面向SWF日志事件流数据的可视分析系统
2021-09-17李玥杨波芦旭熠单桂华
李玥,杨波,芦旭熠,2,单桂华*
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
引言
事件日志是分析计算机系统在操作、调度等阶段可靠性行为的主要数据源之一。在高性能计算机中,大量的系统日志提供了关于系统状态、性能和资源利用的宝贵信息,对系统日志的有效分析可帮助研究人员获取集群工作状态、用户提交行为、作业处理模式等信息,并对集群调度优化做出决策。但是,由于高性能计算机事件日志复杂性高、产生速度快、单条记录维度高,因此对事件日志的交互式可视分析是一个重大的挑战。
时间事件序列数据(Temporal Event Sequence Data)指的是在一段时间内按照时间先后顺序发生的一系列离散事件[1]。近年来,数据可视化技术被广泛地应用于呈现、分析和探索时间事件序列数据,通过序列简化与整合得到序列的演化模式、发展趋势和事件相关关系等,现已有许多可视分析工作对电子医疗病例、用户网络行为、商品生产过程等领域进行分析[2-4]。高性能计算机的事件日志也可视为时间事件序列数据,针对计算机事件日志的特点对时间事件序列数据的可视分析技术进行优化,可以帮助研究人员高效分析高性能计算集群的工作模式,优化集群调度。
本文以高性能计算集群的SWF 格式事件日志的可视分析过程为研究对象,通过数据建模、可视化系统设计、案例分析,探索了用户以交互式可视分析的手段研究日志序列数据的整体流程。首先,对SWF 数据进行建模,模型包括了数据中的事件流时序分析、批量作业的多维属性分析两部分,总结出了分析者对集群中作业调度的整体把握、细节观察、模式发现等主要分析需求。其次,综合考虑到用户交互的简单易用性、关联分析习惯等,设计并实现了一个SWF日志事件流可视分析系统SWFVis。并支持游标卡尺的无级调节交互,鼠标拖拽视角调节、鼠标滚轮缩放等用户友好型交互。在案例分析中,以公开的iPSC/860 与ForHLR II 集群产生的真实数据为例,分析了两个不同集群在作业处理、用户提交行为上的差异性,针对可视化效果中存在的作业聚集状态进行了多维度深入分析,总结了上述聚集模式的成因。最后,本文探讨了整体研究的优缺点以及系统有待改进之处。
1 相关工作
1.1 高性能计算系统日志分析
高性能计算(High Performance Computing,HPC)系统是由大量组件构成的,系统的不同层次、位置的硬件和软件产生了关于系统状态、资源使用和用户应用程序运行等各种类型的日志数据,描述了系统的不同方面。尽管日志数据是从不同的角度单独生成的,但是将它们进行融合和关联就可以提供系统的整体视图,从而促进有效的故障检测、错误传播跟踪和系统可靠性评估[5]。近年来,越来越多的工作对大型系统的日志进行事后分析,评估系统的可靠性,提取系统错误和故障的统计特性。Gupta等人[6]对ORNL 的5 代超级计算机进行了日志分析,研究了平均失败间隔时间(MTBF)和故障的时间和空间特征。该工作对系统日志进行了详细的数据分析,但是并没有提供可用的系统界面,以支持可视分析与交互操作。Li 等人[7]提出了一个集成的日志分析平台FLAP,用于端到端分析和系统管理。该工作运用了数据挖掘、机器学习和信息检索等技术,加速了事件分析过程。Park 等人[8]介绍了用于HPC日志的大数据处理框架LogSCAN,该框架利用可扩展的Cassandra 数据库集群存储日志数据,通过Apache Spark 进行高效检索,用于进一步的数据分析。但是该工作更关注系统中事件发生的时间和所在应用程序的位置,缺少对日志全面的统计分析。此外,这些工作更多的关注大规模日志数据的存储、分类和计算,但是无法使工作人员直观的了解日志中目标实体的状态、执行情况等,没有为事后分析过程提供有效的指导。为了简化工作负载日志和模型的使用,Dror Feitelson 等人定义了标准工作负载格式(Standard Workload Format,SWF)[9],SWF 数据使得分析工作负载或模拟系统调度的程序只需解析单一格式,并且可以应用于多个工作负载。
