-15]。
本论文设计了一个基于多维度数据挖掘的自学习故障根因定位系统。该系统注意到组件和主机之间存在部署环境依赖的关系。这些关系构成了一个系统复杂的网络拓扑结构图,当系统内部某些组件出现故障时,从调用关系上观察会看到存在调用依赖关系的上游组件也表现出异常,从时间上观察会看到在短时间内产生大量告警。因此,该系统以系统拓扑结构、告警时间这两个维度为切入口,以系统历史故障告警为基础数据。基于历史告警数据,使用机器学习相关性分析算法,分析出存在传导关系的故障告警规则。 然后告知运维人员对这些规则进行关系确认和人工标记,借助XGBoost算法[11]学习扩展规则库,最后通过知识图谱实现根因定位,降低故障排障时间成本。
2 基于多维度数据挖掘的自学习故障根因检测系统
2.1 系统和数据集介绍
本论文研究的应用系统来自于数据中心的实际运维场景,其基本组成单位称为网元,网元之间相互协作以对外提供特定的功能。如图1所示,代理服务器1和2(简称haproxy1、haproxy2)、web服务器(简称webcore1、webcore2、webcore3)、数据库服务器(Mysql、Redis1)、主 机1到4(简 称(Host1、Host2、Host3、Host4)均为网元。由此可见,不同的网元实现不同的功能,网元可以进一步分为应用系统和实际物理系统,例如haproxy1、haproxy2、webcore1、webcore2、webcore3、Mysql、Redis1是提供某种特定功能的软件系统,Host1、Host2、Host3、Host4是物理机器。

图1:网元关系
网元之间的关系可以分为网元的调用关系(又称网络调用拓扑关系)和部署关系。图1(a)给出了一个网元调用关系的拓扑图的例子,例如Webcore3调用了Redis缓存组件,那么它们之间就画一条边表示它们之间存在调用关系,每一个调用关系由源网元id、目标网元id、具体网元调用关系等内容构成。网元的部署关系描述了网元之间的部署位置之间的关系,如图1(b)所示,如果Mysql部署在主机4上,则在Mysql和主机4之间画一条边表示它们之间的部署关系。
在系统运维中,通过监测软件对网元进行监控并上报的各项性能数据,这些性能数据也称为指标,监控系统按照一定的时间周期、数据格式对网元的各项指标进行采集上报,指标可以反映网元在某个时间节点的状态。系统故障会导致指标异常,如果指标异常超过某个阈值或者不符合某个固定规则时,该指标会触发告警。
问题的难点在于:在正常情况下,由于业务的随机性会导致多个指标发生异常报警;在于当一个故障发生的时候,会导致这个组件以及与这个组件有调用关系的组件上的众多指标发生异常。如何识别是否有故障发生以及故障发生了如何定位到导致故障的原因。本论文研究基于告警信息和指标历史数据的根因分析和故障定位[12]。
本论文使用的告警信息格式如表1所示。这个表的不同列分别表示告警时间、告警指标、 网元对象id、告警类型、告警内容等字段。其中告警类型表示告警发生的网元的类型是主机或软件实例。