1.2 时间事件序列数据可视化
时间事件序列数据描述了用户或系统在一段时间内的行为和操作,通常由一个或多个记录构成,每个记录由一组带有时间戳的事件类别组成。由于事件序列数据规模通常较大、事件类型繁多、发生时间动态多变,在大量事件序列数据中发现潜在规律十分困难。
近年来,数据可视化技术被广泛地应用于呈现、分析和探索时间事件序列数据,对时间事件序列数据的可视分析主要可分为基于 GanttChart、基于Flow、基于 StoryLines 及基于矩阵的可视化这4 种方法[10]。GanttChart 使用条状图展示事件序列数据的总体时序特征和详细信息,以及事件之间的相关性。Huang 等人[11]在一个视图中对两个GanttChart 进行编码,通过重叠它们对小型序列图比较分析,并提出TbarView 用于对多个大型GanttChart 的比较分析;TipoVis[12]采用排序策略和覆盖策略改进GanttChart,并将其运用到对自闭症儿童的社交和交流行为模式的分析中。这些工作通过改进传统的GanttChart,在一定程度上可以满足较大数据量的可视化需求;但是对于时间跨度较大、时间类别较多、数据记录较多的长序列数据,GanttChart 的可延展性仍会受到限制。
基于Flow 的方法以流的形式将事件序列沿着一条横向的时间轴排列[13]。LifeFlow[14]根据对齐点将事件序列进行对齐,不仅提供了所有事件序列的概述,还呈现了它们发生的频繁程度和事件之间时间间隔的总结信息;EventFlow[2]在 LifeFlow 的基础上,提出了有针对性的简化技术,使用户能够精确地将复杂的时间事件数据集缩减为关键视觉元素,从而获取简化的事件序列数据;OutFlow[15-16]将多个相似的事件序列及其结果聚合成基于图的可视表示,有效地减少了序列模式的多样性,并提出多步骤布局过程,减少图中交叉边并拉直不必要的弯曲边,防止重叠。与GanttChart 相比,基于Flow 的方法简化了数据的可视化呈现,更能突出数据高层次的总结性和概览性信息;但是针对一些长的事件序列,其处理能力还是非常有限,需要应用更多的简化策略。
基于StoryLines 的方法用线表示实体,横轴编码时间,纵轴表示实体间的相似性[17],用于探索大量实体之间的动态关系和交互模式随时间的变化情况。Ogawa 等[18]提出 StoryLines,用于可视化分析软件项目开发中开发人员之间的交互情况。由于实体过多会引起视觉混乱,许多优化的布局算法被提出[19-20],来提高StoryLines 的易读性和美观性。基于StoryLines 的方法更节省屏幕空间,可容纳更多的实体;然而,StoryLines 主要用于实体间的关系分析,无法应用于对序列模式的分析中,因此StoryLines的相关运用并不是十分广泛。
基于矩阵的方法利用基于矩阵的图标来展示、比较和分析多个时间事件序列之间的关联。Perer[21]等人提出MatrixFlow,以患者的临床事件序列数据构建时间演化网络,并利用邻接矩阵将其可视化为一个时间矩阵流;MatrixWave[22]将事件之间的转移关系用一个转移矩阵表示,并采用“之”字形布局方法把矩阵按照访问时间先后连接起来;EventThread[1]基于张量分析将事件序列聚类为线程,并将线程按相似性分组为特定时间的集群,构造线程阶段矩阵来可视化潜在阶段类别和演化模式。相比于基于Flow 的方法,基于矩阵的方法能够有效展示大规模且密集的事件序列数据;但是考虑到美观性和用户接受程度,基于矩阵的方法常常与基于Flow 的方法相结合,并不经常单独使用。
2 系统设计
2.1 数据特征与需求分析
SWF 数据描述了高性能计算集群中作业的历史记录,内容包括每个作业的多维属性、时序关系、调度情况等。数据中存在的基础实体关系为典型的二分图结构,如图1所示。
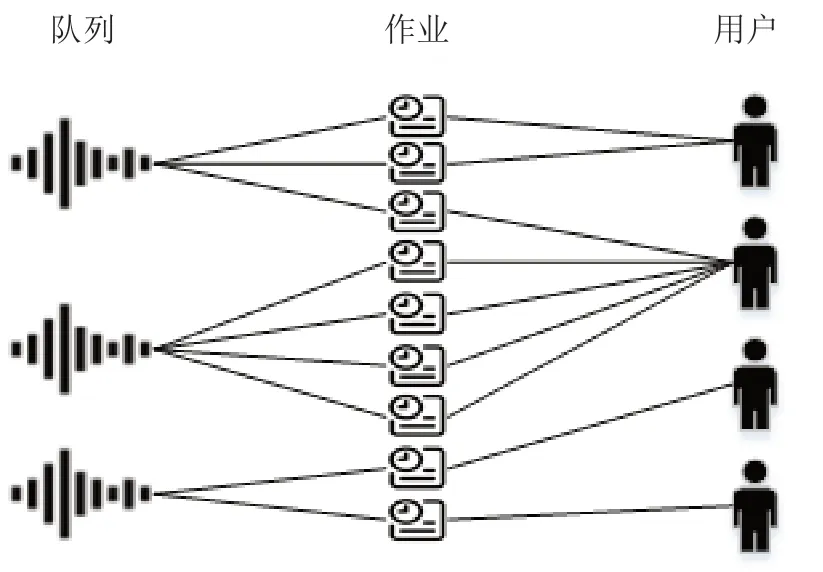
图1 日志数据实体关系Fig.1 The relationships of logging data
用户与队列实体之间存在多对多的关联关系,每一条关联边代表一个作业,构成的整体关系网络体现了用户的提交行为与集群的调度状态。因此,对事件流数据进行分析时,既需要从用户实体出发探索用户作业的提交模式,又需要从队列实体出发探索集群的作业调度方法。
SWF 数据同时具备多维属性,每一条作业信息中,除了包含必要的开始时间、结束时间、等待时间等时序属性外,还具备运算核数、平均CPU 时间、内存占用等共15 个数据维度1https://www.cs.huji.ac.il/labs/parallel/workload/swf.html。因此通过SWF 文件对集群事件流进行分析时,往往需要考虑其他维度对事件流中的调度行为产生的影响。
综合上述数据特征,确定了如下可视分析需求:
(1)以直观的方式展示事件流中作业的并发状态、执行情况,从用户视角观察用户的提交习惯,从集群视角观察作业的调度分配。
(2)发现事件流中的作业行为模式。并通过对作业多维属性状态进行分析,获取影响作业行为模式的关键维度。
2.2 可视化流程
SWF 可视分析系统整体流程如图2所示。整体包括三个阶段:数据获取与解析阶段,包括数据获取模块、数据解析模块、数据输出模块、算法模块;可视化映射阶段,包括可视化映射模块、可视化模块;可视化交互与反馈阶段,包括可视化交互模块。各个阶段的功能如下:
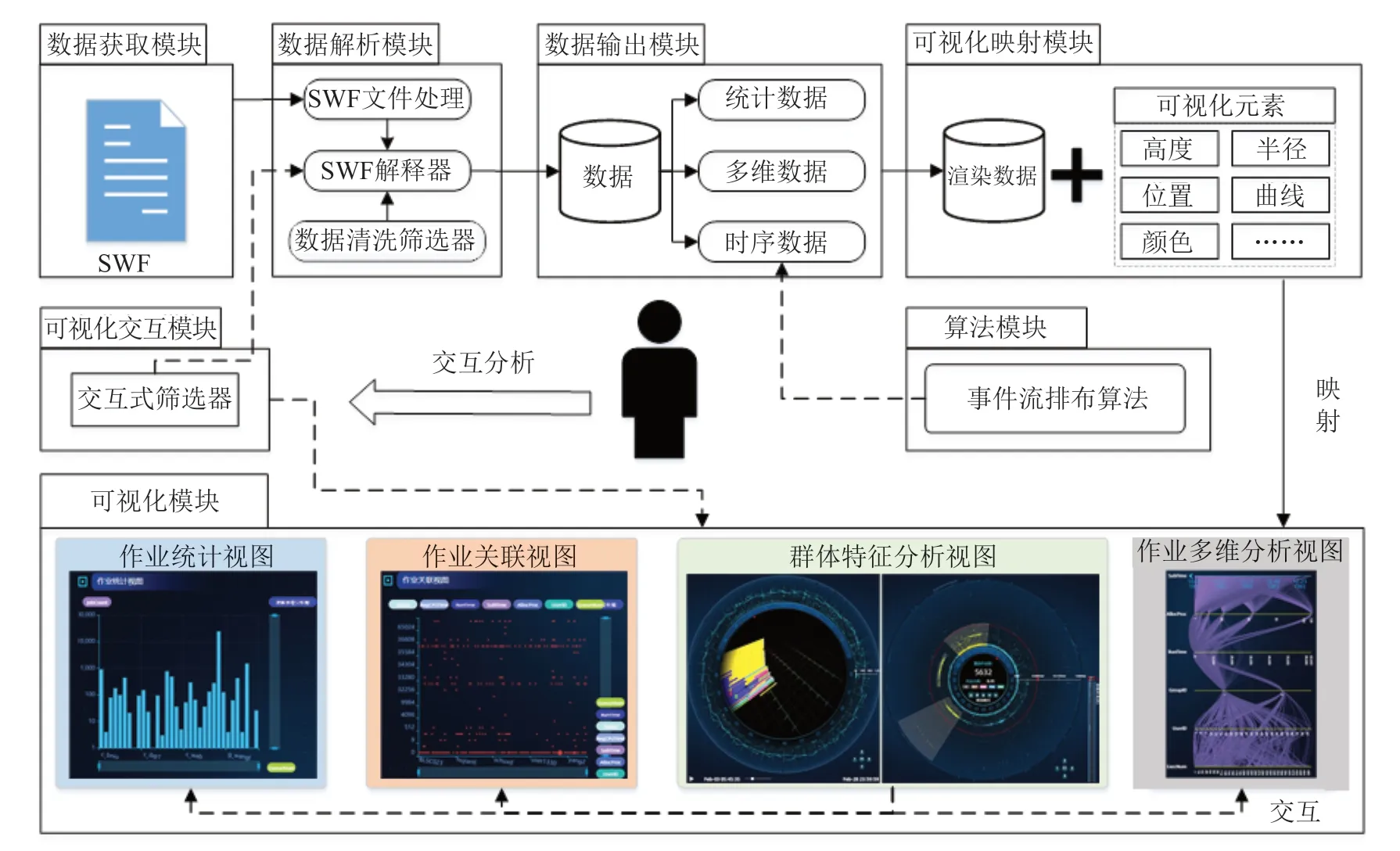
图2 可视化流程Fig.2 Visual process
(1)在数据获取与解析阶段,主要工作为SWF数据的提取与转换。SWF 原始数据为纯文本格式,因此需要将SWF 文件中的数据进行提取与解构,并对数据中存在的时序、维度特征进行针对性的建模。首先,通过数据获取模块接收用户上传的标准SWF格式文件,将SWF 文件发送至文件处理组件,在文件缓存区放置初步解析后的SWF 数据;第二步,数据解析模块中,数据会传入SWF 解释器,该解释器会对SWF 文件内容进行深入解析:包括文本内容分块,多个数据维度的构建,队列、用户、节点信息的提取等一系列操作。其中数据清洗筛选器用于将SWF 文件记录中维度全部为“-1”值(SWF 文件中将无数据项填充为“-1”)或“-1”值在该维度中的占比高于设置的筛选阈值的数据列进行剔除。SWF解释器完成数据清洗操作后,无效的维度会被清除,有效维度中少量“-1”值会被保留,以用于对数据缺失状态进行标记;最后,数据输出模块会针对性的缓存并输出三类数据:具有时序信息的序列化数据,具有多维属性的矩阵数据,以及各个有效维度的统计结果。
(2)在可视化映射阶段,主要的工作为将前一阶段获取的数据转换为可用于可视化视图渲染的数据,将属性值映射为对应视图中可视化元素的高度、半径、位置、曲线、颜色等信息。通过可视化映射模块,将时序数据、高维数据、统计数据根据各自可视化视图所需的格式进行转换,生成与可视化视图约定格式相同的JSON 数据。事件流排布算法提供了将时序数据转换为堆叠事件流图的方法。
事件流排布算法用于接收多维属性的事件流数据,并生成数据中每个作业在三维空间中的位置信息,包括自身开始结束位置、队列中的位置、并行状态时的高度位置等。
(3)在可视化交互与反馈阶段,通过可视化模块中的作业统计、作业关联、群体特征分析和作业多维分析视图帮助用户发现数据中存在的模式与特征,通过用户友好的交互方式对用户发现的特征集群进行深入分析,以获得有价值的结论。可视化交互模块提供了视图自身交互与多视图关联交互等手段,并支持鼠标的点选、拖拽、区域选择等一系列自然操作。交互操作会将交互信息回传至交互式筛选器,并驱动SWF 解释器根据交互需求提取满足条件的数据,实时渲染刷新。
3 可视化设计
SWF日志事件流可视化系统将SWF日志事件流数据与可视化图形相结合,通过多视图联动进行可视分析。根据前述可视化需求及系统分析流程,为了将多维度的日志事件流数据直观展示出来,同时挖掘出数据中蕴含的信息,提供了日志事件流数据的可视化和交互可视分析原型系统(如图3所示)。