表1:告警数据格式
2.2 系统整体结构
如图2所示,定位系统由告警知识图谱和根因定位两部分构成,图2(a)给出了告警知识图谱构建的过程,首先对训练数据集进行提取和构建,然后采用FP-Growth从告警数据集合中发现相关的告警规则,再通过人工经验标注样本训练XGBoost有监督学习模型自动扩张告警规则,最后根据前面步骤得到的告警对构建告警知识图谱。根因定位部分如图2(b)所示,接收到告警数据后,首先把告警数据入库,然后从知识图谱上获得告警子树,并根据得到的告警子树实现根因定位。
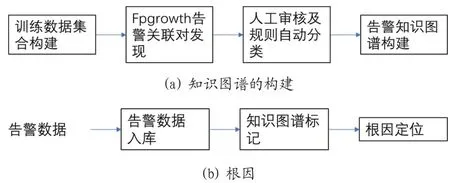
图2:系统整体结构
2.3 训练数据集的构建
本节构建用于后续FP-Growth的告警数据集合。本节的目的是尽可能的把相关的告警数据分类到相同的数据集合中,便于FPGrowth发现关联告警,进而形成具有因果关系的知识图谱。如前所述,故障可能导致告警信号沿着两个维度传播:沿着具有调用关系的网元拓扑传播和沿着时间轴传播。同样地,告警训练集合的构建也应该沿着这两个方向进行构建:基于拓扑的训练数据集的构建;基于时间的训练数据集的构建。前者适用于能够获得拓扑关系和部署关系的场景,后者则适用于一般的场景。
2.3.1 基于拓扑的训练数据集的构建
首先,根据如图1(a)所示的系统拓扑关系对数据和图1(b)所示的部署关系对,获得所有的可能的调用关系对和部署关系对。不失一般性,称一个关系对中的两个网元分别为A和B。
遍历每一个关系对,对于每一个关系对产生一个告警训练数据集合,细节如下:从历史告警数据集合中过滤出从现在开始计算的一个时间窗口内包括有A或者B网元ID的告警记录。然后把这些包括有A或者B网元ID的告警记录并入到训练数据集合。时间窗口是算法的一个参数,本文的时间窗口是一个月。例如在图1(a)中haproxy1和webcore1存在调用关系,则从历史数据中过滤出最近一个月内包含有haproxy1或者webcore1的告警信息,并把这些告警并入到训练数据集合中。
然后,进行告警集合过滤。由上一步可以产生很多训练数据集合,每一个集合中包括了对应具有调用关系的两个网元的所有指标的告警信息。同一个集合中的不同指标之间的可能存在因果关系,也可能不存在因果关系。为了便于后续因果关系的挖掘,需要把那些互相之间不存在因果关系的指标过滤掉。对于每一个训练数据集合,执行如下步骤:
步骤1:统计得到该集合内告警总数量。
步骤2:按照网元、告警指标两个维度对集合进行划分,每一个划分成为一个类别。
步骤3:用告警总数量除以类别数目,得到平均告警数量。
步骤4:对每一个类别进行如下判断:如果该类别的告警数量小于平均告警数量,则认为该类别的告警对于故障定位没有意义,则把该类别中的告警从训练数据集合中删除。
2.3.2 基于时间方式的训练数据集的构建
当无法获得如图1所示的调用和部署关系图时,则采用基于时间的训练数据集的构建方式。对于每一个训练数据集合,执行如下步骤:
步骤1:从历史记录中获取最近一天的历史告警数据,该集合中包括所有网元的所有指标,把该集合作为训练数据集合。然后执行2.3.1节中的步骤1-4,对训练数据集进行过滤。
步骤2:获取历史一个月告警数据集合,重复2.3.1节中的步骤1-4,把2.3.1节中的步骤4得到的需要过滤的网元、指标列表,从本节步骤1得到的训练集合中过滤掉出现在该列表中的告警。
2.4 FP-Growth算法告警指标相关性分析
将2.2节获得的训练数据集合输入至FP-growth算法当中,通过FP-growth算法发现具有强关联性的告警指标组,并给出告警指标组的可信度度量。
具体步骤如下:
步骤1:按照时间维度将训练数据集合分为不同的项集。项集即频繁项集中的购物篮,每一个告警消息相当于购物篮模型中的商品。本文采用2分钟的时间间隔对训练数据集合进行划分,每一个划分是一个项集。采用2分钟间隔的原因如下:从业务层面解释来看,单个告警发生基本上会在2分钟之内影响其它指标。
步骤2:使用FP-growth算法对以上数据进行频繁项挖掘。在本文中,结合实际运维领域知识,将项集的大小限制为2,即仅分析指标A—>B之间的关联关系,以减少计算复杂度。
步骤3:根据置信度和提升度对规则进行过滤。基于实际运维业务经验,本文仅保留置信度大于0.9且提升度大于1的规则,删去其它规则。
最终,FP-growth算法输出的关联规则样式如表2所示。