图3 原型系统界面概览图。(A)作业统计视图,(B)作业关联视图,(C)三维事件流可视化视图,(D)文件基本信息概览视图,(E)作业多维分析视图,(F)24 小时周期作业特征分析散点图。Fig.3 Prototype system interface overview.(A)is job statistics view,(B)is job correlation view,(C)is 3D event flow visualization view,(D)is swf file basic information overview,(E)is job multi-dimension parallel view,(F)is 24 hours scatter diagram for job distribution analysis.
3.1 作业统计视图
该视图用于展示某一维度下作业统计量的分布状态。如图 4(A)所示,纵轴代表作业数量(jobCount),横轴代表作业的提交时间(SubTime),当前柱状图代表了作业的提交时间数量统计。分析者可以点击横轴图标(a),切换为可用的其他维度,例如队列(QuneeNum)、作业运行时间(RunTime)、平均CPU 使用时长(AvqCPUTime)、使用核数(AllocProc)、用户(UserID)和作业状态(Status)等。通过鼠标滚轮或者对横纵轴的范围选择组件(b)进行拖拽,分析者可以对视图中焦点区域(B)进行数据缩放,以进行进一步的数据聚焦。通过点击刷新按钮(c)可以将数据聚焦后的作业集合刷新到作业多维分析视图(图3 E)中,用于观察数据的完整信息并实现可视化对比。

图4 作业统计视图。(A)切换不同维度并展示该维度下的作业数量统计,(B)数据聚焦与更新。Fig.4 Job statistics view.(A)switch different dimensions and display the job statistics,(B)data focus and update.
3.2 作业关联视图
该视图用于分析作业在两个维度之间的关联关系。如图5所示,横轴和纵轴分别代表作业的两个维度,分析者可以通过点击各自的图标(a)和(b)进行切换,以进行任意两个维度的关联性分析。分析者可以通过图中散点的分布判断两个维度之间是否存在明显的关联关系(例如正比或反比),图中散点的大小表示作业数量的多少。与作业统计视图相似,支持数据的缩放以及与多维分析视图间的交互分析。

图5 作业关联视图Fig.5 Job correlation view
3.3 作业特征分析视图
该视图提供对日志事件流中的全体作业生命周期的时序三维显示、二维集群作业分布状态分析与圈选交互。视图整体采用概览圆环视图、三维事件流视图结合交互的方式进行数据可视分析。
三维事件流视图:如图 6所示,概览圆环内部采用三维事件流视图(A)。受到midi 音乐可视化效果的启发2http://www.georgeandjonathan.com,在三维场景中,每个横向延伸的柱体代表一个作业正在执行,柱体的长度在场景中代表执行的时间,柱体的颜色代表提交该作业的用户,可以看到不同的颜色强化了使用者对不同用户的分辨能力。三维场景中不同的纵深代表不同用户(或可切换为集群中不同队列)在整个日志周期中的完整作业提交、执行行为。视图中柱体向空间上方大量叠加的情况为大量作业在并发执行。分析者可以通过右下方的视野切换按钮(B)调整三维区域的观察视角,共4 种模式:主视图(c)、俯视图(a)、左视图(A)和右视图(b),也可通过鼠标在三维场景中拖拽的方式自由调整视角。点击中间按钮可关闭三维场景。最下方的时间条(C)为当前展示的时间节点(日志记录时间),可以通过点击、拖拽的方式实现播放、暂停、切换精确时间点。

图6 三维事件流视图不同视角展示作业生命周期Fig.6 3D event stream view shows the entire jobs life-cycle from different perspectives.