表2:FP-Growth算法输出数据示例
2.5 人工审核及自动规则标记
FP-growth算法得到的规则存在如下问题:由于噪声的影响,可能有的规则在业务逻辑上不正确;其次,可能输出的规则与实际故障经验传导关系方向相反;规则的数量有限。
针对前两个问题,采用人工审核的方法对规则进行审核并做标记。即将FP-growth算法输出的告警指标相关性规则列表,交由运维人员进行标记,对于符合运维人员经验的规则,标记为1,反之标记为0。
对于输出的规则与实际故障经验传导关系方向相反,例如(对象1+指标A—>对象1+指标B, 1)方向相反,则调整规则的传导关系方向,可得(对象1+指标B—>对象1+指标A, 1)。
对于规则数量有限这个问题,则采用如下方法解决:人工审核后的规则本身即可作为后续系统故障产生后告警合并于根因分析的依据,但系统下告警分析出来的规则是慢慢积累,并非一蹴而就的。对于某些规则来说在相同的场景但不同的网元上是通用的,例如Host1 下的磁盘读写速度延迟高导致Host1下CPU使用率高这个规则对于Host2也是适用的。但是有可能Host1的规则生成过一段时间内Host2规则才会产生。为了缩短规则的产生时间和节约人工打标的工作量,本文采用有监督的分类算法实现规则的自动标记。
具体来说,本文采用XGBoost实现有监督学习的分类。在训练阶段,把经过人工审核的规则及标记结果输入到XGBoost训练模型,在预测阶段,输入的格式规则如表2所示,XGBoost输出该规则是否成立。
2.6 根因规则知识图谱的构建
在2.5节获得规则列表后,需构建用于根因定位的根因规则知识图谱,具体方法如下:以告警指标作为图的节点,如果两个规则告警指标之间存在规则,则在对应的两个节点之间增加一个连边,例如,如果存在如下规则:(Host1,告警指标A)—> (Host1,告警指标B),则FD(Host1,告警指标A),(Host1,告警指标B)作为图中的两个节点v1和v2,并从v1向节点v2增加一条有向边。最终得到树形结构的知识图谱,如图3所示。
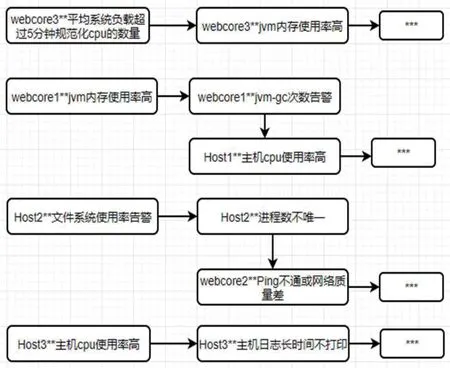
图3:根因规则知识图谱结构
2.7 根因定位
当系统故障时,获取从故障时刻点起半个小时之内的告警数据。然后,对每一个发生的告警,在2.6节获得的知识图谱树中标记该告警对应的节点。如果这些标记的节点构成一个树,这颗树的根节点就是根因。如果得到多个树,就存在多个根因。
3 实验结果
3.1 实验数据集
有部署关系的原始告警数据集(一共33242条原始告警,详情见附件:./data/有部署关系-原始告警.csv)
无部署关系的原始告警数据集(一共33018 条原始告警,详情见附件::./data/有部署关系-原始告警.csv)
3.2 实验流程
(1)对原始告警数据基于时间段(n-min)进行分片处理;
(2)将每个桶内的告警进行去重处理得到关联规则算法的基础项集;
(3)配置支持度、置信度、提升度等过滤关联规则的指标,配置(最小支持度阈值minSupport:0.01,最小置信度阈值minConfidence:0.9,最小提升度阈值minLift:1)如果输出的关联规则均满足上述要求,则认为该规则具有较高的可信度和有效度;
(4)将第2步骤的基础项集数据和第3步骤配置的过滤阈值参数输入关联规则算法,输出关联规则结果集,关联规则形式如: (实例类**webcore1**jvm内存使用率高 —>实例类**webcore1**jvmgc次数告警, 置信度:1,提升度:8.89);
(5)对实验得到的上述关联规结果集则进行人工标注,校验每条规则是否符合运维经验知识,计算以下参数下的Precision、Recall、F1值。

(6)针对时间切片单位n-min中的n-min分别采取 [1min,2min,5min,10min] 不同的值,重复整个实验,得到 [1min,2min,5min,10min]四种不同实验条件下的关联规则结果的Precision、Recall、F1值。
3.3 实验结果
表3、表4分别为对有部署关系和无部署关系的历史告警数据在控制件条件(最小支持度阈值minSupport:0.01,最小置信度阈值minConfidence:0.9,最小提升度阈值minLift:1))下,采用[1min,2min,5min,10min]不同的时间切片进行关联规则分析,并对产生的关联规则进行效果验证的结果。

表3:有部署关系的实验结果

表4:无部署关系的实验结果
把关联规则集合A中的规则数记为n,其中符合运维专家经验的规则数记为m1,历史告警数据中实际包含的正确有效的规则数记为m2。
Precision为关联规则集合A中符合运维专家经验的规则数的占比,计算如下:
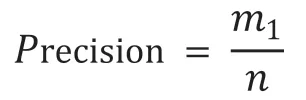
Recall为符合运维专家经验的规则数在历史告警数据中实际全部有效规则数的占比,计算如下:
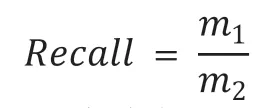
F1为结合Precision和Recall评估指标的综合评价指标,计算如下:
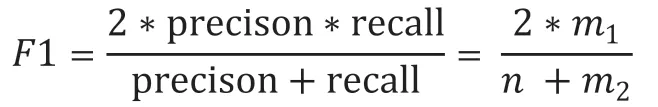
实验结果最终采取综合的评估指标F1值最优,以及如果F1一致,则才取n-min最小的原则,对[1min,2min,5min,10min]不同的时间切片下的结果进行对比发现有部署关系和无部署关系情况下的历史告警数据,取得最优的结果的都是采用2min的时间段进行切片,可以解释为一般的原因告警事件会在2min内引发结果告警事件的发生,符合实际运维场景中的经验知识。
4 结束语
随着云计算的深入发展和IT技术架构的大变革,越来越多的企业开始了数字化转型,开启了“云服务”的时代,但与此同时也涌现了许多运维痛点。本文设计并实现了一种基于多维数据挖掘的自学习故障根因检测系统,包括根因规则知识图谱的构建过程和故障根因的预测分析过程。通过该系统可以实现多维度自动提取运维知识、沉淀专家规则、自动对学习到的规则进行打标以及对新来的告警进行故障根因的预测。使用的架构具备通用性,根因规则输出模型和自动打标模型可以持续训练,为运维工作提高效率的同时也大幅减小了成本。