概览圆环视图:分析者通过点击右下角视野切换按钮(图 6 B)中心的缩放按钮,可以在三维事件流视图与二维概览圆环视图(图 7)之间进行切换。在二维场景下,圆环的一周代表一天的24 小时,24小时按照日出日落时间由暗到亮进行颜色映射。圆环区域中每个点代表日志记录中的一个作业,该点在极坐标系下的角度值代表作业的提交时间,点的半径值代表作业的持续时间,即点从内环边界向外环边界发散的距离。例如,图 7 a所示,当前蓝色点表示16 点提交的一个作业,持续时间为2.6 小时。
游标卡尺无级调节交互:在概览圆环视图中,设置了两个互相垂直的时间调整比例尺,用于模拟游标卡尺的无级调节交互操作。位于概览圆环内的横向的比例尺(b),提供了对聚焦区域的时间区间进行细粒度无极放大的功能;位于概览圆环右侧的纵向比例尺(c),可以通过鼠标拖拽的方式大范围调节聚焦区域的时间区间。
分析者可通过对游标卡尺进行调整,以分析不同持续时间粒度下的作业状态。如图 7所示,分析者可以通过两种不同粒度对时间进行调整。细粒度调整:当鼠标放置在圆环区域(b)某一位置时,会出现红色圆环,代表选中了持续时间在该时间范畴下的全部作业,鼠标再次点击会将当前红圈包围的范围更新至整个圆环区域,达到细粒度时间调整的作用。粗粒度调整:通过鼠标上下拖拽右侧的(c),可以大范围地更新圆环区域半径代表的作业持续时间映射尺度。

图7 概览圆环视图作业操作。(a)作业散点,(b)、(c)游标卡尺交互区,(d)框选作业数,(e)框选作业颜色映射依据,(f)框选功能区。Fig.7 Jobs operation of job-overview-circle view.(a)is a single job point,(b)and(c)is Interactive area of vernier caliper,(d)is number of selected jobs,(e)is colpr mapping of selected jobs,(f)is function area of selection operation.
圈选分析:分析者在确定了合适的时间映射尺度后,可以通过在任意扇型区域采用鼠标点击拖拽的交互方式绘制自由扇型,用于作业节点的圈选。系统支持绘制多个扇型联合选择,如图 7所示。在中间的框选控件中,上方标签(d)会实时显示选中的作业数量。中间区域(e)提供了对当前选中作业节点簇的初步分类映射。“无”:设置当前作业颜色映射为无;“用户”:设置作业的“用户ID 属性”作为颜色映射;“队列”:设置节点的“队列ID 属性”作为颜色映射;“开始”:设置作业的“开始时间”(时间尺度为天)作为颜色映射;“结束”:设置作业的“结束时间”(时间尺度为天)作为颜色映射。
系统支持框选、清除、回退、查看详情及返回初始状态等操作,如图 7(f)所示。框选(“选”)功能支持分析者在圆环上框选感兴趣的区域,支持多区域选择、区域删除等;清除(“清”)功能可以将框选的区域全部清除;回退(“退”)功能支持分析者在进行多步操作后,可以回退到上一次操作;当分析者选择了感兴趣的区域后,可以通过点击“详”按钮查看相关详情,点击后,作业统计视图、作业关联视图和作业多维分析视图三个视图会同步更新为用户选中的作业数据,以对其进行深度可视分析;点击“初”按钮可以将全部视图还原为初始状态。
3.4 作业多维分析视图
该视图采用平行坐标轴的可视化形式提供了对每一个作业全部维度数据进行展示的功能。如图3(E)所示,视图中每一条线代表一个作业,该作业曲线与每一个平行轴相交的位置为该作业在此维度的值。分析者可以通过在一个或多个轴上刷选区间的方式逐步筛选满足条件的作业信息。默认状态下,显示框选作业的多维属性信息。当分析者在作业统计视图或作业关联视图进行数据聚焦操作后,点击视图中“更新多维关系图”按钮,如图 4(c),作业多维分析视图会刷新为分析者聚焦的作业集合。
3.5 文件基本信息概览
该视图用于展示SWF 文件中的头部描述信息,如图3(D)所示,主要包括日志开始时间、日志结束时间、日志记录时区、日志作业量统计量、日志核心数统计量等。
4 案例分析
4.1 数据描述
本文选取了两组在互联网公开的真实生产系统中的并行工作负载日志数据:第一份为1993年NASA 数值空气动力学模拟系统部(Numerical Aerodynamic Simulation,NAS)的iPSC/860 集群系统SWF日志数据,数据规模为1.60MB,包含1993年10月1日至12月31日的42 264 个作业。作业内容主要为航空高性能计算,作业以交互式、批处理为主,提供者为Bill Nitzberg3https://www.cs.huji.ac.il/labs/parallel/workload/l_nasa_ipsc/。另一份作业日志为2016年德国卡尔斯鲁厄技术研究所的 ForHLR II集群系统SWF日志数据,数据规模为7.04MB,包含2016年6月1日至2018年1月4日114 335 个作业。提供者Mehmet Soysal4https://www.cs.huji.ac.il/labs/parallel/workload/l_nasa_ipsc/dex.html。两组日志数据年份跨度较大,以更好地对比、展示长时间跨度下集群在作业提交、调度状态的差异。
4.2 作业状态观察
通过对两组不同的数据进行概览观察,可以帮助分析者掌握作业整体呈现的分布趋势,并发现集群的作业调度特性以及用户的作业提交习惯。
在图 8(a)中,可以看到较为明显的分布特征:(1)6:00 至20:00 的作业量相较于其他时段更多,聚集在0-10 分钟区间附近,20:00 至次日04:00 提交的作业分布位置较为靠近圆环外侧,即作业的持续时间相对较长。(2)将作业的持续时间轴缩放至0-5 分钟区间后,如图 8(c)所示,可以观察到大量的散点分布于6:00 至20:00 的扇型区域内。整体来看,散点呈现内环边界位置聚拢,逐渐向外环边界辐射的趋势,并且会在同半径的圆周上呈现均匀分布的状态。

图8 iPSC日志数据中作业的整体分布概览。(a)为作业在24 小时周期的分布,(b)为散点的队列属性分类结果,(c)为调整作业持续刻度轴后散点分布,(d)为每个用户作业提交执行事件流,(e)为队列中作业提交执行事件流。Fig.8 The overall distribution overview of jobs in the IPSC log data.(a)is the distribution of jobs over a 24-hour period,(b)is the queue attribute classification result of the scatter,(c)is the scatter distribution after adjusting the job duration scale axis,(d)is the execution event stream submitted for each user job,and(e)is the execution event stream submitted for the jobs in the queue.
分析上述散点分布特征,本文认为散点在24 小时周期上呈现的昼多夜少分布特性与集群处理任务的模式有关,即集群在6:00 至20:00 接收并处理了大量的并发量少的独立作业,少量的长耗时任务会被安排在20:00 至次日04:00 进行处理。而散点在区域上呈现的均匀分布状态则与用户提交作业的性质有关,即用户一次性提交的作业量小、所需计算时间短、并发程度低。图 8(d)中通过三维事件流图展示了每个用户的作业处理情况,可以看到用户的提交行为整体上呈现随机提交、耗时短、少并发的特性,也佐证了上述结论。
经查询背景信息,iPSC 将周一至周五的6:00至20:00 定为Prime Time,该时间区间执行的作业核心数限制为64。因此集群会在该时间段大量处理算力要求较低、持续时间较短、交互要求较高的任务。其他时间没有作业核心数限制(最高可达128 核),但是会主动杀死交互式作业,保留批处理作业。图 8(e)中通过三维事件流图展示了每个队列的作业处理情况,其中左侧不连续线条为批处理作业工作队列,右侧并发性相对高的队列为交互式作业处理队列。通过鼠标拖拽视角可以看到,两队列的事件流均为不连续状态,但两条队列的间隔空间大部分彼此互补,即由集群Prime Time 与非Prime Time 之间的切换所导致。同时,在图 8(b)中可以看到,黄色散点(属于批处理作业工作队列)与灰色散点(属于交互式作业处理队列)之间分布差异非常明显。该分布类特征同样与集群的上述调度特性有关。
ForHLR II 集群系统相比于iPSC 集群系统提供了更多的节点与高并发计算能力,用户的作业提交与队列中对任务的调度均出现了大量的并发性与连续性。因此,在图9(a)中ForHLR II 系统日志可视化效果呈现出与图 8(a)iPSC 系统不同的特征:

图9 ForHLR II日志数据中作业的整体分布概览。(a)为持续时间在3 天内的作业在24 小时周期的分布,(b)为持续时间在20 分钟内的作业在24 小时周期的分布,(c)为每个用户作业提交执行事件流,(d)为队列中作业提交执行事件流。Fig.9 The overall distribution overview of jobs in the FORHLR II log data.(a)is the distribution of jobs lasting less than 3 days in the 24-hour period,(b)is the distribution of jobs lasting less than 20 minutes in the 24-hour period,(c)is the submission of an execution event stream for each user job,and(d)is the submission of an execution event stream for jobs in the queue.
任务持续时间更长,阶段性更明显。持续时间在1 天以内的作业分布非常密集,且几乎没有持续时间少于20 秒的作业,在1-3 天的持续时间区间内,散点分布的状态呈现波浪式,且逐层递减,持续时间大于3 天的作业分布稀疏,无明显规律。
散点分布出现多种聚类特征。在不断调整持续时间间隔的过程中,作业散点会大量出现射线型、环型、扇型等聚类特征。下一小节会详细分析各类聚类特征。
作业的并发提交与处理成为主流。其一,在用户作业提交行为上呈现的并发性。如图9(c)中所示,大部分用户事件流中出现了作业的堆叠现象,且部分用户某时刻的作业堆积程度很高,与图 8(d)中随机化、扁平化的状态不同。这表示用户会主动将大批量任务同时提交至系统,在系统调度下,作业几乎同时开始处理,且作业持续时间也基本相同。第二,在作业处理上的高并发性。图9(d)中可以看到,ForHLR II 集群系统同样有两个不同的队列,通过阅读背景信息,可知左侧黄色队列为可视化队列,用于处理使用GPU 的可视化任务,右侧紫色队列为标准计算队列,用于处理一般计算任务(与iPSC 系统不同,ForHLR II 集群系统的队列用于区分作业属性而不是算力差异)。与图 8(e)相比,ForHLR II 集群系统的标准计算队列以大量任务的持续并发处理为主。
ForHLR II 集群系统中也具备与iPSC 集群系统同样的分布特性,即散点在24 小时周期上分布同样呈现昼多夜少的特性。在图9(a)中可以看到,整体分布上0:00 到7:00 更稀疏,且该特征在作业持续时间1-3 天阶段和1 小时以内(如图9(b)所示)两个不同阶段较为明显。本文认为可能是由于用户更倾向于在工作时间(8:00-20:00 左右)提交各类任务,而不具备明显特征的任务散点可能是通过脚本进行自动处理,从而在24 小时的周期上呈现连续性。
综合比较ForHLR II 集群与iPSC/860 集群在SWFVis 中的可视化差异表达,可以发现在23年的时间跨度下,高性能集群随着硬件系统的高速发展,用户提交作业行为从低算力短时任务为主变为高算力长期任务为主;队列中作业处理模式从并发量较低变为大量高并发为主;集群算力分配方案从手动管理变为自动分配。体现了明显的时代化差异。
4.3 作业模式发现
在作业高并发处理环境下,作业散点的分布呈现出多种不同的聚类模式,在本文中已发现的聚类特征有射线型、环型与扇型三种。如图3(F)中所示,框选散点簇分布呈射线型,代表同一时间提交了大批量的作业,且作业在集群中持续时间呈现递增的趋势。在图 7(b)中,框选散点簇分布呈现环型与扇型,前者代表在24 小时周期中,簇中作业的提交呈现连续不间断的特性,且作业在集群中的持续时间基本一致;后者代表在一个极端时间间隔内进行了大批量的作业提交,且簇中作业在集群中的持续时间稳定在一个较小的范围内。
选中散点簇后,点击控制面板中的“详”按钮,可以对所选作业的多维属性进行深入分析。下面分别对三类散点簇进行分析。
射线型聚类。对于图3(F)中出现的射线型聚类特征的散点簇,在详细模式下,通过调节作业统计视图x 轴为“SubTime”属性,可以发现作业提交时间集中在2017年12月18日17:38 左右(图10a),作业的提交数量呈现明显的规律性,应为通过脚本自动提交。通过调节作业关联视图x 轴为“SubTime”,y 轴为“WaitTime”,可以发现在17:37 分至17:38 分之间提交的作业在提交时间与等待时间中呈现典型的正相关性,即作业提交的时间越早,等待的时间越少。这应当是导致散点簇出现射线型分布的原因之一。其次,从作业多维分析视图(图 10b)中可以发现ID 为32 的用户提交了全部的批量作业,并且批量作业的处理核心数均为1。通过刷选视图中的“RunTime“轴,显示作业的执行时间,与提交时间无明显的关系,因此可以认为作业簇中每个作业的执行情况大致相同。作业的整体完成时间(等待时间+运行时间)会受到提交时间的影响呈现正相关的趋势,因此呈现出明显的射线型聚类特征。

图10 射线型散点簇多维分析。(a)“提交时间”维度与“等待时间”维度呈现正相关,(b)当前作业集合多维分析结果。Fig.10 multi-dimensional analysis of radio-type scatter clusters.(a)positive correlation between ‘SubTime’ and ‘WaitTime’,(b)the multi-dimensional analysis results.
扇型聚类。该模式可以分为两种情况,第一,节点簇属于一个用户。在详细模式下,通过对作业统计视图、作业关联视图进行细粒度调整,可以发现扇型聚类与射线型聚类呈现极大的相似性:作业统计视图中,作业提交时间集中且规律;作业关联视图中,“SubTime”与“WaitTime”属性之间呈现的正相关性;作业多维分析视图中,与图 10(b)极为相似的线条分布状态。与射线型聚类不同的是,扇型聚类往往时间间隔更长,例如图 11(a)中提交时间的分布区间为2017年11月14日13:22 至13:26 之间,因此导致在散点聚类中出现了可辨识的宽度。在此种情况下,可以将扇型聚类理解为射线型聚类的扩展状态。第二,节点簇由不同的用户作业组成,在此情况下,可以将扇型聚类作为多组用户射线型聚类的合集,代表不同的用户在该时间段做出了相似的行为。
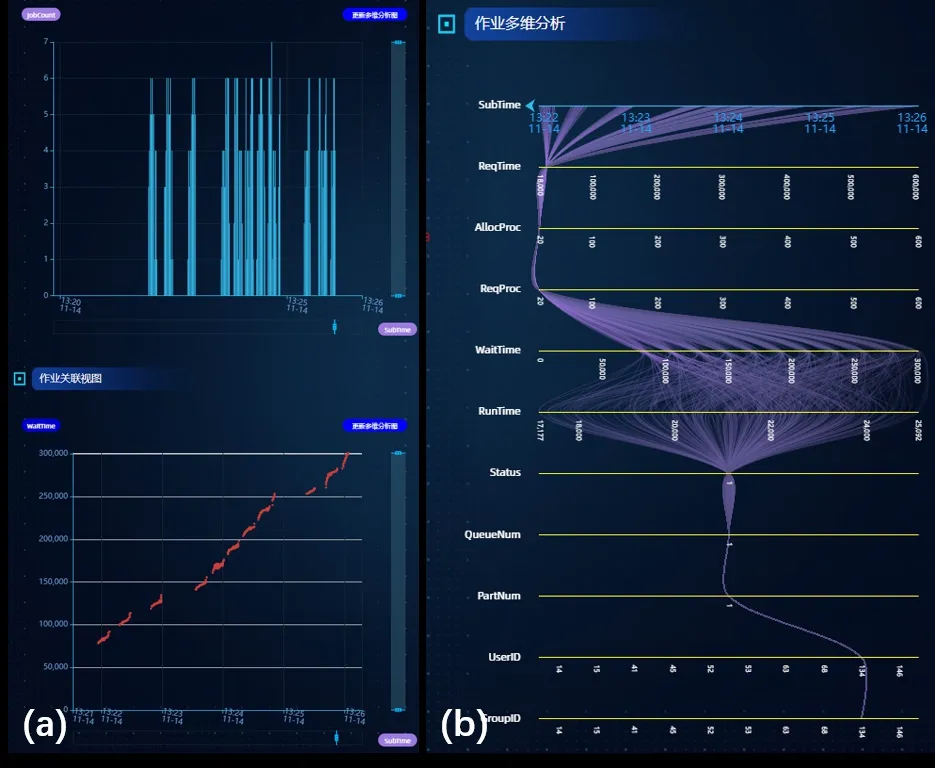
图11 扇型散点簇多维分析。(a)“提交时间”维度与“等待时间”维度呈现正相关,(b)当前作业集合多维分析结果。Fig.11 multi-dimensional analysis of fan-shaped scatter clusters.(a)positive correlation between ‘SubTime’ and ‘WaitTime’,(b)the multi-dimensional analysis results.
环型聚类。在本文中,只讨论单个用户作业产生的环型聚类。由图3E 可知环型聚类中作业的几个基本特征:(1)时间跨度较大,该例中作业提交时间从2017年3月17日至2017年8月11日之间;(2)作业对算力的需求基本一致;(3)等待时间为0,可以看作用户提交的作业在集群中具有较高的处理优先级或用户作业的提交行为在时间上较为离散;(4)作业的执行时间在一个很小的范围内波动。因此,猜测环型聚类产生的原因是用户在不同的时间多次提交相同或类似的作业。而作业本身在算力消耗上的相似性,及作业的频繁提交,形成了大小不一的环型聚类特征。
5 总结与展望
本文首先从SWF日志数据中的基本实体及关系出发,明确数据中存在的时序属性、关联属性与多维属性,并以最基础的时序属性作为主要可视分析对象,确定了两个具体的分析任务:(1)以直观的方式展示日志中作业的并发状态、执行情况,从用户视角观察用户的提交习惯,从集群视角观察作业的调度分配;(2)通过关联分析、多维分析的方式对日志中存在的作业处理模式进行分析。根据分析任务,本文提出了高性能计算集群SWF日志可视分析系统SWFVis,用于帮助分析人员直观观察集群中作业的调度状态,并探索日志数据中存在的潜在模式。在案例分析中,以公开的iPSC/860 与ForHLR II 集群产生的真实数据为例,分析了两者在作业处理、用户提交行为上的差异性,并针对可视化效果中存在的三类作业散点聚类——射线型聚类、扇型聚类、环型聚类进行了多维度的深入分析,总结了上述聚类模式的成因,较好地实现了分析人员对分析任务的需求。
SWFVis 作为信息可视化技术在超算日志分析中的一次尝试,结合了可视化领域中较为成熟的几种可视化方法,包括事件流可视化、关联关系可视化、多维可视化等技术,让人能参与到数据分析的过程中来。然而,随着时间累积以及高性能集群多样化的发展趋势,在超算日志可视分析中,会面临数据规模快速膨胀导致现有可视化视图出现元素密集堆叠、无法直观分析且交互迟缓的现象,数据格式复杂化导致无法找到维度间的相关性等一系类问题。现有的可视分析方法不仅需要持续更新数据映射方式、探索新的数据交互模式,还需要结合机器学习等技术来辅助使用者应对大规模数据的模式识别与信息挖掘。从而更好地发挥人的判别、分析能力,探索模式产生的机理与获得经验结论。
在未来的工作计划中,SWFVis 将在实际生产环境中辅助集群管理员对历史日志进行交互式观察与可视分析。同时,将尝试加入对实时日志数据流的可视分析功能,以达到预警监测、异常捕捉的功能;其次,研究对特定作业或批次进行标定追踪的功能,以观察标定批次作业在不同集群、不同调度策略下产生的分配与执行状态差异。通过对比可视化方法,分析同一任务在两个不同型号集群系统上的结果,给出性价比的差异,指导用户选型。
利益冲突声明
所有作者声明不存在利益冲突关系。
